MySQL 高可用方案之 MHA 架构搭建与实践
MySQL 高可用方案之 MHA 架构搭建与实践
在 MySQL 数据库的高可用方案中,MHA(Master HA)是一款备受青睐的开源工具,它能为 MySQL 主从复制架构提供自动化的主节点故障转移功能。本文将详细介绍 MHA 的架构原理、搭建过程以及故障切换机制,帮助读者快速掌握这一高可用方案的实现。
MHA 架构核心解析
MHA 由 Manager 和 Node 两种角色构成,共同协作实现 MySQL 集群的高可用保障。
Manager 节点作为管理中枢,可部署在独立服务器或某个从节点上,负责定时探测主节点状态。当主节点出现故障时,它能自动筛选出拥有最新数据的从节点并将其提升为新主,同时协调其他从节点重新指向新主,整个过程通常可在 30 秒内完成。
Node 节点则需要部署在每台 MySQL 服务器上,主要负责数据同步和故障切换时的具体操作执行。
MHA 的工作流程基于一主多从架构(至少需要 1 主 2 从共 3 台数据库服务器),通过以下步骤实现高可用:
- 持续监控主节点健康状态
- 主节点故障时筛选最优从节点(数据最新)
- 提升该从节点为新主节点
- 调整其他从节点同步至新主
- 实现虚拟 IP(VIP)自动漂移,保证应用透明接入
环境准备与基础配置
本次实验环境采用 4 台服务器,具体配置如下:
| 角色 | IP 地址 | 操作系统版本/数据库版本 | 说明 |
|---|---|---|---|
| mha-manager | 192.168.2.199 | rhel7.9/mysql8.0.40 | manager控制器 |
| master | 192.168.2.200 | rhel7.9/mysql8.0.40 | 数据库主服务器 |
| rep1 | 192.168.2.201 | rhel7.9/mysql8.0 | 数据库从服务器 |
| rep2 | 192.168.2.202 | rhel7.9/mysql8.0 | 数据库从服务器 |
数据库节点配置
主节点(master)配置:
[root@master ~]# cat /etc/my.cnf
[mysqld]
datadir=/data/mysql
socket=/data/mysql/mysql.sock
server_id=200 # 集群内唯一ID
gtid-mode=on # 启用GTID
enforce-gtid-consistency=true # 强制GTID一致性
log-bin=binlog # 开启二进制日志
relay-log=relay-log # 开启中继日志
relay_log_purge=0 # 禁止自动清理中继日志
log-slave-updates=true # 从节点更新记入二进制日志
#删除注释
sed -i 's/#.*//' /etc/my.cnf
从节点(rep1/rep2)配置:
与主节点类似,主要区别在于server_id需分别设置为 201 和 202,确保集群内唯一。
主从复制配置
在主节点创建复制账号:
mysql> create user 'rep'@'%' identified WITH mysql_native_password by '123';
mysql> grant replication slave on *.* to 'rep'@'%';
在从节点配置主从同步:
mysql> CHANGE REPLICATION SOURCE TO
SOURCE_HOST='192.168.2.200',
SOURCE_USER='rep',
SOURCE_PASSWORD='123',
master_auto_position=1,
SOURCE_SSL=1;
mysql> start replica;
验证复制状态:
mysql> show replica status \G
# 确保Replica_IO_Running和Replica_SQL_Running均为Yes
MHA 组件部署
安装包准备
MHA 需要在 Manager 节点安装 manager 和 node 组件,在数据库节点仅需安装 node 组件。可从 GitHub 获取安装包:
- manager:https://github.com/yoshinorim/mha4mysql-manager/releases/tag/v0.58
- node:https://github.com/yoshinorim/mha4mysql-node/releases/tag/v0.58
部署步骤
- 在 Manager 节点安装所有组件:
[root@mha-manager MHA-7]# yum localinstall ./*.rpm
- 所有主机上配置自解析域名
[root@mha-manager MHA-7]# cat /etc/hosts
192.168.2.200 master
192.168.2.201 rep1
192.168.2.202 rep2
192.168.2.199 mha-manager
- 在数据库节点安装 node 组件:
# 复制安装包到各数据库节点
[root@manager ~]# for i in {master,rep1,rep2};do scp mha4mysql-node-0.58-0.el7.centos.noarch.rpm root@$i:/root;done# 在各数据库节点执行安装
[root@master ~]# yum localinstall mha4mysql-node-0.58-0.el7.centos.noarch.rpm
-
配置 SSH 互信:
MHA 集群中各节点(Manager 与所有数据库节点、数据库节点之间)需要通过 SSH 无密码登录实现互信,核心原理是通过公钥认证机制:
- 每个节点生成一对 SSH 密钥(公钥
id_rsa.pub和私钥id_rsa) - 将所有节点的公钥汇总到同一个
authorized_keys文件 - 把该文件分发到所有节点的
~/.ssh/目录下
或者将 Manager 节点的公私钥都分发给三个数据库节点(master、rep1、rep2)(不安全)的方式。通过这两种方式,节点间 SSH 连接时无需输入密码,MHA Manager 可远程执行命令完成故障检测与切换。
实现方式一:Manager 节点公私钥分发
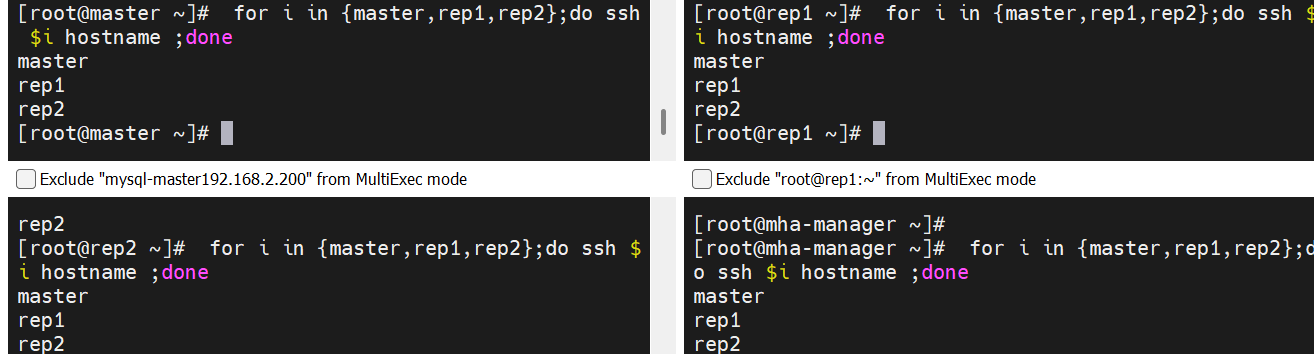
# 1. 所有节点生成密钥对(无需交互,直接生成) ssh-keygen -f /root/.ssh/id_rsa -P '' -q# 2. Manager节点向所有数据库节点分发公钥 for i in {master,rep1,rep2} ;do ssh-copy-id root@$i;done# 3. Manager节点向所有数据库节点分发私钥 for i in {master,rep1,rep2} ;do scp /root/.ssh/id_rsa root@$i:/root/.ssh;done# 4. 验证互信(所有节点应能无密码登录其他节点) for i in {master,rep1,rep2};do ssh root@$i hostname ;done实现方式二:批量分发公钥(适用于节点较多场景)
原理:在 Manager 节点汇总所有节点的公钥,生成统一的
authorized_keys文件,再分发到所有节点,实现全集群互信。# 1. 所有节点生成密钥对(同上) ssh-keygen -f /root/.ssh/id_rsa -P '' -q# 2. 在Manager节点创建统一的authorized_keys touch /root/.ssh/authorized_keys chmod 600 /root/.ssh/authorized_keys# 3. 收集所有节点的公钥到Manager的authorized_keys for node in master rep1 rep2; dossh root@$node "cat /root/.ssh/id_rsa.pub" >> /root/.ssh/authorized_keys done# 4. 将统一的authorized_keys分发到所有节点 for node in master rep1 rep2; doscp /root/.ssh/authorized_keys root@$node:/root/.ssh/ssh root@$node "chmod 600 /root/.ssh/authorized_keys" # 确保权限正确 done# 5. 验证互信 for i in {master,rep1,rep2};do ssh root@$i hostname ;done - 每个节点生成一对 SSH 密钥(公钥
 创建 MHA 管理用户:
创建 MHA 管理用户:
mysql> create user 'mhaadm'@'%' identified WITH mysql_native_password by '123';
mysql> grant all on *.* to 'mhaadm'@'%';
MHA 集群配置
创建配置文件
在 Manager 节点创建配置目录和应用配置文件:
[root@mha-manager ~]# mkdir -p /etc/mha /var/log/mha/app1
[root@mha-manager ~]# vim /etc/mha/app1.cnf
[server default]
user=mhaadm
password=123
manager_workdir=/var/log/mha/app1
manager_log=/var/log/mha/app1/manager.log
ssh_user=root
repl_user=rep
repl_password=123
ping_interval=1
[server1]
hostname=192.168.2.200
ssh_port=22
candidate_master=1 # 可作为候选主节点
[server2]
hostname=192.168.2.201
ssh_port=22
candidate_master=1
[server3]
hostname=192.168.2.202
ssh_port=22
no_master=1 # 不可作为主节点
配置验证
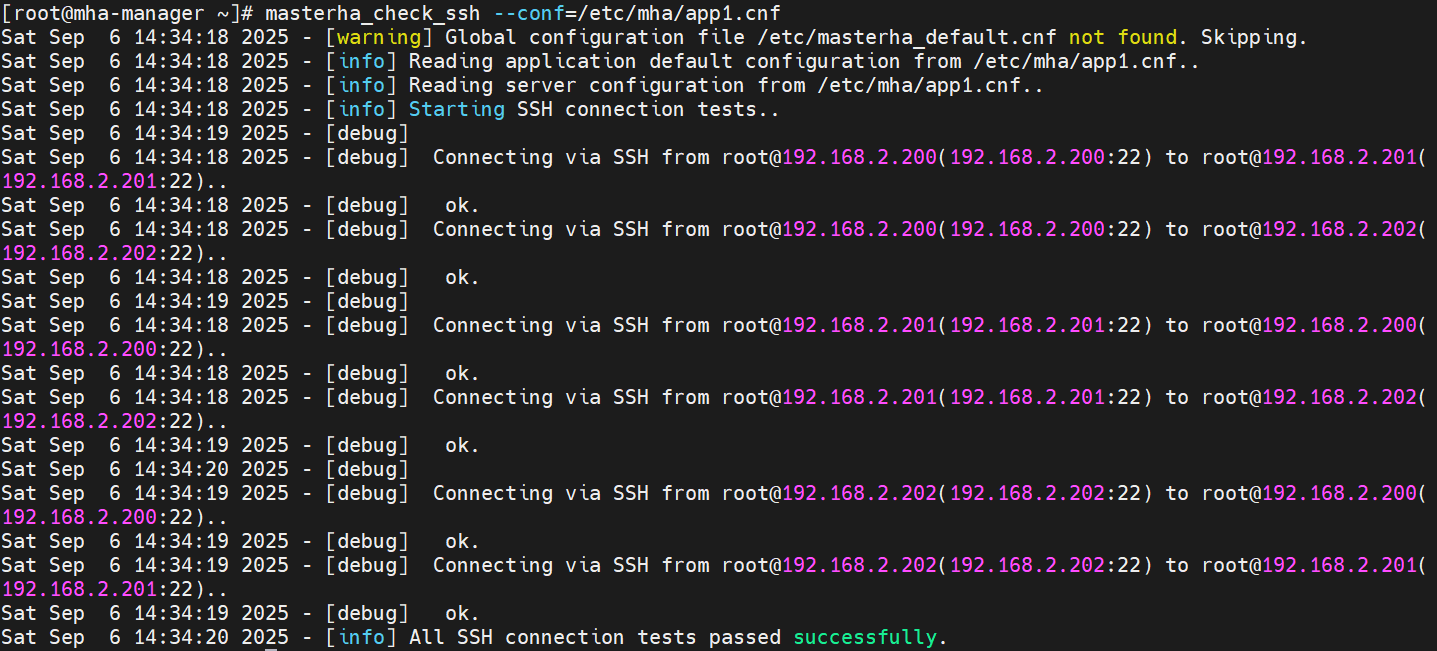
检查 SSH 互信配置:
[root@mha-manager ~]# masterha_check_ssh --conf=/etc/mha/app1.cnf
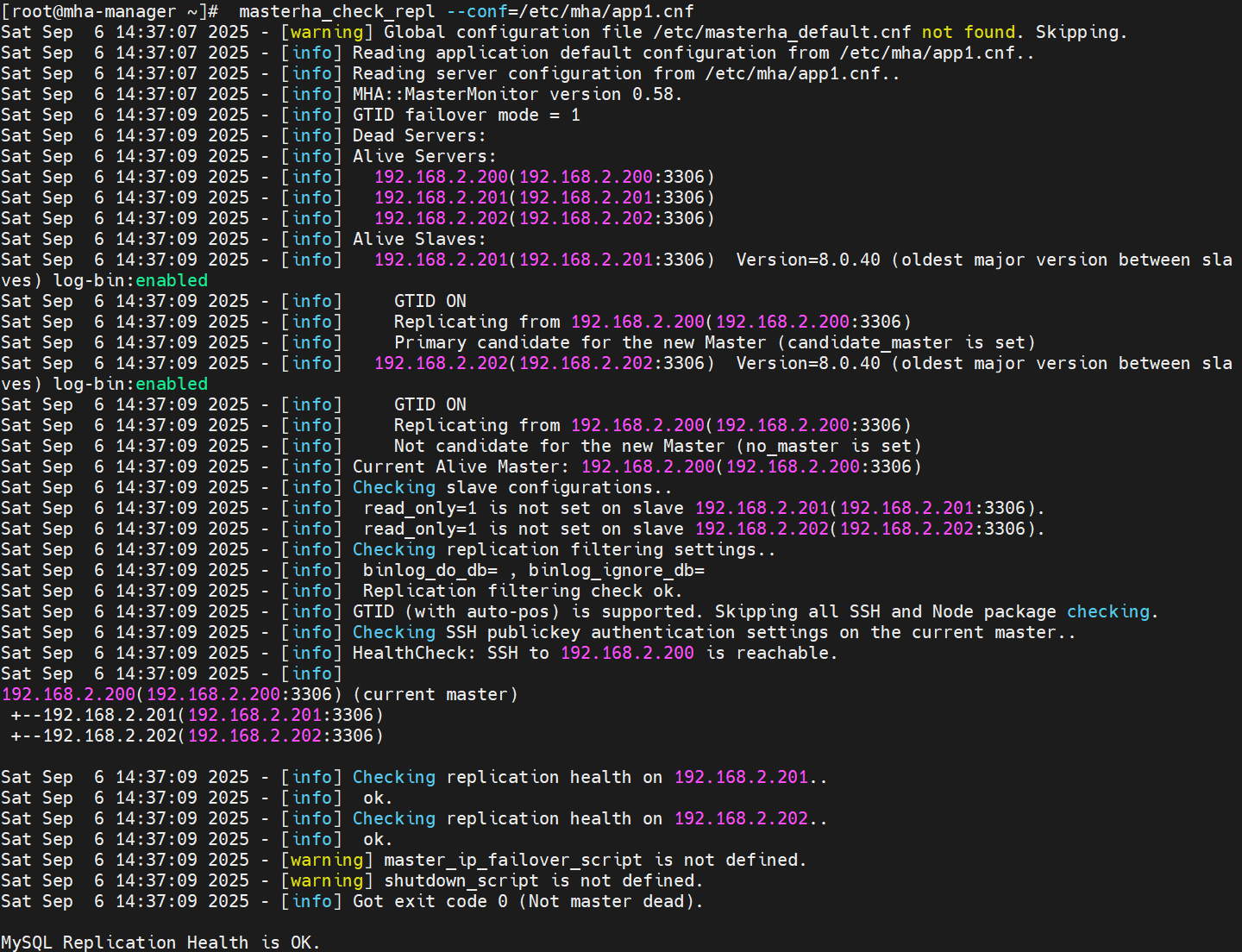
检查主从复制配置:
[root@mha-manager ~]# masterha_check_repl --conf=/etc/mha/app1.cnf
故障切换实战
手动故障切换
模拟主节点故障:
[root@master ~]# /etc/init.d/mysqld stop
执行故障切换:
[root@mha-manager ~]# masterha_master_switch --master_state=dead \
--conf=/etc/mha/app1.cnf \
--dead_master_host=192.168.2.200 \
--dead_master_port=3306 \
--new_master_host=192.168.2.201 \
--new_master_port=3306 \
--ignore_last_failover
自动故障切换
启动 MHA Manager 监控:
[root@mha-manager ~]# masterha_manager --conf=/etc/mha/app1.cnf
模拟主节点故障后,MHA 会自动完成故障转移,过程可通过日志查看:
[root@mha-manager ~]# cat /var/log/mha/app1/manager.log
故障节点恢复后,需将其重新加入集群作为从节点:
mysql> CHANGE REPLICATION SOURCE TO
SOURCE_HOST='新主节点IP',
SOURCE_USER='rep',
SOURCE_PASSWORD='123',
master_auto_position=1,
SOURCE_SSL=1;
mysql> start replica;
VIP 配置实现
为实现故障切换时的 IP 透明切换,需配置虚拟 IP(VIP)自动漂移。
编写 VIP 切换脚本
[root@mha-manager ~]# vim /usr/local/bin/master_ip_failover
#!/usr/bin/env perl
use strict;
use warnings FATAL => 'all';
use Getopt::Long;
my ($command, $ssh_user, $orig_master_host, $orig_master_ip,$orig_master_port, $new_master_host, $new_master_ip, $new_master_port
);
#注意此处配置的ip地址和网卡名称
my $vip = '192.168.2.88/24';
my $ssh_start_vip = "/sbin/ip a add $vip dev ens32";
my $ssh_stop_vip = "/sbin/ip a del $vip dev ens32";GetOptions('command=s' => \$command,'ssh_user=s' => \$ssh_user,'orig_master_host=s' => \$orig_master_host,'orig_master_ip=s' => \$orig_master_ip,'orig_master_port=i' => \$orig_master_port,'new_master_host=s' => \$new_master_host,'new_master_ip=s' => \$new_master_ip,'new_master_port=i' => \$new_master_port,
);exit &main();sub main {print "\n\nIN SCRIPT TEST====$ssh_stop_vip==$ssh_start_vip===\n\n";if ( $command eq "stop" || $command eq "stopssh" ) {my $exit_code = 1;eval {print "Disabling the VIP on old master: $orig_master_host \n";&stop_vip();$exit_code = 0;};if ($@) {warn "Got Error: $@\n";exit $exit_code;}exit $exit_code;}elsif ( $command eq "start" ) {my $exit_code = 10;eval {print "Enabling the VIP - $vip on the new master - $new_master_host
\n";&start_vip();$exit_code = 0;};if ($@) {warn $@;exit $exit_code;}exit $exit_code;}elsif ( $command eq "status" ) {print "Checking the Status of the script.. OK \n";exit 0;}else {&usage();exit 1;}
}
sub start_vip() {`ssh $ssh_user\@$new_master_host \" $ssh_start_vip \"`;
}
sub stop_vip() {return 0 unless ($ssh_user);`ssh $ssh_user\@$orig_master_host \" $ssh_stop_vip \"`;
}
sub usage {print "Usage: master_ip_failover --command=start|stop|stopssh|status --orig_master_host=host --orig_master_ip=ip --orig_master_port=port --new_master_host=host --new_master_ip=ip --new_master_port=port\n";
}[root@mha-manager ~]# chmod +x /usr/local/bin/master_ip_failover
配置文件集成
在 MHA 配置文件中添加脚本路径:
[root@mha-manager ~]# vim /etc/mha/app1.cnf
[server default]
# 新增配置
master_ip_failover_script=/usr/local/bin/master_ip_failover
初始 VIP 设置
在主节点手动配置初始 VIP:
[root@master ~]# ip a add 192.168.2.88/24 dev ens32
在mha-manager上启动MHA
[root@mha-manager ~]# masterha_manager --conf=/etc/mha/app1.cnf --ignore_last_failover
在master节点关闭mysql服务模拟主节点数据崩溃。
[root@master mysql]# /etc/init.d/mysqld stop
模拟主节点故障后,MHA Manager 会迅速检测到这一异常并触发故障转移流程。整个过程中,MHA 会自动完成新主节点(如 rep1)的选举,并通过预设的 VIP 切换脚本,将原本绑定在 master 上的 192.168.2.88 虚拟 IP 迁移到新主节点 rep1 上。待故障转移完成后,我们在 mha-manager 节点尝试通过虚拟 IP 连接 MySQL 数据库,
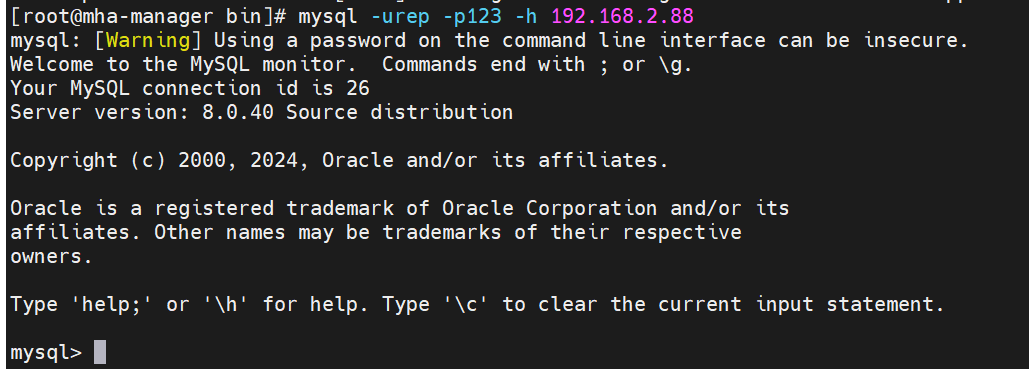
在rep1上查看VIP
[root@rep1 ~]# ip a show ens32
2: ens32: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP group default qlen 1000link/ether 00:0c:29:ad:4b:30 brd ff:ff:ff:ff:ff:ffinet 192.168.2.201/24 brd 192.168.2.255 scope global noprefixroute ens32valid_lft forever preferred_lft foreverinet 192.168.2.88/24 scope global secondary ens32valid_lft forever preferred_lft foreverinet6 fe80::80ca:7198:ade7:bea9/64 scope link noprefixroutevalid_lft forever preferred_lft forever
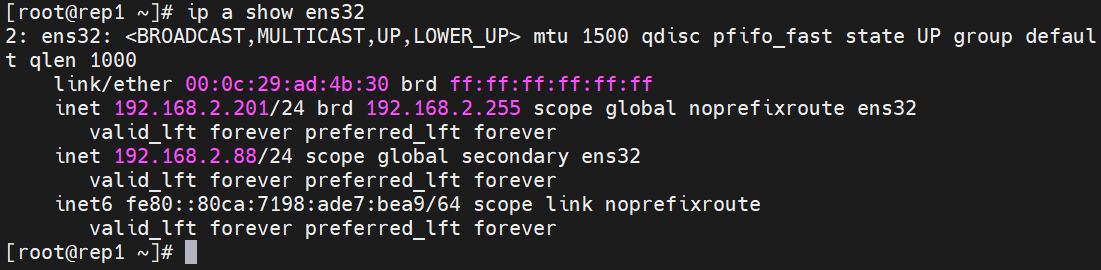
完成以上配置后,当主节点发生故障时,VIP 会自动漂移到新主节点,确保应用程序无需修改连接地址即可继续访问。MHA 通过故障转移脚本实现的高可用设计。其本质是在主从切换过程中,通过自动化脚本完成虚拟 IP 的迁移,确保应用访问地址不变,从而实现服务的无缝切换。
总结
MHA 作为成熟的 MySQL 高可用方案,通过自动化的故障检测和切换机制,能够有效保障数据库服务的连续性。其部署过程虽涉及多个节点的协同配置,但按照本文步骤逐步实施,即可顺利完成搭建。在实际生产环境中,还需结合监控告警、定期演练等措施,进一步提升架构的可靠性。