【prometheus+Grafana篇】基于Prometheus+Grafana实现Linux操作系统的监控与可视化
💫《博主主页》:
🔎 CSDN主页
🔎 IF Club社区主页
🔥《擅长领域》:擅长阿里云AnalyticDB for MySQL(分布式数据仓库)、Oracle、MySQL、Linux、prometheus监控;并对SQLserver、NoSQL(MongoDB)有了解
💖如果觉得文章对你有所帮助,欢迎点赞收藏加关注💖

今天这篇文章继续给大家分享一下通过 Prometheus 来抓取 Linux 系统的监控数据,并利用 Grafana 可视化平台进行展示。同时,还将配置一些常见的 Linux 系统告警项 ,进行实时监控和及时预警,帮助大家第一时间发现Linux潜在问题。
特别说明💥:
📌 开源仪表盘引用
- 本文采用的Linux监控仪表盘直接使用了Grafana官网开源项目(Dashboard ID: 1860),非常感谢原作者的无私分享。关于Grafana的所有配置步骤均基于该开源仪表盘并验证通过,各位可一键导入快速搭建专业级的可视化监控。
⚡ 原创告警规则实现
关于告警部分为博主独立开发完成,针对Linux系统实现了如下告警:
✅ SWAP空间使用过高警报
✅ 目录使用过高警报
✅ 服务器内存使用过高警报
✅ CPU使用率过高告警
✅ CPU因I/O等待时间占比过高
✅ I/O 利用率过高警报
✅ 服务器下载带宽使用过高警报
✅ 服务器上传带宽使用过高警报
prometheus+Grafana全系列文章(实时更新 🔥 ):
【prometheus+Grafana篇】Prometheus与Grafana:深入了解监控架构与数据可视化分析平台_普罗米修斯加grafna-CSDN博客
【prometheus+Grafana篇】从零开始:Linux 7.6 上二进制安装 Prometheus、Grafana 和 Node Exporter-CSDN博客
【prometheus+Grafana篇】Prometheus告警规则参数全解析 + Alertmanager实现多平台告警(含电子邮件/企业微信群/飞书群/钉钉群接受方式)-CSDN博客
【prometheus+Grafana篇】基于Prometheus+Grafana实现Linux操作系统的监控与可视化-CSDN博客
目录
一、安装node-exporter(node-exporter:用于收集操作系统和硬件信息的metrics)
1)下载node-exporter安装包,选择download
2)选择Operating system(操作系统)为linux;选择Architecture(架构)为all
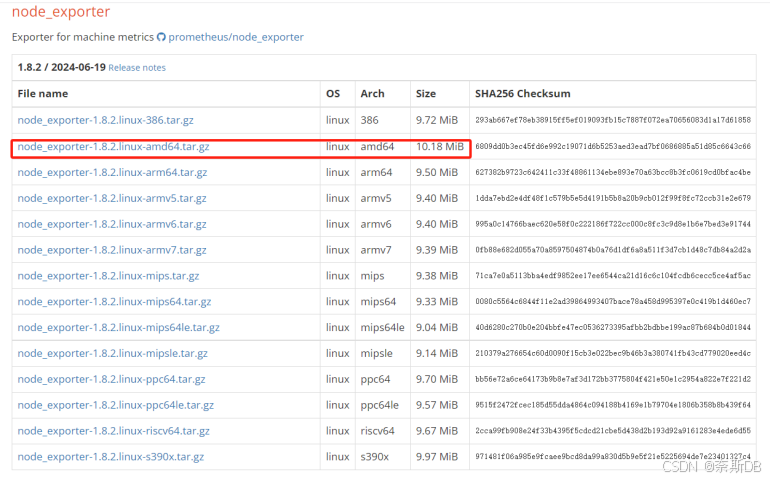
3)目前node-exporter最新版本为1.8.2。对于Arch(Architecture)架构,不同的架构名称代表不同的处理器架构或指令集体系结构,它们用于确定软件或操作系统在哪种硬件架构上运行。
4)解压二进制node-exporter包
5)移动并重命名node-exporter解压出来的目录
6)创建prometheus用户
7)赋权
8)写入linux启动服务项
9)登录node-exporter界面管理,默认端口为9100
二、将当前主机加入到prometheus监控,并通过Grafana展示
1)将node-exporter的信息加入到prometheus监控的配置文件prometheus.yml中
2)配置告警规则文件
3)检查配置文件
4)prometheus.yml文件添加了信息,所以重启prometheus进程或者重新加载配置文件(二选一)
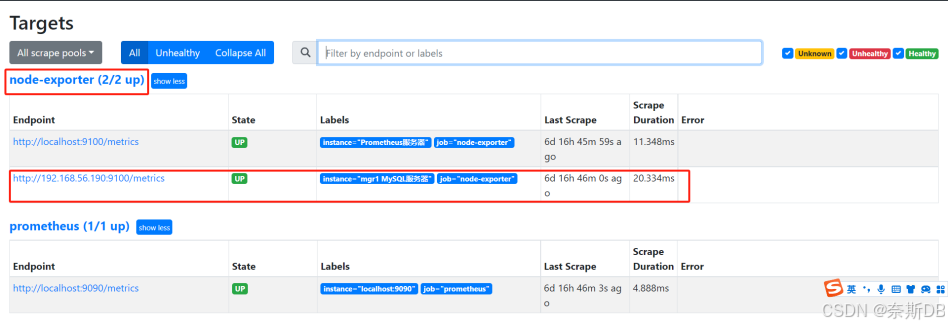
5)在prometheus查看是否可以看到监控信息
6)登录Grafana界面管理,将当前主机的监控信息做展示
一、下载一个仪表盘:Grafana官网“http://www.grafana.com”—Dashboards,然后选择一个下载量高的自己喜欢的node-exporter(主机监控)
二、将仪表盘添加到Grafana上:Dashboards—New—Import—点击“Upload dashboard JSON file”
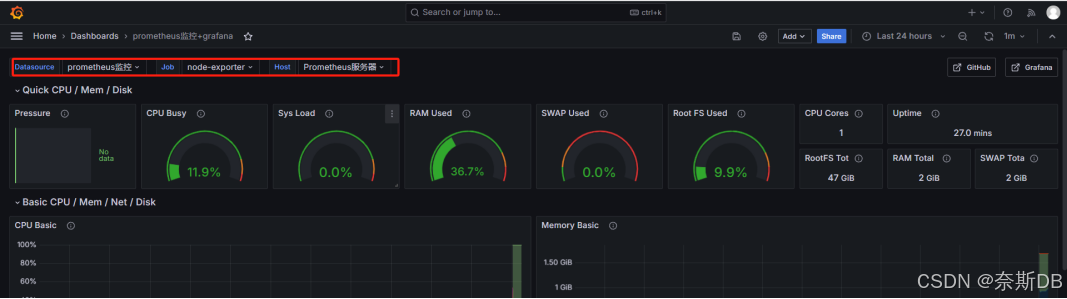
三、仪表盘展示:Dashboards—查看到已经定义好的仪表盘,并且数据源是prometheus监控,点击进去
监控linux信息如下:
| 主机名 | IP地址 | 配置 | 系统 | 描述 |
| linux01 | 110.120.100.190 | 4C 8G | Red Hat Linux 8.3 | 安装node-exporter对这台服务器进行监控 |
node-exporter:默认端口9100。用于收集操作系统和硬件信息的metrics
一、安装node-exporter(node-exporter:用于收集操作系统和硬件信息的metrics)
1)下载node-exporter安装包,选择download
2)选择Operating system(操作系统)为linux;选择Architecture(架构)为all
3)目前node-exporter最新版本为1.8.2。对于Arch(Architecture)架构,不同的架构名称代表不同的处理器架构或指令集体系结构,它们用于确定软件或操作系统在哪种硬件架构上运行。
386:这是 Intel 80386 处理器架构,也被称为 x86。它是早期的32位处理器架构。
amd64:也称为 x86-64 或 x64,这是一种64位的处理器架构,由 AMD 公司推出。它是基于 x86 架构的64位扩展,现在广泛用于桌面和服务器系统。
arm64:这是 ARMv8-A 的64位处理器架构,主要应用于 ARM 架构的64位处理器,包括用于服务器、移动设备和嵌入式系统的处理器。
armv5 和 armv6:这两者都属于 ARM 架构的32位处理器架构,分别对应于较旧的 ARM 处理器。它们通常用于嵌入式系统和一些较老的移动设备。
............
4)解压二进制node-exporter包
[root@linux01 ~]# tar -zxvf node_exporter-1.8.2.linux-amd64.tar.gz
5)移动并重命名node-exporter解压出来的目录
[root@linux01 ~]# mkdir -p /opt/prometheus [root@linux01 ~]# mv node_exporter-1.8.2.linux-amd64 /opt/prometheus/ [root@linux01 ~]# mv /opt/prometheus/node_exporter-1.8.2.linux-amd64 /opt/prometheus/node_exporter
6)创建prometheus用户
[root@linux01 ~]# groupadd prometheus [root@linux01 ~]# useradd -g prometheus -M -s /usr/sbin/nologin prometheus ---创建一个名为prometheus的系统账号,该账号没有家目录并且不能登录Shell。这种设置适用于需要运行服务或任务而不需要用户交互的情况。 -M:不为用户创建家目录。对于系统服务账号来说,通常不需要家目录,因此使用 -M 可以跳过家目录的创建步骤。 -s /usr/sbin/nologin:指定用户登录时使用的Shell。将用户prometheus的登录Shell设置为/usr/sbin/nologin。nologin Shell的作用是阻止用户登录系统,但允许该用户拥有有效的系统账号。这通常用于服务账号,因为它们不需要交互式Shell访问,仅用于执行特定服务或任务。[root@linux01 ~]# passwd prometheus[root@linux01 ~]# id prometheus
7)赋权
[root@linux01 ~]# chown -R prometheus:prometheus /opt/prometheus/node_exporter
8)写入linux启动服务项
Linux7之后通过systemctl方式:
[root@linux01 ~]# cd /usr/lib/systemd/system [root@linux01 ~]# vi node_exporter.service [Unit] Description=node_exporter After=network.target[Service] Type=simple User=prometheus Group=prometheus Restart=on-failure ExecStart=/opt/prometheus/node_exporter/node_exporter --web.listen-address=0.0.0.0:9100[Install] WantedBy=multi-user.target[root@linux01 ~]# systemctl daemon-reload [root@linux01 ~]# systemctl start node_exporter.service [root@linux01 ~]# systemctl enable node_exporter.service [root@linux01 ~]# systemctl status node_exporter.service###--web.listen-address=<address>:<port>:指定服务端口。默认通过9100端口访问node_exporter管理界面,可以修改成其他端口用于访问node_exporter管理界面(如果没有修改端口的需求可以不设置这个参数)。此参数只能在node_exporter命令启动时指定,不可以在配置文件prometheus.yml中指定。
Linux7之前通过service方式:
[root@linux01 ~]# cd /etc/init.d/ [root@linux01 ~]# vi node_exporter #!/bin/bash # chkconfig: - 99 01 # description: node_exporter serviceDAEMON="/opt/prometheus/node_exporter/node_exporter" DAEMON_OPTS="--web.listen-address=0.0.0.0:9100" case "$1" instart)echo "Starting node_exporter"$DAEMON $DAEMON_OPTS &;;stop)echo "Stopping node_exporter" pkill -f "$DAEMON --web.listen-address=0.0.0.0:9100";;restart)$0 stop$0 start ;;status)PID=$(pgrep -f "$DAEMON --web.listen-address=0.0.0.0:9100") if [ -n "$PID" ]; thenecho "node_exporter is running with PID: $PID"elseecho "node_exporter is not running"fi ;;*)echo "Usage: $0 {start|stop|restart|status}"exit 1;; esacexit 0[root@linux01 ~]# chmod 755 /etc/init.d/node_exporter [root@linux01 ~]# chkconfig --add node_exporter [root@linux01 ~]# service node_exporter start [root@linux01 ~]# chkconfig node_exporter on [root@linux01 ~]# service node_exporter status
9)登录node-exporter界面管理,默认端口为9100
http://110.120.100.190:9100/metrics

二、将当前主机加入到prometheus监控,并通过Grafana展示
注意:如下操作是在安装了prometheus和Grafana的主机上进行操作,安装直通车👉【prometheus+Grafana篇】从零开始:Linux 7.6 上二进制安装 Prometheus、Grafana 和 Node Exporter-CSDN博客👈
1)将node-exporter的信息加入到prometheus监控的配置文件prometheus.yml中
[root@prometheus ~]# vi /opt/prometheus/prometheus.yml 在scrape_configs下面新增如下内容:# node-exporter配置- job_name: "linux服务器监控" ###job_name 用来唯一标识一个监控任务。在同一个 prometheus.yml 文件中,不同的 scrape_config可以有不同的job_name,以便 Prometheus 能够区分和管理不同的监控目标和配置,用来将不同的监控目标分组。单位为监控linux设置一个独立的job_namescrape_interval: 15s ###指定这个job_name每隔多久从每个目标(如 Exporter、应用端点)拉取一次指标数据。优先级:会覆盖全局的 global:scrape_interval(如果存在)。file_sd_configs: - files:- /data/prometheus/conf.d/node_targets.json # linux服务器需要监控的机器都单独写在了node_targets.json文件中,是为了避免prometheus.yml内容过多,看起来更简洁[root@prometheus ~]# vi /data/prometheus/conf.d/node_targets.json [{"targets": [ "110.120.100.190:9100" ],"labels": { "instance": "linux服务器(IP:110.120.100.190)" }} ]
2)配置告警规则文件
除了如下告警规则之外,还需要单独配置一个Targets目标不可达(up)的相关规则,因为up 是一个布尔值指标,表示 Prometheus 是否能够成功地 scrape(抓取)到指定的目标(targets)数据,用于判断目标node-exporter相关进程是否在目标主机存活。关于up的规则文件参考:【prometheus+Grafana篇】从零开始:Linux 7.6 上二进制安装 Prometheus、Grafana 和 Node Exporter-CSDN博客
[root@prometheus ~]# cd /opt/prometheus/rules/ ###在prometheus.yml文件中定义了告警规则文件rule_files参数 [root@prometheus rules]# vi node_alerts.ymlgroups:- name: node_alertsrules:- alert: HighSwapUsageexpr: ((node_memory_SwapTotal_bytes - node_memory_SwapFree_bytes) / node_memory_SwapTotal_bytes) * 100 > 90for: 3slabels:severity: criticalannotations:summary: "SWAP空间使用过高警报"description: "当前实例 {{ $labels.instance }} 的SWAP空间使用率已达到 {{ $value | printf \"%.2f\" }}%,超过90%。请检查系统SWAP使用情况!"- alert: HighDiskUsageexpr: 100 - ((node_filesystem_avail_bytes * 100) / node_filesystem_size_bytes) > 90and on(device) node_filesystem_size_bytes{device!="/dev/loop0",device!="/dev/loop1"}for: 3slabels:severity: criticalannotations:summary: "目录使用过高警报"description: "当前实例 {{ $labels.instance }} 的 {{ $labels.mountpoint }} 目录使用率已达到 {{ $value | printf \"%.2f\" }}%,超过90%。请检查磁盘目录使用情况!"- alert: HighMemoryUsageexpr: ((node_memory_MemTotal_bytes - node_memory_MemFree_bytes - (node_memory_Cached_bytes + node_memory_Buffers_bytes + node_memory_SReclaimable_bytes)) / node_memory_MemTotal_bytes) * 100 > 90for: 3slabels:severity: criticalannotations:summary: "服务器内存使用过高警报"description: "当前实例 {{ $labels.instance }} 的服务器内存使用率已达到 {{ $value | printf \"%.2f\" }}%,超过90%。请检查服务器内存使用情况!"- alert: HighCpuUsage # CPU使用率过高告警expr: 100 - (avg by (instance) (irate(node_cpu_seconds_total{mode="idle"}[3m])) * 100) > 90for: 3mlabels:severity: criticalannotations:summary: "CPU使用率过高告警"description: "实例 {{ $labels.instance }} 的CPU使用率(基于3分钟内最后两个数据点计算的瞬时增长率)已持续3分钟超过90%,当前值为 {{ $value | printf \"%.2f\" }}%。请检查服务器CPU使用情况!"- alert: HighIOWait # CPU因I/O等待时间占比过高expr: 100 * (avg by (instance) (irate(node_cpu_seconds_total{mode="iowait"}[3m]))) > 20for: 3mlabels:severity: criticalannotations:summary: "CPU因I/O等待时间占比过高"description: "实例 {{ $labels.instance }} 的I/O等待时间占比(基于3分钟内最后两个数据点计算的瞬时增长率)已持续3分钟高于20%,当前值为 {{ $value | printf \"%.2f\" }}%。请排查CPU因I/O等待时间占比过高的原因!"- alert: HighIOUtilizationexpr: irate(node_disk_io_time_seconds_total[5m]) * 100 > 99for: 5mlabels:severity: criticalannotations:summary: "I/O 利用率过高警报"description: "当前实例 {{ $labels.instance }} 的 {{ $labels.device }} 盘的 I/O 利用率(基于5分钟内最后两个数据点计算的瞬时增长率)已持续5分钟高于99%,当前 I/O 利用率为 {{ $value | printf \"%.2f\" }}%。请检查磁盘 I/O 性能!"- alert: HighNetworkreceiveUsageexpr: rate(node_network_receive_bytes_total[10m]) * 8 / 1000000 > 500 # 500 Mbpsfor: 10mlabels:severity: criticalannotations:summary: "服务器下载带宽使用过高警报"description: "当前实例 {{ $labels.instance }} 的 {{ $labels.device }} 网卡(基于10分钟内所有数据点计算的平均增长率)每秒平均下载带宽已持续10分钟超过500 Mbps(62.5 MB/s),当前每秒平均下载带宽为 {{ $value | printf \"%.2f\" }} Mbps。请检查网络流量和带宽使用情况!"- alert: HighNetworktransmitUsageexpr: rate(node_network_transmit_bytes_total[10m]) * 8 / 1000000 > 500 # 500 Mbpsfor: 10mlabels:severity: criticalannotations:summary: "服务器上传带宽使用过高警报"description: "当前实例 {{ $labels.instance }} 的 {{ $labels.device }} 网卡(基于10分钟内所有数据点计算的平均增长率)每秒平均上传带宽已持续10分钟超过500 Mbps(62.5 MB/s),当前每秒平均上传带宽 {{ $value | printf \"%.2f\" }} Mbps。请检查网络流量和带宽使用情况!"
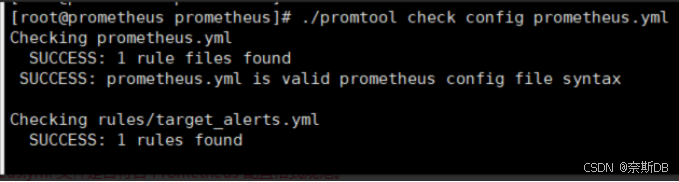
3)检查配置文件
[root@prometheus ~]# cd /opt/prometheus/ [root@prometheus ~]# ./promtool check config prometheus.yml ###用于检查 Prometheus 配置文件(prometheus.yml)的语法和格式是否正确。执行这条命令会执行以下操作:
- 验证配置文件的语法:检查 prometheus.yml 文件是否符合 Prometheus 配置格式规范。
- 检测潜在的错误或警告:如果配置文件中存在拼写错误、格式问题、无效的配置项等问题,它会提供相关的错误信息或警告。比如告警规则写的不对,就会有提示
- 输出有用的诊断信息:如果配置文件存在问题,promtool 会输出详细的错误信息。
4)prometheus.yml文件添加了信息,所以重启prometheus进程或者重新加载配置文件(二选一)
#重载:前提是在prometheus.service启动服务项中加了--web.enable-lifecycle参数:--web.enable-lifecycle:###启用Prometheus的生命周期接口,允许通过HTTP请求来动态重新加载配置等操作。这对于在运行时更新配置或执行其他管理操作非常有用,当修改了prometheus的配置后,可以通过curl命令来重新加载配置文件,而不需要重启prometheus(推荐方式)
[root@prometheus ~]# curl -X POST http://localhost:9090/-/reload
#重启
[root@prometheus ~]# systemctl restart prometheus.service
5)在prometheus查看是否可以看到监控信息
网址:http://110.120.100.190:9100
菜单栏:Status—Targets
6)登录Grafana界面管理,将当前主机的监控信息做展示
地址:http://192.168.56.10:3000
默认用户:admin
默认密码:admin
一、下载一个仪表盘:Grafana官网“http://www.grafana.com”—Dashboards,然后选择一个下载量高的自己喜欢的node-exporter(主机监控)
注意:不需要再增加数据源了。因为在第一次搭建prometheus+Grafana的时候就已经加好了,在添加数据源时,有个配置项是Connection,这里添加的是prometheus的地址,指的是prometheus监控服务器的地址,而不是node-exporter的地址
以1860为例,新增了多个指标,比较全面
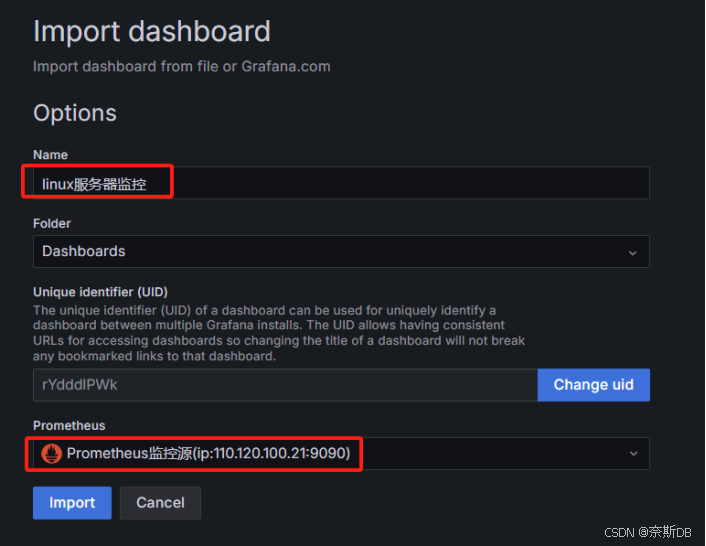
二、将仪表盘添加到Grafana上:Dashboards—New—Import—点击“Upload dashboard JSON file”
Name:定义名称,最好定义为主机ip加用途
Prometheus:选择prometheus源,Prometheus监控源(ip:110.120.100.21:9090)
....
然后import
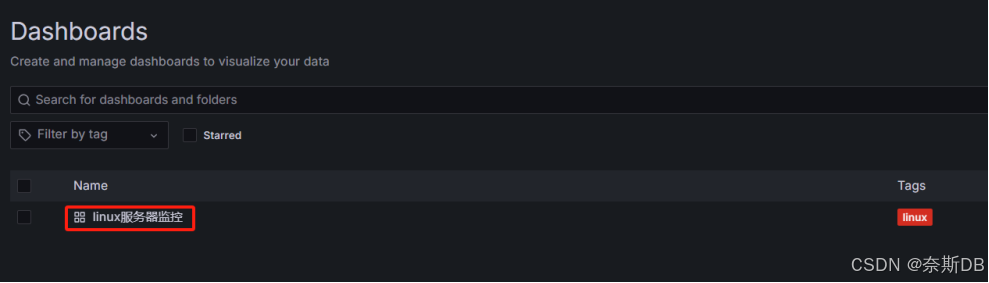
三、仪表盘展示:Dashboards—查看到已经定义好的仪表盘,并且数据源是prometheus监控,点击进去
仪表盘Name:linux服务器监控
数据源Name:prometheus监控,Prometheus监控源(ip:110.120.100.21:9090)
Datasource:选择在添加数据源时,已经定义好的“Prometheus监控源(ip:110.120.100.21:9090)”
Job:这里其实就是当时已经在配置prometheus.yml时,定义的job_name,也就是说Grafana会自动识别到
Host:这里其实就是当时已经在配置prometheus.yml时,定义的instance,也就是说Grafana会自动识别到
关于基于Prometheus+Grafana的Linux系统监控与可视化的内容到这里就结束了,接近上万字了,如果这篇文章对各位有所帮助,不求打赏,看在辛苦整理的份上希望点赞收藏加关注💖