配置Java Selenium Web自动化测试环境
1、new project->MavenArchetype->name重命名->JDK选择17->Maven的Archetype选择quick-start->creat创建
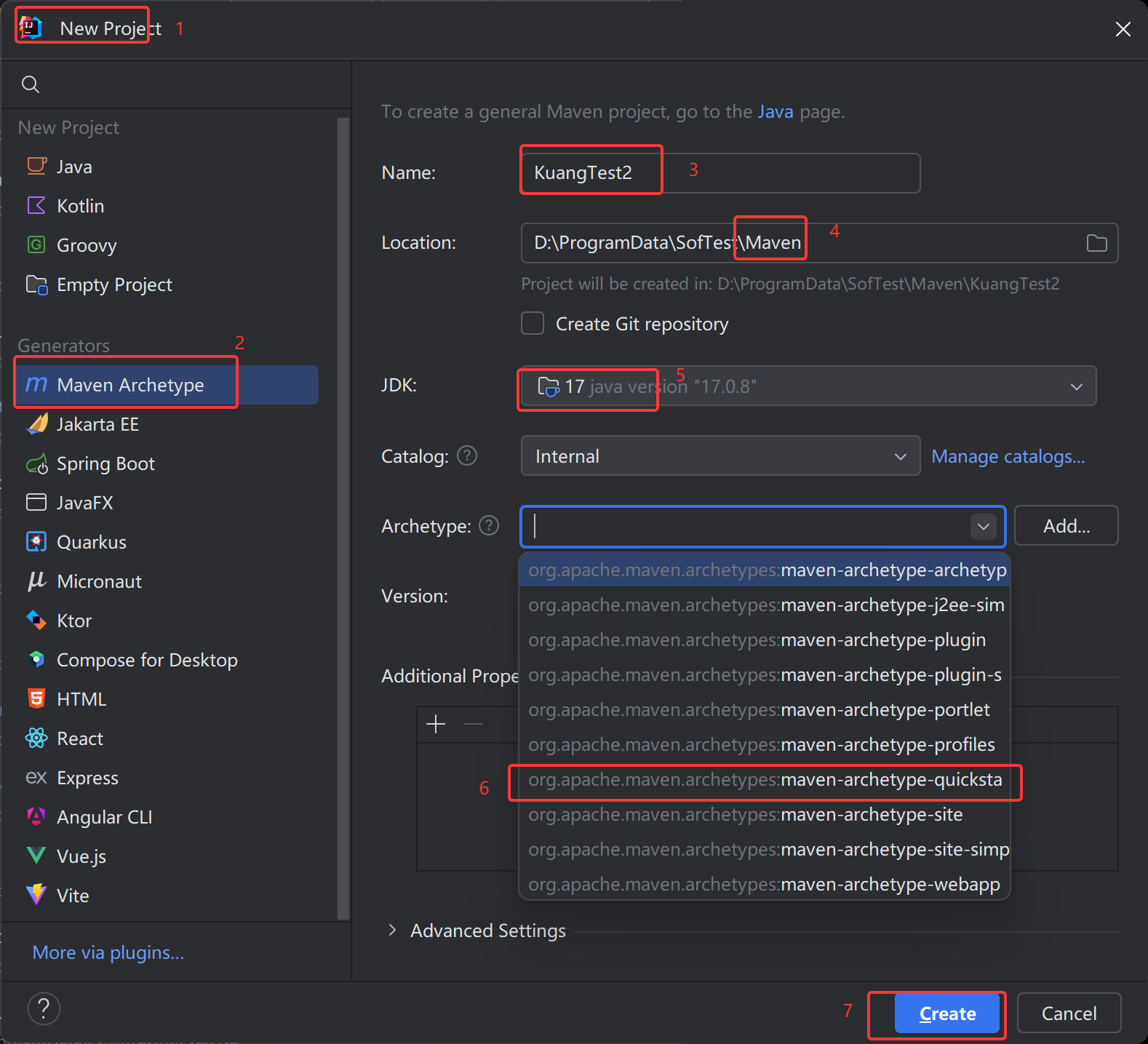
2 pom 导入如下依赖:
<dependencies><!-- Selenium WebDriver --><dependency><groupId>org.seleniumhq.selenium</groupId><artifactId>selenium-java</artifactId><version>4.14.1</version></dependency><!-- WebDriverManager --><dependency><groupId>io.github.bonigarcia</groupId><artifactId>webdrivermanager</artifactId><version>5.6.3</version></dependency><!-- 默认的quick-start框架里应该已经存在junit依赖,用于单元测试 --><dependency><groupId>junit</groupId><artifactId>junit</artifactId><version>3.8.1</version><scope>test</scope></dependency><!-- 用于生成日志信息 --><dependency><groupId>ch.qos.logback</groupId><artifactId>logback-classic</artifactId><version>1.4.8</version></dependency>
</dependencies>
3 下载与自己Chrome浏览器大版本一致的chromedriver
Webdriver浏览器驱动安装地址
https://googlechromelabs.github.io/chrome-for-testing/
我的chrome版本,大版本是136.0
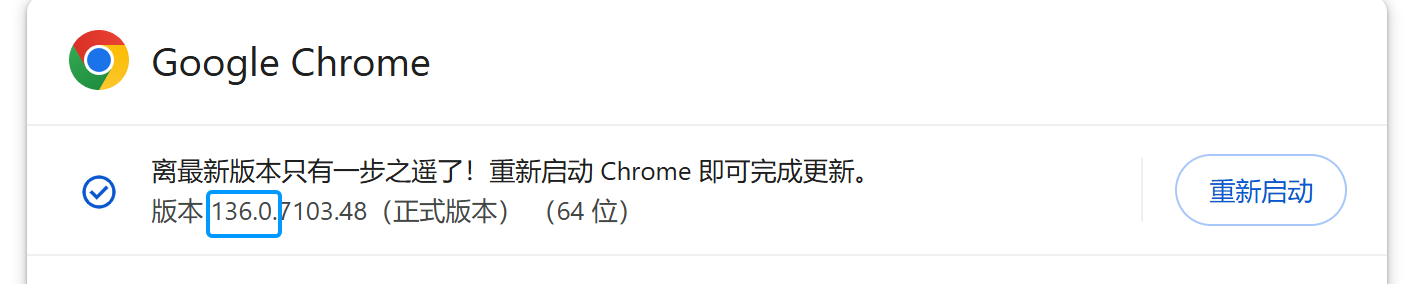
stable的大版本与我的浏览器一致都是136.0

点击stable,确保chrome版本和chromedriver的大版本(136.0)一致

复制搜索该网址,自动开始下载,将下载后的压缩包解压缩后如下

将里面的chromedriver.exe文件复制,粘贴到src新建的drivers文件夹下,具体结构为

4 关闭浏览器自动更新
下载完后一定要关闭Chrome浏览器的自动更新,否则会因为浏览器版本号更新的非常频繁,浏览器与驱动器版本不一致造成访问失败,关闭Chrome浏览器自动更新的方法如下:
ctrl+R进入下面的运行台,输入services.msc回车
找到有关谷歌的如下所有谷歌开头的,启动类型全部改为禁用
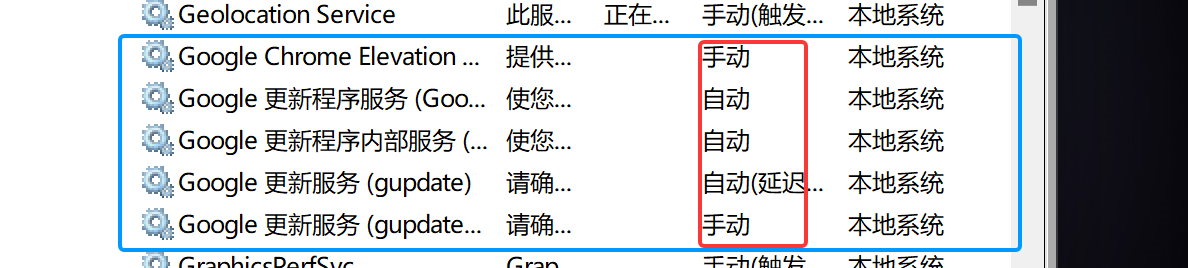
右键点击属性,找到启动类型点禁用 ,点击应用,再点击确定

应用后如下

再次查看属性显示无法自动更新,说明设置禁用成功
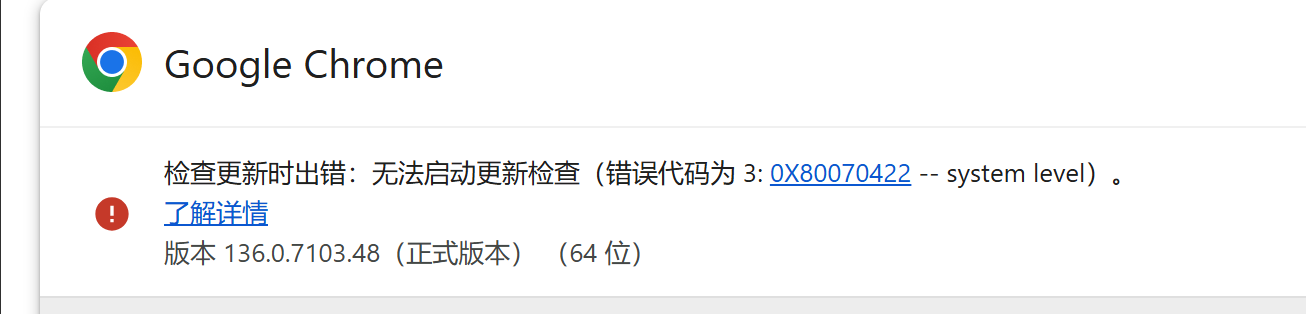
此时浏览器和浏览器驱动都已经具备,自动更新也已经关闭
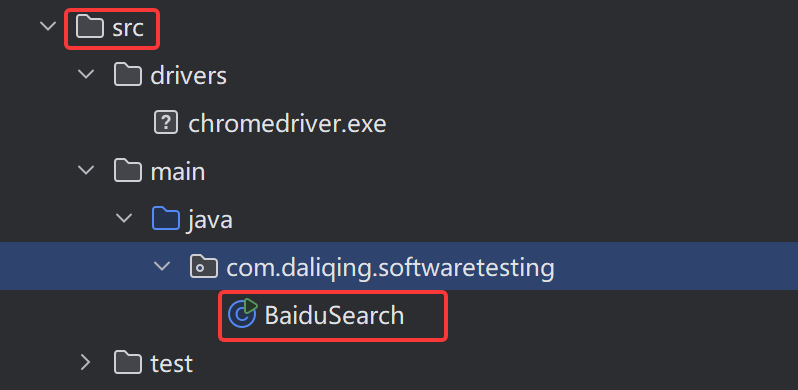
5 创建BaiduSeach类,里面为设置驱动器还有访问百度的方法
项目结构:
代码:
import io.github.bonigarcia.wdm.WebDriverManager;
import org.openqa.selenium.WebDriver;
import org.openqa.selenium.chrome.ChromeDriver;
import org.openqa.selenium.chrome.ChromeOptions;import java.nio.file.Path;
import java.nio.file.Paths;public class BaiduSearch {public static void main(String[] args) {// 设置 ChromeDriver 路径(方法1:通过代码设置)Path p1 = Paths.get("src","drivers","chromedriver.exe");System.setProperty("webdriver.chrome.driver", p1.toAbsolutePath().toString());// 自动管理 ChromeDriverWebDriverManager.chromedriver().setup();// 创建 Chrome 选项ChromeOptions options = new ChromeOptions();options.addArguments("--start-maximized");// 创建 ChromeDriver 实例WebDriver driver = new ChromeDriver(options);try {// 访问百度网站driver.get("https://www.baidu.com");System.out.println("当前页面标题: " + driver.getTitle());Thread.sleep(5000);} catch (InterruptedException e) {e.printStackTrace();} finally {// 关闭浏览器driver.quit();}}
}
5 运行成功,打开了百度页面
