imapal sql优化之hint
Query Hints in Impala SELECT Statements | 5.11.x | Cloudera Documentation
/* SHUFFLE*/和 /* BROADCAST*/主要是用来join语句
表1 odsrmicdata.zhimou_audit_info 614M

表2 odsrmicdata.zhimou_info_compress_check 165M
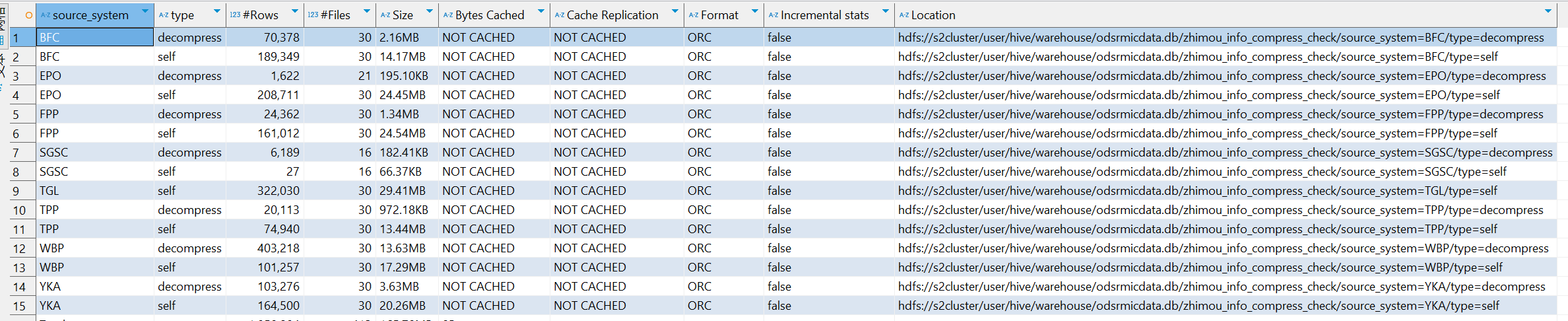
此时两个表join,将小表广播
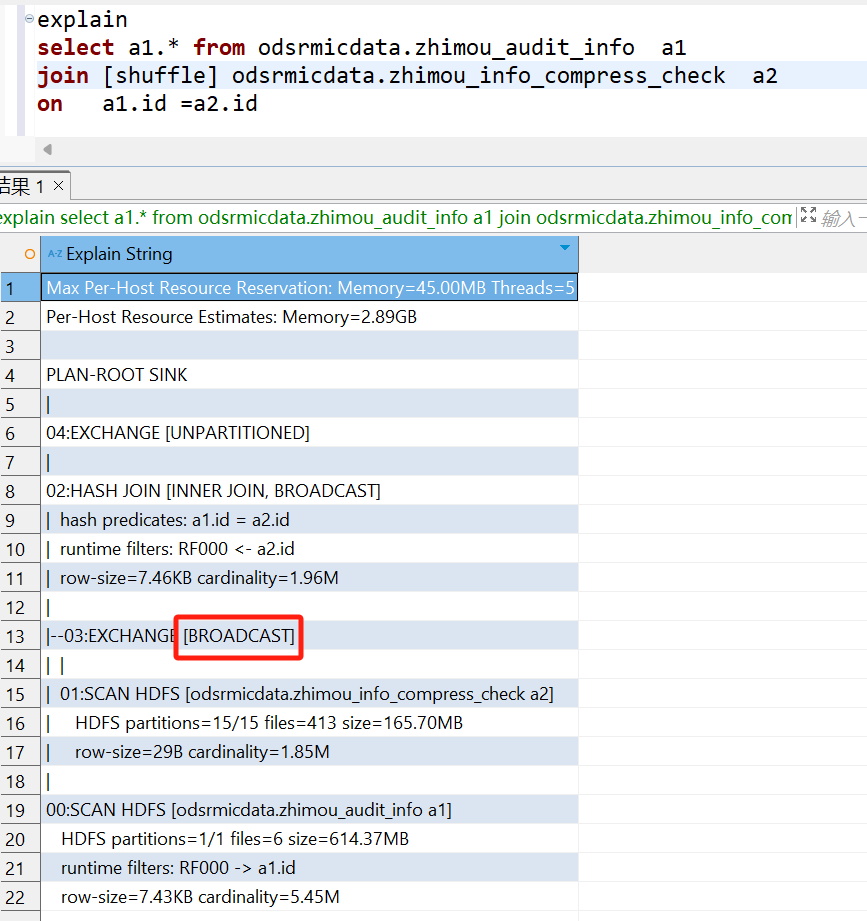
explain
select a1.* from odsrmicdata.zhimou_audit_info a1
join odsrmicdata.zhimou_info_compress_check a2
on a1.id =a2.id
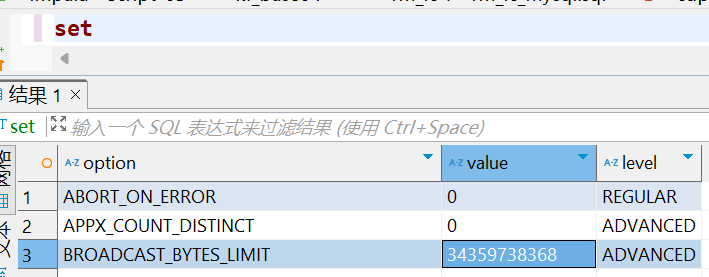
34359738368/1024/1024/1024=32G 额我也不知道为啥这么大。忽略。
如果我此时不想广播呢?因为广播占用内存较多,对实时性要求不高。
BROADCAST_BYTES_LIMIT 34359738368
1.设置广播阈值 set BROADCAST_BYTES_LIMIT=34359738=30M 缩小100倍
这样可以,但是问题在于这个sql我想节约内存,下个sql我想查的快,需要反复的调节大小,比较麻烦
2.使用hint,就是提示impala 我这个sql希望用什么方式join。
explain
select a1.* from odsrmicdata.zhimou_audit_info a1
join [shuffle] odsrmicdata.zhimou_info_compress_check a2
on a1.id =a2.id
explain
select a1.* from odsrmicdata.zhimou_audit_info a1
join /* +SHUFFLE */ odsrmicdata.zhimou_info_compress_check a2
on a1.id =a2.id
explain
select a1.* from odsrmicdata.zhimou_audit_info a1
join -- +shuffle
odsrmicdata.zhimou_info_compress_check a2
on a1.id =a2.id
三种都可以
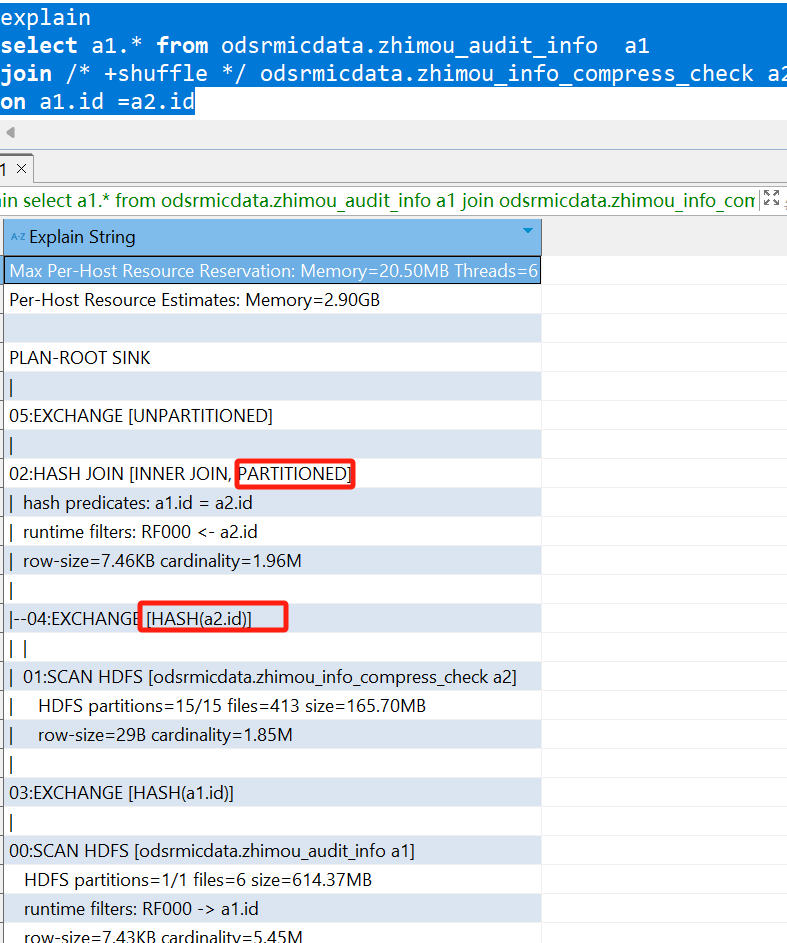
这种就比较方便了,我们继续看下hint还有哪些用法?
SELECT STRAIGHT_JOIN select_list FROM
join_left_hand_table
JOIN [{ /* +BROADCAST */ | /* +SHUFFLE */ }]
join_right_hand_table
remainder_of_query;
join的时候可以指定 广播BROADCAST 和SHUFFLE 上面已经说了。
INSERT insert_clauses
[{ /* +SHUFFLE */ | /* +NOSHUFFLE */ }]
[/* +CLUSTERED */]
SELECT remainder_of_query;
insert的时候可以指定SHUFFLE /NOSHUFFLE/CLUSTERED
SELECT select_list FROM
table_ref
/* +{SCHEDULE_CACHE_LOCAL | SCHEDULE_DISK_LOCAL | SCHEDULE_REMOTE}
[,RANDOM_REPLICA] */
remainder_of_query;
select的时候可以指定SCHEDULE_CACHE_LOCAL/SCHEDULE_DISK_LOCAL/SCHEDULE_REMOTE/RANDOM_REPLICA
注意
1.STRAIGHT_JOIN / DISTINCT / ALL关键词会导致 hint失效
2.为了减少使用hints 尽量多使用compute stats
Hints for join queries:

使用shuffle 是一般用于大表和大表之间的关联
使用broadcast用于大表和小表之间的关联,一般是impala的默认方式
/* SHUFFLE*/和 /* NOSHUFFLE*/ 主要是用来insert语句
Hints for INSERT ... SELECT queries:

对于insert...select这种类型querysql,我们可以通过hint去微调impala的整体操作和资源使用(这里一般指的是impala的parquet分区表?)
/* +SHUFFLE */
会在写数据前增加一个协调的节点,这个节点专门用来写数据到目标表。
比如insert into a select * from b b是分区表 a也是分区表,加了这个就是把b的一个分区的数据拉到协调节点输出到a 然后再拉一个分区。
如果表是非分区表或者所有分区都是常量,这个hint会在协调节点将所有数据写出
1.涉及多个节点的数据传输
2.减少资源的使用量,最终形成的文件数量减少
/* +NOSHUFFLE */
在插入到分区表之前不添加 Exchange 节点,并禁用重新分区。因此,所选执行计划可能是总体上更快,但也可能会生成大量小数据文件或超出容量限制,从而导致作失败
impala自动使用/* +SHUFFLE */作为默认项,如果select语句中包含了原表的所有列,并且没有compute column stats
直接来实战吧
insert overwrite table cc_test.multi_join_impala
select *
from cc_test.multi_join;
insert overwrite table cc_test.multi_join_impala /* +NOSHUFFLE */
select *
from cc_test.multi_join;
insert overwrite table cc_test.multi_join_impala /* +SHUFFLE */
select *
from cc_test.multi_join;
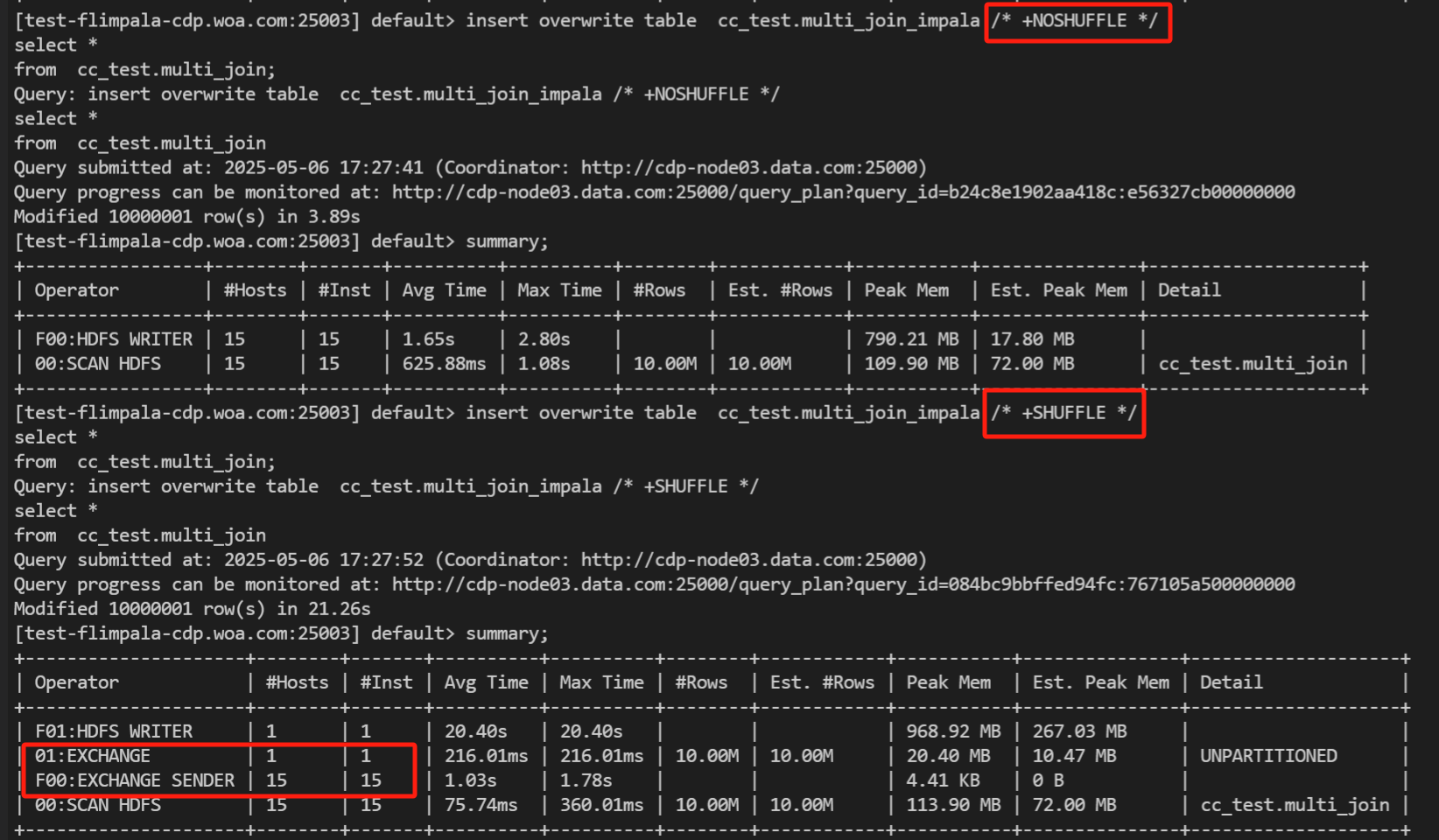
很明显看到shuffle插入的时候多了一个步骤exchange就是把不同节点数据转移到一个节点专门输出。通过查看内存使用情况,可以看到shuffle使用的内存确实比 noshuffle少,当然速度也会变慢(这里的节点数太少不明显,可以自己将文件数变多)

/* CLUSTERED */和 /* NOCLUSTERED */

这两个感觉不出来具体的用处。
还有一些其他的hint有兴趣的自己学习
Query Hints in Impala SELECT Statements | 5.11.x | Cloudera Documentation
SQL Statements - Optimizer Hints - 《Apache Impala v3.x Documentation》 - 书栈网 · BookStack