Linux——线程(1)线程概念与控制
线程?这个名字我们似乎有些眼熟?没错,我们之前提到过的进程和这个有点像。但进程和线程有什么关系呢?本系列我们讲从线程的概念出发,了解一下Linux中的线程以及线程和进程的关系等内容。
一、线程的概念
线程是一个执行流,执行力度比进程要更加细,是进程内部的一个执行分支,是进程中实际运作单位。也就是说,一个进程可以有多个线程,那么操作系统如果要支持线程,就必须对当前的线程进行管理!——先描述再组织。进程对应的我们有PCB,线程我们有TCB。
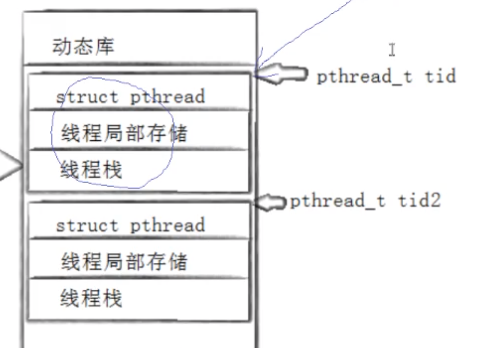
但是我们一想,一个进程有一个PCB,但同时会有多个tcb,一个task_struct要连接这么多的结构,是不是有些太麻烦了?因此,操作系统直接把pcb看成是tcb,也就是说,当我们的进程创建线程时与进程的task_struct共享一份地址空间,然后把代码区分成若干份分别指向不同的线程执行。
也就是说,线程是靠进程模拟实现的。我们把图片左侧的task_struct和红框部分的线程统一称为执行流,其中一个执行流我们称线程,只有task_struct+地址空间+页表称为进程。我们之前的进程系列的进程也算是进程,只不过只有一个执行分支。(线程)在Linux中,我们把执行流统一称为轻量级进程(LWP)。
二、线程的基本模拟

上图是线程创建的接口(稍后会对参数进行解释)
以下是演示代码
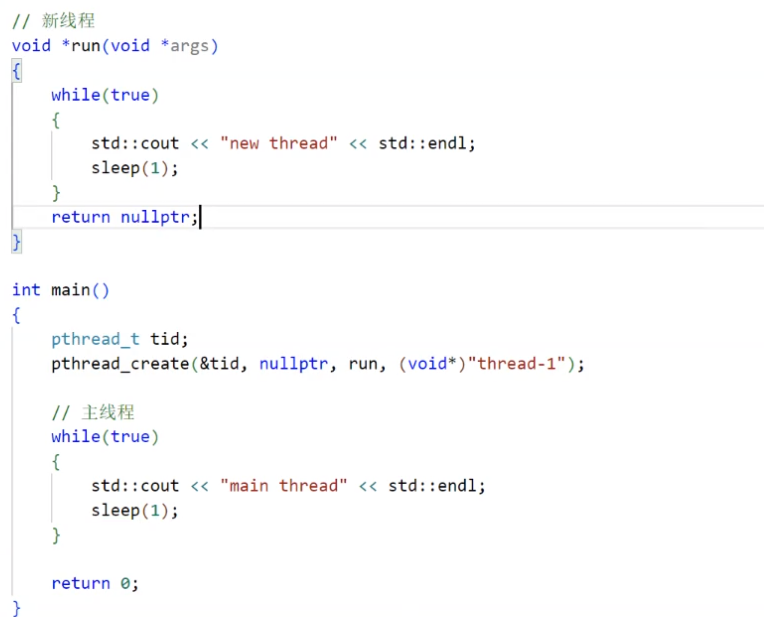
执行流程是,创建了新线程后,之前的执行流会继续向下执行,而新创建的执行流会去执行上面的run函数。但我们编译后发现居然发生了链接报错。
其实,pthread_create并不是一个系统调用,而是glibc封装的一个原生线程库,解决这个问题我们只需要在编译选项后加 -lpthread即可
![]()
运行结果也的确像我们说的

我们通过get两个线程的pid发现与进程的pid相同,也说明了来自于同一个进程
除此之外,我们也可以查询线程的状态,进程的状态我们说过用 ps axj | grep processname
查询线程的状态:
ps -aL | grep processname

在众多的执行流中,pid与LWP相同的是主线程。
我们讲过,线程没必要再创建一个tcb,只要和进程共享一个pcb即可,那么也就不需要给线程执行的代码开辟额外空间,只需要把要执行的函数起始地址交给某执行流即可(函数还是在pcb内)
三、进程与线程
进程是资源分配的基本单位,而线程是调度的基本单位
此外,线程虽然共享进程的数据,但也拥有自己的一部分数据,比如线程id,上下文,调度优先级等。
在文件方面,同一进程的多个线程是共享的,也就是说如果一个线程打开了某个文件,那么其他线程也能看到该文件的内容。包括信号的处理方式等。
在一个进程中,如果有一个线程发生了崩溃,那么整个进程也将崩溃。
与进程之间的切换相比,线程之间的切换需要操作系统做的工作要少很多。线程的切换虚拟内存空间依然是相同的,但是进程切换是不同的。
另外⼀个隐藏的损耗是上下文的切换会扰乱处理器的缓存机制。简单的说,⼀旦去切换上下文,处理器中所有已经缓存的内存地址一瞬间都作废了。还有⼀个显著的区别是当你改变虚拟内存空间的时候,处理的页表缓冲 TLB (快表)会被全部刷新,这将导致内存的访问在⼀ 段时间内相当的低效。但是在线程的切换中,不会出现这个问题,当然还有硬件cache。cache位于CPU用于记录当前位置的附近的数据(也是缓存)。
四、关于虚拟地址与页表的补充
1.虚拟地址和页表的由来
如果没有这两个的分配内存机制,试想一下,我们每一个用户在使用内存时在空间上必定是连续的

因为每个程序的代码的数据大小不同,所以对应所占的空间大小不同,因此,物理内存会被分成若干个大小不同的块(如上图),导致相同的数据类型放在不同的各个区域。此时如果有些程序要推出的话,所占的内存就会被回收,导致这些内存被碎片化。
我们希望改变这种现状,但又不想改变用户使用空间连续的习惯(即用户的空间可以连续但物理内存不要连续),所以才有了虚拟地址空间和页表
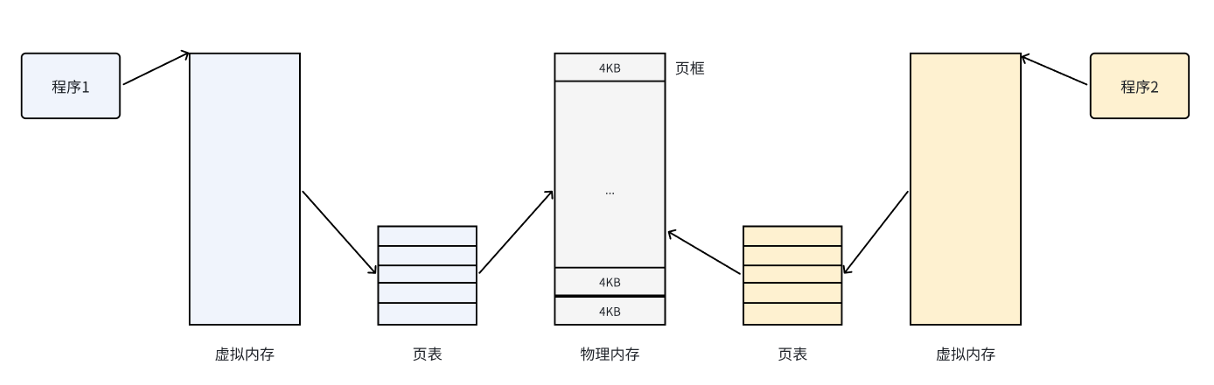
图中有一个名词:页框,其本意就是把物理内存按照固定大小进行分隔的块,最常见的是4KB,而每个页框中存放一个页,大小就是一个页框的大小。(页是数据块,页框是一个存储区域)。这种机制就保证了CPU并非直接访问物理内存,而是通过虚拟地址来间接访问,也就是通过页表,页表上记录了页与页框的对应关系。
2.物理内存的管理
现在我们知道了,一大块物理内存被分割成无数的页(数据块),我们假设每个大小是4KB,假设整个内存是4GB,那么就要有4GB/4KB=100w+个页框。这么多个页框的内存,OS必定要管理,那么就会有对应的结构体来描述组织。而在结构内部我们发现我们发现有类似与数组下标的结构struct page *mem_map[N],可以大胆猜测,虽然物理内存被分割成无数块,但实际上他们还是连续的,那么我们就可以把每一个页框标记一个数组下标,整个内存就是一个巨大的数组,要想找到对应的内存,页表内只需记录映射到内存的下标就可以了!
3.页表的真实面目
目前我们对页表的了解,也就只知道它可以帮助我们映射到物理内存,但其内部还存放着其他信息。
我们之前了解的页表结构并不严谨,试想一下,如果把4GB的物理内存分成若干个4KB的块,然后把虚拟地址的每一块(每个地址是4字节)都记录在内形成映射关系以及对应的物理内存,那么单看页表的大小就要达到16GB左右了,这显然是不合理的。
其实,从虚拟地址到物理地址的转化并不只有页表,还有一个页目录,页目录中有1024个页目录表项,而每个表项对应着一个页表,然后每个页表中有1024个页表项,每个页表项指向物理地址的每一块起始地址,(所有页表的大小就是1024*1024*4=4MB),这样我们用4MB大小就可以映射到整个物理内存了
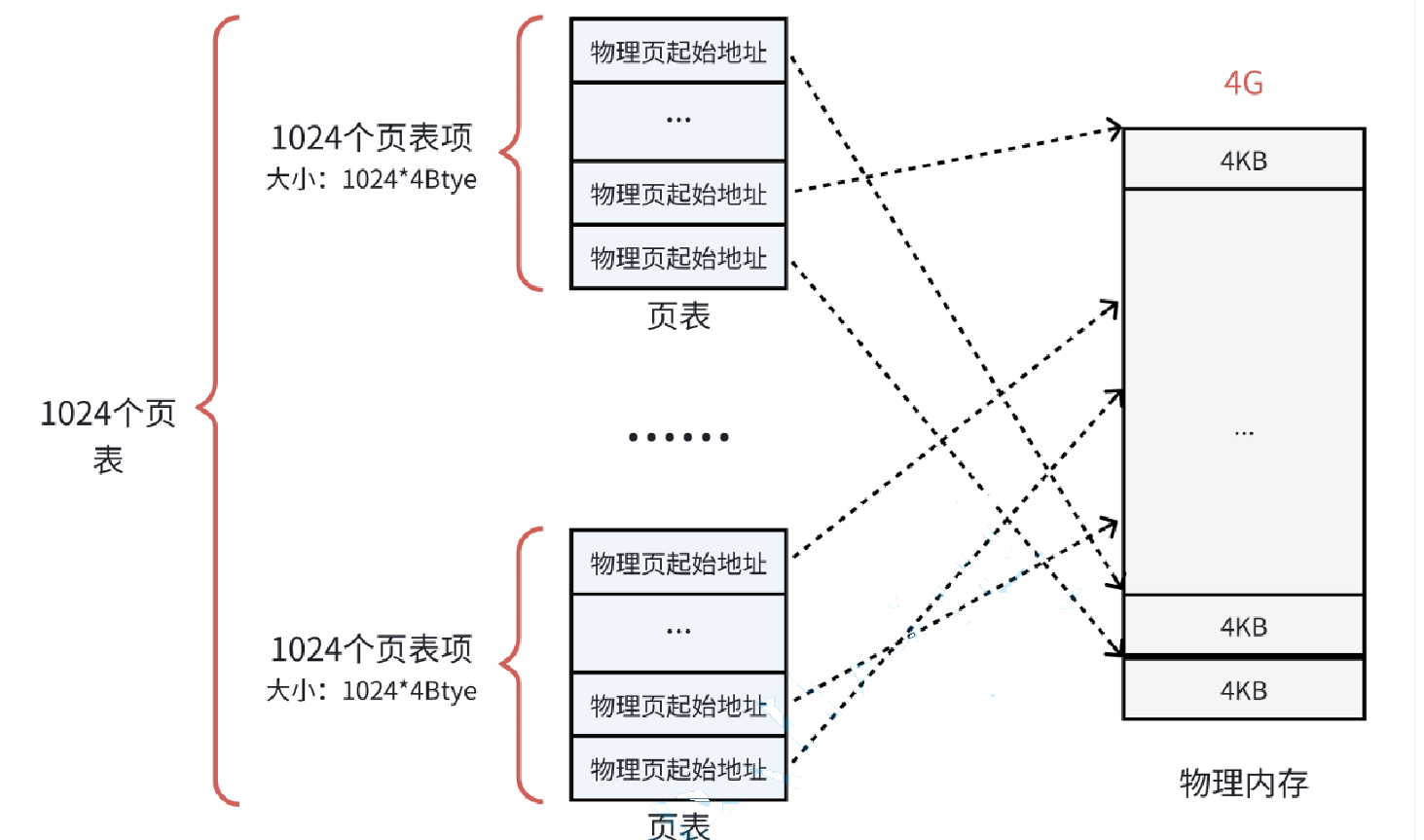
这里的每⼀个表,就是真正的页表,所以⼀共有 1024 个页表。⼀个页表自身占用 4KB,那么1024个页表就占用4MB的物理内存空间,和之前没差别啊?那么 从总数上看是这样,但是⼀个应用程序是不可能完全使用全部的4GB空间的,也许只要几十个页表就 可以了。例如:一个用户程序的代码段、数据段、栈段,⼀共就需要 10 MB 的空间,那么使用 3 个页表就足够了。 计算过程: 每⼀个页表项指向⼀个4KB的物理页,那么⼀个页表中1024个页表项,⼀共能覆盖4MB的物理内存; 那么10MB的程序,向上对齐取整之后(4MB的倍数,就是12MB),就需要3个页表就可以了。
把1024个页表管理起来的就是页目录,每个页目录表项的大小也是4字节。
4.虚拟地址如何转化为物理地址
我们的虚拟地址,一般是由32个比特位组成的,代表要访问某一个字节的地址(不是块的地址),我们把前10个比特位去查页目录表项(1024个,拿下标去查找到对应的页表),再拿次10位在对应的页表下找对应的页表项,然后我们就找到了页框的起始地址。而剩下的12位就是偏移量,利用偏移量就能找到该块中的某一个字节(2的12次就是4096,每个块是4kb*1024=4096字节)。
这个转化过程是MMU硬件完成的(CPU中)。然后再通过CR3寄存器查表找到对应的物理地址。
多级页表给我提供了便利的同时也引入了新的问题——查找次数增多导致效率降低,需要提升效率。在CPU中,还真有一个东西帮助我们——TLB,MMU在查页表前先问问TLB有没有,如果有就直接拿到物理地址,但没有的话就只能查表,然后把地址缓存到TLB方便下次查询,TLB的本质就是缓存。
5.缺页中断
我们的页表中记录的地址其实还记录了有关地址权限的相关信息(RW),假设现在有一个只读的地址,我此时进行写操作,此时MMU在查询地址时就发现不对,就会把错误告诉CPU发生软中断进行错误处理。同时,我们的数据并不用同时加载到内存里,其实一次加载一定部分就可以,等要执行下面的内容再进行加载(也说明了页表虽多但不都用)。
五、线程的控制
1.接口介绍
(1)pthread_create
上面提到过,这并不是系统调用而是一个库,是用户级别的线程库。
参数 :
thread: 返回线程 ID (输出型)
attr: 设置线程的属性, attr 为 NULL 表示使用默认属性
start_routine: 是个函数地址,线程启动后要执行的函数
arg: 传给线程启动函数的参数
arg参数可以是任意类型(变量,数字,对象等)
成功返回0,失败返回错误码。
(2)pthread_self
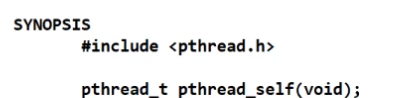
用于获取tid,哪个线程调用就获取哪个tid。
我们也可以同时多个线程执行同一个函数,但如果不加保护的情况下,会发生数据错乱(类似于多态??)此外,进程内的函数,全局变量,线程也是共享的。
(3)线程等待——pthread_join

等待哪个线程就输入哪个LWP,至于第二个参数,是一个二级指针(输出型),原理和进程类似,只要等待线程不退出,主线程就会阻塞等待。(返回值等于0等待成功)
第二个参数一般用于接收线程执行的函数返回值,既然是一个二级指针,我们就需要用一个void*的变量地址传参。

![]()
相当于把10写进了ret。(我们要把return的值强转位void*)
(4) 线程终止
exit():其实在此并不常用,因为exit放在任何位置,只要触发就表示进程退出,所以如果只想让某一线程退出就不能使用这个。用pthread_exit。
 等价于return。
等价于return。
还有一种退出方法
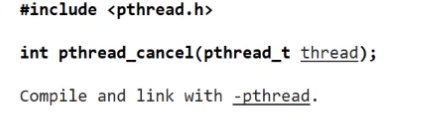
线程可以被取消
2.线程分离
当主线程正在做某些事情时,某个线程要退出,就需要阻塞等待,但如果我们要让主线程做自己的 事情不用等待呢?——把目标线程进行分离(joined:默认要等待,detach:分离态)
接口:pthread_detach(pthread_t thread)
用法通俗易懂,有一点,线程把自己分离需要传的是pthread_self()。一般要分离的线程是我不关心线程的返回值,不需要去等待,等线程退出自动释放资源。
六、关于线程ID
获取线程id可以用接口也可以用输出型参数带出,我们发现线程ID都是很大的一串数字,我们把其转成16进制就是这样的:
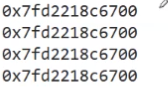
有点眼熟?好像地址啊,的确就是地址!那线程的ID为什么要是地址呢,这个地址的意义在哪里?
我们知道,一个带线程的可执行程序是要第三方库线程库支持的,那么当程序执行时库也要加载(加载到内存空间的共享区以让task_struct看见)。
但对于Linux,没有线程这个概念,只有统一的LWP,用户要用线程,但系统只有创建LWP的接口,库中给我们提供相关线程的接口,同时我们也要获取线程的相关信息(id,优先级等),这就需要库中给我们维护,当我们创建一个线程就可以填充相关属性。用库进行封装,我们就可以避开系统调用,直接去库找就可以了。
库中的每一个线程的tcb可以看成是数组存放