论文速读:《CoM:从多模态人类视频中学习机器人操作,助力视觉语言模型推理与执行》
论文链接:https://arxiv.org/pdf/2504.13351
项目链接:https://chain-of-modality.github.io/
0. 简介
现代机器人教学的一个重要方向是让机器人通过观看人类的视频演示,自动学习并执行复杂的物理操作任务,比如拧瓶盖、插插头、打鼓等。然而,单纯依靠视觉信息,机器人很难捕捉到诸如施力大小、动作力度等细节参数,导致执行效果不佳。最新工作《Chain-of-Modality: Learning Robot Manipulation from Multimodal Human Videos via Visual Language Models》提出了一种创新性的“模态链”(Chain-of-Modality,简称CoM)方法,结合视觉、肌肉电信号和声音等多模态人类演示数据,利用视觉语言模型(VLM)逐步推理,显著提升机器人对任务计划和控制参数的理解与执行能力。
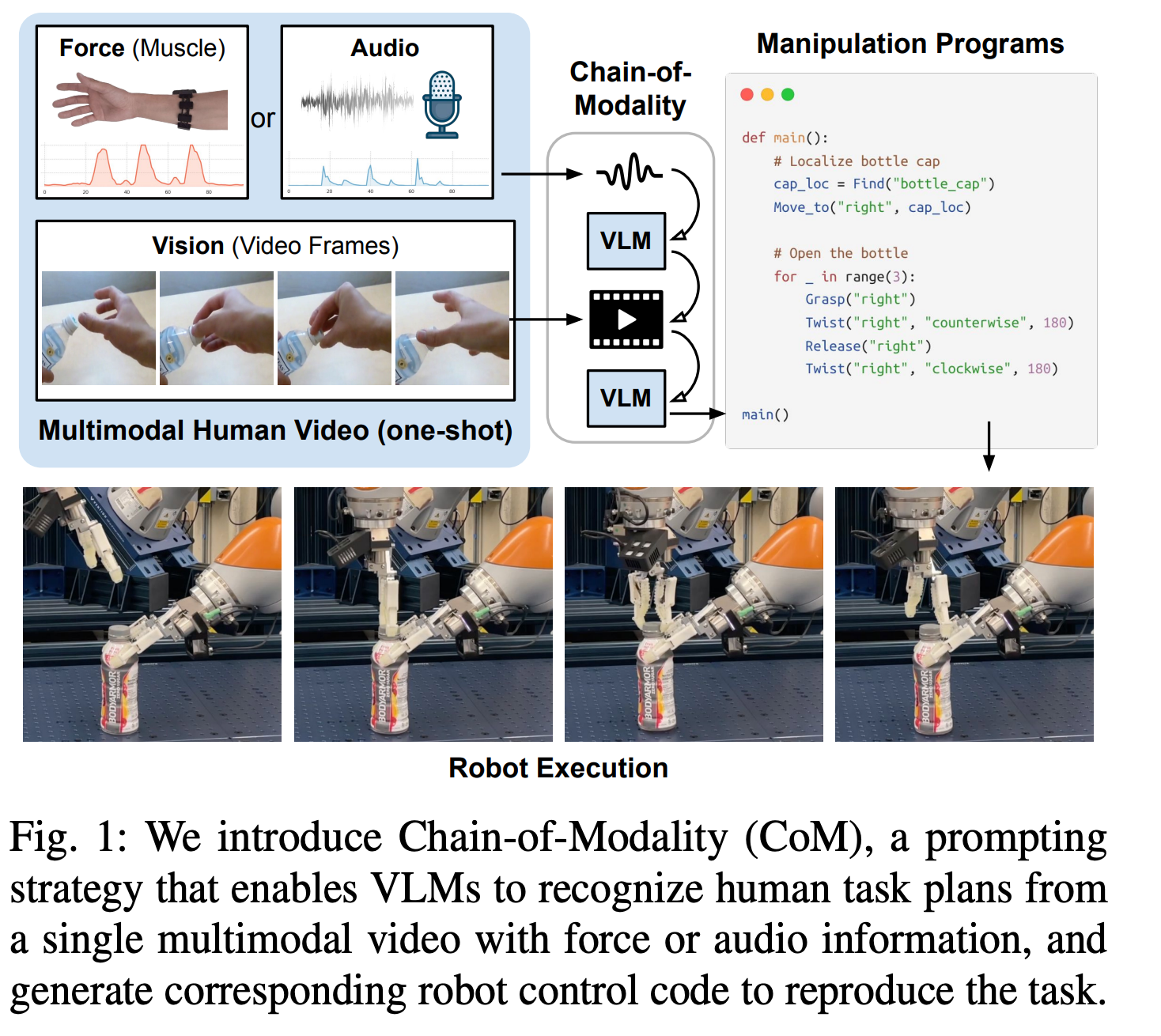
图1:我们提出了链式模态(Chain-of-Modality, CoM)这一提示策略,使得视觉语言模型(VLM)能够从包含力或音频信息的单一多模态视频中识别出人类的任务计划,并生成相应的机器人控制代码以再现该任务。
传统机器人学习多依赖于视觉视频,但很多操作任务需要细粒度的控制参数,尤其是力度和速度,这些信息仅靠视频难以准确推断。本文提出:
- 利用带有肌电(EMG)传感器的臂带捕捉人体肌肉活动,以及带麦克风的运动相机捕捉操作时的声音,补充视觉信息;
- 引入“模态链”提示策略,使VLM能依次分析不同模态数据,逐步整合信息,推理出详细的任务计划和多样化的控制参数;
- 生成机器人可执行的代码,支持跨机器人平台执行,并能泛化到未见物体和新任务。
实验结果显示,CoM相比传统纯视觉方法,任务计划和控制参数提取准确率提升3倍,机器人执行成功率达73%,在新物体和新环境下表现依然稳健。
1. 主要贡献
- 模态链(CoM)提示策略:创新地设计了一个分阶段、多模态顺序推理流程,避免了简单多模态融合时的信息丢失和模态间关联困难,显著提升VLM对复杂多模态输入的理解力。
- 一次性多模态演示视频到机器人代码生成:实现了从单个融合视觉、力和声音信息的人类演示视频,自动生成细粒度操作任务的机器人控制程序。
- 强泛化能力:所生成的代码抽象了具体机器人实现,支持不同机器人平台(如ViperX、KUKA双臂机器人)执行,并能适应未见的物体和随机环境布置。
2. 相关工作
2.1 从视频中理解人类活动
理解视频中的人类活动是计算机视觉领域长期关注的主题。早期研究多聚焦于通过动作分类捕捉视频的高级语义信息,但这类方法往往依赖特定训练数据,难以泛化到未见动作类别。后来,研究者开始尝试从视频中推断更细粒度的任务计划,试图理解动作背后的意图与步骤,但仍存在泛化能力不足的问题。
近年来,随着大型视觉语言模型(Vision-Language Models, VLMs)的兴起,基于提示的推理技术使得模型在理解视频中的人类活动方面取得了显著进展。相比传统方法,VLM能够结合视觉和语言信息,更灵活地解析复杂动作序列。然而,现有工作大多只利用单一视觉模态,忽视了力和声音等关键信息的融合,限制了对细粒度操作细节的捕获。本文则创新性地引入多模态视频数据,结合肌肉信号和物体交互声音,使模型能够理解操作过程中的隐含力学信息,为机器人操作任务提供关键支持。
2.2 机器人与控制的基础模型
近年来,基础模型在机器人领域实现了从高层任务推理到低层运动控制的跨越。早期工作通常依赖自然语言描述来指导机器人规划和决策,任务通过语言指令定义,适用于许多场景。但对于空间模糊性强或需要精细控制的操作任务,单纯语言描述难以准确表达细节。
视觉语言模型的发展引入了更丰富的任务规范,例如视觉注释和图像指令,增强了任务表达能力。本文的方法进一步突破,采用单次多模态人类演示视频作为任务规范,使机器人能够直接从示范中提取任务计划及控制参数。
在机器人控制的实现上,已有多种基于基础模型的方案,例如基于目标条件的子目标选择、轨迹优化的奖励或约束生成,以及利用感知和控制原语生成代码。与这些多依赖语言输入的方案不同,本文展示了视觉语言模型如何直接从单次多模态视频输入推理,生成低级操作程序,为机器人执行新任务提供了富含视觉提示的替代路径。
2.3 从人类视频中学习操作
大量研究探索通过人类视频教机器人操作技能,聚焦于从视频中提取物体功能、运动轨迹、任务动态和奖励表示等信息。其中部分工作训练基于视频条件的操作策略,避免依赖语言指令,提升了策略的灵活性和泛化性。
然而,这些方法普遍只利用图像序列,难以推断许多操作任务所需的重要细节——尤其是力的大小和施加时机等隐性信息。力的准确感知对于如插入插头、拧瓶盖等接触丰富的任务至关重要。
本文则通过引入多种传感模态,包括图像、肌肉电信号(EMG)和交互声音,捕捉操作过程中的细微力学变化,弥补了纯视觉方法的不足,使机器人能够更全面理解人类示范,提升操作的精细度和成功率。
3. 核心方法详解:从多模态人类视频学习
3.1 多模态人类演示视频采集
视频本身难以捕获细粒度的力信息。以插入电源插头任务为例,人类会先施加轻微力调整方向,随后加大力度完成插入。这些力的变化对成功完成任务至关重要,但仅靠视频难以观察。
为此,系统采集了包含以下模态的数据:
- RGB图像:记录操作环境与手部动作。
- 肌肉信号(EMG):通过带肌肉传感器的臂带采集,反映施力时机和强度。
- 物体交互声音:通过麦克风捕捉操作过程中的声音,辅助识别动作阶段。
- 手部姿态:利用视觉方法估计指尖位置,补充动作细节信息。
这些模态数据按时间同步,提供了人类操作任务更加全面且细致的表征。
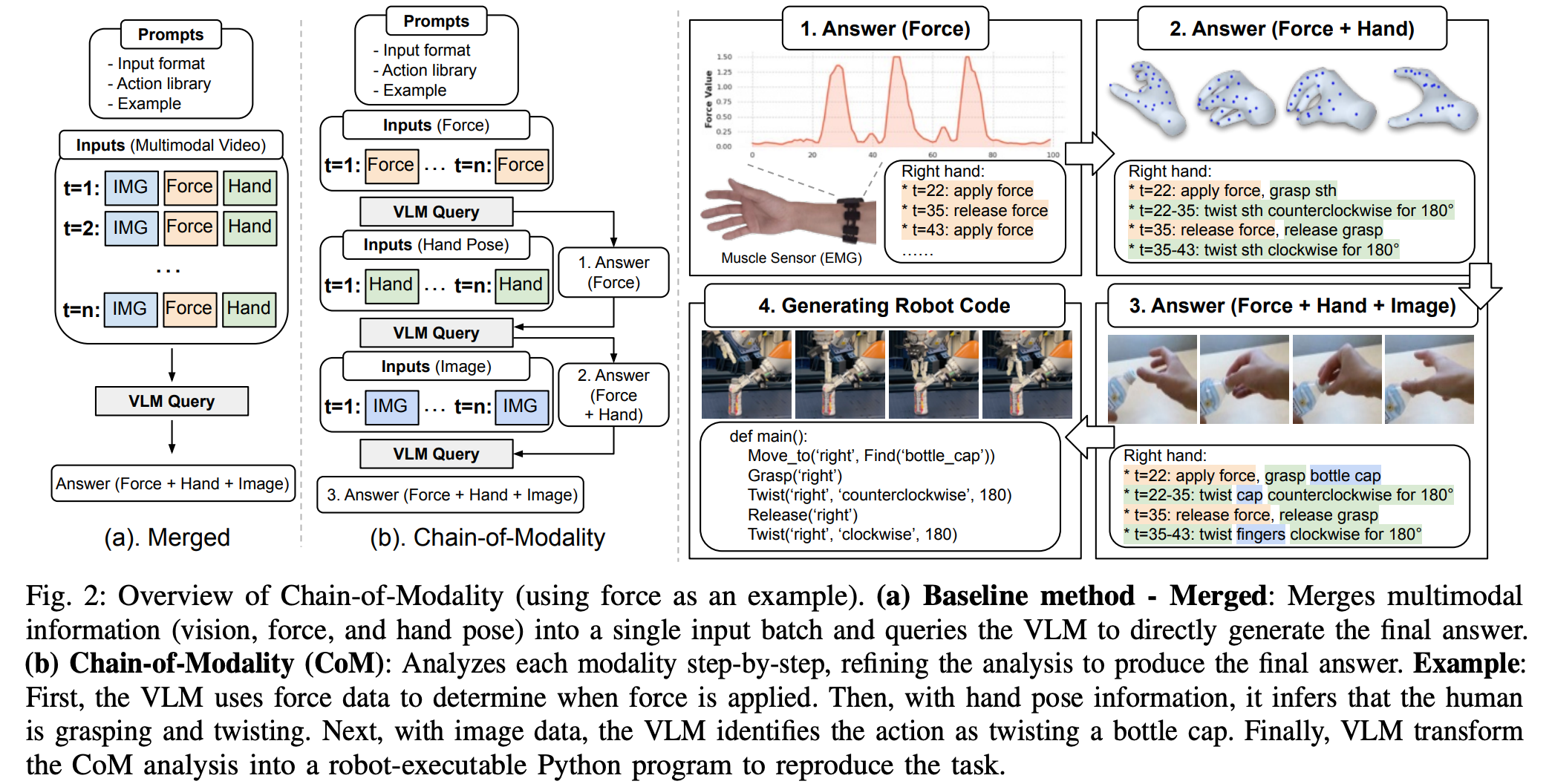
图 2:模态链(以力为例)的概述。 (a) 基线方法 - 合并:将多模态信息(视觉、力和手势)合并为一个单一的输入批次,并直接查询VLM生成最终答案。 (b) 模态链(CoM):逐步分析每种模态,精炼分析以生成最终答案。例如:首先,VLM利用力数据确定何时施加力。然后,结合手势信息,推断出人类正在抓取和扭动物体。接下来,利用图像数据,VLM将该动作识别为扭动瓶盖。最后,VLM将CoM分析转换为可供机器人执行的Python程序,以重现该任务。
3.2 模态链(Chain-of-Modality, CoM)推理策略
传统做法是将所有模态信息交织输入视觉语言模型(VLM),但实验发现顶尖VLM(例如Gemini 1.5 Pro、GPT-4o)往往难以有效关联不同模态,导致信息遗漏或误用。
为此,提出模态链(CoM),一种分阶段、顺序提示策略:
- 第一阶段:分析力或声音信号,定位施力的时间点和次数。
- 第二阶段:结合手部姿态信息,识别具体动作(如抓握、扭转)及其细节(旋转方向和角度)。
- 第三阶段:整合视觉图像,确定操作的具体物体及手部交互关系,完善整体任务计划。
通过逐步整合各模态信息,CoM能有效避免模态间的干扰和信息缺失,提升推理准确率和细节丰富度。
3.3 机器人代码生成
基于CoM得到的动作序列,系统利用同一视觉语言模型生成包含低级API调用的机器人控制代码。代码不仅规划动作顺序,还细化控制参数,如施力大小、运动方向和时序。
示例:
Move_to('left', Find('bottle'))
Grasp('left')
Move_to('right', Find('bottle_cap'))
for _ in range(3):Grasp('right')Twist('right', 'counterclockwise', 180)
Release('right')
Twist('right', 'clockwise', 180)
针对接触丰富的任务,如插入电源插头,代码还包含力的参数:
Grasp('right', 'plug', 100)
Move_to('right', 'box', 20)
Insert('right', 'power_strip', 100)
这些代码通过开放词汇API与感知系统结合,实现对新物体和未见配置的泛化执行。
3.4 实现细节
- 信号处理:肌肉信号8通道采样200Hz,下采样匹配60Hz视频帧率,取最大值作为力信号;音频计算响度作为声音输入;手部姿态通过HaMeR定位指尖像素。
- 机器人感知:利用Gemini 1.5 Pro查询RGB-D图像和目标物体名称,生成2D边界框并结合深度信息构建3D点云,估计物体位置,简化程序与机器人感知的连接。
4. 实验与分析
4.1 实验设计
- 多模态视频分析任务:4类操作(按压、插插头、打鼓、开瓶),每类10个不同物体/视角视频;
- 真实机器人执行任务:开瓶、插插头、擦板、打鼓,跨ViperX和KUKA双臂机器人平台,测试泛化能力;
- 基线方法:包括纯视觉、无力信号、无手势、直接合并模态等多种组合和推理方式。

图3:实验任务概述。(a) 多模态人类视频输入:我们的框架处理单次拍摄的人类视频,结合力传感器或音频数据,利用模态链提取任务计划和控制参数,然后生成机器人控制程序。(b) 机器人代码执行:机器人执行该程序,以复制视频中观察到的任务。© 评估设置:我们在不同的实验设置中评估生成程序的性能。
4.2 关键实验结果
- 模态链显著提升理解能力:CoM准确率达60%,远超直接合并模态的17%和纯视觉的0%,相似度分数提升42%;
- 力信号关键性:无力信号时任务计划准确率接近0,力信息帮助模型准确划分任务阶段和力度变化;
- 手部姿态提升细节解析:帮助区分抓握与扭转动作,识别手指旋转方向和力度变化,细粒度动作识别准确率明显提高;
- 机器人执行成功率高达73%:包括多种未见物体和随机场景,跨机器人平台稳定执行,远超纯视觉基线(0%成功率);
- 典型任务表现:
- 开瓶任务:7种不同瓶子,成功率60%-75%;
- 插插头任务:20次尝试成功15次;
- 打鼓任务:成功再现力度差异,成功率80%。

图4:链式模态的定性结果。我们展示了CoM为四个评估视频生成的任务计划。CoM成功地将视频分割成多个子任务,并在每个阶段明确了所需的技能、力量和目标对象。
5. 结论
本文提出的模态链(CoM)方法,通过顺序整合视觉、肌电和声音等多模态人类演示数据,显著提升了视觉语言模型对复杂操作任务的理解能力。基于CoM的多模态推理不仅能精准提取任务计划和细粒度控制参数,还能自动生成机器人可执行代码,实现跨平台的泛化操作。实验证明,加入力和手部姿态信息是提升机器人操作精度的关键,模态链提示策略有效解决了多模态信息融合难题。