10倍速学完斯坦福的大模型课程
斯坦福25年春季的transformer和大模型新课来了,授课老师Afshine和Shervine Amidi在AI圈子里很有一套,内容从Transformer的基础原理到LLM的实战应用,信息量很大。
但是今天重点推荐的是这门课的小抄,如果你没时间或者没有耐心完整上课,直接去看小抄。

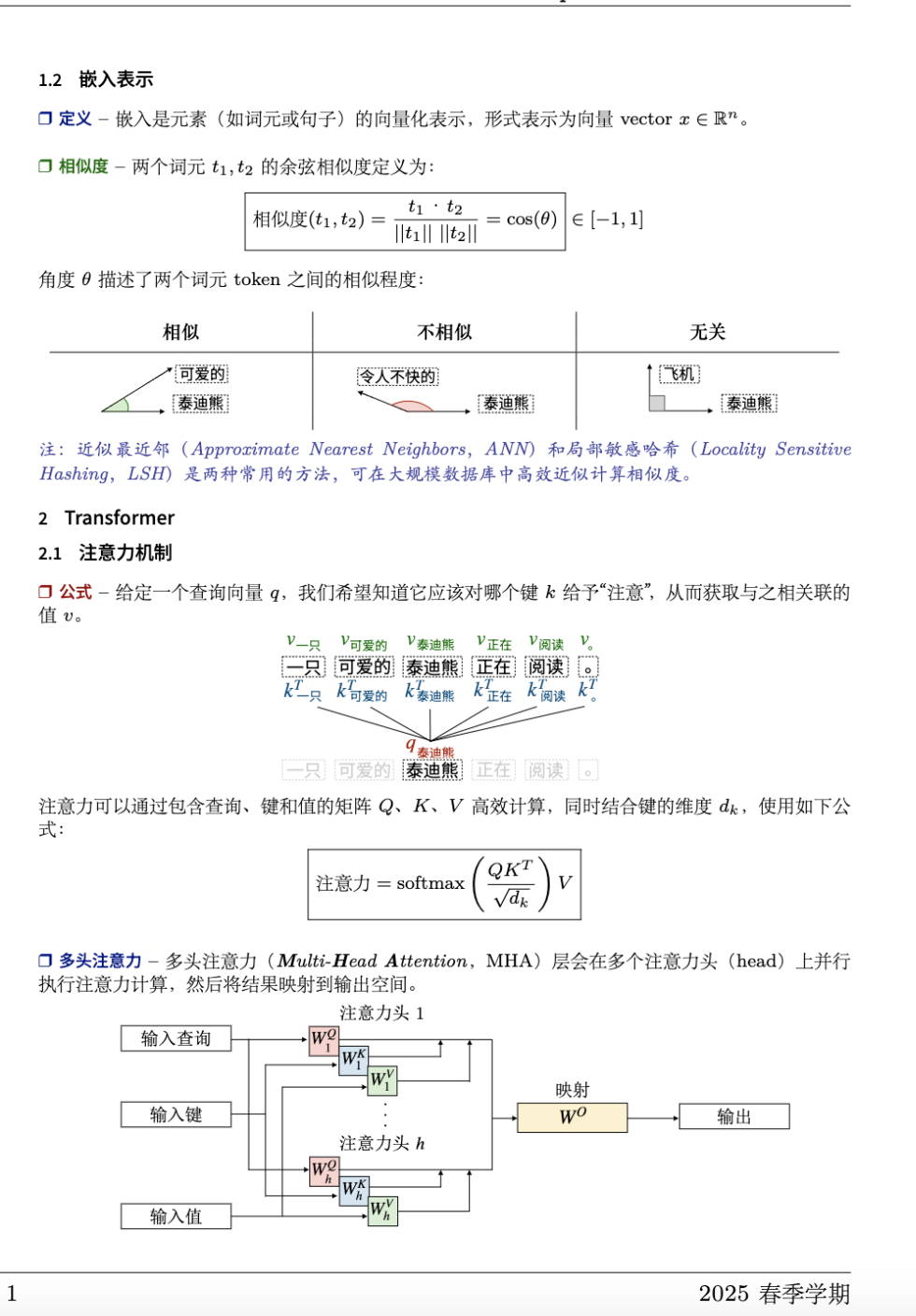
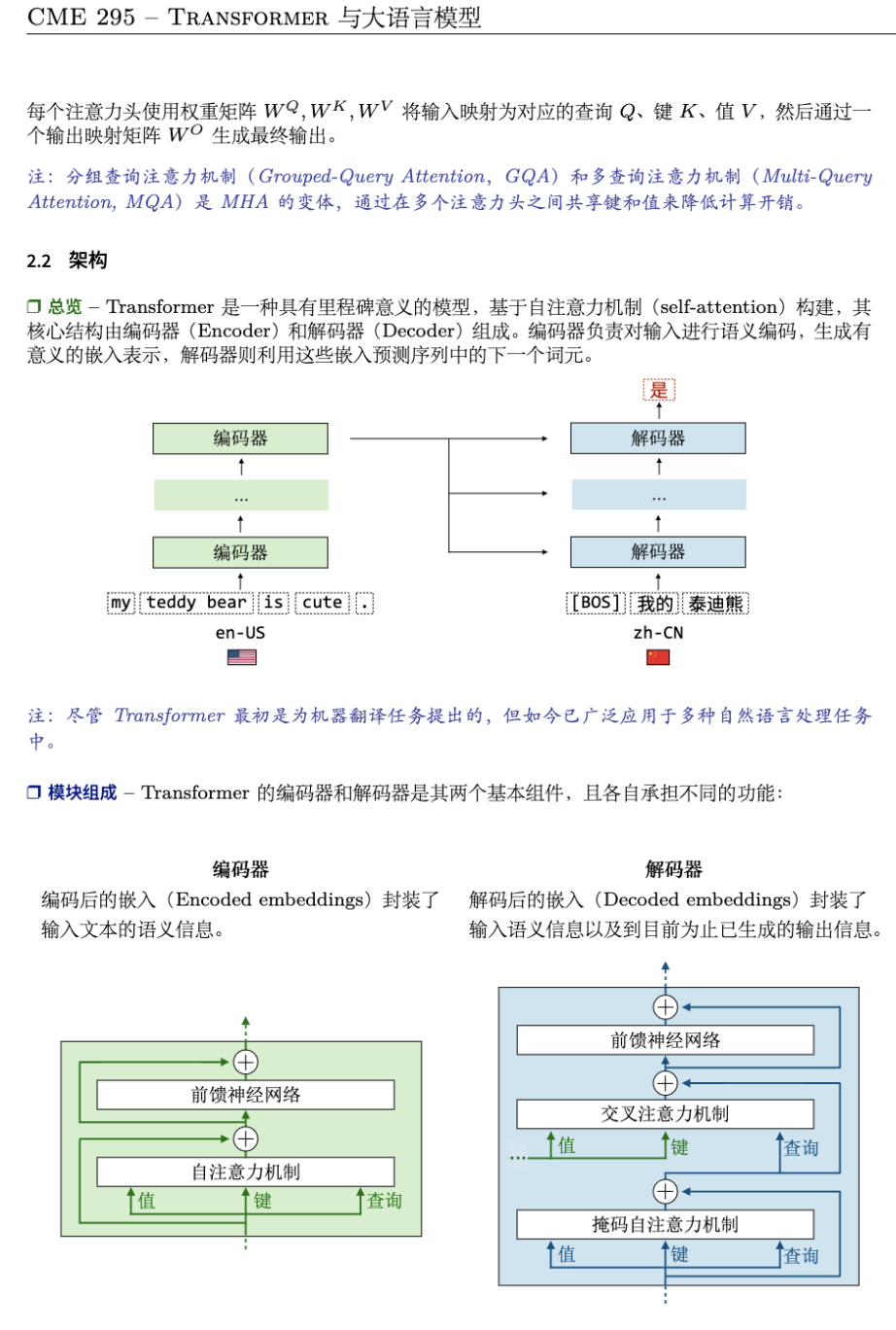
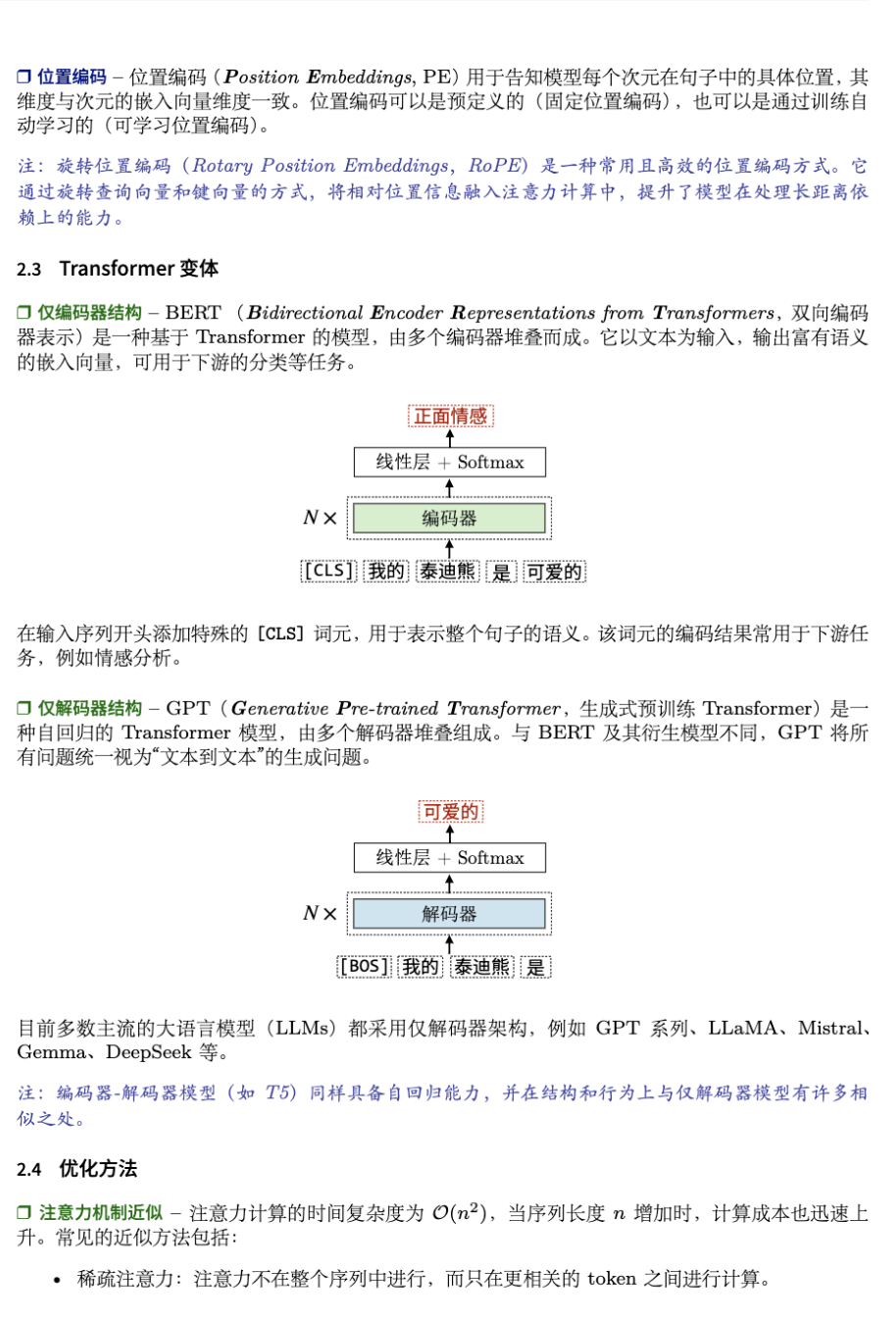
几十页就把一个学期的课浓缩得明明白白,很适合快速过一遍。浓缩了Transformer和LLM的精华。内容从基础讲起,比如Self-Attention机制是咋回事,Transformer架构咋搭的,到高级点的LLM微调(像SFT、LoRA)、提示工程、甚至RAG和AI Agent这些实战应用,都有条有理。比如他们会拿图表给你拆解Attention咋算的,或者讲讲咋用混合专家模型(MoE)省算力,学完感觉脑子里全是干货。

再进阶一点,甚至还有更详细的配套漫画,250页内容,配了600多张图表,把整门课的重点全打包了。从Attention机制的数学细节到提示工程、模型压缩的实用技巧,讲得清楚又直白。比如想知道怎么用LLM当“裁判”评判输出?这里面就有现成案例。新手看能快速上手,老手看能梳理思路。翻着翻着就很愉快地学完了
这份小抄我已经给大家整理好了,戳此免费获取>>>>>>>>>>>>>>>>>>>>>>>>>>>