[Token]What Kind of Visual Tokens Do We Need? AAAI2025
What Kind of Visual Tokens Do We Need? Training-free Visual Token Pruning for Multi-modal Large Language Models from the Perspective of Graph
我们需要什么样的视觉标记?从图的角度看多模态大型语言模型的免训练可视化标记剪枝
paper|code
代码集成度较高,主要剪枝实现代码
文章目录
- Abstract
- Motivation
- Method
- Experiment
- Inspiration
Abstract
多模态大型语言模型经常使用大量的视觉标记来弥补其视觉缺陷,导致计算量过大,视觉冗余明显。在本文中,我们研究了 MLLM 需要什么样的视觉标记,前景和背景标记对于 MLLM 都至关重要。基于这一观察,我们提出了一种基于图的免训练视觉标记修剪方法,G-Prune将视觉token视为节点,并根据它们的语义相似性构建它们的连接。之后,信息流通过加权链接传播,迭代后最重要的token保留给 MLLM。
Motivation
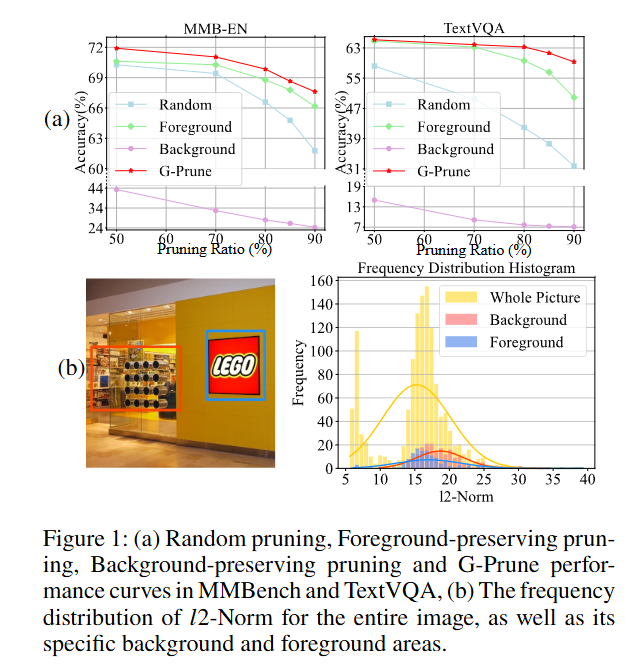
Fig. 1(a)分别展示了随机裁剪、保前景裁剪、保背景裁剪和G-Prune几种裁剪方式的acc随着裁剪率变化的曲线。
Fig. 1(b)展示了整个图像及其特定背景和前景区域的频率分布,计算前景和背景的𝑙2-Norm频率分布直方图,发现它们的分布具有显着的重叠。
为什么这里要展示L2Norm-频率直方图?
L2-Norm用来衡量特征对图片决策的重要程度。如果直接剪掉L2-Norm较低的分支,可能会误删图像中的重要信息。这里统计了整张图片、背景和前景在不同L2-Norm上的频率,重叠部分表示MLLM 任务需要更精细的剪枝策略(如 G-Prune),不能简单依赖 L2-Norm 或前景保留。
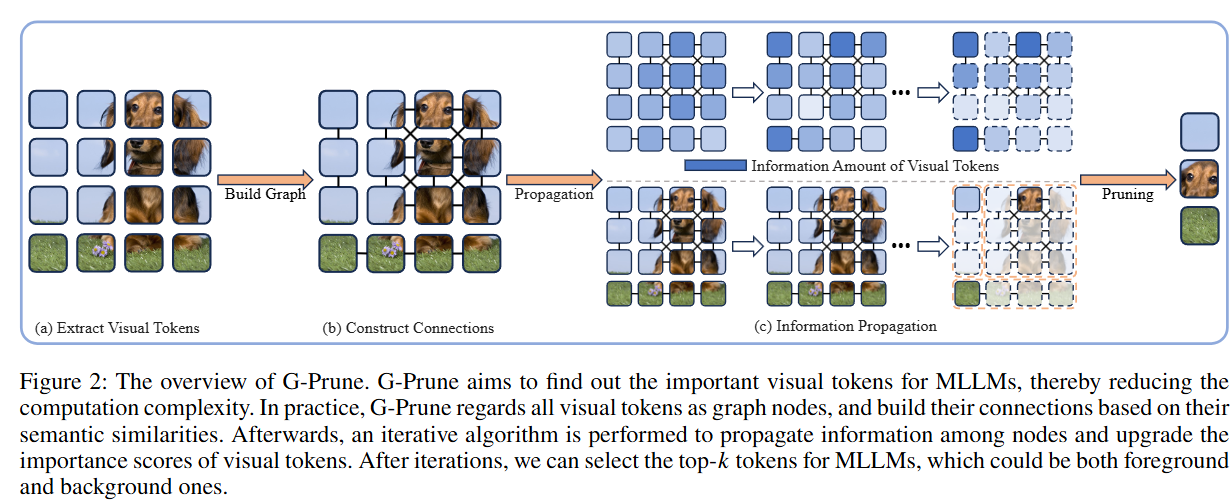
将视觉token视为图形节点,并根据特征距离构建其连接。之后,通过迭代算法在节点之间进行信息传播,以更新重要性得分。最后,可以为MLLM选择最重要的令牌,这可能是前景或背景。这样,可以为MLLM选择最代表的视觉令牌,从而大大降低了序列长度和计算复杂性。
Method

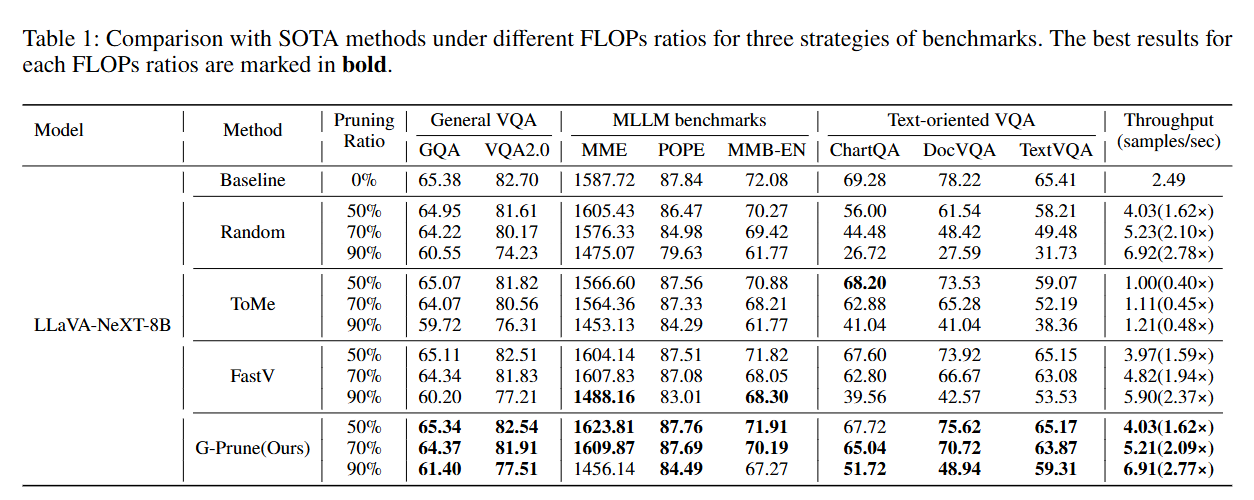
Experiment
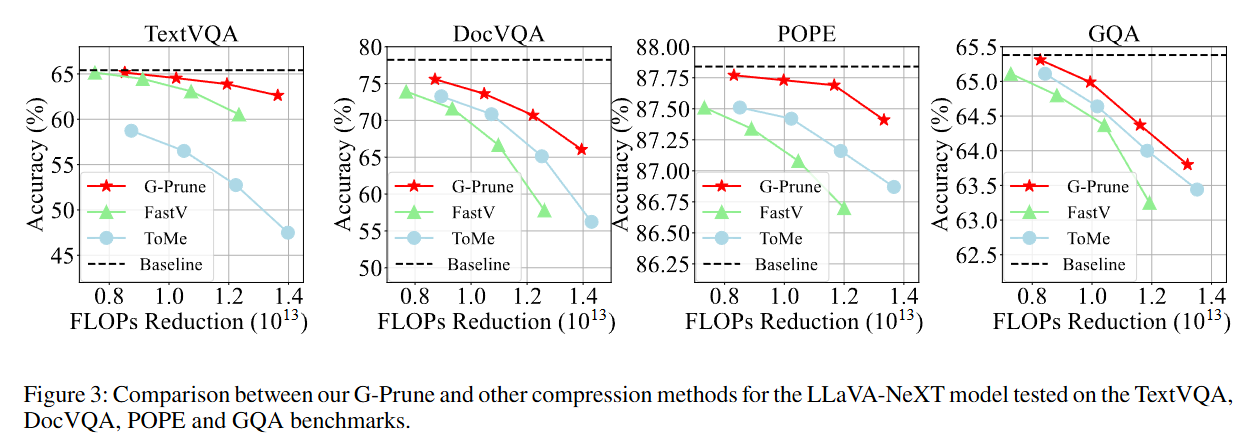
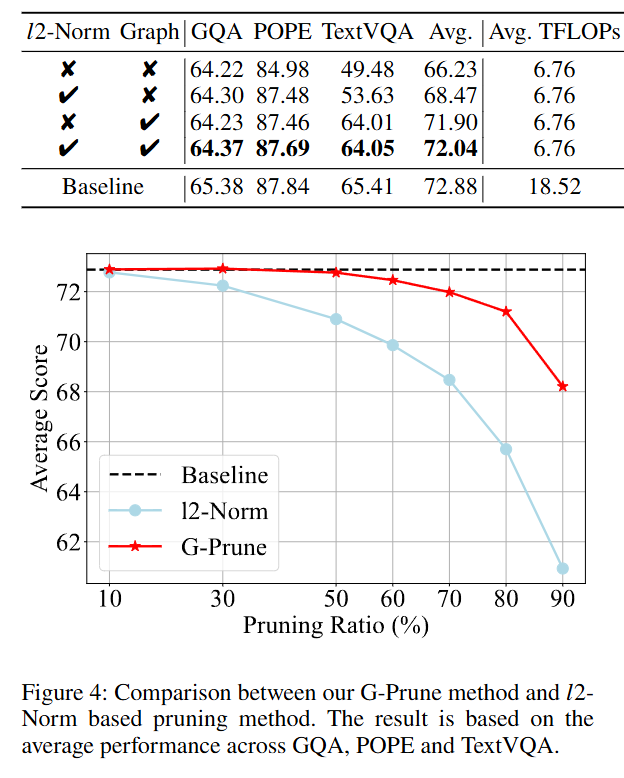
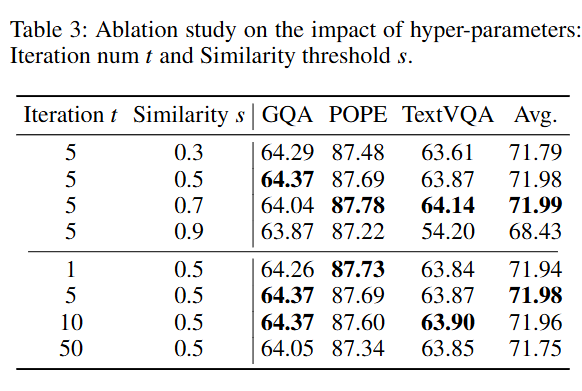
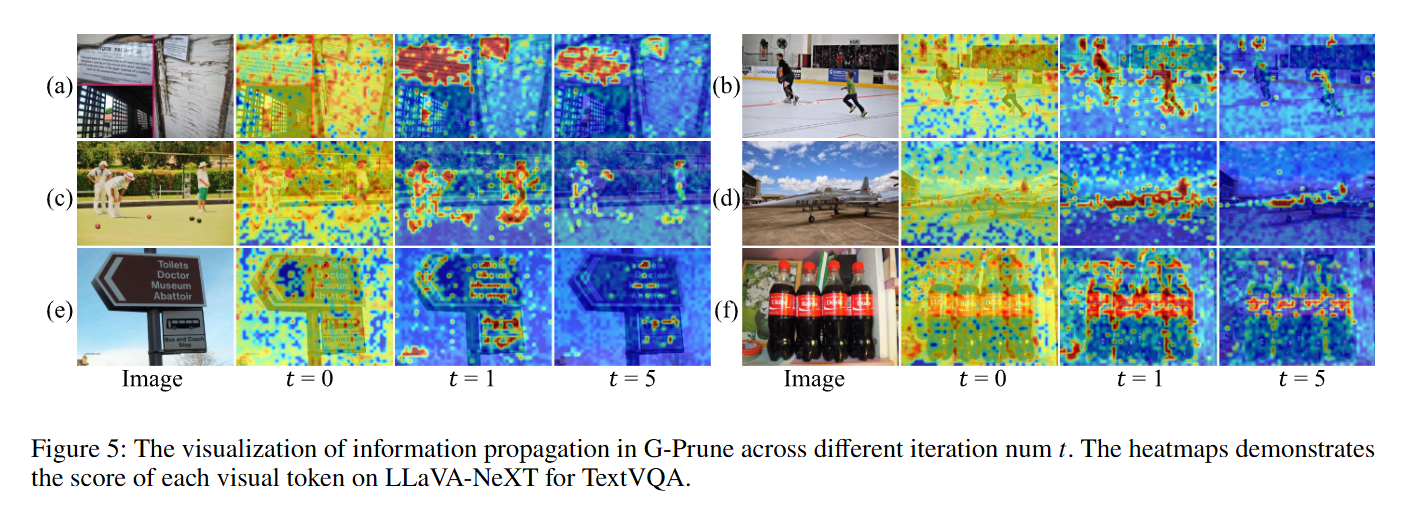
消融实验

Inspiration
group放到mamba做分组扫描