数据中台-数仓分层结构【Doris】
数据仓库采用Doris进行搭建,并分为ODS/DWD/DWM/DWS/ADS等层级结构进行分层数据存储。Doris是百度开源的MPP数据库,可有效支撑大数据量的数据计算和分布式扩展存储。
数据仓库分层架构设计目标
-
解耦与复用性:通过分层隔离原始数据与业务逻辑,提升数据复用性。
-
高效计算:逐层聚合减少重复计算,优化查询性能。
-
数据治理:规范数据血缘、质量监控与权限管理。
-
灵活扩展:适应业务变化,快速响应新需求。
-
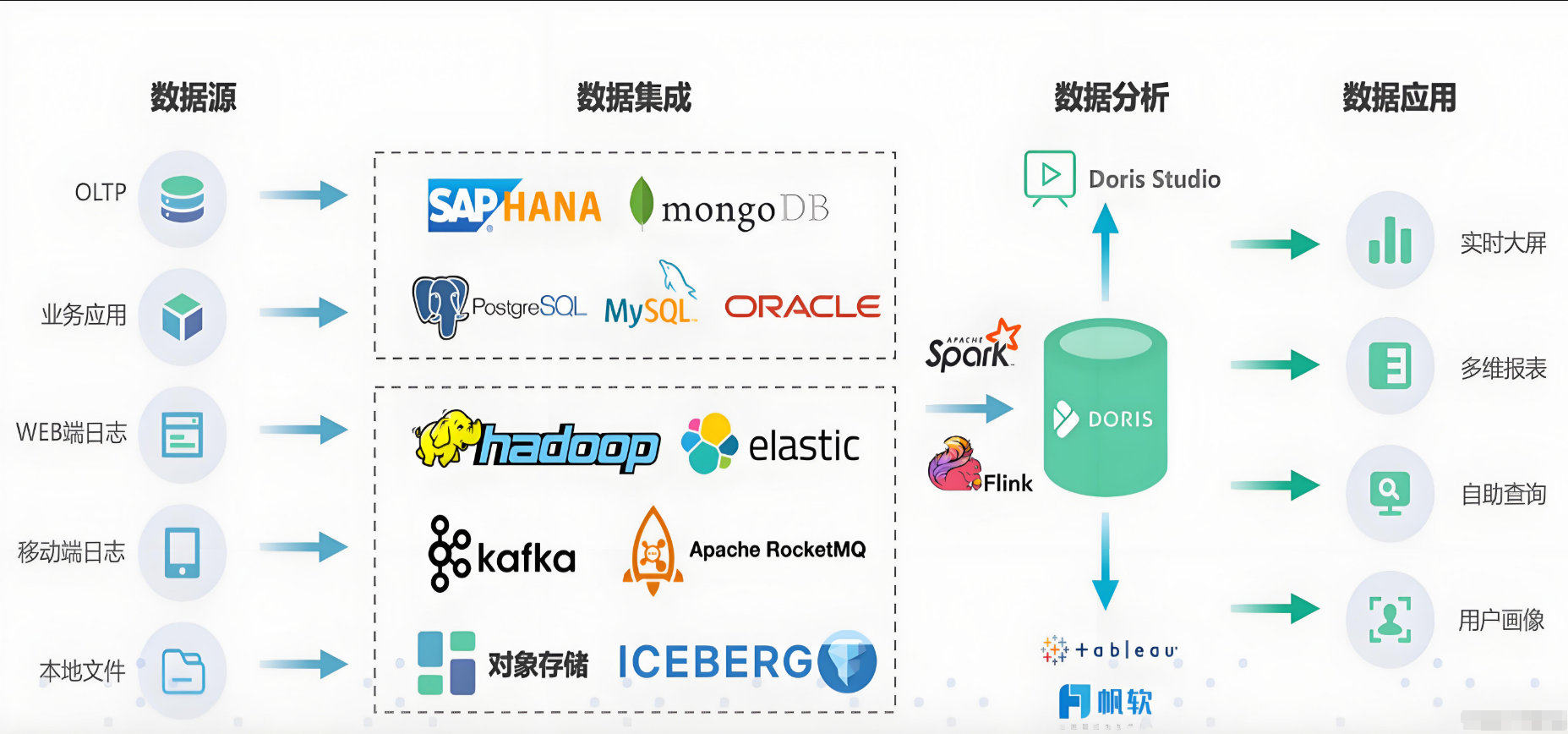
基于Doris的分层架构设计
1. ODS层(Operational Data Store)
-
作用:
-
原始数据接入层,存储未经处理的业务系统数据(全量/增量)。
-
数据格式与来源系统一致,保留历史变更痕迹(如日志、事务表)。
-
-
Doris实现策略:
-
表设计:
-
按业务主题分区(如
dt=YYYYMMDD),支持增量数据按天/小时分区。 -
使用 Duplicate数据模型,存储原始明细数据,避免数据丢失。
-
-
数据接入:
-
通过Flink CDC、Kafka或DataX实时/批量同步MySQL、日志等数据源。
-
-
优化点:
-
启用冷热数据分离策略,将历史数据转存至低成本存储(如HDFS)。
-
-
2. DWD层(Data Warehouse Detail)
-
作用:
-
清洗、标准化ODS层数据,解决脏数据、缺失值、编码不一致等问题。
-
构建业务一致性维度,生成事实表与维度表。
-
-
Doris实现策略:
-
表设计:
-
使用 Aggregate/Unique数据模型,按业务主键去重,确保数据唯一性。
-
定义明确的Schema(如字段类型、约束),添加注释说明业务含义。
-
-
ETL流程:
-
通过Spark/Flink进行数据清洗(如过滤无效记录、补全默认值)。
-
关联维度表生成宽表(如用户ID转用户名、商品ID转类目)。
-
-
优化点:
-
利用Doris的 物化视图 预计算常用维度组合,加速查询。
-
-
3. DWM层(Data Warehouse Middle)
-
作用:
-
轻度汇总层,基于DWD层数据进行跨主题的中间层聚合(如按小时/天粒度统计)。
-
服务于共性业务指标(如UV、PV、交易额),减少上层重复计算。
-
-
Doris实现策略:
-
表设计:
-
使用 Aggregate数据模型,预聚合常用维度(如时间、地域、产品线)。
-
按时间范围分桶(如按周分桶),提升范围查询性能。
-
-
数据处理:
-
通过定时任务(Airflow/DolphinScheduler)调度SQL实现增量聚合。
-
-
优化点:
-
针对高频查询指标,设置 Bloom Filter索引 加速过滤。
-
-
4. DWS层(Data Warehouse Service)
-
作用:
-
高度汇总层,面向业务主题的宽表设计(如用户画像、订单分析)。
-
提供可直接查询的指标数据,支持OLAP分析与BI报表。
-
-
Doris实现策略:
-
表设计:
-
使用 Duplicate/Aggregate模型,按业务场景设计宽表(如用户行为宽表含点击、购买、浏览)。
-
分区键选择高频过滤字段(如
user_id、product_id)。
-
-
数据加工:
-
通过Doris的 Rollup表 实现多维度上卷(如从省份到国家层级汇总)。
-
-
优化点:
-
启用 动态分区 自动管理分区生命周期。
-
-
5. ADS层(Application Data Service)
-
作用:
-
应用数据层,直接对接前端业务系统(如报表、API接口)。
-
按需加工个性化指标,满足实时/离线场景的快速响应。
-
-
Doris实现策略:
-
表设计:
-
使用 Unique模型 存储最终结果数据(如每日营收报表、实时大屏指标)。
-
根据查询需求设置合适的分桶数(避免数据倾斜)。
-
-
数据同步:
-
通过Doris的 External Table 直接查询Hive/HDFS数据,减少数据迁移成本。
-
-
优化点:
-
为高频查询配置 查询缓存(如Session级别缓存)。
-
-
Doris分层架构的核心技术优势
-
高性能查询:
-
MPP架构 + 列式存储,支持高并发复杂查询。
-
分区与分桶策略结合,减少数据扫描范围。
-
-
灵活数据模型:
-
Aggregate/Unique/Duplicate模型适配不同场景。
-
物化视图与Rollup表实现预计算加速。
-
-
实时与离线融合:
-
支持批量数据导入(Broker Load)与实时流写入(Routine Load)。
-
-
资源隔离:
-
通过资源标签(Resource Tag)隔离不同层级负载,保障核心任务稳定性。
-
分层数据流转示意图
sql
复制
下载
数据源 → ODS层(原始数据) ↓ ETL清洗 DWD层(明细数据) ↓ 轻度聚合 DWM层(中间汇总) ↓ 主题宽表构建 DWS层(服务数据) ↓ 业务加工 ADS层(应用数据) → BI/报表/API
总结
基于Doris的分层架构设计,通过 ODS→DWD→DWM→DWS→ADS 逐层加工,实现了数据从原始采集到业务可用的高效转化。Doris凭借其实时分析能力、灵活数据模型与分布式架构,成为支撑数据中台建设的理想引擎,尤其适用于高并发查询、实时报表与复杂分析场景。