卷积神经网络基础(八)
六、与学习相关的技巧
下面我们会进入全新的一章,主要学习与学习相关的技巧。
本章主要介绍神经网络学习过程的重要观点,主题涉及寻找最优权重参数的最优化方法、权重参数的初始值、超参数的设定方法等。为了应对过拟合,本章还会介绍权值衰减、Dropout等正则化方法,并进行实现。最后会介绍一些研究实验中Batch Normalization方法进行简单介绍。
6.1 参数更新
神经网络学习的目的就是找到使损失函数的值尽可能小的参数。这是寻找最优参数的问题,解决这个问题的过程称作最优化(optimization)。然而,这个问题极其复杂,无法轻易找到最优解,并且神经网络中参数数量庞大,最优化问题更加复杂。
在前几章的学习中,我们使用参数梯度(导数)作为线索。使用参数梯度,沿梯度方向更新参数并重复该步骤,逐渐靠近最优参数,这个过程称为随机梯度下降法(stochastic gradient descent),简称SGD。这个方法简单,但也算聪明,只不过根据不同问题也有更好地方法。
6.1.1 探险家故事
SGD法就好比探险家故事。
这个探险家在广袤的干旱地带旅行,坚持寻找山谷。他的目的就是要找到最深的谷底,但是他给自己制定了两个规则:1、不看地图2、把眼睛蒙上。 因此他什么也看不见,那要如何寻找呢?
这就是在寻找最优化参数时的情况,我们要在没有地图且不睁眼的情况下寻找最深的谷底。尽管看不到周围,但是我们能够知道当前所在位置的坡度,(即通过脚底感受地面的倾斜情况)。于是我们可以朝着当前所在位置坡度最大的方向前进,这就是SGD的策略。我们只要重复这个策略,总会到达谷底。
6.1.2 SGD
接下来我们复习一下SGD:
将需要更新的权重参数记为W,损失函数关于W的梯度记为,η表示学习率。实际上会先取好一个值如0.01、0.0001等。⬅表示用右边的值更新左边的值。SGD是一个朝着梯度方向只前进一定距离的简单方法,现在我们将其以python实现。
Class SGD:def __init__(self, lr=0.01):self.lr = lrdef update(self, params, grads):for key in params,keys():params[key] -= self.lr * grads[key]lr表示学习率(learning rate),这个变量会保存为实例变量。此外类中还定义了update方法,这个方法会被反复调用。参数params和grads是字典型变量,按params['W1']、grads['W1']的形式分别保存权重参数和他们的梯度。有了类的定义,我们就可以在神经网络中实现它:
network = TwoLayerNet()
optimizer = SGD()for i in range(10000):...x_batch, t_batch = get_mini_batch(...)grads = network.gradient(x_batch, t_batch)params = network.paramsoptimizer.update(params, grads)...参数的更新由optimizer实现,即SGD承担这个角色。我们这里仅需要将参数和梯度信息传递给optimizer。
像这样单独实现最优化的类,功能模块变得简单。后面我们会实现另一个最优化方法Momentum,同样具有update方法。这样只用将optimizer = SGD()更换为optimizer = Momentum(),就可以从SGD切换回Momentum。

6.1.3 SGD缺点
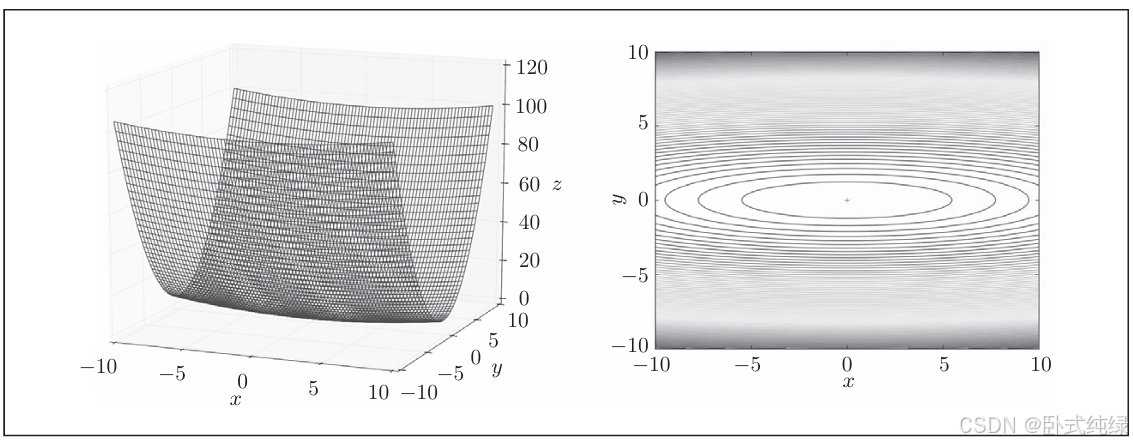
SGD实现较为简单,但执行起来存在一定的缺陷。比如考虑一个实际问题,求解下面这个函数的最小值问题:
这个函数表示的是向x轴方向延伸的碗状函数,其等高线也是呈向x轴方向延伸的椭圆状。
现在我们来看一下它的梯度,用图表示就是:
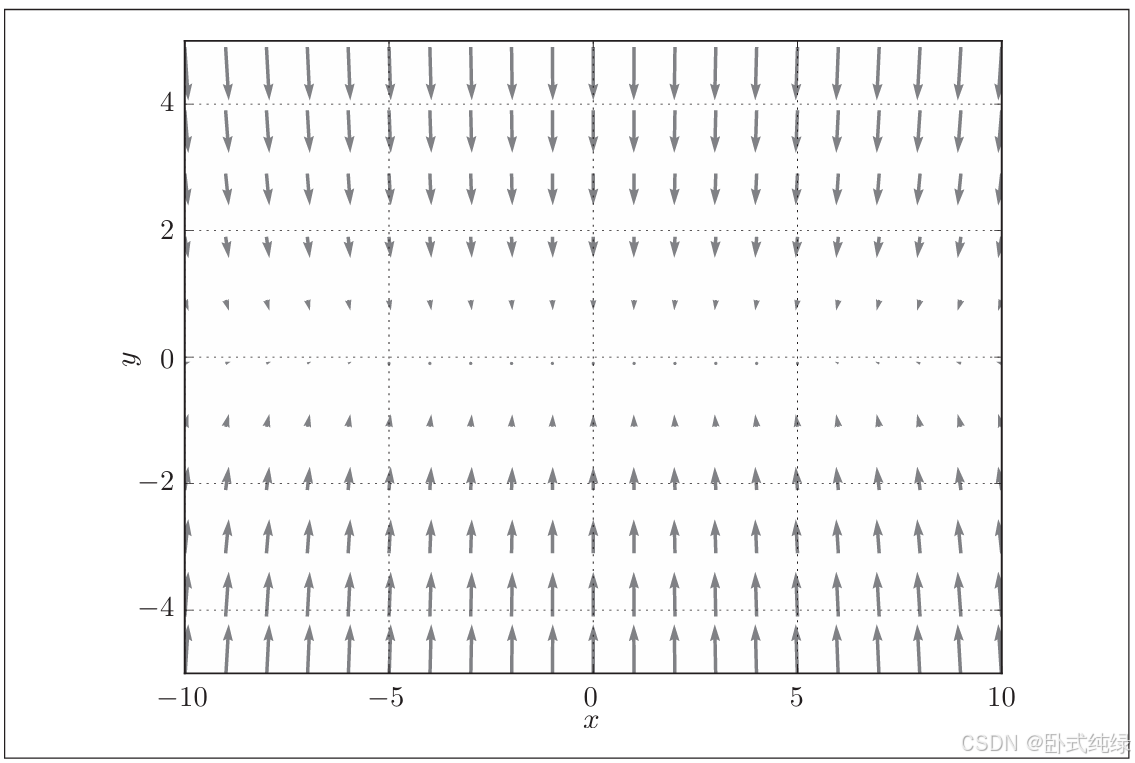
这个梯度的特征是,y轴方向上大,x轴方向上小。换句话说, 就是y轴方向的坡度大,而x轴方向的坡度小。这里需要注意的是,虽然式 (6.2)的最小值在(x,y)=(0,0)处,但是图6-2中的梯度在很多地方并没有指向(0,0)。
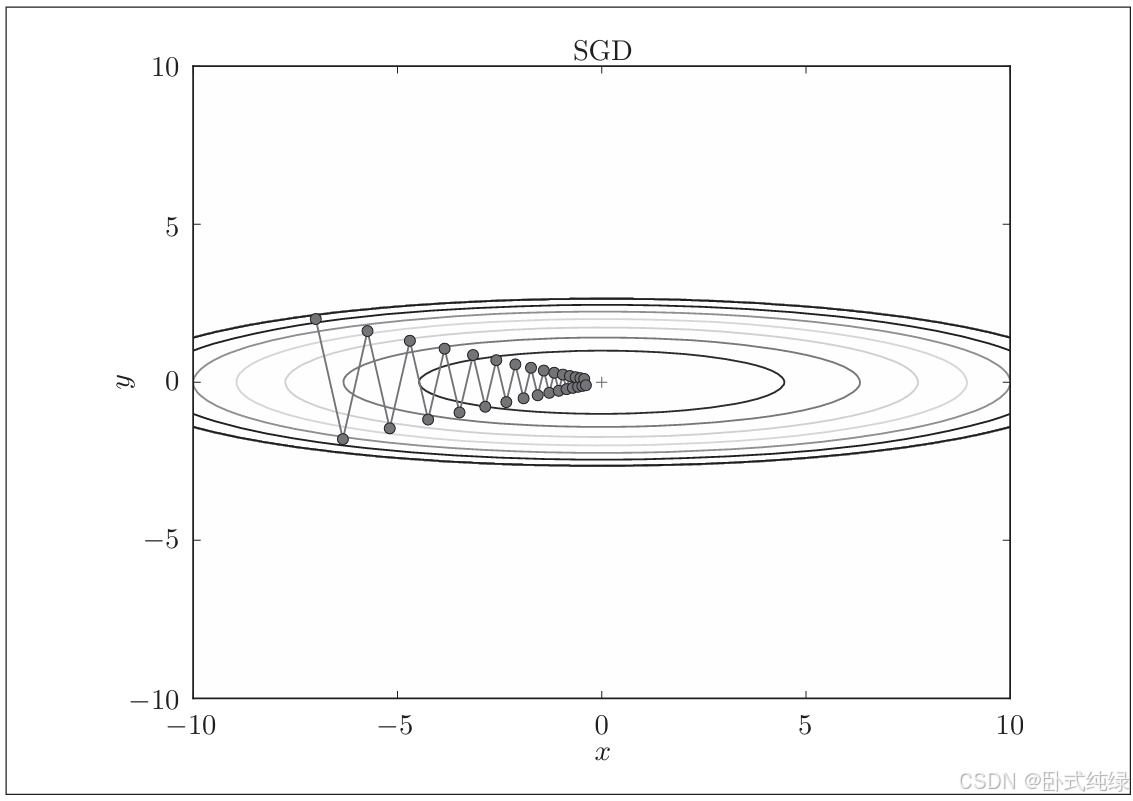
我们来尝试对图6-1这种形状的函数应用SGD。从(x,y)=(−7.0,2.0)处 (初始值)开始搜索,结果如图6-3所示。 在图6-3中,SGD呈“之”字形移动。这是一个相当低效的路径。也就是说, SGD的缺点是,如果函数的形状非均向(anisotropic),比如呈延伸状,搜索 的路径就会非常低效。因此,我们需要比单纯朝梯度方向前进的SGD更聪明的方法。SGD低效的根本原因是,梯度的方向并没有指向最小值的方向。