Semantic Kernel 核心组件 Pipeline:AI 应用的流程引擎
目录
一、Pipeline 的本质:AI 任务的“流水线工厂”
1. Pipeline 的核心作用
2. Pipeline 的典型场景
二、SK Pipeline 的架构设计
1. 核心组件关系
2. Pipeline 的三大核心机制
(1) 技能编排(Skill Orchestration)
(2) 上下文传递(Context Flow)
(3) 异步执行(Async Execution)
三、Pipeline 实战:从薪资计算到智能客服
案例 1:薪资计算 Pipeline
案例 2:智能客服 Pipeline
四、Pipeline 的最佳实践与避坑指南
1. 优化技巧
2. 常见问题与解决
五、总结:为什么 Pipeline 是 SK 的灵魂?

在 AI 应用开发中,如何高效串联多个任务并管理数据流是核心挑战。微软开源的 Semantic Kernel(SK) 框架通过 Pipeline(流水线) 机制,提供了一种简洁的解决方案。本文将从原理、架构、实战三个维度,解析 SK Pipeline 的核心设计。
一句话概括pipline作用就是:Pipeline 是 Semantic Kernel 中用于将多个技能或模型按逻辑顺序串联,并通过自动化上下文传递与异步执行来编排复杂 AI 任务的核心流程引擎。
一、Pipeline 的本质:AI 任务的“流水线工厂”
1. Pipeline 的核心作用
-
任务流程化:将复杂的 AI 任务拆解为多个可复用的步骤(如调用模型、数据处理、逻辑判断)。
-
数据流管理:自动传递每一步的输出作为下一步的输入,形成连贯的工作流。
-
异步优化:通过
asyncio实现非阻塞执行,提升吞吐量。
2. Pipeline 的典型场景
-
多模型协作:例如先用 GPT 生成文本,再用 DALL-E 生成图片。
-
混合逻辑:结合规则引擎(如数学计算)和大模型(如文本理解)。
-
上下文串联:如聊天机器人中维护对话历史上下文。
二、SK Pipeline 的架构设计
1. 核心组件关系

-
Skills(技能):原子化功能单元(如数学计算、文本处理)。
-
Pipeline:负责串联 Skills,管理执行顺序和数据流。
-
Planner(规划器):动态生成 Pipeline 步骤(如
SequentialPlanner)。 -
Connectors(连接器):对接外部服务(如 OpenAI、DashScope)。
2. Pipeline 的三大核心机制
(1) 技能编排(Skill Orchestration)
-
注册技能:通过
kernel.import_skill()加载自定义或内置技能。 -
动态调用:Pipeline 根据 Planner 生成的步骤,按需调用技能。
-
示例代码:
# 注册数学技能
math_skill = kernel.import_skill(MathPlugin(), "math")
# 注册文本技能
text_skill = kernel.import_skill(TextPlugin(), "text")(2) 上下文传递(Context Flow)
-
SKContext 对象:跨步骤传递数据的容器(键值对存储)。
-
自动参数绑定:通过
@sk_function_context_parameter声明参数来源。 -
示例代码:
@sk_function_context_parameter(name="input", description="被减数")
def subtract(self, context: SKContext):input_val = context["input"] # 从前一步获取值return str(float(input_val) - 2000)(3) 异步执行(Async Execution)
-
非阻塞调度:利用
asyncio实现高并发,避免 I/O 等待。 -
性能优化:适合调用外部 API(如大模型接口)。
-
示例代码:
async def main():plan = await planner.create_plan_async(ask)result = await plan.invoke_async()
三、Pipeline 实战:从薪资计算到智能客服
案例 1:薪资计算 Pipeline

代码逻辑:
ask = "底薪 3000 元,涨 15%,提成 5000 元,开销 2000 元,求存款"
plan = await planner.create_plan_async(ask)
# 自动生成步骤:Multiply → Add → Subtract案例 2:智能客服 Pipeline
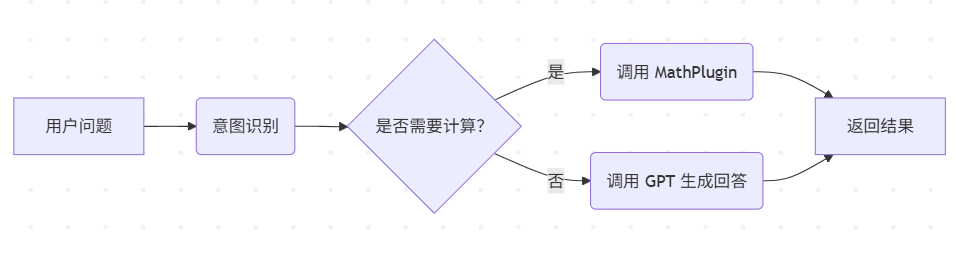
-
优势:
-
混合规则引擎与大模型,兼顾准确性与灵活性。
-
通过 Pipeline 动态路由任务。
-
四、Pipeline 的最佳实践与避坑指南
1. 优化技巧
-
技能解耦:每个 Skill 只负责单一功能(如
MathPlugin仅处理数学计算)。 -
参数描述精准化:使用明确的中文描述参数,帮助 Planner 准确匹配(如“被减数”而非“输入1”)。
-
异步批处理:对多个独立任务使用
asyncio.gather()并行执行。
2. 常见问题与解决
-
问题 1:参数传递失败
-
原因:未正确定义
@sk_function_context_parameter。 -
解决:检查参数名称是否与上下文键名一致。
-
-
问题 2:步骤顺序错误
-
原因:Planner 未能正确理解任务逻辑。
-
解决:手动定义 Pipeline 步骤或优化问题描述。
-
-
问题 3:性能瓶颈
-
原因:同步阻塞调用外部 API。
-
解决:确保所有 I/O 操作为异步(如
async with httpx.AsyncClient())。
-
五、总结:为什么 Pipeline 是 SK 的灵魂?
SK 的 Pipeline 机制 通过三大设计解决了 AI 应用的核心痛点:
-
可组合性:自由拼接 Skills,适应复杂场景。
-
灵活性:支持静态定义与动态生成两种流程模式。
-
高效性:异步执行 + 上下文管理,兼顾性能与功能。
对于开发者而言,掌握 Pipeline 的运作原理,相当于获得了构建高效 AI 应用的“流程引擎”。