数据库所有知识
# 第一章 数据库-理论基础
## 1.1 什么是数据库
数据: 描述事物的符号记录, 可以是数字、 文字、图形、图像、声音、语言等,数据有多种形式,它们都可以经过数字化后存入计算机。
数据库: 存储数据的仓库,是长期存放在计算机内、有组织、可共享的大量数据的集合。数据库中的数据按照一定数据模型组织、描述和存储,具有较小的冗余度,较高的独立性和易扩展性,并为各种用户共享,总结为以下几点:
+ 数据结构化
+ 数据的共享性高,冗余度低,易扩充
+ 数据独立性高
+ 数据由 DBMS 统一管理和控制(安全性、完整性、并发控制、故障恢复)
## 1.2 数据库管理系统(DBMS)
数据库系统成熟的标志就是数据库管理系统的出现。数据库管理系统(DataBase Management System,简称DBMS)是管理数据库的一个软件,它充当所有数据的知识库,并对它的存储、安全、一致性、并发操作、恢复和访问负责。是对数据库的一种完整和统一的管理和控制机制。数据库管理系统不仅让我们能够实现对数据的快速检索和维护,还为数据的安全性、完整性、并发控制和数据恢复提供了保证。数据库管理系统的核心是一个用来存储大量数据的数据库。
DBMS是所有数据的知识库,并对数据的存储、安全、一致性、并发操作、恢复和访问负责。
DBMS有一个数据字典(有时被称为系统表),用于贮存它拥有的每个事物的相关信息,例如名字、结构、位置和类型,这种关于数据的数据也被称为元数据(metadata)。

## 1.3 数据库与文件系统的区别
文件系统: 文件系统是操作系统用于明确存储设备(常见的是磁盘)或分区上的文件的方法和数据结构;即在存储设备上组织文件的方法。操作系统中负责管理和存储文件信息的软件机构称为文件管理系统,简称文件系统。
数据库系统: 数据库管理系统(Database Management System)是一种操纵和管理数据库的大型软件,用于建立、使用和维护数据库,简称 DBMS。它对数据库进行统一的管理和控制,以保证数据库的安全性和完整性。
**对比区别:**
1. 管理对象不同: 文件系统的管理对象是文件,并非直接对数据进行管理,不同的数据结构需要使用不同的文件类型进行保存(举例: txt 文件和 doc 文件不能通过修改文件名完成转换) ;而数据库直接对数据进行存储和管理
2. 存储方式不同:文件系统使用不同的文件将数据分类(.doc/.mp4/.jpg) 保存在外部存储上;数据库系统使用标准统一的数据类型进行数据保存(字母、 数字、符号、时间)
3. 调用数据的方式不同:文件系统使用不同的软件打开不同类型的文件;数据库系统由 DBMS 统一调用和管理。

**优缺点总结:**
+ 由于 DBMS 的存在,用户不再需要了解数据存储和其他实现的细节,直接通过 DBMS 就能获取数据,为数据的使用带来极大便利。
+ 具有以数据为单位的共享性,具有数据的并发访问能力。 DBMS 保证了在并发访问时数据的一致性。
+ 低延时访问,典型例子就是线下支付系统的应用,支付规模巨大的时候,数据库系统的表现远远优于文件系统。
+ 能够较为频繁的对数据进行修改,在需要频繁修改数据的场景下,数据库系统可以依赖 DBMS 来对数据进行操作且对性能的消耗相比文件系统比较小。
+ 对事务的支持。 DBMS 支持事务,即一系列对数据的操作集合要么都完成, 要么都不完成。在DBMS上对数据的各种操作都是原子级的。
## 1.4 数据库的发展史
初始阶段-----人工管理:人力手工整理存储数据
萌芽阶段-----文件系统:使用磁盘文件来存储数据
初级阶段-----第一代数据库:出现了网状模型、层次模型的数据库
中级阶段-----第二代数据库:关系型数据库和结构化查询语言
高级阶段------新一代数据库:NOSQL型数据库、非关系型数据库
## 1.5 常见数据库
### 1.5.1 关系型数据库
**关系型数据库**是建立在关系模型基础上的数据库,借助于集合代数等数学概念和方法来处理数据库中的数据。现实世界中的各种实体以及实体之间的各种联系均用关系模型来表示。 简单说,关系型数据库是由多张能互相联接的二维行列表格组成的数据库。
关系模型就是指**二维表格模型**, 因而一个关系型数据库就是由二维表及其之间的联系组成的一个数据组织。当前主流的关系型数据库有**Oracle、DB2、Microsoft SQL Server、MicrosoftAccess、MySQL、浪潮K-DB 、武汉达梦、南大通用、人大金仓**等。
实体关系模型简称 E-R 模型,是一套数据库的设计工具,他运用真实世界中事物与关系的观念,来解释数据库中的抽象的数据架构。实体关系模型利用图形的方式(实体-关系图)来表示数据库的概念设计,有助于设计过程中的构思及沟通讨论。
### 1.5.2 非关系型数据库
**非关系型数据库**又被称为 NoSQL(Not Only SQL ),意为不仅仅是 SQL, 是一种轻量、开源、不兼容 SQL 功能的数据库, 对 NoSQL 最普遍的定义是“非关联型的”,强调 Key-Value 存储和文档数据库的优点,而不是单纯地反对 RDBMS(关系型数据库管理系统)。
## 1.6 DBMS支持的数据模型

**层次模型**
若用图来表示,层次模型是一棵倒立的树。在数据库中,满足以下条件的数据模型称为层次模型:
+ 有且仅有一个节点无父节点,这个节点称为根节点
+ 其他节点有且仅有一个父节点。桌面型的关系模型数据库

**网状模型**
在现实世界中,事物之间的联系更多的是非层次关系的,用层次模型表示非树型结构是很不直接的,网状模型则可以克服这一弊病。网状模型是一个网络。在数据库中,满足以下两个条件的数据模型称为网状模型。A.允许一个以上的节点无父节点;B.一个节点可以有多于一个的父节点。
从以上定义看出,网状模型构成了比层次结构复杂的网状结构,适宜表示多对多的联系。

**关系模型**
以二维表的形式表示实体和实体之间联系的数据模型称为关系数据模型。从模型的三要素角度看,关系模型的内容为:
数据结构:一张二维表格。
数据操作:数据表的定义、检索、维护、计算等。
数据约束条件:表中列的取值范围即域值的限制条件。

**概念模型:**基于客户的想法和观点所形成的认识和抽象。
实体(Entity):客观存在的、可以被描述的事物。例如员工、部门。
属性(Attribute):用于描述实体所具有的特征或特性。如使用编号、姓名、工资等来属性来描述员工的特征。
关系(Relationship):实体之间的联系。
一对一: 人 和 身份证
一对多: 班级 和 学生
多对多: 学生 和 课程
**数据模型:**也叫关系模型,是实体、属性、关系在数据库中的具体体现。
关系数据库:用于存储各种类型数据的”仓库”,是二维表的集合。
表:实体的映射
行和列:行代表一个具体的实体的数据。也叫一条记录。列是属性的映射,用于描述实体的。
主键和外键。

## 1.7 运维对数据库的要求
### 程序员对数据库要求
基本的SQL操作、CRUD操作
多表连接查询、分组查询和子查询。
常用数据库的的单行函数。
常用数据库的基本命令。
常用数据库的开发工具。
事务概念。
索引、视图、存储过程和触发器。
### 运维对数据库要求
部署环境
数据库安装、参数配置、权限分配
备份/还原
监控
故障处理
性能优化
容灾
升级/迁移
系统用户反馈的数据库问题
### 数据库运维工作总原则
1、能不给数据库做的事情不要给数据库,数据库只做数据容器。
2、对于数据库的变更必须有记录,可以回滚。
## 1.8 MySQL数据库的概述
https://db-engines.com/en/ranking
MySQL是一个中小型关系数据库管理系统,开发者为瑞典**MySQL AB**公司。在2008年1月16号被sun公司10亿美金收购。2009年,SUN又被Oracle以74亿美金收购。
目前MySQL被广泛地应用在Internet上的中小型网站中。由于体积小、速度快、总体拥有成本低,尤其是开放源代码这一特点,许多中小型网站为了降低网站总体拥有成本而选择了MySQL作为网站数据库。
### 1.8.1 MySQL的特性
1. 使用C和C++编写,并使用了多种编译器进行测试,保证源代码的可移植性。
2. 支持AIX、BSDi、FreeBSD、HP-UX、Linux、Mac OS、Novell Netware、NetBSD、OpenBSD、OS/2 Wrap、Solaris、SunOS、Windows等多种操作系统。
3. 为多种编程语言提供了API。这些编程语言包括C、C++、C#、Delphi、Eiffel、Java、Perl、PHP、Python、Ruby和Tcl等。
4. 支持多线程,充分利用CPU资源,支持多用户。
5. 优化的SQL查询算法,有效地提高查询速度。
6. 既能够作为一个单独的应用程序应用在客户端服务器网络环境中,也能够作为一个库而嵌入到其他的软件中。
7. 提供多语言支持,常见的编码如中文的GB 2312、BIG5,日文的Shift_JIS等都可以用作数据表名和数据列名。
8. 提供TCP/IP、ODBC和JDBC等多种数据库连接途径。
9. 提供用于管理、检查、优化数据库操作的管理工具。
10. 可以处理拥有上千万条记录的大型数据库。
## 1.9 MySQL的获取
官网:www.mysql.com
也可以从Oracle官方进入:https://www.oracle.com/
下载地址:https://downloads.mysql.com/archives/community/
选择对应的版本和对应的操作系统:
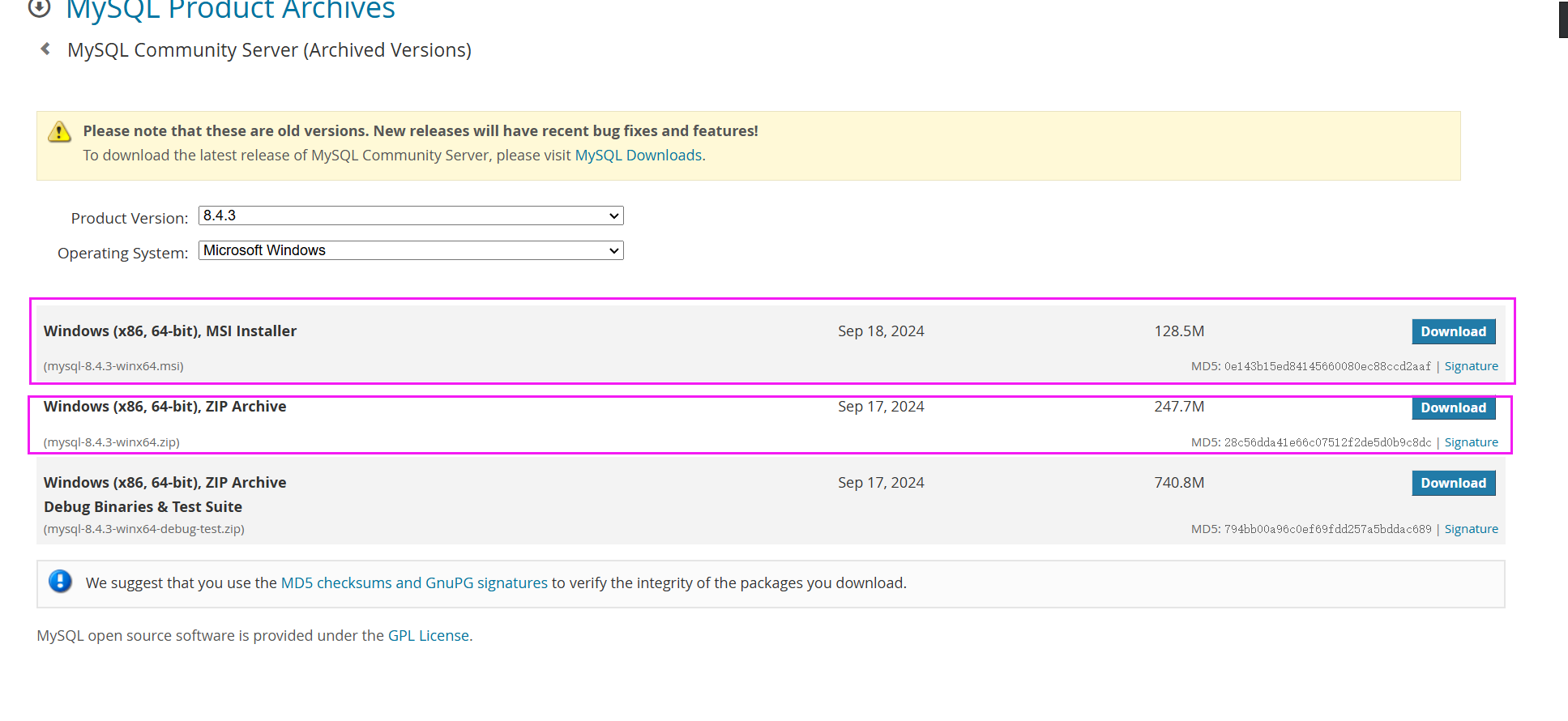
# 第二章 MySQL的安装和配置
针对不同的操作系统,根据上面的情况,来选择对应的版本。
## window操作系统安装
存在两种安装方式:
1. 安装包方式
2. 压缩包方式
### 安装包方式
没有什么特别的地方,下载安装包。下一步、下一步,直至结束。
在此过程中,注意一些选择问题。
安装方式如下:
**1、下载安装包**
官网下载对应的安装包,根据需要下载对应的版本即可:
8.0:https://cdn.mysql.com//Downloads/MySQLInstaller/mysql-installer-community-8.0.18.0.msi
5.7:https://cdn.mysql.com//Downloads/MySQLInstaller/mysql-installer-community-5.7.28.0.msi
当然也可以选择自己需要的版本:https://downloads.mysql.com/archives/installer/
**2、安装过程**









<img src="https://ljh-1258460726.cos.ap-nanjing.myqcloud.com//typora-pic/image-20200918153229294.png" alt="image-20200918153229294" />




安装包的方式比较简单,安装提示对应的完成操作即可(不同的版本可能有所区别,但是都大同小异),这种方式适合于新手使用,一般开发者都建议使用压缩包的方式完成。
### 压缩包方式
**推荐大家使用这种方式**
1. 下载位置:mysql下载位置
2. 解压缩后位置:D:\mysql-8.0.15-winx64
3. 在主目录下复制、创建一个xx.ini,修改为`my.ini`,修改其中的`basedir`和`datadir`
basedir=mysql主目录
datadir=mysql主目录/data
4. 配置bin目录为环境变量
方便在终端情况下,查找MySQL的相关命令
:warning: 注意:一定要重新启动CMD
5. 初始化命令(记录控制台给出的随机密码,一定记住):
:warning: 一定要注意:打开cmd时,必须使用管理员身份!!!cmd打开后,切换到bin目录再执行如下命令
`mysqld --initialize --console`
6. 然后先给mysql服务创建名称(方便到时候建立多个mysql服务时不冲突)
mysqld --install mysql8
7. 启动服务:
net start mysql
8. 登陆旧密码登陆(第3步中的密码):
mysql -u root -p
9. 修改密码:
```mysql
ALTER USER 'root'@'localhost' IDENTIFIED WITH mysql_native_password BY '新密码';
# 之后键入修改密码的命令:
ALTER USER root@localhost IDENTIFIED BY 'root';
```
10. 使用新密码登陆:
mysql -u root -p 新密码
卸载MySQL:
停止服务:net stop mysql
删除服务:mysqld --remove
登录成功后,执行命令:
```mysql
show databases;
```
MySQL的配置文件(window版——my.ini):
~~~ini
[mysqld]
# skip_grant_tables
# 设置3306端口
port=3306
# 设置mysql的安装目录
basedir=D:\dev_soft\mysql-8.0.20-winx64
# 设置mysql数据库的数据的存放目录
datadir=D:\dev_soft\mysql-8.0.20-winx64\data
# 允许最大连接数
max_connections=200
# 允许连接失败的次数。这是为了防止有人从该主机试图攻击数据库系统
max_connect_errors=10
# 服务端使用的字符集默认为UTF8
character-set-server=utf8mb4
# 创建新表时将使用的默认存储引擎
default-storage-engine=INNODB
[client]
#password = your_password
# 设置mysql客户端连接服务端时默认使用的端口
port=3306
default-character-set=utf8mb4
[mysql]
# 设置mysql客户端默认字符集
default-character-set=utf8mb4
~~~
### 使用客户端登录MySQL服务器
cmd输入如下命令:
```cmd
mysql --uroot --p
mysql -h127.0.0.1 -P3306 -uroot -p
```
查看安装的MySQL版本:
```
mysql -V
```
使用帮助命令查看MySQL终端命令:
```mysql
mysql> \h
For information about MySQL products and services, visit:
http://www.mysql.com/
For developer information, including the MySQL Reference Manual, visit:
http://dev.mysql.com/
To buy MySQL Enterprise support, training, or other products, visit:
https://shop.mysql.com/
List of all MySQL commands:
Note that all text commands must be first on line and end with ';'
? (\?) Synonym for `help'.
clear (\c) Clear the current input statement.
connect (\r) Reconnect to the server. Optional arguments are db and host.
delimiter (\d) Set statement delimiter.
ego (\G) Send command to mysql server, display result vertically.
exit (\q) Exit mysql. Same as quit.
go (\g) Send command to mysql server.
help (\h) Display this help.
notee (\t) Don't write into outfile.
print (\p) Print current command.
prompt (\R) Change your mysql prompt.
quit (\q) Quit mysql.
rehash (\#) Rebuild completion hash.
source (\.) Execute an SQL script file. Takes a file name as an argument.
status (\s) Get status information from the server.
system (\!) Execute a system shell command.
tee (\T) Set outfile [to_outfile]. Append everything into given outfile.
use (\u) Use another database. Takes database name as argument.
charset (\C) Switch to another charset. Might be needed for processing binlog with multi-byte charsets.
warnings (\W) Show warnings after every statement.
nowarning (\w) Don't show warnings after every statement.
resetconnection(\x) Clean session context.
For server side help, type 'help contents'
```
如何查看当前数据库管理系统(DBMS):
在MySQL中存在`show`命令,该命令主要用来查询数据库相关信息。
如何查询当前数据库管理下存在多少数据库:
```sql
show databases;
# show命令支持模糊匹配
# 查询以db_开头的数据库
show databases like "db_%";
```
进入某个数据库
```mysql
use 数据库名称
```
查询当前数据库下的表:
~~~sql
show tables;
show tables like "t_%";
~~~
# 第三章 MySQL数据库和表的操作
关系型数据库,都是遵循SQL语法进行数据查询和管理的。
## SQL语句
### 什么是sql
SQL:结构化查询语言(`Structured Query Language`),在关系型数据库上执行数据操作、数据检索以及数据维护的标准语言。使用SQL语句,程序员和数据库管理员可以完成如下的任务。
SQL语言1974年由Boyce和Chamberlin提出,并首先在IBM公司研制的[关系数据库](https://baike.baidu.com/item/关系数据库/1237340?fromModule=lemma_inlink)系统SystemR上实现。由于它具有功能丰富、使用方便灵活、语言简洁易学等突出的优点,深受计算机工业界和计算机用户的欢迎。1980年10月,经[美国国家标准局](https://baike.baidu.com/item/美国国家标准局/3350884?fromModule=lemma_inlink)(ANSI)的数据库委员会X3H2批准,将SQL作为关系数据库语言的美国标准,同年公布了标准SQL,此后不久,[国际标准化组织](https://baike.baidu.com/item/国际标准化组织/779832?fromModule=lemma_inlink)(ISO)也作出了同样的决定。
1986年了,ISO提出SQL的一个标准,SQL86。
+ 改变数据库的结构
+ 更改系统的安全设置
+ 增加用户对数据库或表的许可权限
+ 在数据库中检索需要的信息
+ 对数据库的信息进行更新
### SQL的分类
根据sql的功能,将sql进行如下类别的划分:
> DDL:(Data Definition Language):数据定义语言,定义对数据库对象(库、表、列、索引)的操作。
> CREATE、DROP、ALTER、RENAME、 TRUNCATE等
>
> DML:(Data Manipulation Language): 数据操作语言,定义对数据库记录的操作。
> INSERT、DELETE、UPDATE、SELECT等
>
> DQL(Data Query Language):数据查询语言
>
> SELECT将数据的查询单独说明
>
> DCL:(Data Control Language): 数据控制语言,定义对数据库、表、字段、用户的访问权限和安全级别。
> GRANT、REVOKE等
### SQL语句的书写规范
> 在数据库系统中,SQL语句不区分大小写(关键字建议用大写) 。
> 但字符串常量区分大小写。
> SQL语句可单行或多行书写,以“;”结尾。
> 关键词不能跨多行或简写。
> 用空格和缩进来提高语句的可读性。
> 子句通常位于独立行,便于编辑,提高可读性。
> SELECT * FROM tb_table
> 注释:
> SQL标准:
> /**/。多行注释
> “-- ” 单行注释
> MySQL注释:
> “#”
## 数据库操作
### MySQL数据库的编码
:warning: 注意:MySQL的默认编码是Lain1编码。latin1支持西欧字符、希腊字符等
注意:在早期MySQL为了兼容像中文这种符号,提供了`utf8`编码。
现在因为表情包已经需要使用第四个字节存储,所以,`utf8`不建议使用了,建议使用另一种真正的Unicode编码:`utf8mb4`。
MySQL字符集包括字符集(CHARACTER)和校对规则(COLLATION)两个概念:
latin1支持西欧字符、希腊字符等
gbk支持中文简体字符
big5支持中文繁体字符
utf8几乎支持世界所有国家的字符。
SHOW DATABASES
MySQL自带数据库:
> Information_schema: 主要存储了系统中的一些数据库对象信息:如用户表信息、列信息、权限信
> 息、字符集信息、分区信息等。(数据字典表)
>
> performance_schema: 主要存储数据库服务器的性能参数
>
> mysql: 存储了系统的用户权限信息及帮助信息。
>
> sys: 5.7新增,之前版本需要手工导入。这个库是通过视图的形式把information_schema
>
> performance_schema结合起来,查询出更加令人容易理解的数据
>
> test:系统自动创建的测试数据库,任何用户都可以使用。
### 数据库操作
1. 创建数据库,使用命令是create
案例:
```mysql
# 创建数据库
CREATE DATABASE 数据库名称;
# 创建数据库,同时指定编码
create database db_name default charset="utf8mb4";
create database school DEFAULT CHARACTER SET utf8mb4;
create database school DEFAULT CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci;
# 查询当前数据库是哪个数据库
select database();
查看数据库版本
SELECT VERSION();
查看当前用户
SELECT USER();
查看所有用户
SELECT User,Host,Password FROM mysql.user;
# 查看创建的数据库
show create databsse 数据库名称;
create database db_chengke default charset=utf8mb4;
```
2. 删除数据库,使用drop命令
案例:
~~~sql
drop database 数据库名称;
drop database [if exists] db_chengke;
~~~
### utf8和utf8mb4的区别
MySQL在5.5.3之后增加了这个utf8mb4的编码,mb4就是most bytes 4的意思,专门用来兼容四字节的unicode。好在utf8mb4是utf8的超集,除了将编码改为utf8mb4外不需要做其他转换。当然,为了节省空间,一般情况下使用utf8也就够了。
既然utf8能够存下大部分中文汉字,那为什么还要使用utf8mb4呢? 原来mysql支持的 utf8 编码最大字符长度为 3 字节,如果遇到 4 字节的宽字符就会插入异常了。三个字节的 UTF-8 最大能编码的 Unicode 字符是 0xffff,也就是 Unicode 中的基本多文种平面(BMP)。也就是说,任何不在基本多文本平面的 Unicode字符,都无法使用 Mysql 的 utf8 字符集存储。包括 Emoji 表情(Emoji 是一种特殊的 Unicode 编码,常见于 ios 和 android 手机上),和很多不常用的汉字,以及任何新增的 Unicode 字符,如表情等等(utf8的缺点)。
因此在8.0之后,建议大家使用utf8mb4这种编码。
使用MySQL命令 `SHOW VARIABLES like 'character%'`。
使用MySQL命令“SHOW COLLATION;”即可查看当前MySQL服务实例支持的字符序。
MySQL字符序命名规则是:以字符序对应的字符集名称开头,以国家名居中(或以general居中),以ci、cs或bin结尾。
ci表示大小写不敏感,cs表示大小写敏感,bin表示按二进制编码值比较。
```
character_set_client:MySQL客户机字符集。
character_set_connection:数据通信链路字符集,当MySQL客户机向服务器发送请求时,请求数据以
该字符集进行编码。
character_set_database:数据库字符集。
character_set_filesystem:MySQL服务器文件系统字符集,该值是固定的binary。
character_set_results:结果集的字符集,MySQL服务器向MySQL客户机返回执行结果时,执行结果以
该字符集进行编码。
character_set_server:MySQL服务实例字符集。
character_set_system:元数据(字段名、表名、数据库名等) 的字符集,默认值为utf8。
```
默认为latin1字符集,如何更改为utf8:
```
方法:修改my.cnf配置文件,可修改MySQL默认的字符集,修改完毕重启MySQL
1.在[mysqld]下添加
default-character-set=utf8 #适合5.1及以前版本
(mysql 5.5及以后版本添加character-set-server=utf8)
init_connect = 'SET NAMES utf8'
2.在[client]下添加
default-character-set=utf8
3. 5.8开始,官方建议使用utf8mb4。
```
查看数据库编码情况:
~~~sql
show variables like "char%";
+--------------------------+-------------------------------------------------+
| Variable_name | Value |
+--------------------------+-------------------------------------------------+
| character_set_client | utf8mb4 |
| character_set_connection | utf8mb4 |
| character_set_database | utf8mb4 |
| character_set_filesystem | binary |
| character_set_results | utf8mb4 |
| character_set_server | utf8mb4 |
| character_set_system | utf8 |
| character_sets_dir | D:\dev_soft\mysql-8.0.20-winx64\share\charsets\ |
+--------------------------+-------------------------------------------------+
8 rows in set, 1 warning (0.00 sec)
~~~
## 数据库表的操作
数据表(table),是一种二维表格,类似于execel,用来存储真正的数据。
### 创建表格
~~~sql
-- 语法结构
create table [if not exists] t_name (
# 定义表结构
字段名称1 类型 [约束条件],
字段2 类型 [约束条件],
……
字段n 类型 [约束条件]
);
/**
创建一个用户表
用户的姓名
用户的年龄
用户的性别
用户的地址
用户的电话
**/
create table t_user (
id int,
name varchar(50),
age int,
gender char(5),
address varchar(255),
tel char(11)
);
# 查询表中的数据
select * from t_name;
# 插入数据
insert into t_name values(1, "刘建宏", 16, '男', "四川成都", "110");
mysql> show tables;
+----------------------+
| Tables_in_db_chengke |
+----------------------+
| t_name |
+----------------------+
1 row in set (0.00 sec)
mysql> select * from t_name;
Empty set (0.00 sec)
mysql> desc t_name;
+---------+--------------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+---------+--------------+------+-----+---------+-------+
| id | int | YES | | NULL | |
| name | varchar(50) | YES | | NULL | |
| age | int | YES | | NULL | |
| gender | char(5) | YES | | NULL | |
| address | varchar(255) | YES | | NULL | |
| tel | char(11) | YES | | NULL | |
+---------+--------------+------+-----+---------+-------+
6 rows in set (0.00 sec)
mysql> describe t_name;
+---------+--------------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+---------+--------------+------+-----+---------+-------+
| id | int | YES | | NULL | |
| name | varchar(50) | YES | | NULL | |
| age | int | YES | | NULL | |
| gender | char(5) | YES | | NULL | |
| address | varchar(255) | YES | | NULL | |
| tel | char(11) | YES | | NULL | |
+---------+--------------+------+-----+---------+-------+
6 rows in set (0.00 sec)
mysql> show create table t_name;
+--------+----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| Table | Create Table
|
+--------+----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| t_name | CREATE TABLE `t_name` (
`id` int DEFAULT NULL,
`name` varchar(50) DEFAULT NULL,
`age` int DEFAULT NULL,
`gender` char(5) DEFAULT NULL,
`address` varchar(255) DEFAULT NULL,
`tel` char(11) DEFAULT NULL
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci |
+--------+----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
1 row in set (0.00 sec)
mysql> show create table t_name\G
*************************** 1. row ***************************
Table: t_name
Create Table: CREATE TABLE `t_name` (
`id` int DEFAULT NULL,
`name` varchar(50) DEFAULT NULL,
`age` int DEFAULT NULL,
`gender` char(5) DEFAULT NULL,
`address` varchar(255) DEFAULT NULL,
`tel` char(11) DEFAULT NULL
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci
1 row in set (0.00 sec)
mysql> insert into t_name values(1, "刘建宏", 16, '男', "四川成都", "110");
Query OK, 1 row affected (0.01 sec)
mysql> select * from t_name;
+------+-----------+------+--------+--------------+------+
| id | name | age | gender | address | tel |
+------+-----------+------+--------+--------------+------+
| 1 | 刘建宏 | 16 | 男 | 四川成都 | 110 |
+------+-----------+------+--------+--------------+------+
1 row in set (0.00 sec)
~~~
> :warning: 注意:查询sql时,如果结果较多,查看不方便,则可以反正查询的结果,在sql后面加上`\G`
### 删除表格
~~~sql
drop table [if exists] t_name;
~~~
### 数据类型
数据库用来存储数据的,而数据存在很多类型,因此MySQL数据提供了很多类型,供开发者使用。
主要分为三大类:
1. 数值型
2. 字符串类型
3. 时间和日期类型
在 MySQL 中,有三种主要的类型:文本、数字和日期/时间类型。
**Text 类型:**
| 数据类型 | 描述 |
| ---------------- | ------------------------------------------------------------ |
| CHAR(size) | 保存固定长度的字符串(可包含字母、数字以及特殊字 符)。在括号中指定字符串的长度。最多 255 个字符。 |
| VARCHAR(size) | 保存可变长度的字符串(可包含字母、数字以及特殊字 符)。在括号中指定字符串的最大长度。最多 255 个字 符。 注释:如果值的长度大于 255,则被转换为 TEXT 类型。 |
| TINYTEXT | 存放最大长度为 255 个字符的字符串。 |
| TEXT | 存放最大长度为 65,535 个字符的字符串。 |
| BLOB | 用于 BLOBs (Binary Large OBjects)。存放最多 65,535 字节的数据。 |
| MEDIUMTEXT | 存放最大长度为 16,777,215 个字符的字符串。 |
| MEDIUMBLOB | 用于 BLOBs (Binary Large OBjects)。存放最多 16,777,215 字节的数据。 |
| LONGTEXT | 存放最大长度为 4,294,967,295 个字符的字符串。 |
| LONGBLOB | 用于 BLOBs (Binary Large OBjects)。存放最多 4,294,967,295 字节的数据。 |
| ENUM(x,y,z,etc.) | 允许你输入可能值的列表。可以在 ENUM 列表中列出最大 65535 个值。如果列表中不存在插入的值,则插入空值。 注释:这些值是按照你输入的顺序存储的。 可以按照此格式输入可能的值: ENUM('X','Y','Z') |
| SET | 与 ENUM 类似, SET 最多只能包含 64 个列表项,不过 SET 可存储一个以上的值。 |
**Number 类型:**
| 数据类型 | 描述 |
| --------------- | ------------------------------------------------------------ |
| TINYINT(size) | -128 到 127 常规。 0 到 255 无符号*。在括号中规定最 大位数。 |
| SMALLINT(size) | -32768 到 32767 常规。 0 到 65535 无符号*。在括号中 规定最大位数。 |
| MEDIUMINT(size) | -8388608 到 8388607 普通。 0 to 16777215 无符号*。在 括号中规定最大位数。 |
| INT(size) | -2147483648 到 2147483647 常规。 0 到 4294967295 无 符号*。在括号中规定最大位数。 |
| BIGINT(size) | -9223372036854775808 到 9223372036854775807 常规。 0 到18446744073709551615 无符号*。在括号中规定最大位 数。 |
| FLOAT(size,d) | 带有浮动小数点的小数字。在括号中规定最大位数。在 d 参数中规定小数点右侧的最大位数。 |
| DOUBLE(size,d) | 带有浮动小数点的大数字。在括号中规定最大位数。在 d 参数中规定小数点右侧的最大位数。 |
| DECIMAL(size,d) | 作为字符串存储的 DOUBLE 类型,允许固定的小数点。 |
注意:这些整数类型拥有额外的选项 UNSIGNED。通常,整数可以是负数或正数。如果添加 UNSIGNED属性,那么范围将从 0 开始,而不是某个负数。
**Date 类型:**
| 数据类型 | 描述 |
| ----------- | ------------------------------------------------------------ |
| DATE() | 日期。格式: YYYY-MM-DD 注释:支持的范围是从 '1000-01-01' 到 '9999-12-31' |
| DATETIME() | 日期和时间的组合。格式: YYYY-MM-DD HH:MM:SS 注释:支持的范围是'1000-01-01 00:00:00' 到 '9999-12- 31 23:59:59' |
| TIMESTAMP() | 时间戳。 TIMESTAMP 值使用 Unix 纪元('1970-01-01 00:00:00' UTC) 至今的描述来存储。格式: YYYY-MM-DD HH:MM:SS<br/>注释:支持的范围是从 '1970-01-01 00:00:01' UTC 到 '2038-01-09 03:14:07' UTC |
| TIME() | 时间。格式: HH:MM:SS 注释:支持的范围是从 '-838:59:59' 到 '838:59:59' |
| YEAR() | 2 位或 4 位格式的年。<br/>注释: 4 位格式所允许的值: 1901 到 2155。 2 位格式所允许 的值: 70 到69,表示从 1970 到 2069 |
**常用数据类型:**

### 数据库约束
创建数据库表的时候,`字段名称 该字段类型 [约束 [,……] ]`。
约束是在表上强制执行的数据校验规则。约束主要用于保证数据库的完整性。当表中数据有相互依赖性时,可以保护相关的数据不被删除。大部分数据库支持下面五类完整性约束:
存在如下一些数据库表的约束:
+ 默认值约束
+ 主键约束
+ 非空约束
+ 外键约束
+ 唯一约束
+ 检查约束 【MySQL8之前,不生效。MySQL8之后是支持检查约束】
#### 主键约束
主键从功能上看相当于**非空且唯一**,一个表中只允许一个主键,主键是表中唯一确定一行数据的字段。
一般建议主键采用“int类型”,一般建议由数据库自身维护这个字段的值。
当建立主键约束时,MySQL为主键创建对应的索引——主键索引,主键约束名总为PRIMARY。
~~~sql
create table t_user(
id int,
name varchar(50)
);
# 插入数据测试
insert into t_user values(1, "刘建宏");
insert into t_user values(1, "刘建宏");
select * from t_user;
drop table t_user;
create table t_user(
id int primary key, -- 主键约束
name varchar(50)
);
# 插入数据测试
insert into t_user values(1, "刘建宏");
insert into t_user values(1, "刘建宏");
insert into t_user values(null, "刘建宏");
insert into t_user values(2, "刘建宏");
drop table t_user;
create table t_user(
id int primary key auto_increment, -- 主键约束
name varchar(50)
);
# 插入数据测试
insert into t_user values(1, "刘建宏");
insert into t_user values(1, "刘建宏");
insert into t_user values(null, "刘建宏");
insert into t_user values(2, "刘建宏");
insert into t_user(name) value("刘帅哥");
-- 主键还存在一种写法
create table t_user(
id int auto_increment, -- 主键约束
name varchar(50),
primary key(id)
);
~~~
#### 唯一约束
唯一约束的作用,是保证该字段的值是唯一的,值不允许重复。
~~~sql
唯一性约束条件确保所在的字段或者字段组合不出现重复值
唯一性约束条件的字段允许出现一个NULL
同一张表内可建多个唯一约束
唯一约束可由多列组合而成
建唯一约束时MySQL会为之建立对应的索引——唯一索引。
如果不给唯一约束起名,该唯一约束默认与列名相同。
CREATE TABLE tb_student(
id INT PRIMARY KEY AUTO_INCREMENT,
NAME VARCHAR(18) UNIQUE -- 唯一约束
)
CREATE TABLE tb_student(
id INT AUTO_INCREMENT,
NAME VARCHAR(18), -- 唯一约束
PRIMARY KEY(id),
unique(name)
)
~~~
#### 默认值约束
给给定的字段,设置默认值。
~~~sql
create table t_user(
id int primary key auto_increment,
name varchar(50) unique,
age int
)
insert into t_user values(1, "刘建宏", 20);
insert into t_user(name, age) values("刘帅哥", 18);
insert into t_user values(null, "刘欧巴", 16); -- 因为存在自增,所以可以写null
insert into t_user values(default, "刘文理", 16); -- 因为存在自增,所以可以写默认
insert into t_user(name) values("张三");
insert into t_user(name) values("李四");
create table t_user(
id int primary key auto_increment,
name varchar(50) unique,
age int default 18 -- 默认值约束
);
insert into t_user values(1, "刘建宏", 20);
insert into t_user(name, age) values("刘帅哥", 18);
insert into t_user values(null, "刘欧巴", 16); -- 因为存在自增,所以可以写null
insert into t_user values(default, "刘文理", 16); -- 因为存在自增,所以可以写默认
insert into t_user(name) values("张三");
insert into t_user(name) values("李四");
~~~
#### 非空约束
不允许字段的值为空。
~~~sql
create table t_user(
id int primary key auto_increment,
name varchar(50) unique not null,
age int default 18 ,
password varchar(255) not null
);
insert into t_user values(1, "刘建宏", 20, "123456");
-- 报错
insert into t_user(name, age) values("刘帅哥", 18);
insert into t_user values(null, "刘欧巴", 16); -- 因为存在自增,所以可以写null
insert into t_user(name, age, password) values("刘帅哥", 18, "123456");
insert into t_user(name, password) values("张三", "123456");
~~~
#### 外键约束
暂时不讲,等讲解多表关联时,再讲解。
#### 检查约束
> :warning: 注意:检查约束在MySQL8之前是不生效的,当然也不报错。
>
> MySQL8之后,就支持了检查约束。
~~~sql
create table t_stu(
id int primary key auto_increment,
name varchar(50) not null unique,
age int check(age >= 18),
# gender char(2) check(gender in ("男", "女"))
gender enum("男", "女")
);
insert into t_stu value(null, "zs", 20, "女");
insert into t_stu value(null, "lisi", 10, "女");
insert into t_stu value(null, "lisi", 18, "女");
insert into t_stu value(null, "ww", 28, "哈");
~~~
### 修改表的结构
在sql中,也提供了动态修改表结构的sql功能。
使用`alter`指令,实现对**数据库对象**的结构的调整和修改。
~~~sql
修改列类型
ALTER TABLE 表名 MODIFY 列名 列类型; -- 注意存在值的情况,类型不一定能成功
增加列
ALTER TABLE 表名 ADD 列名 列类型;
删除列
ALTER TABLE 表名 DROP 列名;
列改名
ALTER TABLE 表名 CHANGE 旧列名 新列名 列类型;
更改表名
ALTER TABLE 表名 RENAME 新表名;
RENAME TABLE 表名 TO 新表名;
案例:
alter table t_user add mark int default 0;
alter table t_user modify mark varchar(10);
alter table t_user modify mark int;
alter table t_user add test int;
alter table t_user drop test;
alter table t_user change test address varchar(255);
alter table t_user rename user;
rename table user to t_user;
~~~
### 复制表结构和内容
~~~
复制一个表结构的实现方法有两种
方法一:在create table语句的末尾添加like子句,可以将源表的表结构复制到新表中,语法格式如下。
create table 新表名 like 源表
方法二:在create table语句的末尾添加一个select语句,可以实现表结构的复制,甚至可以将源表的表
记录拷贝到新表中。下面的语法格式将源表的表结构以及源表的所有记录拷贝到新表中。
create table 新表名 select * from 源表
方法三:如果已经存在一张机构一致的表,复制数据
insert into 表 select * from 原表;
~~~
案例:
~~~sql
mysql> create table user like t_user;
Query OK, 0 rows affected (0.06 sec)
mysql> show tables;
+----------------------+
| Tables_in_db_chengke |
+----------------------+
| t_stu |
| t_user |
| user |
+----------------------+
3 rows in set (0.00 sec)
mysql> desc user;
+----------+--------------+------+-----+---------+----------------+
| Field | Type | Null | Key | Default | Extra |
+----------+--------------+------+-----+---------+----------------+
| id | int | NO | PRI | NULL | auto_increment |
| name | varchar(50) | NO | UNI | NULL | |
| age | int | YES | | 18 | |
| password | varchar(255) | NO | | NULL | |
| mark | varchar(10) | YES | | NULL | |
| address | varchar(255) | YES | | NULL | |
+----------+--------------+------+-----+---------+----------------+
6 rows in set (0.00 sec)
mysql> select * from user;
Empty set (0.00 sec)
mysql> select * from t_user;
+----+-----------+------+----------+-----------+---------+
| id | name | age | password | mark | address |
+----+-----------+------+----------+-----------+---------+
| 1 | 刘建宏 | 20 | 123456 | 0 | NULL |
| 2 | 刘帅哥 | 18 | 123456 | 0 | NULL |
| 3 | 张三 | 18 | 123456 | 0 | NULL |
| 4 | hehe | 20 | 122 | 刘建宏 | NULL |
+----+-----------+------+----------+-----------+---------+
4 rows in set (0.00 sec)
mysql> create table user select * from t_user;
Query OK, 4 rows affected (0.04 sec)
Records: 4 Duplicates: 0 Warnings: 0
mysql> show tables;
+----------------------+
| Tables_in_db_chengke |
+----------------------+
| t_stu |
| t_user |
| user |
+----------------------+
3 rows in set (0.00 sec)
mysql> select * from user;
+----+-----------+------+----------+-----------+---------+
| id | name | age | password | mark | address |
+----+-----------+------+----------+-----------+---------+
| 1 | 刘建宏 | 20 | 123456 | 0 | NULL |
| 2 | 刘帅哥 | 18 | 123456 | 0 | NULL |
| 3 | 张三 | 18 | 123456 | 0 | NULL |
| 4 | hehe | 20 | 122 | 刘建宏 | NULL |
+----+-----------+------+----------+-----------+---------+
4 rows in set (0.00 sec)
mysql> desc user;
+----------+--------------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+----------+--------------+------+-----+---------+-------+
| id | int | NO | | 0 | |
| name | varchar(50) | NO | | NULL | |
| age | int | YES | | 18 | |
| password | varchar(255) | NO | | NULL | |
| mark | varchar(10) | YES | | NULL | |
| address | varchar(255) | YES | | NULL | |
+----------+--------------+------+-----+---------+-------+
6 rows in set (0.00 sec)
create table user select id, name, mark from t_user;
-- 将查询的数据快速插入到表中
insert into user select * from user;
~~~
+ 如果直接复制表结构,则会默认将约束也复制过来
+ 如果复制表结构的同时,复制数据,则不会复制约束
### 数据库字典
~~~sql
由information_schema数据库负责维护
tables-存放数据库里所有的数据表、以及每个表所在数据库。
schemata-存放数据库里所有的数据库信息
views-存放数据库里所有的视图信息。
columns-存放数据库里所有的列信息。
triggers-存放数据库里所有的触发器。
routines-存放数据库里所有存储过程和函数。
key_column_usage-存放数据库所有的主外键
table_constraints-存放数据库全部约束。
statistics-存放了数据表的索引。
~~~
### MySQL用户授权
#### 密码策略
mysql升级5.7版本以后,安全性大幅度上升。
MySQL5.7为root用户随机生成了一个密码,打印在error_log中,关于error_log的位置,如果安装的是RPM包,则默认是 /var/log/mysqld.log 。
```shell
awk '/temporary password/ {print $NF}' /var/log/mysqld.log
# or
grep 'password' /var/log/mysqld.log
```
查看数据库当前密码策略:
```mysql
show VARIABLES like "%password%";
```
查看密码插件:
```mysql
SHOW VARIABLES LIKE 'validate_password%';
```
官方文档策略定义:
| Policy | Tests Performed |
| ------------ | ------------------------------------------------------------ |
| 0 or LOW | Length |
| 1 or MEDIUM | Length; numeric, lowercase/uppercase, and special characters |
| 2 or STRONG | Length; numeric, lowercase/uppercase, and special characters; dictionary file |
更改密码策略:
方法1:临时修改:
```mysql
更改密码策略为LOW,改为LOW或0
mysql> SET GLOBAL validate_password_policy='LOW';
Query OK, 0 rows affected (0.01 sec)
更改密码长度
mysql> SET GLOBAL validate_password_length=0;
Query OK, 0 rows affected (0.00 sec)
设置大小写、数字和特殊字符均不要求。
mysql> SET GLOBAL validate_password_special_char_count=0;
Query OK, 0 rows affected (0.00 sec)
mysql> SET GLOBAL validate_password_mixed_case_count=0;
Query OK, 0 rows affected (0.00 sec)
mysql> SET GLOBAL validate_password_number_count=0;
Query OK, 0 rows affected (0.00 sec)
查看:
mysql> SET GLOBAL validate_password_length=0;
Query OK, 0 rows affected (0.00 sec)
mysql> SHOW VARIABLES LIKE 'validate_password%';
+--------------------------------------+-------+
| Variable_name | Value |
+--------------------------------------+-------+
| validate_password_dictionary_file | |
| validate_password_length | 0 |
| validate_password_mixed_case_count | 0 |
| validate_password_number_count | 0 |
| validate_password_policy | LOW |
| validate_password_special_char_count | 0 |
+--------------------------------------+-------+
6 rows in set (0.00 sec)
测试:
mysql> drop user test1@localhost;
Query OK, 0 rows affected (0.00 sec)
```
方法2:初始化时不启用,只需要在初始化时指定 --initialize-insecure 即可,比如:
```mysql
mysqld --initialize-insecure --datadir=/var/lib/mysql --basedir=/usr --user=mysql
```
方法3:修改配置文件
在 /etc/my.cnf 配置文件中增加:
```ini
[mysqld]
validate_password=off
```
修改完毕,重启服务
#### 开启用户的远程登录
注意:MySQL官方是禁止root账号远程登录的!!!
所以在真实的生产环境下,如果没有必要,不建议开启root账号的远程登录。
如果要开启某个账号的远程登录呢?
首先,开启远程登录,必须保证你登录的账号是存在高级权限,一般是root。
登录MySQL,之后,访问`mysql`数据库。
```mysql
use mysql
select host, user from user;
select host, user from mysql.user;
# 发相host是localhost,则修改为% 或者需要的IP地址,或者进行动态匹配
update user set host="192.168.1.10%" where user="ljh";
update user set host="%" where user="ljh";
# 此时修改成功,要让权限生效,必须重启服务
# 如果不想重启服务,可以刷新权限
flush privileges;
```
#### 用户创建和授权
在MySQL8之前,MySQL的`grant`命令非常强大,是集授权、创建用户、修改密码、修改用户远程登录等等一系列功能与一体的命令。
~~~sql
GRANT all ON db_chengke.* TO zs@'%' IDENTIFIED BY '123456';
~~~
在MySQL8之后,MySQL不再允许grant命令创建用户,也就说,要为某一个用户授权,必须先常见这个账号。
```mysql
create user '用户名称'@'%' DENTIFIED BY '123456';
create user zs@'%' identified by "zs";
```
给已经创建的用户授权:
~~~sql
方法1:create和grant结合
help CREATE USER;
命令:CREATE USER <'用户名'@'地址'> IDENTIFIED BY ‘密码’;
查看用户权限: help SHOW GRANTS;
命令:show grants for '用户名'@'地址';
授权:help GRANT;
方法2:直接grant
收回权限:REVOKE
删除用户:DROP USER username
生产环境授权用户建议:
1、博客,CMS等产品的数据库授权
select,insert,update,delete,create
库生成后收回create权限
2、生产环境主库用户授权
select,insert,update,delete
3、生产环境从库授权
select
创建用户方法(推荐使用方法三):
方法一:CREATE USER语句创建
CREATE USER user1@’localhost’ IDENTIFIED BY ‘123456’;
方法二: INSERT语句创建
INSERT INTO mysql.user(user,host, authentication_string,ssl_cipher,
x509_issuer,x509_subject)
VALUES('user2','localhost',password('ABCabc123!'),'','','');
FLUSH PRIVILEGES;
方法三: GRANT语句创建
GRANT SELECT ON *.* TO user3@’localhost’ IDENTIFIED BY ‘123456’;
FLUSH PRIVILEGES;
语法格式:
grant 权限列表 on 库名.表名 to 用户名@'客户端主机'
[identified by '密码' with option参数];
如:
grant select on testdb.* to common_user@'%'
grant insert on testdb.* to common_user@'%'
grant update on testdb.* to common_user@'%'
grant delete on testdb.* to common_user@'%'
grant select, insert, update, delete on testdb.* to common_user@'%'
grant create on testdb.* to developer@'192.168.0.%';
grant alter on testdb.* to developer@'192.168.0.%';
grant drop on testdb.* to developer@'192.168.0.%';
grant all on *.* to dba@localhost; -- dba 可以管理 MySQL 中的所有数据库
show grants; -- 查看当前用户(自己)权限
show grants for dba@localhost;
grant all on *.* to dba@localhost;
# 移除权限
# revoke 跟 grant 的语法差不多,只需要把关键字 “to” 换成 “from” 即可
revoke all on *.* from dba@localhost;
with_option参数
GRANT OPTION: 授权选项
MAX_QUERIES_PER_HOUR: 定义每小时允许执行的查询数
MAX_UPDATES_PER_HOUR: 定义每小时允许执行的更新数
MAX_CONNECTIONS_PER_HOUR: 定义每小时可以建立的连接数
MAX_USER_CONNECTIONS: 定义单个用户同时可以建立的连接数
grant all on db_chengke.* to zs@"%";
flush privileges;
~~~
撤销权限
~~~sql
# 移除权限
# revoke 跟 grant 的语法差不多,只需要把关键字 “to” 换成 “from” 即可
revoke all on *.* from dba@localhost;
~~~
# 第四章 sql之DML
数据库使用时,大多数情况下,开发者只会操作数据,也是就增删改查(CRUD)。
是核心,是任何一个IT人士必备技能。
增删改查四条语句,最重要的是**查询(DQL)**。
有关数据表的DML操作
INSERT INTO
DELETE、TRUNCATE
UPDATE
SELECT
条件查询
查询排序
聚合函数
分组查询
## 增加语句
增加语言,就是给某张表进行数据插入。
语法:
~~~sql
insert INTO table_name[(field1 [, field2 ……]) values(value1 [, vaule2 ……]) [,()]];
~~~
案例:
~~~sql
INSERT INTO t_user value(null, "刘建宏1", 16, "123456", null, null);
insert into t_user(name, password) values("刘建宏5", "hehhehe");
insert into t_user(password, name) values("liujianhong", "刘建宏5");
-- 插入多条数据
insert into t_user(name, password) value("城科1", "chengke"), ("城科2", "chengke");
~~~
## 删除语句和TRUNCATE
删除语言,请注意删除的条件!!!如果不带条件,则删除全表。
语法结构:
~~~sql
delete from table_name [where 条件];
truncate table table_name;
~~~
案例如下:
~~~sql
delete from t_user where id=4;
-- 如果没有条件,则清空全表数据【慎重!!】
delete from user;
-- truncate清空全表[注意:truncate删除数据是不经过数据字典]
truncate table students;
~~~
## 更新语句
更新就是修改表中的数据。
语法结构
~~~sql
update table_name set 字段1=新值 [, 字段2=新值, 字段3=字段3 + 1] [where 条件];
~~~
案例:
~~~sql
update t_user set age = 30 where id = 1;
update t_user set age = 20, password="root" where id = 2;
update t_user set age = age + 1 ;
~~~
## replace语句
该语句是集更新和插入为一体的一个语句。
如果表中没有这条数据,则执行插入,否则执行更新。
~~~sql
replace into t_user(id, name, password) values(100, "test", "test");
replace into t_user(id, name, password) values(100, "testtest", "testtest");
~~~
> :warning: 注意:replace的更新,本质是先删除,再插入。
## select查询语句
在开发中,查询语句是使用最多,也是CRUD中,复杂度最高的sql语句。
查询的语法结构
~~~sql
select *|字段1 [, 字段2 ……] from 表名称 [, 表名称2……] [where 条件] [group by 字段 [having 分组后的筛选]] [order by 字段 [desc|asc] [字段2 [desc|asc] ……]] [limit 分页]
~~~
### 简单的sql查询
~~~sql
-- 查询所有数据
select * from t_user;
-- 查询需要的字段信息
select id, name, password from t_user;
-- 查询一个字段,一个等值条件
select name from t_user where id = 1;
select 字段列表
from 表名称
where 条件
/*
等值查询
*/
select password from t_user where name="刘建宏";
select * from t_user where age = 19;
alter table t_user add birthday datetime default now();
select * from t_user where birthday='2025-03-13 20:52:12';
~~~
select语句中的特殊情况:
~~~sql
对数值型数据列、变量、常量可以使用算数操作符创建表达式(+ - * /)
对日期型数据列、变量、常量可以使用部分算数操作符创建表达式(+ -)
运算符不仅可以在列和常量之间进行运算,也可以在多列之间进行运算。
SELECT last_name, salary, salary*12
FROM employees;
补充:+ 说明
-- MySQL的+默认只有一个功能:运算符
SELECT 100+80; # 结果为180
SELECT '123'+80; # 只要其中一个为数值,则试图将字符型转换成数值,转换成功做预算,结果为203
SELECT 'abc'+80; # 转换不成功,则字符型数值为0,结果为80
SELECT 'This'+'is'; # 转换不成功,结果为0
SELECT 'This'+'30is'; # ?猜测下这个结果是多少?
SELECT NULL+80; # 只要其中一个为NULL,则结果为NULL
~~~
### 等值判断
条件中,出现了相等值的判断,一般采用`=`进行判断。
+ `=` 判断两次的值是否相等
+ `is` 判断空null
+ `is not null`来判断不为空
+ `<=>` 可以判断null或者普通值
### 不等判断
+ `!=` 不等于
+ `<>`也是不等于
### 逻辑运算符
逻辑运算符是多条件关联的一种方式。
> 与或非
+ and
+ or
+ not
> 注意:在sql中,如果要提升条件的运行顺序,或者提高条件的优先级别,则需要使用括号来提升。
### 查询时的别名使用
查询时,将结果的显示字段,使用一个其他名称来代替,就是别名。
~~~sql
mysql> select count(*) from t_user;
+----------+
| count(*) |
+----------+
| 10 |
+----------+
1 row in set (0.00 sec)
mysql> select * from t_user;
+-----+-------------+------+-------------+------+---------+---------------------+
| id | name | age | password | mark | address | birthday |
+-----+-------------+------+-------------+------+---------+---------------------+
| 1 | 刘建宏 | 31 | 123456 | 0 | NULL | 2025-03-13 20:52:12 |
| 2 | 刘帅哥 | 21 | root | 0 | NULL | 2025-03-13 20:52:12 |
| 3 | 张三 | 19 | 123456 | 0 | NULL | 2025-03-13 20:52:12 |
| 5 | 刘建宏1 | 17 | 123456 | NULL | NULL | 2025-03-13 20:52:12 |
| 6 | 刘建宏2 | 17 | 123456 | NULL | NULL | 2025-03-13 20:52:12 |
| 7 | 刘建宏5 | 19 | hehhehe | NULL | NULL | 2025-03-13 20:52:12 |
| 9 | 刘建宏56 | 19 | liujianhong | NULL | NULL | 2025-03-13 20:52:12 |
| 10 | 城科1 | 19 | chengke | NULL | NULL | 2025-03-13 20:52:12 |
| 11 | 城科2 | 19 | chengke | NULL | NULL | 2025-03-13 20:52:12 |
| 100 | testtest | 18 | testtest | NULL | NULL | 2025-03-13 20:52:12 |
+-----+-------------+------+-------------+------+---------+---------------------+
10 rows in set (0.00 sec)
mysql> select count(*) as c from t_user;
+----+
| c |
+----+
| 10 |
+----+
1 row in set (0.00 sec)
mysql> select count(*) as count from t_user;
+-------+
| count |
+-------+
| 10 |
+-------+
1 row in set (0.00 sec)
mysql> select count(*) as 总人数 from t_user;
+-----------+
| 总人数 |
+-----------+
| 10 |
+-----------+
1 row in set (0.00 sec)
mysql> select count(*) 总人数 from t_user;
+-----------+
| 总人数 |
+-----------+
| 10 |
+-----------+
1 row in set (0.00 sec)
~~~
### 常见的条件查询
~~~sql
使用WHERE子句限定返回的记录
WHERE子句在FROM 子句后
SELECT[DISTINCT] {*, column [alias], ...}
FROM table–[WHEREcondition(s)];
WHERE中的字符串和日期值
字符串和日期要用单引号扩起来
字符串是大小写敏感的,日期值是格式敏感的
SELECT last_name, job_id, department_id
FROM employees
WHERE last_name = "king";
WHERE中比较运算符:
SELECT last_name, salary, commission_pct
FROM employees
WHERE salary<=1500;
其他比较运算符
使用BETWEEN运算符显示某一值域范围的记录
SELECTlast_name, salary
FROM employees
WHERE salary BETWEEN 1000 AND 1500;
使用IN运算符
使用IN运算符获得匹配列表值的记录
SELECTemployee_id, last_name, salary, manager_id
FROM employees
WHERE manager_id IN (7902, 7566, 7788);
使用LIKE运算符
使用LIKE运算符执行模糊查询
查询条件可包含文字字符或数字
(%) 可表示零或多个字符
( _ ) 可表示一个字符
SELECT last_name
FROM employees
WHERE last_name LIKE '_A%';
使用IS NULL运算符
查询包含空值的记录
SELECT last_name, manager_id
FROM employees
WHERE manager_id IS NULL;
逻辑运算符
使用AND运算符
AND需要所有条件都是满足T.
SELECT employee_id, last_name, job_id, salary
FROM employees
WHERE salary>=1100–4 AND job_id='CLERK';
使用OR运算符
OR只要两个条件满足一个就可以
SELECT employee_id, last_name, job_id, salary
FROM employees
WHERE salary>=1100 OR job_id='CLERK';
使用NOT运算符
NOT是取反的意思
SELECT last_name, job_id
FROM employees
WHERE job_id NOT IN ('CLERK','MANAGER','ANALYST');
使用正则表达式:REGEXP
<列名> regexp '正则表达式'
select * from product where product_name regexp '^2018';
~~~
### 分组
sql中,分组是一种统计概念。查询的数据,进行数据分析时,可能需要将相同的数据分成一组。
条件后面,当然是存在条件时,不过不存在,则是表名称后面
`group by 字段`。
~~~sql
select gender from t_user group by gender;
+--------+
| gender |
+--------+
| 女 |
| 男 |
+--------+
2 rows in set (0.00 sec)
select gender, count(gender) from t_user group by gender;
+--------+---------------+
| gender | count(gender) |
+--------+---------------+
| 女 | 5 |
| 男 | 5 |
+--------+---------------+
2 rows in set (0.00 sec)
~~~
> :warning: 注意:分组查询时,查询字段必须是分组的字段,或者是**聚合函数**。
### 分组后的筛选
发现,如果直接在分组后的结果集上进行条件判断,将条件写在where中,会报错,因为:结果集是分组后才能做的判断,而where实在查询前的条件判断。
所以不能使用where,必须使用having。
再次强调,having必须写在group by之后!!!没有分组,就不能写having,但是分组可以没有having。
~~~sql
select gender, count(gender) from t_user group by gender having count(gender) > 5;
+--------+---------------+
| gender | count(gender) |
+--------+---------------+
| 女 | 6 |
+--------+---------------+
1 row in set (0.00 sec)
~~~
### 结果排序
将查询结果,以特定的顺序展示(升序或者降序)。
~~~sql
# 语法结构
order by 字段
order by 字段 asc|desc;
order by 字段 asc|desc, 字段2 ;
mysql> select * from t_user order by age;
+-----+-------------+------+-------------+------+---------+---------------------+--------+
| id | name | age | password | mark | address | birthday | gender |
+-----+-------------+------+-------------+------+---------+---------------------+--------+
| 5 | 刘建宏1 | 17 | 123456 | NULL | NULL | 2025-03-13 20:52:12 | 女 |
| 6 | 刘建宏2 | 17 | 123456 | NULL | NULL | 2025-03-13 20:52:12 | 女 |
| 100 | testtest | 18 | testtest | NULL | NULL | 2025-03-13 20:52:12 | 女 |
| 101 | 李四 | 18 | 123123 | NULL | NULL | 2025-03-18 19:38:26 | 女 |
| 3 | 张三 | 19 | 123456 | 0 | NULL | 2025-03-13 20:52:12 | 男 |
| 7 | 刘建宏5 | 19 | hehhehe | NULL | NULL | 2025-03-13 20:52:12 | 男 |
| 9 | 刘建宏56 | 19 | liujianhong | NULL | NULL | 2025-03-13 20:52:12 | 男 |
| 10 | 城科1 | 19 | chengke | NULL | NULL | 2025-03-13 20:52:12 | 男 |
| 11 | 城科2 | 19 | chengke | NULL | NULL | 2025-03-13 20:52:12 | 男 |
| 2 | 刘帅哥 | 21 | root | 0 | NULL | 2025-03-13 20:52:12 | 女 |
| 1 | 刘建宏 | 31 | 123456 | 0 | NULL | 2025-03-13 20:52:12 | 女 |
+-----+-------------+------+-------------+------+---------+---------------------+--------+
11 rows in set (0.00 sec)
mysql> select * from t_user order by age asc;
+-----+-------------+------+-------------+------+---------+---------------------+--------+
| id | name | age | password | mark | address | birthday | gender |
+-----+-------------+------+-------------+------+---------+---------------------+--------+
| 5 | 刘建宏1 | 17 | 123456 | NULL | NULL | 2025-03-13 20:52:12 | 女 |
| 6 | 刘建宏2 | 17 | 123456 | NULL | NULL | 2025-03-13 20:52:12 | 女 |
| 100 | testtest | 18 | testtest | NULL | NULL | 2025-03-13 20:52:12 | 女 |
| 101 | 李四 | 18 | 123123 | NULL | NULL | 2025-03-18 19:38:26 | 女 |
| 3 | 张三 | 19 | 123456 | 0 | NULL | 2025-03-13 20:52:12 | 男 |
| 7 | 刘建宏5 | 19 | hehhehe | NULL | NULL | 2025-03-13 20:52:12 | 男 |
| 9 | 刘建宏56 | 19 | liujianhong | NULL | NULL | 2025-03-13 20:52:12 | 男 |
| 10 | 城科1 | 19 | chengke | NULL | NULL | 2025-03-13 20:52:12 | 男 |
| 11 | 城科2 | 19 | chengke | NULL | NULL | 2025-03-13 20:52:12 | 男 |
| 2 | 刘帅哥 | 21 | root | 0 | NULL | 2025-03-13 20:52:12 | 女 |
| 1 | 刘建宏 | 31 | 123456 | 0 | NULL | 2025-03-13 20:52:12 | 女 |
+-----+-------------+------+-------------+------+---------+---------------------+--------+
11 rows in set (0.00 sec)
mysql> select * from t_user order by age desc;
+-----+-------------+------+-------------+------+---------+---------------------+--------+
| id | name | age | password | mark | address | birthday | gender |
+-----+-------------+------+-------------+------+---------+---------------------+--------+
| 1 | 刘建宏 | 31 | 123456 | 0 | NULL | 2025-03-13 20:52:12 | 女 |
| 2 | 刘帅哥 | 21 | root | 0 | NULL | 2025-03-13 20:52:12 | 女 |
| 3 | 张三 | 19 | 123456 | 0 | NULL | 2025-03-13 20:52:12 | 男 |
| 7 | 刘建宏5 | 19 | hehhehe | NULL | NULL | 2025-03-13 20:52:12 | 男 |
| 9 | 刘建宏56 | 19 | liujianhong | NULL | NULL | 2025-03-13 20:52:12 | 男 |
| 10 | 城科1 | 19 | chengke | NULL | NULL | 2025-03-13 20:52:12 | 男 |
| 11 | 城科2 | 19 | chengke | NULL | NULL | 2025-03-13 20:52:12 | 男 |
| 100 | testtest | 18 | testtest | NULL | NULL | 2025-03-13 20:52:12 | 女 |
| 101 | 李四 | 18 | 123123 | NULL | NULL | 2025-03-18 19:38:26 | 女 |
| 5 | 刘建宏1 | 17 | 123456 | NULL | NULL | 2025-03-13 20:52:12 | 女 |
| 6 | 刘建宏2 | 17 | 123456 | NULL | NULL | 2025-03-13 20:52:12 | 女 |
+-----+-------------+------+-------------+------+---------+---------------------+--------+
11 rows in set (0.00 sec)
mysql> select * from t_user order by age , id desc;
+-----+-------------+------+-------------+------+---------+---------------------+--------+
| id | name | age | password | mark | address | birthday | gender |
+-----+-------------+------+-------------+------+---------+---------------------+--------+
| 6 | 刘建宏2 | 17 | 123456 | NULL | NULL | 2025-03-13 20:52:12 | 女 |
| 5 | 刘建宏1 | 17 | 123456 | NULL | NULL | 2025-03-13 20:52:12 | 女 |
| 101 | 李四 | 18 | 123123 | NULL | NULL | 2025-03-18 19:38:26 | 女 |
| 100 | testtest | 18 | testtest | NULL | NULL | 2025-03-13 20:52:12 | 女 |
| 11 | 城科2 | 19 | chengke | NULL | NULL | 2025-03-13 20:52:12 | 男 |
| 10 | 城科1 | 19 | chengke | NULL | NULL | 2025-03-13 20:52:12 | 男 |
| 9 | 刘建宏56 | 19 | liujianhong | NULL | NULL | 2025-03-13 20:52:12 | 男 |
| 7 | 刘建宏5 | 19 | hehhehe | NULL | NULL | 2025-03-13 20:52:12 | 男 |
| 3 | 张三 | 19 | 123456 | 0 | NULL | 2025-03-13 20:52:12 | 男 |
| 2 | 刘帅哥 | 21 | root | 0 | NULL | 2025-03-13 20:52:12 | 女 |
| 1 | 刘建宏 | 31 | 123456 | 0 | NULL | 2025-03-13 20:52:12 | 女 |
+-----+-------------+------+-------------+------+---------+---------------------+--------+
11 rows in set (0.00 sec)
select age, count(*) as c from t_user where age > 10 group by age having count(age) > 1 order by age desc, c asc;
~~~
### 分页功能
select语句,查询数据时,可能结果会非常多,此时就不能直接展示,分页展示。
总数量(all_data):查询 select count(*)
每页展示的数量(page_size):程序员定
当前页(cur_page):默认第一页,用户自己点击选择
总页数(all_page):总数量 % 每页的数量 == 0 整除后的商 : 商 + 1
~~~sql
limit num # 查询多少条
limit num1, num2; # num1: 偏移量, num2 : 每页的数量
limit cur_page * (page_size - 1), page_size;
~~~
### 为什么分表
数据直接都存储在一张表中:
+ 如果数据很大,性能会出现问题
+ 将不同的数据,如果放在同一个表中,可能数据冗余
+ 数据冗余,会导致数据可能出错
将不同的类型,采用不同的数据表进行存储,如果两张表或者多张表之间存在关联关系,则可以采用外键来描述这种关联关系。
主表中,一般是一个字段,改字段一般是从表的主键。
~~~sql
create table grade(
id int auto_increment,
name varchar(50) unique,
primary key(id)
)
insert into grade(name) value("Java精品班"), ("python数据分析班"), ("网络安全班"), ("云原生高级班");
create table student(
-> id int primary key auto_increment,
-> name varchar(50) unique,
-> gender enum("F", "M"),
-> age int default 18,
-> adddress varchar(255),
-> class_id int
-> );
Query OK, 0 rows affected (0.06 sec)
mysql> desc student;
+----------+---------------+------+-----+---------+----------------+
| Field | Type | Null | Key | Default | Extra |
+----------+---------------+------+-----+---------+----------------+
| id | int | NO | PRI | NULL | auto_increment |
| name | varchar(50) | YES | UNI | NULL | |
| gender | enum('F','M') | YES | | NULL | |
| age | int | YES | | 18 | |
| adddress | varchar(255) | YES | | NULL | |
| class_id | int | YES | | NULL | |
+----------+---------------+------+-----+---------+----------------+
6 rows in set (0.00 sec)
insert into student(name, class_id) values("张三", 1);
insert into student(name, class_id) values("张三2", 2);
insert into student(name, class_id) values("张三3", 1);
insert into student(name, class_id) values("张三4", 3);
insert into student(name, class_id) values("张三5", 1);
insert into student(name, class_id) values("张三6", 4);
-- 此时,插入了一条错误数据,该数据描述的外键不存在,是一条脏数据!!!
insert into student(name, class_id) values("张三666", 44);
# 如果要避免出现这种情况,必须加入外键约束!!
~~~
### 外键和多表关联
外键:指的是两张或者多张表之间关联关系的字段。
外键约束:是表的约束,是约束表在插入外键数据时能够正确的插入。
如何添加约束:
~~~sql
# 在创建表的同时,将外键约束添加上去
# 首先保证班级表创建成功
# 插入正确的数据
create table grade(
id int auto_increment,
name varchar(50) unique,
primary key(id)
)
insert into grade(name) value("Java精品班"), ("python数据分析班"), ("网络安全班"), ("云原生高级班");
外键约束
外键是构建于一个表的两个字段或者两个表的两个字段之间的关系
外键确保了相关的两个字段的两个关系:
子(从)表外键列的值必须在主表参照列值的范围内,或者为空(也可以加非空约束,强制不允许为空)。
当主表的记录被子表参照时,主表记录不允许被删除。
外键参照的只能是主表主键或者唯一键,保证子表记录可以准确定位到被参照的记录。
ALTER TABLE 表名 ADD CONSTRAINT 外键名 FOREIGN KEY(外键字段名)
REFERENCES 外表表名(主键字段名)
[ON DELETE {RESTRICT | CASCADE | SET NULL | NO ACTION | SET DEFAULT}]
[ON UPDATE {RESTRICT | CASCADE | SET NULL | NO ACTION | SET DEFAULT}]
格式FOREIGN KEY (外键列名)REFERENCES 主表(参照列)
~~~
### 表与表之间的关联关系
当表与表之间存在了外键,这就意味着,这两张表之间存在某种关联关系。
一旦表存在了关联关系,则会进行外键设计,如果设计外键,将外键设计在哪张表中?
+ 一对一 :外键可以设计在任意一张表中
+ 一对多 :外键必须设计在多方
+ 多对多 :创建第三张表,来专门描述两张表的关联关系
### 多表关联查询
当两张或者多张表之间存在了关联关系,往往多表查询,如果查询。
+ 交叉连接
+ 内连接
+ 外链接
+ 左外连接
+ 右外连接
+ 自连接
+ 全连接
+ 自然连接 【不建议使用,直到就行】数据库自动使用相同字段名称完成外键关联
~~~sql
select *|字段 [,……] from 表名称 [,表名称] ……
~~~
~~~sql
-- 交叉连接(cross join)
-- 在查询多表时,不指定表的关联关系,数据只能全部匹配
-- 引发笛卡尔积现象
select * from student, grade;
-- sql98的标准写法
select * from student cross join grade;
# 内连接
select * from student, grade where student.class_id = grade.id;
select * from student, grade where student.class_id = grade.id and student.name = '张三';
# 注意:sql98的内连接方式时,如果不指定关联条件,不管怎么写,都是交叉连接
select * from student inner join grade;
select * from student join grade;
# 正确写法,必须写清楚关联条件
select * from student inner join grade on (student.class_id=grade.id);
select * from student join grade on (student.class_id=grade.id) where student.name = "张三3";
# 内连接,只能查询出,存在关联关系的数据,如果不存在关联关系,如目前没有班级的学生,目前没有学生的班级
select * from student cross join grade on (student.class_id=grade.id) where student.name = "张三3";
# 如果要将这些没关联关系的数据查询出来,则需要使用外连接
select * from student left join grade on (student.class_id=grade.id);
select * from student right join grade on (student.class_id=grade.id);
# 注意:mysql不支持全连接查询 full join
# 但是SQL存在联合查询 union 、union all
# 注意:联合查询,必须保证查询的多条SQL返回的结果 结构必须一致,所以联合查询常见于查询一张表
(select * from student where class_id = "1") union (select id, name from student where id > 3);
(select * from student where class_id = "1") union all (select * from student where id > 3);
# 自连接查询
# 表的外键指向自身
create table board (
id int primary key auto_increment,
name varchar(50) unique not null,
intro text,
parent_id int,
foreign key(parent_id) references board(id)
);
insert into board(name, parent_id) values("前端板块", null);
insert into board(name, parent_id) values("后端板块", null);
insert into board(name, parent_id) values("硬件板块", null);
insert into board(name, parent_id) values("html", 1);
insert into board(name, parent_id) values("css", 1);
insert into board(name, parent_id) values("java", 2);
insert into board(name, parent_id) values("python", 2);
insert into board(name, parent_id) values("嵌入式", 3);
insert into board(name, parent_id) values("python基础", 7);
insert into board(name, parent_id) values("django", 7);
insert into board(name, parent_id) values("python GUI开发", 7);
insert into board(name, parent_id) values("css2", 5);
insert into board(name, parent_id) values("css3", 5);
select name from board where parent_id is null;
select name from board where parent_id = (select id from board where name = "前端板块");
select * from board as b, (select id from board where name = "前端板块") as t where b.parent_id = t.id;
select name from (select * from board where parent_id is not null) as t where t.parent_id in (1, 2, 3);
~~~
## SQL中函数
SQL中默认提供很多系统内置函数,帮助开发者实现各种需要的功能。
### 聚合函数
```mysql
聚合函数对一组值进行运算,并返回单个值。也叫组合函数。
COUNT(*|列名) 统计行数
AVG(数值类型列名) 平均值
SUM (数值类型列名) 求和
MAX(列名) 最大值
MIN(列名) 最小值
除了COUNT()以外,聚合函数都会忽略NULL值。
```
| 函数名称 | 作用 |
| -------- | -------------------------------- |
| MAX | 查询指定列的最大值 |
| MIN | 查询指定列的最小值 |
| COUNT | 统计查询结果的行数 |
| SUM | 求和,返回指定列的总和 |
| AVG | 求平均值,返回指定列数据的平均值 |
#### 面试题
**count(*) 和 count(1)和count(列名)区别**
> 1. count(1) and count(*)
>
> 当表的数据量大些时,对表作分析之后,使用count(1)还要比使用count(*)用时多了!
> 从执行计划来看,count(1)和count(*)的效果是一样的。 但是在表做过分析之后,count(1)会比count(*)的用时少些(1w以内数据量),不过差不了多少。
>
> 如果count(1)是聚索引,id,那肯定是count(1)快。但是差的很小的。
> 因为count(*),自动会优化指定到那一个字段。所以没必要去count(1),用count(*),sql会帮你完成优化的 因此:count(1)和count(*)基本没有差别!
>
> 2. count(1) and count(字段)
> 两者的主要区别是
> (1) count(1) 会统计表中的所有的记录数,包含字段为null 的记录。
> (2) count(字段) 会统计该字段在表中出现的次数,忽略字段为null 的情况。即不统计字段为null 的记录。
>
> 3. count(*) 和 count(1)和count(列名)区别
>
> 执行效果上:
> count(*)包括了所有的列,相当于行数,在统计结果的时候,**不会忽略列值为NULL**
> count(1)包括了忽略所有列,用1代表代码行,在统计结果的时候,**不会忽略列值为NULL**
> count(列名)只包括列名那一列,在统计结果的时候,会忽略列值为空(这里的空不是只空字符串或者0,而是表示null)的计数,即某个字段值为NULL时,不统计。
>
> 执行效率上:
> **列名为主键,count(列名)会比count(1)快**
> **列名不为主键,count(1)会比count(列名)快**
> **如果表多个列并且没有主键,则 count(1) 的执行效率优于 count(\*)**
> **如果有主键,则 select count(主键)的执行效率是最优的**
> **如果表只有一个字段,则 select count(*)最优。**
### 数值型函数
| 函数名称 | 作用 |
| --------------- | ---------------------------------------------------------- |
| ABS | 求绝对值 |
| SQRT | 求平方根 |
| POW 和 POWER | 两个函数的功能相同,返回参数的幂次方 |
| MOD | 求余数 |
| CEIL 和 CEILING | 两个函数功能相同,都是返回不小于参数的最小整数,即向上取整 |
| FLOOR | 向下取整,返回值转化为一个BIGINT |
| RAND | 生成一个0~1之间的随机数,传入整数参数是,用来产生重复序列 |
| ROUND | 对所传参数进行四舍五入 |
| SIGN | 返回参数的符号 |
### 字符串函数
| 函数名称 | 作用 |
| ------------------------------------------------------------ | ------------------------------------------------------------ |
| LENGTH | 计算字符串长度函数,返回字符串的字节长度 |
| CHAR_LENGTH | 计算字符串长度函数,返回字符串的字节长度,注意两者的区别 |
| CONCAT | 合并字符串函数,返回结果为连接参数产生的字符串,参数可以使一个或多个 |
| INSERT(str,pos,len,newstr) | 替换字符串函数 |
| LOWER | 将字符串中的字母转换为小写 |
| UPPER | 将字符串中的字母转换为大写 |
| [LEFT](https://www.cnblogs.com/poloyy/p/12894627.html)(str,len) | 从左侧字截取符串,返回字符串左边的若干个字符 |
| RIGHT | 从右侧字截取符串,返回字符串右边的若干个字符 |
| TRIM | 删除字符串左右两侧的空格 |
| REPLACE(s,s1,s2) | 字符串替换函数,返回替换后的新字符串 |
| SUBSTRING(s,n,len) | 截取字符串,返回从指定位置开始的指定长度的字符换 |
| REVERSE | 字符串反转(逆序)函数,返回与原始字符串顺序相反的字符串 |
| STRCMP(expr1,expr2) | 比较两个表达式的顺序。若expr1 小于 expr2 ,则返回 -1,0相等,1则相反 |
| LOCATE(substr,str [,pos]) | 返回第一次出现子串的位置 |
| INSTR(str,substr) | 返回第一次出现子串的位置 |
### 日期和时间函数
| 函数名称 | 作用 |
| ---------------------------------------------- | ------------------------------------------------------------ |
| CURDATE() <br>CURRENT_DATE()<br/>CURRENT_DATE | 两个函数作用相同,返回当前系统的日期值 |
| CURTIME()<br/>CURRENT_TIME()<br/>CURRENT_TIME | 两个函数作用相同,返回当前系统的时间值 |
| NOW | 返回当前系统的日期和时间值 |
| SYSDATE | 返回当前系统的日期和时间值 |
| DATE | 获取指定日期时间的日期部分 |
| TIME | 获取指定日期时间的时间部分 |
| MONTH | 获取指定日期中的月份 |
| MONTHNAME | 获取指定曰期对应的月份的英文名称 |
| DAYNAME | 获取指定曰期对应的星期几的英文名称 |
| YEAR | 获取年份,返回值范围是 1970〜2069 |
| DAYOFWEEK | 获取指定日期对应的一周的索引位置值,也就是星期数,注意周日是开始日,为1 |
| WEEK | 获取指定日期是一年中的第几周,返回值的范围是否为 0〜52 或 1<br/>〜53 |
| DAYOFYEAR | 获取指定曰期是一年中的第几天,返回值范围是1~366 |
| DAYOFMONTH 和 DAY | 两个函数作用相同,获取指定日期是一个月中是第几天,返回值范围是1~31 |
| DATEDIFF(expr1,expr2) | 返回两个日期之间的相差天数,如<br>SELECT DATEDIFF('2007-12-31 23:59:59','2007-12-30'); |
| SEC_TO_TIME | 将秒数转换为时间,与TIME_TO_SEC 互为反函数 |
| TIME_TO_SEC | 将时间参数转换为秒数,是指将传入的时间转换成距离当天00:00:00的秒数,**00:00:00为基数,等于 0 秒** |
### 流程控制函数
| 函数名称 | 作用 |
| ------------------------------------------------------ | ------------------------------------------------------------ |
| IF(expr,v1,v2) | 判断,流程控制,当expr = true时返回 v1,当expr = false、null 、 0时返回v2 |
| IFNULL(v1,v2) | 判断是否为空,如果 v1 不为 NULL,则 IFNULL 函数返回 v1,否则返回 v2 |
| [CASE](https://www.cnblogs.com/poloyy/p/12891100.html) | 搜索语句 |
流程控制函数示例:
```mysql
1、使用IF()函数进行条件判断
mysql> SELECT IF(12,2,3),
-> IF(1<2,'yes ','no'),
-> IF(STRCMP('test','test1'),'no','yes');
+------------+---------------------+---------------------------------------+
| IF(12,2,3) | IF(1<2,'yes ','no') | IF(STRCMP('test','test1'),'no','yes') |
+------------+---------------------+---------------------------------------+
| 2 | yes | no |
+------------+---------------------+---------------------------------------+
1 row in set (0.00 sec)
2、分别显示emp表有奖金和没奖金的员工信息。
mysql> select ename,comm,if(comm is null,'没奖金,呵呵','有奖金,嘻嘻') 备注 from emp;
+-----------+-------+------------------+
| ename | comm | 备注 |
+-----------+-------+------------------+
| 甘宁 | NULL | 没奖金,呵呵 |
| 黛绮丝 | 3000 | 有奖金,嘻嘻 |
| 殷天正 | 5000 | 有奖金,嘻嘻 |
| 刘备 | NULL | 没奖金,呵呵 |
| 谢逊 | 14000 | 有奖金,嘻嘻 |
| 关羽 | NULL | 没奖金,呵呵 |
| 张飞 | NULL | 没奖金,呵呵 |
| 诸葛亮 | NULL | 没奖金,呵呵 |
| 曾阿牛 | NULL | 没奖金,呵呵 |
| 韦一笑 | 0 | 有奖金,嘻嘻 |
| 周泰 | NULL | 没奖金,呵呵 |
| 程普 | NULL | 没奖金,呵呵 |
| 庞统 | NULL | 没奖金,呵呵 |
| 黄盖 | NULL | 没奖金,呵呵 |
| 张三 | 50000 | 有奖金,嘻嘻 |
+-----------+-------+------------------+
15 rows in set (0.00 sec)
3、使用IFNULL()函数进行条件判断
mysql> SELECT IFNULL(1,2), IFNULL(NULL,10), IFNULL(1/0, 'wrong');
+-------------+-----------------+----------------------+
| IFNULL(1,2) | IFNULL(NULL,10) | IFNULL(1/0, 'wrong') |
+-------------+-----------------+----------------------+
| 1 | 10 | wrong |
+-------------+-----------------+----------------------+
1 row in set, 1 warning (0.00 sec)
IFNULL() 函数用于判断第一个表达式是否为 NULL,如果为 NULL 则返回第二个参数的值,如果不为
NULL 则返回第一个参数的值。
IFNULL() 函数语法格式为:
IFNULL(expression, alt_value)
4、使用CASE value WHEN语句执行分支操作
CASE <表达式>
WHEN <值1> THEN <操作>
WHEN <值2> THEN <操作>
...
ELSE <操作>
END
将 <表达式> 的值 逐一和 每个 when 跟的 <值> 进行比较
如果跟某个<值>想等,则执行它后面的 <操作> ,如果所有 when 的值都不匹配,则执行 else 的操作
如果 when 的值都不匹配,且没写 else,则会报错
SELECT name,dept_id,
CASE
dept_id
WHEN 0 THEN
"实习生"
WHEN 1 THEN
"销售部"
WHEN 2 THEN
"信息部"
WHEN 2 THEN
"财务部" ELSE "没有部门"
END AS "部门"
FROM
emp;
mysql> SELECT CASE 2 WHEN 1 THEN 'one' WHEN 2 THEN 'two' ELSE 'more' END;
+------------------------------------------------------------+
| CASE 2 WHEN 1 THEN 'one' WHEN 2 THEN 'two' ELSE 'more' END |
+------------------------------------------------------------+
| two |
+------------------------------------------------------------+
1 row in set (0.00 sec)
5、使用CASE WHEN语句执行分支操作
mysql> SELECT CASE WHEN 1<0 THEN 'true' ELSE 'false' END;
+--------------------------------------------+
| CASE WHEN 1<0 THEN 'true' ELSE 'false' END |
+--------------------------------------------+
| false |
+--------------------------------------------+
1 row in set (0.00 sec)
6、查询emp表员工工资
要求:部门号为20,显示工资为1.2倍
部门号为30,显示工资为1.3倍
其他部门,显示原工资。
mysql> select deptno,sai 原工资,
-> case deptno
-> when 20 then sai*1.2
-> when 30 then sai*1.3
-> else sai
-> end as 显示工资 from emp;
+--------+-----------+--------------+
| deptno | 原工资 | 显示工资 |
+--------+-----------+--------------+
| 20 | 8000 | 9600.0 |
| 30 | 16000 | 20800.0 |
| 30 | 12500 | 16250.0 |
| 20 | 29750 | 35700.0 |
| 30 | 12500 | 16250.0 |
| 30 | 28500 | 37050.0 |
| 10 | 24500 | 24500 |
| 20 | 30000 | 36000.0 |
| 10 | 50000 | 50000 |
| 30 | 15000 | 19500.0 |
| 20 | 11000 | 13200.0 |
| 30 | 9500 | 12350.0 |
| 20 | 30000 | 36000.0 |
| 10 | 13000 | 13000 |
| 50 | 80000 | 80000 |
+--------+-----------+--------------+
15 rows in set (0.00 sec)
7、查询员工工资情况
要求:工资大于20000,显示A
工资大于15000,显示B
工资大于10000,显示C
否则,显示D
mysql> select ename,sai,
-> case
-> when sai>20000 then 'A'
-> when sai>15000 then 'B'
-> when sai>10000 then 'C'
-> else 'D'
-> end as '工资级别' from emp;
+-----------+-------+--------------+
| ename | sai | 工资级别 |
+-----------+-------+--------------+
| 甘宁 | 8000 | D |
| 黛绮丝 | 16000 | B |
| 殷天正 | 12500 | C |
| 刘备 | 29750 | A |
| 谢逊 | 12500 | C |
| 关羽 | 28500 | A |
| 张飞 | 24500 | A |
| 诸葛亮 | 30000 | A |
| 曾阿牛 | 50000 | A |
| 韦一笑 | 15000 | C |
| 周泰 | 11000 | C |
| 程普 | 9500 | D |
| 庞统 | 30000 | A |
| 黄盖 | 13000 | C |
| 张三 | 80000 | A |
+-----------+-------+--------------+
15 rows in set (0.00 sec)
```
作业:
1、第二周布置的作业
2、第三周的课堂代码
3、如下两道题
~~~sql
一、单表查询
素材: 表名:worker-- 表中字段均为中文,比如 部门号 工资 职工号 参加工作 等
CREATE TABLE `worker` (
`部门号` int(11) NOT NULL,
`职工号` int(11) NOT NULL,
`工作时间` date NOT NULL,
`工资` float(8,2) NOT NULL,
`政治面貌` varchar(10) NOT NULL DEFAULT '群众',
`姓名` varchar(20) NOT NULL,
`出生日期` date NOT NULL,
PRIMARY KEY (`职工号`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8 ROW_FORMAT=DYNAMIC;
INSERT INTO `worker` (`部门号`, `职工号`, `工作时间`, `工资`, `政治面貌`, `姓名`, `出生
日期`) VALUES (101, 1001, '2015-5-4', 3500.00, '群众', '张三', '1990-7-1');
INSERT INTO `worker` (`部门号`, `职工号`, `工作时间`, `工资`, `政治面貌`, `姓名`, `出生
日期`) VALUES (101, 1002, '2017-2-6', 3200.00, '团员', '李四', '1997-2-8');
INSERT INTO `worker` (`部门号`, `职工号`, `工作时间`, `工资`, `政治面貌`, `姓名`, `出生
日期`) VALUES (102, 1003, '2011-1-4', 8500.00, '党员', '王亮', '1983-6-8');
INSERT INTO `worker` (`部门号`, `职工号`, `工作时间`, `工资`, `政治面貌`, `姓名`, `出生
日期`) VALUES (102, 1004, '2016-10-10', 5500.00, '群众', '赵六', '1994-9-5');
INSERT INTO `worker` (`部门号`, `职工号`, `工作时间`, `工资`, `政治面貌`, `姓名`, `出生
日期`) VALUES (102, 1005, '2014-4-1', 4800.00, '党员', '钱七', '1992-12-30');
INSERT INTO `worker` (`部门号`, `职工号`, `工作时间`, `工资`, `政治面貌`, `姓名`, `出生
日期`) VALUES (102, 1006, '2017-5-5', 4500.00, '党员', '孙八', '1996-9-2');
1、显示所有职工的基本信息。
2、查询所有职工所属部门的部门号,不显示重复的部门号。
3、求出所有职工的人数。
4、列出最高工和最低工资。
5、列出职工的平均工资和总工资。
6、创建一个只有职工号、姓名和参加工作的新表,名为工作日期表。
7、显示所有女职工的年龄。
8、列出所有姓刘的职工的职工号、姓名和出生日期。
9、列出1960年以前出生的职工的姓名、参加工作日期。
10、列出工资在1000-2000之间的所有职工姓名。
11、列出所有陈姓和李姓的职工姓名。
12、列出所有部门号为2和3的职工号、姓名、党员否。
13、将职工表worker中的职工按出生的先后顺序排序。
14、显示工资最高的前3名职工的职工号和姓名。
15、求出各部门党员的人数。
16、统计各部门的工资和平均工资
17、列出总人数大于4的部门号和总人数。
二、多表查询
1.创建student和score表
CREATE TABLE student (
id INT(10) NOT NULL UNIQUE PRIMARY KEY ,
name VARCHAR(20) NOT NULL ,
sex VARCHAR(4) ,
birth YEAR,
department VARCHAR(20) ,
address VARCHAR(50)
);
创建score表。SQL代码如下:
CREATE TABLE score (
id INT(10) NOT NULL UNIQUE PRIMARY KEY AUTO_INCREMENT ,
stu_id INT(10) NOT NULL ,
c_name VARCHAR(20) ,
grade INT(10)
);
2.为student表和score表增加记录
向student表插入记录的INSERT语句如下:
INSERT INTO student VALUES( 901,'张老大', '男',1985,'计算机系', '北京市海淀区');
INSERT INTO student VALUES( 902,'张老二', '男',1986,'中文系', '北京市昌平区');
INSERT INTO student VALUES( 903,'张三', '女',1990,'中文系', '湖南省永州市');
INSERT INTO student VALUES( 904,'李四', '男',1990,'英语系', '辽宁省阜新市');
INSERT INTO student VALUES( 905,'王五', '女',1991,'英语系', '福建省厦门市');
INSERT INTO student VALUES( 906,'王六', '男',1988,'计算机系', '湖南省衡阳市');
向score表插入记录的INSERT语句如下:
INSERT INTO score VALUES(NULL,901, '计算机',98);
INSERT INTO score VALUES(NULL,901, '英语', 80);
INSERT INTO score VALUES(NULL,902, '计算机',65);
INSERT INTO score VALUES(NULL,902, '中文',88);
INSERT INTO score VALUES(NULL,903, '中文',95);
INSERT INTO score VALUES(NULL,904, '计算机',70);
INSERT INTO score VALUES(NULL,904, '英语',92);
INSERT INTO score VALUES(NULL,905, '英语',94);
INSERT INTO score VALUES(NULL,906, '计算机',90);
INSERT INTO score VALUES(NULL,906, '英语',85);
3.查询student表的所有记录
4.查询student表的第2条到4条记录
5.从student表查询所有学生的学号(id)、姓名(name)和院系(department)的信息
6.从student表中查询计算机系和英语系的学生的信息
7.从student表中查询年龄18~22岁的学生信息
8.从student表中查询每个院系有多少人
9.从score表中查询每个科目的最高分
10.查询李四的考试科目(c_name)和考试成绩(grade)
11.用连接的方式查询所有学生的信息和考试信息
12.计算每个学生的总成绩
13.计算每个考试科目的平均成绩
14.查询计算机成绩低于95的学生信息
15.查询同时参加计算机和英语考试的学生的信息
16.将计算机考试成绩按从高到低进行排序
17.从student表和score表中查询出学生的学号,然后合并查询结果
18.查询姓张或者姓王的同学的姓名、院系和考试科目及成绩
19.查询都是湖南的学生的姓名、年龄、院系和考试科目及成绩
~~~
# 第五章 MySQL备份恢复
## MySQL日志管理
在数据库保存数据时,有时候不可避免会出现数据丢失或者被破坏,这样情况下,我们必须保证数据的**安全性和完整性**,就需要使用日志来查看或者恢复数据了。
数据库中数据丢失或被破坏可能原因:
+ 误删除数据库
+ 数据库工作时,意外断电或程序意外终止
+ 由于病毒造成的数据库损坏或丢失
+ 文件系统损坏后,系统进行自检操作
+ 升级数据库时,命令语句不严格
+ 设备故障等等
+ 自然灾害
+ 盗窃
### MySQL日志类型
MySQL有几个不同的日志文件,可以帮助你找出mysqld内部发生的事情:
| 日志类型 | 记入文件中的信息类型 |
| ---------- | ------------------------------------------------------------ |
| 错误日志 | 记录启动、运行或停止时出现的问题 |
| 查询日志 | 记录建立的客户端连接和执行的语句 |
| 二进制日志 | 记录所有更改数据的语句。主要用于复制和即时点恢复 |
| 慢日志 | 记录所有执行时间超过long_query_time秒的所有查询或不使用索引的查询 |
| 事务日志 | 记录InnoDB等支持事务的存储引擎执行事务时产生的日志 |

默认情况下,所有日志创建于mysqld数据目录中。通过刷新日志,你可以强制 mysqld来关闭和重新打开日志文件(或者在某些情况下切换到一个新的日志)。当你执行一个`FLUSH LOGS`语句或执行`mysqladmin flush-logs`或`mysqladmin refresh`时,出现日志刷新。如果你正使用MySQL复制功能,从复制服务器将维护更多日志文件,被称为接替日志。
在mysql中,执行SQL语句:
```mysql
FLUSH LOGS
```
在shell中,通过mysqladmin命令执行日志刷新:
```shell
mysqladmin flush-logs
mysqladmin refresh
```
### 错误日志
错误日志主要记录如下几种日志:
+ 服务器启动和关闭过程中的信息
+ 服务器运行过程中的错误信息
+ 事件调度器运行一个时间是产生的信息
+ 在从服务器上启动从服务器进程是产生的信息
错误日志定义:
可以用--log-error[=file_name]选项来指定mysqld保存错误日志文件的位置。如果没有给定file_name值,mysqld使用错误日志名host_name.err 并在数据目录中写入日志文件。如果你执行FLUSH LOGS,错误日志用-old重新命名后缀并且mysqld创建一个新的空日志文件。(如果未给出--log-error选项,则不会重新命名)
查看当前错误日志配置:
```mysql
mysql> SHOW GLOBAL VARIABLES LIKE '%log_error%';
是否记录警告日志:
mysql> SHOW GLOBAL VARIABLES LIKE '%log_warnings%';
```
### 通用查询日志
启动开关:general_log={ON|OFF}
日志文件变量:general_log_file[=/PATH/TO/file]
全局日志开关:log={ON|OFF} 该开关打开后,所有日志都会被启用
记录类型:log_output={TABLE|FILE|NONE}:
因此,要启用通用查询日志,需要至少配置general_log=ON,log_output={TABLE|FILE}。而general_log_file如果没有指定,默认名是host_name.log。
看看上述几个值的默认配置:
```mysql
mysql> SHOW GLOBAL VARIABLES LIKE '%general_log%';
mysql> SHOW GLOBAL VARIABLES LIKE '%log_output%';
```
### 慢查询日志
MySQL如果启用了 slow_query_log=ON 选项,就会记录执行时间超过long_query_time的查询(初使表锁定的时间不算作执行时间)。日志记录文件为slow_query_log_file[=file_name],如果没有给出file_name值, 默认为主机名,后缀为-slow.log。如果给出了文件名,但不是绝对路径名,文件则写入数据目录。
默认与慢查询相关变量:
```mysql
# 默认没有启用慢查询,为了服务器调优,建议开启
mysql> SHOW GLOBAL VARIABLES LIKE '%slow_query_log%';
# 开启方法,当前生效,永久有效配置文件中设置
SET GLOBAL slow_query_log=ON;
# 使用 mysqldumpslow 命令获得日志中显示的查询摘要来处理慢查询日志
# mysqldumpslow slow.log
# 那么多久算是慢呢?
# 如果查询时长超过long_query_time的定义值(默认10秒),即为慢查询:
mysql> SHOW GLOBAL VARIABLES LIKE 'long_query_time';
```
### 二进制日志
#### 开启日志
二进制日志启动开关:**log-bin [= file_name]**。
注意:在5.6及以上版本一定要手动指定。5.6以下版本默认file_name为$datadir/mysqld-binlog。查看二进制日志的工具为:mysqlbinlog
注意:在最新的8版本中,默认开启了二进制日志!!!
二进制日志包含了所有更新了数据或者已经潜在更新了数据(例如,没有匹配任何行的一个DELETE)的所有
语句。
语句以“事件”的形式保存,它描述数据更改。二进制日志还包含关于每个更新数据库的语句的执行时间信息。
它不包含没有修改任何数据的语句。
二进制日志的主要目的是在数据库存在故障时,恢复时能够最大可能地更新数据库(即时点恢复),因为二进
制日志包含备份后进行的所有更新。二进制日志还用于在主复制服务器上记录所有将发送给从服务器的语句。
二进制日志是记录执行的语句还是执行后的结果数据呢?分为三种情况:
1. 假如一个表有10万行数据,而现在要执行一个如下语句将amount字段的值全部在原来的基础上增加1000:
```mysql
UPDATE sales.january SET amount=amount+1000 ;
```
此时如果要记录执行后的结果数据的话,日志会非常大。因此在这种情况下应记录执行语句。这种方式就是基于语句的二进制日志。
2. 如果向某个字段插入的是当前的时间呢?如下:
```mysql
INSERT INTO tb SET Birthdate=CURRENT_TIME();
```
此时就不能记录语句了,因为不同时间执行的结果是不一样的。这是应该记录这一行的值,这种就是基于行(row)的二进制日志。
3. 在有些情况,可能会结合两种方式来记录,这种叫做**混合方式的二进制日志**。
#### 二进制日志的管理
日志滚动。在my.cnf中设定max_binlog_size = 200M,表示限制二进制日志最大尺寸为200M,超过200M后进行滚动。MySQL的滚动方式与其他日志不太一样,滚动时会创建一个新的编号大1的日志用于记录最新的日志,而
原日志名字不会被改变。每次重启MySQL服务,日志都会自动滚动一次。
另外如果需要手动滚动,则使用命令 mysql> `FLUSH LOGS` ;
#### 日志查看
```mysql
查看有哪些二进制日志文件:mysql> SHOW BINARY LOGS;
查看当前正在使用的是哪一个二进制日志文件:mysql> SHOW MASTER STATUS;
查看二进制日志内容:mysql> SHOW BINLOG EVENTS IN 'mysqld-binlog.000002';
##该语句还可以加上Position(位置),指定显示从哪个Position(位置)开始:
mysql> SHOW BINLOG EVENTS IN 'mysqld-binlog.000002' FROM 203;
使用命令mysqlbinlog查看二进制日志内容:mysqlbinlog [options] log-files
```
#### 二进制日志还原数据
使用mysqlbinlog读取需要的日志内容,使用标准输入重定向到一个sql文件,然后在mysql服务器上导入即可,如下:
```mysql
mysqlbinlog mysqld-binlog.000002 >/root/temp_date.sql
```
如果报编码错误:mysqlbinlog: [ERROR] unknown variable 'default-character-set

原因:mysqlbinlog这个工具无法识别binlog中的配置中的default-character-set=utf8mb4这个指令。
有两种方式解决:
1. 添加 --no-defaults 参数
mysqlbinlog --no-defaults binlog.000069 >c:/a.sql # 注意需要指定binlog的位置,如果是当前路径,则可以直接使用名称即可。
2. 修改配置文件`my.cnf`
default-character-set=utf8mb4 修改为 character-set-server = utf8mb4,但是需要重启MySQL服务。
删除二进制日志文件:
二进制日志文件不能直接删除的,如果使用`rm`等命令直接删除日志文件,可能导致数据库的崩溃。必须使用命令 `PURGE` 删除日志,语法如下:
```mysql
PURGE { BINARY | MASTER } LOGS { TO 'log_name' |BEFORE datetime_expr }
```
注意:如果数据库使用的编码是utf8mb4编码,mysqlbinlog命令可能不能解析这种编码,提供两种方案:
1. 在MySQL的配置/etc/my.cnf中将**default-character-set=utf8mb4 **修改为 **character-set-server = utf8**,但是这需要重启MySQL服务,如果你的MySQL服务正在忙,那这样的代价会比较大。
2. 用mysqlbinlog **--no-defaults** mysql-bin.000004 命令打开。
## MySQL备份
### 备份类型
根据服务器状态,可以分为热备份、温备份、冷备份
+ 热备份:读、写不受影响;
+ 温备份:仅可以执行读操作;
+ 冷备份:离线备份;读、写操作均中止;
从对象来分,可以分为物理备份与逻辑备份
+ 物理备份:复制数据文件;
+ 逻辑备份:将数据导出至文本文件中;
从数据收集来分,可以完全备份、增量备份、差异备份
+ 完全备份:备份全部数据;
+ 增量备份:仅备份上次完全备份或增量备份以后变化的数据;
+ 差异备份:仅备份上次完全备份以来变化的数据;
#### 逻辑备份优缺点
**逻辑备份的优点:**
在备份速度上两种备份要取决于不同的存储引擎
物理备份的还原速度非常快。但是物理备份的最小粒度只能做到表
逻辑备份保存的结构通常都是纯ASCII的,所以我们可以使用文本处理工具来处理
逻辑备份有非常强的兼容性,而物理备份则对版本要求非常高
逻辑备份也对保持数据的安全性有保证
**逻辑备份的缺点:**
逻辑备份要对RDBMS产生额外的压力,而裸备份无压力
逻辑备份的结果可能要比源文件更大。所以很多人都对备份的内容进行压缩
逻辑备份可能会丢失浮点数的精度信息
### 备份内容
```mysql
数据文件
日志文件(比如事务日志,二进制日志)
存储过程,存储函数,触发器
配置文件(十分重要,各个配置文件都要备份)
用于实现数据库备份的脚本,数据库自身清理的Crontab等……
```
### 备份工具
#### MySQL自带的备份工具
mysqldump,是mysql数据库管理系统,自带的逻辑备份工具,支持所有引擎,MyISAM引擎是温备,InnoDB引擎是热备,备份速度中速,还原速度非常非常慢。但是在实现还原的时候,具有很大的操作余地。具有很好的弹性。
```shell
mysqldump 命令
mysqldump –u root –p dbname > 保存路径.sql
mysqldump –u root –p db_bbs > d:/db_bbs.bak.sql
[将数据库db_bbs以脚本的形式保存到D盘]
将sql脚本还原为数据库
mysql –u root –p dbname < 保存路径
```
mysqlhotcopy 物理备份工具,但只支持MyISAM引擎,基本上属于冷备的范畴,物理备份,速度比较快。mysql5.7已经没有这个命令了,多用于mysql5.5之前。mysqlhotcopy使用lock tables、flush tables和cp或scp来快速备份数据库或单个表,属于裸文件备份(物理备份),只能用于MyISAM引擎的数据库。本质是使用锁表语句,然后cp或scp。
#### 文件系统备份工具
cp命令, 冷备份,支持所有引擎,复制命令,只能实现冷备,物理备份。使用归档工具,cp命令,对其进行备份的,备份速度快,还原速度几乎最快,但是灵活度很低,可以跨系统,但是跨平台能力很差。
lvm 几乎是热备份,支持所有引擎,基于快照(LVM,ZFS)的物理备份,速度非常快,几乎是热备。只影响数据几秒钟而已。但是创建快照的过程本身就影响到了数据库在线的使用,所以备份速度比较快,恢复速度比较快,没有什么弹性空间,而且LVM的限制:不能对多个逻辑卷同一时间进行备份,所以数据文件和事务日志等各种文件必须放在同一个LVM上。而ZFS则非常好的可以在多逻辑卷之间备份。
#### 其它工具
ibbackup 商业工具 MyISAM是温备份,InnoDB是热备份 ,备份和还原速度都很快,这个软件它的每服务器授权版本是5000美元。
xtrabackup 开源工具 MyISAM是温备份,InnoDB是热备份 ,是ibbackup商业工具的替代工具。
mysqlbackup ORACLE公司也提供了针对企业的备份软件MySQL Enterprise Backup简称:mysqlbackup。
MySQL企业备份工具执行在线“热备“,无阻塞的MySQL数据库备份。全备份可以在所有InnoDB数据库上
执行,而无需中断MySQL查询或更新。此外,支持增量备份,只备份自上次备份后有变化的数据。另外部分备
份,支持特定的表或表空间按需要进行备份。
## 可视化管理工具
MySQL早期版本,官方没有提供了
Oracle收购后,提供了一个,但是很少用了——MySQL Workbench。
### Navicat
推荐使用
### datagrip
推荐使用
更多好用的工具
……
# 第六章 引擎、视图和索引
## 视图
### 什么是视图
视图(view),它是一种数据库对象。
视图通过以**定制的方式**显示来自一个或多个表的**特定数据**。
视图是一种数据库对象,用户可以像查询普通表一样查询视图。
**视图内其实没有存储任何数据**,它只是对表的一个查询的一种定义。
视图的定义保存在**数据字典【information_schema】**内,创建视图所基于对表称为“基表”。
### 为什么需要视图
例如经常要对emp和dept表进行连接查询,每次都要做表的连接,写同样的一串语句,同时由于工资列队数据比较敏感,对外要求不可见。对这样的问题就可以通过视图来解决。
### 图的作用和优点
**作用:**
+ 控制安全【实现对敏感数据隐藏】
+ 保存查询数据【便捷性】
**优点:**
+ 提供了灵活一致级别安全性。
+ 隐藏了数据的复杂性
+ 简化了用户的SQL指令
+ 通过重命名列,从另一个角度提供数据
### 创建视图
语法结构:
~~~sql
create view [if not exists] 视图 as (查询sql);
CREATE VIEW 视图名
[(alias[, alias]...)]--为视图字段指定别名
AS subquery
[WITH READ ONLY];
-- 将学生的姓名和班级姓名做成一个视图
create view v_stu_grade as (select t.id as uid, t.name as uname, g.name as class_name from t_stus as t, grade as g where t.class_id = g.id)
-- 查看视图
show tables;
# 查询视图
select * from v_stu_grade;
-- 带条件查询
select class_name from v_stu_grade where uid=35;
-- 查看视图结构
desc v_stu_grade;
~~~
### 视图使用规则
1. 视图必须有唯一命名
2. 在mysql中视图的数量没有限制
3. 创建视图必须从管理员那里获得必要的权限
4. 视图支持嵌套,也就是说可以利用其他视图检索出来的数据创建新的视图
5. 在视图中可以使用OREDR BY,但是如果视图内已经使用该排序子句,则视图的ORDER BY将覆盖前面的
ORDER BY。
6. 视图不能索引,也不能关联触发器或默认值
7. 视图可以和表同时使用【在使用上和表没有区别】
### 视图的修改
注意:视图中是不存储数据的!!!所以视图不要进行增删改操作!!!!试图就是用来查询的。
~~~sql
使用CREATE VIEW 语句修改EMP_V_10 视图. 为每个列指定列名.
CREATE VIEW emp_v_10
(id, name, sal, dept_id)
AS SELECT id,name,
salary, dept_id
FROM employees
WHERE dept_id = 10;
在CREATE VIEW 语句中字段与子查询中的字段必须一一对应,否则就别指定别名,或在子查询中指定别名
使用ALTER VIEW 语句修改EMP_V_10 视图. 为每个列指定列名.
ALTER VIEW emp_v_10
(id, name, sal, dept_id)
AS SELECT id,name,
salary, dept_id
FROM employees
WHERE dept_id = 10;
在CREATE VIEW 语句中字段与子查询中的字段必须一一对应,否则就别指定别名,或在子查询中指定别名
创建复杂视图,创建一个从两个表中查询数据,并进行分组计算的复杂视图.
CREATE VIEW dept_sum_vu_10
(name, minsal, maxsal, avgsal)
AS SELECT d.name, MIN(e.salary),
MAX(e.salary),AVG(e.salary)
FROM employees e, departments d
WHERE e.dept_id = d. id
AND e.dept_id = 10;
~~~
### 删除视图
~~~sql
drop view 视图名称;
~~~
> :warning: 注意:视图的主要作用是用来保证数据安全和简化查询复杂度的,不能加快查询速度,不能提升效率。
案例:
~~~sql
1、在数据库example下创建college表。College表内容如下所示
字段名 字段描述 数据类型 主键 外键 非空 唯一 自增
number 学号 INT(10) 是 否 是 是 否
name 姓名 VARCHAR(20) 否 否 是 否 否
major 专业 VARCHAR(20) 否 否 是 否 否
age 年龄 I NT(5) 否 否 否 否 否
CREATE TABLE college(
number INT(10) NOT NULL UNIQUE PRIMARY KEY COMMENT '学号',
name VARCHAR(20) NOT NULL COMMENT '姓名',
major VARCHAR(20) NOT NULL COMMENT '专业',
age INT(5) COMMENT '年龄'
);
2、在student表上创建视图college_view。视图的字段包括student_num、student_name、
student_age和department。ALGORITHM设置为MERGE类型,并且为视图加上WITH LOCAL CHECK
OPTION条件
CREATE ALGORITH=MERGE VIEW
college_view(student_num,student_name,student_age,department)
AS SELECT number,name,age,major FROM college
WITH LOCAL CHECK OPTION;
3、查看视图college_view的详细结构
SHOW CREATE VIEW college_view \G
4、 更新视图。向视图中插入3条记录。记录内容如下表所示
umer name major age
0901 张三 外语 20
0902 李四 计算机 22
0903 王五 计算机 19
INSERT INTO college_view VALUES(0901,'张三',20,'外语');
INSERT INTO college_view VALUES(0902,'李四',22,'计算机');
INSERT INTO college_view VALUES(0903,'王五',19,'计算机');
5 、修改视图,使其显示专业为计算机的信息,其他条件不变
方法一:
CREATE OR REPLACE ALGORITHM=UNDEFINED VIEW
college_view(student_num,student_name,student_age,department)
AS SELECT number,name,age,major
FROM college WHERE major=’计算机’
WITH LOCAL CHECK OPTION;
方法二:
ALTER ALGORITHM=UNDEFINED VIEW
college_view(student_num,student_name,student_age,department)
AS SELECT number,name,age,major
FROM college WHERE major=’计算机’
WITH LOCAL CHECK OPTION;
6 、删除视图college_view
DROP VIEW college_view;
~~~
## 数据库引擎
### MySQL数据库的架构
MySQL数据库是基于C/S结构设计的。
服务器端,MySQL的架构设置。

数据库的核心是引擎,而MySQL的引擎是插拔式的,这就意味着,可以根据不同的业务情况,来替换不同的引擎,达到需要的对应效果。
### myql的常见引擎
~~~sql
show engines;
~~~

+ 默认引擎是innodb【8版本中】
+ 注意:MySQL从1.5之后才默认引擎为innoDB,之前的版本中是--`MyISAM`
+ *OLTP*与*OLAP*:在线事务处理与联机分析处理【自己查看学习】

### 选择引擎
创建表的时候选择引擎:
~~~sql
create table 表名称(
结构定义
)[engin=xxx auto_incrent=10 character set utf8mb4];
-- 查看数据库表创建的sql
show create table t_user\G
*************************** 1. row ***************************
Table: t_user
Create Table: CREATE TABLE `t_user` (
`id` int NOT NULL AUTO_INCREMENT,
`name` varchar(50) NOT NULL,
`age` int DEFAULT '18',
`password` varchar(255) NOT NULL,
`mark` varchar(10) DEFAULT NULL,
`address` varchar(255) DEFAULT NULL,
`birthday` datetime DEFAULT CURRENT_TIMESTAMP,
`gender` enum('男','女') DEFAULT NULL,
PRIMARY KEY (`id`),
UNIQUE KEY `name` (`name`)
) ENGINE=InnoDB AUTO_INCREMENT=102 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci
~~~
当使用了innoDB引擎创建的表文件,一般表现形式为:`xxxx.ibd`,可以借助官方提供的工具:ibd2sdi.exe来查看这个文件:
~~~cmd
ibd2sdi board.ibd
["ibd2sdi"
,
{
"type": 1,
"id": 1240,
"object":
{
"mysqld_version_id": 80020,
"dd_version": 80017,
"sdi_version": 80019,
"dd_object_type": "Table",
"dd_object": {
"name": "board",
"mysql_version_id": 80020,
"created": 20250326123800,
"last_altered": 20250326123800,
"hidden": 1,
"options": "avg_row_length=0;encrypt_type=N;key_block_size=0;keys_disabled=0;pack_record=1;stats_auto_recalc=0;stats_sample_pages=0;",
"columns": [
{
"name": "id",
"type": 4,
"is_nullable": false,
"is_zerofill": false,
"is_unsigned": false,
"is_auto_increment": true,
"is_virtual": false,
"hidden": 1,
"ordinal_position": 1,
"char_length": 11,
"numeric_precision": 10,
"numeric_scale": 0,
"numeric_scale_null": false,
"datetime_precision": 0,
"datetime_precision_null": 1,
"has_no_default": false,
"default_value_null": false,
"srs_id_null": true,
"srs_id": 0,
"default_value": "AAAAAA==",
"default_value_utf8_null": true,
"default_value_utf8": "",
"default_option": "",
"update_option": "",
"comment": "",
"generation_expression": "",
"generation_expression_utf8": "",
"options": "interval_count=0;",
"se_private_data": "table_id=1854;",
"column_key": 2,
"column_type_utf8": "int",
"elements": [],
"collation_id": 255,
"is_explicit_collation": false
},
{
"name": "name",
"type": 16,
"is_nullable": false,
"is_zerofill": false,
"is_unsigned": false,
"is_auto_increment": false,
"is_virtual": false,
"hidden": 1,
"ordinal_position": 2,
"char_length": 200,
"numeric_precision": 0,
"numeric_scale": 0,
"numeric_scale_null": true,
"datetime_precision": 0,
"datetime_precision_null": 1,
"has_no_default": true,
"default_value_null": false,
"srs_id_null": true,
"srs_id": 0,
"default_value": "AAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAA\nAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAA\nAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAA\nAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAA",
"default_value_utf8_null": true,
"default_value_utf8": "",
"default_option": "",
"update_option": "",
"comment": "",
"generation_expression": "",
"generation_expression_utf8": "",
"options": "interval_count=0;",
"se_private_data": "table_id=1854;",
"column_key": 3,
"column_type_utf8": "varchar(50)",
"elements": [],
"collation_id": 255,
"is_explicit_collation": false
},
{
"name": "intro",
"type": 27,
"is_nullable": true,
"is_zerofill": false,
"is_unsigned": false,
"is_auto_increment": false,
"is_virtual": false,
"hidden": 1,
"ordinal_position": 3,
"char_length": 65535,
"numeric_precision": 0,
"numeric_scale": 0,
"numeric_scale_null": true,
"datetime_precision": 0,
"datetime_precision_null": 1,
"has_no_default": false,
"default_value_null": true,
"srs_id_null": true,
"srs_id": 0,
"default_value": "",
"default_value_utf8_null": true,
"default_value_utf8": "",
"default_option": "",
"update_option": "",
"comment": "",
"generation_expression": "",
"generation_expression_utf8": "",
"options": "interval_count=0;",
"se_private_data": "table_id=1854;",
"column_key": 1,
"column_type_utf8": "text",
"elements": [],
"collation_id": 255,
"is_explicit_collation": false
},
{
"name": "parent_id",
"type": 4,
"is_nullable": true,
"is_zerofill": false,
"is_unsigned": false,
"is_auto_increment": false,
"is_virtual": false,
"hidden": 1,
"ordinal_position": 4,
"char_length": 11,
"numeric_precision": 10,
"numeric_scale": 0,
"numeric_scale_null": false,
"datetime_precision": 0,
"datetime_precision_null": 1,
"has_no_default": false,
"default_value_null": true,
"srs_id_null": true,
"srs_id": 0,
"default_value": "",
"default_value_utf8_null": true,
"default_value_utf8": "",
"default_option": "",
"update_option": "",
"comment": "",
"generation_expression": "",
"generation_expression_utf8": "",
"options": "interval_count=0;",
"se_private_data": "table_id=1854;",
"column_key": 4,
"column_type_utf8": "int",
"elements": [],
"collation_id": 255,
"is_explicit_collation": false
},
{
"name": "DB_TRX_ID",
"type": 10,
"is_nullable": false,
"is_zerofill": false,
"is_unsigned": false,
"is_auto_increment": false,
"is_virtual": false,
"hidden": 2,
"ordinal_position": 5,
"char_length": 6,
"numeric_precision": 0,
"numeric_scale": 0,
"numeric_scale_null": true,
"datetime_precision": 0,
"datetime_precision_null": 1,
"has_no_default": false,
"default_value_null": true,
"srs_id_null": true,
"srs_id": 0,
"default_value": "",
"default_value_utf8_null": true,
"default_value_utf8": "",
"default_option": "",
"update_option": "",
"comment": "",
"generation_expression": "",
"generation_expression_utf8": "",
"options": "",
"se_private_data": "table_id=1854;",
"column_key": 1,
"column_type_utf8": "",
"elements": [],
"collation_id": 63,
"is_explicit_collation": false
},
{
"name": "DB_ROLL_PTR",
"type": 9,
"is_nullable": false,
"is_zerofill": false,
"is_unsigned": false,
"is_auto_increment": false,
"is_virtual": false,
"hidden": 2,
"ordinal_position": 6,
"char_length": 7,
"numeric_precision": 0,
"numeric_scale": 0,
"numeric_scale_null": true,
"datetime_precision": 0,
"datetime_precision_null": 1,
"has_no_default": false,
"default_value_null": true,
"srs_id_null": true,
"srs_id": 0,
"default_value": "",
"default_value_utf8_null": true,
"default_value_utf8": "",
"default_option": "",
"update_option": "",
"comment": "",
"generation_expression": "",
"generation_expression_utf8": "",
"options": "",
"se_private_data": "table_id=1854;",
"column_key": 1,
"column_type_utf8": "",
"elements": [],
"collation_id": 63,
"is_explicit_collation": false
}
],
"schema_ref": "db_chengke",
"se_private_id": 1854,
"engine": "InnoDB",
"last_checked_for_upgrade_version_id": 0,
"comment": "",
"se_private_data": "autoinc=13;version=0;",
"row_format": 2,
"partition_type": 0,
"partition_expression": "",
"partition_expression_utf8": "",
"default_partitioning": 0,
"subpartition_type": 0,
"subpartition_expression": "",
"subpartition_expression_utf8": "",
"default_subpartitioning": 0,
"indexes": [
{
"name": "PRIMARY",
"hidden": false,
"is_generated": false,
"ordinal_position": 1,
"comment": "",
"options": "flags=0;",
"se_private_data": "id=1597;root=4;space_id=797;table_id=1854;trx_id=169047;",
"type": 1,
"algorithm": 2,
"is_algorithm_explicit": false,
"is_visible": true,
"engine": "InnoDB",
"elements": [
{
"ordinal_position": 1,
"length": 4,
"order": 2,
"hidden": false,
"column_opx": 0
},
{
"ordinal_position": 2,
"length": 4294967295,
"order": 2,
"hidden": true,
"column_opx": 4
},
{
"ordinal_position": 3,
"length": 4294967295,
"order": 2,
"hidden": true,
"column_opx": 5
},
{
"ordinal_position": 4,
"length": 4294967295,
"order": 2,
"hidden": true,
"column_opx": 1
},
{
"ordinal_position": 5,
"length": 4294967295,
"order": 2,
"hidden": true,
"column_opx": 2
},
{
"ordinal_position": 6,
"length": 4294967295,
"order": 2,
"hidden": true,
"column_opx": 3
}
],
"tablespace_ref": "db_chengke/board"
},
{
"name": "name",
"hidden": false,
"is_generated": false,
"ordinal_position": 2,
"comment": "",
"options": "flags=0;",
"se_private_data": "id=1598;root=5;space_id=797;table_id=1854;trx_id=169047;",
"type": 2,
"algorithm": 2,
"is_algorithm_explicit": false,
"is_visible": true,
"engine": "InnoDB",
"elements": [
{
"ordinal_position": 1,
"length": 200,
"order": 2,
"hidden": false,
"column_opx": 1
},
{
"ordinal_position": 2,
"length": 4294967295,
"order": 2,
"hidden": true,
"column_opx": 0
}
],
"tablespace_ref": "db_chengke/board"
},
{
"name": "parent_id",
"hidden": false,
"is_generated": false,
"ordinal_position": 3,
"comment": "",
"options": "flags=0;",
"se_private_data": "id=1599;root=6;space_id=797;table_id=1854;trx_id=169047;",
"type": 3,
"algorithm": 2,
"is_algorithm_explicit": false,
"is_visible": true,
"engine": "InnoDB",
"elements": [
{
"ordinal_position": 1,
"length": 4,
"order": 2,
"hidden": false,
"column_opx": 3
},
{
"ordinal_position": 2,
"length": 4294967295,
"order": 2,
"hidden": true,
"column_opx": 0
}
],
"tablespace_ref": "db_chengke/board"
}
],
"foreign_keys": [
{
"name": "board_ibfk_1",
"match_option": 1,
"update_rule": 1,
"delete_rule": 1,
"unique_constraint_name": "PRIMARY",
"referenced_table_catalog_name": "def",
"referenced_table_schema_name": "db_chengke",
"referenced_table_name": "board",
"elements": [
{
"column_opx": 3,
"ordinal_position": 1,
"referenced_column_name": "id"
}
]
}
],
"check_constraints": [],
"partitions": [],
"collation_id": 255
}
}
}
,
{
"type": 2,
"id": 802,
"object":
{
"mysqld_version_id": 80020,
"dd_version": 80017,
"sdi_version": 80019,
"dd_object_type": "Tablespace",
"dd_object": {
"name": "db_chengke/board",
"comment": "",
"options": "encryption=N;",
"se_private_data": "flags=16417;id=797;server_version=80020;space_version=1;state=normal;",
"engine": "InnoDB",
"files": [
{
"ordinal_position": 1,
"filename": ".\\db_chengke\\board.ibd",
"se_private_data": "id=797;"
}
]
}
}
}
]
~~~
如果使用其他引擎呢?MyISAM 呢?
~~~sql
CREATE TABLE test(
id INT PRIMARY KEY auto_increment,
name VARCHAR(255)
)ENGINE=myisam
show CREATE table test;
~~~
查看data文件夹下的表文件,可以看到,myisam引擎创建的表,存在三个文件。
## 数据库索引
索引(index):和view等一样,索引也是一种数据库对象。
索引是一种**特殊的数据库结构**,可以用来快速查询数据库表中的特定记录。**索引是提高数据库性能的重要方式**。MySQL中,所有的数据类型都可以被索引。MySQL的索引包括**普通索引、惟一性索引、全文索引、单列索引、多列索引和空间索引**等。
索引是一种特殊的文件(InnoDB数据表上的索引是表空间的一个组成部分),它们包含着对数据表里所有记录的引用指针。更通俗的说,数据库索引好比是一本书前面的目录,能加快数据库的查询速度。(**注意:一般数据库默认都会为主键生成索引**)。
如果说,没有任何加快查询的方案(没有索引),我们查询数据只能做全表扫描匹配,效率非常低!!!
借助一些数据结构与算法在手段,实现数据的快速检索,这就是数据库索引。
如果没有索引进行匹配,则条件查询时,会进行全表扫描【全表匹配】,性能非常差。
### 什么是索引
```mysql
模式(schema)中的一个数据库对象
在数据库中用来加速对表的查询
通过使用快速路径访问方法快速定位数据,减少了磁盘的I/O
与表独立存放,但不能独立存在,必须属于某个表
由数据库自动维护,表被删除时,该表上的索引自动被删除。
索引的作用类似于书的目录,几乎没有一本书没有目录,因此几乎没有一张表没有索引。
```
**索引的原理**
就是把无序的数据变成有序的查询
1. 把创建的索引的列的内容进行排序
2. 对排序结果生成倒排表
3. 在倒排表内容上拼上数据地址链
4. 在查询的时候,先拿到倒排表内容,再取出数据地址链,从而拿到具体数据
### 索引优缺点
索引的优点是可以提高检索数据的速度,这是创建索引的最主要的原因;对于有依赖关系的子表和父表之间的
联合查询时,可以提高查询速度;使用分组和排序子句进行数据查询时,同样可以显著节省查询中分组和排序的时间。
索引的缺点是创建和维护索引需要耗费时间,耗费时间的数量随着数据量的增加而增加;索引需要占用物理空
间,每一个索引要占一定的物理空间;增加、删除和修改数据时,要动态的维护索引,造成数据的维护速度降低了。
### 索引分类
**索引分为聚簇索引和非聚簇索引两种,聚簇索引是按照数据存放的物理位置为顺序的,而非聚簇索引就不一样了;聚簇索引能提高多行检索的速度,而非聚簇索引对于单行的检索很快。**
MySQL的索引包括普通索引、惟一性索引、全文索引、单列索引、多列索引和空间索引等。
### 索引的设计原则
为了使索引的使用效率更高,在创建索引的时候必须考虑在哪些字段上创建索引和创建什么类型的索引。本小
节将向读者介绍一些索引的设计原则。
1. 选择惟一性索引
2. 为经常需要排序、分组和联合操作的字段建立索引
3. 为常作为查询条件的字段建立索引
4. 限制索引的数目
5. 尽量使用数据量少的索引
6. 尽量使用前缀来索引
7. 删除不再使用或者很少使用的索引
### 创建索引
创建索引是指在某个表的一列或多列上建立一个索引,以便提高对表的访问速度。创建索引有三种方式,这三种方式分别是:
+ 创建表的时候创建索引
+ 在已经存在的表上创建索引
+ 使用ALTER TABLE语句来创建索引
#### 创建表是创建索引
```mysql
创建表的时候可以直接创建索引,这种方式最简单、方便。其基本形式如下:
CREATE TABLE 表名 ( 属性名 数据类型 [完整性约束条件],
属性名 数据类型 [完整性约束条件],
…
属性名 数据类型
[UNIQUE | FULLTEXT | SPATIAL] INDEX | KEY
[别名](属性名1 [(长度)] [ASC | DESC])
);
-- 在创建表的同时创建索引
create table emp(
id int auto_increment,
name varchar(50),
age int default 18,
nickname varchar(255),
gender enum("男", "女"),
-- 主键索引【主键约束就是主键索引】
primary key(id),
-- 唯一索引
unique index (name),
-- 注意:username创建了一个普通索引
-- 也是单列索引
index (nickname),
-- 多列索引
index(age, gender)
)
--- 表已经存在的情况下创建索引
-- 使用create index
CREATE INDEX 索引名称 ON 表名称(column)
create index age_index on stus2(age);
-- 使用alter(索引是作用表的)
ALTER TABLE table_name ADD INDEX index_name (column)
1 普通索引
# 直接创建索引
CREATE INDEX index_name ON table(column(length))
# 创建表的时候同时创建索引
Create table index1(
Id int,
Name varchar(20),
Sex boolean,
index(id),
);
# 修改表结构的方式添加索引
ALTER TABLE table_name ADD INDEX index_name(column(length))
# 查询索引
Show create table index1 \G
# 查询某张表中索引情况
-- 注意:查看当前表中索引创建情况
show index from table_name;
# 使用计划查询SQL使用索引情况
Explain select * from index1 where id=1 \G
# 删除索引
DROP INDEX index_name ON table
# 2 创建唯一性索引 ,当然也有多种创建方式
Create table index2(
Id int unique,
Name varchar(20),
Unique index index2_id(id asc)
);
# 3 创建全文索引(FULLTEXT)
# MySQL从3.23.23版开始支持全文索引和全文检索,FULLTEXT索引仅可用于 MyISAM 表;
# 他们可以从CHAR、VARCHAR或TEXT列中作为CREATE TABLE语句的一部分被创建,
# 或是随后使用ALTER TABLE 或CREATE INDEX被添加。
# 对于较大的数据集,将你的资料输入一个没有FULLTEXT索引的表中,
# 然后创建索引,其速度比把资料输入现有FULLTEXT索引的速度更为快。
# 不过切记对于大容量的数据表,生成全文索引是一个非常消耗时间非常消耗硬盘空间的做法。
只能创建在char,varchar或text类型的字段上。
create table index3(
Id int,
Info varchar(20),
Fulltext index index3_info(info)
);
explain select * from table where id=1;
EXPLAIN分析结果的含义:
table:这是表的名字。
type:连接操作的类型,ALL、index、range、 ref、eq_ref、const、system、NULL(从左到右,性能从差到好)
possible_keys:可能可以利用的索引的名字
Key:它显示了MySQL实际使用的索引的名字。如果它为空(或NULL),则MySQL不使用索引。
key_len:索引中被使用部分的长度,以字节计。
ref:它显示的是列的名字(或单词“const”),MySQL将根据这些列来选择行
rows:MySQL所认为的它在找到正确的结果之前必须扫描的记录数。显然,这里最理想的数字就是1
Extra:这里可能出现许多不同的选项,其中大多数将对查询产生负面影响
# 4 创建单列索引
Create table index4(
Id int,
Subject varchar(30),
Index index4_st(subject(10))
);
# 5 创建多列索引
使用多列索引时一定要特别注意,只有使用了索引中的第一个字段时才会触发索引。
如果没有使用索引中的第一个字段,那么这个多列索引就不会起作用。
也就是说多个单列索引与单个多列索引的查询效果不同,因为执行查询时,
MySQL只能使用一个索引,会从多个索引中选择一个限制最为严格的索引。
Create table index5(
Id int,
Name varchar(20),
Sex char(4),
Index index5_ns(name,sex)
);
# 6 创建空间索引
Create table index6(
Id int,
Space geometry not null,
Spatial index index6_sp(space)
)engine=myisam;
建空间索引时,表的存储引擎必须是myisam类型,而且索引字段必须有非空约束。空间数据类型包括
geometry,point,linestring和polygon类型等。平时很少用到。
```
#### create index
首先保证已经存在表,才能使用这个命令创建索引。
```mysql
在已经存在的表上,可以直接为表上的一个或几个字段创建索引。基本形式如下:help create index
CREATE [ UNIQUE | FULLTEXT | SPATIAL ] INDEX 索引名
ON 表名 (属性名 [ (长度) ] [ ASC | DESC] );
1.创建普通索引
CREATE INDEX index_name ON table(column(length))
2.创建惟一性索引
CREATE UNIQUE INDEX indexName ON table(column(length))
3.创建全文索引
CREATE FULLTEXT INDEX index_content ON article(content)
4.创建单列索引
CREATE INDEX index3_name on index3 (name(10));
5.创建多列索引
6.创建空间索引
```
#### ALTER TABLE
用ALTER TABLE语句来创建索引,也是存在表的情况下。
```mysql
在已经存在的表上,可以通过ALTER TABLE语句直接为表上的一个或几个字段创建索引。基本形式如下:
ALTER TABLE 表名 ADD [ UNIQUE | FULLTEXT | SPATIAL ] INDEX
索引名(属性名 [ (长度) ] [ ASC | DESC]);
1.创建普通索引
ALTER TABLE table_name ADD INDEX index_name (column(length))
2.创建惟一性索引
ALTER TABLE table_name ADD UNIQUE indexName (column(length))
3.创建全文索引
ALTER TABLE index3 add fulltext index index3_name(name);
4.创建单列索引
ALTER TABLE index3 add index index3_name(name(10));
5.创建多列索引
6.创建空间索引
```
### 删除索引
删除索引是指将表中已经存在的索引删除掉。一些不再使用的索引会降低表的更新速度,影响数据库的性能。
对于这样的索引,应该将其删除。本节将详细讲解删除索引的方法。
对应已经存在的索引,可以通过DROP语句来删除索引。基本形式如下:
```sql
DROP INDEX 索引名 ON 表名 ;
-- 查看索引名称
show index from emp;
-- 根据索引名称来删除所以
-- age是索引名称
drop index age on emp;
```
案例:
~~~sql
1、 在数据库job下创建workInfo表。创建表的同时在id字段上创建名为index_id的唯一性索引,而且以
降序的格式排列。workInfo表内容如下所示
字段描述 数据类型 主键 外键 非空 唯一 自增
id 编号 INT(10) 是 否 是 是 是
name 职位名称 VARCHAR(20) 否 否 是 否 否
type 职位类别 VARCHAR(10) 否 否 否 否 否
address 工作地址 VARCHAR(50) 否 否 否 否 否
wage 工资 INT 否 否 否 否 否
contents 工作内容 TINYTEXT 否 否 否 否 否
extra 附加信息 TEXT 否 否 否 否 否
CREATE TABLE workInfo(
id INT(10) NOT NULL UNIQUE PRIMARY KEY AUTO_INCREMENT,
name VARCHAR(20) NOT NULL,
type VARCHAR(10),
address VARCHAR(50),
tel VARCHAR(20),
wage INT,
content TINYTEXT,
extra TEXT,
UNIQUE INDEX index_id(id DESC)
);
2 、使用create index语句为name字段创建长度为10的索引index_name
CREATE INDEX index_name ON workInfo(name(10));
3 、使用alter table语句在type和address上创建名为index_t的索引
ALTER TABLE workInfo ADD INDEX index_t(type,address);
4 、将workInfo表的存储引擎更改为MyISAM类型
ALTER TABLE workInfo ENGINE=MyISAM;
5 、使用alter table语句在extra字段上创建名为index_ext的全文索引
ALTER TABLE workInfo ADD FULLTEXT INDEX index_ext(extra);
6 、删除workInfo表的唯一性索引index_id
DROP INDEX index_id ON workInfo;
1、创建测试表
create table test1(
id int,num int,pass varchar(50)
);
create table test2(
id int,num int,pass varchar(50),
index idIdx (id)
);
create table test3(
id int,num int,pass varchar(50)
);
2、向表test1里插入1000000条数据
for ((i=1;i<=1000000;i++));do `mysql -p123456 -uroot -e "insert into it.test1
values($i,floor($i+rand()*$i),md5($i));"`; done > /tmp/mysql.txt 2>&1
# 注意:测试时可以插入300000条记录
mysql> select count(*) from test1;
+----------+
| count(*) |
+----------+
| 300000 |
+----------+
1 row in set (0.12 sec)
3、在有索引和没有索引的情况下执行查询
1)没有创建索引时查询
mysql> reset query cache;
mysql> explain select num,pass from test3 where id>=5000 and id<5050;
2)创建索引后再次查询
mysql> reset query cache;
mysql> explain select num,pass from test2 where id>=5000 and id<5050;
4、在有索引和没有索引的情况下新增数据
1)没有创建索引时插入数据
mysql> insert into test3 select * from test1;
Query OK, 300000 rows affected (1.00 sec)
Records: 300000 Duplicates: 0 Warnings: 0
2)创建索引后再次插入数据
mysql> insert into test2 select * from test1;
Query OK, 300000 rows affected (1.17 sec)
Records: 300000 Duplicates: 0 Warnings: 0
~~~
### MySQL使用索引的场景
```mysql
1) 快速查找符合where条件的记录
2) 快速确定候选集。若where条件使用了多个索引字段,则MySQL会优先使用能使候选记录集规模最小的那
个索引,以便尽快淘汰不符合条件的记录。
3) 如果表中存在几个字段构成的联合索引,则查找记录时,这个联合索引的最左前缀匹配字段也会被自动作
为索引来加速查找。
例如,若为某表创建了3个字段(c1, c2, c3)构成的联合索引,则(c1), (c1, c2), (c1, c2, c3)均
会作为索引,(c2, c3)就不会被作为索引,而(c1, c3)其实只利用到c1索引。
4) 多表做join操作时会使用索引(如果参与join的字段在这些表中均建立了索引的话)。
5)若某字段已建立索引,求该字段的min()或max()时,MySQL会使用索引
6)对建立了索引的字段做sort或group操作时,MySQL会使用索引
1) B-Tree可被用于sql中对列做比较的表达式,如=, >, >=, <, <=及between操作
2) 若like语句的条件是不以通配符开头的常量串,MySQL也会使用索引。
比如,SELECT * FROM tbl_name WHERE key_col LIKE 'Patrick%'或SELECT * FROM
tbl_name WHERE key_col LIKE 'Pat%_ck%'可以利用索引,而SELECT * FROM tbl_name WHERE
key_col LIKE '%Patrick%'(以通配符开头)和SELECT * FROM tbl_name WHERE key_col LIKE
other_col(like条件不是常量串)无法利用索引。
对于形如LIKE '%string%'的sql语句,若通配符后面的string长度大于3,则MySQL会利用Turbo
Boyer-Moore algorithm算法进行查找.
3) 若已对名为col_name的列建了索引,则形如"col_name is null"的SQL会用到索引。
4) 对于联合索引,sql条件中的最左前缀匹配字段会用到索引。
5) 若sql语句中的where条件不只1个条件,则MySQL会进行Index Merge优化来缩小候选集范围
MySQL只对一下操作符才使用索引:<,<=,=,>,>=,between,in,以及某些时候的like(不以通配符%或_开头的情形)。而理论上每张表里面最多可创建16个索引(版本不同,可能会有变化)。
```
##### MySQL索引的优化
上面都在说使用索引的好处,但过多的使用索引将会造成滥用。因此索引也会有它的缺点:虽然索引大大提高了查询速度,同时却会降低更新表的速度,如对表进行INSERT、UPDATE和DELETE。
因为更新表时,MySQL不仅要保存数据,还要保存一下索引文件。建立索引会占用磁盘空间的索引文件。一般情况这个问题不太严重,但如果你在一个大表上创建了多种组合索引,索引文件的会膨胀很快。
索引只是提高效率的一个因素,如果你的MySQL有大数据量的表,就需要花时间研究建立最优秀的索引,或优化查询语句。下面是一些总结以及收藏的MySQL索引的注意事项和优化方法。
**何时使用聚集索引或非聚集索引**

### 聚簇索引和非聚簇索引
#### 非聚簇索引
索引节点的叶子页面就好比一片叶子。叶子头便是索引键值。
先创建一张表:
```mysql
CREATE TABLE `user` (
`id` INT NOT NULL ,
`name` VARCHAR NOT NULL ,
`class` VARCHAR NOT NULL);
```
对于MYISAM引擎,如果创建 id 和 name 为索引。对于下面查询:
```mysql
select * from user where id = 1
```
会利用索引,先在索引树中快速检索到 id,但是要想取到id对应行数据,必须找到改行数据在硬盘中的存储位置,因此MYISAM引擎的索引,叶子页面上不仅存储了主键id 还存储着 数据存储的地址信息。如图:

像这样的索引就称为非聚簇索引。
非聚簇索引的二级索引与主键索引类似。假设我们对name添加索引,那么name的索引树叶子将是如下结构:

#### 聚簇索引
对于非聚簇索引来说,每次通过索引检索到所需行号后,还需要通过叶子上的磁盘地址去磁盘内取数据(回行)消耗时间。为了优化这部分回行取数据时间,InnoDB 引擎采用了聚簇索引。
聚簇索引,即将数据存入索引叶子页面上。对于 InnoDB 引擎来说,叶子页面不再存该行对应的地址,而是直接存储数据:

这样便避免了回行操作所带来的时间消耗。 使得 InnoDB 在某些查询上比 MyISAM 还要快!
关于查询时间,一般认为 MyISAM 牺牲了功能换取了性能,查询更快。但事实并不一定如此。多数情况下,MyISAM 确实比 InnoDB 查的快 。但是查询时间受多方面因素影响。InnoDB 查询变慢得原因是因为支持事务、回滚等等,使得 InnoDB的叶子页面实际上还包含有事务id(换句话说就是版本号) 以及回滚指针。
在二级索引方面, InnoDB 与 MyISAM 有很大区别。
InnoDB默认对主键建立聚簇索引。如果你不指定主键,InnoDB会用一个具有唯一且非空值的索引来代替。如果不存在这样的索引,InnoDB会定义一个隐藏的主键,然后对其建立聚簇索引。一般来说,InnoDB 会以聚簇索引的形式来存储实际的数据,它是其它二级索引的基础。
假设对 InnoDB 引擎上表name字段加索引,那么name索引叶子页面则只会存储主键id:

检索时,先通过name索引树找到主索引id,再通过id在主索引树的聚簇索引叶子页面取出数据。
参考资料:https://blog.csdn.net/shachao888/article/details/110150863
## 作业4:
```mysql
学生表:Student (Sno, Sname, Ssex , Sage, Sdept)
学号,姓名,性别,年龄,所在系 Sno为主键
课程表:Course (Cno, Cname,)
课程号,课程名 Cno为主键
学生选课表:SC (Sno, Cno, Score)
学号,课程号,成绩 Sno,Cno为主键
1.用SQL语句创建学生表student,定义主键,姓名不能重名,性别只能输入男或女,所在系的默认值是 “计算机”。
2.修改student 表中年龄(age)字段属性,数据类型由int 改变为smallint。
3.为SC表建立按学号(sno)和课程号(cno)组合的升序的主键索引,索引名为SC_INDEX 。
4.创建一视图 stu_info,查询全体学生的姓名,性别,课程名,成绩。
```
# 第七章 SQL编程
SQL虽然主要用做数据库的数据查询,所以被称为结构化查询语言。但是需要大家注意的是:SQL是一门编程语言,是可以进行程序编写的!!!
当然SQL编程不想常规的编程语言,用来实现应用程序的。它主要的作用是用来**辅助数据库查询或者管理**的。
在开发中,使用SQL编程,主要用于如下一些内容的编写和制:
+ 触发器(trigger)
+ 存储过程(procedure)
+ 存储函数(function)
+ 游标(cursor)【了解即可】
## sql编程错误问题
> MySQL开启bin-log后,调用存储过程或者函数以及触发器时,会出现错误号为1418的错误:
> 在MySQL中创建函数时出现这种错误的解决方法:
>
> 方法1:第一种是在创建子程序(存储过程、函数、触发器)时,声明为DETERMINISTIC或NO SQL与READS SQL DATA中的一个, 例如:
> CREATE DEFINER = CURRENT_USER PROCEDURE `NewProc`()
> DETERMINISTIC
> BEGIN
> #Routine body goes here...
> END;;
>
> 方法2:第二种是信任子程序的创建者,禁止创建、修改子程序时对SUPER权限的要求,设置log_bin_trust_routine_creators全局系统变量为1。
> (1)在客户端上执行 SET GLOBAL log_bin_trust_function_creators = 1。
> (2)MySQL启动时,加上--log-bin-trust-function-creators选项,参数设置为1。
> (3)在MySQL配置文件my.ini或my.cnf中的[mysqld]段上加log-bin-trust-function-creators=1。
当然,在8之后的版本,这个错误系统已经替我们解决了。
## 触发器
触发器(trigger)是一个特殊的存储过程,它的执行不是由程序调用,也不是手工启动,而是由**事件【增删改】**来触发,比如当对一个表进行操作( **insert,delete, update**)时就会激活它执行,把这种执行的代码,称为触发器(Trigger)。
触发器经常用于**加强数据的完整性约束和业务规则**等。例如,当学生表中增加了一个学生的信息时,学生的总数就应该同时改变。因此可以针对学生表创建一个触发器,每次增加一个学生记录时,就执行一次学生总数的计算操作,从而保证学生总数与记录数的一致性。
> :warning: 注意:如果需要在命令行中(cmd、shell)终端中执行SQL编程相关的内容,引入SQL编程中,会出现分号(`;`)作为编程主体部分命令的分割符存在,所以,终端中sql的结束符,不能在再使用分号了(`;`)。
>
> 解决方案:使用delimiter这个命令替换掉; 如
>
> ~~~sql
> # 使用$结束SQL
> \d $
>
> # 使用两个$结束SQL
> delimiter $$
> ~~~
### 如何定义触发器
语法结构:
~~~sql
create trigger 触发器名称 before|after 触发事件
on 表名称 FOR EACH ROW
begin
# 触发器实体部分,由SQL组成,如果SQL是多条,则使用;隔离每一条SQL
end
# 说明:
<触发器名称> 最多64个字符,它和MySQL中其他对象的命名方式一样
{ BEFORE | AFTER } 触发器时机
{ INSERT | UPDATE | DELETE } 触发的事件
ON <表名称> 标识建立触发器的表名,即在哪张表上建立触发器
FOR EACH ROW 触发器的执行间隔:
FOR EACH ROW子句通知触发器 每隔一行执行一次动作,而不是对整个表执行一次
<触发器程序体> 要触发的SQL语句:可用顺序,判断,循环等语句实现一般程序需要的逻辑功能
~~~
~~~sql
## 示例1:
1. 创建表
mysql>
create table student3(
id int unsigned auto_increment primary key not null,
name varchar(50)
);
mysql>
insert into student3(name) values('jack');
create table student_total(total int);
insert into student_total values(1);
# 有要求1:将student3表中数据增加时,student_total数据随之加1
create trigger tri_student3_increment after insert
on student3 FOR EACH ROW
begin
# 更新数据统计表中的数据
update student_total set total = total + 1;
end
# 证明该触发器实现成功
insert into student3(name) values('tom');
# 查询student_total,可以看到,随着学生表的数据增加,学生统计表的淑君随之变化
# 定义触发器,实现删除时,数据也减一的效果
create trigger tri_del_student3_student_total after delete
on student3 for each row
begin
#
update student_total set total = total - 1;
end
mysql> delimiter ;
查看触发器
1. 通过SHOW TRIGGERS语句查看
SHOW TRIGGERS\G
2. 通过系统表triggers查看
USE information_schema
SELECT * FROM triggers\G
SELECT * FROM triggers WHERE TRIGGER_NAME='触发器名称'\G
-- 查看当前数据库下的所有触发器
show TRIGGERS;
-- 查询当前DBMS下所有触发器
SELECT * FROM information_schema.`TRIGGERS`;
-- 通过名称这条件查询
SELECT * FROM information_schema.`TRIGGERS` WHERE trigger_name = "trigger_add_student4_student_total2";
删除触发器
通过DROP TRIGGERS语句删除
sql> DROP TRIGGER 解发器名称
示例2:
创建表tab1
DROP TABLE IF EXISTS tab1;
CREATE TABLE tab1(
id int primary key auto_increment,
name varchar(50),
sex enum('m','f'),
age int
);
创建表tab2
DROP TABLE IF EXISTS tab2;
CREATE TABLE tab2(
id int primary key auto_increment,
name varchar(50),
salary double(10,2)
);
触发器tab1_after_delete_trigger
作用:tab1表删除记录后,自动将tab2表中对应记录删除
mysql> \d /
mysql>
create trigger tab1_after_delete_trigger
after delete on tab1
for each row
begin
delete from tab2 where name=old.name;
end/
触发器tab1_after_update_trigger
作用:当tab1更新后,自动更新tab2
mysql> \d $$
mysql>
create trigger tab1_after_update_trigger
after update on tab1
for each row
begin
update tab2 set name=new.name where name=old.name;
end$$
Query OK, 0 rows affected (0.19 sec)
触发器tab1_after_insert_trigger
作用:当tab1增加记录后,自动增加到tab2
mysql> \d /
mysql>
create trigger tab1_after_insert_trigger
after insert on tab1
for each row
begin
insert into tab2 values(null, name, 5000);
end/
Query OK, 0 rows affected (0.19 sec)
~~~
## 存储过程
### 什么是存储过程或者函数
存储过程和函数是**事先经过编译**并存储在数据库中的**一段sql语句集合**,调用存储过程函数可以简化应用开发人员的很多工作,减少数据在数据库和应用服务器之间的传输,对于提高数据处理的效率是有好处的。
存储过程和函数的区别:
1. 函数必须有返回值,而存储过程没有。
2. 存储过程的参数可以是**IN、OUT、INOUT**类型,函数的参数只能是IN
### 存储过程的优点
+ 存储过程只在创建时进行编译;而SQL语句每执行一次就编译一次,所以使用存储过程可以提高数据库执行速度
+ 简化复杂操作,结合事务一起封装
+ 复用性好
+ 安全性高,可指定存储过程的使用权
**注意:并发量少的情况下,很少使用存储过程。并发量高的情况下,为了提高效率,用存储过程比较多。**
### 存储过程创建与调用
创建存储过程语法 :
~~~sql
create procedure sp_name(参数列表)
[特性...]过程体
存储过程的参数形式:[IN | OUT | INOUT]参数名 类型
IN 输入参数
OUT 输出参数[可以理解成返回值]
INOUT 输入输出参数【即充当传入的参数,又充当返回值】
delimiter $$
create procedure 过程名(参数列表)
begin
SQL语句
end $$
delimiter ;
调用:
call 存储过程名(实参列表)
/**
存储过程的创建语法结构:
CREATE PROCEDURE([参数列表])
begin
-- 一行或者多行sql组成
存储过程实体部分
end
*/
-- 第一个,写一个没有返回值,也不需要参数
-- 实现一个存储过程,查询t_user 表共有多少条记录(record)
CREATE PROCEDURE pro_query_student_count()
BEGIN
SELECT COUNT(1) FROM t_user;
END
-- 存储过程时手动调用
-- 使用call关键字调用
CALL pro_query_student_count();
-- 使用存储过程,循环插入数据到某张表中
-- 1、存储过程的定义
# 2、如何在sql编程中,定义变量(全局变量、局部变量、会话变量)
# 使用show variables 查看全局变量 show variables like "%char%"
# 使用set 修改变量 【会话级别有效】set character_set_client = "gbk"
# 查询一个会话变量
-- select @a;
CREATE PROCEDURE autoincrement_t1()
BEGIN
-- 定义局部变量
declare i int DEFAULT 1; # int i = 1;
while(i <= 1000) do
INSERT INTO t1(`name`) VALUES(MD5(i));
SET i = i + 1;
end WHILE;
END
CALL autoincrement_t1()
DROP PROCEDURE autoincrement_t1
-- 存储过程如何调用
-- call关键字来调用
call pro_query_student_count();
-- sql定义变量
-- 全局变量
-- set指令是sql中可以修改或者设置(定义)变量的一个关键字
-- 使用set修改全局变量:set character_set_client = "gbk";
-- 使用set修改会话级别变量:set @a = 10;
-- 修改局部变量 set i = i + 1;
-- 局部变量的定义 declare 关键字
SELECT @a;
-- 程序控制流程
-- 单分支
-- if 条件 then
-- end if;
-- 双分支
-- if 条件 then
--
-- else
--
-- end if;
/*
-- 多分支
if 条件 then
elseif
elseif
elseif
else
end if;
*/
-- 循环
-- while 条件 do
--
-- 循环体
-- end WHILE;
-- 通过循环插入数据数据表中
-- create PROCEDURE xxxx()
-- BEGIN
--
-- DECLARE i int DEFAULT 1;
-- WHILE i <= 10000 DO
-- insert into t1(name) values(CONCAT("刘建宏", "是个大帅哥", i));
-- set i = i + 1;
-- END WHILE;
-- END
-- 可以这样设置,适合于单个变量赋值
-- set @a = (SELECT COUNT(*) from t1);
-- 注意:在sql中,如果是查询的结果需要赋值到变量中
-- 推荐使用into语句完成,上面的方式不通用
SELECT COUNT(*) INTO @a from t_user;
SELECT * from t1 ORDER BY id DESC LIMIT 10;
SELECT @a;
create PROCEDURE auto_t1_params(IN a int)
BEGIN
DECLARE i int DEFAULT 1;
WHILE i <= a DO
insert into t1(name) values(CONCAT("刘建宏", "是个大帅哥", i));
set i = i + 1;
END WHILE;
END
set @a = 100;
CALL auto_t1_params(10);
CALL auto_t1_params(@a);
CREATE PROCEDURE query_t_user_count(OUT num int)
BEGIN
SELECT COUNT(1) INTO num from t_user;
END
SELECT @b;
CALL query_t_user_count(@b);
-- 查询姓名中姓xx的人数是多少
-- 使用多个参数
create PROCEDURE query_user_by_name(IN p1 VARCHAR(50), OUT num int)
BEGIN
SELECT COUNT(*) INTO num FROM t_user WHERE `name` LIKE CONCAT(p1, "%");
END
call query_user_by_name("刘建宏", @c);
SELECT @c;
SELECT * from t_user;
create procedure proce_param_inout(inout p1 int)
begin
if (p1 is not null) then
set p1=p1+1;
else
select 100 into p1; # set p1 = 100;
end if;
end
SELECT @d;
call proce_param_inout(@d);
-- 返回t1的条数,以xxx开头的数据的数量
create PROCEDURE query_t1_by_age02(INOUT num int)
BEGIN
SELECT COUNT(1) INTO num FROM db_chengke.t_user WHERE age = num;
END;
CALL query_t1_by_age01(@b, 21);
select @b;
~~~
### 存储过程的案例
~~~sql
===================NONE========================
mysql> \d $
mysql>
create procedure p1()
begin
select count(*) from mysql.user;
end$
Query OK, 0 rows affected (0.51 sec)
mysql> \d ;
mysql> call p1()
mysql>
create table t1(
id int,
name varchar(50)
);
Query OK, 0 rows affected (2.81 sec)
mysql> delimiter $$
mysql>
create procedure autoinsert1()
begin
declare i int default 1; # int i = 1;
while(i<20000)do
insert into t1 values(i, md5(i));
set i=i+1;
end while;
end$$
mysql> delimiter ;
====================IN==========================
mysql>
create procedure autoinsert2(IN a int)
BEGIN
declare i int default 1;
while(i<=a)do
insert into t1 values(i,md5(i));
set i=i+1;
end while;
END$$
Query OK, 0 rows affected (0.00 sec)
mysql> call autoinsert2(10);
Query OK, 1 row affected (1.10 sec)
mysql> set @num=20;
mysql> select @num;
+------+
| @num |
+------+
| 20 |
+------+
1 row in set (0.00 sec)
mysql> call autoinsert2(@num);
====================OUT=======================
mysql> delimiter $$
mysql>
CREATE PROCEDURE p2 (OUT param1 INT)
BEGIN
SELECT COUNT(*) INTO param1 FROM t1;
END$$
Query OK, 0 rows affected (0.00 sec)
mysql> delimiter ;
mysql> select @a;
+------+
| @a |
+------+
| NULL |
+------+
1 row in set (0.00 sec)
mysql> CALL p2(@a);
Query OK, 0 rows affected (0.00 sec)
mysql> SELECT @a;
+------+
| @a |
+------+
| 3 |
+------+
===================IN 和 OUT=====================
作用:统计指定部门的员工数
mysql>
create procedure count_num(IN p1 varchar(50), OUT p2 int)
BEGIN
select count(*) into p2 from employee where post=p1;
END$$
Query OK, 0 rows affected (0.00 sec)
mysql> \d ;
mysql> call count_num('hr',@a);
mysql>select @a;
作用:统计指定部门工资超过例如5000的总人数
mysql>
create procedure count_num(IN p1 varchar(50), IN p2 float(10,2), OUT p3 int)
BEGIN
select count(*) into p3 from employee where post=p1 and salary>=p2;
END$$
Query OK, 0 rows affected (0.00 sec)
mysql> \d ;
mysql> call count_num('hr',5000,@a);
====================INOUT======================
mysql>
create procedure proce_param_inout(inout p1 int)
begin
if (p1 is not null) then
set p1=p1+1;
else
select 100 into p1;
end if;
end$$
Query OK, 0 rows affected (0.00 sec)
mysql> \d ;
mysql> select @h;
+------+
| @h |
+------+
| NULL |
+------+
1 row in set (0.00 sec)
mysql> call proce_param_inout(@h);
Query OK, 1 row affected (0.00 sec)
mysql> select @h;
+------+
| @h |
+------+
| 100 |
+------+
1 row in set (0.00 sec)
mysql> call proce_param_inout(@h);
Query OK, 0 rows affected (0.00 sec)
mysql> select @h;
+------+
| @h |
+------+
| 101 |
+------+
1 row in set (0.00 sec)
~~~
## 存储函数
函数:一个功能代码的集合,在数据库当然就是一段sql的集合。
数据库中,默认是已经提供了系统内置函数的,如 uuid()、md5()、 user()、 database()【第四章最后部分】。一般来说,这些已经够用了,但是需要定制特殊功能的函数,则需要自定义函数(UDF)。
MySQL存储函数(自定义函数),函数一般用于计算和返回一个值,可以将经常需要使用的计算或功能写成一个函数。函数和存储过程类似。
存储过程和函数的区别:
1. 函数必须有返回值,而存储过程可以没有。
2. 存储过程的参数可以是**IN、OUT、INOUT**类型,函数的参数只能是**IN**
### 如何定义存储函数
定义语法规范:
~~~sql
create FUNCTION func_name([参数列表])
-- 必须声明返回值类型
RETURNS type
[characteristic ...]
BEGIN
routine_body
END;
参数说明:
(1)func_name :存储函数的名称。
(2)param_name type:可选项,指定存储函数的参数。type参数用于指定存储函数的参数类型,该类型
可以是MySQL数据库中所有支持的类型。
(3)RETURNS type:指定返回值的类型。
(4)characteristic:可选项,指定存储函数的特性。
(5)routine_body:SQL代码内容[函数体,由一行到多行sql组成]。
~~~
### 查看调用存储函数
在MySQL中,存储函数的使用方法与MySQL内部函数的使用方法基本相同。用户自定义的存储函数与MySQL内部函数性质相同。区别在于,存储函数是用户自定义的。而内部函数由MySQL自带。其语法结构如下:
~~~sql
# 查看函数调用的结果
SELECT func_name([parameter[,…]]);
# 直接嗲用
func_name([parameter[,…]]);
~~~
### 案例实现
~~~sql
################1、无参有返回值#########################
# 统计emp表中员工个数
mysql> \d $
mysql>
CREATE FUNCTION myf1()
RETURNS int
BEGIN
DECLARE c INT DEFAULT 0;
SELECT COUNT(1) INTO c FROM emp;
RETURN c;
END$
Query OK, 0 rows affected (0.00 sec)
mysql> \d;
mysql> select myf1();
+--------+
| myf1() |
+--------+
| 15 |
+--------+
1 row in set (0.05 sec)
#################2、有参有返回值#####################
示例1:根据员工名返回工资
mysql> \d $
mysql>
CREATE FUNCTION myf2(empName varchar(20))
RETURNS INT
BEGIN
DECLARE sal INT;
SELECT sai INTO sal FROM emp WHERE ename=empName;
RETURN sal;
END $
Query OK, 0 rows affected (0.00 sec)
mysql> \d;
mysql> select myf2('刘备');
+----------------+
| myf2('刘备') |
+----------------+
| 29750 |
+----------------+
1 row in set (0.00 sec)
示例2:根据部门编号,返回平均工资
mysql> \d $
mysql>
CREATE FUNCTION myf3(d_No int)
RETURNS DOUBLE
BEGIN
DECLARE avg_sal DOUBLE;
SELECT AVG(sai) INTO avg_sal FROM emp WHERE deptno=d_No;
RETURN avg_sal;
END $
Query OK, 0 rows affected (0.00 sec)
mysql> \d ;
mysql> select myf3(20);
+----------+
| myf3(20) |
+----------+
| 21750 |
+----------+
1 row in set (0.00 sec)
~~~
### 修改存储函数
MySQL中,通过**ALTER FUNCTION** 语句来修改存储函数,其语法格式如下:
````mysql
ALTER FUNCTION func_name [characteristic ...]
characteristic:
COMMENT 'string'
| LANGUAGE SQL
| { CONTAINS SQL | NO SQL | READS SQL DATA | MODIFIES SQL DATA }
| SQL SECURITY { DEFINER | INVOKER }
````
上面这个语法结构是MySQL官方给出的,修改的内容可以包SQL语句也可以不包含。
### 删除存储函数
MySQL中使用DROP FUNCTION语句来删除存储函数。
示例:删除存储函数。
```mysql
DROP FUNCTION IF EXISTS func_user;
```
## 游标【了解即可】
游标(Cursor)是处理多行数据的,游标需要开启,抓取,关闭的。
在 MySQL 中,存储过程或函数中的查询有时会返回多条记录,而使用简单的 SELECT 语句,没有办法得到第一行、下一行或前十行的数据,这时可以使用游标来逐条读取查询结果集中的记录。游标在部分资料中也被称为光标。
关系数据库管理系统实质是面向集合的,在 MySQL 中并没有一种描述表中单一记录的表达形式,除非使用 WHERE 子句来限制只有一条记录被选中。所以有时我们必须借助于游标来进行单条记录的数据处理。
一般通过游标定位到结果集的某一行进行数据修改。
> 结果集是符合 SQL 语句的所有记录的集合。
个人理解游标就是一个标识,用来标识数据取到了什么地方,如果你了解编程语言,可以把他理解成数组中的下标。
不像多数 DBMS,MySQL 游标只能用于存储过程和函数。
下面介绍游标的使用,主要包括游标的声明、打开、使用和关闭。
### 声明游标
MySQL 中使用 **DECLARE** 关键字来声明游标,并定义相应的 SELECT 语句,根据需要添加 WHERE 和其它子句。其语法的基本形式如下:
```mysql
DECLARE cursor_name CURSOR FOR select_statement;
```
其中,cursor_name 表示游标的名称;select_statement 表示 SELECT 语句,可以返回一行或多行数据。
下面声明一个名为 nameCursor 的游标,代码如下:
```mysql
mysql> DELIMITER //
mysql> CREATE PROCEDURE processnames()
-> BEGIN
-> DECLARE nameCursor CURSOR
-> FOR
-> SELECT name FROM tb_student;
-> END//
Query OK, 0 rows affected (0.07 sec)
```
以上语句定义了 nameCursor 游标,游标只局限于存储过程中,存储过程处理完成后,游标就消失了。
### 打开游标
声明游标之后,要想从游标中提取数据,必须首先打开游标。在 MySQL 中,打开游标通过 **OPEN** 关键字来实现,其语法格式如下:
```mysql
OPEN cursor_name;
```
其中,cursor_name 表示所要打开游标的名称。需要注意的是,打开一个游标时,游标并不指向第一条记录,而是指向第一条记录的前边。
在程序中,一个游标可以打开多次。用户打开游标后,其他用户或程序可能正在更新数据表,所以有时会导致用户每次打开游标后,显示的结果都不同。
### 使用游标
游标顺利打开后,可以使用 **FETCH...INTO** 语句来读取数据,其语法形式如下:
```mysql
FETCH cursor_name INTO var_name [,var_name]...
```
上述语句中,将游标 cursor_name 中 SELECT 语句的执行结果保存到变量参数 var_name 中。变量参数 var_name 必须在游标使用之前定义。使用游标类似高级语言中的数组遍历,当第一次使用游标时,此时游标指向结果集的第一条记录。
MySQL 的游标是只读的,也就是说,你只能顺序地从开始往后读取结果集,不能从后往前,也不能直接跳到中间的记录。
### 关闭游标
游标使用完毕后,要及时关闭,在 MySQL 中,使用 **CLOSE** 关键字关闭游标,其语法格式如下:
```mysql
CLOSE cursor_name;
```
CLOSE 释放游标使用的所有内部内存和资源,因此每个游标不再需要时都应该关闭。
在一个游标关闭后,如果没有重新打开,则不能使用它。但是,使用声明过的游标不需要再次声明,用 OPEN 语句打开它就可以了。
如果你不明确关闭游标,MySQL 将会在到达 END 语句时自动关闭它。游标关闭之后,不能使用 FETCH 来使用该游标。
#### 游标案例
创建 users 数据表,并插入数据,SQL 语句和运行结果如下:
```mysql
mysql> CREATE TABLE `users`
-> (
-> `ID` BIGINT(20) UNSIGNED NOT NULL AUTO_INCREMENT,
-> `user_name` VARCHAR(60),
-> `user_pass` VARCHAR(64),
-> PRIMARY KEY (`ID`)
-> );
Query OK, 0 rows affected (0.06 sec)
mysql> INSERT INTO users VALUES(null,'liujianhong','liujianhong'),
-> (null,'liu','liu123'),
-> (null,'ling','ling123');
Query OK, 3 rows affected (0.01 sec)
```
创建存储过程 test_cursor,并创建游标 cur_test,查询 users 数据表中的第 3 条记录,SQL 语句和执行过程如下:
```mysql
mysql> DELIMITER //
mysql> CREATE PROCEDURE test_cursor (in param INT(10),out result VARCHAR(90))
-> BEGIN
-> DECLARE name VARCHAR(20);
-> DECLARE pass VARCHAR(20);
-> DECLARE done INT;
-> DECLARE cur_test CURSOR FOR SELECT user_name,user_pass FROM users;
-> DECLARE continue handler FOR SQLSTATE '02000' SET done = 1;
-> IF param THEN INTO result FROM users WHERE id = param;
-> ELSE
-> OPEN cur_test;
-> repeat
-> FETCH cur_test into name,pass;
-> SELECT concat_ws(',',result,name,pass) INTO result;
-> until done
-> END repeat;
-> CLOSE cur_test;
-> END IF;
-> END //
Query OK, 0 rows affected (0.10 sec)
mysql> call test_cursor(3,@test)//
Query OK, 1 row affected (0.03 sec)
mysql> select @test//
+-----------+
| @test |
+-----------+
| ling,ling123 |
+-----------+
1 row in set (0.00 sec)
```
创建 pro_users() 存储过程,定义 cur_1 游标,将表 users 中的 user_name 字段全部修改为 MySQL,SQL 语句和执行过程如下。
```mysql
mysql> CREATE PROCEDURE pro_users()
-> BEGIN
-> DECLARE result VARCHAR(100);
-> DECLARE no INT;
-> DECLARE cur_1 CURSOR FOR SELECT user_name FROM users;
-> DECLARE CONTINUE HANDLER FOR NOT FOUND SET no=1;
-> SET no=0;
-> OPEN cur_1;
-> WHILE no=0 do
-> FETCH cur_1 into result;
-> UPDATE users SET user_name='MySQL'
-> WHERE user_name=result;
-> END WHILE;
-> CLOSE cur_1;
-> END //
Query OK, 0 rows affected (0.05 sec)
mysql> call pro_users() //
Query OK, 0 rows affected (0.03 sec)
mysql> SELECT * FROM users //
+----+-----------+-----------+
| ID | user_name | user_pass |
+----+-----------+-----------+
| 1 | MySQL | liujianhon|
| 2 | MySQL | liu123 |
| 3 | MySQL | ying |
+----+-----------+-----------+
3 rows in set (0.00 sec)
```
结果显示,users 表中的 user_name 字段已经全部修改为 MySQL。
## 作业
创建表并插入数据:
```
字段名 数据类型 主键 外键 非空 唯一 自增
id INT 是 否 是 是 否
name VARCHAR(50) 否 否 是 否 否
glass VARCHAR(50) 否 否 是 否 否
sch 表内容
id name glass
1 xiaommg glass 1
2 xiaojun glass 2
```
1、创建一个可以统计表格内记录条数的存储函数 ,函数名为count_sch()
2、创建一个存储过程avg_sai,有3个参数,分别是deptno,job,接收平均工资,功能查询emp表dept为30,job为销售员的平均工资。
# 第八章 MySQL事务和SQL优化
## 什么是事务
`Transaction`,一个最小的不可再分的工作单元;通常一个事务对应一个完整的业务(例如银行账户转账业务,该业务就是一个最小的工作单元)。一个完整的业务需要批量的`DML`(insert、update、delete)语句共同联合完成。事务只和DML语句有关,或者说DML语句才有事务。这个和业务逻辑有关,业务逻辑不同,DML语句的个数不同。
数据库事务( transaction)是访问并可能操作各种数据项的一个数据库操作序列,这些操作要么全部执行,要么全部不执行,是一个不可分割的工作单位。事务由事务开始与事务结束之间执行的全部数据库操作组成。
以银行转账为例:账户转账是一个完整的业务,最小的单元,不可再分——也就是说银行账户转账是一个事务:
```sql
update t_act set balance=balance - 400 where actno=1;
update t_act set balance=balance + 400 where actno=2;
```
以上两台DML语句必须同时成功或者同时失败。最小单元不可再分,当第一条DML语句执行成功后,并不能将底层数据库中的第一个账户的数据修改,只是将操作记录了一下;这个记录是在内存中完成的;当第二条DML语句执行成功后,和底层数据库文件中的数据完成同步。若第二条DML语句执行失败,则清空所有的历史操作记录,要完成以上的功能必须借助事务。
事务:一组逻辑操作单元,使数据从一种状态变换到另一种状态。
事务处理(事务操作):保证所有事务都作为一个工作单元来执行,即使出现了故障,都不能改变这种执行方式。当在一个事务中执行多个操作时,要么所有的事务都被提交(**commit**),那么这些修改就永久地保存下来;
要么数据库管理系统将放弃所作的所有修改,整个事务回滚(**rollback**)到最初状态。
为确保数据库中数据的一致性,数据的操纵应当是离散的成组的逻辑单元:当它全部完成时,数据的一致性可以保持,而当这个单元中的一部分操作失败,整个事务应全部视为错误,所有从起始点以后的操作应全部回退到开始状态。
## 事务的特性
事务是由一组SQL语句 组成的逻辑处理单元,它的**ACID**特性如下:
**原子性(Atomicity):**原子性是指事务是一个不可分割的工作单位,事务中的操作要么都发生,要么都不发生。
**一致性(Consistency):**事务必须使数据库从一个一致性状态变换到另外一个一致性状态。
**隔离性(Isolation):**事务的隔离性是多个用户并发访问数据库时,数据库为每一个用户开启的事务,不能被其他事务的操作数据所干扰,多个并发事务之间要相互隔离。
**持久性(Durability):**持久性是指一个事务一旦被提交,它对数据库中数据的改变就是永久性的,接下来即使数据库发生故障也不应该对其有任何影响。

## MySQL使用事务
如果没有开启事务,相当于每一条SQL就是一个独立的事务。
此时,每一条SQL,会自动提交(auto_commit)。
MySQL开启事务、回滚事务、提交事务命令。
```mysql
begin
说明:在5.5 以上的版本,不需要手工begin,只要你执行的是一个DML,会自动在前面加一个begin命令。
commit:提交事务
完成一个事务,一旦事务提交成功 ,就说明具备ACID特性了。
rollback :回滚事务
将内存中,已执行过的操作,回滚回去
```
**自动提交策略:**
MySQL默认已经开启自动提交,我们可以通过对应的设置来开启或者关闭自动提交。
```mysql
db01 [(none)]>select @@autocommit;
db01 [(none)]>set autocommit=0;
db01 [(none)]>set global autocommit=0;
注:
自动提交是否打开,一般在有事务需求的MySQL中,将其关闭
不管有没有事务需求,我们一般也都建议设置为0,可以很大程度上提高数据库性能
(1)
set autocommit=0;
set global autocommit=0;
(2)
vim /etc/my.cnf
autocommit=0
```
**隐式提交语句:**
```mysql
用于隐式提交的 SQL 语句:
begin
a
b
begin
SET AUTOCOMMIT = 1
导致提交的非事务语句:
DDL语句: (ALTER、CREATE 和 DROP)
DCL语句: (GRANT、REVOKE 和 SET PASSWORD)
锁定语句:(LOCK TABLES 和 UNLOCK TABLES)
导致隐式提交的语句示例:
TRUNCATE TABLE
LOAD DATA INFILE
SELECT FOR UPDATE
```
**开始事务流程:**
```mysql
1、检查autocommit是否为关闭状态
select @@autocommit;
或者:
show variables like 'autocommit';
2、开启事务,并结束事务
begin
delete from student where name='alexsb';
update student set name='alexsb' where name='alex';
rollback;
begin
delete from student where name='alexsb';
update student set name='alexsb' where name='alex';
commit;
```
## InnoDB 事务的ACID如何保证
实现事务的本质,就是通过日志来记录数据,保证事务的成功提交或者回滚。
这些日志,被称为事务日志,主要是两个:
+ 重做日志(redo.log) 保证事务正常提交成功
+ 回滚日志(undo.log)保证事务错误,回滚数据成功
### 基本概念
```mysql
redo log ---> 重做日志 ib_logfile0~1 50M , 轮询使用
redo log buffer ---> redo内存区域
ibd ----> 存储 数据行和索引
buffer pool --->缓冲区池,数据和索引的缓冲
LSN : 日志序列号
磁盘数据页,redo文件,buffer pool,redo buffer
MySQL 每次数据库启动,都会比较磁盘数据页和redolog的LSN,必须要求两者LSN一致数据库才能正常启动
WAL : write ahead log 日志优先写的方式实现持久化
脏页: 内存脏页,内存中发生了修改,没写入到磁盘之前,我们把内存页称之为脏页.
CKPT:Checkpoint,检查点,就是将脏页刷写到磁盘的动作
TXID: 事务号,InnoDB会为每一个事务生成一个事务号,伴随着整个事务
```
### redo log
Redo是什么?
```mysql
redo,顾名思义“重做日志”,是事务日志的一种。
```
作用是什么?
```
在事务ACID过程中,实现的是“D”持久化的作用。对于AC也有相应的作用
```
redo日志位置
```
redo的日志文件:iblogfile0 iblogfile1
```
redo buffer
```mysql
redo的buffer:数据页的变化信息+数据页当时的LSN号
LSN:日志序列号 磁盘数据页、内存数据页、redo buffer、redolog
```
redo的刷新策略
```
commit;
刷新当前事务的redo buffer到磁盘
还会顺便将一部分redo buffer中没有提交的事务日志也刷新到磁盘
```
MySQL CSR——前滚
```mysql
MySQL : 在启动时,必须保证redo日志文件和数据文件LSN必须一致, 如果不一致就会触发CSR,最终保证一致
情况一:
我们做了一个事务,begin;update;commit.
1. 在begin ,会立即分配一个TXID=tx_01.
2. update时,会将需要修改的数据页(dp_01,LSN=101),加载到data buffer中
3. DBWR线程,会进行dp_01数据页修改更新,并更新LSN=102
4. LOGBWR日志写线程,会将dp_01数据页的变化+LSN+TXID存储到redobuffer
5. 执行commit时,LGWR日志写线程会将redobuffer信息写入redolog日志文件中,基于WAL原则,在日志完全写入磁盘后,commit命令才执行成功,(会将此日志打上commit标记)
6. 假如此时宕机,内存脏页没有来得及写入磁盘,内存数据全部丢失
7. MySQL再次重启时,必须要redolog和磁盘数据页的LSN是一致的.但是,此时dp_01,TXID=tx_01磁盘是
LSN=101,dp_01,TXID=tx_01,redolog中LSN=102
MySQL此时无法正常启动,MySQL触发CSR.在内存追平LSN号,触发ckpt,将内存数据页更新到磁盘,从而保证磁盘数据页和redolog LSN一值.这时MySQL正长启动
以上的工作过程,我们把它称之为基于REDO的"前滚操作"
```
### undo 回滚日志
undo是什么?
```
undo,顾名思义“回滚日志”
```
作用是什么?
```mysql
在事务ACID过程中,实现的是“A” 原子性的作用
另外CI也依赖于Undo
在rolback时,将数据恢复到修改之前的状态
在CSR实现的是,将redo当中记录的未提交的时候进行回滚.
undo提供快照技术,保存事务修改之前的数据状态.保证了MVCC,隔离性,mysqldump的热备
```
### 实现MVCC的三个隐藏字段
**对于使用 InnoDB 存储引擎的表来说,它的聚簇索引记录中都包含 3 个隐藏列**
**db_row_id:隐藏的行 ID。在没有自定义主键也没有 Unique 键的情况下,会使用该隐藏列作为主键。**
**db_trx_id:操作这个数据的事务 ID,也就是最后一个对该数据进行插入或更新的事务 ID。**
**db_roll_ptr:回滚指针,也就是指向这个记录的 Undo Log 信息。Undo Log 中存储了回滚需要的数据**
### 事务的隔离级别
## 事务的隔离级别
多个线程开启各自事务操作数据库中数据时,数据库系统要负责隔离操作,以保证各个线程在获取数据时的准确性。
如果不考虑隔离性,可能会引发如下问题:
1、幻想读
2、不可重复读取
3、脏读
### 脏读
指一个事务读取了另外一个事务未提交的数据。
```mysql
这是非常危险的,假设A向B转帐100元,对应sql语句如下所示
1. update account set money=money+100 where name=‘b’;
2. update account set money=money-100 where name=‘a’;
```
### 不可重复读
不可重复读,是指在数据库访问中,一个事务范围内两个相同的查询却返回了不同数据。
这是由于查询时系统中其他事务修改的提交而引起的。比如事务T1读取某一数据,事务T2读取并修改了该数据,T1为了对读取值进行检验而再次读取该数据,便得到了不同的结果。
一种更易理解的说法是:在一个事务内,多次读同一个数据。在这个事务还没有结束时,另一个事务也访问该同一数据并修改数据。那么,在第一个事务的两次读数据之间。由于另一个事务的修改,那么第一个事务两次读到的数据可能不一样,这样就发生了在一个事务内两次读到的数据是不一样的,因此称为不可重复读,即原始读取不可重复。
### 虚读/幻读
是指在一个事务内读取到了别的事务插入的数据,导致前后读取不一致。
如:**事务A 按照一定条件进行数据读取, 期间事务B 插入了相同搜索条件的新数据,事务A再次按照原先条件进行读取时,发现了事务B 新插入的数据 称为幻读。**
#### 幻读和不可重复读的区别:
**不可重复读:是同一条SQL查询的内容不同(被修改了)**
**幻读是:查询的结果条数不同(增加了、或者删除了记录)**
#### 幻读的影响
会造成一个事务中先产生的锁,无法锁住后加入的满足条件的行。
产生数据一致性问题,在一个事务中,先对符合条件的目标行做变更,而在事务提交前有新的符合目标条件的行加入。这样通过binlog恢复的数据是会将所有符合条件的目标行都进行变更的。
#### 幻读产生的原因
行锁只能锁住行,即使把所有的行记录都上锁,也阻止不了新插入的记录。
#### MySQL如何解决幻读
- 将两行记录间的空隙加上锁,阻止新记录的插入;这个锁称为**间隙锁**。
- 间隙锁与间隙锁之间没有冲突关系。跟间隙锁存在冲突关系的,是**往这个间隙中插入一个记录**这个操作。
### 事务的隔离级别
为了处理这些问题,SQL标准定义了以下几种事务隔离级别
| | 脏读 | 不可重复读 | 幻读 |
| ---------------- | ---- | ---------- | ---- |
| Read uncommitted | √ | √ | √ |
| Read committed | × | √ | √ |
| Repeatable read | × | × | √ |
| Serializable | × | x | x |
数据库共定义了四种隔离级别:
- Serializable:可避免脏读、不可重复读、幻读情况的发生。(串行化)
- Repeatable read:可避免脏读、不可重复读情况的发生。(可重复读)
- Read committed:可避免脏读情况发生(读已提交)。
- Read uncommitted:最低级别,以上情况均无法保证。(读未提交)
可以通过命令` set transaction`命令设置事务隔离级别:
```mysql
set transaction_isolation level 设置事务隔离级别
select @@transaction_isolation; 查询当前事务隔离级别
```
## 数据库锁
锁(lock):代表一种状态,而在数据库中锁,指的就是并发时的数据控制问题,也是就加锁。
锁的分类
+ 基于锁的颗粒度:行级锁、表级锁、间隙锁
+ 基于锁的读写功能:读锁(共享锁、S锁)、写锁(排它锁、X锁)
+ 基于锁的功能:悲观锁和乐观锁
+ 悲观锁:肯定加锁,默认会出错
+ 乐观锁:默认不会出错,所以并发度非常高,MVCC(Multiversion Concurrency Control)
## 数据库优化
系统优化:硬件、架构
- 服务优化
- 应用优化
影响性能的因素
- 应用程序
- 查询
- 事务管理
- 数据库设计
- 数据分布
- 网络
- 操作系统
- 硬件
谁参与优化
```
数据库管理员
业务部门代表
应用程序架构师
应用程序设计人员
应用程序开发人员
硬件及系统管理员
存储管理员
```
**1、系统优化**
```
1、硬件优化
cpu 64位 一台机器8-16颗CPU
内存 96-128G 3-4个实例
硬盘:数量越多越好 性能:ssd(高并发业务) > sas (普通业务)>sata(线下业务)
raid 4块盘,性能 raid0 > raid10 > raid5 > raid1
网卡:多块网卡bond
2、软件优化
操作系统:使用64位系统
软件:MySQL 编译优化
```
**2、服务优化**
```
MySQL配置原则
配置合理的MySQL服务器,尽量在应用本身达到一个MySQL最合理的使用
针对 MyISAM 或 InnoDB 不同引擎进行不同定制性配置
针对不同的应用情况进行合理配置
针对 my.cnf 进行配置,后面设置是针对内存为2G的服务器进行的合理设置
```
**公共选项:**
| 选项 | 缺省值 | 推荐值 | 说明 |
| ---------------- | ----------- | ------ | ------------------------------------------------------------ |
| max_connections | 100 | 1024 | MySQL服务器同时处理的数据库连接的最大数量 |
| query_cache_size | 0 (不开启) | 16M | 查询缓存区的最大长度,按照当前需求,一倍一倍增加,本选项比较重要 |
| sort_buffer_size | 512K | 16M | 每个线程的排序缓存大小,一般按照内存可以设置为2M以上,推荐是16M,该选项对排序order by,group by起作用 |
| record_buffer | 128K | 16M | 每个进行一个顺序扫描的线程为其扫描的每张表分配这个大小的一个缓冲区,可以设置为2M以上 |
| table_cache | 64 | 512 | 为所有线程打开表的数量。增加该值能增加mysqld要求的文件描述符的数量。MySQL对每个唯一打开的表需要2个文件描述符。 |
**MyISAM 选项:**
| 选项 | 缺省值 | 推荐值 | 说明 |
| ----------------------- | ------ | ------ | ------------------------------------------------------------ |
| key_buffer_size | 8M | 256M | 用来存放索引区块的缓存值, 建议128M以上,不要大于内存的30% |
| read_buffer_size | 128K | 16M | 用来做MyISAM表全表扫描的缓冲大小. 为从数据表顺序读取数据的读操作保留的缓存区的长度 |
| myisam_sort_buffer_size | 16M | 128M | 设置,恢复,修改表的时候使用的缓冲大小,值不要设的太大 |
**InnoDB 选项:**
| 选项 | 缺省值 | 推荐值 | 说明 |
| ------------------------------- | ------ | ------ | ------------------------------------------------------------ |
| innodb_buffer_pool_size | 32M | 1G | InnoDB使用一个缓冲池来保存索引和原始数据, 这里你设置越大,你在存取表里面数据时所需要的磁盘I/O越少,一般是内存的一半,不超过2G,否则系统会崩溃,这个参数非常重要 |
| innodb_additional_mem_pool_size | 2M | 128M | InnoDB用来保存 metadata 信息,如果内存是4G,最好本值超过200M |
| innodb_flush_log_at_trx_commit | 1 | 0 | 0 代表日志只大约每秒写入日志文件并且日志文件刷新到磁盘; 1 为执行完没执行一条SQL马上commit; 2代表日志写入日志文件在每次提交后,但是日志文件只有大约每秒才会刷新到磁盘上. 对速度影响比较大,同时也关系数据完整性 |
| innodb_log_file_size | 8M | 256M | 在日志组中每个日志文件的大小, 一般是innodb_buffer_pool_size的25%,官方推荐是innodb_buffer_pool_size 的 40-50%, 设置大一点来避免在日志文件覆写上不必要的缓冲池刷新行为 |
| innodb_log_buffer_size | 128K | 8M | 用来缓冲日志数据的缓冲区的大小.推荐是8M,官方推荐该值小于16M,最好是 1M-8M 之间 |
**参数优化 :**
**Max_connections**
```mysql
(1)简介
Mysql的最大连接数,如果服务器的并发请求量比较大,可以调高这个值,当然这是要建立在机器能够支撑的
情况下,因为如果连接数越来越多,mysql会为每个连接提供缓冲区,就会开销的越多的内存,所以需要适当
的调整该值,不能随便去提高设值。
(2)判断依据
show variables like 'max_connections';
+-----------------+-------+
| Variable_name | Value |
+-----------------+-------+
| max_connections | 151 |
+-----------------+-------+
show status like 'Max_used_connections';
+----------------------+-------+
| Variable_name | Value |
+----------------------+-------+
| Max_used_connections | 101 |
+----------------------+-------+
(3)修改方式举例
vim /etc/my.cnf
Max_connections=1024
补充:
1.开启数据库时,我们可以临时设置一个比较大的测试值
2.观察show status like 'Max_used_connections';变化
3.如果max_used_connections跟max_connections相同,
那么就是max_connections设置过低或者超过服务器的负载上限了,
低于10%则设置过大.
```
**back_log**
```mysql
(1)简介
mysql能暂存的连接数量,当主要mysql线程在一个很短时间内得到非常多的连接请求时候它就会起作用,如
果mysql的连接数据达到max_connections时候,新来的请求将会被存在堆栈中,等待某一连接释放资源,
该推栈的数量及back_log,如果等待连接的数量超过back_log,将不被授予连接资源。
back_log值指出在mysql暂时停止回答新请求之前的短时间内有多少个请求可以被存在推栈中,只有如果期
望在一个短时间内有很多连接的时候需要增加它
(2)判断依据
show full processlist
发现大量的待连接进程时,就需要加大back_log或者加大max_connections的值
(3)修改方式举例
vim /etc/my.cnf
back_log=1024
```
**wait_timeout和interactive_timeout**
```mysql
(1)简介
wait_timeout:指的是mysql在关闭一个非交互的连接之前所要等待的秒数
interactive_timeout:指的是mysql在关闭一个交互的连接之前所需要等待的秒数,比如我们在终端上进
行mysql管理,使用的即使交互的连接,这时候,如果没有操作的时间超过了interactive_time设置的时
间就会自动的断开,默认的是28800,可调优为7200。
wait_timeout:如果设置太小,那么连接关闭的就很快,从而使一些持久的连接不起作用
(2)设置建议
如果设置太大,容易造成连接打开时间过长,在show processlist时候,能看到很多的连接 ,一般希望
wait_timeout尽可能低
(3)修改方式举例
wait_timeout=60
interactive_timeout=1200
长连接的应用,为了不去反复的回收和分配资源,降低额外的开销。
一般我们会将wait_timeout设定比较小,interactive_timeout要和应用开发人员沟通长链接的应用是
否很多。如果他需要长链接,那么这个值可以不需要调整。
另外还可以使用类外的参数弥补。
```
**max_allowed_packet**
```mysql
(1)简介:
mysql根据配置文件会限制,server接受的数据包大小。
(2)配置依据:
有时候大的插入和更新会受max_allowed_packet参数限制,导致写入或者更新失败,更大值是1GB,必须
设置1024的倍数
(3)配置方法:
max_allowed_packet=32M
```
参数优化示例:
```ini
[mysqld]
basedir=/data/mysql
datadir=/data/mysql/data
socket=/tmp/mysql.sock
log-error=/var/log/mysql.log
log_bin=/data/binlog/mysql-bin
binlog_format=row
skip-name-resolve
server-id=52
gtid-mode=on
enforce-gtid-consistency=true
log-slave-updates=1
relay_log_purge=0
max_connections=1024
back_log=128
wait_timeout=60
interactive_timeout=7200
key_buffer_size=16M
query_cache_size=64M
query_cache_type=1
query_cache_limit=50M
max_connect_errors=20
sort_buffer_size=2M
max_allowed_packet=32M
join_buffer_size=2M
thread_cache_size=200
innodb_buffer_pool_size=1024M
innodb_flush_log_at_trx_commit=1
innodb_log_buffer_size=32M
innodb_log_file_size=128M
innodb_log_files_in_group=3
binlog_cache_size=2M
max_binlog_cache_size=8M
max_binlog_size=512M
expire_logs_days=7
read_buffer_size=2M
read_rnd_buffer_size=2M
bulk_insert_buffer_size=8M
[client]
socket=/tmp/mysql.sock
```
压力测试 :
```shell
mysqlslap --defaults-file=/etc/my.cnf --concurrency=100 --iterations=1 --create-schema='db1' --query="select * from db1.t_100w where k2='FGCD'"
engine=innodb --number-of-queries=200000 -uroot -proot -verbose
```
**3、应用优化**
```
设计合理的数据表结构:适当的数据冗余
对数据表建立合适有效的数据库索引
数据查询:编写简洁高效的SQL语句
表结构设计原则
选择合适的数据类型:如果能够定长尽量定长
使用 ENUM 而不是 VARCHAR,ENUM类型是非常快和紧凑的,在实际上,其保存的是 TINYINT,但其
外表上显示为字符串。这样一来,用这个字段来做一些选项列表变得相当的完美 。
不要使用无法加索引的类型作为关键字段,比如 text类型
为了避免联表查询,有时候可以适当的数据冗余,比如邮箱、姓名这些不容易更改的数据
选择合适的表引擎,有时候 MyISAM 适合,有时候InnoDB适合
为保证查询性能,最好每个表都建立有 auto_increment 字段, 建立合适的数据库索引
最好给每个字段都设定 default 值
索引建立原则(一)
一般针对数据分散的关键字进行建立索引,比如ID、QQ,•
像性别、状态值等等建立索引没有意义字段唯一,最少,不可为null
对大数据量表建立聚集索引,避免更新操作带来的碎片。
尽量使用短索引,一般对int、char/varchar、date/time 等类型的字段建立索引
需要的时候建立联合索引,但是要注意查询SQL语句的编写
谨慎建立 unique 类型的索引(唯一索引)
大文本字段不建立为索引,如果要对大文本字段进行检索,
可以考虑全文索引
频繁更新的列不适合建立索引
索引建立原则(二)
order by 字句中的字段,where 子句中字段,最常用的sql语句中字段,应建立索引。
唯一性约束,系统将默认为改字段建立索引。
对于只是做查询用的数据库索引越多越好,但对于在线实时系统建议控制在5个以内。
索引不仅能提高查询SQL性能,同时也可以提高带where字句的update,Delete SQL性能。
Decimal 类型字段不要单独建立为索引,但覆盖索引可以包含这些字段。
只有建立索引以后,表内的行才按照特地的顺序存储,按照需要可以是asc或desc方式。
如果索引由多个字段组成将最用来查询过滤的字段放在前面可能会有更好的性能。
编写高效的 SQL (一)
能够快速缩小结果集的 WHERE 条件写在前面,如果有恒量条件,也尽量放在前面
尽量避免使用 GROUP BY、DISTINCT 、OR、IN 等语句的使用,避免使用联表查询和子查询,
因为将使执行效率大大下降
能够使用索引的字段尽量进行有效的合理排列,如果使用了联合索引,请注意提取字段的前后顺序
针对索引字段使用 >, >=, =, <, <=, IF NULL和BETWEEN 将会使用索引,
如果对某个索引字段进行 LIKE 查询,使用 LIKE ‘%abc%’不能使用索引,使用 LIKE ‘abc%’
将能够使用索引 如果在SQL里使用了MySQL部分自带函数,索引将失效,
同时将无法使用 MySQL 的 Query Cache,
比如 LEFT(), SUBSTR(), TO_DAYS(),DATE_FORMAT(), 等,
如果使用了 OR 或 IN,索引也将失效
使用 Explain 语句来帮助改进我们的SQL语句
编写高效的 SQL (二)
不要在where 子句中的“=”左边进行算术或表达式运算,否则系统将可能无法正确使用索引
尽量不要在where条件中使用函数,否则将不能使用索引
避免使用 select *, 只取需要的字段
对于大数据量的查询,尽量避免在SQL语句中使用order by 字句,避免额外的开销
如果插入的数据量很大,用select into 替代 insert into 能带来更好的性能
采用连接操作,避免过多的子查询,产生的CPU和IO开销
只关心需要的表和满足条件的数据
适当使用临时表或表变量
对于连续的数值,使用between代替in
where 字句中尽量不要使用CASE条件
尽量不用触发器,特别是在大数据表上
更新触发器如果不是所有情况下都需要触发,应根据业务需要加上必要判断条件
使用union all 操作代替OR操作,注意此时需要注意一点查询条件可以使用聚集索引,
如果是非聚集索引将起到相反的结果
当只要一行数据时使用 LIMIT 1
尽可能的使用 NOT NULL填充数据库
拆分大的 DELETE 或 INSERT 语句
批量提交SQL语句
```
4、架构优化
```
1)业务拆分:搜索功能,like ,前后都有%,一般不用MySQL数据库
2)业务拆分:某些应用使用nosql持久化存储,例如memcahcedb、redis、ttserver 比如粉丝关注、好
友关系等;
3)数据库前端必须要加cache,例如memcached,用户登录,商品查询
4)动态数据静态化。整个文件静态化,页面片段静态化
5)数据库集群与读写分离;
6)单表超过2000万,拆库拆表,人工或自动拆分(登录、商品、订单等)
```
5、流程、制度、安全优化
```
任何一次人为数据库记录的更新,都要走一个流程
1)人的流程:开发-->核心开发-->运维或DBA
2)测试流程:内网测试-->IDC测试-->线上执行
3)客户端管理:phpmyadmin等
```
## 数据库三范式
为了建立冗余较小、结构合理的数据库,设计数据库时必须遵循一定的规则。在关系型数据库中这种规则就称为范式。范式是符合某一种设计要求的总结。要想设计一个结构合理的关系型数据库,必须满足一定的范式。
在实际开发中最为常见的设计范式有三个:
**1.第一范式(确保每列保持原子性)**
第一范式是最基本的范式。如果数据库表中的所有字段值都是不可分解的原子值,就说明该数据库表满足了第一范式。**要求任何一张表必须有主键,每一个字段原子性不可再分。**
第一范式的合理遵循需要根据系统的实际需求来定。第一范式是最重要的范式。所有的表的设计都需要满足,必须有主键,并且没有给字段都是原子性不可再分的。
| 编号 | 姓名 | 联系方式 |
| ---- | ---- | ------------------------- |
| 1001 | 张三 | zs@126.com 18994868548 |
| 1002 | 李四 | ls@126.com 18995486324 |
以上设计就是不合适的,不满足第一范式,因为没主键,第二联系方式可以继续拆分
| 编号PK | 姓名 | 邮箱地址 | 电话 |
| ------ | ---- | ---------- | ----------- |
| 1001 | 张三 | zs@126.com | 18994868548 |
| 1002 | 李四 | ls@126.com | 18995486324 |
2. **第二范式(确保表中的每列都和主键相关)**
第二范式在第一范式的基础之上更进一层。第二范式需要确保数据库表中的每一列都和主键相关,而不能只与主键的某一部分相关(主要针对联合主键而言)。也就是说在一个数据库表中,一个表中只能保存一种数据,不可以把多种数据保存在同一张数据库表中。
**第二范式,建立在第一范式的基础之上,要求所有非主键字段完全依赖主键,不要产生部分依赖。**
| 学号 | 姓名 | 教师编号 | 教师姓名 |
| ---- | ---- | -------- | -------- |
| 1001 | 张三 | 001 | 王老师 |
| 1002 | 李四 | 002 | 卢老师 |
以上设计不满足第一范式,没主键。修改表。将学号+教师编号 PK.
| 学号 | 教师编号 | 学生姓名 | 教师姓名 |
| ---- | -------- | -------- | -------- |
| 1001 | 001 | 张三 | 王老师 |
| 1002 | 002 | 李四 | 卢老师 |
| 1003 | 001 | 王五 | 王老师 |
但是不满足第二范式,因为姓名依赖学号。教师姓名依赖教师编号。产生部分依赖造成数据冗余,空间浪费。
需要修改
| 学生编号 | 学生姓名 |
| -------- | -------- |
| 1001 | 张三 |
| 1002 | 李四 |
| 教师编号PK | 教师姓名 |
| ---------- | -------- |
| 001 | 王老师 |
| 002 | 卢老师 |
| PK | 学生编号FK | 教师编号FK |
| ---- | ---------- | ---------- |
| 1 | 1001 | 001 |
| 2 | 1002 | 002 |
这样设计,在很大程度上减小了数据库的冗余。
**3**.第三范式
**第三范式:建立在第二范式的基础之上,要求所有非主键字段直接依赖主键,不要产生传递依赖。**
| 学生编号PK | 姓名 | 班级编号 | 班级名称 |
| ---------- | ---- | -------- | ---------- |
| 1001 | 张三 | 001 | 一年级一班 |
| 1002 | 李四 | 002 | 一年级二班 |
| 1003 | 王五 | 001 | 一年级一班 |
满足第一范式?满足,有主键
满足第二范式?满足,因为主键不是复合主键,没有产生部分依赖,主键是单一主键。
满足第三范式?不满足,第三范式要是不产生传递依赖。一年级一班依赖001,001依赖1001 不符合。
以上拆分两张表即一个学生表,一个班级表,在学生表设计外键即可。
# Redis部分
## 什么是NoSQL
NoSQL(Not Only SQL)即不仅仅是SQL,泛指非关系型的数据库,它可以作为关系型数据库的良好补充。随着互联网web2.0网站的兴起,非关系型的数据库现在成了一个极其热门的新领域,非关系数据库产品的发展非常迅速。
## 为什么会出现NoSQL技术
随着互联网web2.0网站的兴起,传统的关系型数据库在应付web2.0网站,特别是超大规模和高并发的SNS(Social Networking Services 社交网络服务)类型的web2.0纯动态网站已经显得力不从心,暴露了很多难以克服的问题:
1. High performance - 数据的高并发读写
web2.0网站要根据用户个性化信息来实时生成动态页面和提供动态信息,所以基本上无法使用动态页面静态化技术,因此数据库并发负载非常高,往往要达到每秒上万次读写请求。而关系型数据库应付上万次SQL查询还勉强可以承受,但是应付上万次SQL写数据请求,硬盘IO就已经无法承受了。其实对于普通的BBS网站,往往也存在对高并发写请求的需求,例如网站的实时统计在线用户状态,记录热门帖子的点击次数,投票计数等,因此这是一个相当普遍的需求。
2. Huge Storage - 海量数据的高效率存储和访问
类似Facebook,twitter,Friendfeed这样的SNS网站,每天用户产生海量的用户动态,如Friendfeed一个月就达到了2.5亿条用户动态。对于关系型数据库而言,在一张2.5亿条记录的表里面进行SQL查询,效率是极其低下乃至不可忍受的。同样对于大型web网站的用户登录系统,如腾讯、阿里、网易等动辄数以亿计的帐号,使用关系型数据库很难应付。
3. High Scalability & High Availability - 数据库的高扩展和高可用
在基于web的架构当中,数据库是最难进行横向扩展的,当一个应用系统的用户量和访问量与日俱增的时候,你的数据库却没有办法像web server和app server那样简单的通过添加更多的硬件和服务节点来扩展性能和负载能力。对于很多需要提供24小时不间断服务的网站来说,对数据库系统进行升级和扩展是非常痛苦的事情,往往需要停机维护和数据迁移,因此需要数据库具有可扩展和高可用的特性。
> 总结:传统的关系型数据库只能存储结构化数据,对于非结构化的数据支持不够完善。NoSQL数据库的产生就是为了解决大规模数据集合多重数据种类带来的挑战,尤其是大数据应用难题。

## NoSQL的类别
- 键值(Key-Value)存储数据库
说明:这一类数据库主要会使用到一个哈希表,这个表中有一个特定的键和一个指针指向特定的数据。
Key/Value模型对于IT系统来说优势在于简单、易部署。
应用:内容缓存,主要用于处理大量数据的高访问负载。
产品:Tokyo Cabinet/Tyrant、Redis、Voldemort、Berkeley DB
优势:快速查询
劣势:存储的数据缺少结构化
- 列存储数据库
说明:这部分数据库通常是用来应对分布式存储的海量数据。键仍然存在,但是它们的特点是指向了多个列,这些列是由列家族来安排的。
应用:分布式文件系统
产品:Cassandra,HBase,Riak
优势:查找速度快,可扩展性强,更容易进行分布式扩展
劣势:功能相对局限
- 文档型数据库
说明:该类型的数据模型 是版本化的文档,半结构化的文档以特定的格式存储,如JSON。文档型数据库可以看作是键值数据库的升级版,允许之间嵌套键值。而且文档型数据库比键值数据库的查询效率更高。
应用:Web应用
产品:CouchDB,MongoDB
优势:数据结构要求不严格
劣势:查询性能不高,且缺乏统一的查询语法
- 图形(Graph)数据库
说明:图形结构的数据库同其他行列以及刚性结构的SQL数据库不同,它是使用灵活的图形模型,并且能够扩展到多个服务器上。NoSQL数据库没有标准的查询语言(SQL),因此进行数据库查询需要制定数据模型。许多NoSQL数据库都有REST格式的数据接口或者查询API。
应用:社交网络
产品: Neo4j,InfoGrid,Infinite Graph
优势:利用图结构相关算法
劣势:需要对整个图做计算才能得出结果,不容易做分布式的集群方案
## NoSQL适应场景
1. 数据模型比较简单
2. 需要灵活性更强的IT系统
3. 对数据库性能要求较高
4. 不需要高度的数据一致性
5. 对于给定key,比较容易映射复杂的环境
6. 取最新的N个数据(如排行榜)
7. 数据缓存
## 在分布式数据库中CAP原理
### 传统的ACID是什么
关系型数据库遵循ACID规则,事务在英文中是transaction,和现实世界中的交易很类似,它有如下四个特性:
1. A (Atomicity) 原子性
指事务里的所有操作要么都成功,要么都失败。事务成功的条件是事务里的所有操作都成功,只要有一个操作失败,整个事务就失败,需要回滚。
2. C (Consistency) 一致性
指数据库要一直处于一致的状态,事务的运行不会改变数据库原本的一致性约束。
3. I (Isolation) 隔离性
指并发的事务之间不会互相影响,如果一个事务要访问的数据正在被另外一个事务修改,只要另外一个事务未提交,它所访问的数据就不受未提交事务的影响。
4. D (Durability) 持久性
是指一旦事务提交后,它所做的修改将会永久的保存在数据库中,即使出现宕机也不会丢失。
### CAP
> - Consistency(强一致性)
> - Availability(可用性)
> - Partition tolerance(分区容错性)
CAP理论是指在分布式存储系统中,最多只能实现上面的两点。由于当前的网络硬件存在延迟丢包等问题,所以分区容忍性是我们必须要实现的。所以我们只能在一致性和可用性之间进行权衡,没有NoSQL系统能同时保证这三点。
- CA 传统Oracle数据库
- AP 大多数网站架构的选择
- CP Redis、Mongodb
> 注意:在做分布式架构的时候必须做出取舍。一致性和可用性之间取一个平衡。对于大多数web应用,其实并不需要强一致性。因此牺牲C换取P,这是目前分布式数据库产品的方向。
### 经典CAP图
CAP理论的核心是:`一个分布式系统不可能同时很好的满足一致性,可用性和分区容错性这三个需求,最多只能同时较好的满足两个。`因此,根据 CAP 原理将 NoSQL 数据库分成了满足 CA 原则、满足 CP 原则和满足 AP 原则三 大类:
- CA - 单点集群,满足一致性,可用性的系统,通常在可扩展性上不太强大。
- CP - 满足一致性,分区容忍必的系统,通常性能不是特别高。
- AP - 满足可用性,分区容忍性的系统,通常可能对一致性要求低一些。

### 什么是BASE
BASE就是为了解决关系数据库强一致性引起的问题而导致可用性降低而提出的解决方案。BASE其实是下面三个术语的缩写:
> 基本可用(Basically Available)
>
> 软状态(Soft state)
>
> 最终一致(Eventually consistent)
它的思想是通过让系统放松对某一时刻数据一致性的要求来换取系统整体伸缩性和性能上改观。为什么这么说呢,缘由就在于大型系统往往由于地域分布和极高性能的要求,不可能采用分布式事务来完成这些指标,要想获得这些指标,我们必须采用另外一种方式来完成,这里BASE就是解决这个问题的办法。
## 什么是Redis
2008年,意大利的一家创业公司Merzia推出了一款基于MySQL的网站实时统计系统LLOOGG,然而没过多久该公司的创始人 Salvatore Sanfilippo便开始对MySQL的性能感到失望,于是他决定亲自为LLOOGG量身定做一个数据库,并于2009年开发完成,这个数据库就是Redis。不过Salvatore Sanfilippo并不满足只将Redis用于LLOOGG这一款产品,而是希望更多的人使用它,于是在同一年Salvatore Sanfilippo将Redis开源发布,并开始和Redis的另一名主要的代码贡献者Pieter Noordhuis一起继续着Redis的开发,直到今天。
Salvatore Sanfilippo自己也没有想到,短短的几年时间,Redis就拥有了庞大的用户群体。Hacker News在2012年发布了一份数据库的使用情况调查,结果显示有近12%的公司在使用Redis。国内如新浪微博、街旁网、知乎,国外如GitHub、Stack Overflow、Flickr、暴雪和Instagram,都是Redis的用户。
VMware公司从2010年开始赞助Redis的开发, Salvatore Sanfilippo和Pieter Noordhuis也分别在3月和5月加入VMware,全职开发Redis。【本部分内容取自《REDIS入门指南》】
> Redis is an open source (BSD licensed), in-memory data structure store, used as a database, cache and message broker. It supports data structures such as strings, hashes, lists, sets, sorted sets with range queries, bitmaps, hyperloglogs, geospatial indexes with radius queries and streams. Redis has built-in replication, Lua scripting, LRU eviction, transactions and different levels of on-disk persistence, and provides high availability via Redis Sentinel and automatic partitioning with Redis Cluster.
Redis(REmote Dctionary Server 远程字典服务器),是完全开源免费的,用C语言编写的,遵守`BSD`协议,是一个高性能的(key/value)分布式内存数据库,基于内存运行,并支持持久化的NoSQL数据库,是当前最热门的NoSQL数据库之一, 也被人们称为数据结构服务器。
Redis是一个开源(BSD许可),内存存储的数据结构服务器,可用作数据库,高速缓存和消息队列代理。它支持[字符串](https://www.redis.net.cn/tutorial/3508.html)、[哈希表](https://www.redis.net.cn/tutorial/3509.html)、[列表](https://www.redis.net.cn/tutorial/3510.html)、[集合](https://www.redis.net.cn/tutorial/3511.html)、[有序集合](https://www.redis.net.cn/tutorial/3512.html),[位图](https://www.redis.net.cn/tutorial/3508.html),[hyperloglogs](https://www.redis.net.cn/tutorial/3513.html)等数据类型。内置复制、[Lua脚本](https://www.redis.net.cn/tutorial/3516.html)、LRU收回、[事务](https://www.redis.net.cn/tutorial/3515.html)以及不同级别磁盘持久化功能,同时通过Redis Sentinel提供高可用,通过Redis Cluster提供自动[分区](https://www.redis.net.cn/tutorial/3524.html)。
Redis是一个开源的高性能键值对(Key-Value)数据库。它通过提供多种键值数据类型来适应不同场景下的存储需求,目前为止Redis支持的键值数据类型如下:
- 字符串类型
- 散列类型
- 列表类型
- 集合类型
- 有序集合类型
学习参考网站:https://www.redis.net.cn/
### Redis能干什么
- 内存存储和持久化:redis支持异步将内存中的数据写到硬盘上,同时不影响继续服务
- 取最新N个数据的操作,如:可以将最新的10条评论的ID放在Redis的List集合里面
- 模拟类似于HttpSession这种需要设定过期时间的功能
- 发布、订阅消息系统
- 定时器、计数器
### Redis的特点
- 性能极高:Redis 读的速度是 110000 次 /s,写的速度是 81000 次 /s 。
- 丰富的数据类型:Redis 支持二进制案例的 String,List,Hash,Set及 ZSet 数据类型操作。
- 原子性:Redis 的所有操作都是原子性的,意思就是要么成功执行要么失败完全不执行。单个操作是原子性的。多个操作也支持事务,即原子性,通过 MULTI 和 EXEC 指令包起来。
- 数据持久化:可以将内存中的数据保存在磁盘中,重启的时候可以再次加载进行使用
- 其他特性:Redis 还支持 publish/subscribe 通知,key 过期等特性。
> Redis 提供的API支持:C、C++、C#、Clojure、Java、JavaScript、Lua、PHP、Python、Ruby、Go、Scala、Perl等多种语言。
### Redis与memcached对比
- 共同点
无论是Memcached还是Redis底层都是使用C语言编写,都是基于key-value,存储的数据都是在内存中。
- 不同点
Memcached支持的数据类型比较简单(String,Object);Redis 支持的数据类型比较丰富。
Memcached默认一个值的最大存储不能超过1M;Redis一个值的最大存储1G。
Memcached中存储的数据不能持久化,一旦断电数据丢失;Redis中存储的数据可以持久化。
Memcached是多线程,支持并发访问;Redis是单线程,不支持并发访问。
Memcached自身不支持集群环境;Redis从3.0版本之后自身开始提供集群环境支持。
## Redis的安装
从Redis官网进行下载。https://redis.io/
### window安装
注意:Redis官方没有提供Redis的window版本,只提供了linux版本C语言源码安装方式,所以在企业中只能使用linux版本安装【参考后面部分】,但是在学习阶段,我们在window上使用确实方便。
微软的开源部门,为我们根据Redis源码,编译得到了一个window版的Redis。
官方地址:https://github.com/MicrosoftArchive/redis/releases
遗憾的是,微软在2016年后,也就是Redis3之后没有在更新版本,学习的话,是可以的,但是新版本的新特性则无法使用。
因此在2017年开始,另外一个程序员:tporadowski,开始了window上Redis的维护,从4.0开始,目前已经到5.0版本,建议大家下载这个版本:
官方地址:https://github.com/tporadowski/redis/releases
1、使用`.msi`方式安装
这种安装方式没有什么可说的,下一步,下一步,直至完成,完成后,Redis就会被注册成window的服务,在Redis主目录下,使用redis-cli,即可连接Redis服务器。
2、使用`zip`方式安装【推荐方式】
下载安装包,解压后,打开文件夹,内容如下:

为了方便启动,我们在该目录下新建一个 **startup.cmd** 的文件,然后将以下内容写入文件:
> **redis-server redis.windows.conf**
这个命令其实就是在调用 redis-server.exe 命令来读取 redis.window.conf 的内容,我们双击刚才创建好的 startup.cmd 文件,就能成功的看到 Redis 启动:

或者另一种方法打开一个cmd窗口使用cd命令切换目录到redis目录下:


输入启动命令:
> redis-server.exe redis.windows.conf
在启动时候得另启一个cmd窗口,原来的不要关闭,不然就无法访问服务端了,切换到redis目录下运行
> redis-cli.exe -h 127.0.0.1 -p 6379
设置键值对:
> set myKey abc
取出键值对:
> get myKey

直接也可以通过点击程序开启连接

为了方便,我们还可以配置redis的环境变量,可以把 redis 的路径加到系统的环境变量里,这样就省得再输路径了,后面的那个 redis.windows.conf 可以省略,如果省略,会启用默认的。
**配置环境变量**
配置redis环境变量,把redis路径配置到系统变量的path值中,如图:

**配置后台运行**
添加进服务
1. 进入 DOS窗口
2. 在进入redis的安装目录 cmd窗口执行一下命令
3. 输入:`redis-server --service-install redis.windows.conf` --loglevel verbose ( 安装redis服务 )
4. 输入:redis-server --service-start ( 启动服务 )
5. 输入:redis-server --service-stop (停止服务)

### 源码安装
下面以 redis-6.2.7.tar.gz 版为例,来说明redis的安装与配置。
#### 1、准备安装环境
由于 Redis 是基于 C 语言编写的,因此首先需要安装 Redis 所需要的依赖:
```sh
yum install -y gcc tcl gcc-c++ make
```
#### 2、上传安装文件
将下载好的 redis-6.2.7.tar.gz 安装包上传到虚拟机的任意目录(一般推荐上传到 `/usr/local/src`目录)。
#### 3、解压安装文件
上传后执行如下命令来进行解压。
```sh
tar -zxvf redis-6.2.7.tar.gz
```
#### 4、进入安装目录
解压完成后,执行如下命令进入解压目录。
```sh
cd redis-6.2.7
```
#### 5、运行编译命令
然后执行如下命令进行编译。
```sh
make && make install
```
> 说明:如果在编译过程中出现 `Jemalloc/jemalloc.h:没有那个文件` 没有的错误,在确保 gcc 安装成功后,可执行 `make distclean` 进行清除后再次安装。
如果没有出错,就会安装成功。默认的安装路径是在 `/usr/local/bin` 目录下。可以将这个目录配置到环境变量中,这样就可以在任意目录下运行这些命令了。主要的几个命令说明如下:
- redis-server:它是 redis 的服务端启动脚本
- redis-cli:它是 redis 提供的客户端启动脚本
- redis-sentinel:它是 redis 提供的哨兵启动脚本
- redis-benchmark:性能测试工具,可以在自己电脑上运行来查看性能
- redis-check-aof:修复有问题的AOF文件
- redis-check-dump:修复有问题的dump.rdb文件
#### 6、前台启动
执行如下命令来启动 redis。
```sh
redis-server
```

注意:这里直接执行 `redis-server` 启动的 Redis 服务,是在前台直接运行的(效果如上图),也就是说,执行完该命令后,如果关闭当前会话,则Redis服务也随即关闭,因此这种方式不推荐使用。正常情况下,启动 Redis 服务需要从后台启动。
> 查看Redis服务:
>
> 1. ps -ef | grep redis
>
> 关闭Redis服务:
>
> 1. pkill redis-server
> 2. kill 进程号
> 3. 单实例关闭:redis-cli shutdown
> 4. 多实例关闭:redis-cli -p 6379 shutdown
#### 7、后台启动
在 redis 的安装目录中,有一个 redis.conf 文件,我们把这个文件复制到 /etc/目录下:
```sh
cp /usr/local/redis/redis.conf /etc/
```
然后修改 `/etc/redis.conf` 文件,把 daemonize 值设置为 yes 即可。
```sh
vim /etc/redis.conf # 修改daemonize no
```

保存退出后,执行如下命令来启动服务。
```sh
bin>redis-server /etc/redis.conf
```
#### 8、验证服务
我们可以使用 redis-cli 脚本来连接 redis 服务。
```sh
redis-cli -p 6379
```
然后执行如下命令:
```sh
127.0.0.1:6379> ping
PONG
```
如果能够看到如上信息,表示连接成功。
#### 9、关闭服务
可以执行如下命令来关闭 redis 服务。
```sh
redis-cli shutdown
```
关闭后可以执行如下命令来查看进程是否还存在。
```sh
ps -ef | grep redis
```
> 注意:也可以进入终端后再关闭:
>
> ```sh
> 127.0.0.1:6379> shutdown
> ```
#### 10、相关知识
redis 默认的端口号是 `6379`,默认有 16 个数据库,类似数组下标从 0 开始,初始默认使用 0 号数据库。
可以使用 `select <dbid>` 命令来切换数据库。例如切换到 2 号数据库是 `select 2`。
在 redis 中,可以使用 `dbsize` 命令来查看当前数据库的 key 的数量,也可以使用 `flushdb` 命令来清空当前数据库中所有数据,还可以使用 `flushall` 命令来删除所有数据库中的数据。
Redis是单线程+多路IO复用技术。多路复用是指使用一个线程来检查多个文件描述符(Socket)的就绪状态,比如调用select和poll函数,传入多个文件描述符,如果有一个文件描述符就绪,则返回,否则阻塞直到超时。得到就绪状态后进行真正的操作可以在同一个线程里执行,也可以启动线程执行(比如使用线程池)。
#### 11、开启启动
redis 没有开机启动功能,我们需要编写脚本来实现这个功能。我们在 `/etc/systemd/system` 目录下新建 `redis.service` 文件。
```sh
cd /etc/systemd/system
mkdir redis.service
```
然后添加如下内容:
```bash
[Unit]
#服务描述
Description=Redis Server Manager
#服务类别
After=network.target
[Service]
#后台运行的形式
Type=forking
#服务命令
ExecStart=/usr/local/redis-6.2.7/bin/redis-server /etc/redis.conf
#给服务分配独立的临时空间
PrivateTmp=true
[Install]
#运行级别下服务安装的相关设置,可设置为多用户,即系统运行级别为3
WantedBy=multi-user.target
```
然后执行如下命令:
```sh
systemctl start redis.service #启动redis服务
systemctl enable redis.service #设置开机自启动
```
### Docker安装
#### 1、拉取镜像
```sh
// 拉取最新
docker pull redis
//拉取指定版本
docker pull redis:6.2.7
```
#### 2、查看镜像
```sh
docker images
```
#### 3、运行容器
```sh
docker run --restart=always --log-opt max-size=100m --log-opt max-file=2 -p 6379:6379 --name myredis -v /home/redis/myredis/myredis.conf:/etc/redis/redis.conf -v /home/redis/myredis/data:/data -d redis redis-server /etc/redis/redis.conf --appendonly yes --requirepass 000415
```
> 参数说明:
>
> - –restart=always:总是开机启动
> - –log:配置日志
> - -p 6379:6379:将6379端口挂载出去
> - –name:给这个容器取一个名字
> - -v:数据卷挂载
> - /home/redis/myredis/myredis.conf:/etc/redis/redis.conf:这里是将 liunx 路径下的myredis.conf 和redis下的redis.conf 挂载在一起。
> - /home/redis/myredis/data:/data:这个同上
> - -d redis:表示后台启动redis
> - redis-server /etc/redis/redis.conf:以配置文件启动redis,加载容器内的conf文件,最终找到的是挂载的目录 /etc/redis/redis.conf 也就是liunx下的/home/redis/myredis/myredis.conf
> - –appendonly yes:开启redis 持久化
> - –requirepass 000415:设置密码 (如果你是通过docker 容器内部连接的话,可设可不设。但是如果想向外开放的话,一定要设置)
#### 4、查看容器
```sh
docker ps
```
#### 5、连接容器
```sh
docker exec -it myredis redis-cli
```
#### 6、测试容器
```sh
set name zs
get name
```
## Redis的数据类型
Redis提供了很多好用的数据类型,用来存储不同的数据,方便开发者操作。
+ String
+ hash
+ list
+ set
+ zset
+ bitmap
+ hyperloglogs
+ (geo)地图定位……
### Key操作
#### 相关命令
| 序号 | 命令语法 | 描述 |
| ---- | ----------------------------------------- | ------------------------------------------------------------ |
| 1 | DEL key | 该命令用于在 key 存在时删除 key |
| 2 | DUMP key | 序列化给定 key ,并返回被序列化的值 |
| 3 | EXISTS key | 检查给定 key 是否存在,存在返回1,否则返回0 |
| 4 | EXPIRE key seconds | 为给定 key 设置过期时间,以秒计 |
| 5 | EXPIREAT key timestamp | EXPIREAT 的作用和 EXPIRE 类似,都用于为 key 设置过期时间。不同在于 EXPIREAT 命令接受的时间参数是 UNIX 时间戳 |
| 6 | PEXPIRE key milliseconds | 设置 key 的过期时间以毫秒计 |
| 7 | PEXPIREAT key milliseconds-timestamp | 设置 key 过期时间的时间戳(unix timestamp) 以毫秒计 |
| 8 | KEYS pattern | 查找所有符合给定模式( pattern)的 key |
| 9 | MOVE key db | 将当前数据库的 key 移动到给定的数据库 db 当中 |
| 10 | PERSIST key | 移除 key 的过期时间,key 将持久保持 |
| 11 | PTTL key | 以毫秒为单位返回 key 的剩余的过期时间 |
| 12 | TTL key | 以秒为单位,返回给定 key 的剩余生存时间(TTL, time to live) |
| 13 | RANDOMKEY | 从当前数据库中随机返回一个 key |
| 14 | RENAME key newkey | 修改 key 的名称 |
| 15 | RENAMENX key newkey | 仅当 newkey 不存在时,将 key 改名为 newkey |
| 16 | SCAN cursor [MATCH pattern] [COUNT count] | 迭代数据库中的数据库键 |
| 17 | TYPE key | 返回 key 所储存的值的类型 |
| 18 | SELECT db | 选择数据库 数据库为0-15(默认一共16个数据库) |
| 19 | DBSIZE | 查看数据库的key数量 |
| 20 | FLUSHDB | 清空当前数据库 |
| 21 | FLUSHALL | 清空所有数据库 |
| 22 | ECHO | 打印命令 |
> 说明:
> KEYS * 匹配数据库中所有key
> KEYS h?llo 匹配hello,hallo,hxllo等
> KEYS h*llo 匹配hllo和heeello等
> KEYS h[ae]llo 匹配hello和hallo
#### 示例演示
```bash
127.0.0.1:6379> dbsize
(integer) 0
127.0.0.1:6379> keys *
(empty array)
127.0.0.1:6379> set name openlab
OK
127.0.0.1:6379> get name
"openlab"
127.0.0.1:6379> type name
string
127.0.0.1:6379> EXISTS name
(integer) 1
```
### String
String 是 redis 最基本的类型,你可以理解成与 Memcached 一模一样的类型,一个 key 对应一个 value。
String 类型是二进制安全的,意思是 redis 的 string 可以包含任何数据。比如jpg图片或者序列化的对象。
String 类型是 Redis 最基本的数据类型,String 类型的值最大能存储 512MB。
> String类型一般用于缓存、限流、计数器、分布式锁、分布式Session。
#### 结构图

#### 相关命令
| 序号 | 命令语法 | 描述 |
| ---- | -------------------------------- | ------------------------------------------------------------ |
| 1 | SET key value | 设置指定 key 的值 |
| 2 | GET key | 获取指定 key 的值 |
| 3 | GETRANGE key start end | 返回 key 中字符串值的子字符,end=-1时表示全部 |
| 4 | SETBIT key offset value | 对 key 所储存的字符串值,设置或清除指定偏移量上的位(bit) |
| 5 | GETBIT key offset | 对 key 所储存的字符串值,获取指定偏移量上的位(bit) |
| 6 | MSET key value [key value ...] | 同时设置一个或多个 key-value 对 |
| 7 | MGET key1 [key2..] | 获取所有(一个或多个)给定 key 的值 |
| 8 | GETSET key value | 将给定 key 的值设为 value ,并返回 key 的旧值(old value) |
| 9 | SETEX key seconds value | 将值 value 关联到 key ,并将 key 的过期时间设为 seconds (以秒为单位) |
| 10 | SETNX key value | 只有在 key 不存在时设置 key 的值 |
| 11 | SETRANGE key offset value | 用 value 参数覆写给定 key 所储存的字符串值,从偏移量 offset 开始 |
| 12 | STRLEN key | 返回 key 所储存的字符串值的长度 |
| 13 | MSETNX key value [key value ...] | 同时设置一个或多个 key-value 对,当且仅当所有给定 key 都不存在 |
| 14 | PSETEX key milliseconds value | 与 SETEX 命令相似,但它以毫秒为单位设置 key 的生存时间 |
| 15 | INCR key | 将 key 中储存的数字值增一 |
| 16 | INCRBY key increment | 将 key 所储存的值加上给定的增量值(increment) |
| 17 | INCRBYFLOAT key increment | 将 key 所储存的值加上给定的浮点增量值(increment) |
| 18 | DECR key | 将 key 中储存的数字值减一 |
| 19 | DECRBY key decrement | key 所储存的值减去给定的减量值(decrement) |
| 20 | APPEND key value | 如果 key 已经存在并且是一个字符串,APPEND 命令将指定的 value 追加到该 key 原来值 value 的末尾 |
#### 示例演示
```bash
127.0.0.1:6379> SET name redis
OK
127.0.0.1:6379> GET name
"redis"
# 如果值是中文,则需要在连接客户端是指定规则
./redis-cli -p 6379 --raw
```
### List
Redis列表是简单的字符串列表,按照插入顺序排序。你可以添加一个元素到列表的头部(左边)或者尾部(右边)一个列表最多可以包含 2^32^ - 1 个元素 (4294967295, 每个列表超过40亿个元素)。
> List类型一般用于关注人、简单队列等。
#### 结构图

#### 相关命令
| 序号 | 命令语法 | 描述 |
| ---- | ------------------------------------- | ------------------------------------------------------------ |
| 1 | LPUSH key value1 [value2] | 将一个或多个值插入到列表头部 |
| 2 | LPOP key | 移出并获取列表的第一个元素 |
| 3 | LRANGE key start stop | 获取列表指定范围内的元素 |
| 4 | LPUSHX key value | 将一个值插入到已存在的列表头部 |
| 5 | RPUSH key value1 [value2] | 在列表中添加一个或多个值 |
| 6 | RPOP key | 移除列表的最后一个元素,返回值为移除的元素 |
| 7 | RPUSHX key value | 为已存在的列表添加值 |
| 8 | LLEN key | 获取列表长度 |
| 9 | LINSERT key BEFORE\|AFTER pivot value | 在列表的元素前或者后插入元素 |
| 10 | LINDEX key index | 通过索引获取列表中的元素 |
| 11 | LSET key index value | 通过索引设置列表元素的值 |
| 12 | LREM key count value | 移除列表元素 |
| 13 | LTRIM key start stop | 对一个列表进行修剪,就是让列表只保留指定区间内的元素,不在指定区间之内的元素都将被删除 |
| 14 | BLPOP key1 [key2 ] timeout | 移出并获取列表的第一个元素,如果列表没有元素会阻塞列表直到等待超时或发现可弹出元素为止 |
| 15 | BRPOP key1 [key2 ] timeout | 移出并获取列表的最后一个元素,如果列表没有元素会阻塞列表直到等待超时或发现可弹出元素为止 |
| 16 | BRPOPLPUSH source destination timeout | 从列表中弹出一个值,将弹出的元素插入到另外一个列表中并返回它;如果列表没有元素会阻塞列表直到等待超时或发现可lpu弹出元素为止 |
| 17 | RPOPLPUSH source destination | 移除列表的最后一个元素,并将该元素添加到另一个列表并返回 |
#### 示例演示
```bash
127.0.0.1:6379> LPUSH name zhangsan
(integer) 1
127.0.0.1:6379> LPUSH name lisi
(integer) 2
127.0.0.1:6379> LPUSH name wangwu
(integer) 3
127.0.0.1:6379> LRANGE name 0 10
1) "wangwu"
2) "lisi"
3) "zhangsan"
```
### Set
Redis 的 Set 是 String 类型的无序集合。集合中成员是唯一的,这就意味着集合中不能出现重复的数据。Redis 中集合是通过哈希表实现的,所以添加,删除,查找的复杂度都是 O(1)。 集合中最大的成员数为 2^32^ - 1 (4294967295, 每个集合可存储40多亿个成员)。
> Set类型一般用于赞、踩、标签、好友关系等。
#### 结构图

#### 相关命令
| 序号 | 命令语法 | 描述 |
| ---- | ---------------------------------------------- | --------------------------------------------------- |
| 1 | SADD key member1 [member2] | 向集合添加一个或多个成员 |
| 2 | SMEMBERS key | 返回集合中的所有成员 |
| 3 | SCARD key | 获取集合的成员数 |
| 4 | SRANDMEMBER key [count] | 返回集合中一个或多个随机数 |
| 5 | SISMEMBER key member | 判断 member 元素是否是集合 key 的成员 |
| 6 | SREM key member1 [member2] | 移除集合中一个或多个成员 |
| 7 | SDIFF key1 [key2] | 返回给定所有集合的差集 |
| 8 | SDIFFSTORE destination key1 [key2] | 返回给定所有集合的差集并存储在 destination 中 |
| 9 | SINTER key1 [key2] | 返回给定所有集合的交集 |
| 10 | SINTERSTORE destination key1 [key2] | 返回给定所有集合的交集并存储在 destination 中 |
| 11 | SUNION key1 [key2] | 返回所有给定集合的并集 |
| 12 | SUNIONSTORE destination key1 [key2] | 所有给定集合的并集存储在 destination 集合中 |
| 13 | SMOVE source destination member | 将 member 元素从 source 集合移动到 destination 集合 |
| 14 | SPOP key | 移除并返回集合中的一个随机元素 |
| 15 | SSCAN key cursor [MATCH pattern] [COUNT count] | 迭代集合中的元素 |
> - cursor:游标
> - MATCH pattern:查询 Key 的条件
> - Count count:返回的条数,默认值为 10
>
> SCAN 是一个基于游标的迭代器,需要基于上一次的游标延续之前的迭代过程。SCAN 以 0 作为游标,开始一次新的迭代,直到命令返回游标 0 完成一次遍历。
> 此命令并不保证每次执行都返回某个给定数量的元素,甚至会返回 0 个元素,但只要游标不是 0,程序都不会认为 SCAN 命令结束,但是返回的元素数量大概率符合 Count 参数。另外,SCAN 支持模糊查询。
>
> 例:`SSCAN names 0 MATCH test* COUNT 10 # 每次返回10条以test为前缀的key`
#### 示例演示
```bash
127.0.0.1:6379> SADD course redis
(integer) 1
127.0.0.1:6379> SADD course mongodb
(integer) 1
127.0.0.1:6379> SADD course mysql
(integer) 1
127.0.0.1:6379> SADD course mysql
(integer) 0
127.0.0.1:6379> SMEMBERS course
1) "mongodb"
2) "redis"
3) "mysql"
127.0.0.1:6379> sscan course 0 match m* count 10
1) "0"
2) 1) "mongodb"
2) "mysql"
```
### Zset
Redis 有序集合和集合一样也是string类型元素的集合且不允许重复的成员。不同的是每个元素都会关联一个double类型的分数。redis正是通过分数来为集合中的成员进行从小到大的排序。有序集合的成员是唯一的,但分数(score)却可以重复。
集合是通过哈希表实现的,所以添加,删除,查找的复杂度都是O(1)。 集合中最大的成员数为 2^32^ - 1 (4294967295, 每个集合可存储40多亿个成员)。
> Zset类型一般用于排行榜等。
#### 结构图

#### 相关命令
| 序号 | 命令语法 | 描述 |
| ---- | ---------------------------------------------- | ------------------------------------------------------------ |
| 1 | ZADD key score1 member1 [score2 member2] | 向有序集合添加一个或多个成员,或者更新已存在成员的分数 |
| 2 | ZCARD key | 获取有序集合的成员数 |
| 3 | ZCOUNT key min max | 计算在有序集合中指定区间分数的成员数 |
| 4 | ZINCRBY key increment member | 有序集合中对指定成员的分数加上增量 increment |
| 5 | ZLEXCOUNT key min max | 在有序集合中计算指定字典区间内成员数量 |
| 6 | ZRANGE key start stop [WITHSCORES] | 通过索引区间返回有序集合指定区间内的成员 |
| 7 | ZRANGEBYLEX key min max [LIMIT offset count] | 通过字典区间返回有序集合的成员 |
| 8 | ZRANGEBYSCORE key min max [WITHSCORES] [LIMIT] | 通过分数返回有序集合指定区间内的成员 |
| 9 | ZRANK key member | 返回有序集合中指定成员的索引 |
| 10 | ZREM key member [member ...] | 移除有序集合中的一个或多个成员 |
| 11 | ZREMRANGEBYLEX key min max | 移除有序集合中给定的字典区间的所有成员 |
| 12 | ZREMRANGEBYRANK key start stop | 移除有序集合中给定的排名区间的所有成员 |
| 13 | ZREMRANGEBYSCORE key min max | 移除有序集合中给定的分数区间的所有成员 |
| 14 | ZREVRANGE key start stop [WITHSCORES] | 返回有序集中指定区间内的成员,通过索引,分数从高到低 |
| 15 | ZREVRANGEBYSCORE key max min [WITHSCORES] | 返回有序集中指定分数区间内的成员,分数从高到低排序 |
| 16 | ZREVRANK key member | 返回有序集合中指定成员的排名,有序集成员按分数值递减(从大到小)排序 |
| 17 | ZSCORE key member | 返回有序集中,成员的分数值 |
| 18 | ZINTERSTORE destination numkeys key [key ...] | 计算给定的一个或多个有序集的交集并将结果集存储在新的有序集合 key 中 |
| 19 | ZUNIONSTORE destination numkeys key [key ...] | 计算给定的一个或多个有序集的并集,并存储在新的 key 中 |
| 20 | ZSCAN key cursor [MATCH pattern] [COUNT count] | 迭代有序集合中的元素(包括元素成员和元素分值) |
#### 示例演示
```bash
127.0.0.1:6379> ZADD courses 1 redis
(integer) 1
127.0.0.1:6379> ZADD courses 2 mongodb
(integer) 1
127.0.0.1:6379> ZADD courses 3 mysql
(integer) 1
127.0.0.1:6379> ZADD courses 3 mysql
(integer) 0
127.0.0.1:6379> ZADD courses 4 mysql
(integer) 0
127.0.0.1:6379> ZRANGE courses 0 10 WITHSCORES
1) "redis"
2) "1"
3) "mongodb"
4) "2"
5) "mysql"
6) "4"
```
### Hash
Redis hash 是一个 string 类型的 field 和 value 的映射表,hash 特别适合用于存储对象。Redis 中每个 hash 可以存储 2^32^ - 1 键值对(40多亿)。
> Hash类型一般用于存储用户信息、用户主页访问量、组合查询等。
#### 结构图

#### 相关命令
| 序号 | 命令语法 | 描述 |
| ---- | ---------------------------------------------- | ----------------------------------------------------- |
| 1 | HSET key field value | 将哈希表 key 中的字段 field 的值设为 value |
| 2 | HGET key field | 获取存储在哈希表中指定字段的值 |
| 3 | HGETALL key | 获取在哈希表中指定 key 的所有字段和值 |
| 4 | HEXISTS key field | 查看哈希表 key 中,指定的字段是否存在 |
| 5 | HSETNX key field value | 只有在字段 field 不存在时,设置哈希表字段的值 |
| 6 | HKEYS key | 获取所有哈希表中的字段 |
| 7 | HVALS key | 获取哈希表中所有值 |
| 8 | HLEN key | 获取哈希表中字段的数量 |
| 9 | HMGET key field1 [field2] | 获取所有给定字段的值 |
| 10 | HMSET key field1 value1 [field2 value2] | 同时将多个 field-value (域-值)对设置到哈希表 key 中 |
| 11 | HINCRBY key field increment | 为哈希表 key 中的指定字段的整数值加上增量 increment |
| 12 | HINCRBYFLOAT key field increment | 为哈希表 key 中的指定字段的浮点数值加上增量 increment |
| 13 | HDEL key field1 [field2] | 删除一个或多个哈希表字段 |
| 14 | HSCAN key cursor [MATCH pattern] [COUNT count] | 迭代哈希表中的键值对 |
#### 示例演示
```bash
127.0.0.1:6379> HMSET hpe name "zhangsan" age 18 gender "男" birth 2000-01-01
OK
127.0.0.1:6379> HGETALL hpe
1) "name"
2) "zhangsan"
3) "age"
4) "18"
5) "gender"
6) "男"
7) "birth"
8) "2000-01-01"
```
### Bitmaps
#### 介绍
现代计算机用二进制(位) 作为信息的基础单位, 1个字节等于8位, 例如“abc”字符串是由3个字节组成, 但实际在计算机存储时将其用二进制表示, “abc”分别对应的ASCII码分别是97、 98、 99, 对应的二进制分别是01100001、 01100010和01100011,如下图:

合理地使用操作位能够有效地提高内存使用率和开发效率。
Redis 6 中提供了 Bitmaps 这个“数据类型”可以实现对位的操作:
1)Bitmaps本身不是一种数据类型,实际上它就是字符串(key-value),但是它可以对字符串的位进行操作。
2)Bitmaps单独提供了一套命令,所以在Redis中使用Bitmaps和使用字符串的方法不太相同。 可以把Bitmaps想象成一个以位为单位的数组, 数组的每个单元只能存储0和1, 数组的下标在Bitmaps中叫做偏移量。

#### 相关命令
#### 1、setbit
这个命令用于设置Bitmaps中某个偏移量的值(0或1),offset偏移量从0开始。格式如下:
```sh
setbit <key> <offset> <value>
```
例如,把每个独立用户是否访问过网站存放在Bitmaps中, 将访问的用户记做1,没有访问的用户记做0,用偏移量作为用户的id。
设置键的第offset个位的值(从0算起) , 假设现在有20个用户,userid=1,6,11,15,19的用户对网站进行了访问, 那么当前Bitmaps初始化结果如图:

下面示例是代表 2022-07-18 这天的独立访问用户的Bitmaps:
```sh
127.0.0.1:6379> setbit unique:users:20220718 1 1
127.0.0.1:6379> setbit unique:users:20220718 6 1
127.0.0.1:6379> setbit unique:users:20220718 11 1
127.0.0.1:6379> setbit unique:users:20220718 15 1
127.0.0.1:6379> setbit unique:users:20220718 19 1
```
> 注意:
>
> 很多应用的用户id以一个指定数字(例如10000) 开头, 直接将用户id和Bitmaps的偏移量对应势必会造成一定的浪费, 通常的做法是每次做setbit操作时将用户id减去这个指定数字。
>
> 在第一次初始化Bitmaps时, 假如偏移量非常大, 那么整个初始化过程执行会比较慢, 可能会造成Redis的阻塞。
#### 2、getbit
这个命令用于获取Bitmaps中某个偏移量的值。格式为:
```sh
getbit <key> <offset>
```
获取键的第offset位的值(从0开始算)。例如获取id=6的用户是否在2022-07-18这天访问过, 返回0说明没有访问过:
```sh
127.0.0.1:6379> getbit unique:users:20220718 6
127.0.0.1:6379> getbit unique:users:20220718 7
```
#### 3、bitcount
这个命令用于统计字符串被设置为1的bit数。一般情况下,给定的整个字符串都会被进行计数,通过指定额外的 start 或 end 参数,可以让计数只在特定的位上进行。start 和 end 参数的设置,都可以使用负数值:比如 -1 表示最后一个位,而 -2 表示倒数第二个位,start、end 是指bit组的字节的下标数,二者皆包含。格式如下:
```sh
bitcount <key> [start end]
```
用于统计字符串从start字节到end字节比特值为1的数量。例如,统计id在第1个字节到第3个字节之间的独立访问用户数, 对应的用户id是11, 15, 19。
```sh
127.0.0.1:6379> bitcount unique:users:20220718 1 3
```
#### 4、bitop
这个命令是一个复合操作, 它可以做多个Bitmaps的and(交集) 、 or(并集) 、 not(非) 、 xor(异或) 操作并将结果保存在destkey中。格式如下:
```sh
bitop and(or/not/xor) <destkey> [key…]
```
例如:2020-11-04 日访问网站的userid=1,2,5,9。
```sh
127.0.0.1:6379> setbit unique:users:20201104 1 1
127.0.0.1:6379> setbit unique:users:20201104 2 1
127.0.0.1:6379> setbit unique:users:20201104 5 1
127.0.0.1:6379> setbit unique:users:20201104 9 1
```
2020-11-03 日访问网站的userid=0,1,4,9。
```sh
127.0.0.1:6379> setbit unique:users:20201103 0 1
127.0.0.1:6379> setbit unique:users:20201103 1 1
127.0.0.1:6379> setbit unique:users:20201103 4 1
127.0.0.1:6379> setbit unique:users:20201103 9 1
```
计算出两天都访问过网站的用户数量
```sh
127.0.0.1:6379> bitop and unique:users:and:20201104_03 unique:users:20201103 unique:users:20201104
127.0.0.1:6379> bitcount unique:users:and:20201104_03
```

计算出任意一天都访问过网站的用户数量(例如月活跃就是类似这种) , 可以使用or求并集
```sh
127.0.0.1:6379> bitop or unique:users:or:20201104_03 unique:users:20201103 unique:users:20201104
127.0.0.1:6379> bitcount unique:users:or:20201104_03
```
### HyperLogLog
#### 简介
在工作当中,我们经常会遇到与统计相关的功能需求,比如统计网站PV(PageView页面访问量),可以使用Redis的incr、incrby轻松实现。
但像UV(UniqueVisitor,独立访客)、独立IP数、搜索记录数等需要去重和计数的问题如何解决?这种求集合中不重复元素个数的问题称为基数问题。
解决基数问题有很多种方案:
1)数据存储在MySQL表中,使用distinct count计算不重复个数
2)使用Redis提供的hash、set、bitmaps等数据结构来处理
以上的方案结果精确,但随着数据不断增加,导致占用空间越来越大,对于非常大的数据集是不切实际的。
为了能够降低一定的精度来平衡存储空间,Redis推出了HyperLogLog。
HyperLogLog 是用来做基数统计的算法,HyperLogLog 的优点是:在输入元素的数量或者体积非常非常大时,计算基数所需的空间总是固定的、并且是很小的。
在 Redis 里面,每个 HyperLogLog 键只需要花费 12 KB 内存,就可以计算接近 2^64 个不同元素的基数。这和计算基数时,元素越多耗费内存就越多的集合形成鲜明对比。
但是,因为 HyperLogLog 只会根据输入元素来计算基数,而不会储存输入元素本身,所以 HyperLogLog 不能像集合那样,返回输入的各个元素。
> 什么是基数?
>
> 比如数据集 {1, 3, 5, 7, 5, 7, 8},那么这个数据集的基数集为 {1, 3, 5 ,7, 8},基数(不重复元素)为5。 基数估计就是在误差可接受的范围内,快速计算基数。
#### 相关命令
| 序号 | 命令语法 | 描述 |
| ---- | ----------------------------------------- | ----------------------------------------- |
| 1 | PFADD key element [element ...] | 添加指定元素到 HyperLogLog 中 |
| 2 | PFCOUNT key [key ...] | 返回给定 HyperLogLog 的基数估算值 |
| 3 | PFMERGE destkey sourcekey [sourcekey ...] | 将多个 HyperLogLog 合并为一个 HyperLogLog |
#### 示例演示
```bash
127.0.0.1:6379> PFADD course "redis"
(integer) 1
127.0.0.1:6379> PFADD course "mongodb"
(integer) 1
127.0.0.1:6379> PFADD course "mysql"
(integer) 1
127.0.0.1:6379> PFADD course "redis"
(integer) 0
redis 127.0.0.1:6379> PFCOUNT course
(integer) 3
127.0.0.1:6379> PFADD course1 "redis"
(integer) 0
redis 127.0.0.1:6379> pfmerge course course1
(integer) 1
redis 127.0.0.1:6379> PFCOUNT course
(integer) 3
```
将所有元素添加到指定HyperLogLog数据结构中。如果执行命令后HLL估计的近似基数发生变化,则返回1,否则返回0。
### Geospatial
#### 简介
Redis 3.2 中增加了对GEO类型的支持。GEO,Geographic,地理信息的缩写。该类型,就是元素的2维坐标,在地图上就是经纬度。redis基于该类型,提供了经纬度设置,查询,范围查询,距离查询,经纬度Hash等常见操作。
#### 相关命令
| 序号 | 命令语法 | 描述 |
| ---- | ------------------------------------------------------------ | ------------------------------------------ |
| 1 | geoadd key longitude latitude member [longitude latitude member...] | 添加地理位置(经度,纬度,名称) |
| 2 | geopos key member [member...] | 获得指定地区的坐标值 |
| 3 | geodist key member1 member2 [m\|km\|ft\|mi] | 获取两个位置之间的直线距离 |
| 4 | georadius key longitude latitude radius [m\|km\|ft\|mi] | 以给定的经纬度为中心,找出某一半径内的元素 |
#### 示例演示
1)添加城市坐标
例如,设置上海、重庆、深圳和北京的坐标
```bash
127.0.0.1:6379> geoadd china:city 121.47 31.23 shanghai
127.0.0.1:6379> geoadd china:city 106.50 29.53 chongqing 114.05 22.52 shenzhen 116.38 39.90 beijing
```
```markdown
有效的经度从 -180 度到 180 度。有效的纬度从 -85.05112878 度到 85.05112878 度。
当坐标位置超出指定范围时,该命令将会返回一个错误。
已经添加的数据,是无法再次往里面添加的。
```
2)获取城市坐标
例如,获取上海的坐标。
```bash
127.0.0.1:6379> geopos china:city shanghai
```
3)用于获取两个位置之间的直线距离。
例如,获取北京和深圳的直线距离。
```bash
127.0.0.1:6379> geopos china:city beijing shanghai km
```
```markdown
单位:
m:表示单位为米[默认值]。
km:表示单位为千米。
mi:表示单位为英里。
ft:表示单位为英尺。
```
4)用于获取指定坐标半径内的元素
例如,获取经度为 110,纬度为 30,半径为 1000KM 的所有城市。
```bash
127.0.0.1:6379> georadius china:city 110 30 1000 km
```
## Redis的配置文件
下面我们介绍 Redis 配置文件(redis.conf 文件)中有哪些配置项及它们的作用。
````markdown
vim 设置行号:
:set nu
取消行号:
: set nonu
搜索关键字:
/关键字
取消高亮:
: set noh
````
### Units
配置大小单位,开头定义了一些基本的度量单位,只支持 bytes,不支持 bit。大小写不敏感。

### INCLUDES
类似 JSP 程序中的 include,多实例的情况可以把公用的配置文件提取出来。

### NETWORK
#### bind
默认情况下 `bind=127.0.0.1` 只能接受本机的访问请求。在不写的情况下,无限制接受任何 IP 地址的访问。
生产环境需要填写你应用服务器的地址。由于服务器是需要远程访问的,所以需要将其注释掉。
> 注意:如果开启了protected-mode,那么在没有设定bind ip且没有设密码的情况下,Redis只允许接受本机的响应。

保存配置,停止服务,重启启动查看进程,不再是本机访问了。
#### protected-mode
将本机访问保护模式设置no

#### port
端口号,默认 6379

#### tcp-backlog
设置 tcp 的 backlog,backlog 其实是一个连接队列,backlog队列总和 = 未完成三次握手队列 + 已经完成三次握手队列。
在高并发环境下你需要一个高 backlog 值来避免慢客户端连接问题。
> 注意:
>
> Linux内核会将这个值减小到/proc/sys/net/core/somaxconn的值(128),所以需要确认增大/proc/sys/net/core/somaxconn和/proc/sys/net/ipv4/tcp_max_syn_backlog(128)两个值来达到想要的效果

#### timeout
一个空闲的客户端维持多少秒会关闭,0表示关闭该功能。即永不关闭。

#### tcp-keepalive
对访问客户端的一种心跳检测,每 n 秒检测一次。
单位为秒,如果设置为0,则不会进行 Keepalive 检测,建议设置成 60。

### GENERAL
#### daemonize
是否为后台进程,即守护进程,用于后台启动,设置为yes。

#### pidfile
存放pid文件的位置,每个实例会产生一个不同的pid文件。

#### loglevel
指定日志记录级别,Redis 总共支持四个级别:debug、verbose、notice、warning,默认为notice。
四个级别根据使用阶段来选择,生产环境选择 notice 或者warning。

#### logfile
日志文件名称

#### databases
设定库的数量,默认16,默认数据库为0,可以使用 `SELECT <dbid>`命令在连接上指定数据库id。

### SECURITY
#### 设置密码
当设置好密码后(即把 requirepass foobared 注解解开),然后使用客户端连接服务器后,在执行 set 命令时,提示需要获取权限。
可以在命令中访问密码的查看、设置和取消。
```bash
127.0.0.1:6379> config get requirepass
1) "requirepass"
2) ""
127.0.0.1:6379> config set requirepass "123456"
OK
127.0.0.1:6379> config get requirepass
(error)NOAUTH Authentication required.
127.0.0.1:6379> auth 123456
OK
127.0.0.1:6379> get k1
"v1"
127.0.0.1:6379> config set requirepass ""
OK
127.0.0.1:6379> config get requirepass
1) "requirepass"
2) ""
```
> 注意:
>
> 在命令中设置密码,只是临时的。重启redis服务器,密码就还原了。
>
> 永久设置,需要再配置文件中进行设置。
### CLIENTS
#### maxclients
设置redis同时可以与多少个客户端进行连接。默认情况下为10000个客户端。如果达到了此限制,redis则会拒绝新的连接请求,并且向这些连接请求方发出“max number of clients reached”以作回应。

#### maxmemory
建议必须设置,否则可能导致将内存占满,造成服务器宕机。
设置redis可以使用的内存量。一旦到达内存使用上限,redis将会试图移除内部数据,移除规则可以通过maxmemory-policy来指定。
如果redis无法根据移除规则来移除内存中的数据,或者设置了“不允许移除”,那么redis则会针对那些需要申请内存的指令返回错误信息,比如SET、LPUSH等。
但是对于无内存申请的指令,仍然会正常响应,比如GET等。如果你的redis是主redis(说明你的redis有从redis),那么在设置内存使用上限时,需要在系统中留出一些内存空间给同步队列缓存,只有在你设置的是“不移除”的情况下,才不用考虑这个因素。

#### maxmemory-policy
用于设置内存达到使用上限后的移除规则。有以下参数可设置:
- volatile-lru:使用LRU算法移除key,只对设置了过期时间的键;(最近最少使用)
- allkeys-lru:在所有集合key中,使用LRU算法移除key
- volatile-random:在过期集合中移除随机的key,只对设置了过期时间的键
- allkeys-random:在所有集合key中,移除随机的key
- volatile-ttl:移除那些TTL值最小的key,即那些最近要过期的key
- noeviction:不进行移除。针对写操作,只是返回错误信息

#### maxmemory-samples
用于设置样本数量,LRU算法和最小TTL算法都并非是精确的算法,而是估算值,所以你可以设置样本的大小,redis默认会检查这么多个key并选择其中LRU的那个。
一般设置3到7的数字,数值越小样本越不准确,但性能消耗越小。

## redis的订阅者模式
### 简介
Redis 发布订阅 (pub/sub) 是一种消息通信模式:发送者 (pub) 发送消息,订阅者 (sub) 接收消息。Redis 客户端可以订阅任意数量的频道。下图展示了频道 channel1 ,以及订阅这个频道的三个客户端 —— client1 、client2 和 client3 之间的关系:

当有新消息通过 PUBLISH 命令发送给频道 channel1 时, 这个消息就会被发送给订阅它的三个客户端:

### 常用命令
| 序号 | 命令语法 | 描述 |
| ---- | ------------------------------------------- | -------------------------------- |
| 1 | PSUBSCRIBE pattern [pattern ...] | 订阅一个或多个符合给定模式的频道 |
| 2 | PUBSUB subcommand [argument [argument ...]] | 查看订阅与发布系统状态 |
| 3 | PUBLISH channel message | 将信息发送到指定的频道 |
| 4 | PUNSUBSCRIBE [pattern [pattern ...]] | 退订所有给定模式的频道 |
| 5 | SUBSCRIBE channel [channel ...] | 订阅给定的一个或多个频道的信息 |
| 6 | UNSUBSCRIBE [channel [channel ...]] | 指退订给定的频道 |
### 示例演示
以下实例演示了发布订阅是如何工作的。在我们实例中我们创建了订阅频道名为 redisChat:
```bash
127.0.0.1:6379> SUBSCRIBE redisChat
Reading messages... (press Ctrl-C to quit)
1) "subscribe"
2) "redisChat"
3) (integer) 1
```
现在,我们先重新开启个 redis 客户端,然后在同一个频道 redisChat 发布两次消息,订阅者就能接收到消息。
```bash
127.0.0.1:6379> PUBLISH redisChat "send message"
(integer) 1
127.0.0.1:6379> PUBLISH redisChat "hello world"
(integer) 1
```
然后切换到前一个客户端,就可以看到如下信息:
```bash
127.0.0.1:6379> SUBSCRIBE redisChat
Reading messages... (press Ctrl-C to quit)
1) "subscribe"
2) "redisChat"
3) (integer) 1
# 订阅者的客户端显示如下
1) "message"
2) "redisChat"
3) "send message"
1) "message"
2) "redisChat"
3) "hello world"
```
## 事务管理
### 事务定义
Redis 事务是一个单独的隔离操作:事务中的所有命令都会序列化、按顺序地执行。事务在执行的过程中,不会被其他客户端发送来的命令请求所打断。
Redis 事务的主要作用就是串联多个命令防止别的命令插队。
### Multi、Exec、discard
从输入 Multi 命令开始,输入的命令都会依次进入命令队列中,但不会执行,直到输入 Exec 后,Redis 会将之前的命令队列中的命令依次执行。
组队的过程中可以通过 discard 来放弃组队。

1)组队成功,提交成功的情况:
```bash
127.0.0.1:6379> multi
OK
127.0.0.1:6379> set k1 v1
QUEUED
127.0.0.1:6379> set k2 v2
QUEUED
127.0.0.1:6379> exec
1) OK
2) OK
```
2)组队阶段报错,提交失败的情况:
```bash
127.0.0.1:6379> multi
OK
127.0.0.1:6379> set k3 v3
QUEUED
127.0.0.1:6379> set k4
(error) ERR wrong number of arguments for 'set' command
127.0.0.1:6379> set k5 v5
QUEUED
127.0.0.1:6379> exec
1) (error) EXECABORT Transaction discarded because of previous errors.
```
3)组队成功,提交有成功有失败的情况:
```bash
127.0.0.1:6379> multi
OK
127.0.0.1:6379> set k3 v3
QUEUED
127.0.0.1:6379> incr k3
QUEUED
127.0.0.1:6379> set k4 v4
QUEUED
127.0.0.1:6379> exec
1) OK
2) (error) ERR value is not an integer or out of range
3) OK
```
### 事务的错误处理
组队中某个命令出现了报告错误,执行时整个的所有队列都会被取消。

如果执行阶段某个命令报出了错误,则只有报错的命令不会被执行,而其他的命令都会执行,不会回滚。

### 事务的冲突问题
#### 事务场景
有一账户余额为 10000 元,现在三个请求,第一个请求想给金额减 8000 元,第二个请求想给金额减 5000 元,第三个请求想给金额减 1000 元。如果没有事务,可能会发生如下情况。

#### 悲观锁
悲观锁(Pessimistic Lock)顾名思义,就是很悲观,每次去拿数据的时候都认为别人会修改,所以每次在拿数据的时候都会上锁,这样别人想拿这个数据就会block直到它拿到锁。传统的关系型数据库就用到了很多这种锁机制,比如行锁,表锁,读锁,写锁等,都是在做操作之前先上锁。

#### 乐观锁
乐观锁(Optimistic Lock)顾名思义,就是很乐观,每次去拿数据的时候都认为别人不会修改,所以不会上锁,但是在更新的时候会判断一下在此期间别人有没有去更新这个数据,可以使用版本号等机制。乐观锁适用于多读的应用类型,这样可以提高吞吐量。Redis就是利用这种check-and-set机制实现事务的。

#### WATCH
在执行 multi 之前,先执行 `watch key1 [key2]` 可以监视一个(或多个) key ,如果在事务执行之前这个/些 key 被其他命令所改动,那么事务将被打断。
为了演示这个功能,我们先设置一个 balance 的初始值为 10000。然后打开一个客户端,在两个客户端中都去监视 balance,同时也开启事务。
```bash
127.0.0.1:6379> set balance 10000
```
在客户端 A :
```bash
127.0.0.1:6379> watch balance
OK
127.0.0.1:6379> multi
OK
127.0.0.1:6379> decrby balance 8000
QUEUED
127.0.0.1:6379> exec
1) (integer) 2000
```
在客户端 B :
```bash
127.0.0.1:6379> watch balance
OK
127.0.0.1:6379> multi
OK
127.0.0.1:6379> incrby balance 2000
QUEUED
127.0.0.1:6379> exec
1) (nil)
```
可以看到,客户端 B 中没有操作成功。
#### unwatch
用于取消 WATCH 命令对所有 key 的监视。
如果在执行 WATCH 命令之后,EXEC 命令或DISCARD 命令先被执行了的话,那么就不需要再执行UNWATCH 了。
### 事务三特性
Redis 的事务有以下三个特性:
1. 单独的隔离操作
事务中的所有命令都会序列化、按顺序地执行。事务在执行的过程中,不会被其他客户端发送来的命令请求所打断。
2. 没有隔离级别的概念
队列中的命令没有提交之前都不会实际被执行,因为事务提交前任何指令都不会被实际执行。
3. 不保证原子性
事务中如果有一条命令执行失败,其后的命令仍然会被执行,没有回滚。
## 数据持久化
官网文档地址:https://redis.io/docs/manual/persistence/
> Persistence refers to the writing of data to durable storage, such as a solid-state disk (SSD). Redis itself provides a range of persistence options:
>
> - RDB (Redis Database): The RDB persistence performs point-in-time snapshots of your dataset at specified intervals.
> - AOF (Append Only File): The AOF persistence logs every write operation received by the server, that will be played again at server startup, reconstructing the original dataset. Commands are logged using the same format as the Redis protocol itself, in an append-only fashion. Redis is able to [rewrite](https://redis.io/docs/manual/persistence/#log-rewriting) the log in the background when it gets too big.
> - No persistence: If you wish, you can disable persistence completely, if you want your data to just exist as long as the server is running.
> - RDB + AOF: It is possible to combine both AOF and RDB in the same instance. Notice that, in this case, when Redis restarts the AOF file will be used to reconstruct the original dataset since it is guaranteed to be the most complete.
>
> The most important thing to understand is the different trade-offs between the RDB and AOF persistence.
Redis提供了主要提供了 2 种不同形式的持久化方式:
- RDB(Redis数据库):RDB 持久性以指定的时间间隔执行数据集的时间点快照。
- AOF(Append Only File):AOF 持久化记录服务器接收到的每个写操作,在服务器启动时再次播放,重建原始数据集。 命令使用与 Redis 协议本身相同的格式以仅附加方式记录。 当日志变得太大时,Redis 能够在后台重写日志。
### RDB
#### 什么是RDB
在指定的时间间隔内将内存中的数据集快照写入磁盘, 也就是Snapshot快照,它恢复时是将快照文件直接读到内存里。
#### 如何备份
Redis会单独创建(fork)一个子进程来进行持久化,会先将数据写入到 一个临时文件中,待持久化过程都结束后,再用这个临时文件替换上次持久化好的文件。 整个过程中,主进程是不进行任何IO操作的,这就确保了极高的性能。如果需要进行大规模数据的恢复,且对于数据恢复的完整性不是非常敏感,那RDB方式要比AOF方式更加的高效。RDB的缺点是最后一次持久化后的数据可能丢失。
#### Fork
Fork 的作用是复制一个与当前进程一样的进程。新进程的所有数据(变量、环境变量、程序计数器等) 数值都和原进程一致,但它是一个全新的进程,并作为原进程的子进程。
在 Linux 程序中,fork() 会产生一个和父进程完全相同的子进程,但子进程在此后多会 exec 系统调用,出于效率考虑,Linux 中引入了“写时复制技术”。
一般情况下父进程和子进程会共用同一段物理内存,只有进程空间的各段的内容要发生变化时,才会将父进程的内容复制一份给子进程。

#### 持久化流程

启动:
- 检查是否存在子进程正在执行 AOF 或者 RDB 的持久化任务。如果有则返回 false。
- 调用 Redis 源码中的 rdbSaveBackground 方法,方法中执行 fork() 产生子进程执行 RDB 操作。
- 关于 fork() 中的 Copy-On-Write。
#### 相关配置
#### 1、配置文件名
快照持久化是Redis中默认开启的持久化方案,根据redis.conf中的配置,快照将被写入dbfilename指定的文件中(默认是dump.rdb文件)。
```bash
# The filename where to dump the DB
dbfilename dump.rdb
```
#### 2、配置文件路径
根据redis.conf中的配置,快照将保存在dir选项指定的路径上,我们可以修改为指定目录
```bash
# Note that you must specify a directory here, not a file name.
# dir ./
dir "/usr/local/redis/data/"
```
> 注意:由于此路径是一个相对路径,它会根据执行命令所在目录来生成dump.rdb文件,因此建议改为一个固定位置,如:/usr/local/redis/data
#### 3、save
格式:save 秒钟 写操作次数
```bash
save 900 1 # 在900s内如果有1条数据被写入,则产生一次快照。
save 300 10 # 在300s内如果有10条数据被写入,则产生一次快照
save 60 10000 # 在60s内如果有10000条数据被写入,则产生一次快照
stop-writes-on-bgsave-error yes # 如果为yes则表示,当备份进程出错的时候,主进程就停止进行接受新的写入操作,这样是为了保护持久化的数据一致性的问题。
```
使用演示
我们把持久化的策略修改为 `save 30 5`,表示 30 秒内写入 5 条数据就产生一次快照,也就是生成 rdb 文件。
修改好的保存并重启 redis 服务,然后打开客户端,执行如下命令:
```bash
127.0.0.1:6379> set k1 v1
OK
127.0.0.1:6379> set k2 v2
OK
127.0.0.1:6379> set k3 v3
OK
127.0.0.1:6379> set k4 v4
OK
127.0.0.1:6379> set k5 v5
OK
127.0.0.1:6379> set k6 v6
OK
```
然后查看 dump.rdb 文件的大小,就可以发现文件快照已经产生了。
> 问题:是否这 6 条数据都持久化了?
>
> 答:只持久化了前 5 条数据,最后 1 条数据没有持久化。
注意:Redis 中持久化命令有两种:
- save:手动保存,只管保存不管其它,所有操作全部阻塞。不建议使用。
- bgsave:自动保存,Redis会在后台异步进行快照操作, 快照同时还可以响应客户端请求。
#### 4、stop-writes-on-bgsave-error
当 Redis 无法写入磁盘的话,直接关掉 Redis 的写操作,推荐配置为 yes。
#### 5、rdbcompression
对于存储到磁盘中的快照,可以设置是否进行压缩存储。如果是的话,Redis 会采用 LZF 算法进行压缩。
如果你不想消耗CPU来进行压缩的话,可以设置为关闭此功能。推荐配置为 yes。
#### 6、rdbchecksum
在存储快照后,还可以让 Redis 使用 CRC64 算法来进行数据校验,检查数据完整性。
但是这样做会增加大约 10% 的性能消耗,如果希望获取到最大的性能提升,可以关闭此功能。推荐配置为 yes。
#### 备份和恢复
#### 1、备份
首先执行如下命令来清空数据:
```bash
127.0.0.1:6379> flushdb
```
然后再重新添加如下数据:
```bash
127.0.0.1:6379> set k1 v1
OK
127.0.0.1:6379> set k2 v2
OK
127.0.0.1:6379> set k3 v3
OK
127.0.0.1:6379> set k4 v4
OK
127.0.0.1:6379> set k5 v5
OK
127.0.0.1:6379> set k6 v6
OK
```
接着执行如下命令来备份 dump.rdb
```bash
cp dump.rdb dump.rdb.back
```
最后把 Redis 服务关闭
```bash
redis-cli shutdown
```
然后把 dump.rdb 文件删除
```bash
rm -f dump.rdb
```
#### 2、恢复
首先执行如下命令来把 dump.rdb.back 文件修改为 dump.rdb。
```bash
mv dump.rdb.back dump.rdb
```
然后重启 Redis 服务。
```bash
bin> redis-server /etc/redis.conf
```
然后连接客户端后再执行如下命令来查看:
```bash
127.0.0.1:6379> keys *
1) "k1"
2) "k2"
3) "k3"
4) "k4"
5) "k5"
```
#### 优势
RDB 方式适合大规模的数据恢复,并且对数据完整性和一致性要求不高更适合使用。它有以下几种优势:
- 节省磁盘空间
- 恢复速度快

#### 劣势
- Fork的时候,内存中的数据被克隆了一份,大致2倍的膨胀性需要考虑
- 虽然Redis在fork时使用了写时拷贝技术,但是如果数据庞大时还是比较消耗性能。
- 在备份周期在一定间隔时间做一次备份,所以如果Redis意外down掉的话,就会丢失最后一次快照后的所有修改。
### AOF
#### 什么是AOF
以日志的形式来记录每个写操作(增量保存),将Redis执行过的所有写指令记录下来(读操作不记录), 只追加文件但不可以改写文件,Redis启动之初会读取该文件重新构建数据。简单说,Redis 重启时会根据日志文件的内容将写指令从前到后执行一次以完成数据的恢复工作。
在Redis的默认配置中AOF(Append Only File)持久化机制是没有开启的,要想使用AOF持久化需要先开启此功能。AOF持久化会将被执行的写命令写到AOF文件末尾,以此来记录数据发生的变化,因此只要Redis从头到尾执行一次AOF文件所包含的所有写命令,就可以恢复AOF文件的记录的数据集。
#### 持久化流程

1)客户端的请求写命令会被 append 追加到 AOF 缓冲区内。
2)AOF 缓冲区根据 AOF 持久化策略 [always,everysec,no] 将操作sync同步到磁盘的 AOF 文件中。
3)AOF 文件大小超过重写策略或手动重写时,会对 AOF 文件 rewrite 重写,压缩 AOF 文件容量。
4)Redis 服务重启时,会重新 load 加载 AOF 文件中的写操作达到数据恢复的目的。
#### 使用AOF
##### 1、开启AOF
修改 redis.conf 配置文件:
- 通过修改redis.conf配置中`appendonly yes`来开启AOF持久化
- 通过appendfilename指定日志文件名字(默认为appendonly.aof)
- 通过appendfsync指定日志记录频率
##### 2、配置选项
| 选项 | 同步频率 |
| -------- | -------------------------------------------------- |
| always | 每个redis写命令都要同步写入硬盘,严重降低redis速度 |
| everysec | 每秒执行一次同步显式的将多个写命令同步到磁盘 |
| no | 由操作系统决定何时同步 |
> 三个选项详细说明如下:
>
> - always选项,每个redis写命令都会被写入AOF文件中,好处是当发生系统崩溃时数据丢失减至最少,缺点是这种策略会产生大量的I/O操作,会严重降低服务器的性能。
> - everysec选项,以每秒一次的频率对AOF文件进行同步,可以保证系统崩溃时只会丢失一秒左右的数据,并且 Redis 每秒执行一次同步对服务器几乎没有任何影响。
> - no选项,完全由操作系统决定什么时候同步AOF日志文件,这个选项不能给服务器性能带来多大的提升,反而会增加系统崩溃时数据丢失的数量。
##### 3、使用演示
1)配置好后,停止 Redis 服务,然后再重新开启 Redis 服务后,就可以在 RDB 生成的同目录下(/usr/local/redis/data)会生成一个 appendonly.aof 文件。
2)使用客户端连接 Redis 服务,然后执行:
```bash
127.0.0.1:6379> keys *
(empty array)
```
发现没有任何数据。这说明:如果 RDB 和 AOF 文件同时存在,Redis 默认使用的是 AOF 文件。
##### 4、备份
AOF的备份机制和性能虽然和RDB不同,但是备份和恢复的操作同RDB一样:都是拷贝备份文件,需要恢复时再拷贝到Redis工作目录下,启动系统即加载。
首先添加数据:
```bash
127.0.0.1:6379> set k11 v11
OK
127.0.0.1:6379> set k12 v12
OK
127.0.0.1:6379> set k13 v13
OK
127.0.0.1:6379> set k14 v14
OK
127.0.0.1:6379> set k15 v15
OK
```
然后停止 Redis 服务,并重命名文件
```bash
redis-cli shutdown
mv appendonly.aof appendonly.aof.back
```
##### 5、恢复
重新把 aof 文件改名回来,再重启 Redis 服务,连接客户端:
```
127.0.0.1:6379> keys *
1) "k11"
2) "k12"
3) "k13"
4) "k14"
5) "k15"
```
发现确实可在恢复。
##### 6、异常恢复
如遇到 AOF 文件被损坏,可以通过 `/usr/local/bin/redis-check-aof --fix appendonly.aof` 进行恢复。
首先我们人为的在 appendonly.aof 中添加一点内容,如:
```bash
vim appendonly.aof
# 在文件最后添加
redis-aof
```
保存退出后关闭 Redis 服务后再重启 Redis 服务,并用客户端进行连接。这时会发现连接出错:
```bash
bin]# redis-cli
Could not connect to Redis at 127.0.0.1:6379:Connection refused.
```
这时我们需要对 appendonly.aof 文件进行修复:
```bash
bin]# redis-check-aof --fix appendonly.aof
```
在提示中输入 y 即可。
修复后再次重启 Redis 服务,并连接客户端就可以了。
#### Rewrite压缩
##### 1、Rewrite是什么
AOF采用文件追加方式,文件会越来越大为避免出现此种情况,新增了重写机制, 当AOF文件的大小超过所设定的阈值时,Redis就会启动AOF文件的内容压缩, 只保留可以恢复数据的最小指令集。可以使用命令bgrewriteaof
##### 2、重写原理
AOF文件持续增长而过大时,会fork出一条新进程来将文件重写(也是先写临时文件最后再 rename),redis 4.0 版本后的重写,是指上就是把rdb 的快照,以二级制的形式附在新的aof头部,作为已有的历史数据,替换掉原来的流水账操作。
`no-appendfsync-on-rewrite:`
如果 no-appendfsync-on-rewrite=yes ,不写入aof文件只写入缓存,用户请求不会阻塞,但是在这段时间如果宕机会丢失这段时间的缓存数据。 这样做可以降低数据安全性,提高性能。
如果 no-appendfsync-on-rewrite=no, 还是会把数据往磁盘里刷,但是遇到重写操作,可能会发生阻塞。这样做可以数据安全,但是性能降低。
触发机制,何时重写
Redis会记录上次重写时的AOF大小,默认配置是当AOF文件大小是上次rewrite后大小的一倍且文件大于64M时触发
重写虽然可以节约大量磁盘空间,减少恢复时间。但是每次重写还是有一定的负担的,因此设定Redis要满足一定条件才会进行重写。
auto-aof-rewrite-percentage:设置重写的基准值,文件达到100%时开始重写(文件是原来重写后文件的2倍时触发)
auto-aof-rewrite-min-size:设置重写的基准值,最小文件64MB。达到这个值开始重写。
例如:文件达到70MB开始重写,降到50MB,下次什么时候开始重写?100MB
系统载入时或者上次重写完毕时,Redis会记录此时AOF大小,设为base_size,
如果Redis的AOF当前大小>= base_size +base_size*100% (默认)且当前大小>=64mb(默认)的情况下,Redis会对AOF进行重写。
##### 3、重写流程
1)bgrewriteaof触发重写,判断是否当前有bgsave或bgrewriteaof在运行,如果有,则等待该命令结束后再继续执行。
2)主进程fork出子进程执行重写操作,保证主进程不会阻塞。
3)子进程遍历redis内存中数据到临时文件,客户端的写请求同时写入aof_buf缓冲区和aof_rewrite_buf重写缓冲区保证原AOF文件完整以及新AOF文件生成期间的新的数据修改动作不会丢失。
4)子进程写完新的AOF文件后,向主进程发信号,父进程更新统计信息。主进程把aof_rewrite_buf中的数据写入到新的AOF文件。
5)使用新的AOF文件覆盖旧的AOF文件,完成AOF重写。

#### 优势
- 备份机制更稳健,丢失数据概率更低。
- 可读的日志文本,通过操作AOF稳健,可以处理误操作。
#### 劣势
- 比起RDB占用更多的磁盘空间。
- 恢复备份速度要慢。
- 每次读写都同步的话,有一定的性能压力。
- 存在个别Bug,造成恢复不能。
#### 如何选择
那么,在开发中是选择 RDB 还是选择 AOF 来持久化呢?
官网建议如下:
> ## Ok, so what should I use?
>
> The general indication you should use both persistence methods is if you want a degree of data safety comparable to what PostgreSQL can provide you.
>
> If you care a lot about your data, but still can live with a few minutes of data loss in case of disasters, you can simply use RDB alone.
>
> There are many users using AOF alone, but we discourage it since to have an RDB snapshot from time to time is a great idea for doing database backups, for faster restarts, and in the event of bugs in the AOF engine.
>
> The following sections will illustrate a few more details about the two persistence models.
- RDB持久化方式能够在指定的时间间隔能对你的数据进行快照存储
- AOF持久化方式记录每次对服务器写的操作,当服务器重启的时候会重新执行这些命令来恢复原始的数据,AOF命令以redis协议追加保存每次写的操作到文件末尾.
- Redis还能对AOF文件进行后台重写,使得AOF文件的体积不至于过大
- 只做缓存:如果你只希望你的数据在服务器运行的时候存在,你也可以不使用任何持久化方式.
- 同时开启两种持久化方式
- 在这种情况下,当redis重启的时候会优先载入AOF文件来恢复原始的数据, 因为在通常情况下AOF文件保存的数据集要比RDB文件保存的数据集要完整.
- RDB的数据不实时,同时使用两者时服务器重启也只会找AOF文件。那要不要只使用AOF呢?
- 建议不要,因为RDB更适合用于备份数据库(AOF在不断变化不好备份), 快速重启,而且不会有AOF可能潜在的bug,留着作为一个万一的手段。
## 高频面试题
### 缓存穿透
#### 描述
用户想要查询某个数据,在 Redis 中查询不到,即没有缓存命中,这时就会直接访问数据库进行查询。当请求量超出数据库最大承载量时,就会导致数据库崩溃。这种情况一般发生在非正常 URL 访问,目的不是为了获取数据,而是进行恶意攻击。

#### 现象
1、应用服务器压力变大
2、Redis缓存命中率降低
3、一直查询数据库
#### 原因
一个不存在缓存及查询不到的数据,由于缓存是不命中时被动写的,并且出于容错考虑,如果从存储层查不到数据则不写入缓存,这将导致这个不存在的数据每次请求都要到存储层去查询,失去了缓存的意义。
#### 解决
① 对空值缓存:如果一个查询数据为空(不管数据是否存在),都对该空结果进行缓存,其过期时间会设置非常短。
② 设置可以访问名单:使用bitmaps类型定义一个可以访问名单,名单id作为bitmaps的偏移量,每次访问时与bitmaps中的id进行比较,如果访问id不在bitmaps中,则进行拦截,不允许访问。
③ 采用布隆过滤器:布隆过滤器可以判断元素是否存在集合中,他的优点是空间效率和查询时间都比一般算法快,缺点是有一定的误识别率和删除困难。
④ 进行实时监控:当发现 Redis 缓存命中率急速下降时,迅速排查访问对象和访问数据,将其设置为黑名单。
### 缓存击穿
#### 描述
key中对应数据存在,当key中对应的数据在缓存中过期,而此时又有大量请求访问该数据,由于缓存中过期了,请求会直接访问数据库并回设到缓存中,高并发访问数据库会导致数据库崩溃。

#### 现象
1、数据库访问压力瞬时增加
2、Redis中没有出现大量 Key 过期
3、Redis正常运行
4、数据库崩溃
#### 原因
由于 Redis 中某个 Key 过期,而正好有大量访问使用这个 Key,此时缓存无法命中,因此就会直接访问数据层,导致数据库崩溃。
最常见的就是非常“热点”的数据访问。
#### 解决
① 预先设置热门数据:在redis高峰访问时期,提前设置热门数据到缓存中,或适当延长缓存中key过期时间。
② 实时调整:实时监控哪些数据热门,实时调整key过期时间。
③ 对于热点key设置永不过期。
### 缓存雪崩
#### 描述
key中对应数据存在,在某一时刻,缓存中大量key过期,而此时大量高并发请求访问,会直接访问后端数据库,导致数据库崩溃。
> 注意:缓存击穿是指一个key对应缓存数据过期,缓存雪崩是大部分key对应缓存数据过期。
正常情况下:

缓存失效瞬间:

#### 现象
1、数据库压力变大导致数据库和 Redis 服务崩溃
#### 原因
在极短时间内,查询大量 key 的集中过期数据。
#### 解决
① 构建多级缓存机制:nginx缓存 + redis缓存 + 其他缓存。
② 设置过期标志更新缓存:记录缓存数据是否过期,如果过期会触发另外一个线程去在后台更新实时key的缓存。
③ 将缓存可以时间分散:如在原有缓存时间基础上增加一个随机值,这个值可以在1-5分钟随机,这样过期时间重复率就会降低,防止大量key同时过期。
④ 使用锁或队列机制:使用锁或队列保证不会有大量线程一次性对数据库进行读写,从而避免大量并发请求访问数据库,该方法不适用于高并发情况。