ALiBi (Attention with Linear Biases) 优化LLM 模型注意力
概述
ALiBi 是什么?
ALiBi (Attention with Linear Biases) 是一种注意力机制优化技术,最初在论文《Train Short, Test Long: Attention with Linear Biases Enables Input Length Extrapolation》(2022)中提出。
https://arxiv.org/pdf/2108.12409![]() https://arxiv.org/pdf/2108.12409它通过在 Transformer 的注意力机制中引入线性偏置,取代传统的基于绝对位置嵌入(Positional Embedding)的编码方式,从而提高模型对长序列的泛化能力。使用线性形式的偏置,使得不同位置之间的关系可以通过简单的线性函数建模。这种方式不仅简化了位置编码的复杂性,还提高了模型的灵活性。也因为 ALiBi 不需要显式地计算每个位置的偏置,特别是在长序列中,其计算效率更高,能够在资源有限的情况下处理更长的输入。
https://arxiv.org/pdf/2108.12409它通过在 Transformer 的注意力机制中引入线性偏置,取代传统的基于绝对位置嵌入(Positional Embedding)的编码方式,从而提高模型对长序列的泛化能力。使用线性形式的偏置,使得不同位置之间的关系可以通过简单的线性函数建模。这种方式不仅简化了位置编码的复杂性,还提高了模型的灵活性。也因为 ALiBi 不需要显式地计算每个位置的偏置,特别是在长序列中,其计算效率更高,能够在资源有限的情况下处理更长的输入。
核心思想
- 传统 Transformer(如 BERT、GPT)使用固定的位置嵌入(例如正弦函数或可学习的嵌入),这些嵌入在训练时针对固定长度优化,难以泛化到更长的序列。
- ALiBi 在注意力计算时,直接为每个 token 对的注意力分数添加一个线性偏置,偏置值与 token 间的相对距离成比例:
-
对于 token 位置 iii 和 jjj,注意力分数为:
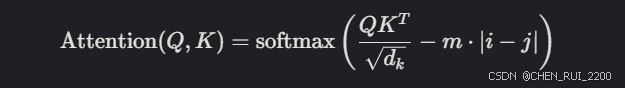
其中 m 是一个固定的斜率(通常与注意力头索引相关),∣i−j∣ |i - j| ∣i−j∣ 是 token 间的距离。偏置值随距离线性递减,鼓励模型更关注靠近的 token。可以用较短的序列(例如 512 或 1024 token)训练模型,节省内存和计算资源。只在注意力计算时添加偏置,计算开销小。
同时 ALiBi 是一种同时应用于训练阶段和推理阶段的技术而不仅仅局限于训练。
1. 训练阶段
在训练时,ALiBi 修改注意力机制,通过线性偏置引导模型学习 token 间的相对位置关系。由于偏置基于相对距离(而非绝对位置),模型对序列长度的依赖减少,训练时无需为不同长度准备多种位置嵌入。
- 优势:
- 短序列训练:可以用较短的序列(例如 512 或 1024 token)训练模型,节省内存和计算资源。
- 泛化能力:训练中学习的注意力模式可泛化到更长序列,适合大模型(比方说我经常用的 32B 参数模型)。在 Transformer 的注意力层中,直接修改 softmax 输入,添加线性偏
def alibi_attention(query, key, value, num_heads):# 获取输入的序列长度(query 的序列长度)seq_len = query.size(1)# 获取每个头的维度(即每个头中元素的数量)head_dim = query.size(-1)# 计算斜率,生成一个大小为 (num_heads,) 的张量# 斜率为 2 的负指数形式,用于调整注意力的影响slopes = torch.tensor([2**(-(i+1)) for i in range(num_heads)], device=query.device)# 创建位置索引张量,范围从 0 到 seq_len-1,并增加一个维度positions = torch.arange(seq_len, device=query.device).unsqueeze(0) # 形状为 (1, seq_len)# 计算偏置项,使用斜率和位置差的绝对值# biases 的形状为 (num_heads, seq_len, seq_len)# 计算每一对位置之间的偏置biases = -slopes.view(-1, 1, 1) * torch.abs(positions.unsqueeze(-1) - positions)# 计算注意力得分,使用查询向量与键向量的点积# 将得分除以 sqrt(head_dim) 以进行缩放(避免数值过大)attn_scores = torch.matmul(query, key.transpose(-1, -2)) / (head_dim ** 0.5)# 将偏置项添加到注意力得分中attn_scores = attn_scores + biases# 对注意力得分进行 softmax 操作以获得注意力权重# 这里的 softmax 是在最后一个维度上进行的attn_weights = torch.softmax(attn_scores, dim=-1)# 计算最终的注意力输出,通过将注意力权重与值向量相乘return torch.matmul(attn_weights, value)2 推理阶段
- 在推理时,ALiBi 的线性偏置机制仍然生效,允许模型处理比训练时更长的序列。例如,训练时用 512 token,推理时可直接处理 4096 token,甚至更长,而无需额外的微调或修改。
- 推理时支持超长对话或文档处理,适合你的技术支持机器人场景(多轮长对话)。无需为长序列存储大量位置嵌入,降低内存占用。
优化文本输出
设计与修改
参考我之前使用minimind 进行LLM 训练
Minimind 训练一个自己专属语言模型_query-utterance pair-CSDN博客文章浏览阅读1.7k次,点赞39次,收藏13次。发现了一个宝藏项目, 宣传是完全从0开始,仅用3块钱成本 + 2小时!即可训练出仅为25.8M的超小语言模型最小版本体积是 GPT-3 的 17000,做到最普通的个人GPU也可快速训练trlpeft训练数据集下载地址创建./dataset目录, 存放训练数据集,该里清洗出字符<512长度的大约1.6GB的语料直接拼接而成关于“, 它是一个完整、格式统一、安全的大模型训练和研究资源。_query-utterance pairhttps://blog.csdn.net/u011564831/article/details/146912785?spm=1011.2415.3001.5331
模型里注意力部分,原始的注意力是这样的
class Attention(nn.Module):def __init__(self, args: LMConfig):super().__init__()self.n_kv_heads = args.n_heads if args.n_kv_heads is None else args.n_kv_headsassert args.n_heads % self.n_kv_heads == 0self.n_local_heads = args.n_headsself.n_local_kv_heads = self.n_kv_headsself.n_rep = self.n_local_heads // self.n_local_kv_headsself.head_dim = args.dim // args.n_headsself.wq = nn.Linear(args.dim, args.n_heads * self.head_dim, bias=False)self.wk = nn.Linear(args.dim, self.n_kv_heads * self.head_dim, bias=False)self.wv = nn.Linear(args.dim, self.n_kv_heads * self.head_dim, bias=False)self.wo = nn.Linear(args.n_heads * self.head_dim, args.dim, bias=False)self.attn_dropout = nn.Dropout(args.dropout)self.resid_dropout = nn.Dropout(args.dropout)self.dropout = args.dropoutself.flash = hasattr(torch.nn.functional, 'scaled_dot_product_attention') and args.flash_attn# print("WARNING: using slow attention. Flash Attention requires PyTorch >= 2.0")mask = torch.full((1, 1, args.max_seq_len, args.max_seq_len), float("-inf"))mask = torch.triu(mask, diagonal=1)self.register_buffer("mask", mask, persistent=False)def forward(self,x: torch.Tensor,pos_cis: torch.Tensor,past_key_value: Optional[Tuple[torch.Tensor, torch.Tensor]] = None,use_cache=False):bsz, seq_len, _ = x.shapexq, xk, xv = self.wq(x), self.wk(x), self.wv(x)xq = xq.view(bsz, seq_len, self.n_local_heads, self.head_dim)xk = xk.view(bsz, seq_len, self.n_local_kv_heads, self.head_dim)xv = xv.view(bsz, seq_len, self.n_local_kv_heads, self.head_dim)xq, xk = apply_rotary_emb(xq, xk, pos_cis)# kv_cache实现if past_key_value is not None:xk = torch.cat([past_key_value[0], xk], dim=1)xv = torch.cat([past_key_value[1], xv], dim=1)past_kv = (xk, xv) if use_cache else Nonexq, xk, xv = (xq.transpose(1, 2),repeat_kv(xk, self.n_rep).transpose(1, 2),repeat_kv(xv, self.n_rep).transpose(1, 2))if self.flash and seq_len != 1:dropout_p = self.dropout if self.training else 0.0output = F.scaled_dot_product_attention(xq, xk, xv,attn_mask=None,dropout_p=dropout_p,is_causal=True)else:scores = (xq @ xk.transpose(-2, -1)) / math.sqrt(self.head_dim)scores += self.mask[:, :, :seq_len, :seq_len]scores = F.softmax(scores.float(), dim=-1).type_as(xq)scores = self.attn_dropout(scores)output = scores @ xvoutput = output.transpose(1, 2).reshape(bsz, seq_len, -1)output = self.resid_dropout(self.wo(output))return output, past_kv将严格按照原始 Attention 类的参数和结构进行修改,确保 AttentionWithALiBi 可以无缝替换原始类。
修改点分析
- 原始参数接口:
- 原始 Attention 类的 forward 方法接受以下参数:
def forward(self, x: torch.Tensor, pos_cis: torch.Tensor, past_key_value: Optional[Tuple[torch.Tensor, torch.Tensor]] = None, use_cache=False)- pos_cis 是用于RoPE的位置编码张量。
- 修改后的代码移除了 pos_cis 参数,导致接口不兼容。
- 为了确保替换性,AttentionWithALiBi 的 forward 方法必须保留相同的参数签名,即使 pos_cis 在ALiBi中未使用。
- 原始 Attention 类的 forward 方法接受以下参数:
- 功能兼容性:
- 原始代码支持RoPE、因果掩码、Flash Attention、KV缓存和分组注意力(n_kv_heads 和 n_rep)。
- 修改后的代码需要保留这些功能,仅将RoPE和因果掩码替换为ALiBi偏置,同时保持其他逻辑(如 repeat_kv、Flash Attention、KV缓存)不变。
- 结构一致性:
- 原始 Attention 类的初始化和前向传播逻辑高度依赖 args: LMConfig 的属性(如 n_heads, n_kv_heads, dim, max_seq_len, dropout, flash_attn)。
- 修改后的代码必须使用相同的 args 属性,避免引入新依赖。
- 替换问题可能原因:
- pos_cis 参数移除导致调用代码报错(例如,TypeError: forward() missing 1 required positional argument: 'pos_cis')。
- ALiBi偏置矩阵的形状或设备与Flash Attention不兼容。
- 缺少对 apply_rotary_emb 和 repeat_kv 的定义或依赖。
修改目标
- 保留原始接口:forward 方法保持参数一致(x, pos_cis, past_key_value, use_cache),忽略 pos_cis。
- 替换RoPE和掩码:用ALiBi偏置替代 apply_rotary_emb 和 self.mask。
- 保持功能:支持Flash Attention、KV缓存、分组注意力,逻辑与原始代码一致。
- 最小改动:只修改与位置编码相关的部分,避免引入新依赖或改变现有行为。
- 调试支持:添加日志验证ALiBi偏置的正确性。
修改后的注意力代码
class AttentionWithALiBi(nn.Module):def __init__(self, args: LMConfig):super().__init__()self.n_kv_heads = args.n_heads if args.n_kv_heads is None else args.n_kv_headsassert args.n_heads % self.n_kv_heads == 0self.n_local_heads = args.n_headsself.n_local_kv_heads = self.n_kv_headsself.n_rep = self.n_local_heads // self.n_local_kv_headsself.head_dim = args.dim // args.n_headsself.wq = nn.Linear(args.dim, args.n_heads * self.head_dim, bias=False)self.wk = nn.Linear(args.dim, self.n_kv_heads * self.head_dim, bias=False)self.wv = nn.Linear(args.dim, self.n_kv_heads * self.head_dim, bias=False)self.wo = nn.Linear(args.n_heads * self.head_dim, args.dim, bias=False)self.attn_dropout = nn.Dropout(args.dropout)self.resid_dropout = nn.Dropout(args.dropout)self.dropout = args.dropoutself.flash = hasattr(torch.nn.functional, 'scaled_dot_product_attention') and args.flash_attn# ALiBi斜率:为每个头定义一个负斜率self.slopes = torch.tensor([2 ** (-(i + 1)) for i in range(self.n_local_heads)])self.max_seq_len = args.max_seq_lenprint(f"Debug: Initialized AttentionWithALiBi, n_heads={self.n_local_heads}, slopes={self.slopes[:3]}...")def forward(self,x: torch.Tensor,pos_cis: torch.Tensor,past_key_value: Optional[Tuple[torch.Tensor, torch.Tensor]] = None,use_cache: bool = False) -> Tuple[torch.Tensor, Optional[Tuple[torch.Tensor, torch.Tensor]]]:bsz, seq_len, _ = x.shapexq, xk, xv = self.wq(x), self.wk(x), self.wv(x)xq = xq.view(bsz, seq_len, self.n_local_heads, self.head_dim)xk = xk.view(bsz, seq_len, self.n_local_kv_heads, self.head_dim)xv = xv.view(bsz, seq_len, self.n_local_kv_heads, self.head_dim)# KV缓存实现past_len = 0if past_key_value is not None:past_len = past_key_value[0].size(1)xk = torch.cat([past_key_value[0], xk], dim=1)xv = torch.cat([past_key_value[1], xv], dim=1)past_kv = (xk, xv) if use_cache else Nonexq, xk, xv = (xq.transpose(1, 2), # [bsz, n_local_heads, seq_len, head_dim]repeat_kv(xk, self.n_rep).transpose(1, 2),repeat_kv(xv, self.n_rep).transpose(1, 2))# 生成ALiBi偏置total_len = seq_len + past_lenpositions = torch.arange(past_len, total_len, device=x.device).unsqueeze(0) # [1, total_len]relative_distances = torch.abs(positions.unsqueeze(-1) - positions) # [1, total_len, total_len]slopes = self.slopes.to(device=x.device) # 确保斜率在正确设备上biases = -slopes.view(-1, 1, 1) * relative_distances # [n_local_heads, total_len, total_len]biases = biases.unsqueeze(0) # [1, n_local_heads, total_len, total_len]if self.flash and seq_len != 1:dropout_p = self.dropout if self.training else 0.0output = F.scaled_dot_product_attention(xq, xk, xv,attn_mask=biases, # 使用ALiBi偏置dropout_p=dropout_p,is_causal=False # 禁用内置因果掩码)else:scores = (xq @ xk.transpose(-2, -1)) / math.sqrt(self.head_dim) # [bsz, n_local_heads, seq_len, total_len]scores = scores + biases[:, :, -seq_len:, :] # 应用ALiBi偏置scores = F.softmax(scores.float(), dim=-1).type_as(xq)scores = self.attn_dropout(scores)output = scores @ xvoutput = output.transpose(1, 2).reshape(bsz, seq_len, -1)output = self.resid_dropout(self.wo(output))return output, past_kv替换原有的注意力
将MiniMindBlock模型的注意力直接替换为AttentionWithALiBi
class MiniMindBlock(nn.Module):def __init__(self, layer_id: int, config: LMConfig):super().__init__()self.n_heads = config.n_headsself.dim = config.dimself.head_dim = config.dim // config.n_headsself.attention = AttentionWithALiBi(config)self.layer_id = layer_idself.attention_norm = RMSNorm(config.dim, eps=config.norm_eps)self.ffn_norm = RMSNorm(config.dim, eps=config.norm_eps)self.feed_forward = FeedForward(config) if not config.use_moe else MOEFeedForward(config)重新训练
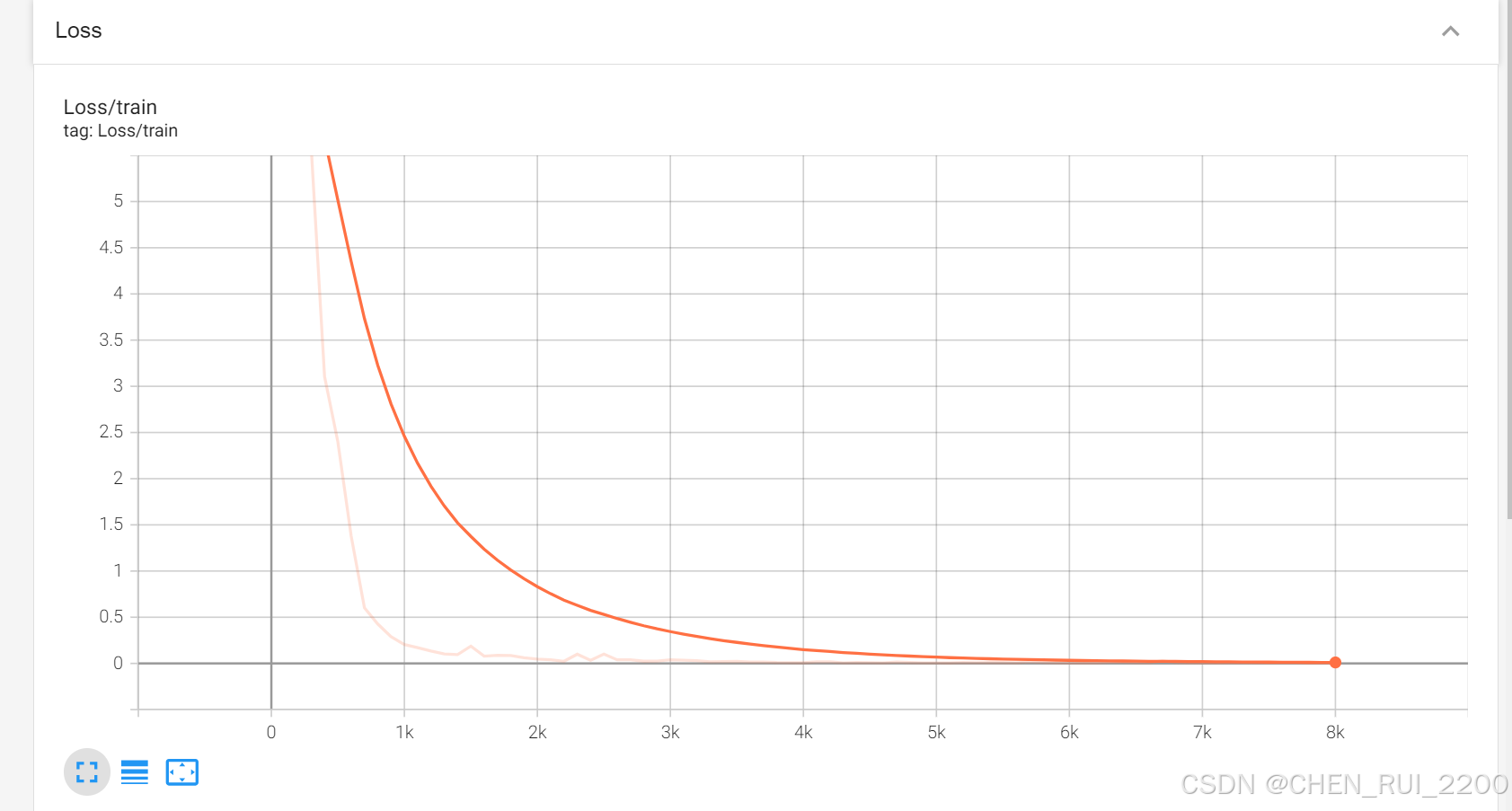
这是使用之前Attention 的损失函数值
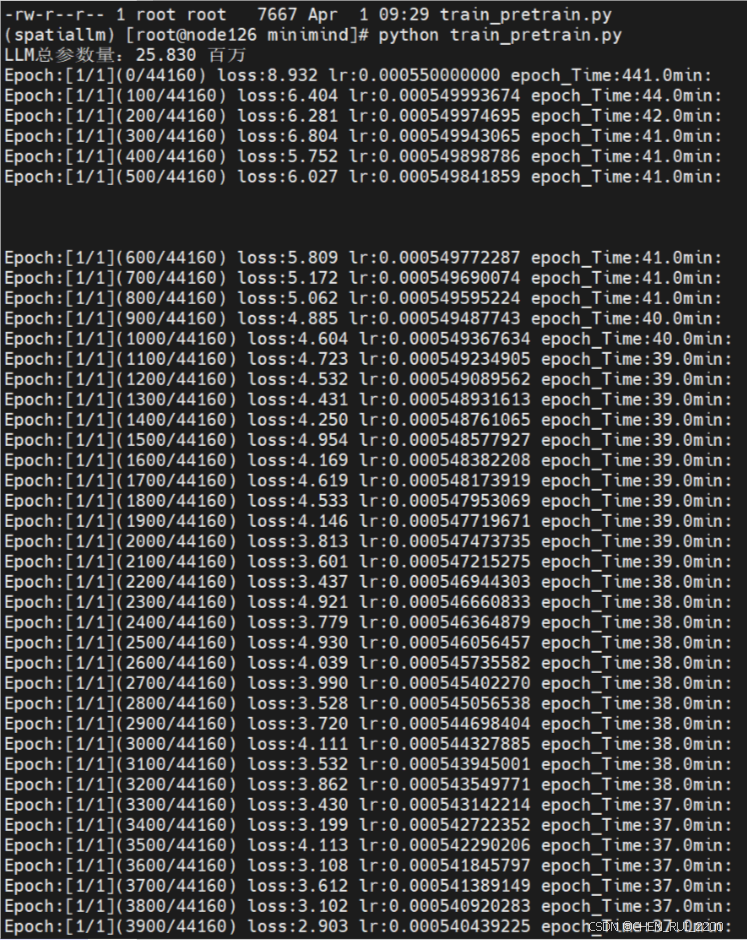
使用修改后的AttentionWithALiBi
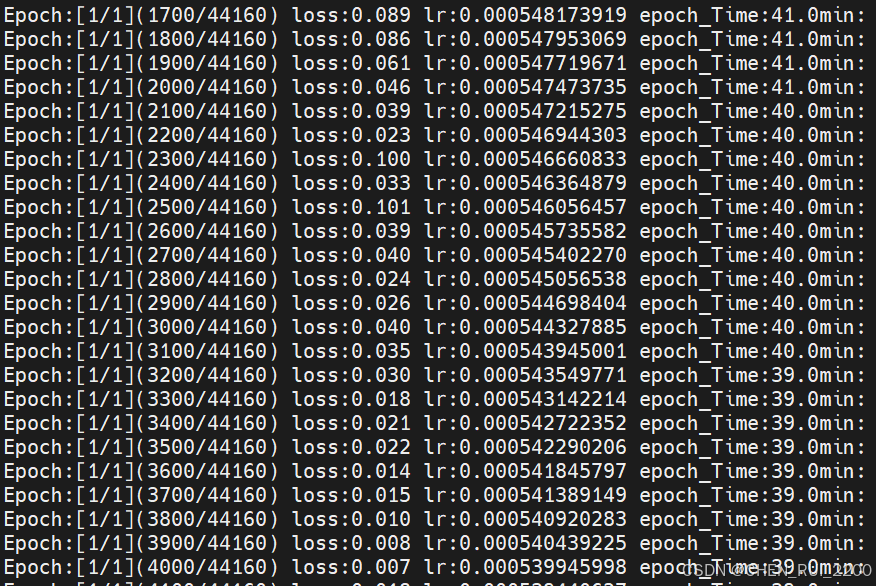
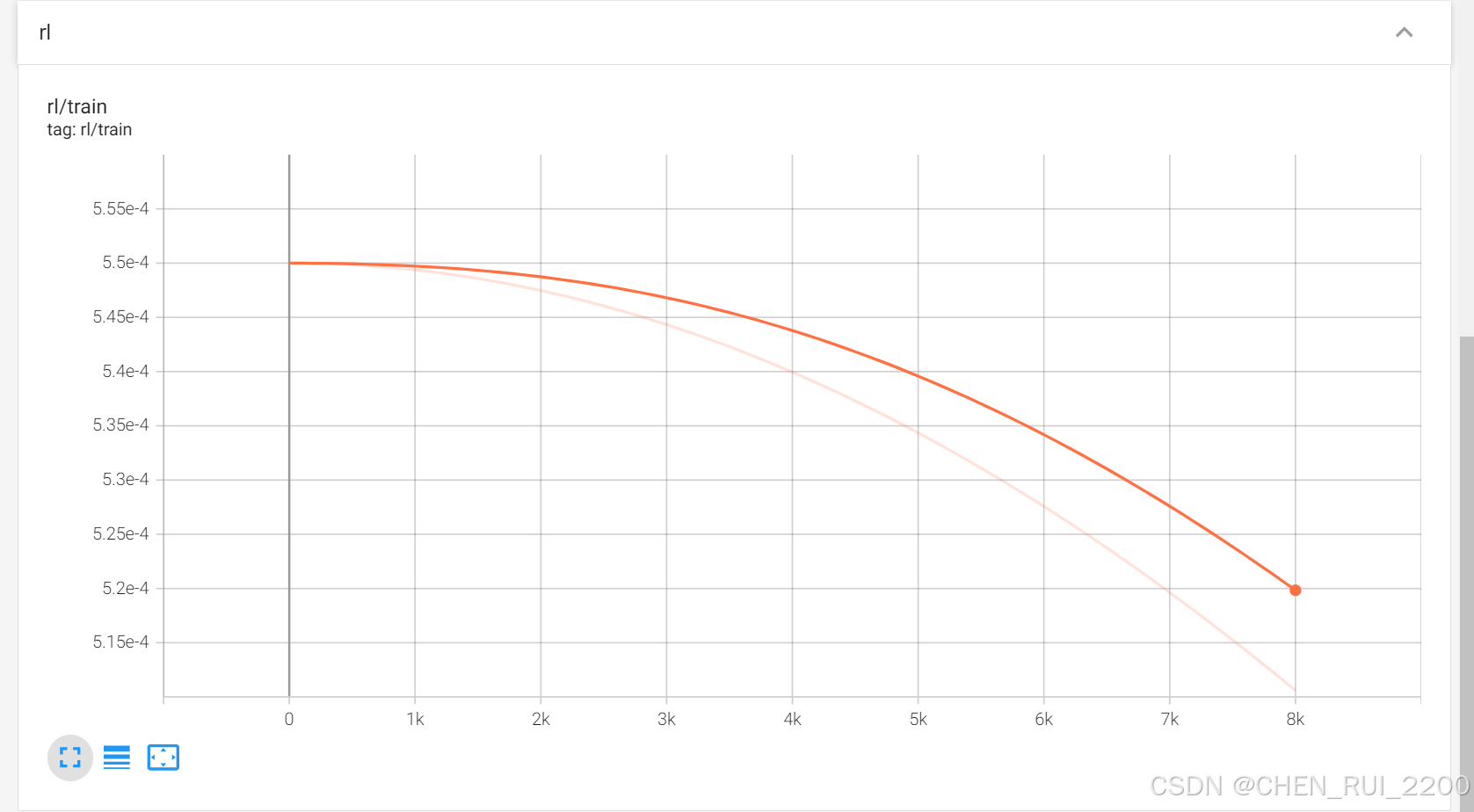
效果很明显训练收敛的很快,此处是我后面又重新训练记录的图比较注意力修改前后对比