【Machine Learning Q and AI 读书笔记】- 05 利用数据减少过拟合现象
Machine Learning Q and AI 中文译名 大模型技术30讲,主要总结了大模型相关的技术要点,结合学术和工程化,对LLM从业者来说,是一份非常好的学习实践技术地图.
本文是Machine Learning Q and AI 读书笔记的第5篇,对应原书第五章 《利用数据来减少过拟合现象》.
TL;DR
本章从数据的角度解决模型过拟合问题,把常用方法分成以下3类:
- 采集更多数据
- 数据增强
- 预训练
采集更多数据(Collecting more data)
One of the best ways to reduce overfitting is to collect more (goodquality) data.
减少过拟合现象最好的方式之一是采集更多高质量的数据. 那么,如何判断一个模型是否能从更多数据中提升能力,可以通过绘制学习曲线(Learning Curve)来判断.
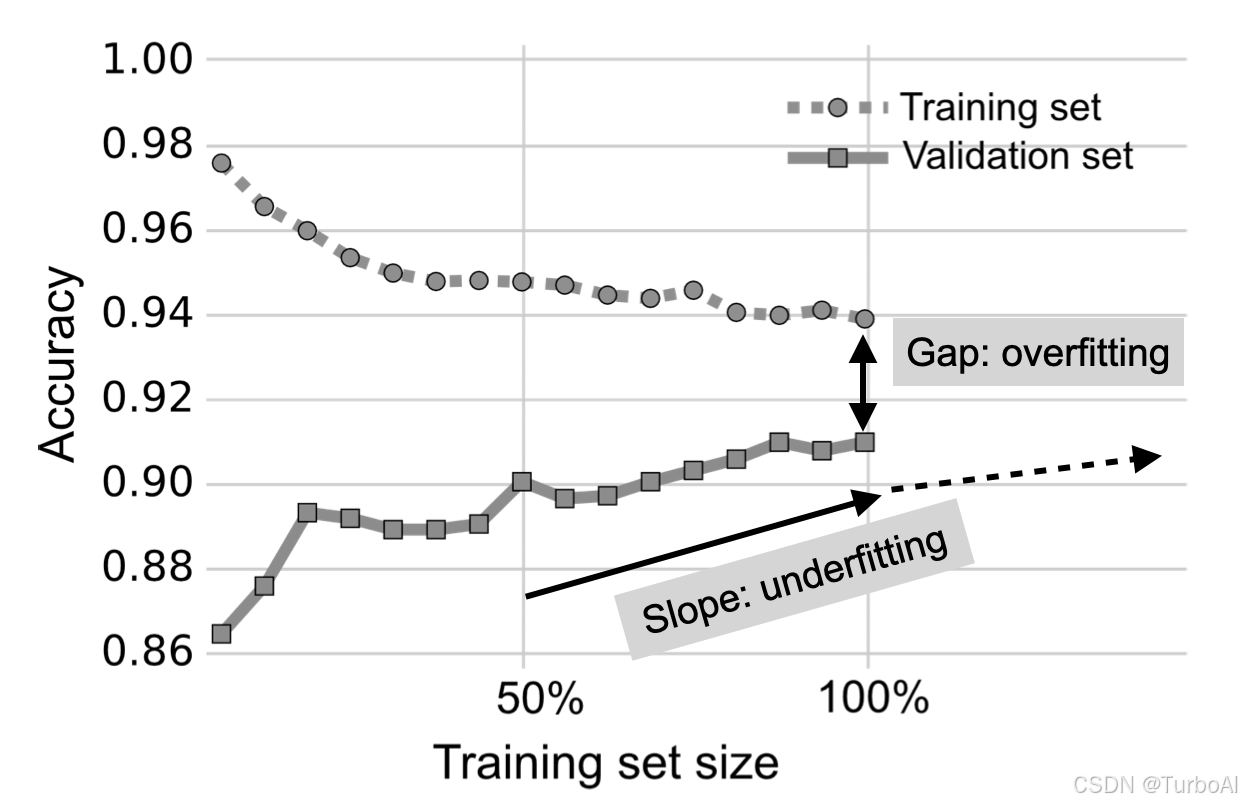
如何绘制学习曲线呢? 可以让模型在不同大小的训练集上进行训练,并且在固定大小的验证集(测试集)上对训练后的模型进行评估. 如果随着训练集大小的增加,模型在验证集上的准确性也会提高,则表明通过采集更多数据能提升模型性能.
模型在训练集与验证集上的表现的差距,反应了过拟合的程度,差距越大,过拟合越严重。而验证集上的正确率随着训练集增大而提高时,说明模型存在欠拟合,增加数据量会有帮助.
数据增强(Data Augmentation)
Data augmentation refers to generating new data records or features based on existing data.
数据增强是指基于现有数据生成新的数据样本或者特征.
通过数据增强,我们能生成原始数据的多个不同版本,从而提升模型的泛化能力. 原因在原文中有解释.
Augmented data can help the model to generalize better since it makes it harder to memorize spurious information via training examples or features (or exact pixel values for specific pixel locations in the case of image data).
增强数据可以帮助模型更好地泛化,因为它使得模型更难通过训练样本或特征(在图像数据的情况下,即特定像素位置的精确像素值)来记忆虚假信息。
数据增强技术广泛运用在了图像和文本数据上.
预训练(Pretraining)
自监督学习允许我们通过大型无标签数据集对神经网络进行预训练,这也有助于减少在较小的目标数据集上发生过拟合的现象.
总结
本章主要从数据量增加,数据增强,和预训练三个与数据量相关的方面讨论如何降低过拟合.