梯度下降法
梯度下降法是一种常见的求最小值(或最值)的方法。它是通过沿着函数梯度的负方向进行迭代更新,直到找到局部最小值或最大值。梯度下降法应用于多元函数时,通过更新参数的方式找到最优解。
梯度下降法步骤:
- 初始化参数: 假设你有一个目标函数 f ( x 1 , x 2 , … , x p ) f(x_1, x_2, \dots, x_p) f(x1,x2,…,xp) ,并从一个初始点 x 0 x_0 x0开始。
- 计算梯度: 计算目标函数在当前点的梯度向量:
- ∇ f ( x 1 , x 2 , … , x p ) = ( ∂ f ∂ x 1 , ∂ f ∂ x 2 , … , ∂ f ∂ x p ) ∇ f(x_1, x_2, \dots, x_p) = \left( \frac{\partial f}{\partial x_1}, \frac{\partial f}{\partial x_2}, \dots, \frac{\partial f}{\partial x_p} \right) ∇f(x1,x2,…,xp)=(∂x1∂f,∂x2∂f,…,∂xp∂f)
- 更新参数: 根据梯度向量更新参数:
- x n e w = x o l d − α ⋅ ∇ f ( x o l d ) x_{new} = x_{old} - \alpha \cdot \nabla f(x_{old}) xnew=xold−α⋅∇f(xold)
- 其中, α \alpha α是学习率,决定每次更新的步长。
- 迭代: 不断重复以上步骤,直到梯度足够接近零,或者达到某个预设的停止条件(循环次数)。
#目标函数
def f(x):return (x-2)**2
#目标函数的梯度
def f1(x):return 2*(x-2)
def gradient_descent(k):x0=0a=1res=[]res.append(x0)for i in range(k):x1=x0-a*f1(x0)print(f'当前第{i}次迭代:x={x1:.6f},f(x)={f(x1):.6f}')res.append(f(x1))x0=x1return x0,res
# 调用
final_x,res = gradient_descent(10)
print(f"最终结果: x = {final_x:.6f}")
# 绘制x的变化曲线
plt.plot(res, marker='o')
plt.xlabel('epoach')
plt.ylabel('f(x)')
plt.title('gradient_descent')
plt.grid()
plt.show()
不同学习率下f(x)变化对比:
相同循环次数下
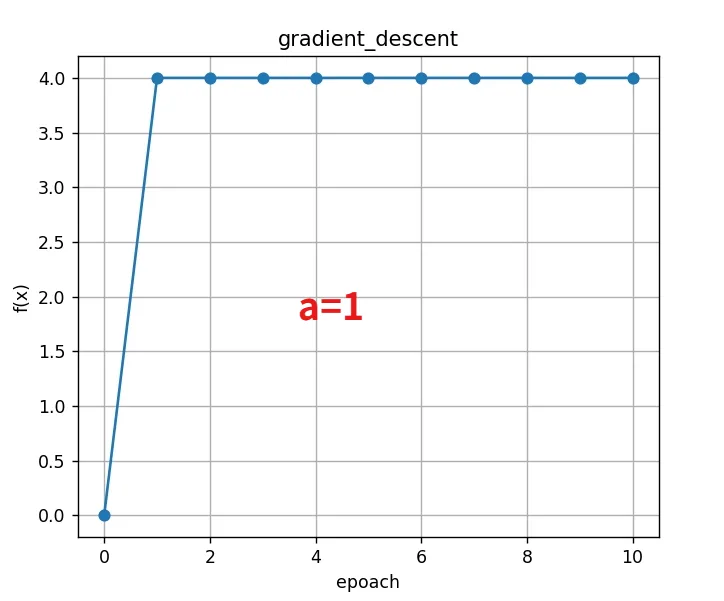
当前第0次迭代:x=4.000000,f(x)=4.000000
当前第1次迭代:x=0.000000,f(x)=4.000000
当前第2次迭代:x=4.000000,f(x)=4.000000
当前第3次迭代:x=0.000000,f(x)=4.000000
当前第4次迭代:x=4.000000,f(x)=4.000000
当前第5次迭代:x=0.000000,f(x)=4.000000
当前第6次迭代:x=4.000000,f(x)=4.000000
当前第7次迭代:x=0.000000,f(x)=4.000000
当前第8次迭代:x=4.000000,f(x)=4.000000
当前第9次迭代:x=0.000000,f(x)=4.000000
最终结果: x = 0.000000
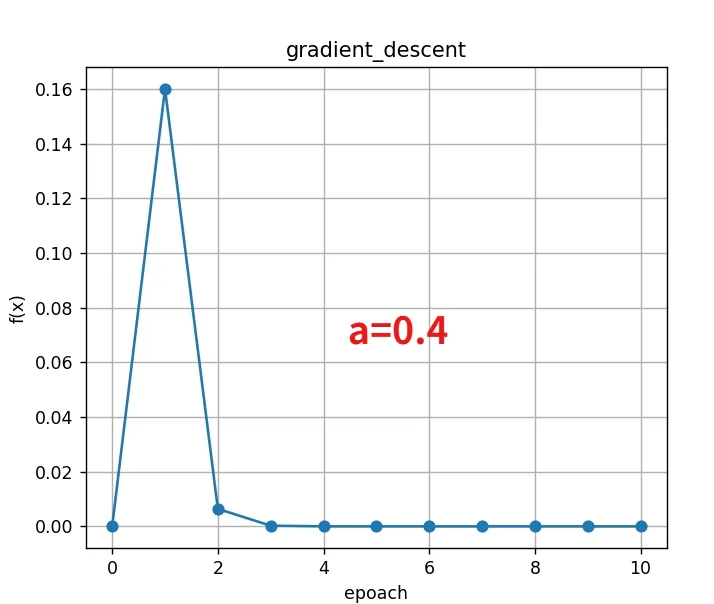
当前第0次迭代:x=1.600000,f(x)=0.160000
当前第1次迭代:x=1.920000,f(x)=0.006400
当前第2次迭代:x=1.984000,f(x)=0.000256
当前第3次迭代:x=1.996800,f(x)=0.000010
当前第4次迭代:x=1.999360,f(x)=0.000000
当前第5次迭代:x=1.999872,f(x)=0.000000
当前第6次迭代:x=1.999974,f(x)=0.000000
当前第7次迭代:x=1.999995,f(x)=0.000000
当前第8次迭代:x=1.999999,f(x)=0.000000
当前第9次迭代:x=2.000000,f(x)=0.000000
最终结果: x = 2.000000
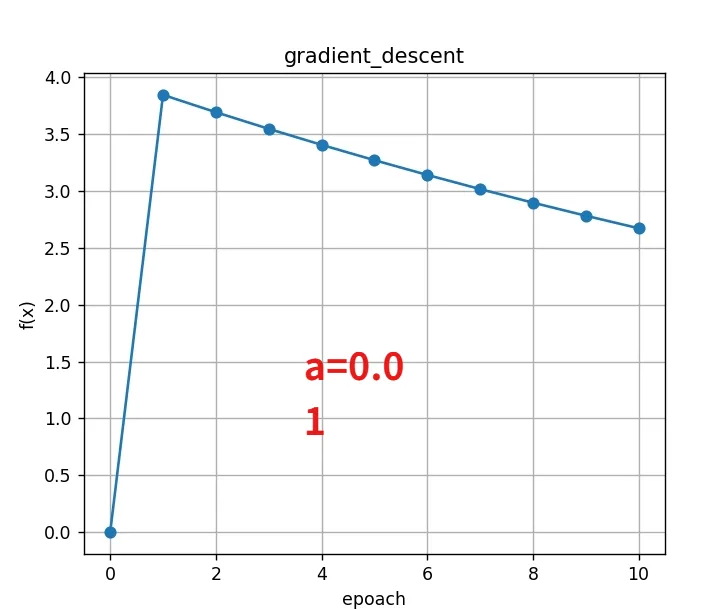
当前第0次迭代:x=0.040000,f(x)=3.841600
当前第1次迭代:x=0.079200,f(x)=3.689473
当前第2次迭代:x=0.117616,f(x)=3.543370
当前第3次迭代:x=0.155264,f(x)=3.403052
当前第4次迭代:x=0.192158,f(x)=3.268291
当前第5次迭代:x=0.228315,f(x)=3.138867
当前第6次迭代:x=0.263749,f(x)=3.014568
当前第7次迭代:x=0.298474,f(x)=2.895191
当前第8次迭代:x=0.332504,f(x)=2.780541
当前第9次迭代:x=0.365854,f(x)=2.670432
最终结果: x = 0.365854

当前第0次迭代:x=0.004000,f(x)=3.984016
当前第1次迭代:x=0.007992,f(x)=3.968096
当前第2次迭代:x=0.011976,f(x)=3.952239
当前第3次迭代:x=0.015952,f(x)=3.936446
当前第4次迭代:x=0.019920,f(x)=3.920716
当前第5次迭代:x=0.023880,f(x)=3.905049
当前第6次迭代:x=0.027833,f(x)=3.889444
当前第7次迭代:x=0.031777,f(x)=3.873902
当前第8次迭代:x=0.035713,f(x)=3.858422
当前第9次迭代:x=0.039642,f(x)=3.843004
最终结果: x = 0.039642
由上面可知:
学习率 α 不能太大也不能太小
➔ 太大:容易越过最优点,甚至发散;
➔ 太小:收敛很慢,需要很多步。