P1308 统计单词数详解
此题涉及以下知识
1,find的潜在运行方式,若没找到时返回值判定
2,find的逐次遍历寻找技巧
3,getline的使用方法
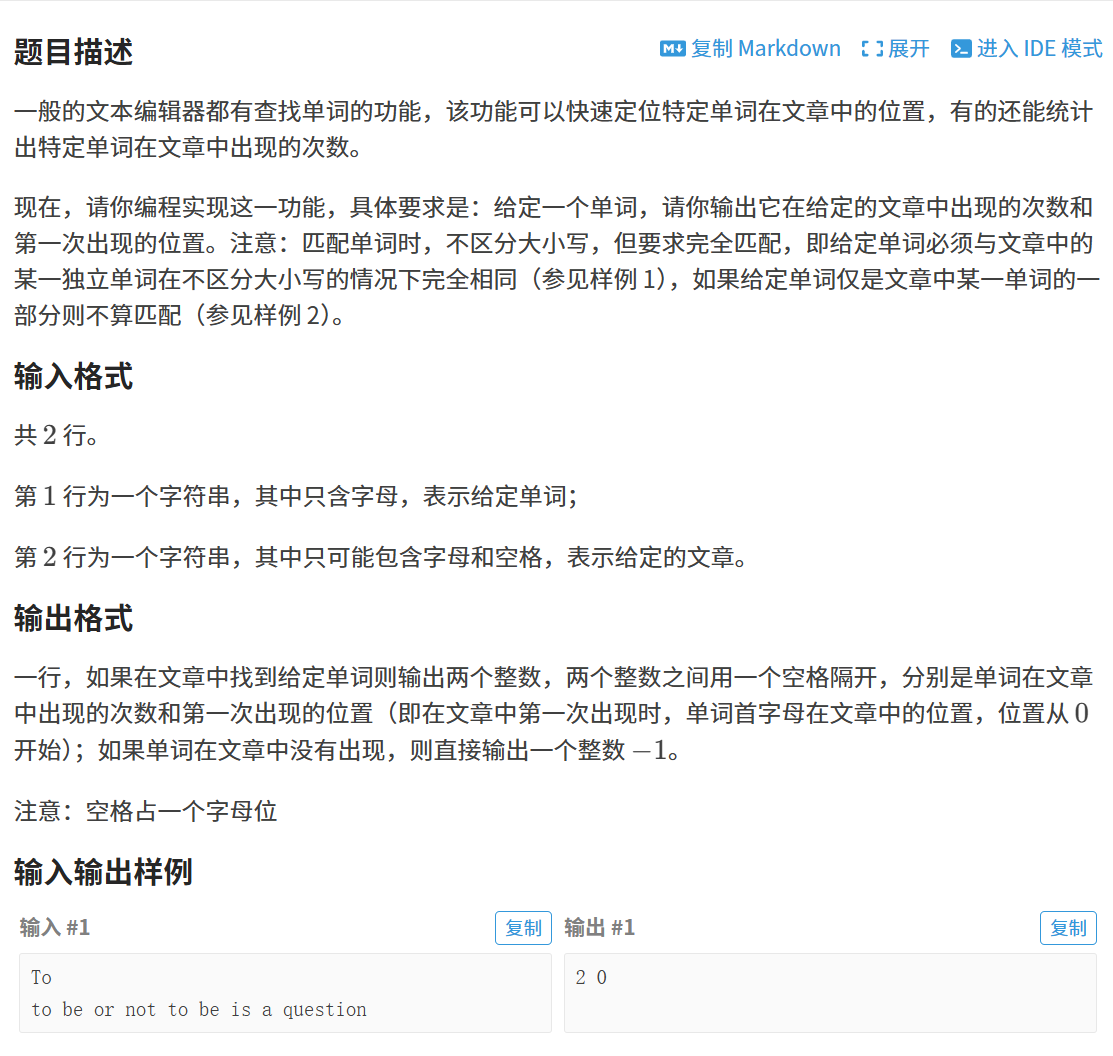
我的解答:先有个印象,看不懂没关系,后面慢慢解释

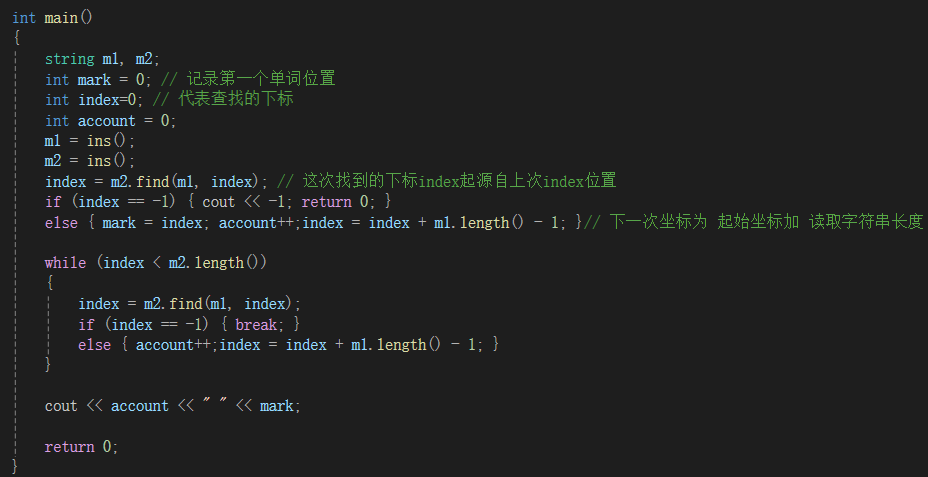
1,find的运行方式
s1.find( s2 , 查找起始点 )
在 C++ 中,find() 方法在未找到子串或字符时不会返回 -1,而是返回一个特殊的常量 npos
1. string::npos 的本质
- 类型:
size_t(无符号整数类型)。 - 值:通常是
size_t类型的最大值(例如4294967295在 32 位系统中)。 - 比较逻辑:虽然
string::npos的值不等于-1,但当你用int类型变量接收返回值时:
这是因为int pos = str.find("xyz"); // 若未找到,pos 会被赋值为 -1size_t的最大值(string::npos)在转换为int时会发生溢出,导致结果为-1。
所以可用 pos == -1,表示find寻找失败,原字符串里面无目标字符
2,find的逐次遍历技巧
int m1 ;
接收索引位置的变量 即 m1 = s1.find(s2,起始下标位置索引)
这时,你有没有发现,m1和find里面的第二个参数能不能也是 m1,而此时 m1又代表什么含义,会发生什么效果,被for循环包裹时哦
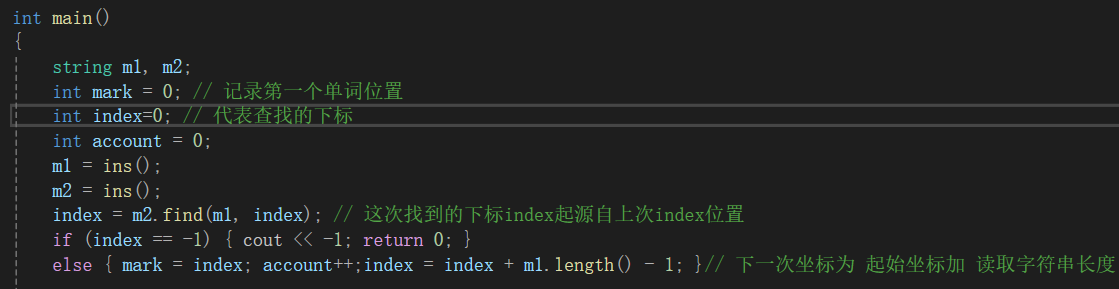
find里面的index象征上一次查找单词查找到的位置下标,那么下一次查找,是不是就可用沿着上一次的index查找结束的位置
 mark用来记录第一次找到单词的索引位置,题目要求输出
mark用来记录第一次找到单词的索引位置,题目要求输出
account记录次数,题目要求输出
index = index + m1.length()-1 因为是要找一个单独的单词,不包含在其他单词中间,我们这里采取的技巧就是,要查找的目标单词前后都加上一个空格,这才能说明他是一个单独的单词,而也成于此,也得于此,原本下一个位置索引,即 index = index + m1.length()-1 里面最左边的index原本应该表示为 原来的索引位置 加上 查找到的目标单词长度 就等于下一次查找的起始位置,但是因为目标单词前后都有空格,如果按上面这样,之后的下一个单词前面就少了一个空格,就是它是目标单词,但是计算机也认为他是某个单词的一部分,而不认这个亲儿子

我此步的目标是为了获得 将所有大写字母转成小写字母后的 目标单词字符串和原文字符串,再在目标单词前后加上空格方便识别他是一个单独的单词,而在原文字符串前后也加空格是为了从原文单词从头到尾的识别,让第一个单词前面也有空格可以识别判断是否是目标单词
3,而此时又涉及到了 getline()
在C++中,getline 函数用于从输入流中读取一行文本,直到遇到换行符或指定的分隔符。
getline主要用于从输入流中读取一行文本,直到遇到换行符('\n')或者指定的分隔符。与cin不同,getline可以读取包含空格的字符串,而cin在遇到空格时会停止读
(1) 标准形式:读取到换行符
istream& getline (istream& is, string& str);- 功能:从输入流
is中读取字符,存入字符串str,直到遇到换行符\n
输入流 is 也即是 cin
2) 指定分隔符:读取到自定义字符
istream& getline (istream& is, string& str, char delim);- 功能:读取到指定的分隔符
delim(不包含在结果中)。 - 即是读取到 分隔符这个特定符合就停止读取
其时这题解也说的七七八八了,最后一个是 可能你好奇有个while ,这只不过是在找到目标单词后继续往后找,知道结束,前面的 if 和 else 只是为了判断原单词在文章是否存在,存在则记录第一个,之后的不记录,不存在则直接返回 -1 结束