Kafka核心原理与常见面试问题解析
这是一个关于 Kafka 核心原理和常见面试问题的全面总结。无论是准备面试还是深入理解 Kafka,这份指南都会对你非常有帮助。
第一部分:Kafka 核心原理
1. Kafka 是什么?
Kafka 是一个分布式、高性能、高可用、可扩展的流处理平台。它主要有三大核心功能:
-
消息系统(Messaging System): 作为发布-订阅模型的消息队列,解耦生产者和消费者。
-
流存储(Stream Storage): 以高容错、持久化的方式存储流式数据。
-
流处理(Stream Processing): 通过 Kafka Streams API 实时处理流数据。
2. 核心概念
-
Producer(生产者): 向 Kafka 主题发布消息的客户端。
-
Consumer(消费者): 从 Kafka 主题订阅并消费消息的客户端。
-
Consumer Group(消费者组): 由多个消费者实例组成的逻辑组,用于实现主题的并行消费和容错。一个分区只能被同一个消费者组内的一个消费者消费,但可以被多个不同的消费者组消费。
-
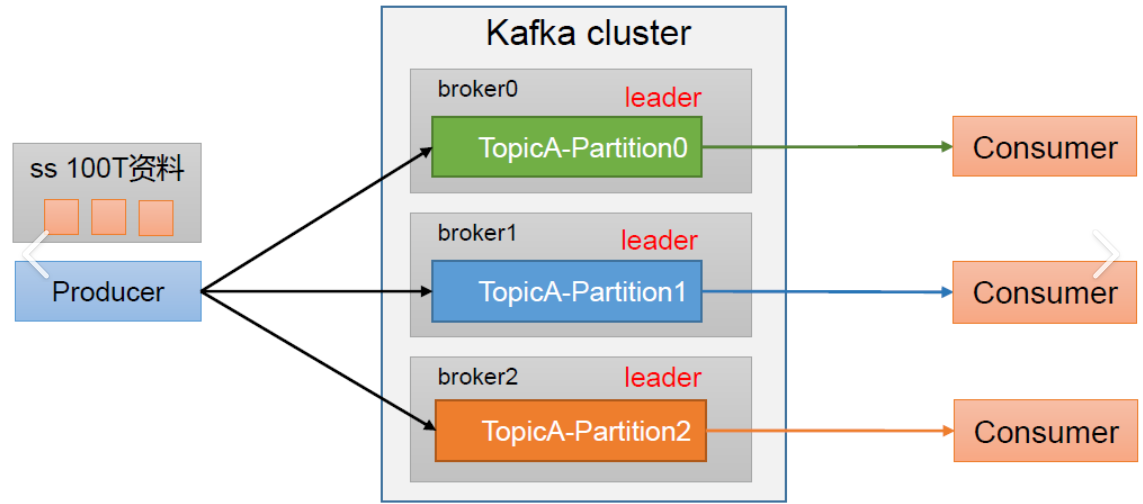
Broker: 一个独立的 Kafka 服务器节点,多个 Broker 组成一个 Kafka 集群。
-
Topic(主题): 消息的类别或名称,生产者向指定 Topic 发送消息,消费者从指定 Topic 消费消息。
-
Partition(分区): 为了实现水平扩展和高吞吐,一个 Topic 可以被分成多个 Partition。每个 Partition 是一个有序、不可变的消息序列。
-
Replica(副本): 每个 Partition 可以有多个副本(Replica),用于提供数据冗余和高可用。副本分为:
-
Leader Replica: 负责处理所有客户端的读写请求。
-
Follower Replica: 被动地从 Leader 复制数据,不与客户端交互。如果 Leader 宕机,其中一个 Follower 会被选举为新的 Leader。
-
-
Offset(偏移量): 消息在 Partition 中的唯一标识,是一个单调递增的整数。消费者通过管理其消费的 Offset 来跟踪消费进度。
-
ZooKeeper: 在 Kafka 旧版本中(
< 2.8.0),ZooKeeper 负责管理集群元数据、Broker 注册、Leader 选举、消费者组偏移量等。Kafka 2.8.0+ 版本引入了 KRaft 模式,可以完全摆脱 ZooKeeper,使用内部共识协议进行元数据管理。
3. 核心架构与工作流程
-
生产者发布消息:
-
生产者将消息发送到指定的 Topic。
-
消息通过
Partitioner被分配到某个具体的 Partition。默认策略是:如果指定了 Key,则对 Key 进行哈希;如果未指定 Key,则采用轮询(Round-Robin)。 -
生产者可以配置不同的消息确认(acks) 模式(
acks=0,acks=1,acks=all)来权衡吞吐量和数据可靠性。
-
-
Broker 存储消息:
-
消息以顺序追加(Append-Only) 的方式写入 Partition 的日志文件(Log Segment)。顺序磁盘 I/O 的速度甚至超过随机内存 I/O,这是 Kafka 高吞吐的关键。
-
消息不会在消费后被删除,而是根据配置的保留策略(基于时间或日志大小)被清理。
-
-
消费者消费消息:
-
消费者以 Consumer Group 的形式工作。
-
每个 Consumer 会被分配消费一个或多个 Partition。
-
消费者通过定期提交 Offset 来记录消费位置。Offset 可以存储在 ZooKeeper(旧)或 Kafka 内部的
__consumer_offsets主题(新)中。
-
4. 保证高可用和高可靠的核心机制
-
副本(Replication)机制:
-
每个 Partition 的多个副本分布在不同 Broker 上。
-
Leader 负责读写,Follower 从 Leader 异步(默认)或同步地拉取数据进行复制。
-
-
ISR(In-Sync Replica)同步副本集合:
-
这是与 Leader 保持“同步”的副本(包括 Leader 自己)的列表。
-
一个 Follower 是否在 ISR 中,取决于它是否在
replica.lag.time.max.ms时间内与 Leader 保持同步。 -
当 Leader 失效时,只会从 ISR 列表中选举新的 Leader,从而避免数据丢失。
-
-
生产者确认机制(acks):
-
acks=0: 生产者不等待任何确认,吞吐量最高,但可能丢失数据。 -
acks=1: 生产者等待 Leader 成功写入本地日志即确认。如果 Leader 在 Follower 复制前宕机,仍可能丢失数据。 -
acks=all(或acks=-1): 生产者等待 Leader 和所有 ISR 中的 Follower 都成功复制消息后才确认。这是最可靠的模式,但延迟最高。
-
第二部分:常见面试问题与解答
1. Kafka 为什么这么快 / 高吞吐?
这是一个必问题。核心原因在于其架构设计对操作系统和磁盘的极致利用。
-
顺序磁盘 I/O: 消息追加写入,避免了磁盘寻址的开销。
-
Page Cache: 利用操作系统页缓存而不是 JVM 内存,避免了对象开销和 GC 压力,同时利用了操作系统的文件预读和写聚合功能。
-
零拷贝(Zero-Copy): 使用
sendfile系统调用,数据直接从磁盘文件通过 DMA 拷贝到网卡缓冲区,避免了在用户空间和内核空间之间的多次上下文切换和数据拷贝。 -
批处理(Batching): 生产者和消费者都支持批量处理消息,减少了网络 I/O 次数。
-
数据压缩: 生产者可将消息批量压缩,减少网络和磁盘 I/O。
-
分区并行处理: Topic 分区机制实现了生产和消费的并行化。
2. 如何保证消息不丢失?
这是一个“端到端”的可靠性问题,需要从三个角色看:
-
生产者端:
-
设置
acks=all或-1,确保消息被所有 ISR 副本确认。 -
设置
retries为一个较大的值,并启用重试(注意可能带来的消息重复)。
-
-
Broker 端:
-
设置
unclean.leader.election.enable = false,防止非 ISR 中的副本(落后太多的副本)成为 Leader,导致数据丢失。 -
设置
replication.factor >= 3,确保每个分区有足够副本。 -
设置
min.insync.replicas > 1(例如 2),保证最少需要多少个 ISR 副本才能正常工作。与acks=all配合,如果 ISR 副本数少于这个值,生产者会收到异常,从而知道系统不可靠。
-
-
消费者端:
-
关闭自动提交 Offset(
enable.auto.commit=false),改为在消息处理完成后手动提交 Offset。避免消息还没处理完就提交了 Offset,导致消费者崩溃时消息丢失。
-
3. 如何保证消息不被重复消费(幂等性)?
消息重复通常由生产者的重试机制和消费者的 Offset 管理导致。
-
生产者幂等(Idempotent Producer):
-
开启
enable.idempotence=true。Kafka 会为每个生产者会话和每个分区分配一个 PID 和序列号(Sequence Number),Broker 会据此对消息去重,避免因重试导致的Broker 端消息重复。
-
-
事务(Transaction):
-
用于实现“精确一次(Exactly-Once)”语义,跨多个分区和生产者会话的原子性写入。常用于 Kafka Streams。
-
-
消费者端幂等:
-
生产者幂等和事务无法解决消费者端重复消费(例如:消息处理完后,提交 Offset 前消费者崩溃了,重启后会再次消费)。
-
解决方案是业务层面实现幂等。例如,为每条消息生成一个唯一 ID,在数据库中处理前先检查该 ID 是否已存在。
-
4. 如何保证消息的顺序性?
Kafka 只保证在单个 Partition 内消息是有序的。
-
全局有序: 设置 Topic 只有一个 Partition(不推荐,牺牲了扩展性)。
-
局部有序: 如果需要某个 Key(如订单ID)相关的消息有序,则在生产时指定这个 Key。由于同一个 Key 的消息会被发送到同一个 Partition,从而保证了这些消息的顺序。消费者也按分区顺序消费即可。
5. 什么是 Rebalance?它有什么影响?
-
是什么: 当消费者组内消费者数量发生变化(增、减)、或 Topic 的分区数发生变化时,Kafka 会重新分配分区给消费者的过程。
-
影响: 非常昂贵。在 Rebalance 期间,所有消费者都会停止工作(Stop-The-World),直到分配完成。频繁的 Rebalance 会严重影响消费性能。
-
如何避免:
-
小心处理消费者的会话超时(session.timeout.ms) 和心跳超时(heartbeat.interval.ms) 参数,避免因网络波动导致的心跳超时被误认为消费者宕机。
-
使用 Kafka 提供的 ** Cooperative Sticky Assignor** 分配策略,可以减少 Rebalance 的影响范围。
-
6. Kafka 中 ZooKeeper 的作用是什么?KRaft 又是什么?
-
ZooKeeper 的作用(旧版本):
-
管理 Broker 元数据(Broker 列表、Topic、Partition 信息)。
-
进行 Leader Partition 的选举。
-
管理消费者组的 Offset(旧方式)和 Group 成员关系。
-
-
KRaft:
-
Kafka 2.8.0 版本开始引入,3.0 版本正式生产可用。它用 Kafka 自身的 Raft 共识协议取代了 ZooKeeper 来管理元数据。
-
优点: 简化了部署架构(无需再维护 ZooKeeper 集群)、提升了性能、增强了集群的稳定性和可扩展性(元数据管理不再受 ZooKeeper 容量限制)。
-
7. Lag(滞后)是什么意思?
指消费者当前已提交的 Offset 与 Partition 最新消息的 Offset 之间的差值。Lag 越大,说明消费者落后生产者越多。监控 Consumer Lag 是评估消费者健康状况的关键指标。
8. 如何解决消息积压(Lag 过大)问题?
-
紧急扩容: 增加 Topic 的分区数,并同时增加消费者组内的消费者实例数(消费者数不能超过分区数)。
-
提升消费者吞吐能力:
-
优化消费者代码处理逻辑,提高单条消息处理速度。
-
增加消费者批量拉取消息的大小(
fetch.max.bytes)和条数(max.poll.records)。 -
使用多线程异步处理消息(需注意 Offset 提交的时机)。
-
-
源头限流: 如果积压无法快速解决,可以协调暂时降低生产者的发送速率。
希望这份详细的总结能帮助你彻底理解 Kafka 并从容应对面试!