LLM面试基础(一)
主流的开源大模型体系有哪些
主流的开源大模型体系按照架构可以分为 Encoder-Decoder、Causal Decoder 和 Prefix Decoder 三类。以下是具体介绍:
Encoder-Decoder 模型:该体系模型在输入阶段利用双向注意力机制,充分理解输入文本的含义,在输出时采用单向注意力机制。这类模型在自然语言处理的理解类任务,如文本摘要、问答系统中表现优异。T5、Flan-T5、BART 等模型属于这一体系。
Causal Decoder 模型:此体系的模型采用从左到右的单向注意力机制,生成当前词时仅能依赖其前面已生成的词,适合自回归任务。它在文本生成任务中优势显著,比如小说创作、诗歌生成等场景,能够根据前文内容逐步生成自然流畅的后续文本。LLaMA-7B 及其衍生物就是这一体系的典型代表。
Prefix Decoder 模型:该体系模型在处理输入时采用双向注意力机制,能够全面捕捉输入文本前后文的信息,而在输出时则转换为单向注意力机制。其在对话交互场景中表现出色,能够基于对输入的充分理解生成连贯且逻辑合理的回复。ChatGLM、ChatGLM2 以及 U-PaLM 等模型属于这一体系。
此外,还有一些基于特定技术或应用场景的开源大模型,如 DeepSeek V3/R1,引入了 Multi-Head Latent Attention(MLA)和 Mixture-of-Experts(MoE)技术,提高了计算效率。OLMo 2 则是由艾伦人工智能研究院开发,训练数据和代码完全开源,在计算资源受限情况下能寻找性能与效率的最佳平衡点。
为什么叫Prefix Decoder,前缀?
Prefix Decoder 被称为 “前缀解码器” 是因为它在处理输入时,会将输入序列分为 “前缀” 和 “生成提示” 两部分。
具体来说,Prefix Decoder 的输入前缀部分会由解码器的前 N 层用双向注意力机制进行处理,这使得前缀中的每个词元都可以访问前缀中的所有其他词元,从而实现对输入信息的充分理解,就好像给模型提供了一个 “前缀” 作为提示。而在生成输出时,Prefix Decoder 则转换为单向注意力机制,由解码器的后 M 层根据前缀部分的语义向量和已生成的内容来逐词生成结果。这种结构设计使得模型能够在利用前缀信息进行充分理解的基础上,进行有效的文本生成,因此被称为 “Prefix Decoder”。
用通俗的语言解释Prefix Decoder
咱们可以用 “看剧本 + 接台词” 的日常场景,把 Prefix Decoder(前缀解码器)讲明白,不用纠结复杂术语:
你可以把这个模型想象成一个 “会接话的演员”,它干活分两步,核心就围绕 “先吃透前面的信息,再顺着往下说”—— 这里的 “前面信息”,就是名字里的 “前缀”。
第一步:先把 “前缀剧本” 彻底看明白
比如你跟它说 “今天天气特别好,我打算去公园”,这句话就是给模型的 “前缀”。这时候模型不会急着接话,而是像演员熟读剧本一样,用 “双向视角” 把这句话翻来覆去琢磨透:它会同时看 “天气好” 和 “去公园” 的关系,也知道 “今天” 是时间、“公园” 是地点,甚至能联想到 “去公园可能要散步、晒太阳”—— 相当于把 “前缀” 里所有信息都串成一张网,一点都不遗漏。
第二步:顺着 “前缀” 往下接,不跑偏
等吃透了 “前缀”,模型开始接话时,就换了个 “单向视角”:只能顺着前面的话往下说,不能回头 “改剧本”。比如它接 “那可以带个野餐垫,晒晒太阳很舒服”,这个回复一定是跟着 “天气好、去公园” 来的,不会突然蹦出 “昨天雨下得很大”(因为和 “前缀” 里的 “今天天气好” 矛盾),也不会凭空说 “我喜欢吃火锅”(和 “去公园” 的场景没关系)。
简单总结就是:
“前缀” 就是你先给模型的 “背景信息 / 开头的话”,“解码器” 就是它接话的能力。整个过程像你跟朋友聊天:先认真听完朋友说的话(吃透前缀),再顺着朋友的意思往下聊(单向接话),既不会没听懂就插嘴,也不会聊到跑偏的话题 —— 这就是 Prefix Decoder 的核心逻辑。
用通俗的语言解释Causal Decoder
咱们可以把 Causal Decoder(因果解码器)想象成一个 “只会顺着往前写的故事作者”,核心逻辑就是 “只能看着前面写过的内容,一步步往下编,没法回头看后面的”—— 这里的 “因果”,其实就是 “前面的内容决定后面的内容”。
比如你让它写一个开头是 “周末早上,我被窗外的鸟叫吵醒了” 的小故事,它写的时候会像咱们平时记流水账一样,完全 “顺着时间线走”:
第一步,先写开头 “周末早上,我被窗外的鸟叫吵醒了”—— 这时候它只知道 “开头”,还没后面的内容。
第二步,要写下一句时,它只能盯着 “被鸟叫吵醒” 这几个字想:吵醒之后会干嘛?可能是 “揉了揉眼睛,慢悠悠坐起来”—— 这一步只能参考 “前面的开头”,没法提前知道后面要写 “去厨房煮咖啡”。
第三步,再写下一句时,它能参考的就只有 “开头 + 第二步写的坐起来”,比如接着写 “走到窗边拉开窗帘,阳光一下子涌了进来”—— 还是只能盯着 “前面所有写过的内容”,不能 “跳步” 也不能 “回头改”。
哪怕写的时候偶尔有点小瑕疵(比如前面没提 “家里有猫”,后面突然写 “猫跳上了桌子”),它也没法像人一样回头检查修改,只能硬着头皮顺着前面的内容往下补(比如补一句 “这是上周刚领养的小橘猫,总爱黏着我”),因为它从始至终都 “看不到后面还没写的内容”,只能靠 “前面的内容” 推导 “后面该写啥”。
简单总结就是:Causal Decoder 像个 “没剧本的即兴作者”,写东西只能 “走一步看一步”,前面写了啥,后面就只能跟着啥走,既不能提前剧透后面的内容,也不能回头修改前面的细节 —— 所有内容都是 “前面的因,导致后面的果”,这就是它叫 “因果解码器” 的原因。
用通俗的语言解释Encoder-Decoder 模型
咱们可以把 Encoder-Decoder(编码器 - 解码器)模型,想象成一个 “专业的翻译员”,它干活分两步:先 “彻底听懂 / 看懂原文”,再 “准确说出 / 写出译文”——“Encoder” 就是负责 “听懂看懂” 的角色,“Decoder” 就是负责 “说出来写出来” 的角色,两者配合完成复杂任务。
举个最常见的例子,比如让它把 “今天天气很好,适合去爬山” 翻译成英文:
第一步:Encoder(编码器)先 “吃透原文”
就像翻译员拿到中文句子后,不会急着翻,而是先逐字逐句琢磨透所有信息:它会搞清楚 “今天” 是时间、“天气很好” 是状态、“适合去爬山” 是建议,还会注意到 “天气好” 和 “爬山” 之间的因果关系(因为天气好,所以适合爬山)。这个过程里,Encoder 会把所有信息 “压缩” 成一个 “理解包”—— 就像翻译员在脑子里把中文意思捋顺,记牢所有关键细节,确保没遗漏、没误解。
第二步:Decoder(解码器)再 “精准输出”
等 Encoder 把 “理解包” 递过来,Decoder 就开始生成英文了。它会盯着这个 “理解包”,结合英文的语法习惯,一句一句 “还原” 信息:先译 “Today” 对应 “今天”,再译 “the weather is very nice” 对应 “天气很好”,最后译 “which is suitable for climbing mountains” 对应 “适合去爬山”。而且它生成的时候很细心,会确保英文句子的逻辑和中文一致(比如用 “which” 连接,体现 “天气好” 和 “爬山” 的关系),不会译得颠三倒四。
再比如用它做 “文本摘要”(把长文章缩成短摘要):Encoder 先把长文章的核心观点、时间线、人物关系全看懂,压缩成 “核心包”;Decoder 再根据 “核心包”,用简洁的话把关键信息总结出来,既不丢重点,也不添额外内容。
简单总结就是:Encoder-Decoder 像个 “两步走的专业处理员”—— 第一步先 “彻底理解输入的内容”(比如原文、长文章、问题),第二步再 “根据理解输出想要的结果”(比如译文、摘要、答案)。它的核心优势就是 “先懂再输出”,适合需要 “先理解、再创作” 的任务,就像人做事要 “先想明白,再动手做” 一样。
用通俗的语言解释为什么Causal Decoder结构会在所有token上计算损失,而Prefix Decoder只会在输出上计算损失
Causal Decoder 结构会在所有 token 上计算损失,而 Prefix Decoder 只会在输出上计算损失,主要是因为它们的工作方式和目标不同。
Causal Decoder 可以想象成一个 “从头开始写故事” 的作者。它在写故事的过程中,每写一个词,都要根据前面已经写好的所有词来决定下一个词怎么写,也就是它的每个词都是基于前面的词一步步预测出来的。所以在训练的时候,为了让它写得更准确,就要检查它写的每一个词和正确答案相比是不是合适,因此会在所有的 token(也就是每一个词)上都计算损失,这样它就能知道自己每个地方写得对不对,从而不断调整自己的写作方式。
而 Prefix Decoder 更像是一个 “根据给定开头续写故事” 的作者。它先拿到一个 “开头”,这个开头就是 “前缀”,它会用一种方式把这个开头彻底理解清楚。然后在续写故事的时候,它只需要关注自己续写出来的内容是不是合理,不需要再去管开头部分写得怎么样,因为开头是给定的,不需要它去修改。所以在训练的时候,就只需要在它续写出来的输出部分计算损失,看看它续写的内容和正确的续写内容相比有没有差距,然后根据这个差距来调整自己续写的能力。
去噪自编码器的英文名字和扩散模型有什么关系
去噪自编码器的英文名字是 Denoising Autoencoder,通常缩写为 DAE。
它是自编码器(Autoencoder, AE)的一种重要变体,核心特点是在训练时会先给输入数据(比如图片、文本序列)添加 “噪声”(比如随机遮挡、像素扰动等),然后让模型学习从带噪声的输入中恢复出原始的、无噪声的数据。这种 “去噪” 能力让模型能更深入地捕捉数据的核心特征,而非简单记忆输入,因此在特征提取、数据修复、降维等任务中应用广泛。
去噪自编码器(Denoising Autoencoder,DAE)和扩散模型(Diffusion Model)有着紧密的联系,扩散模型可以看作是去噪自编码器的一种扩展和深化。
原理上的相似性:去噪自编码器的训练过程是先对输入数据添加噪声,然后让模型学习从带噪声的数据中恢复出原始数据。扩散模型同样涉及去噪过程,它通过逐渐去噪正态分布变量来学习数据分布,其逆转过程中的每一步都是将一个带噪声的输入变得更干净一点,这与去噪自编码器的去噪原理是一致的。
扩散模型可视为去噪自编码器序列:扩散模型可以解释为一个等加权的去噪自编码器序列ϵθ(xt,t)(t=1…T),其中xt是输入x的噪声版本,t从{1,...,T}中均匀采样。这些去噪自编码器被训练来预测其输入的去噪变体,也就是说扩散模型在训练时是通过多个去噪自编码器来逐步实现从噪声到真实数据的转换。
关键区别:扩散模型与传统去噪自编码器有两个关键区别。一是扩散模型有额外的输入t,这个t用于指示去噪过程进行到了哪一步,使得单个模型能用同一套共享参数处理许多不同的噪声水平;二是去噪自编码器通常关注学习一个有用的潜在表示,而扩散模型更关心模型的输出,不需要瓶颈结构,加入瓶颈可能反而对扩散模型不利。
用通俗的语言解释等加权的去噪自编码器序列
等加权的去噪自编码器序列可以这样理解:
首先,去噪自编码器我们已经知道了,它就像是一个能把有噪声的数据恢复成干净数据的工具,比如你给它一张有雪花点的老照片,它能想办法把雪花点去掉,恢复出照片原来清晰的样子。
而 “等加权的去噪自编码器序列” 呢,就好像是一群这样的去噪自编码器排着队工作。想象一下有一排工人,每个工人都负责对照片做一点去噪的工作。
“等加权” 的意思是,这些工人在工作时的重要性或者说他们工作的 “力度” 都是一样的。比如说,第一个工人去掉一些噪声,第二个工人接着再去掉一些,他们在整个去噪过程中所起的作用没有谁轻谁重之分,都是平等地为了把照片变得更清晰而努力。
在扩散模型中,这个等加权的去噪自编码器序列就像是一个接力赛,每个去噪自编码器都从上一个那里接过稍微有点噪声的图像,然后再进一步去噪,直到最后得到一张几乎没有噪声的清晰图像。它们就像是一群分工明确、齐心协力的小伙伴,按照顺序,每个都出一样的力,来完成从有噪声的数据到干净数据的转换任务。
用通俗的语言解释什么是涌现能力
涌现能力是指一个系统在其组成部分相互作用的过程中,当复杂性增加到某一临界点时,出现的子系统或较小规模版本中未曾存在的行为或特性。
以人工智能领域的大语言模型为例,当模型的规模和训练参数达到一定的阈值时,模型会突然展现出一些在小规模模型中不存在的能力,比如复杂推理、数学运算、多语言翻译等,这些能力并非是训练目标中明确设计的,而是模型在学习过程中自动学会的。
例如,一个小规模的语言模型可能只能进行简单的文本生成,如生成一些简单的句子。但当模型规模大幅增加,达到千亿参数级别时,它可能就突然具备了理解复杂语义、进行逻辑推理以及根据上下文生成连贯且有深度的长篇文本的能力,就好像模型突然 “开窍” 了一样,这种能力的突然出现就是涌现能力。
再比如,一群蚂蚁个体的行为比较简单,只是进行一些觅食、搬运等基本活动,但当众多蚂蚁聚集在一起形成蚁群时,却能展现出复杂的社会结构和行为模式,如分工协作、建造复杂的蚁巢等,这也是一种涌现现象,蚁群作为一个整体展现出了单个蚂蚁所不具备的能力。
用通俗的语言解释涌现能力出现的原因
要理解涌现能力为什么会出现,不用纠结复杂公式,咱们用 “搭积木”“凑零件” 的日常逻辑就能说清楚。核心其实就一句话:当系统里的 “小部分” 足够多、连接足够密,它们之间会碰撞出 “1+1 远大于 2” 的新效果,这种新效果就是涌现 —— 不是谁设计出来的,是 “凑够量、连对路” 后自然冒出来的。
具体可以拆成 3 个通俗的角度看:
1. 先得有 “足够多的零件”:规模到了,才能 “攒出花样”
涌现的前提是 “量的积累”,就像你想拼一个复杂的乐高城堡,只给 10 块积木,最多拼个小房子;但给你 1000 块、10000 块,就能拼出带城门、吊桥、塔楼的城堡 —— 这些 “复杂结构” 在积木少的时候根本不可能有。
AI 模型的涌现也是如此:小规模模型(比如几百万、几千万参数)就像 “少积木”,只能做简单事(比如识别单个词、生成短句子);但当参数堆到几十亿、几千亿(比如千亿级大模型),相当于 “积木够多了”,突然就能做复杂推理(比如解数学题、写论文)。不是参数里藏了 “推理技能”,而是 “参数数量够了”,才能支撑更复杂的内部协作。
2. 零件得 “连对路”:混乱的连接没用,有序的互动才会生新能力
光有数量不够,还得让 “小部分” 之间能 “有效互动”。比如一群人随机乱走,最多是拥挤;但如果他们按规则组队(比如排成队列、分工协作),就能完成单人做不到的事(比如搬重物、搭帐篷)。
AI 模型里的 “参数” 就像 “人”,每个参数只负责一点点简单计算(比如判断两个词的关联度)。但大模型会通过训练,让这些参数形成 “有序的连接”—— 比如 A 参数的结果传给 B,B 再结合 C 的结果输出,无数个这样的 “小计算链条” 织成一张大网。当这张网的 “连接逻辑足够精细”,突然就会出现新功能:比如原本只能算 “词关联” 的链条,连起来后居然能 “理解逻辑关系”(比如 “因为 A 所以 B”)。
3. 得有 “对的训练目标”:给系统一个 “使劲的方向”,新能力才会往有用的方向冒
涌现不是 “瞎冒”,得有个目标引导。比如你养一盆花,给它浇水、晒太阳(目标是 “让它活”),它才会慢慢长出新叶、开花;如果不管不顾,它可能只会枯萎,不会有 “开花” 这种涌现。
AI 模型的涌现也需要 “对的训练目标”—— 比如大模型的训练目标是 “预测下一个词”(看似简单)。为了做好这件事,模型会被迫学习越来越多的 “隐藏知识”:比如要预测 “太阳从____升起”,得先学 “方位常识”;要预测 “因为下雨,所以____”,得先学 “因果逻辑”。当模型为了 “做好预测” 而学的知识足够多、关联足够密,突然就会 “举一反三”—— 比如用学过的因果逻辑去解数学题,用方位常识去回答地理问题,这些 “新能力” 其实是为了完成原始目标,无意间 “攒出来的副产品”。
总结一下:涌现能力不是 “突然开挂”,而是 “三个条件凑齐” 的自然结果 ——足够多的 “小部分”、足够有序的 “互动连接”、一个能引导学习的 “目标”。就像一堆零件,凑够数量、按规则装好、有明确用途,突然就从 “一堆铁” 变成了 “能跑的汽车”—— 汽车的 “行驶能力”,就是零件们涌现出来的新特性。
为何现在的大模型大部分是Decoder only结构?
现在的大模型大多采用 Decoder-only 结构(比如 GPT 系列、LLaMA、Mistral 等),核心原因可以用 “简单、能打、省成本” 这三个通俗的词来概括,具体来说:
1. 任务适配性强:生成任务是 “刚需”,Decoder-only 天生擅长
现在大模型最核心的应用场景是生成式任务—— 写文案、聊天、编代码、做翻译等等,本质都是 “根据前面的内容,一步步生成后面的内容”。
而 Decoder-only 结构的核心逻辑就是 “自左向右生成”(像写文章一样,从第一个字写到最后一个字,每个字只依赖前面的内容),这和生成任务的需求完美匹配。比如你让模型写一封邮件,它从 “尊敬的客户” 开始,后面的每一句话都是顺着前面的意思往下说,不需要回头 “修改”,效率很高。
相比之下,Encoder-Decoder 结构(比如早期的 T5)更适合 “先理解再生成” 的任务(比如翻译、摘要),但现在大模型追求 “全能”,既要能生成,又要能理解(比如回答问题)。而 Decoder-only 通过 “把问题当开头,直接生成答案”(比如输入 “什么是 AI?”,模型直接接 “AI 是……”),用一种模式就能兼容理解和生成任务,更灵活。
2. 结构简单:少个 “零件”,跑得更快、学得更好
Decoder-only 结构比 Encoder-Decoder 少了 “编码器” 这个模块,整个模型的逻辑更简单:所有参数都专注于 “生成” 这一件事,不用协调 “编码器理解” 和 “解码器生成” 之间的配合。
这带来两个好处:
训练效率高:少一个模块,参数能更集中地优化生成能力,同样的计算资源下,能把模型做得更大、训练得更充分。
推理速度快:生成内容时,不需要先让编码器处理一遍再传给解码器,直接 “从头生成”,响应更快(比如聊天时,回复弹出的速度更及时)。
3. 规模效应明显:参数堆得越大,能力 “涨” 得越猛
大模型的核心竞争力来自 “规模”—— 参数越多、训练数据越大,往往能力越强(尤其涌现能力)。而 Decoder-only 结构在 “堆规模” 这件事上更 “划算”:
因为它的核心是 “自回归生成”(每个词依赖前面的词),训练时可以用一种叫 “ causal masking ” 的技巧,让模型高效学习长文本的依赖关系(比如一句话里,前面的词如何影响后面的词)。这种学习方式对长文本、复杂逻辑的捕捉能力特别强,参数规模上去后,很容易涌现出推理、创作等高级能力。
而 Encoder-Decoder 结构因为要兼顾 “理解” 和 “生成”,参数分配更分散,规模扩大时,能力提升往往不如 Decoder-only 明显。
4. 工程落地容易:省钱、好部署、生态成熟
从实际应用角度看,Decoder-only 结构更 “接地气”:
硬件友好:结构简单意味着计算时内存占用更可控,大模型部署时(比如放到服务器上提供 API),成本更低。
生态成熟:GPT 系列带火了 Decoder-only 后,大量工具、框架(比如 Hugging Face、加速推理的库)都围绕这种结构优化,开发者用起来更顺手,企业也更愿意跟进。
简单说,Decoder-only 就像一个 “专精生成的全能选手”:结构简单却能打,适配性强还省钱,在大模型追求 “大而全” 的当下,自然成了主流选择。当然,Encoder-Decoder 在特定任务(比如精准翻译、长文本摘要)中仍有优势,但综合来看,Decoder-only 的性价比更高。
用通俗的语言解释Encoder的双向注意力会存在低秩问题
咱们可以用 “传话游戏” 的场景来理解这个问题:
Encoder 的双向注意力就像一群人围坐成圈玩传话 —— 每个人(代表一个词)都能听到圈里所有人说的话(所以叫 “双向”),然后综合大家的信息再往下传。理想情况下,每个人都能精准捕捉到其他人的关键信息,比如 A 说的 “天气”、B 说的 “爬山”、C 说的 “带水”,最后汇总出 “天气好适合爬山记得带水” 的完整意思。
但 “低秩问题” 就像这个游戏玩着玩着出了岔子:大家传着传着,慢慢都只关注少数几个人的话了。比如最后所有人都只听 A 和 B 的,不管 C 说什么都忽略,那汇总出来的信息就只剩 “天气好适合爬山”,漏掉了 “带水” 这个关键细节。
为什么会这样?因为双向注意力虽然理论上能 “关注所有信息”,但模型在学习时,为了省事(或者说受限于自身能力),会不自觉地把复杂的信息压缩成 “简单模式”—— 就像人记笔记时,总忍不住只记几个关键词,而不是完整句子。这样一来,原本需要 “高维度、多方面” 才能表达清楚的信息,被压缩成了 “低维度、少方面” 的简化版,就像把一张高清图存成了模糊的缩略图,细节全没了。
结果就是:双向注意力看似 “什么都能关注”,实际却可能因为信息压缩过度,只捕捉到少数核心关联,漏掉很多重要细节 —— 这就是 “低秩问题” 的通俗解释。
用通俗的语言解释为什么会出现低秩现象
要理解双向注意力为啥会出现 “低秩” 这个现象,咱们不用绕复杂公式,就从模型 “学习的本能” 和 “任务的特点” 这两个角度掰扯清楚,保证一听就懂:
先回忆下前提:双向注意力的核心是 “每个词都看所有词”,比如一句话里 “猫” 要关注 “追”“老鼠”“桌子下”,理论上能捕捉所有关联。但实际学完后,它往往只盯着少数几个 “关键关联”(比如只关注 “猫 - 追 - 老鼠”),其他关联都变模糊了 —— 这就是 “低秩”(信息维度被压缩,像高清图变模糊)。
1. 模型 “偷懒”:学简单的模式比学复杂的更省力
模型学习的本质,是在海量数据里找 “能少费劲又能答对题” 的规律。双向注意力要学 “每个词对所有词的关注权重”,这本来是个超复杂的任务(比如一句话 10 个词,要学 10×10=100 个权重关系)。
但模型会 “投机取巧”:它发现很多时候,不用学 100 个独特的权重 —— 只要抓住几个 “通用关联”(比如 “主语 - 动词 - 宾语” 的固定搭配),就能应付大部分句子。比如不管是 “猫追老鼠”“狗追兔子” 还是 “鸟捉虫子”,模型都只重点学 “第一个词(主语)→第二个词(动词)→第三个词(宾语)” 这几条关联,其他关联(比如 “猫 - 老鼠” 之外的 “猫 - 桌子下”)就随便给个差不多的权重。
这样一来,原本 100 维的复杂关联,就被压缩成了 “主语 - 动词 - 宾语” 这 3 维的简单模式 —— 维度一降,就成了 “低秩”。你可以理解成:学生做题时,发现背 3 个公式就能应付 80% 的题,就懒得去学剩下 20% 题需要的 10 个公式了。
2. 数据 “偏心”:大部分数据里,有用的关联本就不多
模型学的是训练数据里的规律,但现实中的文本数据,本身就存在 “大部分关联没用” 的情况。比如一句话 “今天天气很好,我想去公园放风筝”:
真正有价值的关联只有几个:“天气好→去公园”“去公园→放风筝”;
没用的关联占大多数:比如 “今天” 和 “风筝”、“很好” 和 “公园”,这些词之间其实没什么强联系。
模型在学的时候,会本能地 “放大有用关联,忽略无用关联”—— 毕竟把 “天气好→去公园” 学扎实,比纠结 “今天→风筝” 重要多了。但这么一来,所有词的注意力权重,最终都会向那几个 “有用关联” 集中,其他权重要么趋近于 0,要么长得差不多。
就像你记笔记时,只会把 “天气好、去公园、放风筝” 这几个关键词画重点,其他词都一笔带过 —— 最后笔记上只有几个重点词的关联,整体信息维度自然就低了,这就是 “低秩”。
3. 优化 “限制”:模型没能力学出高维度的复杂关联
就算模型想学好所有关联,它的 “学习能力” 也有限制。双向注意力的权重是靠 “矩阵计算” 学出来的,这个矩阵的 “秩”(可以理解成 “信息维度”)越高,就需要模型有越多的参数、越多的计算资源去支撑。
但实际训练时,模型的参数不是无限的,计算资源也有限 —— 就像你大脑的记忆力有限,记不住一本书里所有细节,只能记住几个核心观点。所以模型就算想学 100 维的关联,最后也只能学到其中几维,剩下的维度要么学不会,要么学混了,最后呈现出来的就是 “低秩” 的结果。
总结一下:双向注意力出现低秩,不是模型 “不想做好”,而是它会 “挑省事的学”(学简单模式)、“按数据教的学”(数据里有用关联本就少),再加上 “能力不够”(参数和计算有限)—— 三者叠加,就导致它明明能 “看所有词”,最后却只抓住了少数关联,成了 “低秩” 的样子。
用通俗的语言解释 Layer Norm
要理解 Layer Norm(层归一化),咱们先从生活里的 “标准化操作” 说起 —— 比如学校考试后算排名、食堂打菜控制分量,本质都是 “先把混乱的数据变整齐,再做后续处理”,Layer Norm 干的就是类似的事,只不过处理的是模型里的 “数据信号”。
举个具体的例子:假设模型某一层有 3 个 “信号处理器”(可以理解成 3 个负责计算的小单元),分别处理一句话里的 3 个词(比如 “猫”“追”“老鼠”)。经过一轮计算后,这 3 个处理器输出的 “信号强度” 可能相差特别大:
“猫” 的信号:100(过强,像噪音一样会盖过其他信息)
“追” 的信号:2(过弱,关键信息快被淹没了)
“老鼠” 的信号:5(强度中等)
如果直接把这种 “强弱不均” 的信号传给下一层,会有两个大问题:
下一层只会盯着 “100” 这个强信号学,忽略 “2” 和 “5” 里的有用信息,学偏了;
信号波动太大,下一层学起来很费劲,就像你每天吃的饭一会儿 10 碗、一会儿 1 口,肠胃肯定适应不了。
而 Layer Norm 的作用,就是给这些 “信号” 做一次 “标准化体检”,把它们拉到同一个 “合理区间” 里,步骤像这样:
第一步:算 “平均水平”
先算出这 3 个信号的平均值(比如 100+2+5=107,107÷3≈35.67)。这就像全班考试后,先算个平均分,知道整体水平。
第二步:算 “波动程度”
再算它们的 “标准差”(简单理解就是 “和平均值差多少” 的平均),比如这 3 个信号离 35.67 的差距很大,标准差就高。这一步是为了知道 “数据乱不乱”—— 就像有的班分数都在 80 分左右(标准差小,很整齐),有的班从 20 分到 100 分都有(标准差大,很混乱)。
第三步:“拉齐” 到标准区间
用每个信号减去 “平均值”,再除以 “标准差”,把它们变成 “围绕 0 波动、波动幅度差不多” 的新信号。比如刚才的 100、2、5,经过这一步可能变成:
“猫”:(100-35.67)÷ 标准差≈2(从超强变中等)
“追”:(2-35.67)÷ 标准差≈-1(从超弱变中等偏下)
“老鼠”:(5-35.67)÷ 标准差≈-0.8(波动变小)
这下 3 个信号都在 “-2 到 2” 的区间里,强弱均匀,不会有谁盖过谁。
第四步:留 “灵活空间”(可选但重要)
最后会加一个 “小调整”:给每个信号乘一个 “系数”(比如 1.2、0.9),再加一个 “偏移值”(比如 0.5、-0.1)。这一步是为了不让 “标准化” 太死板 —— 比如有的任务里,“追” 这个动词的信号本来就该比名词强一点,就可以通过系数把它稍微调回去,保证模型还能保留有用的 “信号差异”,而不是把所有信号都搞成完全一样的 “机器人”。
总结一下:Layer Norm 就像模型里的 “信号整理员”—— 先把某一层里杂乱无章、强弱不一的信号,通过 “算平均、算波动、拉齐区间” 变得整齐,再留一点灵活调整的空间,让下一层能更轻松、更准确地学习有用信息,避免因为信号太乱而学偏、学慢。
用通俗的语言解释RMS Norm
要理解 RMS Norm(Root Mean Square Normalization,均方根归一化),咱们可以先从它的 “亲戚” Layer Norm 说起 —— 它俩都是模型里的 “信号整理员”,核心目的都是把杂乱的信号变整齐,但 RMS Norm 走了条 “更简单的捷径”,就像 “简化版的信号整理流程”。
先回到之前 Layer Norm 的例子:假设模型某一层有 3 个信号(比如对应 “猫”“追”“老鼠”),计算后输出强度是「100、2、5」—— 强弱差距极大,下一层没法好好学。Layer Norm 的解决思路是 “先算平均、再算波动、最后拉齐”,步骤有点多;而 RMS Norm 直接跳过了 “算平均” 这一步,只抓 “波动” 来整理信号,效率更高。
咱们用同样的例子,拆解 RMS Norm 的 “简化操作”:
第一步:只算 “信号波动的平方平均”
RMS Norm 不管几个信号的 “平均强度”,直接先算每个信号 “平方后的平均值”。比如刚才的「100、2、5」:
先给每个信号平方:100²=10000,2²=4,5²=25;
再算这些平方值的平均值:(10000+4+25)÷3 ≈ 3343(这个值叫 “均方”)。
这一步的核心是 “抓住信号的‘杂乱程度’”—— 平方后的值越大,说明这个信号越 “出格”(比如 100 平方后远超 2 和 5),平均值能反映整体的波动大小。
第二步:开根号,得到 “均方根”
给刚才算的 “均方” 开个根号(比如√3343≈57.8),这个结果就叫 “均方根(RMS)”。它的作用和 Layer Norm 里的 “标准差” 类似,都是用来衡量 “信号到底有多乱”—— 数值越大,说明信号强弱差异越离谱。
第三步:用原信号除以 “均方根”,直接拉齐
把每个原信号除以这个 “均方根”,就能把所有信号拉到 “差不多的强度区间”。比如:
“猫” 的信号:100÷57.8≈1.73(从超强的 100 降到 1.7 左右);
“追” 的信号:2÷57.8≈0.035(从超弱的 2 升到 0.035);
“老鼠” 的信号:5÷57.8≈0.086(从 5 升到 0.086)。
这下原本差距 100 倍的信号,现在都缩到了 “0 到 2” 的区间里,不会有某个信号 “太抢戏”,下一层就能正常学习了。
第四步:和 Layer Norm 一样,留 “灵活调整空间”
最后同样会加一步 “系数 × 信号 + 偏移值” 的调整。比如觉得 “追” 这个动词的信号还是太弱,可以乘个系数(比如 10),让它变成 0.35,既保留了 “整理后的整齐度”,又没把有用的信号差异完全抹掉 —— 避免模型变成 “一刀切的死板机器”。
为啥 RMS Norm 要 “偷懒” 跳过 “算平均”?
其实是为了 “省力气” 和 “避坑”:
省计算成本:算 “平均” 需要多一步加法和除法,而大模型每层有上百万个信号,少一步操作就能大幅减少计算量,让模型跑得更快;
避免 “平均干扰”:在很多任务(比如翻译、对话)里,信号的 “平均强度” 其实没那么重要 —— 真正影响学习的是 “个别信号太出格”(比如 100 这种极端值)。RMS Norm 只抓 “极端值” 来修正,既解决了核心问题,又不用浪费精力在 “算平均” 上。
总结一下:RMS Norm 就像 “精简版的信号整理员”—— 它不像 Layer Norm 那样 “又算平均又算波动”,而是直接瞄准 “信号太乱” 的核心问题,只通过 “算平方平均→开根号→除以均方根” 这三步,快速把极端信号拉回正常区间,既解决了问题,又省了计算力,所以现在很多大模型(比如 LLaMA)都喜欢用它。
用通俗的语言解释Deep Norm
Deep Norm 是一种用于深度学习的归一化技术,主要是为了解决超深层神经网络训练时的稳定性问题。
我们可以把神经网络想象成一个生产流水线,每一层就像是流水线上的一个工作站。在这个过程中,数据就像原材料,从一个工作站传到下一个工作站。而 Layer Norm 就像是在每个工作站对原材料进行一次标准化处理,让它们的规格保持一致,这样下一个工作站就能更好地处理这些原材料。
Deep Norm 则是在 Layer Norm 的基础上做了一些改进。它主要做了两件事:
第一件事是在残差连接前乘以一个系数 α,来缩放输入特征。可以把残差连接想象成一条 “快速通道”,数据除了正常经过工作站处理外,还可以通过这条快速通道直接传递到下一层。而乘以系数 α 就像是给通过快速通道的数据 “放大” 或 “缩小” 一些,这样可以让信号的强度保持在一个合适的范围。比如,如果数据信号太弱,乘以一个大于 1 的 α,就可以把信号放大,让下一层更容易捕捉到有用的信息;如果信号太强,乘以一个小于 1 的 α,就可以把信号缩小,避免它 “淹没” 了其他信息。
第二件事是在 Xavier 初始化时,对部分参数乘以 β,以减小初始化范围。初始化就像是给每个工作站的 “工作人员”(参数)设定一个初始的工作状态。如果初始状态设置得不好,“工作人员” 可能会手忙脚乱,导致整个流水线运行不稳定。而 Deep Norm 通过乘以 β,让参数的初始值范围变小,就像是给 “工作人员” 一个更明确的初始工作指引,让他们能更稳定地开始工作,从而避免了梯度爆炸等问题,让模型训练更加稳定。
简单来说,Deep Norm 就是通过这两个巧妙的调整,让超深层的神经网络在训练时能够更稳定地处理数据,就像给流水线的运行加了一层 “稳定器”,使得模型可以堆叠到上千层,同时还能保持较好的性能。
用通俗的语言解释ffn
要理解 FFN(Feed-Forward Network,前馈神经网络),咱们可以先把它类比成 “工厂里的加工流水线”—— 它的核心作用就是 “把收到的原材料(数据信号),按固定流程加工成更有用的样子,再传给下一个环节”。而且它有个关键特点:信号只往前传,不回头(“前馈” 就是这个意思),就像流水线里的零件只会从第一道工序流到最后一道,不会倒着走。
咱们用一个具体场景拆解 FFN 的 “加工流程”,比如让模型判断一句话里的 “猫” 是不是动物:
第一步:接收 “原材料”(输入层)
FFN 的第一步会收到一堆 “原始信号”,就像流水线刚收到的零件。比如判断 “猫是动物吗” 时,输入可能是:
表示 “猫” 的词向量(一串数字,比如 [0.8, 0.2, 0.1]);
表示 “是” 的词向量(比如 [0.3, 0.9, 0.4]);
表示 “动物” 的词向量(比如 [0.7, 0.1, 0.6])。
这些 “数字串” 就是 FFN 要处理的 “原材料”,它们会被汇总成一个 “总信号”(比如把三个向量拼起来,变成更长的数字串),传给下一个环节。
第二步:“放大 + 筛选” 有用信息(隐藏层)
这是 FFN 的核心,就像流水线里的 “核心加工工序”—— 它要做两件关键的事:先把有用的信息 “放大”,再把没用的信息 “过滤掉”。
具体怎么做呢?分两步:
先 “放大” 信号维度:
比如输入的 “总信号” 是 100 个数字(维度 100),FFN 会用一个 “权重矩阵”(可以理解成 “放大镜”)把它变成 400 个数字(维度 400)。这么做的目的是 “给信息更多空间”—— 比如 “猫” 这个信号里,可能藏着 “有毛、会叫、哺乳动物” 这些细节,维度放大后,这些细节能被更清晰地拆分开。再 “筛选” 有用信息:
放大维度后,信号里可能混了很多没用的 “噪音”(比如 “猫的颜色” 对判断 “是不是动物” 没用)。这时候就要用一个 “激活函数”(相当于 “筛选器”),把有用的信号留下、没用的压掉。
比如常用的 ReLU 激活函数,就像 “一刀切”:凡是小于 0 的数字(没用的噪音)全变成 0,大于 0 的数字(有用的信息)保留原样。这样一来,“有毛、哺乳动物” 这些有用信号就被留下了,“颜色、大小” 这些噪音就被过滤掉了。
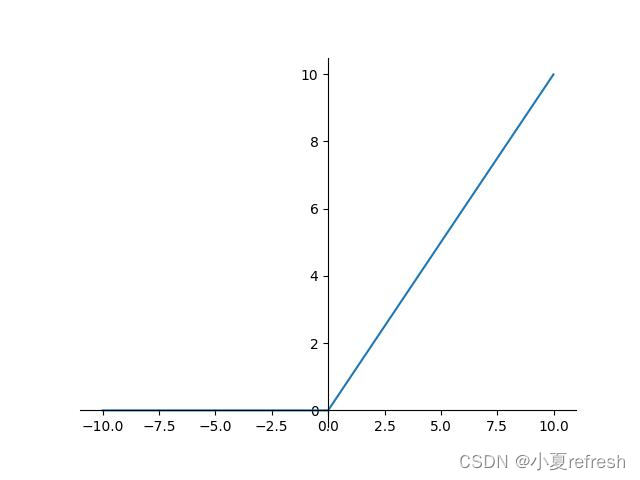
而且,FFN 可以有好几层这样的 “隐藏层”—— 比如先把 100 维放大到 400 维、筛选一次,再放大到 200 维、再筛选一次,就像流水线里 “多道工序反复加工”,把信息磨得更精细。
第三步:输出 “成品”(输出层)
经过几轮隐藏层的 “加工” 后,FFN 最后会把信号 “压缩回目标维度”,输出一个 “明确结果”,就像流水线最后产出的 “成品”。
比如判断 “猫是动物吗”,输出层会把前面加工好的 200 维信号,再通过一个权重矩阵压缩成 2 个数字(对应 “是” 和 “不是”),比如输出 [0.95, 0.05]—— 这就表示模型认为 “猫是动物” 的概率是 95%,“不是” 的概率是 5%,完成了最终判断。
FFN 的两个关键特点(帮你更懂它)
“前馈” 不回头:信号从 “输入层→隐藏层→输出层” 一路往前,不会像 RNN(循环神经网络)那样 “回头看之前的信号”。比如判断 “猫是动物” 时,FFN 只处理当下这三个词的信号,不会去回忆 “上一句话里有没有提到狗”—— 这既是它的简单之处,也是它的局限(所以后来才会和注意力机制结合,弥补这个问题)。
“通用” 的加工器:不管是处理文字、图片还是声音,FFN 的核心逻辑都一样 ——“接收信号→放大筛选→输出结果”。比如处理图片时,输入换成 “像素点的数字信号”,隐藏层照样放大、筛选,最后输出 “是猫还是狗” 的结果。
一句话总结
FFN 就像一个 “单向的、多工序加工流水线”:把收到的 “数字信号”(原材料),通过 “放大维度→筛选噪音” 的反复加工,最后输出一个 “明确结果”(成品)。它本身不 “记东西”(不回头看),但胜在简单、高效,是深度学习里最基础、最常用的 “信息加工模块”—— 比如 Transformer 模型里,每个注意力层后面都会接一个 FFN,用来进一步细化注意力挑出来的有用信息。
用通俗的语言解释GELU
![]()
要理解 GELU(Gaussian Error Linear Unit),咱们可以先把它类比成 **“更聪明的信息筛选器”**—— 它的核心作用和之前说的 ReLU 类似(都是从一堆信号里挑有用的留下),但比 ReLU “更细腻”,不会像 ReLU 那样 “一刀切”,而是能根据信号的 “重要程度” 灵活调整筛选力度。
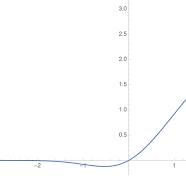
先回顾下 ReLU 的 “简单粗暴”:比如有个信号数值是 0.3,ReLU 会直接留下它;如果是 - 0.2,ReLU 会直接把它变成 0(相当于 “完全扔掉”)。但 GELU 不这么干 —— 它会想:“这个信号到底有多大概率是‘有用的’?概率高就多留一点,概率低就少留一点,不轻易把信号完全扔掉。”
用 “学生答题” 类比 GELU 的逻辑
咱们拿模型处理文字信号举个例子:比如模型在分析 “猫会爬树” 这句话,其中有个信号是 “猫有爪子”(对应数值是 0.5),另一个信号是 “猫喜欢吃鱼”(对应数值是 - 0.1)。GELU 会怎么筛选这两个信号呢?
它会先做一件事:给每个信号算一个 “有用概率”—— 这个概率不是瞎猜的,而是参考 “正态分布”(可以理解成 “常见情况统计规律”):
信号数值越大(比如 0.5),说明它和 “猫会爬树” 的关联性越强,“有用概率” 就越高(比如算出来是 70%);
信号数值越小(比如 - 0.1),关联性越弱,“有用概率” 就越低(比如算出来是 45%)。
然后,GELU 会用 “信号本身的数值 × 它的有用概率”,来决定最终留下多少信息:
对于 “猫有爪子”(0.5 × 70% = 0.35):留下 0.35 的信号(因为有用概率高,所以多留);
对于 “猫喜欢吃鱼”(-0.1 × 45% = -0.045):只留下 - 0.045 的信号(因为有用概率低,所以少留,但没有完全扔掉)。
为什么 GELU 比 ReLU “更聪明”?
ReLU 的问题是 “太绝对”:只要信号是负数,就完全扔掉(变成 0),但很多时候,“不太有用” 的信号(比如 - 0.1)也可能藏着一点点关键信息(比如 “猫喜欢吃鱼” 虽然和 “爬树” 关联弱,但能辅助确认 “这是一只真实的猫”)。
而 GELU 的优势就在于 **“留有余地”**:
对正数信号:数值越大,留下的比例越高(有用的信息多保留);
对负数信号:数值不是特别小(比如 - 0.1、-0.2)时,不会完全扔掉,而是留下一小部分(避免漏掉潜在有用的细节);只有数值特别小(比如 - 2、-3)时,才会几乎留不下(确实是没用的噪音)。
一句话总结
GELU 就像一个 “会权衡的筛选员”:面对一堆信号,它不会像 ReLU 那样 “好的全留、坏的全扔”,而是先判断每个信号的 “有用概率”,再按概率比例留下信息 —— 既保证有用信号不丢失,也不轻易浪费掉 “可能有点用” 的小细节,所以在 Transformer 这类复杂模型里,比 ReLU 表现更稳定。