聊一聊Qwen3思考模式实现以及背后原理探讨
Qwen3思考模式切换实现
硬开关
我们先通过官方的示例代码来体验一下,如何实现在思考模式和非思考模式之间切换
通过tokenizer.apply_chat_template的enable_thinking参数来实现
默认情况下,Qwen3 启用了思考功能,类似于 QwQ-32B。这意味着模型将运用其推理能力来提升生成响应的质量。例如,当在tokenizer.apply_chat_template明确设置enable_thinking=True或保留其默认值时,模型将启动其思考模式。代码如下:
text = tokenizer.apply_chat_template(messages,tokenize=False,add_generation_prompt=True,enable_thinking=True # True is the default value for enable_thinking
)
在这种模式下,模型会生成包裹在…块中的思考内容,然后是最终的响应。
对于思考模式,官方提示请使用Temperature=0.6、TopP=0.95、TopK=20和MinP=0( 中的默认设置generation_config.json)。请勿使用贪婪解码,因为它会导致性能下降和无休止的重复。https://huggingface.co/Qwen/Qwen3-32B
Qwen3提供了一个硬开关,可以严格禁用模型的思考行为,使其功能与之前的 Qwen2.5-Instruct 模型保持一致。此模式在需要禁用思考以提高效率的场景中尤为有用。
text = tokenizer.apply_chat_template(messages,tokenize=False,add_generation_prompt=True,enable_thinking=False # Setting enable_thinking=False disables thinking mode
)
在此模式下,模型不会生成任何思考内容,也不会包含…块。
对于非思考模式,我们建议使用Temperature=0.7、TopP=0.8、TopK=20和MinP=0。
软开关
Qwen3示例给了一种高级用法: 通过用户输入在思考模式和非思考模式之间切换,具体来说就是通过用户输入层控制是否思考,提供了一种软切换机制,允许用户在enable_thinking=True时动态控制模型的行为。实现方式就是可以在用户提示或系统消息中添加/think和/no_think,以便在不同回合之间切换模型的思维模式。
在多回合对话中,模型将遵循最后一条的指令。
以下是多轮对话的示例:
from transformers import AutoModelForCausalLM, AutoTokenizerclass QwenChatbot:def __init__(self, model_name="Qwen/Qwen3-32B"):self.tokenizer = AutoTokenizer.from_pretrained(model_name)self.model = AutoModelForCausalLM.from_pretrained(model_name)self.history = []def generate_response(self, user_input):messages = self.history + [{"role": "user", "content": user_input}]text = self.tokenizer.apply_chat_template(messages,tokenize=False,add_generation_prompt=True)inputs = self.tokenizer(text, return_tensors="pt")response_ids = self.model.generate(**inputs, max_new_tokens=32768)[0][len(inputs.input_ids[0]):].tolist()response = self.tokenizer.decode(response_ids, skip_special_tokens=True)# Update historyself.history.append({"role": "user", "content": user_input})self.history.append({"role": "assistant", "content": response})return response# Example Usage
if __name__ == "__main__":chatbot = QwenChatbot()# First input (without /think or /no_think tags, thinking mode is enabled by default)user_input_1 = "How many r's in strawberries?"print(f"User: {user_input_1}")response_1 = chatbot.generate_response(user_input_1)print(f"Bot: {response_1}")print("----------------------")# Second input with /no_thinkuser_input_2 = "Then, how many r's in blueberries? /no_think"print(f"User: {user_input_2}")response_2 = chatbot.generate_response(user_input_2)print(f"Bot: {response_2}") print("----------------------")# Third input with /thinkuser_input_3 = "Really? /think"print(f"User: {user_input_3}")response_3 = chatbot.generate_response(user_input_3)print(f"Bot: {response_3}")
思考模式软硬开关如何兼容
我们会自然想到一种情况,就是用户即在tokenizer.apply_chat_template中设置了enable_thinking参数,又在用户输入的时候可能加入了/think和/no_think符号,这种情况软硬开关如何兼容呢?
为了实现 API 兼容性,当enable_thinking=True时,无论用户使用/think还是/no_think,模型都会始终输出一个包裹在<think>...</think>中的块。
但是,如果禁用思考功能,此块内的内容可能为空。当enable_thinking=False时,软开关无效。无论用户输入任何/think或/no_think符号,模型都不会生成思考内容,也不会包含…块。
我们可以看到enable_thinking的优先级是要大于/think或/no_think的优先级。
接下来我们通过Qwen3模型中的tokenizer_config.json来分析如何通过对话模板来如何实现快慢思考的?下面截图就是:
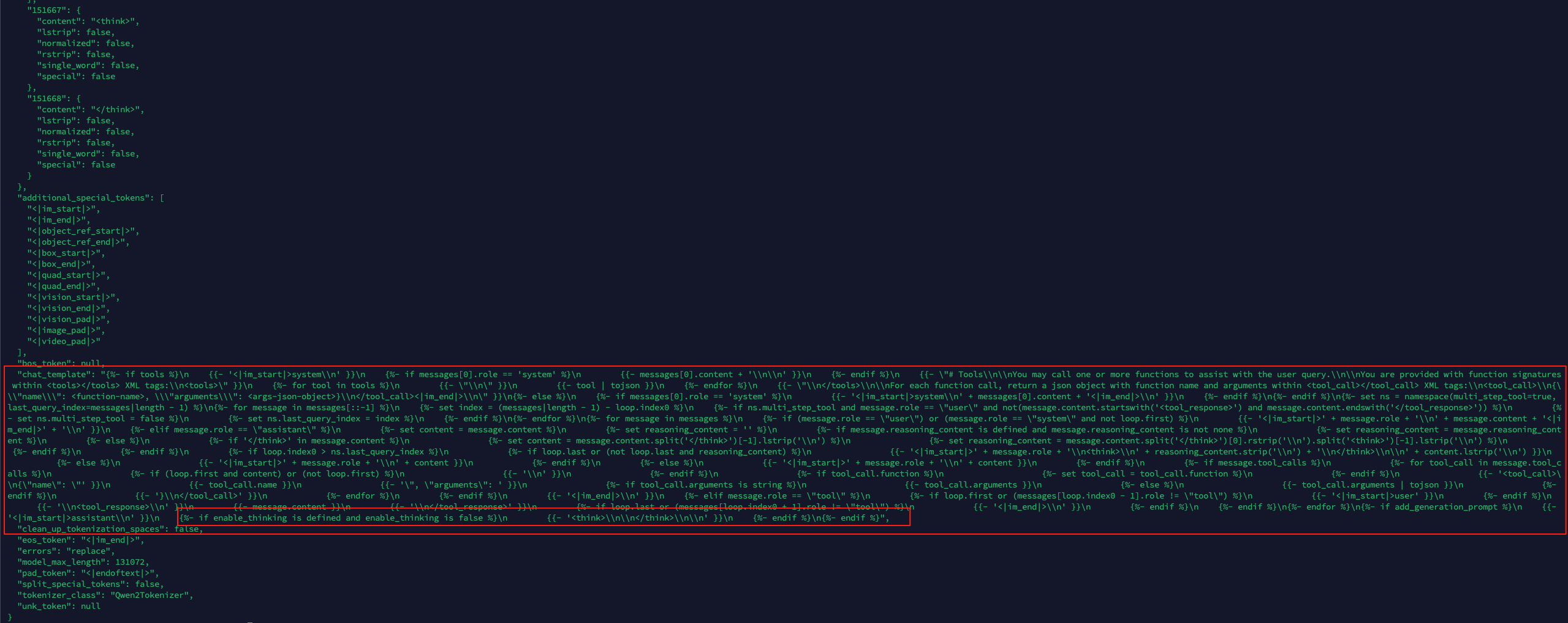
多说一句,Chat template 是大语言模型(LLM)中的一个关键组件,它定义了如何将对话转换为模型可以理解的格式化输入。我将详细解释其原理并提供具体示例。
Qwen3的 Chat Template 原理详解
Chat template 是大语言模型(LLM)中的一个关键组件,它定义了如何将对话转换为模型可以理解的格式化输入。我将详细解释其原理并提供具体示例。
基本原理
Chat template 本质上是一个文本模板,使用特定语法(通常是 Jinja2 模板语法)来处理和格式化对话数据。它的主要功能是:
- 角色区分:明确标识不同参与者(系统、用户、助手等)的消息
- 特殊标记插入:添加模型训练时使用的特殊标记
- 结构化表示:将多轮对话组织成模型预期的格式
- 功能支持:处理工具调用、思考过持等高级功能
关键组件解析
在 Qwen3-8B 的 chat_template 中:
<|im_start|>和<|im_end|>:标记消息的开始和结束role:标识消息发送者(system、user、assistant、tool)<think></think>:围绕助手的思考过程<tool_call></tool_call>:包含工具调用信息<tool_response></tool_response>:包含工具响应信息
实例说明
让我通过几个具体例子来说明 chat_template 如何工作:
例子1:简单对话
假设有以下对话:
系统:你是一个有用的助手
用户:你好
助手:你好!有什么我可以帮助你的?
使用 Qwen3-8B 的 chat_template 处理后,会变成:
<|im_start|>system
你是一个有用的助手
<|im_end|>
<|im_start|>user
你好
<|im_end|>
<|im_start|>assistant
你好!有什么我可以帮助你的?
<|im_end|>
例子2:包含思考过程的对话
系统:你是一个有用的助手
用户:42+28等于多少?
助手:(思考:我需要计算42+28,42+28=70)
70
处理后:
<|im_start|>system
你是一个有用的助手
<|im_end|>
<|im_start|>user
42+28等于多少?
<|im_end|>
<|im_start|>assistant
<think>
我需要计算42+28,42+28=70
</think>70
<|im_end|>
例子3:工具调用
系统:你是一个有用的助手
用户:查询北京今天的天气
助手:我将调用天气API
(调用天气工具)
工具响应:北京今天晴朗,温度22-28度
助手:根据查询,北京今天天气晴朗,温度在22-28度之间。
处理后:
<|im_start|>system
你是一个有用的助手
<|im_end|>
<|im_start|>user
查询北京今天的天气
<|im_end|>
<|im_start|>assistant
我将调用天气API
<tool_call>
{"name": "weather_api", "arguments": {"city": "北京", "date": "today"}}
</tool_call>
<|im_end|>
<|im_start|>user
<tool_response>
北京今天晴朗,温度22-28度
</tool_response>
<|im_end|>
<|im_start|>assistant
根据查询,北京今天天气晴朗,温度在22-28度之间。
<|im_end|>
Chat template 在实际处理中利用了 Jinja2 模板引擎的多种功能:
- 条件处理:
{%- if ... %}和{%- endif %}用于根据消息类型选择不同的格式化方式 - 循环遍历:
{%- for message in messages %}用于处理多轮对话 - 变量替换:
{{- message.content }}插入实际消息内容 - 命名空间:
{%- set ns = namespace(...) %}跟踪状态信息
Chat template 对模型使用至关重要:
- 训练一致性:确保推理时的格式与训练时一致
- 功能支持:使模型能识别并正确处理特殊功能(工具调用、思考过程)
- 性能优化:正确的格式化可以显著提高模型输出质量
下面一个代码可以看到enable_thinking为False/True时不同的分词结果
prompt = "42+28等于多少?"
messages = [{"role": "user", "content": prompt}
]text = tokenizer.apply_chat_template(messages,tokenize=False,add_generation_prompt=True,enable_thinking=True # Setting enable_thinking=False disables thinking mode
)
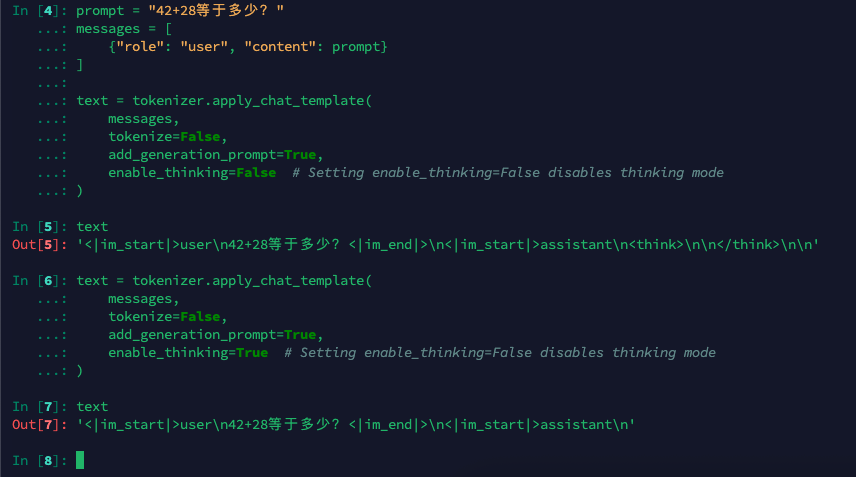
可以看到上面分词之后的唯一差别的地方就是,enable_thinking=False时添加了一个<think>\n\n</think>\n,添加了一个空白思考,用来告诉模型已经思考结束。
那么好奇问了,如果enable_thinking=True,然后我在对话的后面添加一个<think>\n\n</think>\n会怎么样呢,就是下面:
prompt = "42+28等于多少?"+“<think>\n\n</think>\n”
messages = [{"role": "user", "content": prompt}
]text = tokenizer.apply_chat_template(messages,tokenize=False,add_generation_prompt=True,enable_thinking=True # Setting enable_thinking=False disables thinking mode
)
这个时候其实还是会输出思考内容的,大家可以试试看看
思考:Qwen3模型如何实现快慢思考
通过软开关,我们可以看到Qwen3是可以通过从输入上来控制的快慢思考的,自然而然想到的是不是在训练的时候加了一些策略,直觉就是:
有一部分数据带有思维链一部分没有带有思维链
- no_think:问题+答案
- think:问题+【思考内容+答案】
在第三阶段,Qwen3在一份包括长思维链数据和常用的指令微调数据的组合数据上对模型进行微调,将非思考模式整合到思考模型中。确保了推理和快速响应能力的无缝结合。
这个地方可以做到软硬的实现,一个是硬开关优先级的控制,可以通过强化学习来实现,比如模板部分是否存在<think>\n\n</think>\n,另一个就是软开关,可能就是不同训练数据混在一起训练,让模型面临简单或者复杂问题自主决定思考的自由度。
有同学说,针对Qwen3有些模型师Moe,是不是可以:
把解码头改成多专家的形式,一个think一个不think,这样可行吗
这个是可以的,不过Qwen3 8B不是Moe
也有同学说deepseek之前文章也是这么搞的,r1通过注入思考空指令如何不进行思考,
或者存在一种情况
类似于在R1应用中sys_prompt写成:
think>用户说我是一个端水大师,要从aaa bbb cc方面考虑问题,现在我要先做…… </think>
以期实现减少、甚至截断模型原本reasoning的部分
一些控制思考深度的研究方法
笔者收集了一些资料,在深度学习与自然语言处理公众号看到一些关于大模型“过度思考”解读的一些文章
让模型学会「偷懒」
论文:Towards Thinking-Optimal Scaling of Test-Time Compute for LLM Reasoning
链接:https://arxiv.org/pdf/2502.18080
解决方案:让模型自己决定「想多久」论文提出Thinking-Optimal Scaling(TOPS)策略,核心思想是:学会「偷懒」。
三步走实现:
- 模仿学习:用少量样例教模型「不同难度用不同思考长度」;
- 动态生成:对同一问题生成短/中/长三种思考链;
- 自我改进:自动选择最短的正确答案作为训练数据。
LightThinker的“思考压缩”
论文:LightThinker: Thinking Step-by-Step Compression
链接:https://arxiv.org/pdf/2502.15589
项目:https://github.com/zjunlp/LightThinker
LightThinker的秘籍分为两大招:何时压缩和如何压缩
何时压缩?
LightThinker提供了两种策略:
- Token级压缩:每生成固定数量的token就压缩一次,简单粗暴但可能把一句话“腰斩”。
- 思考级压缩:等模型写完一个完整段落(比如一段分析或一次试错)再压缩,保留语义完整性,但需要模型学会“分段”。
如何压缩?
这里有个关键操作:
- 把隐藏状态压缩成“要点token”!数据重构:训练时在数据中插入特殊标记(比如触发压缩,[C]存储压缩内容),教模型学会“记重点”。
- 注意力掩码:设计专属注意力规则,让压缩后的token只能关注问题描述和之前的压缩内容,避免“翻旧账”。
在思考中提前预判答案
论文:Reasoning Models Know When They’re Right: Probing Hidden States for Self-Verification
链接:https://arxiv.org/pdf/2504.05419v1
通过训练一个简单的“探针”(类似体检仪器),研究者发现:
-
高准确率:探针预测中间答案正确性的准确率超过80%(ROC-AUC >0.9)。
-
提前预判:模型甚至在答案完全生成前,隐藏状态就已暴露正确性信号!
研究团队设计了一套流程:
-
切分推理链:将长推理过程按关键词(如“再检查”“另一种方法”)分割成多个片段。
-
标注正确性:用另一个LLM(Gemini 2.0)自动判断每个片段的答案是否正确。
-
训练探针:用两层神经网络分析模型隐藏状态,预测答案正确性。
总结

混合推理模型已经有不少了,例如 Claude 3.7 Sonnet 和 Gemini 2.5 Flash, Qwen3 应该是开源且效果好的典例。未来这可能也是一个趋势,不需要特意区分普通模型和思考模型,而是同一个模型按需使用。
Claude 3.7 sonnet 的混合推理模型
Claude 3.7 sonnet 的混合推理模型(Hybrid Reasoning Model)是 LLM 和 reasoning model 的结合的新范式,之后大概率所有 AI labs 的模型发布模型都会以类似形式,社区也不会再单独比较 base model 和 reasoning model 的能力。
使用 Claude 3.7 Sonnet 时,用户可以通过“extended thinking” 的设置选择是否需要输出长 CoT:
• 打开 extended thinking,则输出 CoT step-by-step 思考,类似开启了人类的 Slow thinking 并且其思考长度是可以选择的,因此 extended thinking 并不是 0 或 1,而是一个可以拖动的光谱,
• 关闭 extended thinking,则和 LLM 一样直接输出。
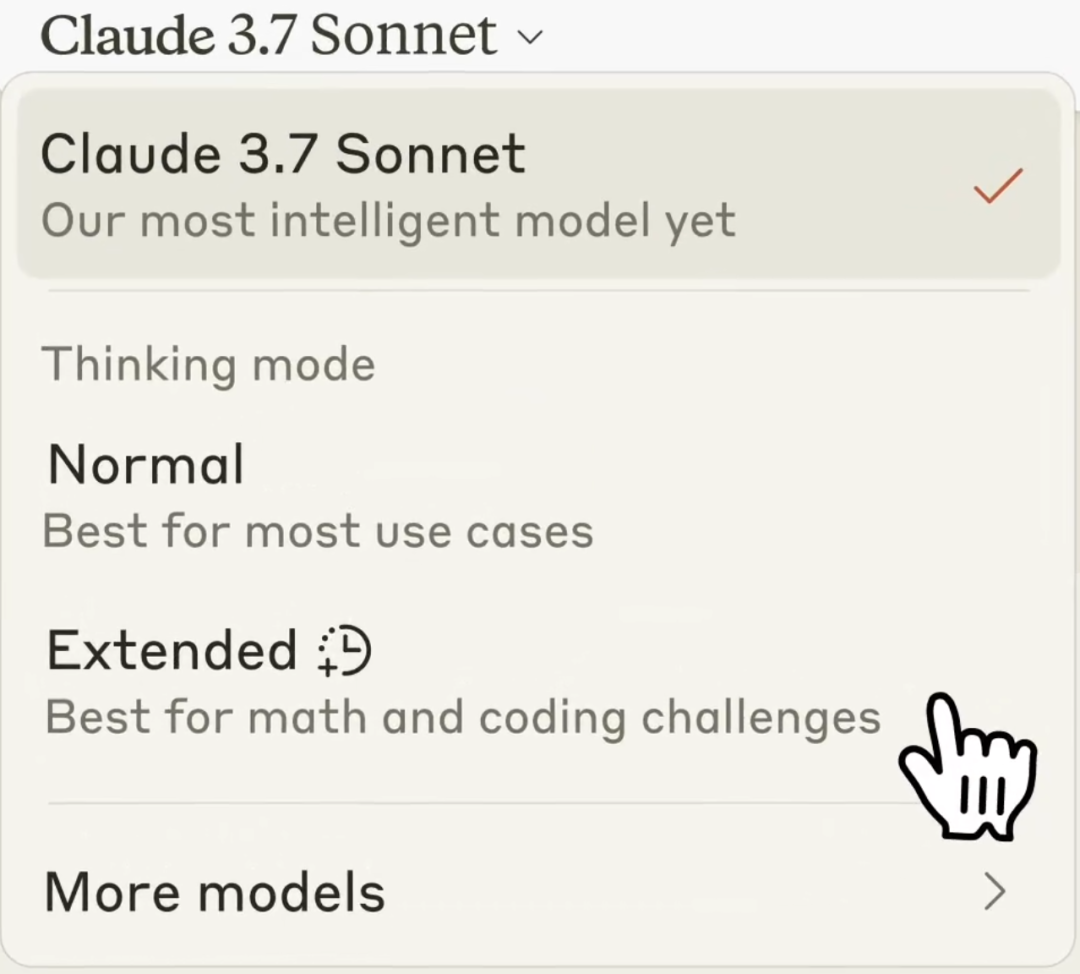
这个设计其实 Dario 很早就暗示过,在他看来:base model 与 reasoning model应该是个连续光谱。Claude System Card 中提到,extended thinking 的开关与长短是通过定义 system prompt 来实现的。我们推测要实现这样的融合模型,应该需要在 RL 训练之后通过 post training 让模型学会什么时候应该 step by step thinking,如何控制推理长度。
对于这个新范式,我们的预测是:
-
之后的 hybrid reasoning model 需要在 fast thinking 和 slow thinking 的选择上更加智能,模型自己具备 dynamic computing 能力,能规划并分配解决一个问题的算力消耗和 token 思考量。Claude 3.7 Sonnet 目前还是将 inference time 的打开和长短交由用户自己来决定,AI 还无法判断 query 复杂度、无法根据用户意图自行选择。
-
之后所有头部 research lab 发布模型都会以类似形式,不再只是发 base model。
其实现在打开 ChatGPT 上方的模型选择,会弹出五六个模型,其中有 4o 也有 o3,用户需要自行选择是用 LLM 还是 reasoning model,使用体验非常混乱。因此,hybrid reasoning model 从智能能力和用户体验看都是下一步的必然选择。

Gemini 2.5 Flash精细化的思维管理控制
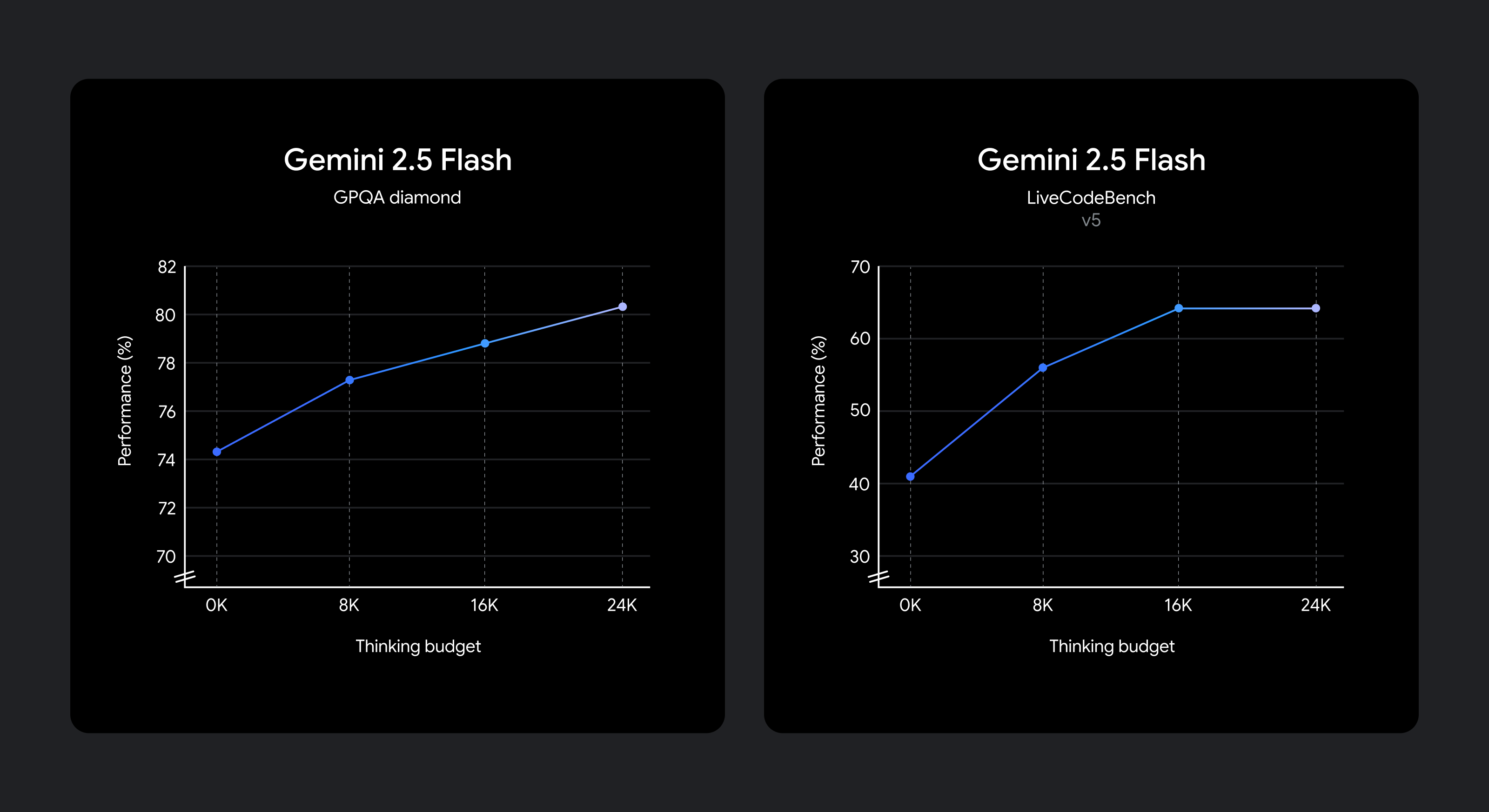
我们知道,不同案例会以不同的方式权衡质量、成本和延迟。为了让开发者具备灵活性,Gemini 2.5 Flash研发出了可供设置的思考预算功能,开发者可借此在模型进行思考的同时,对其可以生成的最大令牌数实现精细控制。预算更高意味着,模型可以更深入地进行推理,进而提高质量。值得注意的是,虽然预算使 2.5 Flash 的思考深度存在上限,但若提示无需深度思考,模型便不会耗尽全部预算。
低推理需求提示:
示例 1:“谢谢”用西班牙语怎么说?
示例 2:加拿大有多少个省份?
中等推理需求提示:
示例 1:投掷两个骰子,点数之和为 7 的概率是多少?
示例 2:我所在的健身房会于周一、周三和周五的上午 9 点至下午 3 点,以及周二、周六的下午 2 点至晚上 8 点开放篮球活动。我每周工作 5 天,工作时间为上午 9 点至下午 6 点,我想在平日打 5 个小时篮球,请为我制定可行的时间表。
高推理需求提示:
示例 1:长度 L=3m 的悬臂梁有一个矩形截面(宽度 b=0.1m,高度 h=0.2m),且由钢 (E=200 GPa) 制成。其整个长度承受 w=5 kN/m 的均匀分布载荷,自由端则承受 P=10 kN 的集中载荷。计算最大弯曲应力 (σ_max)。
示例 2:编写函数 evaluate_cells(cells: Dict[str, str]) -> Dict[str, float],用以计算电子表格单元格值。
每个单元格包含:
一个数字(例如“3”)
或一个使用 +、-、*、/ 和其他单元格的公式,如“=A1 + B1 * 2”。
要求:
解析单元格之间的依赖关系。
遵守运算符优先级(*/ 优于 ±)。
检测循环并指出 ValueError(“在<单元格>检测到循环”)。
无 eval()。仅使用内置库。
最后来说:
我们希望模型经过训练,可以判断给定提示所需的思考时长,继而根据感知到的任务复杂程度自主决定思考深度。
参考内容
- 从 R1 到 Sonnet 3.7,Reasoning Model 首轮竞赛中有哪些关键信号?https://blog.csdn.net/m0_37733448/article/details/146001136
- 想得久≠答得对!LLM应该自主决定Reasoning长度!https://mp.weixin.qq.com/s/XTiJrWkuRmyzW5KO3lwrow