网络原理(6)—— 应用层之HTTP协议
目录
一. 应用层
二. 重要应用层协议DNS(Domain Name System)
三. HTTP协议
3.1 HTTP抓包工具
3.2 HTTP格式
3.2.1 请求
3.2.2 响应
3.3 HTTP的工作过程
一. 应用层
应用层协议就像是人们之间的交流规则,它帮助不同的计算机程序(应用)能够互相理解和交换信息。在互联网上,当你在使用电子邮件、浏览网页或者视频聊天时,你的电脑和其他电脑之间需要按照一定的规则来传递信息。这些规则就是应用层协议。它们定义了信息应该如何打包、发送、接收以及如何处理可能出现的错误。
比如,当你使用浏览器上网时,浏览器和网站服务器之间使用的HTTP协议就是一种应用层协议。它规定了浏览器如何请求网页以及服务器如何响应这些请求。这样,不管你用的是哪种浏览器,也不管网站服务器在世界哪个角落,只要大家都遵循HTTP协议,信息就能正确传递。
我们之前编写完了基本的 Java Socket,要知道,我们之前所写的所有代码都在应用层,都是为了完成某项业务,如翻译等。应用层的协议主要涉及到两种情况:1)使用已经创建好的协议(后续会学习) 2)自己定义应用层协议
在日常开发中,自定义应用层协议是很常见的。前后端的程序员会开一个会,商讨确定 “前后端交互的接口”,约定前端要给后端发什么样的请求,对应的后端要返回什么样的响应(有很多细节需要确定)。确定好之后,就可以分别进行开发了。当前后端都分别开发完后,再把两边的代码放到一起,进行“联调”,针对之前约定好的前后端交互接口,进行验证。
- 自定义协议具体要做什么呢?
比如 开发一个“外卖软件”
1)明确传输的信息
打开软件,首先需要展示一个 “商家列表”,并且显示的商家列表都是点餐者附近的商家。
先确定传递的信息
- 请求:用户的id,用户所处的位置(计算机使用经纬度确定)
- 响应:商家列表,包含多个商家,每个商家信息中,又有商家的名字,图片,距离,评分
以上信息的确定,是根据当前需求产生的(需求详细设计文档)
2)明确传输数据的格式
针对信息组织的格式,也有很多种方式,使用哪种方式都可以,但是确保前端和后端是同一种式。
数据格式
A. 文本格式
1. 行文本格式(CSV):每行代表一条记录,字段之间用逗号分隔。
比如:
- 请求:用户id,用户位置\n(1001,E45N60\n)
- 响应:商家的id,商家名称,商家图片,商家地址,商家的距离,商家的评分;商家的id,商家名称,商家图片,商家地址,商家的距离,商家的评分(2001,魏家凉皮,http://image1.com,1.5km,4.5;2002,杨国福麻辣烫,http://image2.com,2.0km,4.6\n)
2. XML格式(传统方案):通过“成对的标签”表示“键值对”信息,标签可以自定义,具有层级关系。可以使用XML传输网络数据,也可以作为程序的配置文件。
比如:
<request>
<userId>1001</userId>
<position>E45N60</position>
</request>
XML 进行网络传输的时候,有明显的缺点:文档通常包含大量的标签和结构信息,这导致文件大小比纯文本数据大,增加了存储和传输的开销(消耗大量的带宽)
XML 和 HTML都是用于结构化数据的标记语言,以标签的形式表示,但是XML里的标签是程序员自定义的,而html的标签都是固定的(已有的一套标准)
3. JSON格式(主流):“键值对"格式,键和值使用 “:” 分割,键值对之间使用 “,” 分割,所有的键值对,都使用 “{ }” 括起来
比如:{
"userId": 1001,
"position": "E60N45"
}
相比于XML来说,可读性也是很好的,同时能够节省一定的带宽。但是 JSON 的可读性并没有那么好,由于没有明确要求数据的格式,会存在一些极端情况,比如:{"userId": 1001,"position": "E60N45"} 键值对数据很多时,数据放在一行,可读性就会非常差了。
4. YML/YAML:强制要求了数据格式,键值对必须独占一行,而且“嵌套”结构,必须通过缩进来表示。通常使用空格(而不是制表符)进行缩进,推荐使用两个或四个空格。
比如:request:
userId: 1001
position: E60N45
B. 二进制格式
Google Protocol Buffers:关注性能,牺牲了可读性,通过.proto文件定义数据结构,然后生成对应语言的代码。极大缩减了要传输的数据的体积,从而减少了带宽消耗,提高效率。
二. 重要应用层协议DNS(Domain Name System)
DNS是一整套从域名映射到IP的系统,把URL地址解析为IP地址这一过程就叫DNS解析。其实DNS就是一个数据库,这个数据库里面记录着很多URL和对应的IP地址。
DNS是按照层级划分的:
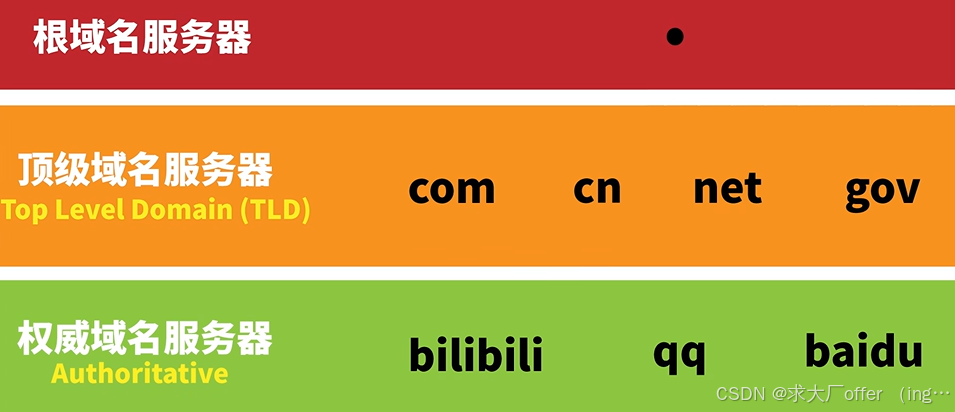
- 根服务器:根服务器是DNS层次结构的顶部,负责管理顶级域名服务器,如com、org、net、edu以及国家代码顶级域名(如uk、de、cn等),并响应关于这些TLDs的DNS查询。全球共有13组根服务器,每组有多台服务器分布在不同的地理位置,以确保稳定性和可靠性。根服务器负责管理DNS根区域,即域名系统的最高层级。
- TLD域名服务器:顶级域名服务器分别管理各自的域名服务器,比如bilibili、qq、daidu等。TLD DNS服务器负责管理顶级域名的DNS解析,它们是域名系统的第二级。
- 权威域名服务器:负责特定域名解析的服务器,管理各自的主机。权威DNS服务器负责管理域名的DNS区域文件,它们是域名解析过程中的最终信息提供者。
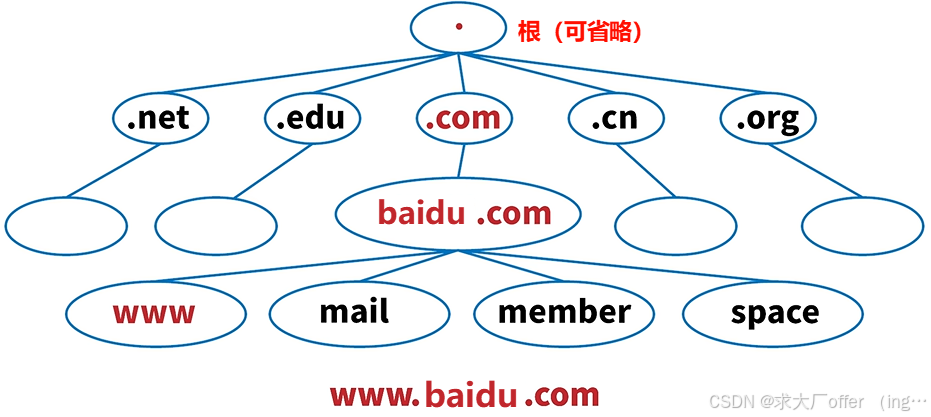
域名解析过程:
- DNS查询发起:客户端(如浏览器)发起一个DNS查询请求,请求解析特定的域名。
- 本地DNS缓存查询:客户端首先检查本地DNS缓存,以确定是否最近已经解析过该域名。
- 递归DNS查询:如果本地缓存中没有记录,客户端的递归DNS服务器将代表客户端向其他DNS服务器发起查询。
- 选代DNS查询:递归DNS服务器首先向根DNS服务器查询,根服务器将指向相应的顶级域(TLD)DNS服务器。
- TLD DNS服务器查询:递归DNS服务器接着向TLD DNS服务器查询,获取域名注册商的DNS服务器地址。
- 权威DNS服务器查询:递归DNS服务器最后向权威DNS服务器查询,这是负责管理特定域名的DNS服务器。
- DNS响应:权威DNS服务器返回域名对应的IP地址给递归DNS服务器。
- DNS缓存和响应:递归DNS服务器将IP地址缓存起来,并将结果返回给客户端,客户端也将结果缓存以供后续使用。

三. HTTP协议
HTTP(全称为“超文本传输协议”)是一种应用非常广泛的应用层协议,我们平时打开一个网站就是通过HTTP协议来传输数据的。HTTP 往往是基于传输层的 TCP 协议实现的(HTTP1.0,HTTP1.1,HTTP2.0 均为TCP,HTTP3 基于UDP 实现),目前我们主要使用的是HTTP1.1和HTTP 2.0
所谓“超文本”的含义,就是传输的内容不仅仅是文本(比如html, CSS等文本) , 还可以是一些其他的资源,比如图片,视频,音频等二进制的数据。
当我们在浏览器中输入一个百度搜索的 “网址”(URL)时,浏览器就给百度的服务器发送了一个HTTP请求,百度的服务器返回了一个HTTP响应。这个响应结果被浏览器解析之后,就展示成我们看到的页面内容(这个过程中浏览器可能会给服务器发送多个HTTP请求,服务器会对应返回多个响应,这些响应里就包含了页面HTML,CSS,JavaScript,图片,字体等信息)
3.1 HTTP抓包工具
HTTP是一个文本格式的协议,可以通过Chrome开发者工具或者Fiddler抓包,分析HTTP请求/响应的细节。
以Fiddler为例:
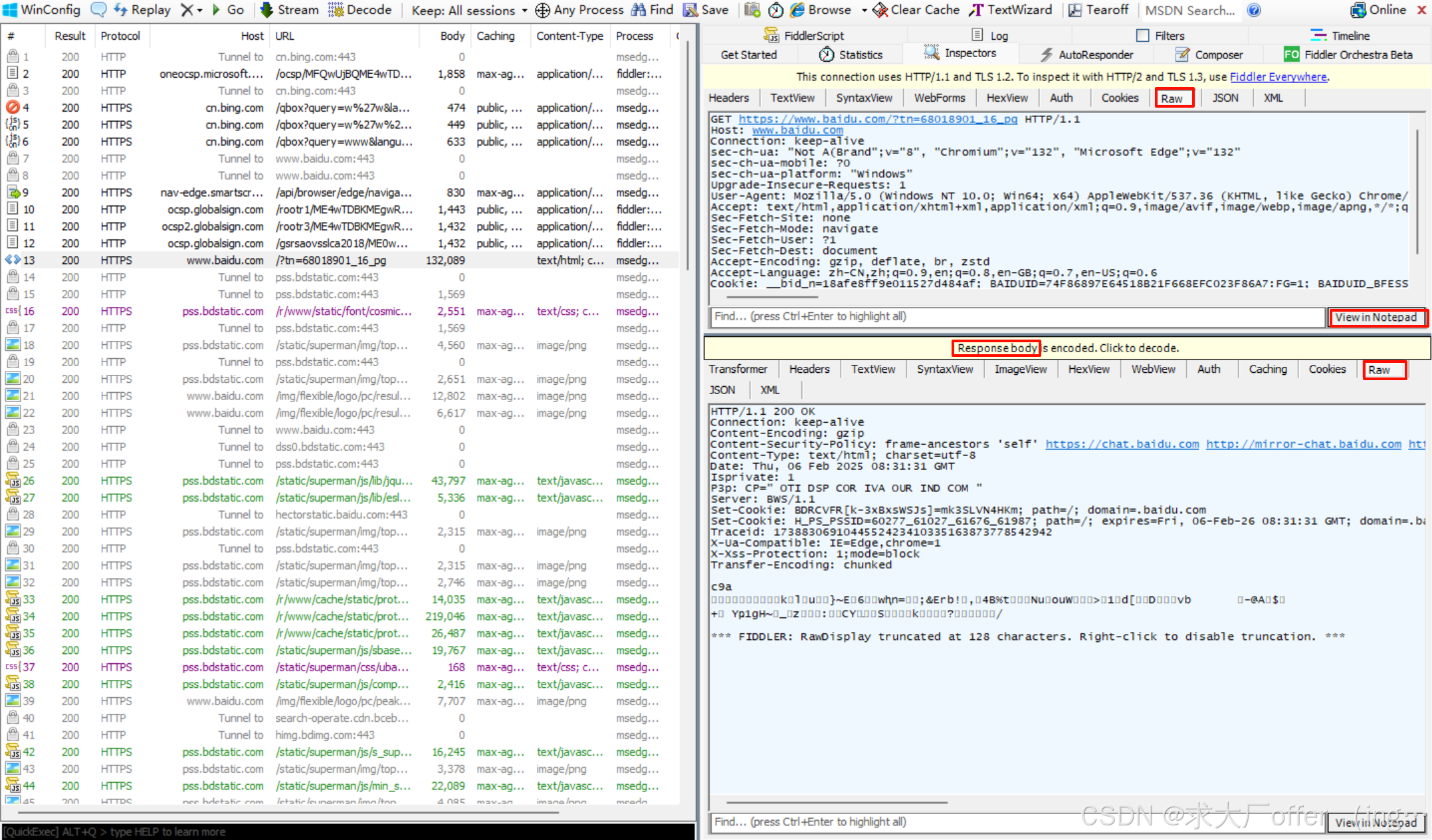
- 左侧窗口显示了所有的HTTP请求/响应,可以选中某个请求查看详情(发送HTTP请求,就是往TCP Socket中,按照规定格式,写入一段字符串;收到HTTP响应,就是从TCP Socket中,读出一段字符串再按照规则解析)
- 右侧上方显示了HTTP请求的报文内容(切换到Raw标签页可以看到详细的数据格式)
- 右侧下方显示了HTTP响应的报文内容(切换到Raw标签页可以看到详细的数据格式),返回的响应数据是压缩过的,在二进制的角度上对数据进行重新编码,保证信息量不变,体积缩小。解压缩之后,浏览器看到的网页就是由HTML/CSS/JavaScript/JSON/图片/音频/字体等构成的。
- 请求和响应的详细数据,可以通过右下角的View in Notepad通过记事本打开
Fiddler的快捷键
- Ctrl + X:清除会话列表中的所有条目
- Ctrl + A:全选会话列表中的所有条目;Del:清空所有内容
访问一个网页,不是一次HTTP请求就能搞定的,而是由多个HTTP请求(尤其是GET)得到的结果,最终汇总而成的(HTML包含的一些link,script,img.….都可能进一步的触发HTTP请求,进一步从服务器获取资源)
- Ctrl+F5:当你按下Ctrl+F5时,浏览器会绕过缓存,直接从服务器加载页面的所有内容。使用Ctrl+F5可以确保浏览器加载页面的最新版本,忽略任何本地缓存。
- F5:单按F5键的作用是刷新当前页面,浏览器会重新加载当前页面,但通常会从缓存中加载某些文件,而不是从服务器重新下载。如图片、CSS和JavaScript文件等,这些内容一般都是固定的,改变频率非常低,只需要第一次访问主页的时候,把固定的资源,都保存下来(电脑的硬盘上),后续再访问就没必要重复获取上述内容了,从而节省服务器的带宽,加快页面展示的速度。
与Ctrl+F5不同,单按F5不会强制浏览器忽略缓存。它允许浏览器使用其缓存来提高页面加载速度,除非服务器指示资源已更改,或者浏览器缓存策略要求重新验证资源。 很明显,当用F5刷新时,Fiddler抓到的包比Ctrl+F5抓到的少很多
Fiddler抓包工具原理:
Fiddler是一个广泛使用的网络调试代理工具,它允许开发者监控和修改电脑与互联网之间的HTTP和HTTPS流量。
Fiddler工作的核心原理是它充当了一个本地代理服务器,位于客户端和互联网之间,它代表客户端发送请求,并接收来自服务器的响应(正向代理)。启动Fiddler时,它会设置自己的代理监听端口(默认为8888),并配置操作系统或浏览器,使得所有的网络流量都通过Fiddler代理。
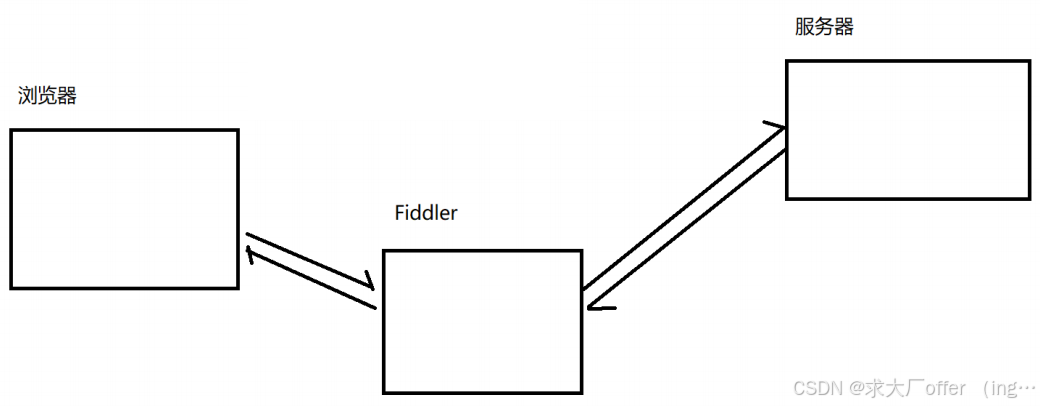
正向代理:帮客户端访问服务器
- 比如 你想买一个国外的东西,但是卖家不直接卖给中国人,这时候你找到了一个代购。代购帮你从国外买东西,然后寄给你。这里的代购就相当于正向代理。
- 正向代理是帮客户端(你)访问他们无法直接访问的服务器(国外卖家)。简单来说,正向代理就是帮你“偷偷”上网的工具。
反向代理:帮服务器接收和处理客户端的请求
- 比如 你开了一个网店,每天有很多顾客来买东西,但你一个人忙不过来。于是你请了一个客服团队来帮你处理订单。顾客不知道具体是哪个客服在服务他们,他们只知道是在跟你这个网店打交道。
- 这里的客服团队就相当于反向代理。反向代理是帮服务器(你的网店)接收来自客户端(顾客)的请求,然后将请求分发给不同的服务器(客服)处理。简单来说,反向代理就是帮你“分担”访问压力的工具。
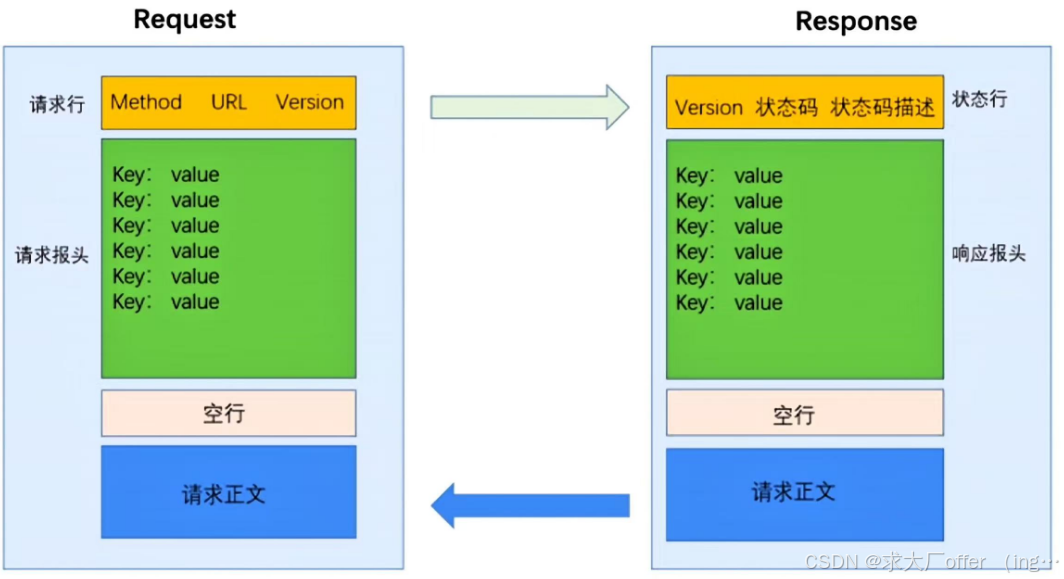
3.2 HTTP格式
3.2.1 请求
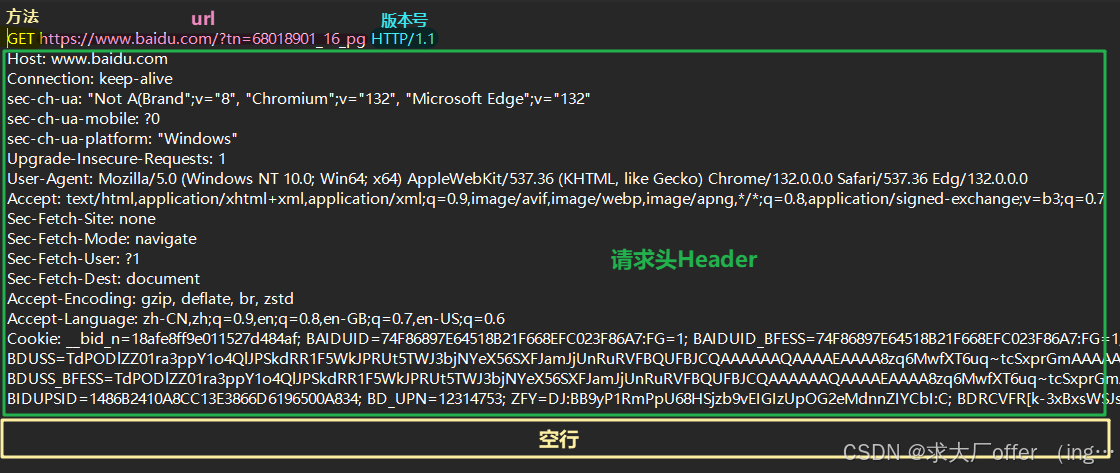
1)请求行:
- 方法:如GET、POST、PUT等,表示对资源的操作
- URL:统一资源标识符,指定请求的资源
- HTTP版本:如 HTTP/1.1
2)请求头(Header)
- 请求的属性,包含了关于客户端环境和请求本身的信息,如请求的主机名、用户代理(浏览器类型)、接受的内容类型等,用 “: ” (冒号+空格) 分割的键值对,如 Host: www.sogou.com
Connection: keep-alive - 每组属性之间使用 “\n” 分隔
- 遇到空行表示 Header 部分结束
3)空行
- 在请求头和请求体之间必须有一个空行,用于分隔头部和内容。
4)请求体(RequestBody)
- 空行后面的内容都是 Body,Body 允许为空字符串。如果 Body 存在,则在 Header 中会有一个 Content-Length 属性来标识 Body 的长度
- 对于需要发送数据的请求(如POST或PUT),Body 会包含在请求中发送的数据。
3.2.2 响应
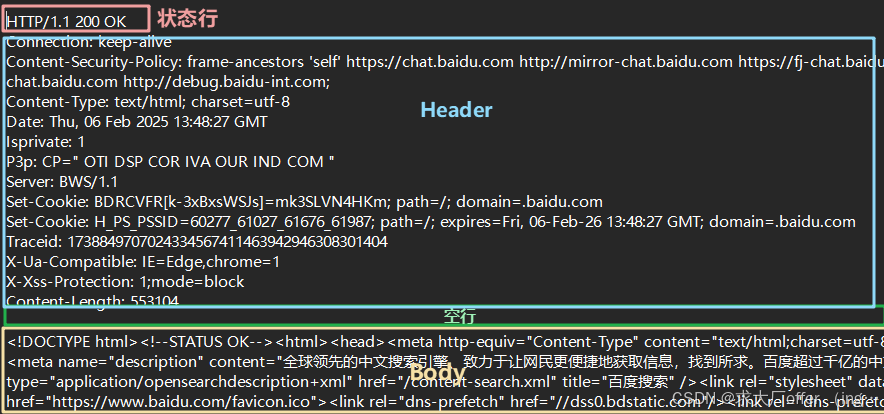
1)状态行
- HTTP版本:如 HTTP/1.1
- 状态码:如200表示成功,404 表示未找到
- 状态消息:提供状态码的简短描述,如 200-->“OK” 或 404-->“Not Found”
2)响应头(Headers)
- 响应的属性,包含了关于响应本身的信息,如内容类型、内容长度、服务器类型等,冒号分割的键值对
- 每组属性之间使用 “\n” 分隔
- 遇到空行表示Header部分结束
3)空行
- 响应头和响应体之间必须有一个空行,用于分隔头部和内容
4)响应体(ResponseBody)
- 响应体包含了从服务器发送给客户端的实际内容,通常是HTML页面、图片、视频等资源。
3.3 HTTP的工作过程
- 用户输入URL:用户在客户端应用程序(通常是Web浏览器)的地址栏中输入统一资源定位符(URL),例如http://www.baidu.com。
- DNS解析:浏览器解析URL中的域名,通过域名系统(DNS)查询将其转换为服务器的IP地址。
- 建立连接:客户端通过TCP协议与服务器建立连接,这通常涉及三次握手过程。
- 发送HTTP请求:客户端向服务器发送一个HTTP请求。请求包括方法、请求的URL、协议版本,以及一系列可选的请求头。
- 服务器处理请求:服务器接收到请求后,根据请求的方法和URL,处理请求并生成响应。这可能涉及服务器端脚本的执行、数据库查询或其他资源访问。
- 服务器响应:服务器将处理结果封装在HTTP响应中发送回客户端。响应包括协议版本、状态码、状态信息,以及一系列响应头和可选的响应体。
- 关闭连接:在发送完响应后,服务器和客户端通常会关闭TCP连接。在HTTP/1.1中,如果请求头中包含Connection: keep-alive,则连接可能会被保持打开状态,以用于后续请求。
- 客户端处理响应:客户端收到服务器的响应后,会根据状态码和响应头来处理响应。如果一切正常,客户端会将响应体(如HTML页面)渲染并展示给用户。