操作系统面试题(3)
21.malloc的底层实现
malloc申请内存会以两种方式向操作系统申请堆内存:
通过 brk() 系统调用从堆分配内存
brk()就是将堆顶指针向高地址移动,获得新的内存空间
通过 mmap() 系统调用在文件映射区域分配内存
mmap() 通过系统调用,在文件映射区分配一块内存,也就是从文件映射区偷了一块内存。
通常情况下,如果分配内存小于128k用brk,大于就用mmap
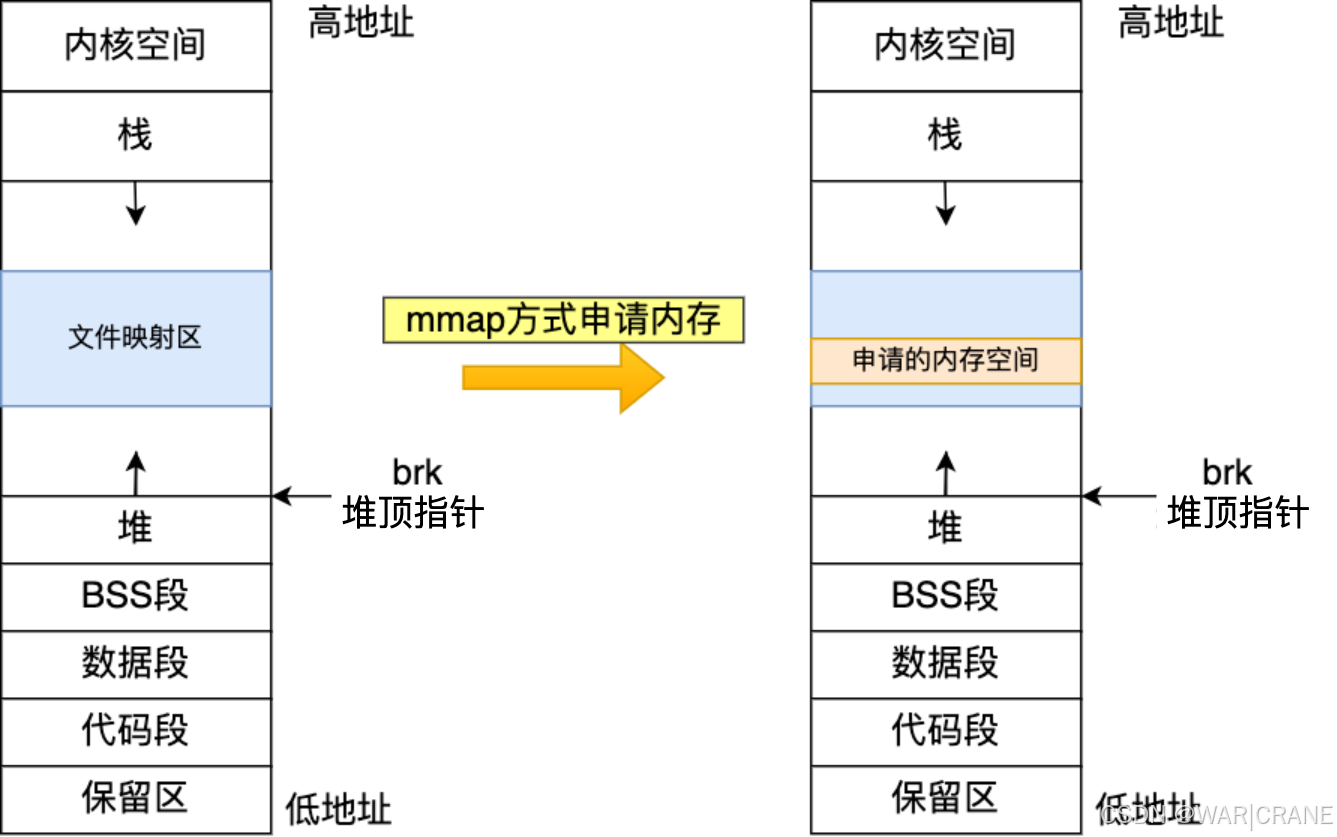
整个内存分配过程如下
第一步:申请虚拟地址空间
类似你买房时“签合同划地盘”,但还没付钱装修(物理内存)。
进程通过brk()或mmap()系统调用,向操作系统“预订”一块虚拟内存区域(此时仅是地址范围,物理内存尚未分配)。第二步:实际使用时触发缺页中断
类似你第一次去新房时发现没钥匙(物理页未分配),物业(内核)紧急处理。
当进程首次读写这块虚拟地址时,CPU发现没有对应的物理内存,触发 缺页中断第三步:内核分配物理内存
物业临时给你钥匙(分配物理页),之后就能正常访问了。
操作系统在缺页中断处理中,实际分配物理内存页,并建立虚拟地址到物理内存的映射。最终完成
至此,内存才真正可用。后续访问不再触发缺页中断(除非内存被换出到Swap)。
22.什么是字节序?怎么判断大端小端
字节序是对象在内存中的存储方式,大端是高位在前(高位在低地址),小端是低位在前(低位在低地址)。
判断系统是大端小端的方法:
union Un {short s; // 2字节char c[2]; // 2字节
};//联合的成员共用一块内存空间int main() {Un un;un.s = 0x0102; // 赋值测试值if (un.c[0] == 1 && un.c[1] == 2) {cout << "大端序 (Big-Endian)" << endl;} else if (un.c[0] == 2 && un.c[1] == 1) {cout << "小端序 (Little-Endian)" << endl;} else {cout << "未知字节序" << endl;}return 0;
}那字节序有什么用呢?
在网络编程中,不同字节序的机器发送和接收到顺序不同。因此字节序的核心作用是解决不同硬件、协议间的数据兼容性问题。
23.Linux的I/O模型、同步异步阻塞非阻塞的区别
IO过程包括:
内核从IO设备中读写数据
进程从内核复制数据
阻塞和非阻塞:
阻塞:调用IO操作时,缓冲区满了,线程或进程会转为阻塞状态直到IO可用
非阻塞:调用IO操作时,内核马上返回结果,如果IO不可用就返回错误。所以非阻塞方式下就要不断轮询访问内核,直到IO可用。
同步IO模型中,进程从内核拷贝数据是阻塞的。
同步和异步:
同步IO模型包括阻塞IO、非阻塞IO、和IO多路复用。特点就是进程从内核拷贝数据是阻塞的。
异步IO就是IO过程的两个阶段都是不阻塞的,等IO完成后内核会向进程发送一个信号。(无需轮询)
同步IO,进程需要 主动参与 IO 操作的全过程,包括等待数据就绪和完成数据拷贝。如果这个接口返回的时候,它的职责已经结束了,那就是同步IO。
异步IO,进程将 整个 IO 操作(包括数据拷贝)交给内核,内核完成后通知进程。
24.IO多路复用的三种方法
(1)select
select把所有监听的文件描述符拷贝到内核中,挂起进程。当某个文件描述符可读或可写的时候,中断程序唤起进程,select将监听的文件描述符再次拷贝到用户空间,然后遍历这些文件描述符找到可用的文件。下次监控的时候需要再次拷贝这些文件描述符到内核空间。select支持监听的描述符最大数量是1024。
(2)poll
大部分和select无异,只不过select通过数组存储需要管理的文件描述符。poll通过链表
(3)epoll(重点)
epoll的特点是基于事件驱动,性能高。epoll的IO复用的过程大概如下:
先通过epoll_create()在内核初始化一个eventpoll实例,同时初始化红黑树和就绪链表;
再通过epoll_ctl()监听并管理红黑树中的文件描述符(插入删除),同时向内核注册文件描述符的回调函数;
然后通过epoll_wait()将进程放到eventpoll的等待队列里,阻塞进程,当某个文件描述符的IO可用,内核会通过回调函数将文件描述符放进就绪链表里,把就绪链表返回到用户空间。
最重要的区别就是select和poll每次调用都要把文件描述符拷贝到内核。而epoll通过epoll_ctl()将文件描述符一次性添加到内核的红黑树中,后续调用无需重复拷贝,只需用epoll_wait()就好。
25.查询进程占用cpu的命令
top 实时进程监控
uptime 系统负载概览
w 登录用户及进程
vmstat 系统整体性能
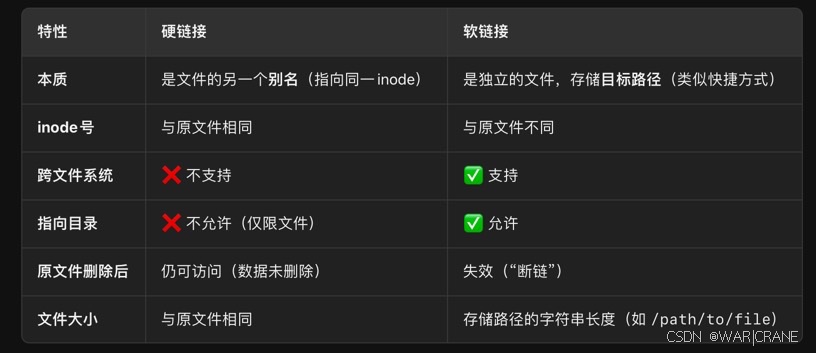
26.硬连接和软连接的区别
27. 查看文件内容命令
(1)cat和tac
cat就是全放到屏幕上,屏幕放不下就只能看见一部分。加上-n就是显示行数
tac从最后一行开始输出。
(2)more和less
more可以翻页,但是只能向后翻页。more可以配合管道符使用。
less在more的基础上可以前后翻页。
(3)head和tail
常用语法:
head [-n number] 文件名 //显示前n行
tail [-n number] 文件名 //显示后n行
(4)nl
nl和cat -n效果相同,显示行号
(5)vim
28.coredump
coredump是程序崩溃时操作系统自动生成的内存快照,记录了崩溃瞬间的程序状态(如内存、寄存器、堆栈信息等)。
结合调试工具(如 GDB),可通过分析 coredump 快速定位崩溃原因,如:
读写越界(数组越界访问、指针指向错误内存,字符串越界读写)
使用的函数线程不安全,读写未加锁。
指针转换错误
堆栈溢出
29.tcpdump
tcpdump是 Linux 系统中功能强大的命令行网络抓包工具,用于捕获和分析网络接口的数据包。它支持过滤特定协议、端口、IP 地址等,是网络故障排查、流量分析和安全检测的必备工具。
- 若不指定网卡(
-i参数),默认监视第一个接口(如 eth0)。 - 示例中未指定网络接口的命令会默认抓取 eth0 流量。
30. crontab
crontab是 Linux 系统的定时任务工具,用于周期性执行命令或脚本。
通过配置文件(crontab -e)设置任务,格式:分 时 日 月 周 [用户] 命令
示例:30 3 * * * /backup.sh 表示每天3:30执行备份脚本。
31.查看后台进程命令
jobs
ps
top(之前查询进程占用cpu也有他,类似资源管理器)