专家系统的推理流程深度解析
内容补充:
(1)有关“专家系统的基本概念”:专家系统的基本概念解析——基于《人工智能原理与方法》的深度拓展_专家系统的本质-CSDN博客(2)有关“专家系统的一般结构”:专家系统的一般结构解析——基于《人工智能原理与方法》的深度拓展-CSDN博客
(3)有关“专家系统的知识获取、检测与组织管理”:专家系统的知识获取、检测与组织管理——基于《人工智能原理与方法》的深度解析-CSDN博客
一、专家系统的完整推理流程
专家系统的推理流程是知识与数据结合求解问题的核心过程,其本质是“符号操作与逻辑推导的系统化实现”,涵盖从数据输入到结论输出的完整闭环。以下是抽象化的推理流程模型:
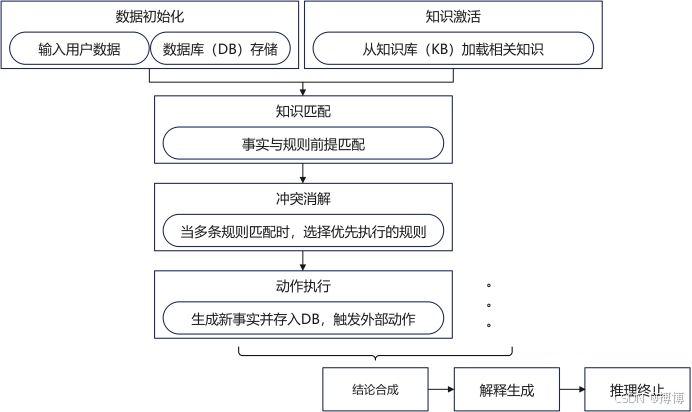
(一)推理准备阶段
1.数据初始化
(1)输入用户数据:结构化事实(如“体温 = 38.5℃”)或非结构化数据(如“咳嗽剧烈”,经NLP解析为“咳嗽程度 = 剧烈”)。
(2)数据库(DB)存储:将事实存入工作内存(Working Memory),如医疗系统的“患者当前事实表”。
2.知识激活
从知识库(KB)加载相关知识:根据问题类型筛选规则子集(如诊断类问题加载“症状 - 疾病” 规则)。
示例:变压器故障诊断时,仅激活“油色谱分析”“电压波动”相关规则,忽略无关的“绝缘材料” 规则。
(二)推理执行阶段
1.知识匹配
(1)事实与规则前提匹配:通过模式匹配算法(如Rete算法)检测事实是否满足规则条件。
(2)数学表达:对规则![]() ,若事实集合
,若事实集合![]() ,则规则激活。
,则规则激活。
2.冲突消解
当多条规则匹配时,选择优先执行的规则(详见第二部分)。
3.动作执行
执行规则结论:生成新事实(如“发热”标记)并存入DB;触发外部动作(如医疗系统建议“进行血常规检查”)。
(三)结果处理阶段
1.结论合成
合并多条规则结论:若多条规则推导同一结论,通过不确定性推理方法合成置信度(如可信度理论、贝叶斯公式)。
2.解释生成
回溯推理路径:记录触发的规则序列、事实匹配过程,生成“为何”“如何”解释(如“因体温 38.5℃触发规则R001,故标记为发热”)。
3.推理终止
满足终止条件时结束:目标达成(如反向链找到目标疾病);无新事实生成且无待验证目标(如正向链无更多规则匹配)。
二、正向链推理(Forward Chaining)——数据驱动的推理引擎
正向链是“事实→规则→新事实”的链式推导,适用于监控、预测等数据丰富场景,其核心步骤如下:
(一)事实匹配(Fact Matching)
1.模式匹配算法
Rete算法:将规则编译为数据流网络,通过 α 节点(单条件匹配)和 β 节点(多条件合并)实现增量式匹配,时间复杂度从暴力匹配的O(nm) 降至O(k(m+n))(k 为平均条件数)。
示例:规则R: 体温>38℃ ∧ 咳嗽 → 感冒(CF=0.8) 的匹配过程:
(1)事实“体温 = 38.5℃”激活 α 节点1(体温 > 38℃);
(2)事实“咳嗽 = 是”激活 α 节点2(咳嗽);
(3)β 节点合并两个 α 节点输出,生成规则实例。
2.匹配优化
索引技术:对事实属性建立索引(如“体温”字段建立B + 树),快速定位匹配规则。
(二)冲突消解(Conflict Resolution)——规则选择策略
当多个规则实例激活时,需通过消解策略选择执行顺序,王永庆归纳了五种经典方法:
1.优先级排序法
为规则分配优先级(如医疗规则中“致命疾病优先”),示例:
(1)R1: 体温>40℃ → 重症发热(CF=1.0,优先级=100)
(2)R2: 体温>38℃ → 发热(CF=1.0,优先级=50)
(3)当体温 = 40.5℃时,优先执行 R1。
2.最新事实优先(Most Recent Fact, MRFC)
选择匹配最新录入事实的规则,适用于实时监控场景。
数学定义:设事实f_i 的时间戳为t_i,规则R_j 匹配的事实集合为F_j,则优先级
![]() ,选择P_j 最大的规则。
,选择P_j 最大的规则。
3.特异性更高优先(More Specific Rule)
前提条件更具体的规则优先(如“体温> 39℃且咳嗽”比“体温 > 38℃”更具体)。
判断方法:若规则 R1 的前提是 R2 前提的子集(P1 ⊂ P2),则 R1 更具体。
4.最少匹配数优先
选择前提条件最少的规则,减少计算开销,适用于效率优先场景。
5.人工干预法
由用户或专家指定规则执行顺序,作为其他策略的补充(如调试阶段临时调整)。
(三)动作执行(Action Execution)
1.结论处理
生成新事实:如规则“发热∧咳嗽→感冒” 执行后,向工作内存添加“疾病 = 感冒(CF=0.8)”。
触发副作用:如工业系统中规则“压力> 阈值→报警”执行时,同时记录报警日志并发送通知。
2.循环控制
推理循环:重复“匹配 - 消解 - 执行”直至无新规则匹配,伪代码如下:
python代码如下:
def forward_chaining(initial_facts): working_memory = initial_facts.copy() while True: matched_rules = match_rules(working_memory) if not matched_rules: break selected_rule = conflict_resolution(matched_rules) new_facts = execute_rule(selected_rule, working_memory) working_memory.update(new_facts) if goal_achieved(working_memory): break return working_memory (四)其他关键步骤
(1)事实过滤:排除过时或无关事实(如超过24小时的体温数据自动失效)。
(2)递归深度控制:设置最大推理步数防止无限循环(如限制最多执行100条规则)。
三、反向链推理(Backward Chaining)——目标驱动的假设验证
反向链从目标出发,反向验证前提条件,适用于诊断、调试等目标明确场景,其核心流程如下:
(一)目标初始化
用户设定目标:如医疗系统中用户输入“是否患肺炎”,或系统自动生成默认目标(如“最高优先级疾病”)。
子目标分解:将复杂目标拆分为原子目标,如“肺炎诊断”分解为“是否高热”“是否咳嗽超过3周”“痰涂片是否阳性”。
(二)反向匹配与回溯
规则检索:查找结论为当前目标的所有规则,如目标“肺炎”对应规则:
R1: 高热∧咳嗽>3周∧痰涂片阳性→肺炎(CF=0.95)
R2: 高热∧胸片阴影→肺炎(CF=0.90)
条件验证:
若条件已知(如“高热 = 是”),直接检查;
若条件未知,递归生成子目标(如“验证是否咳嗽> 3周”),并向用户提问或查询数据库。
(三)证据积累与置信度传播
证据收集:
(1)正向收集:通过用户输入、传感器数据获取证据(如“痰涂片阳性 = 是”);
(2)反向推导:通过其他规则推导子目标(如“白细胞计数> 10^9/L→感染→可能高热”)。
置信度计算:
(1)合取条件:CF(合取) = min(CF_1, CF_2, ..., CF_n);
(2)析取条件:CF(析取) = max(CF_1, CF_2,..., CF_n);
示例:规则R1的前提CF分别为 0.9(高热)、0.8(咳嗽 > 3 周)、0.7(痰涂片阳性),则结论CF=0.7×0.95=0.665。
(四)剪枝与终止
失败剪枝:若子目标置信度低于阈值(如 0.2),提前终止该路径推理;
成功终止:当目标置信度超过阈值(如 0.8)或所有可能规则已验证,返回结论。
四、确定性推理(Certainty Reasoning)——精确知识的逻辑推导
当知识确定(无模糊性,CF=1.0)时,推理退化为经典逻辑推导,核心特征:
(一)逻辑基础
经典逻辑推理是根据经典逻辑(命题逻辑及一阶谓词逻辑)的逻辑规则进行的一种推理,主要推理方法有自然演绎推理、归结演绎推理及与/或形演绎推理等。由于这种推理是基于经典逻辑的,其真值只有“真”和“假”两种,因此它是一种精确推理,或称为确定性推理。
一阶谓词逻辑:规则表示为∀x (P_1(x) ∧ P_2(x) → C(x),如“所有高热患者都属于发热人群”。
1.自然演绎推理
(1)P 规则(前提引入规则):是自然演绎推理中最基础的规则,允许在推理过程的任意步骤中引入已知为真的前提(或假设)。
(2)T 规则(结论引入规则):允许在推理过程中,根据已有的前提和推理规则,推导出新的结论并引入推理步骤。
(3)假言推理(Modus Ponens):若P → C 且 P 为真,则 C 为真。
(4)拒取式推理(Modus Tollens): 拒取式推理是假言推理的逆过程,其核心是若已知 P →Q为真且Q为假,则可推出P为假。
有关“经典逻辑推理”:经典逻辑推理的基本概念——基于王永庆著《人工智能原理与方法》的深度解析_什么是基于默认信息的推理?解释在人工智能系统中如何应用默认推理来处理不完-CSDN博客 有关“自然演绎推理”:自然演绎推理——基于王永庆著《人工智能原理与方法》的深度解析-CSDN博客
2.归结演绎推理
自然演绎推理是对前提P 和 Q 证明 P → Q 的永真性,归结演绎推理则是应用反证法的思想可把关于永真性的证明转化为不可满足性(永假性)的证明,即如欲证明 P → Q 永真,只要证明 P ∧ ¬ Q 是不可满足的就可以了。关于不可满足性的证明,需要描述如何将问题转化为子句集,然后通过归结反演树证明定理。
有关“归结演绎推理”:归结演绎推理——基于王永庆著《人工智能原理与方法》的深度解析-CSDN博客
3.与/或形演绎推理
与/或形演绎推理是利用与/或图的形式,正向演绎从事实出发应用B规则扩展与/或图,逆向演绎从目标出发应用A规则反向扩展,双向演绎结合两者,通过图的扩展和节点匹配来完成推理,强调推理过程的图形化表示和对不同推理方向的支持。
有关“与/或形演绎推理”:与/或形演绎推理——基于王永庆著《人工智能原理与方法》的深度解析_与或形-CSDN博客
(二)推理算法
(1)归结原理(Resolution Principle):将规则转换为子句形式,通过消解反证目标,适用于数学定理证明等场景。
示例:证明“若体温> 38℃则发热,某患者体温39℃,则该患者发热”,通过归结消解矛盾(假设“不发热”与前提冲突)。
(2)自然演绎法:通过逻辑规则(合取引入、析取消去等)逐步推导结论,适合人类可读的推理过程展示。
五、不确定性推理(Uncertainty Reasoning)——处理不完整/模糊知识
现实场景中知识常具有不确定性,王永庆总结了三种主流方法:
(一)可信度理论(Certainty Factor, CF)——MYCIN 系统方法
1.基本概念
规则表示:IF P THEN C (CF_rule),其中CF_rule∈[-1, 1] 表示规则强度。
事实置信度:CF(fact)∈[0, 1](证据支持度)或[-1, 0](证据反对度)。
2.置信度计算
(1)单规则推导:![]() ;
;
(2)多规则合成:
同向证据(均支持结论):![]()
反向证据(一支持一反对):![]()
示例:两条规则推导“感冒”:
R1: 发热→感冒(CF=0.8),发热 CF=0.9 → 感冒 CF=0.72;
R2: 咳嗽→感冒(CF=0.7),咳嗽 CF=0.8 → 感冒 CF=0.56;
合成后 CF=0.72+0.56-0.72×0.56=0.848。
(二)贝叶斯推理(Bayesian Reasoning)——概率逻辑
1.条件概率模型
设D为疾病,S为症状,根据贝叶斯定理:
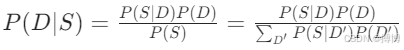
示例:已知肺炎(D)的先验概率P(D)=0.01,高热(S1)在肺炎中的概率P(S1|D)=0.9,在非肺炎中的概率P(S1|¬ D)=0.2,则:![]()
2.贝叶斯网络(Bayesian Network)
用有向无环图表示变量依赖,如“肺炎→高热”“肺炎→咳嗽”,通过条件概率表(CPT)高效计算联合概率。
(三)模糊推理(Fuzzy Reasoning)——处理模糊概念
1.模糊集合与隶属度
定义模糊集:如“高热”对应隶属函数
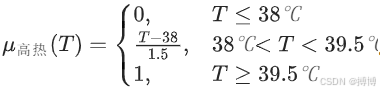 。
。
2.模糊规则与推理
规则形式:IF x is A THEN y is B,如“若体温是高热,则疾病可能性是肺炎”。
推理步骤:模糊化输入(计算隶属度)→ 规则匹配→ 模糊合成→ 去模糊化(如重心法得到确定结论)。
六、其他推理方式
(一)混合推理(Hybrid Reasoning)
结合正向链与反向链,先正向筛选候选结论,再反向精修。
医疗诊断示例:
正向链:根据症状“高热、咳嗽” 筛选可能疾病(感冒、肺炎、流感);
反向链:对每个候选疾病,反向验证关键检查指标(如肺炎需要胸片阴影)。
(二)类比推理(Analogical Reasoning)
基于案例的推理(CBR)。
检索相似案例:如输入“变压器 H₂=150ppm, CH₄=60ppm”,查找历史案例库中最相似的故障案例;
重用解决方案:根据相似案例的故障类型(如“放电故障”),推荐检测步骤。
(三)元推理(Meta-Reasoning)
对推理过程的推理。
动态调整推理策略:如数据稀疏时优先用反向链,数据丰富时用正向链;
资源分配:根据问题复杂度分配计算资源(如复杂目标增加推理时间预算)。
七、完整推理案例——变压器故障诊断系统
(一)案例背景
输入:油色谱数据H₂=150ppm, CH₄=60ppm, C₂H₂=25ppm。
目标:判断故障类型(放电 / 过热 / 绝缘老化)。
(二)正向链推理流程
(1)事实匹配:
规则 R1:H₂>100∧CH₄>50∧C₂H₂>20 → 放电故障(CF=0.95) 匹配;
规则 R2:CH₄>80∧C₂H₂<10 → 过热故障(CF=0.90) 不匹配(C₂H₂=25>10)。
(2)冲突消解:仅 R1 匹配,无冲突。
(3)动作执行:添加“故障类型 = 放电故障(CF=0.95)”到工作内存。
(4)结论合成:单一规则推导,结论确定。
(三)反向链验证(假设“放电故障”)
目标分解:验证 R1 的三个前提:
(1)H₂>100:已知 150>100,成立(CF=1.0);
(2)CH₄>50:已知 60>50,成立(CF=1.0);
(3)C₂H₂>20:已知 25>20,成立(CF=1.0)。
置信度计算:CF=1.0×1.0×1.0 ×0.95=0.95,超过阈值0.8,目标成立。
(四)不确定性处理(若 C₂H₂=15ppm,处于临界值)
模糊处理:定义“C₂H₂偏高”的隶属度为0.7(15ppm对应隶属函数值);
置信度调整:CF=1.0×1.0×0.7×0.95=0.665,仍高于阈值0.6,保留“放电故障”结论,附加提示“C₂H₂浓度接近临界值,建议复查”。
八、推理流程的数学化与优化
(一)复杂度分析
正向链:时间复杂度![]() (Rete 算法),空间复杂度O(n)(存储激活规则);
(Rete 算法),空间复杂度O(n)(存储激活规则);
反向链:时间复杂度![]() (d 为平均分支因子,n 为推理深度),通过剪枝可降至
(d 为平均分支因子,n 为推理深度),通过剪枝可降至![]() 。
。
(二)优化策略
(1)索引与缓存:缓存高频匹配结果,减少重复计算;
(2)并行推理:对独立规则或子目标并行匹配(如GPU加速模式匹配);
(3)主动推理:主动请求关键证据(如反向链中优先询问对目标影响最大的问题)。
九、总结与前沿趋势
(一)核心价值
推理流程是专家系统的“智能引擎”,其设计需平衡:
(1)准确性:通过不确定性推理处理现实模糊性;
(2)效率:利用Rete算法、索引技术提升匹配速度;
(3)可解释性:通过推理日志、解释模块满足用户透明性需求。
(二)前沿方向
(1)神经符号推理:结合神经网络(处理图像/文本)与符号推理(逻辑验证),如医疗影像诊断中CNN定位病灶后,通过规则系统验证诊断逻辑;
(2)自适应推理策略:根据实时数据量、问题复杂度动态切换正向/反向链,或调整不确定性推理方法;
(3)量子计算加速:利用量子并行性优化大规模规则库的匹配与消解(理论上可将O(n) 匹配降至
![]() )。
)。
(三)公式总结
(1)可信度合成(同向):![]()
(2)贝叶斯定理:![]()
(3)模糊隶属度:![]() 表示元素 x 属于模糊集 A 的程度
表示元素 x 属于模糊集 A 的程度
通过系统化设计推理流程,专家系统得以在医疗、工业、金融等领域实现可靠决策,而随着 AI 技术的进步,其推理能力将向更智能、更高效、更透明的方向持续演进。