大连理工大学选修课——机器学习笔记(7):集成学习及随机森林
集成学习及随机森林
集成学习概述
泛化能力的局限
每种学习模型的能力都有其上限
- 限制于特定结构
- 受限于训练样本的质量和规模
如何再提高泛化能力?
- 研究新结构
- 扩大训练规模
提升模型的泛化能力
创造性思路
- 组合多个学习模型
集成学习
集成学习不是特定的学习模型,而实一种构建模型的思路,一种训练学习的思想
强可学习和弱可学习
强可学习:对于一个概念或者一个类,如果存在一个多项式学习算法可以学习它,正确率高,则该概念是强可学习的。
弱可学习:如果能学习,但正确率只比瞎猜略好,则称为弱可学习。
也已证明,强可学习和弱可学习等价:
如果一个问题存在弱可学习算法,则必然存在强可学习算法
为集成学习奠定了基础
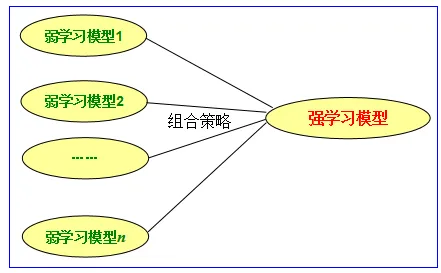
集成学习的基本问题
如何建立或选择弱学习模型
弱学习模型通常是单个的模型,是被集成的成员
如何制定组合策略
如何将多个学习模型的预测结果整合在一起
不同的组合策略会带来不同的结果
构建弱学习模型的策略
通常弱学习模型都是同类学习模型
同类模型之间的关系
-
无依赖关系
- 系列成员模型可以并行生成
- 代表算法:bagging,随机森林
-
强依赖关系
- 系列成员模型可串行生成
- 代表算法:boosting、梯度提升树
-
平均法
-
处理回归问题
-
对弱学习模型的输出进行平均得到最终的预测输出
H ( x ) = 1 n ∑ i = 1 n h i ( x ) H(x)=\frac{1}{n}\sum_{i=1}^nh_i(x) H(x)=n1i=1∑nhi(x)
-
也可以引入权重
H ( x ) = 1 n ∑ i = 1 n w i h i ( x ) H(x)=\frac{1}{n}\sum_{i=1}^nw_ih_i(x) H(x)=n1i=1∑nwihi(x)
-
-
投票法
-
处理分类问题
少数服从多数,最大票数相同则随机选择
也可以新增加要求,例如票数过半
也可以给每个成员不同的投票权重
-
再学习法
平均法和投票法可能带来大学习误差
- 再学习
-
建立新的学习模型:再集成学习的组合端增加一个学习模型
-
成员学习的模型输出作为新的学习模型的输入,集成模型的数量为n,新数据集维度为n
-
代表方法:stacking
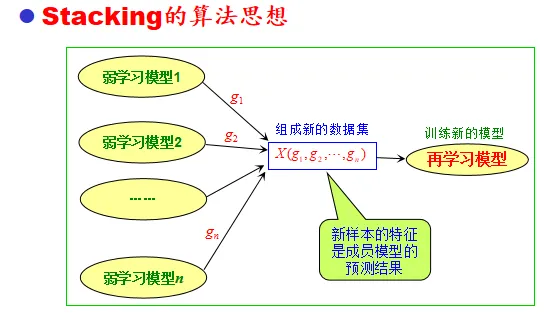
-
- 再学习
Bagging
——Bagging Aggregating的缩写
Bootstrap是一种有放回操作的抽样方法
- 抽取的样本会有重复
在这里,用来指导构建弱分类器
-
使用同类学习模型时采用的策略
-
可降低模型过拟合的可能性
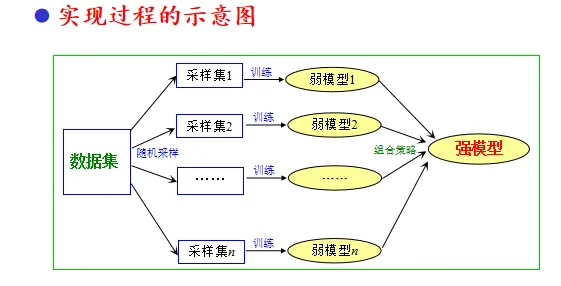
采样过程说明
-
样本集规模为M,采样集规模也为M
- 样本集的样本不减少,每次采集后还要放回,因此同一样本可能会多次采集到。
- 每次随机采集一个样本,随机采集M次,组成采样集
- 随机采样,组成规模为M的n个采样集
- 由于随机性,n个采样集不完全一样
- 训练出的弱学习模型也存在差别
-
采样集中不被选中样本的概率
每次采样,每个样本不被选中的概率为:
p ( x ) = 1 − 1 M p(x)=1-\frac{1}{M} p(x)=1−M1
M次不被选中的概率为:
p ( x ) = ( 1 − 1 M ) M lim M → ∞ ( 1 − 1 M ) M = 1 e ≈ 0.368 p(x)=(1-\frac{1}{M})^M\\ \lim_{M\to\infty}(1-\frac{1}{M})^M=\frac{1}{e}\approx0.368 p(x)=(1−M1)MM→∞lim(1−M1)M=e1≈0.368
这些数据称为袋外数据,大约36.8%的样本可以用作测试集
弱学习模型的选择
- 原则上没有限制,通常选择决策树或神经网络
组合策略
回归问题用平均法,分类问题用投票法
算法描述
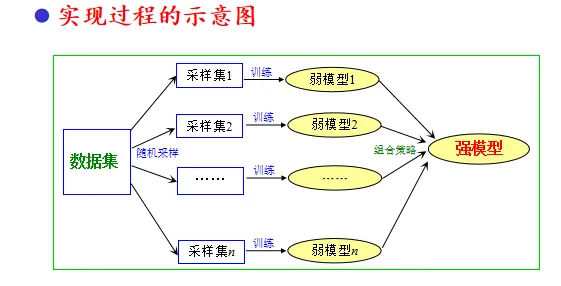
随机森林
——Bagging算法的一个具体实现
- 采用CART作为弱学习模型
- 特征选择也引入了随机性
- 随机选择特征的子集 d s u b < d d_{sub}<d dsub<d
- 在子集中选择最优的分割特征
- 该操作可以进一步增强学习模型的泛化能力
极端随机树(ExtraTrees)
极端随机树的弱分类器不依赖于训练的改变
- 不抽样,也就不使用Bootstrap方法
- 也不像Boosting那样,改变训练样本权重
它的随机性体现在树结点分裂时的两个随机过程
- 随机选择一小部分样本的特征
- 随机在部分属性随机选择使结点分裂的属性
- 因为不考虑分裂的是不是最优属性,因此有些“极端”。
极端随机树的优势
算法复杂度
- 对比RandomForest,Extratree更快
- 不抽样,不选择最优特征
拟合效果
因为不选择最优特征,预测结果的方差大,不易过拟合
基本不用剪枝
泛化能力
在某些领域ExtraTree比RandomForest好些
对于那些训练集分布与真实差别比较大的数据,ExtraTree更有优势
如果弱学习模型引入Bootstrap,随机性会进一步增大