day 11 超参数调整
一、内参与外参(超参数)
内参是模型为了适应训练数据而自动调整的,是模型内部与训练数据紧密相关的因素,不同的训练数据会导致模型学习到不同的参数值,这些参数在模型训练完成后就固定下来。
超参数是在模型训练前需要人为设定的参数,比如决策树模型中的最大深度,一个叶节点的最小样本数等,这些参数控制着模型的结构、训练过程以及学习方式,合适的超参数可以让模型更好的拟合数据,提高泛化能力。超参数不依赖于具体的训练数据实例,但是会影响模型对训练数据的学习效果,通常需要一些技巧,如网格搜索、随机搜索、交叉验证等方法。
模型 = 算法 + 实例化设置的外参(超参数)+训练得到的内参
二、调参方法
调参可以分成 2 步,第一步调参来找到每个模型综合性能最好的参数,对比选出最好的模型, 第二部再根据最好的模型来调整阈值。
网格搜索(GridSearch):
网格搜索是对用户指定的多个参数的所有组合进行遍历搜索。例如,对于一个有两个超参数 param1 和 param2 的模型,param1 有 [a, b, c] 三种取值,param2 有 [x, y] 两种取值,网格搜索会对 (a, x)、(a, y)、(b, x)、(b, y)、(c, x)、(c, y) 这六种参数组合都进行尝试,找到的是局部最优解。
调参过程:定义模型→定义参数网格(每个点对应一组参数取值)→初始化网格搜索→训练集进行网格搜索,输出最佳参数→使用最佳参数训练模型 →在测试集上进行预测,计算准确率
贝叶斯优化:
用已有的参数 - 性能数据,不断更新对目标函数的认知,在考虑各种参数组合使目标函数变好可能性(概率)的基础上,平衡探索新参数和利用已知好参数,逐步找到最优参数组合,比网格搜索更高效,尤其在参数空间较大时,能快速收敛到较优解。
朴素贝叶斯模型:
就是基于贝叶斯原理,利用训练集中已知的标签结果,去计算样本在具有某些特征值时属于不同类别的概率大小 。
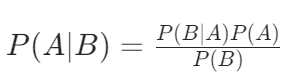
随机搜索:
从参数空间中随机选择一定数量的参数组合进行实验。例如,在一个较大的参数空间中,随机抽取 100 组参数组合来训练模型并用交叉验证评估性能,然后从这 100 个结果中选择最优的参数组合。相比暴力搜索,随机搜索计算效率更高,能在较短时间内探索较大的参数空间。但由于是随机采样,不能保证找到真正的全局最优解,只是有较大概率找到接近全局最优的解。
调参过程的局限性:
调参范围有限:在调参时,我们通常会根据经验设定一个参数搜索范围。但这个范围可能没有包含真正能使模型在所有数据上都达到最佳性能的参数值。例如,在调整决策树的最大深度参数时,设定搜索范围是 1 到 10,可能真正最优的深度是 15,由于没有在这个范围内搜索,导致选出的参数不是全局最优,在测试集上不能发挥最佳性能。
调参方法的误差:调参方法本身可能存在一定误差。例如使用网格搜索方法调参,它是在给定的参数网格点上进行搜索,找到验证集上表现最好的参数组合。但这种离散的搜索方式可能无法精确找到全局最优解,只是在网格点中找到相对较好的参数,这就可能导致在测试集上的结果不如预期。
三、为什么划分验证集?
若验证集与训练集题目类型高度相似,模型在验证集表现好,可能只是记住了特定题型解法,产生 “模型有效” 的假象(即过拟合)。当测试集加入线性代数这类全新内容,模型因未在训练和验证阶段接触相关题型,无法将已有知识迁移应用,导致表现不佳,体现出模型缺乏泛化能力。
训练集用于训练模型,验证集用于在模型训练过程中调整超参数,测试集用于评估模型最终的泛化性能(泛化能力指的是模型对未见过的数据进行准确预测的能力)。
四、有无办法不划分验证集也能避免偶然性?
交叉验证(cross val):
目的:是为了让评估指标变得更可信(可能因划分方式的随机性,导致验证集不能很好地代表整体数据特征,它与最终的测试集无关)。
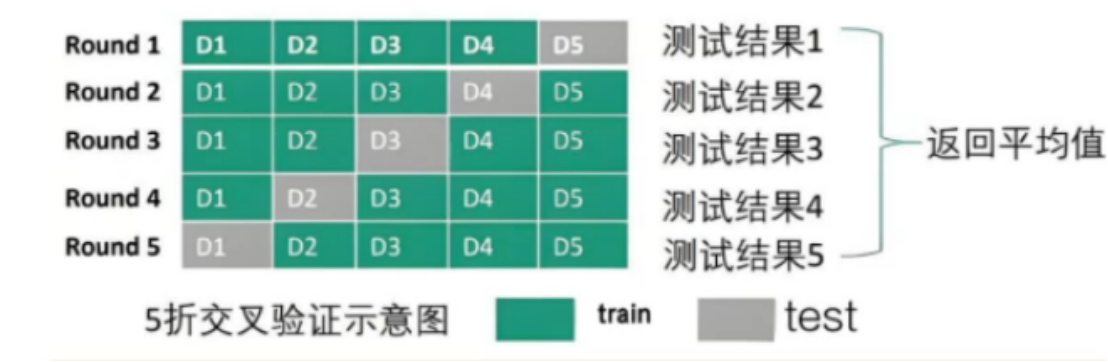
过程:n折交叉验证需要n倍的时间。交叉验证过程中,将数据集分成多个子集,多次训练和评估模型。每次使用不同子集作为训练集和测试集,得到一组性能指标(如准确率、召回率等),然后计算这些指标的平均值,能反映模型在不同数据划分下的平均表现。
例如在 5 折交叉验证中,模型在 5 个不同的数据子集组合上进行训练和测试,最终得到的准确率平均值,能让我们了解模型在整体数据集上相对稳定的性能水平,一定程度上体现了模型的泛化能力,即对新数据的适应能力。
交叉验证的 K 折划分是将数据集无重叠地分成 K 个子集,每次训练和测试使用不同的 K - 1 折训练集和 1 折测试集组合,其重点在于全面地用不同数据部分评估模型。

验证过程:定义模型(使用默认参数)→进行n折交叉验证→输出每折准确率→输出平均准确率
所以如果不做交叉验证,就需要划分验证集和测试集,但是很多调参方法中都默认有交叉验证,所以实际中可以省去划分验证集和测试集的步骤。
五、基准模型
基准模型是在特定任务或数据集上,选择的一个相对简单、易于理解和实现的模型。它代表了在该任务上的一种基础性能水平。比如在预测房价的回归任务里,简单的线性回归模型可以充当基准模型;或者首先运行一个使用默认参数的 RandomForestClassifier,记录其性能作为比较的基准。
作用:
将新模型与基准模型对比,能清晰看出新模型是否取得了真正的进步。例如,研究一种新的深度学习架构用于手写数字识别,通过与传统的 K - 近邻算法(基准模型)对比准确率,判断新架构是否有效。
通过基准模型在数据集上的表现,可以初步了解该数据集的难度。如果基准模型表现很差,说明数据集可能具有高度复杂性,或者数据存在噪声、标注错误等问题。比如在一个文本情感分类任务中,简单的朴素贝叶斯基准模型准确率很低,这就暗示数据集的文本特征可能复杂多变,或者标注质量有待提高。
在探索多种模型解决问题时,先建立基准模型可以快速获得一个基础性能,避免一开始就投入大量时间和资源到复杂模型中。如果复杂模型提升效果不明显,就可以考虑调整策略,而不是盲目追求模型复杂度。例如,在尝试用深度神经网络解决一个问题前,先使用简单的决策树模型作为基准,若决策树已能满足需求,就无需再耗费资源搭建复杂的神经网络。
六、整个流程
预处理代码:
import pandas as pd
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
#随机森林分类器
from sklearn.ensemble import RandomForestClassifier
# 用于评估分类器性能的指标
from sklearn.metrics import accuracy_score, precision_score, recall_score, f1_score
#用于生成分类报告和混淆矩阵
from sklearn.metrics import classification_report, confusion_matrix
#用于忽略警告信息
import warnings
warnings.filterwarnings("ignore") # 设置中文字体(解决中文显示问题)
plt.rcParams['font.sans-serif'] = ['SimHei']
# 正常显示负号
plt.rcParams['axes.unicode_minus'] = False
data = pd.read_csv('data.csv') # 先筛选字符串变量
discrete_features = data.select_dtypes(include=['object']).columns.tolist()# Home Ownership 标签编码
home_ownership_mapping = {'Own Home': 1,'Rent': 2,'Have Mortgage': 3,'Home Mortgage': 4
}
data['Home Ownership'] = data['Home Ownership'].map(home_ownership_mapping)# Years in current job 标签编码
years_in_job_mapping = {'< 1 year': 1,'1 year': 2,'2 years': 3,'3 years': 4,'4 years': 5,'5 years': 6,'6 years': 7,'7 years': 8,'8 years': 9,'9 years': 10,'10+ years': 11
}
data['Years in current job'] = data['Years in current job'].map(years_in_job_mapping)# Purpose 独热编码
data = pd.get_dummies(data, columns=['Purpose'])
# 重新读取数据,用来做列名对比
data2 = pd.read_csv("data.csv")
# 新建一个空列表,用于存放独热编码后新增的特征名
list_final = []
# 这里打印出来的就是独热编码后的特征名
for i in data.columns:if i not in data2.columns:list_final.append(i)
# 将bool类型转换为数值
for i in list_final:data[i] = data[i].astype(int) # Term 0 - 1 映射
term_mapping = {'Short Term': 0,'Long Term': 1
}
data['Term'] = data['Term'].map(term_mapping)
data.rename(columns={'Term': 'Long Term'}, inplace=True)
continuous_features = data.select_dtypes(include=['int64', 'float64']).columns.tolist() # 连续特征用众数补全
for feature in continuous_features: mode_value = data[feature].mode()[0] data[feature].fillna(mode_value, inplace=True)
划分训练集、验证集和测试集 :
# train_test_split函数只能划分一次,需要调用两次。
from sklearn.model_selection import train_test_split
# 提取特征与标签
X = data.drop(['Credit Default'], axis=1)
y = data['Credit Default']
# 按照8:2划分训练集与临时集
X_train, X_temp, y_train, y_temp = train_test_split(X, y, test_size=0.2, random_state=42)
# 将临时数据集的50%作为测试集,最终按8:1:1的比例划分为训练集、验证集和测试集
X_val, X_test, y_val, y_test = train_test_split(X_temp, y_temp, test_size=0.5, random_state=42)
# 查看划分后的结构
print("Data shapes:")
print("X_train:", X_train.shape)
print("y_train:", y_train.shape)
print("X_val:", X_val.shape)
print("y_val:", y_val.shape)
print("X_test:", X_test.shape)
print("y_test:", y_test.shape)
# 输出:
Data shapes:
X_train: (6000, 31)
y_train: (6000,)
X_val: (750, 31)
y_val: (750,)
X_test: (750, 31)
y_test: (750,)评估基准模型:
# 默认参数的随机森林
print("--- 1. 默认参数随机森林 (训练集 -> 测试集) ---")
# 记录调参时长
import time
# 记录开始时间
start_time = time.time()
rf_model = RandomForestClassifier(random_state=42)
rf_model.fit(X_train, y_train)
rf_pred = rf_model.predict(X_test)
# 记录结束时间
end_time = time.time() print(f"训练与预测耗时: {end_time - start_time:.4f} 秒")
print("\n默认随机森林 在测试集上的分类报告:")
print(classification_report(y_test, rf_pred))
print("默认随机森林 在测试集上的混淆矩阵:")
print(confusion_matrix(y_test, rf_pred))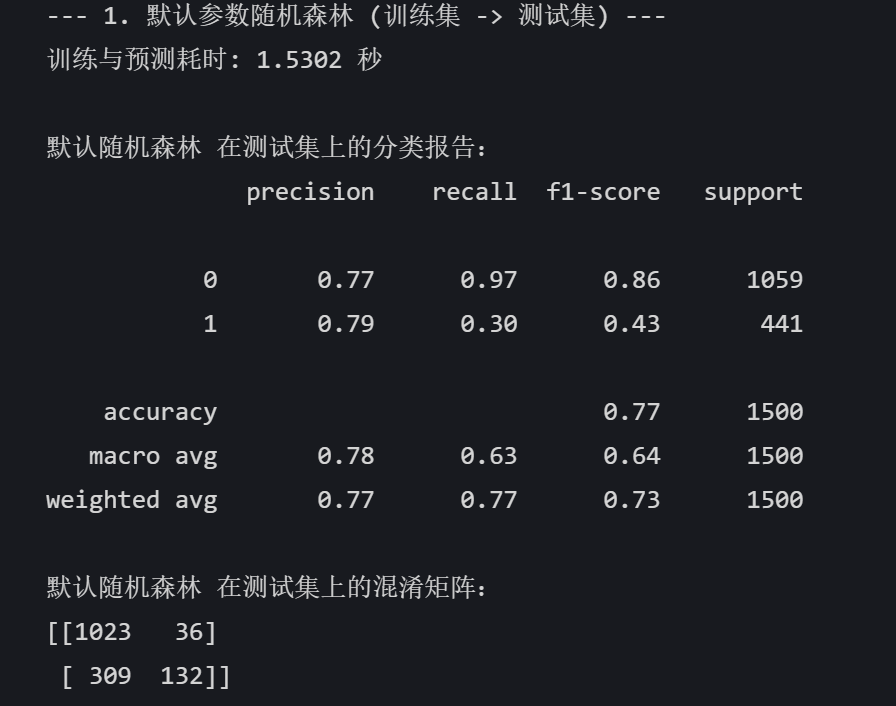
网格搜索:
print("\n--- 2. 网格搜索优化随机森林 (训练集 -> 测试集) ---")
from sklearn.model_selection import GridSearchCV# 定义要搜索的参数网格
param_grid = {'n_estimators': [50, 100, 200], # 集成模型中树的数量'max_depth': [None, 10, 20, 30], # 每棵树的最大深度,限制树的复杂度,防止过拟合'min_samples_split': [2, 5, 10], # 在树的节点上进行划分时,所需的最小样本数'min_samples_leaf': [1, 2, 4] # 一个叶节点所需的最小样本数
}# 创建网格搜索对象
grid_search = GridSearchCV(estimator=RandomForestClassifier(random_state=42), # 随机森林分类器param_grid=param_grid, # 参数网格cv=5, # 5折交叉验证n_jobs=-1, # 使用所有可用的CPU核心进行并行计算scoring='accuracy') # 使用准确率作为评分标准# 在训练集上进行网格搜索(模型实例化和训练的方法都被封装在这个网格搜索对象里了)
start_time = time.time()
grid_search.fit(X_train, y_train)
end_time = time.time()print(f"网格搜索耗时: {end_time - start_time:.4f} 秒")
print("最佳参数: ", grid_search.best_params_)
# 使用最佳参数的模型进行预测
best_model = grid_search.best_estimator_
best_pred = best_model.predict(X_test) print("\n网格搜索优化后的随机森林 在测试集上的分类报告:")
print(classification_report(y_test, best_pred))
print("网格搜索优化后的随机森林 在测试集上的混淆矩阵:")
print(confusion_matrix(y_test, best_pred))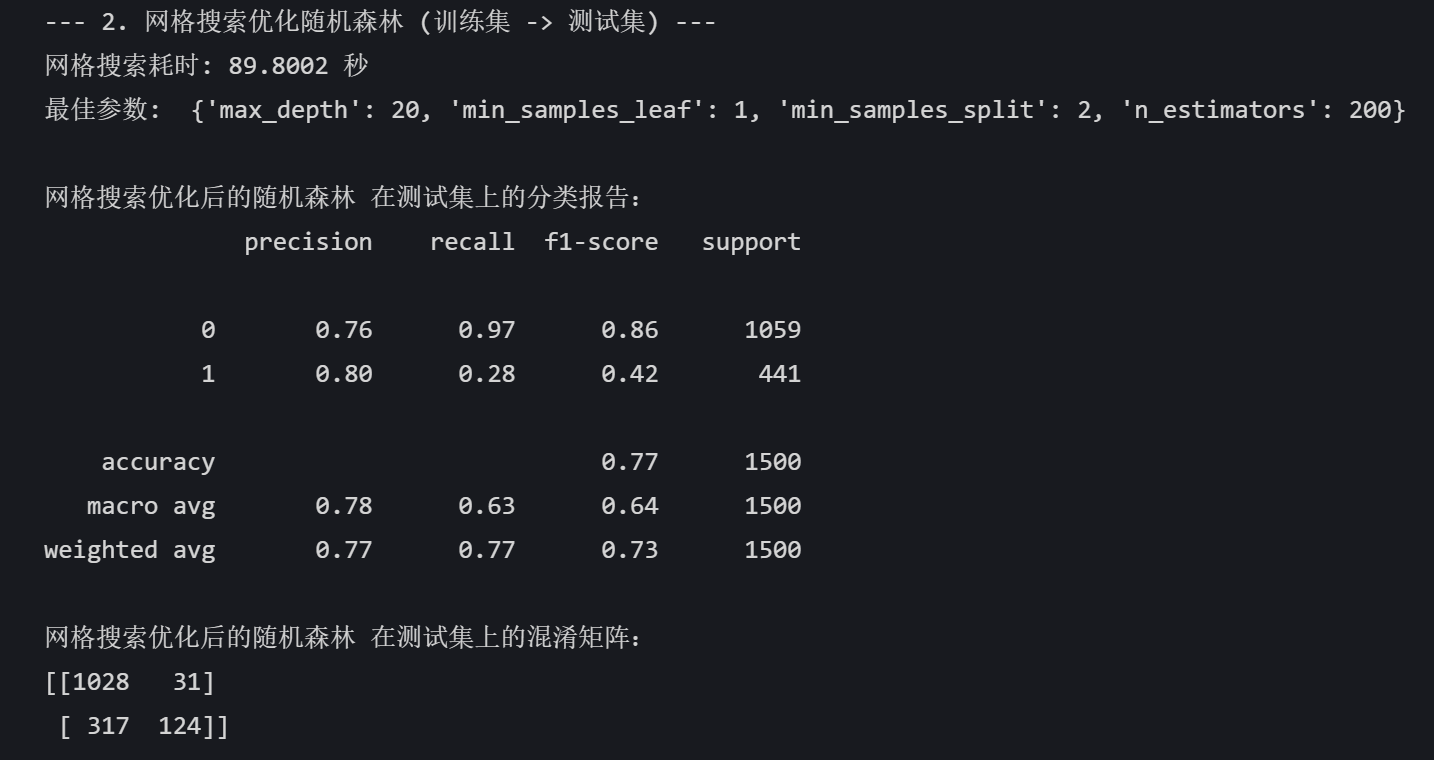
贝叶斯优化简单方法:
准备工作:贝叶斯优化需要安装scikit-optimize这个库(在Anaconda Prompt中)
pip install scikit-optimize -i https://pypi.tuna.tsinghua.edu.cn/simple
print("\n--- 3. 贝叶斯优化随机森林 (训练集 -> 测试集) ---")
from skopt import BayesSearchCV
from skopt.space import Integer
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import classification_report, confusion_matrix
import time# 定义要搜索的参数空间
search_space = {'n_estimators': Integer(50, 200),'max_depth': Integer(10, 30),'min_samples_split': Integer(2, 10),'min_samples_leaf': Integer(1, 4)
}# 创建贝叶斯优化搜索对象
bayes_search = BayesSearchCV(estimator=RandomForestClassifier(random_state=42),search_spaces=search_space, # 超参数搜索空间n_iter=32, # 迭代次数,可根据需要调整cv=5, # 5折交叉验证,这个参数是必须的n_jobs=-1, # 设置为 -1 表示使用所有可用的 CPU 核心进行并行计算scoring='accuracy' # 分类问题中常用的评估指标
)# 在训练集上进行贝叶斯优化搜索
start_time = time.time()
bayes_search.fit(X_train, y_train)
end_time = time.time()print(f"贝叶斯优化耗时: {end_time - start_time:.4f} 秒")
print("最佳参数: ", bayes_search.best_params_)# 使用最佳参数的模型进行预测
best_model = bayes_search.best_estimator_
best_pred = best_model.predict(X_test)print("\n贝叶斯优化后的随机森林 在测试集上的分类报告:")
print(classification_report(y_test, best_pred))
print("贝叶斯优化后的随机森林 在测试集上的混淆矩阵:")
print(confusion_matrix(y_test, best_pred))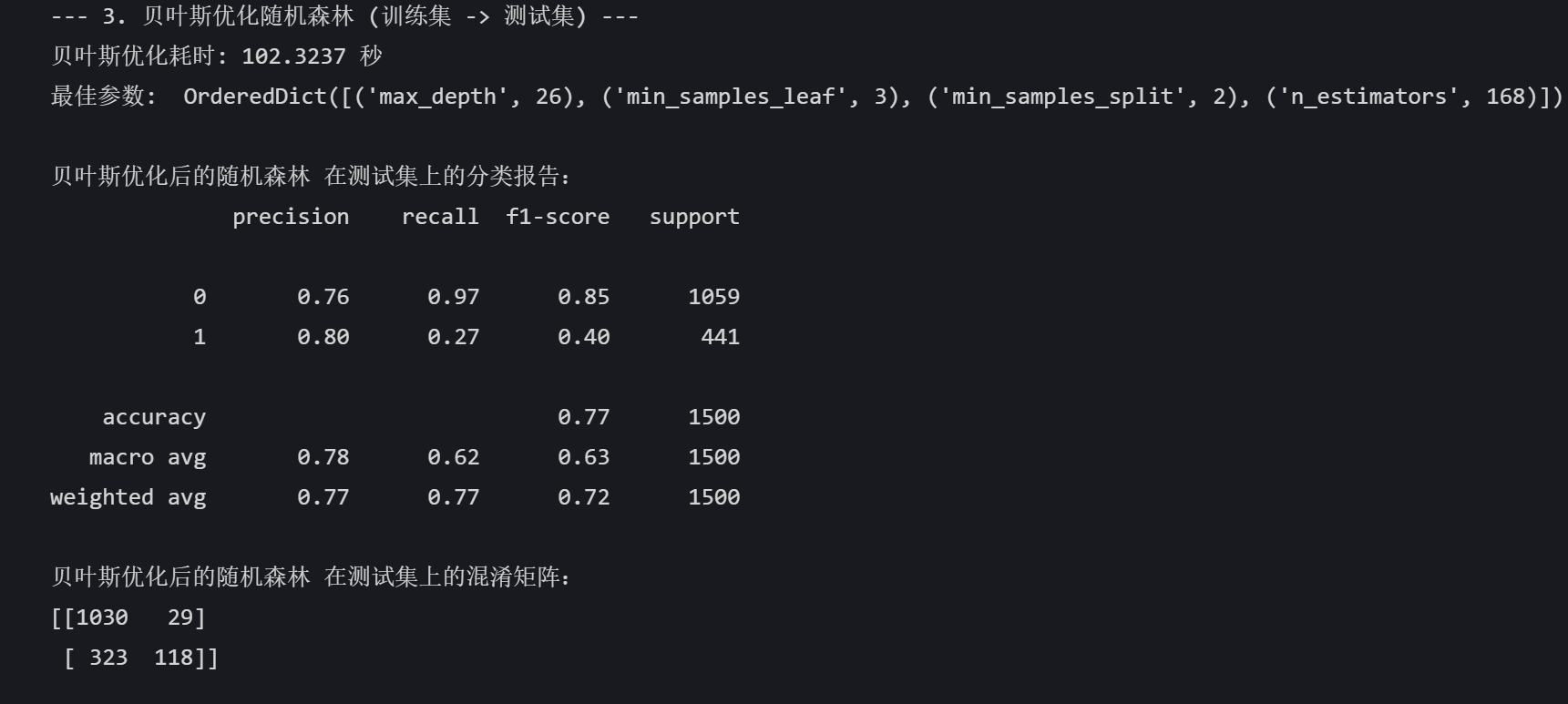
贝叶斯优化另一方法:
上面的代码比较简洁美观,和网格搜索的代码书写风格高度一致。下面介绍一种贝叶斯优化方法的其他实现代码,它允许用户自定义目标函数,像通过 rf_eval 函数定义基于随机森林超参数计算交叉验证平均准确率的目标函数,极大增强了适配不同任务与评估标准的能力。同时,可不依赖交叉验证,只需修改评估指标即可,为用户提供更自由的评估途径。此外,借助 verbose 参数,设置后能输出中间过程信息,便于了解优化进展,监测算法是否正常收敛。
# 导入必要的库
print("\n--- 4. 贝叶斯优化随机森林 (训练集 -> 测试集) ---")
from bayes_opt import BayesianOptimization
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import cross_val_score
from sklearn.metrics import classification_report, confusion_matrix
import time
import numpy as np# 定义目标函数 rf_eval
def rf_eval(n_estimators, max_depth, min_samples_split, min_samples_leaf):
# 将传入的超参数转换为整数类型,因为贝叶斯优化可能会传入浮点数n_estimators = int(n_estimators)max_depth = int(max_depth)min_samples_split = int(min_samples_split)min_samples_leaf = int(min_samples_leaf)
# 使用传入的超参数初始化一个随机森林分类器model = RandomForestClassifier(n_estimators=n_estimators,max_depth=max_depth,min_samples_split=min_samples_split,min_samples_leaf=min_samples_leaf,random_state=42)
# 对模型进行5折交叉验证,以准确率作为评估指标,返回平均值scores = cross_val_score(model, X_train, y_train, cv=5, scoring='accuracy')return np.mean(scores)# 定义参数搜索空间 pbounds_rf
pbounds_rf = {'n_estimators': (50, 200),'max_depth': (10, 30),'min_samples_split': (2, 10),'min_samples_leaf': (1, 4)
}# 创建贝叶斯优化对象 optimizer_rf
optimizer_rf = BayesianOptimization(f=rf_eval, # 指定目标函数,即贝叶斯优化要最大化的函数。 pbounds=pbounds_rf, # 指定超参数的搜索空间random_state=42,verbose=2 # 设置详细程度,2 表示在每次迭代时打印详细信息,包括超参数组合和目标函数值。
)# 运行贝叶斯优化
start_time = time.time()
optimizer_rf.maximize(init_points=5, # 开始优化前,先随机采样 5 组超参数进行评估,这些样本点用于初始化概率模型。n_iter=32 # 在每次迭代中,根据之前的结果选择一组新的超参数进行评估。
)
end_time = time.time()
print(f"贝叶斯优化耗时: {end_time - start_time:.4f} 秒")
print("最佳参数: ", optimizer_rf.max['params'])# 使用最佳参数进行预测与评估
best_params = optimizer_rf.max['params']
# 使用最佳超参数初始化一个新的随机森林分类器 best_model。
best_model = RandomForestClassifier(n_estimators=int(best_params['n_estimators']),max_depth=int(best_params['max_depth']),min_samples_split=int(best_params['min_samples_split']),min_samples_leaf=int(best_params['min_samples_leaf']),random_state=42
)
best_model.fit(X_train, y_train)
best_pred = best_model.predict(X_test)print("\n贝叶斯优化后的随机森林 在测试集上的分类报告:")
print(classification_report(y_test, best_pred))
print("贝叶斯优化后的随机森林 在测试集上的混淆矩阵:")
print(confusion_matrix(y_test, best_pred))@浙大疏锦行