DeepSeek实战--LLM微调
1.为什么是微调 ?
微调LLM(Fine-tuning Large Language Models) 是指基于预训练好的大型语言模型(如GPT、LLaMA、PaLM等),通过特定领域或任务的数据进一步训练,使其适应具体需求的过程。它是将通用语言模型转化为专用模型的核心方法。
2.微调适用于哪些场景?
1)领域专业化
- 医疗:微调后的模型可理解医学论文、生成诊断建议。
- 法律:准确引用法律条文,避免生成错误解释。
2)任务适配
- 文本分类:将生成模型转为情感分析工具(输出正面/负面标签)。
- 代码生成:训练模型遵循企业内部的编程规范和API调用规则。
3)风格控制
- 模仿特定作者的写作风格(如鲁迅的文风、科技博客的简洁性)。
- 生成符合品牌调性的营销文案(如正式、幽默、口语化)。
4)安全对齐
- 过滤有害内容,避免模型生成暴力、偏见或虚假信息。
- 确保输出符合伦理规范(如医疗建议需标注“非专业诊断”)。
3.有哪些微调的方法 ?
1)是模型供应商提供了商业模型的在线微调能力,比如 OpenAI 的 GPT 3.5 等模型就支持在线微调。这种模式是基于商业大模型的微调,因此微调后模型还是商业大模型,我们去使用时依然要按 token 付费。
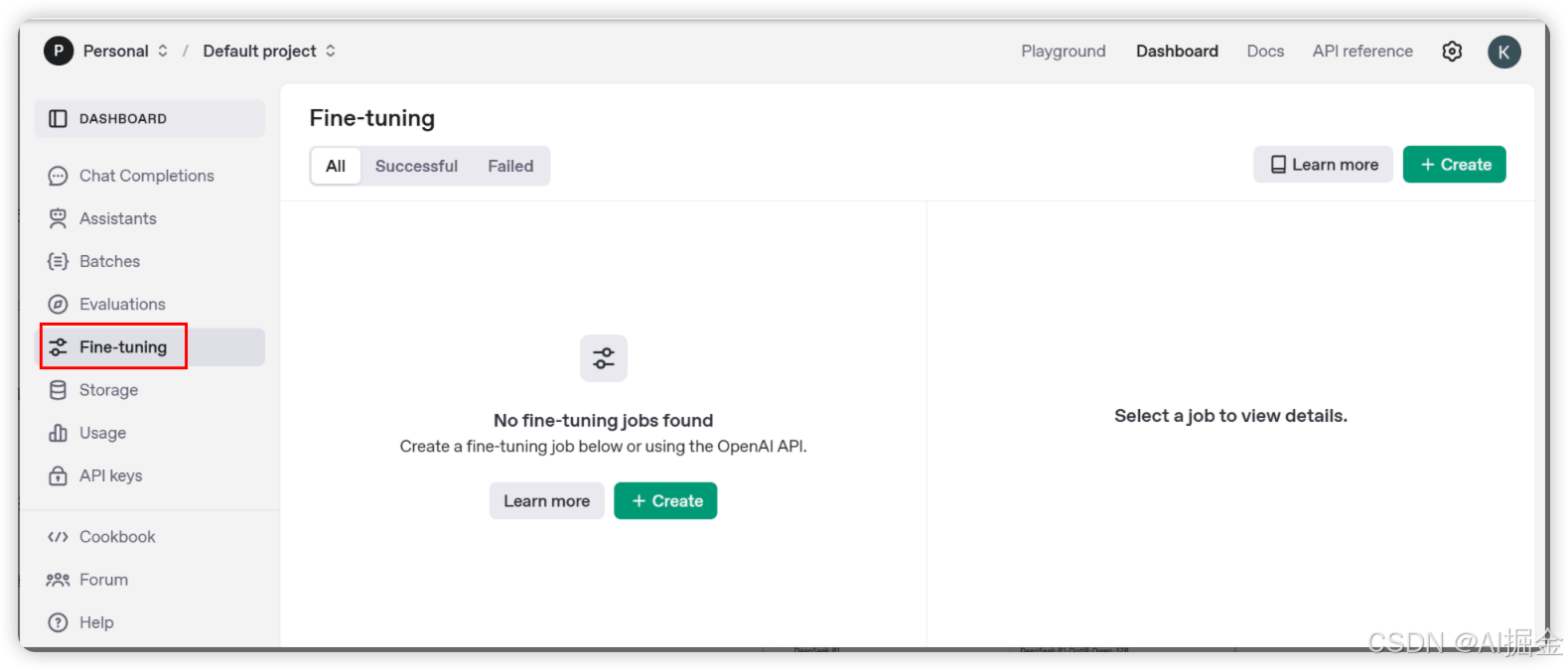
2) 云厂商做的一些模型在线部署、微调平台。比如阿里云的"阿里云百炼",就具备模型的部署和训练功能。这种模式我们只需要租用云厂商的 GPU 算力即可。这些模型部署训练功能都是云厂商为了卖卡或大模型 而推出的增值服务。
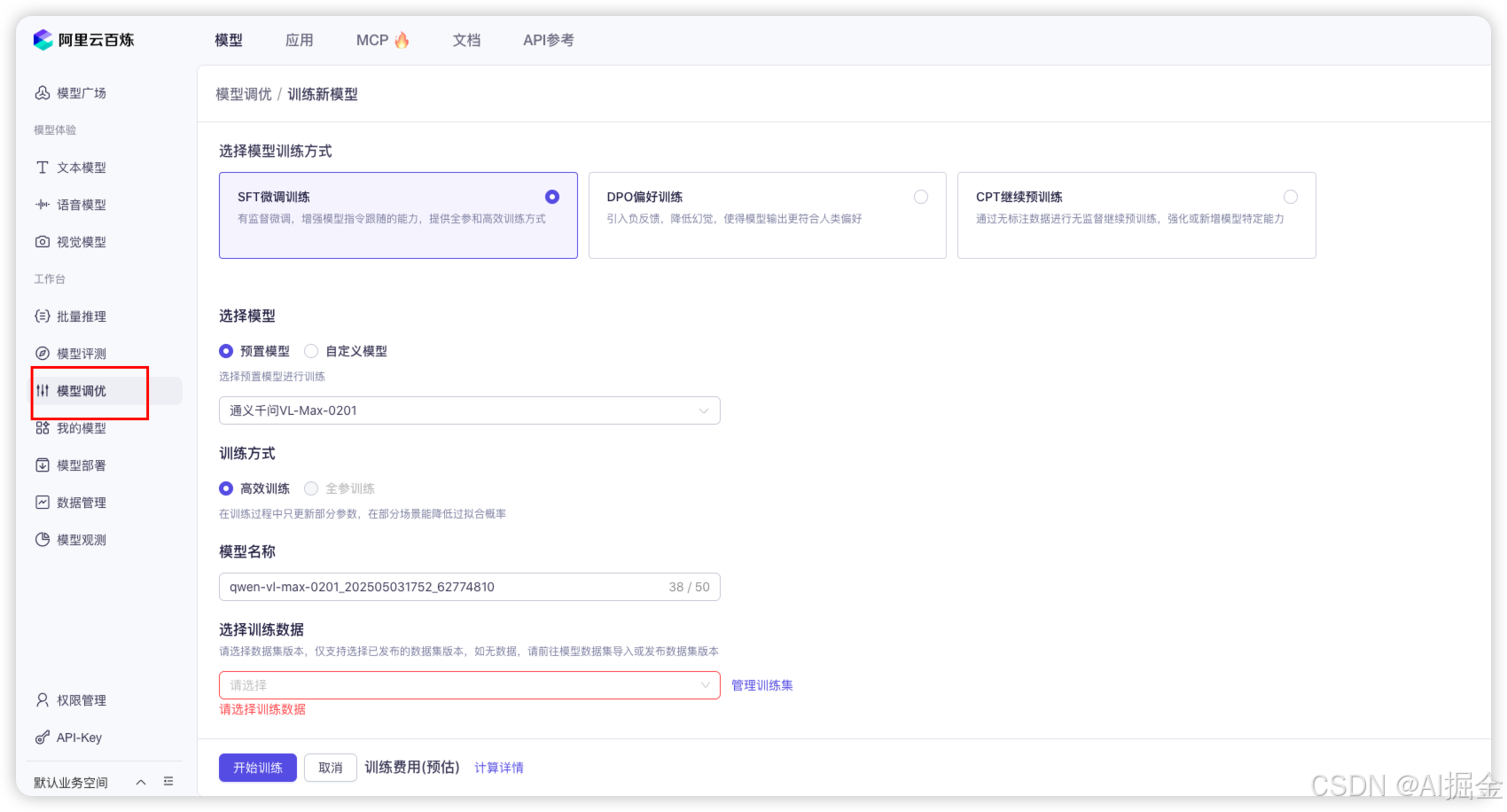
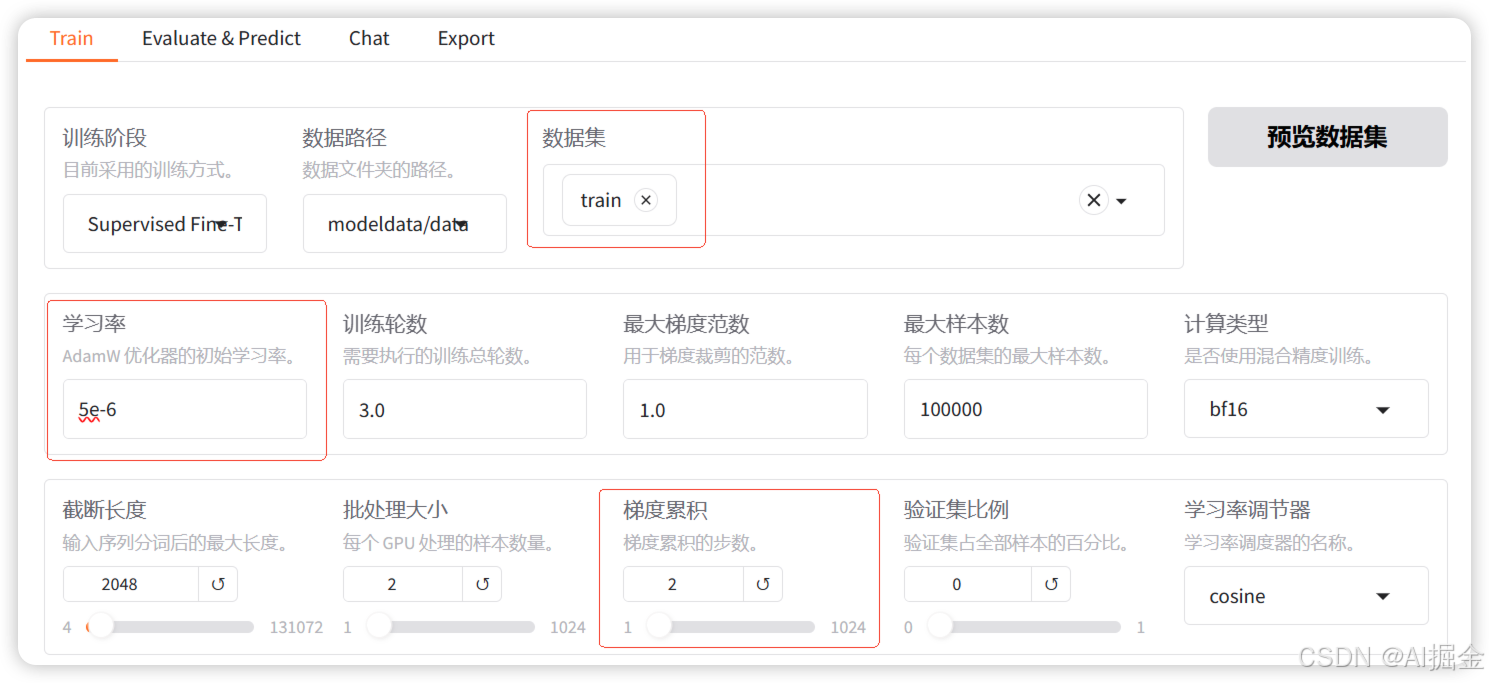
3)如果你或你的公司手里有足够的卡,希望完全本地私有化部署和微调,此时就可以使用一些开源方案,部署一个微调平台来进行模型微调。
比如:目前开源社区非常火的一站式微调和评估平台–LLama-factory。
LLama-factory 是一款整合了主流的各种高效训练微调技术,适配市场主流开源模型,而形成的一个功能丰富、适配性好的训练框架。LLama-factory 提供了多个高层次抽象的调用接口,包含多阶段训练、推理测试、benchmark 评测、API Server 等,使开发者开箱即用。同时提供了网页版工作台,方便初学者迅速上手操作,开发出自己的第一个模型。
4.微调vs预训练
- 预训练(Pre-training)
LLM 最初通过海量通用文本(如书籍、网页)进行训练,学习语言的通用规律(语法、语义、常识)。
目标:掌握“通用语言能力”,例如续写文本、回答问题。
- 微调(Fine-tuning)
在预训练模型的基础上,用特定数据(如医疗报告、法律文书、客服对话)进一步训练,调整模型参数。
目标:让模型从“通才”变为“专才”,适配特定任务或领域。
5. 微调vs其它技术
