【深度解析】YOLOE登场:CNN路线的开放世界新答卷,超越YOLO-World与Transformer

近年来,Transformer架构以雷霆之势席卷计算机视觉领域,从ViT到DETR再到Grounding DINO,各类Transformer模型频频刷新检测与分割性能的新高。在这样的大背景下,卷积神经网络(CNN)体系似乎逐渐退居二线。
然而,YOLO系列以其一贯的轻量高效,始终在实际部署场景中占据重要地位。尤其是腾讯团队提出的YOLO-World,首次将开放词汇检测(Open-Vocabulary Detection)引入了YOLO体系,实现了令人惊叹的实时开放检测。

如今,清华大学团队在YOLO-World的基础上提出了新一代模型——YOLOE(Real-Time Seeing Anything),不仅进一步提升了检测性能与推理速度,更引入了多模态提示支持和强大的实例分割能力,拓展了开放世界视觉任务的新边界。
那么,YOLOE与火爆的Transformer模型之间有何区别?与YOLO-World相比又有何升级?本文将带你深入了解。
论文地址:https://arxiv.org/pdf/2503.07465
项目链接:https://github.com/THU-MIG/yoloe
目录
一、Transformer当道,YOLO系为何坚持CNN路线?
二、YOLO-World与YOLOE
YOLO-World简述
YOLOE的进一步进化
三、YOLOE的核心亮点详解
多提示机制:灵活适应多样场景
开放词汇实例分割:检测与分割合二为一
四、Coovally平台助力:从实验到应用一站式打通
五、使用案例和应用
开放世界物体检测:
快速检测和单次检测:
大词汇量和长尾识别:
交互式检测和分割:
自动数据标注和引导:
任意物体的分割:
六、YOLOE的意义与未来展望
一、Transformer当道,YOLO系为何坚持CNN路线?
在视觉领域,Transformer模型凭借其出色的全局建模能力成为主流。以ViT、DETR、Grounding DINO等为代表的Transformer系模型,擅长捕捉长距离依赖关系,能有效处理复杂场景下的视觉理解任务。
但Transformer的优势也伴随着明显的代价:
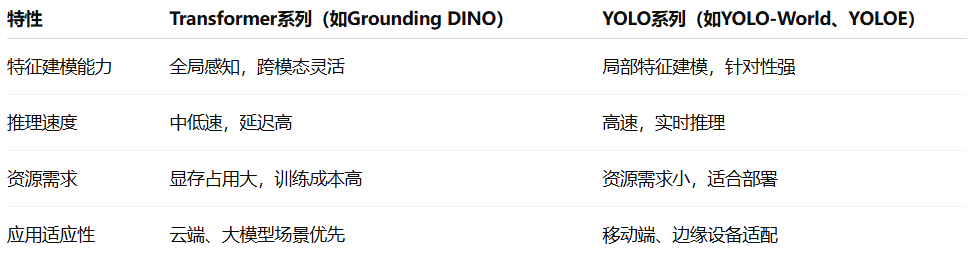
YOLO体系在快速推理和资源友好性方面始终有着不可替代的优势,尤其适合边缘计算、移动设备、无人机等对实时性要求极高的场景。
YOLO-World的出现,首次证明了轻量CNN结构也能在开放世界检测领域一战。YOLOE则在此基础上进一步突破,让轻量化与开放世界能力达到了新的高度。
二、YOLO-World与YOLOE
-
YOLO-World简述
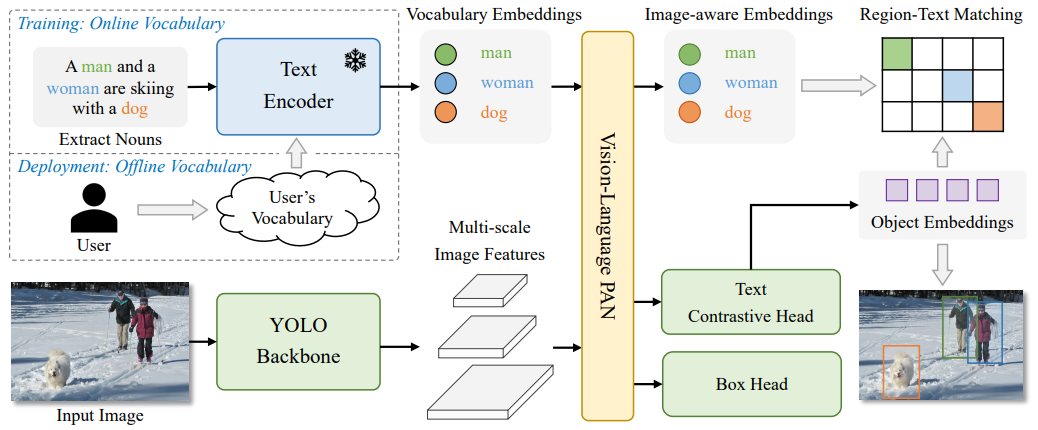
YOLO-World由腾讯AI Lab提出,核心贡献在于:
-
将文本Prompt机制引入YOLO结构;
-
支持在预定义类别之外识别开放世界中的任意目标;
-
保持了YOLO一贯的推理高效性,实现了开放检测的实时化。
在当时,YOLO-World开辟了一个全新的方向,让轻量检测模型也能具备一定的开放词汇理解能力。
-
YOLOE的进一步进化
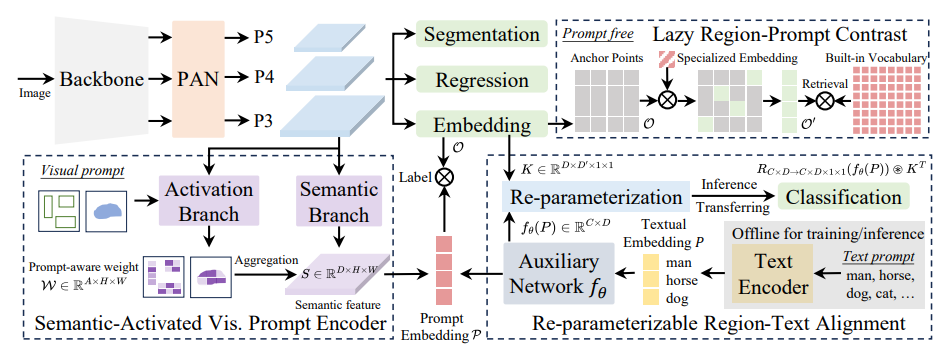
清华团队提出的YOLOE,则在YOLO-World基础上做出了系统性扩展与优化:
-
支持多种提示模式(Prompt):不仅支持文本提示,还支持视觉提示(如选框、局部区域),甚至在无提示条件下自动识别(Prompt-Free)。
-
引入分割能力:不仅能检测,还能进行开放词汇条件下的实例分割(Segmentation)。
-
提升推理速度与精度:在开放世界任务中,YOLOE进一步缩短了推理时间,同时在检测和分割准确率上超越YOLO-World。
以下为简要对比:
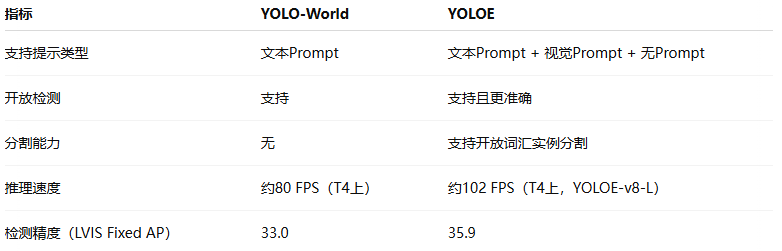
可以看到,YOLOE在检测性能、分割支持和推理速度上均优于YOLO-World,真正实现了在实时性与开放世界能力之间的平衡与提升。
三、YOLOE的核心亮点详解
-
多提示机制:灵活适应多样场景

YOLOE首次引入了多提示机制(Multi-Prompt Support),具体包括:
-
文本提示(Text Prompt):输入文字描述,检测对应类别物体;
-
视觉提示(Visual Prompt):通过局部图像或框选区域引导检测;
-
无提示(Prompt-Free):直接对画面中的所有可见物体进行识别和分类。
这种多模式提示支持极大增强了模型在实际应用中的灵活性,比如在无人巡检、医疗影像筛查等任务中,不同场景可以选择最适合的提示方式。
更多详解内容以及讲解可以访问《清华YOLOE新发布:实时识别任何物体!零样本开放检测与分割》
-
开放词汇实例分割:检测与分割合二为一
在YOLO-World时代,分割功能尚未被纳入实时开放检测体系。而YOLOE率先实现了:
-
开放词汇实例分割(Open-Vocabulary Instance Segmentation)
-
实时推理,毫不拖慢检测速度
对比如下:

YOLOE通过扩展带有掩码预测分支的检测头,将实例分割直接集成到其架构中。这种方法与YOLOv8类似,但适用于任何已提示的对象类别。分割掩码会自动包含在推理结果中,并可通过以下方式访问 results[0].masks. 这种统一的方法无需单独的检测和分割模型,从而简化了需要精确到像素的对象边界的应用的工作流程。
YOLOE打破了以往要快就不能分割,要分割就必须牺牲速度的局限,实现了实时检测与实时分割的统一。
在智慧城市、零售分析、工业巡检等应用中,实时分割尤其重要,比如快速圈定破损区域、识别特定材质物体等。
四、Coovally平台助力:从实验到应用一站式打通
面对YOLOE这种集成开放检测与分割的新型模型,快速部署与灵活实验变得尤为关键。
为了满足研发与应用需求,Coovally平台即将推出全新能力:
-
SSH直连Coovally云端算力,无需繁琐配置;
-
全面支持VS Code、Cursor、windsurf等主流开发工具:实现云端代码实时调试与训练;
-
支持YOLO、YOLOE、Transformer类模型自由微调与二次开发;
-
弹性算力资源:根据实验规模灵活扩展,无论是小样本调试还是大规模微调均可应对。
同时,Coovally平台还整合了国内外开源社区1000+模型算法和各类公开识别数据集,无论是YOLO系列模型还是Transformer系列视觉模型算法,平台全部包含,无论是学术研究中的小规模探索,还是产业项目中的快速落地,Coovally都能大幅提升开发效率,加速成果转化。
平台链接:https://www.coovally.com
如果你想要另外的模型算法和数据集,欢迎后台或评论区留言,我们找到后会第一时间与您分享!
五、使用案例和应用
YOLOE 的开放式词汇检测和分词功能使其应用范围超越了传统的固定类模型:
-
开放世界物体检测:
非常适合机器人等动态场景,机器人可通过提示识别以前未见过的物体,安防系统也可快速适应新的威胁(如危险物品),无需重新训练。
-
快速检测和单次检测:
通过视觉提示 (SAVPE),YOLOE 可从单个参考图像中快速学习新对象,非常适合工业检测(即时识别部件或缺陷)或定制监控,只需最少的设置即可实现视觉搜索。
-
大词汇量和长尾识别:
YOLOE 拥有超过 1000 个类别的词汇量,在生物多样性监测(检测稀有物种)、博物馆藏品、零售库存或电子商务等任务中表现出色,无需进行大量的每类训练即可可靠地识别许多类别。
-
交互式检测和分割:
YOLOE 支持实时交互式应用,如可搜索的视频/图像检索、增强现实(AR)和直观的图像编辑,由自然输入(文本或视觉提示)驱动。用户可以使用分割掩码动态地精确隔离、识别或编辑对象。
-
自动数据标注和引导:
YOLOE 通过提供初始边界框和分割注释来促进数据集的快速创建,大大减少了人工标注的工作量。在分析大型媒体集合时尤为重要,它可以自动识别存在的对象,帮助更快地建立专门的模型。
-
任意物体的分割:
通过提示将分割功能扩展到任意物体--尤其适用于医学成像、显微镜或卫星图像分析,无需专门的预训练模型即可自动识别并精确分割结构。与 SAM不同的是,YOLOE 可同时自动识别和分割对象,从而为内容创建或场景理解等任务提供帮助。
六、YOLOE的意义与未来展望
YOLOE的出现,标志着YOLO体系正式跨入开放世界视觉任务的全新阶段。
在Transformer大模型主导视觉领域的时代,YOLOE坚持轻量高效的CNN路线,并通过合理引入Prompt机制与高效特征建模,打破了实时检测与开放性、分割能力之间的矛盾。
未来,随着开放世界任务需求不断增长(例如自动驾驶、智能制造、精准医疗等领域),YOLOE这类模型将在更多场景中发挥关键作用。
同时,依托像Coovally这样的云端平台,开发者可以更加高效地探索YOLOE的潜力,不断拓展人工智能在现实世界的应用边界。
实时Seeing Anything,从YOLOE出发;赋能下一代视觉应用,从Coovally开始。
