Gradio全解20——Streaming:流式传输的多媒体应用(2)——构建对话式聊天机器人
Gradio全解20——Streaming:流式传输的多媒体应用(2)——构建对话式聊天机器人
- 本篇摘要
- 20. Streaming:流式传输的多媒体应用
- 20.2 构建对话式聊天机器人
- 20.2.1 应用概述
- 20.2.2 记录用户音频
- 20.2.3 存储音频并生成响应
- 20.2.4 构建Gradio应用
- 参考文献:
本章目录如下:
- 《Gradio全解20——Streaming:流式传输的多媒体应用(1)——流式传输音频:魔力8号球》;
- 《Gradio全解20——Streaming:流式传输的多媒体应用(2)——构建对话式聊天机器人》;
- 《Gradio全解20——Streaming:流式传输的多媒体应用(3)——实时语音识别技术》;
- 《Gradio全解20——Streaming:流式传输的多媒体应用(4)——基于Groq的带自动语音检测功能的多模态Gradio应用》;
- 《Gradio全解20——Streaming:流式传输的多媒体应用(5)——基于WebRTC的摄像头实时目标检测》;
- 《Gradio全解20——Streaming:流式传输的多媒体应用(6)——构建视频流目标检测系统》;
本篇摘要
本章讲述流式传输的应用,包括音频、图像和视频格式的流式传输。
20. Streaming:流式传输的多媒体应用
本章讲述流式传输的应用,包括音频、图像和视频格式的流式传输。音频应用包括流式传输音频、构建音频对话式聊天机器人、实时语音识别技术和自动语音检测功能;图像应用包括基于WebRTC的摄像头实时目标检测;视频应用包括构建视频流目标检测系统。
20.2 构建对话式聊天机器人
新一代AI用户界面正朝着原生音频体验发展,用户将能够与聊天机器人对话并接收语音回复。基于这一范式已开发出多个模型,包括GPT-4o和mini omni。本节将以mini omni为例,带读者逐步构建自己的对话式聊天应用。
20.2.1 应用概述
Mini-Omni是一款开源多模态大语言模型,具备边思考边对话的能力;该模型还具有端到端的实时语音输入与流式音频输出对话功能,可实现完整的语音交互体验,其github地址为:https://github.com/gpt-omni/mini-omni。下方可查看使用Mini-Omni的最终应用的演示效果:
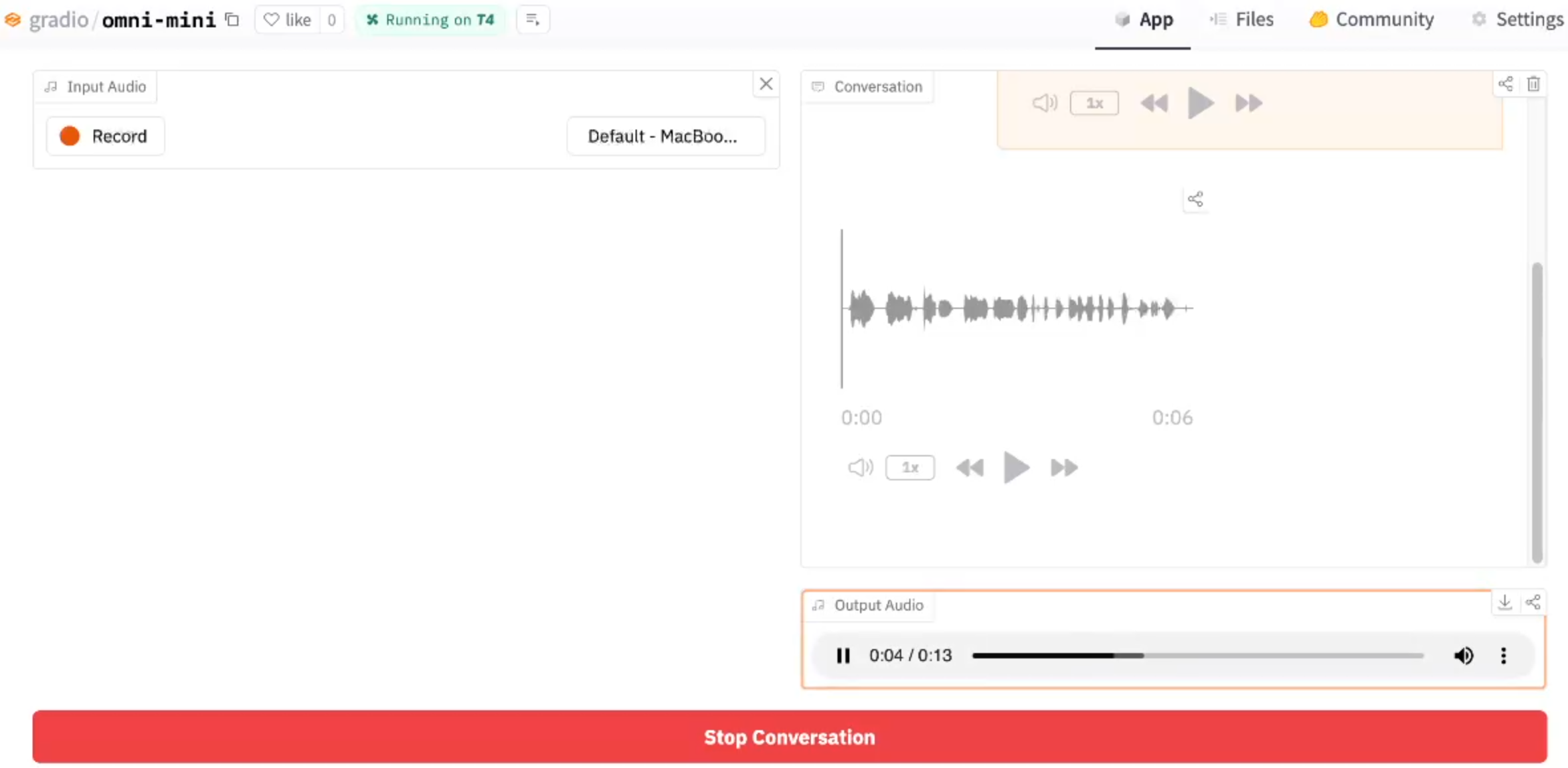
我们的应用将实现以下用户体验:
- 用户点击按钮开始录制语音消息;
- 应用检测到用户停止说话后自动结束录制;
- 用户音频传入mini omni模型,模型会流式返回响应;
- mini omni完成应答后重新激活用户麦克风;
- 所有对话历史(用户与omni的语音记录)显示在聊天组件中。
其Hugging Face地址为:gradio/omni-mini。下面让我们深入实现细节。
20.2.2 记录用户音频
我们会将用户麦克风的音频流式传输至服务器,并在每个新音频片段到达时判断用户是否已停止说话。以下是我们的process_audio函数:
import numpy as np
from utils import determine_pausedef process_audio(audio: tuple, state: AppState):if state.stream is None:state.stream = audio[1]state.sampling_rate = audio[0]else:state.stream = np.concatenate((state.stream, audio[1]))pause_detected = determine_pause(state.stream, state.sampling_rate, state)state.pause_detected = pause_detectedif state.pause_detected and state.started_talking:return gr.Audio(recording=False), statereturn None, state
该函数接收两个输入参数:当前音频片段(由采样率sampling_rate和音频流numpy数组组成的元组)和当前应用状态。我们将使用以下AppState数据类来管理应用状态:
from dataclasses import dataclass, field@dataclass
class AppState:stream: np.ndarray | None = Nonesampling_rate: int = 0pause_detected: bool = Falsestarted_talking: bool = Falsestopped: bool = Falseconversation: list = field(default_factory=list)
该函数会将新音频片段与现有音频流拼接,并检测用户是否停止说话。若检测到停顿,则返回停止录制的指令;否则返回None表示无需变更。
determine_pause函数的具体实现属于omni-mini项目特有,源码如下:
def determine_pause(audio: np.ndarray, sampling_rate: int, state: AppState) -> bool:"""Take in the stream, determine if a pause happened"""temp_audio = audiodur_vad, _, time_vad = run_vad(temp_audio, sampling_rate)duration = len(audio) / sampling_rateif dur_vad > 0.5 and not state.started_talking:print("started talking")state.started_talking = Truereturn Falseprint(f"duration_after_vad: {dur_vad:.3f} s, time_vad: {time_vad:.3f} s")return (duration - dur_vad) > 1
20.2.3 存储音频并生成响应
处理完用户音频后,我们需要生成并流式传输聊天机器人的响应。以下是我们的response函数实现:
import io
import tempfile
from pydub import AudioSegmentdef response(state: AppState):if not state.pause_detected and not state.started_talking:return None, AppState()audio_buffer = io.BytesIO()segment = AudioSegment(state.stream.tobytes(),frame_rate=state.sampling_rate,sample_width=state.stream.dtype.itemsize,channels=(1 if len(state.stream.shape) == 1 else state.stream.shape[1]),)segment.export(audio_buffer, format="wav")with tempfile.NamedTemporaryFile(suffix=".wav", delete=False) as f:f.write(audio_buffer.getvalue())state.conversation.append({"role": "user","content": {"path": f.name,"mime_type": "audio/wav"}})output_buffer = b""for mp3_bytes in speaking(audio_buffer.getvalue()):output_buffer += mp3_bytesyield mp3_bytes, statewith tempfile.NamedTemporaryFile(suffix=".mp3", delete=False) as f:f.write(output_buffer)state.conversation.append({"role": "assistant","content": {"path": f.name,"mime_type": "audio/mp3"}})yield None, AppState(conversation=state.conversation)
该函数主要完成以下功能:
- 将用户音频转换为WAV格式文件;
- 将用户消息添加至对话历史记录;
- 使用speaking函数生成并流式传输聊天机器人响应;
- 将聊天机器人响应保存为MP3文件;
- 将聊天机器人响应添加至对话历史记录。
注:speaking函数的具体实现属于omni-mini项目特有,源码如下:
def speaking(audio_bytes: str):base64_encoded = str(base64.b64encode(audio_bytes), encoding="utf-8")files = {"audio": base64_encoded}with requests.post(API_URL, json=files, stream=True) as response:try:for chunk in response.iter_content(chunk_size=OUT_CHUNK):if chunk:# Create an audio segment from the numpy arrayaudio_segment = AudioSegment(chunk,frame_rate=OUT_RATE,sample_width=OUT_SAMPLE_WIDTH,channels=OUT_CHANNELS,)# Export the audio segment to MP3 bytes - use a high bitrate to maximise qualitymp3_io = io.BytesIO()audio_segment.export(mp3_io, format="mp3", bitrate="320k")# Get the MP3 bytesmp3_bytes = mp3_io.getvalue()mp3_io.close()yield mp3_bytesexcept Exception as e:raise gr.Error(f"Error during audio streaming: {e}")
其中API_URL的定义如下:
from huggingface_hub import snapshot_download
from threading import Thread
from server import serverepo_id = "gpt-omni/mini-omni"
snapshot_download(repo_id, local_dir="./checkpoint", revision="main")IP = "0.0.0.0"
PORT = 60808thread = Thread(target=serve, daemon=True)
thread.start()API_URL = "http://0.0.0.0:60808/chat"
可以看到,此处将mini-omni下载到本地并在本地运行,更详细源码请参考omni-mini/app.py
20.2.4 构建Gradio应用
我们使用Gradio的Blocks API构建完整应用,另外,还可以在界面中设置time_limit和stream_every参数。time_limit限制每个用户流的处理时间,默认值为30秒,因此用户无法流式传输超过30秒的音频。stream_every参数控制数据发送到处理函数的频率,默认值为0.5秒。代码如下:
import gradio as grdef start_recording_user(state: AppState):if not state.stopped:return gr.Audio(recording=True)with gr.Blocks() as demo:with gr.Row():with gr.Column():input_audio = gr.Audio(label="Input Audio", sources="microphone", type="numpy")with gr.Column():chatbot = gr.Chatbot(label="Conversation", type="messages")output_audio = gr.Audio(label="Output Audio", streaming=True, autoplay=True)state = gr.State(value=AppState())stream = input_audio.stream(process_audio,[input_audio, state],[input_audio, state],stream_every=0.5,time_limit=30,)respond = input_audio.stop_recording(response,[state],[output_audio, state])respond.then(lambda s: s.conversation, [state], [chatbot])restart = output_audio.stop(start_recording_user,[state],[input_audio])cancel = gr.Button("Stop Conversation", variant="stop")cancel.click(lambda: (AppState(stopped=True), gr.Audio(recording=False)), None,[state, input_audio], cancels=[respond, restart])if __name__ == "__main__":demo.launch()
当前实现创建了一个包含以下组件的用户界面:
- 音频输入组件 - 用于录制用户语音消息;
- 聊天组件 - 实时显示对话历史记录;
- 音频输出组件 - 播放聊天机器人语音响应;
- 重置按钮 - 终止当前对话并清空状态。
应用以0.5秒为间隔流式处理用户音频片段,经处理后生成响应内容,并动态更新对话历史展示。
总结:本节演示了如何利用Gradio框架与mini omni模型构建对话式聊天机器人应用。该基础架构可灵活扩展,用于开发各类语音交互式聊天演示。另外,开发者可尝试集成不同模型、优化音频处理流程或创新界面设计,打造个性化的对话式AI体验!
参考文献:
- Streaming AI Generated Audio
- Run Inference on servers
- Spaces ZeroGPU: Dynamic GPU Allocation for Spaces