2024理想算法岗笔试笔记

要理解指令微调(Instruction Tuning),需要先将其置于大语言模型(LLM)的训练框架中 —— 它并非模型训练的起点,而是针对 “让模型更懂人类需求” 的关键优化步骤。简单来说,指令微调是通过让模型学习 “指令 - 响应” 配对数据,将原本擅长 “预测下一个词” 的基础模型,升级为能精准理解人类指令、输出符合预期结果的 “实用型模型” 的过程。
2025算法八股——大模型开发——指令微调-CSDN博客
2025算法八股——大模型开发——Agent相关-CSDN博客
-
非凸、非连续:0/1 损失在y⋅f(x)=0处突变(从 0 跳到 1),函数图像是 “阶跃状”,没有连续的梯度。这导致无法用梯度下降等主流优化算法求解(需要损失函数连续可导或至少存在次梯度)。
-
只关注 “是否正确”,不关注 “正确的程度”:例如,一个样本被模型预测为y⋅f(x)=100(非常确信的正确),与y⋅f(x)=0.1(勉强正确),在 0/1 损失下都算 “损失为 0”,但前者显然是更优的预测结果。0/1 损失无法区分这种 “置信度差异”,不利于模型学习 “更稳健的分类边界”。
2025算法八股——机器学习——SVM损失函数-CSDN博客
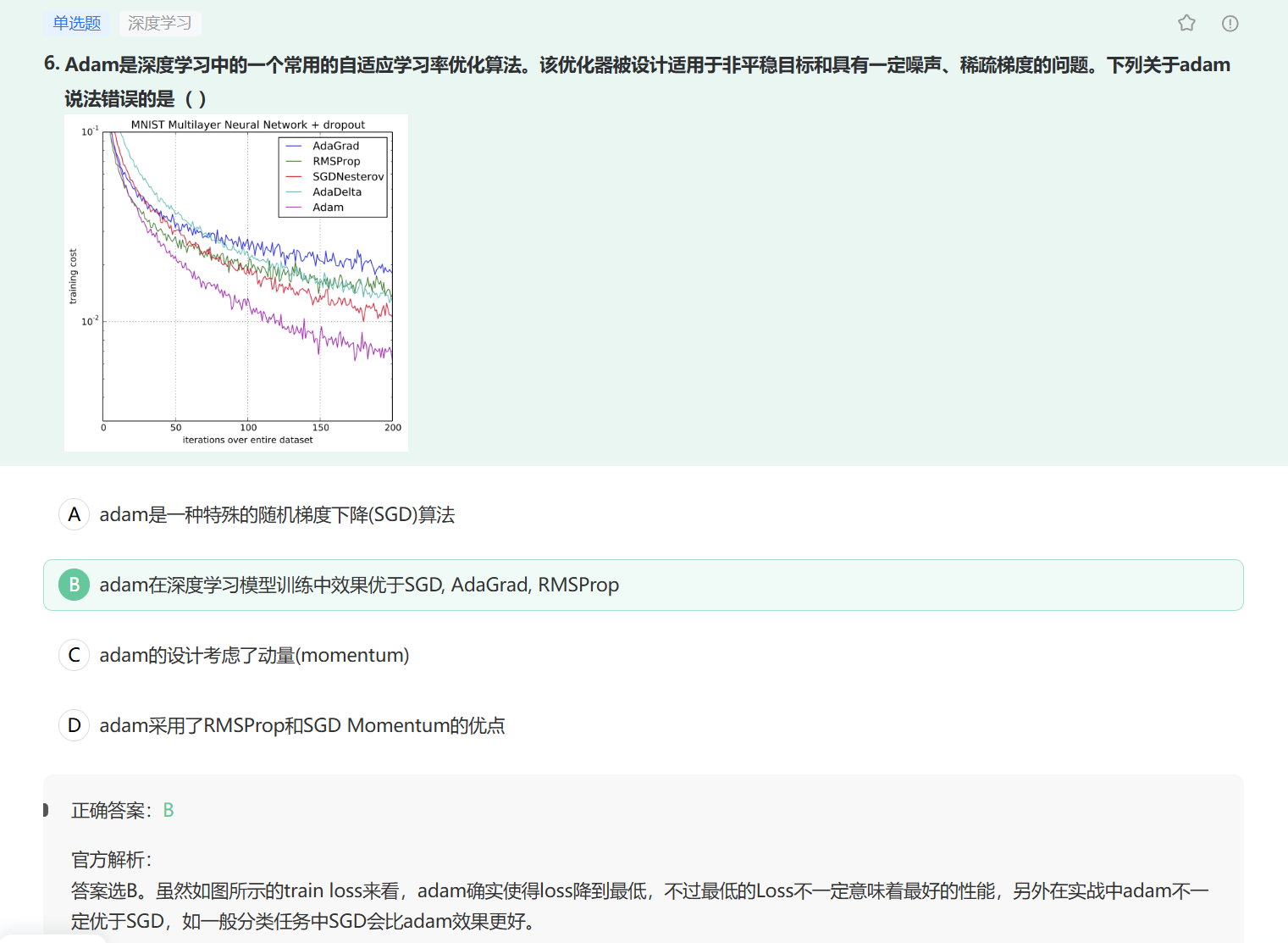
2025算法八股——深度学习——优化器小结-CSDN博客
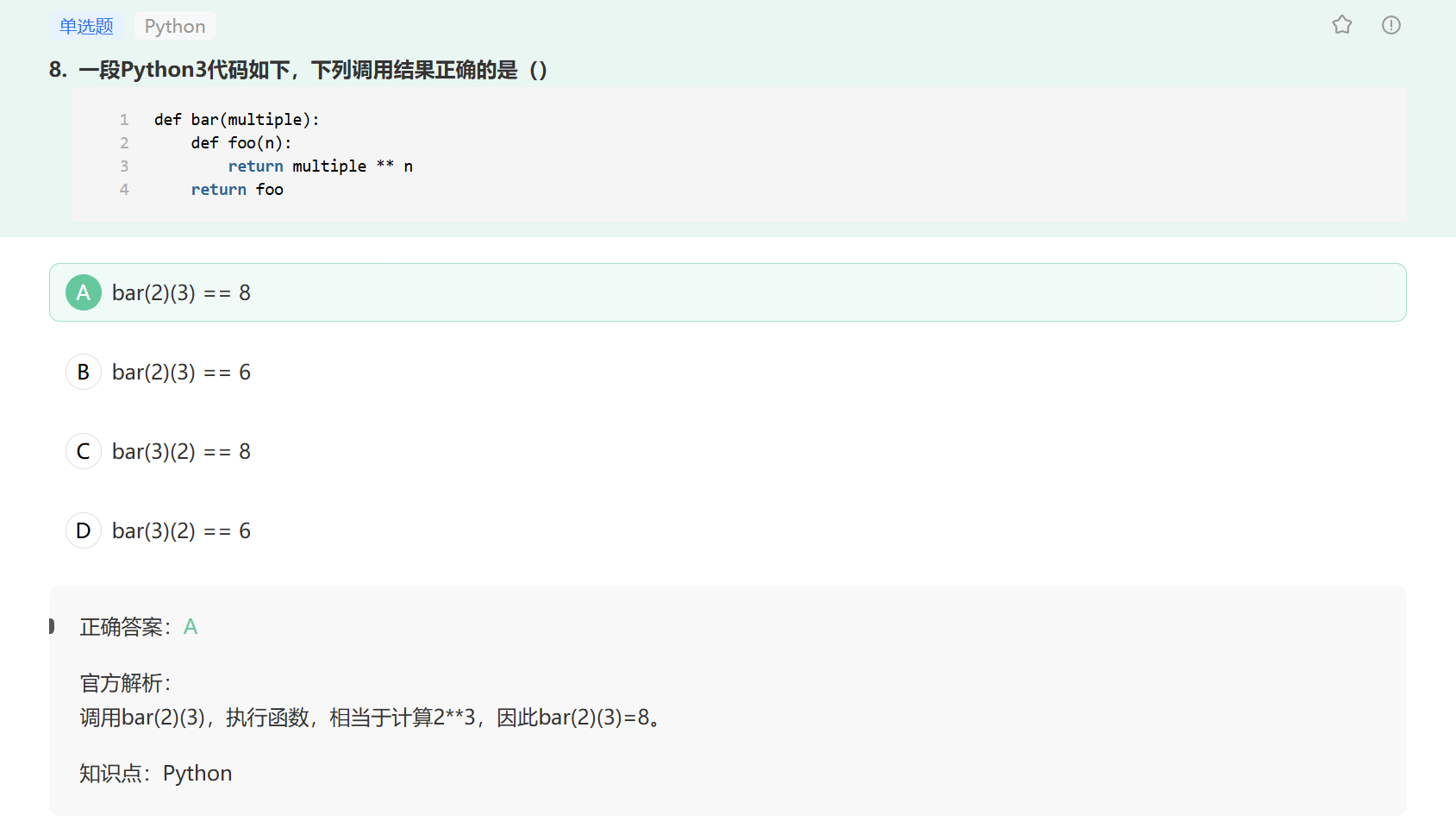
Python 允许 bar(2)(3) 这种调用方式,这是因为 bar() 函数返回的是另一个函数(foo),所以可以直接在返回值后继续添加括号调用该函数。
这种模式称为 “函数闭包”(closure),即内部函数 foo 可以访问外部函数 bar 中定义的变量(multiple),即使在 bar 函数执行完毕后,这个变量依然会被保留。这使得我们可以创建具有 “记忆” 能力的函数,在实际开发中常用于实现装饰器、工厂函数等场景。
搞清楚c就都搞清楚了
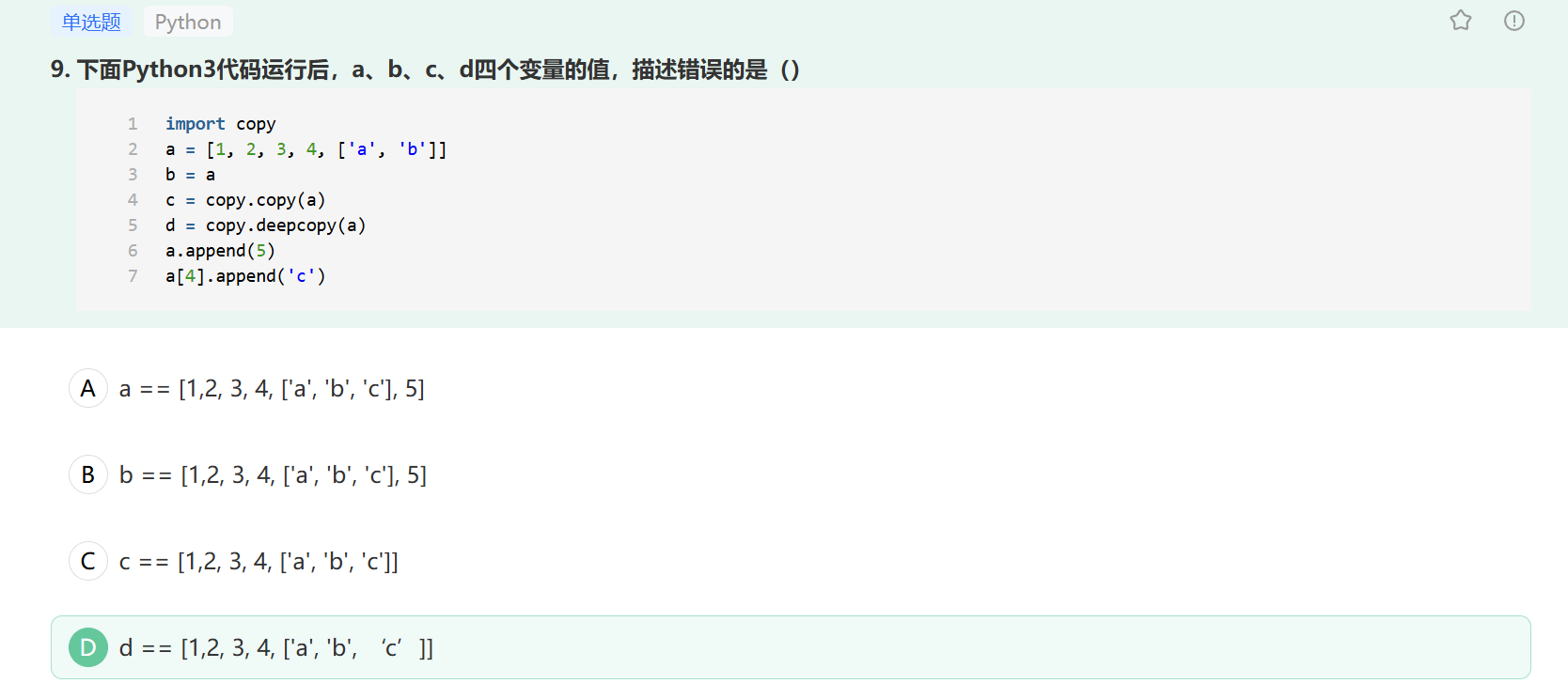
官方解析:
考察:赋值、深拷贝、浅拷贝
1.对象的赋值
都是进行对象引用(内存地址)传递,即‘’ b is a‘’ ,a 变 b 也变
2.浅拷贝
会创建一个新的对象,即 “c is not a” ,但是,对于对象中的元素,浅拷贝就只会使用原始元素的引用(内存地址),也就是说
”c[i] is a[i]”
当我们使用下面的操作的时候,会产生浅拷贝的效果:
- 使用切片
[:]操作 - 使用工厂函数(如list/dir/set)
- 使用copy模块中的copy()函数
3.深拷贝
会创建一个新的对象,即”d is not a” ,并且对于对象中的元素,深拷贝都会重新生成一份(有特殊情况),而不是简单的使用原始元素的引用(内存地址)
拷贝的特殊情况
其实,对于拷贝有一些特殊情况:
- 对于非容器类型(如数字、字符串、和其他’原子’类型的对象)没有拷贝这一说
- 如果元祖变量只包含原子类型对象,则不能深拷贝
知识点:Python
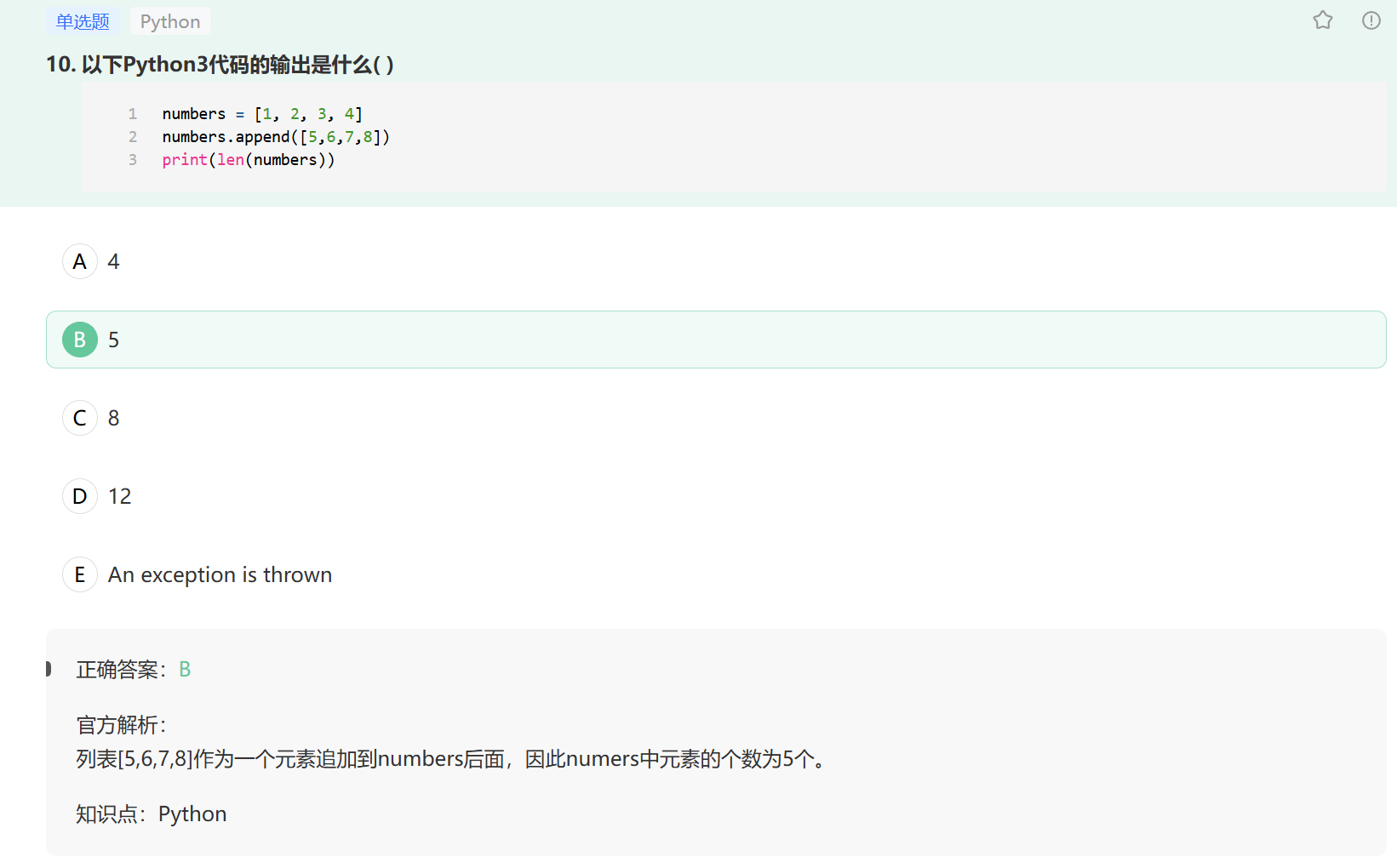
在 Python 中,append 和 extend 都是列表(list)的常用方法,但它们的功能不同,并非严格意义上的 “相对” 关系,而是用于不同场景的列表扩展操作:
-
append(item):将item作为单个元素添加到列表末尾。
例如:[1,2].append([3,4])结果为[1,2,[3,4]](把列表[3,4]当作一个整体元素添加)。 -
extend(iterable):将iterable(可迭代对象,如列表、元组等)中的每个元素逐个添加到列表末尾。
例如:[1,2].extend([3,4])结果为[1,2,3,4](把[3,4]中的元素拆分后添加)。
两者的核心区别在于:
append 是 “整体添加”,extend 是 “拆分添加”。