【AI论文】RefVNLI:迈向可扩展的主题驱动文本到图像生成评估
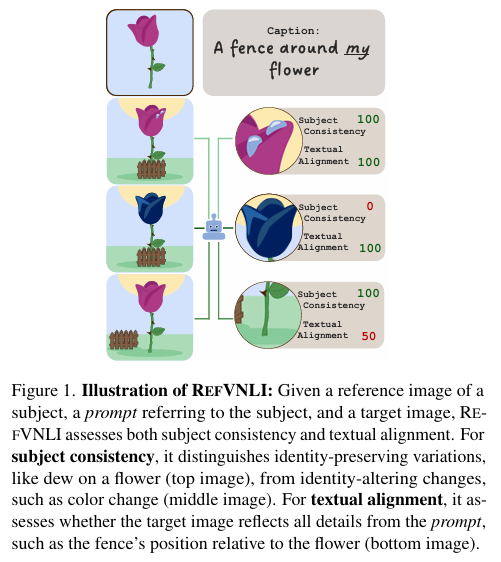
摘要:主题驱动的文本到图像(T2I)生成旨在生成与给定文本描述一致的图像,同时保留参考主题图像的视觉特征。 尽管该领域具有广泛的下游适用性——从增强图像生成的个性化到视频渲染中一致的角色表示——但该领域的进展受到缺乏可靠的自动评估的限制。 现有的方法要么只评估任务的一个方面(即文本对齐或主题保留),与人类判断不一致,要么依赖于昂贵的基于API的评估。 为了解决这个问题,我们引入了RefVNLI,这是一种经济有效的度量方法,可以在一次预测中同时评估文本对齐和主题保留。 RefVNLI 在从视频推理基准和图像扰动中获得的大规模数据集上进行训练,在多个基准和主题类别(如动物、物体)上优于或匹配现有的基线,在文本对齐上实现了高达 6.4 分的增益,在主题一致性上实现了 8.5 分的增益。 它在不太知名的概念上也表现出色,与人类偏好的一致性超过87%。Huggingface链接:Paper page,论文链接:2504.17502
研究背景和目的
研究背景
随着人工智能技术的不断发展,文本到图像(T2I)生成技术在多个领域展现出了巨大的应用潜力。特别是在主题驱动的T2I生成中,该技术能够根据给定的文本描述和参考主题图像生成符合要求的图像,这在图像编辑、个性化图像生成、视频渲染中的角色一致性表示等方面具有广泛的应用前景。然而,当前主题驱动的T2I生成领域面临着自动评估方法不可靠的问题。现有的评估方法往往只能评估任务的一个方面,如文本对齐或主题保留,而无法同时兼顾两者。此外,这些方法要么与人类判断不一致,要么依赖于昂贵的基于API的评估,这限制了该领域的进一步发展。
针对上述问题,研究一种能够同时评估文本对齐和主题保留的可靠且经济有效的评估方法显得尤为重要。这不仅有助于推动主题驱动的T2I生成技术的进步,还能够提高生成图像的质量和一致性,从而满足更广泛的应用需求。
研究目的
本文旨在提出一种名为RefVNLI的评估方法,用于主题驱动的T2I生成的可靠且可扩展的评估。RefVNLI旨在通过一次预测同时评估生成图像与给定文本描述之间的文本对齐程度以及生成图像与参考主题图像之间的主题保留程度。该方法的提出旨在解决当前评估方法中存在的局限性,为主题驱动的T2I生成领域提供一种更加全面、准确且经济的评估手段。
研究方法
数据集构建
为了训练RefVNLI评估模型,本文构建了一个大规模的数据集。该数据集包含大量的<image ref, prompt, image tgt>三元组,其中image ref表示参考主题图像,prompt表示给定的文本描述,image tgt表示生成的图像。数据集的构建过程主要包括两个步骤:
-
主题驱动的图像对生成:本文利用视频数据集(如Mementos和TVQA+)来生成包含相同或不同主题的图像对。通过从视频中提取帧,并对帧中的主体进行识别和定位,本文能够生成大量的正样本(包含相同主题的图像对)和负样本(包含不同主题的图像对)。此外,为了增强模型对身份特定属性的敏感性,本文还对图像进行了扰动处理,如遮挡和修复关键区域,以生成额外的负样本。
-
图像-提示对生成:对于每个<image ref, image tgt>对,本文使用大型语言模型(如Gemini)来生成与image tgt对应的正面提示(positive prompt),并确保提示中明确提到了主体。同时,为了生成负面提示(negative prompt),本文还交换了不同图像之间的提示,并创建了硬负面提示(hard negative prompt),通过修改正面提示中的单个非主体细节来增强模型的鲁棒性。
通过上述步骤,本文成功构建了一个包含120万个三元组的大规模数据集,用于训练RefVNLI评估模型。
模型训练
本文选择PaliGemma作为RefVNLI评估模型的基础架构。PaliGemma是一种适用于多图像输入的3B视觉语言模型,在迁移学习方面表现出色。在训练过程中,本文采用二元分类任务来同时评估文本对齐和主题保留。具体来说,模型首先评估文本对齐(即image tgt与prompt之间的对齐程度),然后评估主题保留(即image tgt与image ref之间的主题一致性)。通过计算每个分类任务中预测为正样本的概率之比,本文能够得出文本对齐和主题保留的分数。
研究结果
定量评估
本文在多个基准数据集上对RefVNLI进行了定量评估,包括DreamBench++、ImagenHub和KITTEN等。评估结果显示,RefVNLI在文本对齐和主题保留两个任务上均表现出色,优于或匹配现有的基线方法。特别是在主题一致性方面,RefVNLI在多个基准数据集上实现了显著的增益,如在DreamBench++的动物类别上实现了6.3分的增益。此外,RefVNLI在综合评估(即文本对齐和主题保留的调和平均数)上也表现优异,一致性地领先于其他基线方法。
定性评估
除了定量评估外,本文还通过定性分析来进一步验证RefVNLI的有效性。通过对比RefVNLI与其他基线方法在不同情况下的评估结果,本文发现RefVNLI能够更好地捕捉生成图像与文本描述和参考图像之间的细微差异。特别是在处理不太知名的概念时,RefVNLI与人类偏好的一致性超过了87%,表现出了强大的泛化能力。
研究局限
尽管RefVNLI在多个基准数据集上表现出了优异的性能,但仍存在一些局限性。首先,RefVNLI在训练过程中依赖于大量的人工标注数据,这限制了其在某些领域的应用。其次,RefVNLI在处理具有复杂艺术风格的主题图像时可能表现不佳,因为它在训练过程中主要关注于身份特定属性的保留。此外,RefVNLI目前只能处理单个参考图像的情况,无法同时处理多个参考图像。
未来研究方向
针对上述局限性,未来的研究工作可以从以下几个方面展开:
-
减少对数据标注的依赖:通过探索自监督学习和弱监督学习等方法,减少RefVNLI对数据标注的依赖,提高其在不同领域的应用广泛性。
-
增强对艺术风格的评估能力:通过引入额外的训练数据和改进模型架构,提高RefVNLI在处理具有复杂艺术风格的主题图像时的评估能力。
-
支持多个参考图像:扩展RefVNLI的功能,使其能够同时处理多个参考图像,以更好地满足实际应用中的需求。
-
提高评估效率:通过优化模型架构和训练过程,提高RefVNLI的评估效率,使其能够在更短的时间内完成大量生成图像的评估任务。
综上所述,RefVNLI为主题驱动的T2I生成领域提供了一种可靠且经济有效的评估方法。未来的研究工作将进一步推动该领域的发展,提高生成图像的质量和一致性。