基于Kubernetes的Apache Pulsar云原生架构解析与集群部署指南(上)
#作者:闫乾苓
文章目录
- 概念和架构
- 概述
- 主要特点
- 消息传递
- 核心概念
- Pulsar 的消息模型
- Pulsar 的消息存储与分发
- Pulsar 的高级特性
- 架构
- Broker
- BookKeeper
- ZooKeeper
概念和架构
概述
Pulsar 是一个多租户、高性能的服务器到服务器消息传递解决方案。Pulsar 最初由雅虎开发,目前由Apache 软件基金会管理。
主要特点
- 原生支持 Pulsar 实例中的多个集群,并可跨集群实现消息的无缝地理复制。
- 发布和端到端延迟非常低。
- 无缝扩展到超过一百万个主题。
- 一个简单的客户端 API,具有Java、Go、Python和C ++的绑定。
- 主题的多种订阅类型(独占、共享和故障转移)。
- Apache BookKeeper提供持久消息存储,保证消息传递。无服务器轻量级计算框架Pulsar Functions提供流原生数据处理能力。
- 基于 Pulsar Functions 构建的无服务器连接器框架Pulsar IO可以更轻松地将数据移入和移出 Apache Pulsar。
- 当数据老化时,分层存储会将数据从热/温存储卸载到冷/长期存储(例如 S3 和 GCS)。
消息传递
Pulsar 基于发布-订阅模式(通常缩写为 pub-sub)。在此模式下,生产者向主题发布消息;消费者 订阅这些主题,处理传入的消息,并在处理完成后向代理发送确认。
订阅创建后,Pulsar会保留所有消息,即使消费者断开连接也是如此。只有当消费者确认所有消息均已成功处理时,保留的消息才会被丢弃。
如果某条消息消费失败,你希望该消息再次被消费,你可以启用消息重投机制,请求broker重新发送该消息。
核心概念
消息
消息是 Pulsar 的基本“单位”。下表列出了消息的组成部分
| 成分 | 描述 |
|---|---|
| 值/数据有效载荷 | 消息携带的数据。 |
| 键 | 消息可以选择用键进行标记,这对于主题压缩等操作很有用。 |
| 特性 | 用户定义属性的可选键/值映射。 |
| 生产者名称 | 生成消息的生产者的名称。如果未指定生产者名称,则使用默认名称。 |
| 主题名称 | 发布消息的主题的名称。 |
| 架构版本 | 生成消息的模式的版本号。 |
| 序列 ID | 每条 Pulsar 消息都属于其主题上的一个有序序列。消息的序列 ID 最初由其生产者分配,指示其在该序列中的顺序,也可以自定义。 |
| 序列 ID | 可用于消息去重。如果brokerDeduplicationEnabled设置为true,则每条消息的序列 ID 在主题(非分区)或分区的生产者中都是唯一的。 |
| 消息 ID | 消息持久化存储后,bookies 会立即为其分配消息 ID。消息 ID 指示消息在账本中的特定位置,并且在 Pulsar 集群中是唯一的。 |
| 发布时间 | 消息发布的时间戳。该时间戳由生产者自动应用。 |
| 活动时间 | 应用程序附加到消息的可选时间戳。例如,应用程序会在消息处理时附加时间戳。如果事件时间未设置任何内容,则值为0。 |
消息默认大小为 5MB。您可以通过以下配置来设置消息的最大大小
在broker.conf文件中
# The max size of a message (in bytes).
maxMessageSize=5242880
在bookkeeper.conf文件中
# The max size of the netty frame (in bytes). Any messages received larger than this value are rejected. The default value is 5 MB.
nettyMaxFrameSizeBytes=5253120
主题(Topic)
主题是消息传递的基本单元,生产者将消息发送到主题,消费者从主题中消费消息。
Pulsar 支持两种类型的主题:
- 持久化主题(Persistent Topic):消息存储在持久化存储中(如 Apache BookKeeper),确保消息不会丢失。
- 非持久化主题(Non-Persistent Topic):消息不存储在持久化存储中,适合对可靠性要求较低但性能要求高的场景。
生产者(Producer)
- 生产者是负责向主题发布消息的客户端。
- 生产者可以选择同步或异步的方式发送消息。
Pulsar 支持消息批处理(Batching)和压缩(Compression),以提高消息传输效率。
消费者(Consumer)
-
消费者是从主题中读取消息的客户端。
-
消费者可以以多种模式订阅主题:
- 独占模式(Exclusive):只有一个消费者可以消费消息。
- 共享模式(Shared):多个消费者共享消息,每个消息只被一个消费者消费。
- 故障转移模式(Failover):主消费者消费消息,如果主消费者失败,则备用消费者接管。
- 键共享模式(Key_Shared):根据消息的键(Key)分配给不同的消费者。
订阅(Subscription)
订阅定义了消费者如何从主题中消费消息。
Pulsar 支持两种订阅类型:
- 独占订阅(Exclusive Subscription):只有一个消费者可以消费消息。
- 共享订阅(Shared Subscription):多个消费者可以同时消费消息。
- 故障转移订阅(Failover Subscription):主消费者消费消息,备用消费者在主消费者失败时接管。
Pulsar 的消息模型
Pulsar 提供了两种主要的消息模型:
队列模型(Queue Model)
- 在队列模型中,消息被多个消费者共享,每个消息只被一个消费者消费。
- 这种模型适用于负载均衡的场景,例如任务分发。
流模型(Stream Model) - 在流模型中,每个消费者独立消费消息流,所有消费者都能接收到完整的消息流。
- 这种模型适用于需要广播消息的场景,例如实时数据分析。
Pulsar 的消息存储与分发
分布式架构
Pulsar 的架构分为两层:
- Broker 层:负责接收和分发消息。
- BookKeeper 层:负责持久化存储消息。
这种分离设计使得 Pulsar 能够扩展到大规模集群,同时保证高性能和高可靠性。
消息分片(Segmentation)
Pulsar 将主题划分为多个分片(Segment),每个分片由 BookKeeper 中的不同节点存储。
这种分片机制提高了存储效率和容错能力。
消息保留与过期
Pulsar 支持灵活的消息保留策略:
- 基于时间的保留:消息在指定时间后自动删除。
- 基于大小的保留:当主题的总消息大小超过限制时,旧消息会被删除。
这些策略可以通过配置进行调整。
Pulsar 的高级特性
消息确认(Acknowledgment)
消费者在成功处理消息后,会向 Pulsar 发送确认(Ack)。
如果消费者未能确认消息,Pulsar 会重新传递该消息。
消息去重(Deduplication)
Pulsar 支持消息去重功能,确保即使生产者重复发送消息,消费者也不会收到重复的消息。
延迟消息(Delayed Messages)
Pulsar 支持延迟消息功能,允许生产者指定消息的投递时间。
例如,可以设置消息在 10 秒后才被消费者接收。
消息压缩(Compression)
Pulsar 支持多种压缩算法(如 LZ4、Zlib 等),以减少消息在网络中的传输开销。
消息 TTL(Time-to-Live)
Pulsar 支持为消息设置 TTL,超时未被消费的消息会被自动丢弃。
架构
Apache Pulsar 是一个分布式发布/订阅消息系统,其架构设计非常独特且高效,结合了传统消息队列和流处理系统的优点。Pulsar 的架构分为两层:Broker 层 和 BookKeeper层,并通过多租户、跨地域复制等特性支持大规模分布式部署。
Pulsar 的架构可以概括为以下三个核心组件:
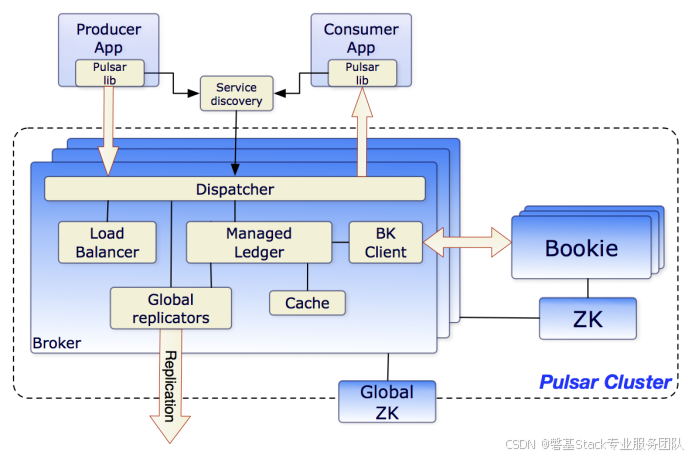
Broker
Broker 的职责
- 消息接收与分发:
- 生产者将消息发送到 Broker,Broker 将消息写入 BookKeeper。
- 消费者从 Broker 请求消息,Broker 从 BookKeeper 中读取消息并返回。
- 主题管理:
- 创建、删除和管理主题。
- 支持分区主题(Partitioned Topic),即将一个主题划分为多个分区以提高吞吐量。
- 订阅管理:
- 管理消费者的订阅模式(如独占、共享、故障转移等)。
- 跟踪消费者的消费进度(Cursor)。
Broker 的高可用性
- 多个 Broker 节点组成一个集群,通过负载均衡器分配流量。
- 如果某个 Broker 节点失效,其他节点会接管其工作,确保服务不中断。
BookKeeper
BookKeeper 的职责
- 消息持久化:
- 每条消息被存储为一个日志条目(Ledger Entry)。
- 每个主题的消息被分割成多个日志(Ledger),以便于管理和扩展。
- 数据分片与副本:
- 每个 Ledger 被分成多个片段(Segment),分布存储在不同的 BookKeeper 节点上。
- 每个 Segment 默认有三个副本,分布在不同的物理节点上,确保数据的高可用性。
- 数据一致性:
- 使用 Quorum 机制(例如 2/3 副本写入成功)保证数据的一致性和可靠性。
BookKeeper 的性能优化
- 读写分离:
- 写操作由 Leader 节点负责,读操作可以从任意副本节点执行。
- 缓存机制:
- BookKeeper 节点会缓存最近的数据,减少磁盘 I/O 开销。
ZooKeeper
ZooKeeper 的职责
- 元数据管理:
- 存储主题、分区、订阅、消费者组等元数据。
- 记录每个消费者的消费偏移量(Offset)。
- 集群协调:
- 管理 Broker 和 BookKeeper 节点的状态。
- 实现分布式锁和选举机制。
ZooKeeper 的高可用性
- 使用多个 ZooKeeper 节点组成一个集群(Ensemble),通过 ZAB 协议实现一致性。
- 如果某个 ZooKeeper 节点失效,其他节点会接管其工作。