JavaEE---7.文件操作和IO
目录
一、文件操作
1.1 认识文件
1.2 树形结构组织(N叉树)和目录
1.3 文件路径(path)
1.4 其他知识
1.5 Java中操作文件
二、文件内容的读写——数据流
InputStream
1.InputStream.read()
2.InputStream.read(buffer)
3.InputStream.read(byte[] buffer,int off,int len)
以OutputSteam
1.OutputSteam.write()
2.OutputStream.read(buffer)
3.OutputSream.read(byte[] buffer,int off,int len)
Reader
1.reader.read()
2.reader.read(buffer)
Writer
1.writer.write()
2.writer.write(buffer)
作为scanner的参数
三、练习
1.通过关键字再指定路径中删除(查找(递归遍历)+删除)
2.文件的复制
3.查询指定路径下的文件内部是否存在关键词(遍历打开非目录文件+将非目录文件下的所有字符全部字符串拼接,并且最后查看是否含有该关键字)
一、文件操作
1.1 认识文件
狭义上的文件(file)针对硬盘这种持久化存储的I/O设备,当我们想要进行数据保存的时候,往往不是保存成一个整体,而是独立成一个个的单位进行保存,这个独立的单位就被抽象成文件的概念。
广义上,硬件设备,软件资源都是属于文件。
文件除了有数据内容之外,还有一部分信息,例如文件名、文件类型、文件大小等并不作为文件的数据而存在,我们把这部分信息视为文件的元信息。
机械硬盘:擅长顺序读写,不擅长随机读写
固态硬盘:擅长随机读写,不擅长顺序读写,速度约是机械硬盘的十倍
1.2 树形结构组织(N叉树)和目录
文件越来越多,对于文件的组织按照层级结构进行组织---就是数据结构中所学过的树形结构。一种专门用来存放管理信息的特殊文件,就是我们平时称的文件夹(folder)或者目录(directory)。
1.3 文件路径(path)
定位文件需要一个路径,从树形结构的角度来看树中的每一个节点都可以被一条从根开始移植达到的节点的路径锁描述,这种描述方式被称为绝对路径。
除了从根开始进行路径的描述,我们可以从任意节点处罚,进行路径的描述,而这种的描述方法就被称为相对路径。相对于当前所在节点的一条路径。
路径中存在路径分隔符,也就是/",绝大多数系统的路径分隔符是'/',而windows是路径用的是反斜杠'\'
![]()
但是使用“C:/Users/Administrator/Desktop”这一串去定位也能定位到
可见windows不仅支持反斜杠作为路径分隔符,也支持斜杠作为路径分隔符
1.4 其他知识
即使是普通的文件,根据其保存的数据不同,也经常被分为不同的类型,我们一般简单的划分为文本文件(内部是二进制文件,但是可以在字符集码表上查到对应的字符,编码后的文本)和二进制文件(码表上查不到),分别指代保存被字符集编码的文本和按照标准格式保存的非被字符集编码过的文件。
Windows操作系统上,会按照文件名的后缀来确定文件类型以及该类型文件的默认打开程序。但这个习俗并不是同用的,在OSX、Unix、Linux等操作系统上,就没有这样的习惯,一般不对文件类型做出如此精确的分类。
文件由于被操作系统管理,所有根据不同的用户,会赋予用户不同的对待该文件的权限,一般地可以认为有可读、可写、可执行权限。
Windows操作系统上还有一类文件比较特殊,就是平时看到的快捷方式,这种文件就是对真是文件的一种引用。其他的操作系统也有类似的概念,比如软链接等。
最后很多操作系统为了实现接口的统一性,将所有的I/O设备都抽象成了文件的概念,使用这一理念最知名的就是Unix、Linux操作系统------万物皆可为文件
1.5 Java中操作文件
此处主要涉及文件的元信息,路径的操作,暂时不会涉及文件中内容的读写操作
Java中通过java.io.File 这个类来对一个文件(包括目录)进行抽象的描述,注意:有File对象并不代表真实存在该文件
先来看看File的属性,构造方法和方法
属性
| 修饰符及类型 | 属性 | 说明 |
| static String | pathSeparator | 依赖于系统的路径分隔符,String类型的表示 |
| static Char | pathSeparator | 依赖于系统的路径分隔符,Char类型的表示 |
构造方法
| 签名 | 说明 |
| File(File parent,String child) | 根据父目录+孩子文件路径,创建一个新的File实例 |
| File(String pathname) | 根据文件路径创建出一个新的File实例,路径可以是绝对路径或者是相对路径 |
| File(String parent,String child) | 根据父目录+孩子文件路径,创建一个新的File实例,父目录用路径表示 |
方法
| 修饰符及返回值类型 | 方法签名 | 说明 |
| String | getParent() | 返回File对象的父目录文件路径 |
| String | getName() | 返回File对象的纯文件名称 |
| String | getPath() | 返回File对象的文件路径 |
| String | getAbsolutePath() | 返回File对象的绝对路径 |
| String | getCanonicalPath() | 返回File对象的修饰过的绝对路径 |
| boolean | exists() | 判断File对象描述的文件是否真实存在 |
| boolean | isDirectory() | 判断File对象代表的文件是否是一个目录 |
| boolean | isFile | 判断File对象代表的文件是否是一个普通文件 |
| boolean | createNewFile() | 根据File对象,自动创建一个空文件,成功创建后返回true;创建失败有两个可能性:1.空间满了 2.权限不够 |
| boolean | delete() | 根据File对象,删除该文件,成功删除后返回true;删除失败有两个可能性: 1.路径错误 2.权限不够 |
| void | deleteOnmExit() | 根据File对象,标注文件将被删除,删除动作会到JVM运行结束时才会进行(进程结束)。意义:构造临时文件 |
| String[] | list() | 返回File对象代表的目录下的所有文件名 |
| File[] | listFiles() | 返回File对象代表的目录下的所有文件,以File对象表示 |
| boolean | mkdir() | 创建File对象代表的目录 |
| boolean | mkdirs() | 创建File对象代表的目录,如果必要回创建中间目录 |
| boolean | renameTo(File dest) | 进行文件的改名,也可以视为我们平时的剪切粘贴操作 |
| boolean | canRead() | 判断用户是否对文件有可读权限 |
| boolean | canWrite() | 判断用户是否对文件有可写权限 |
示例一:
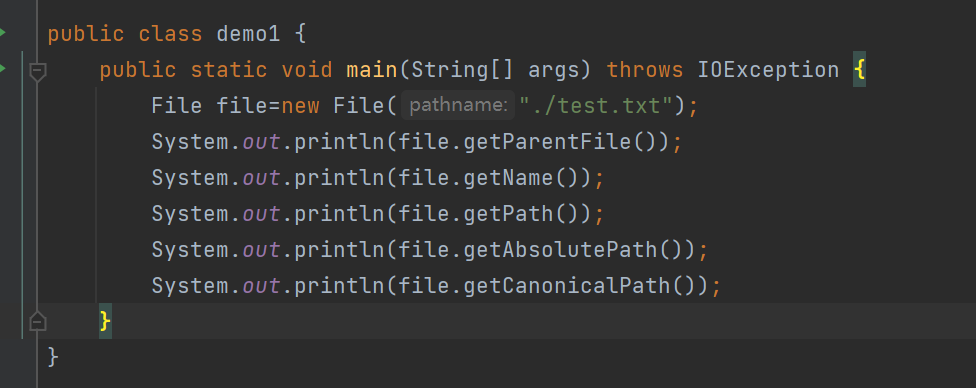

相对路径的基准是以当前IDEA的项目下
示例二
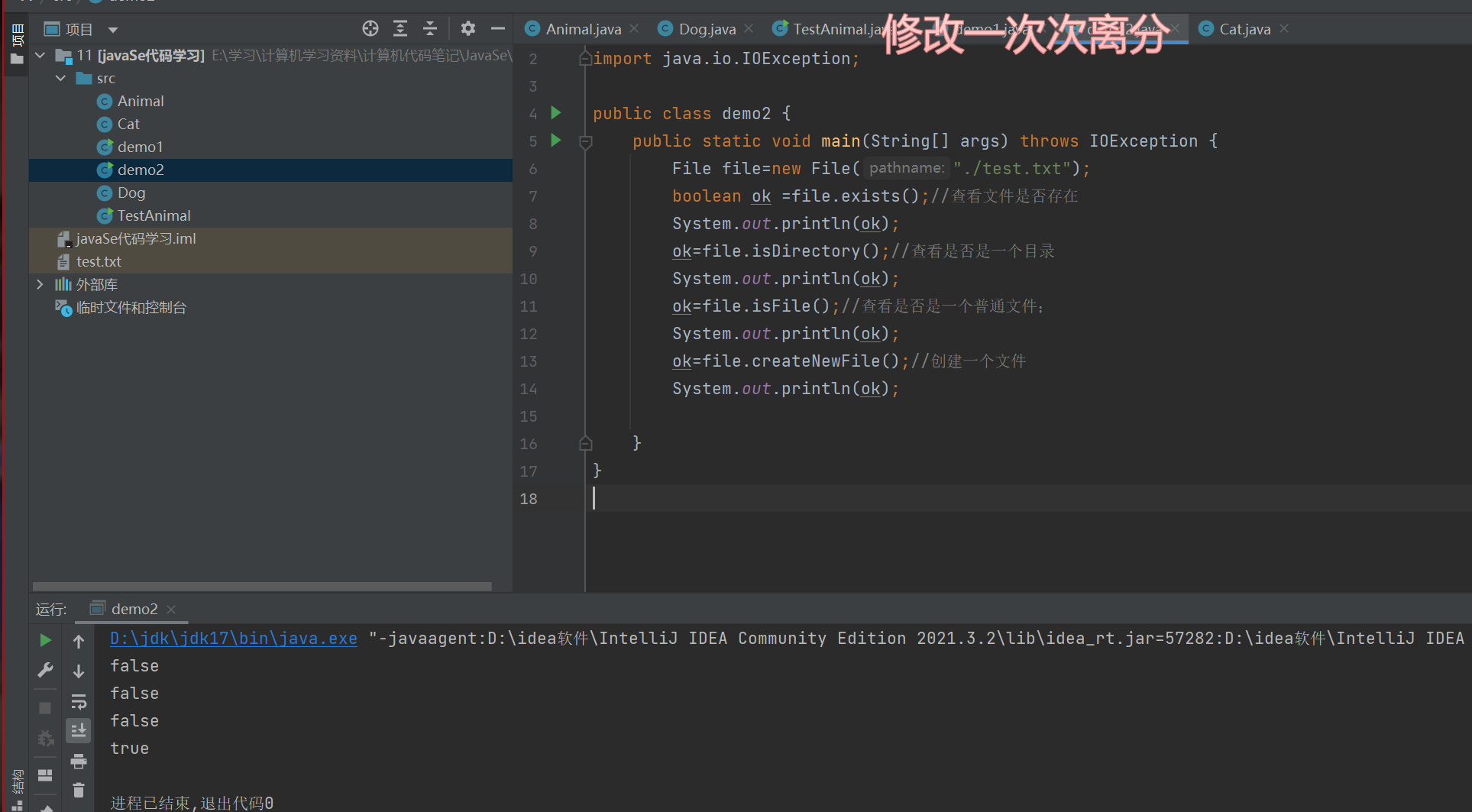
可在创建后,项目中确实出现了test.txt
示例三
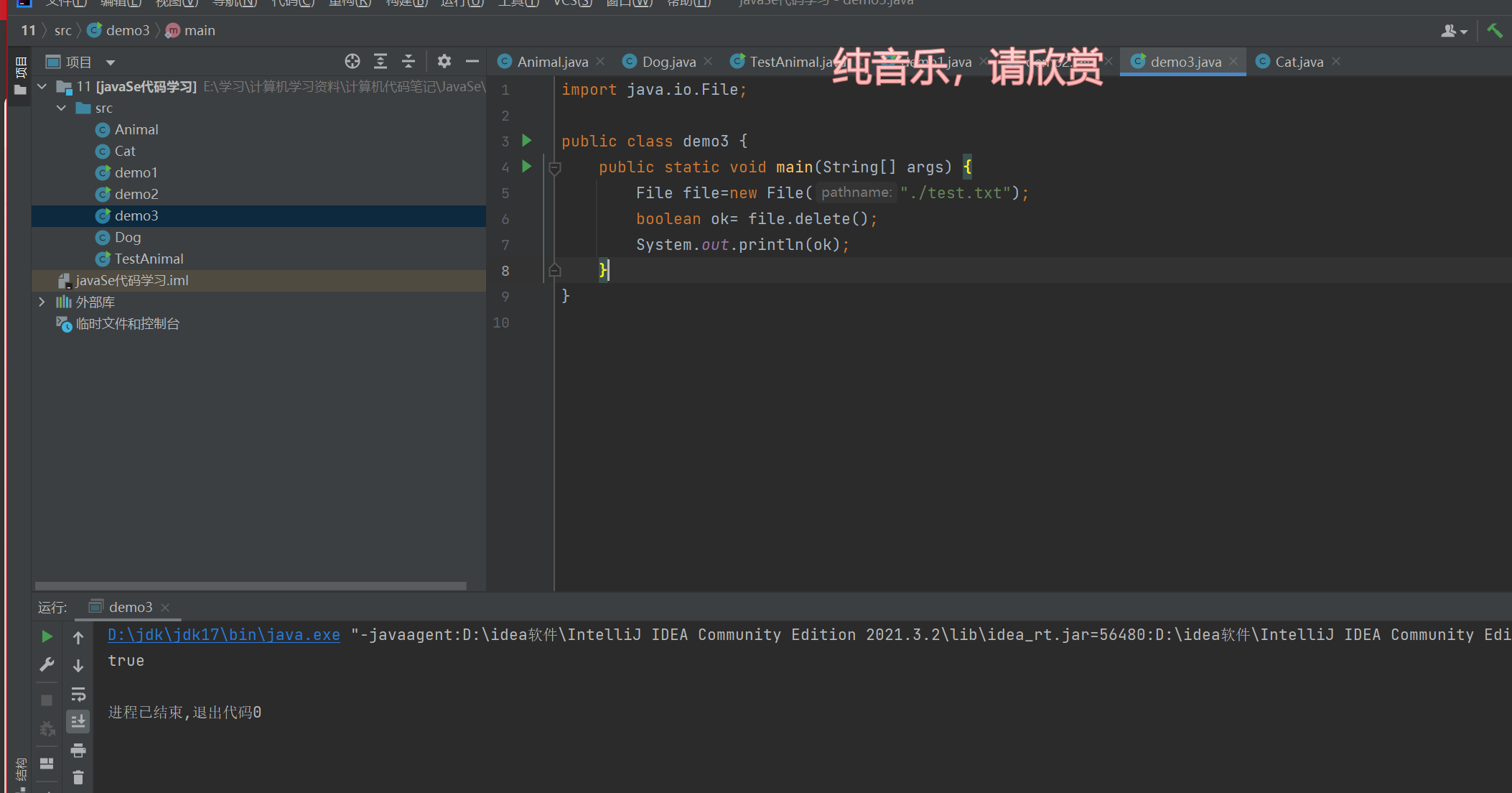
使用后,文件被删除了
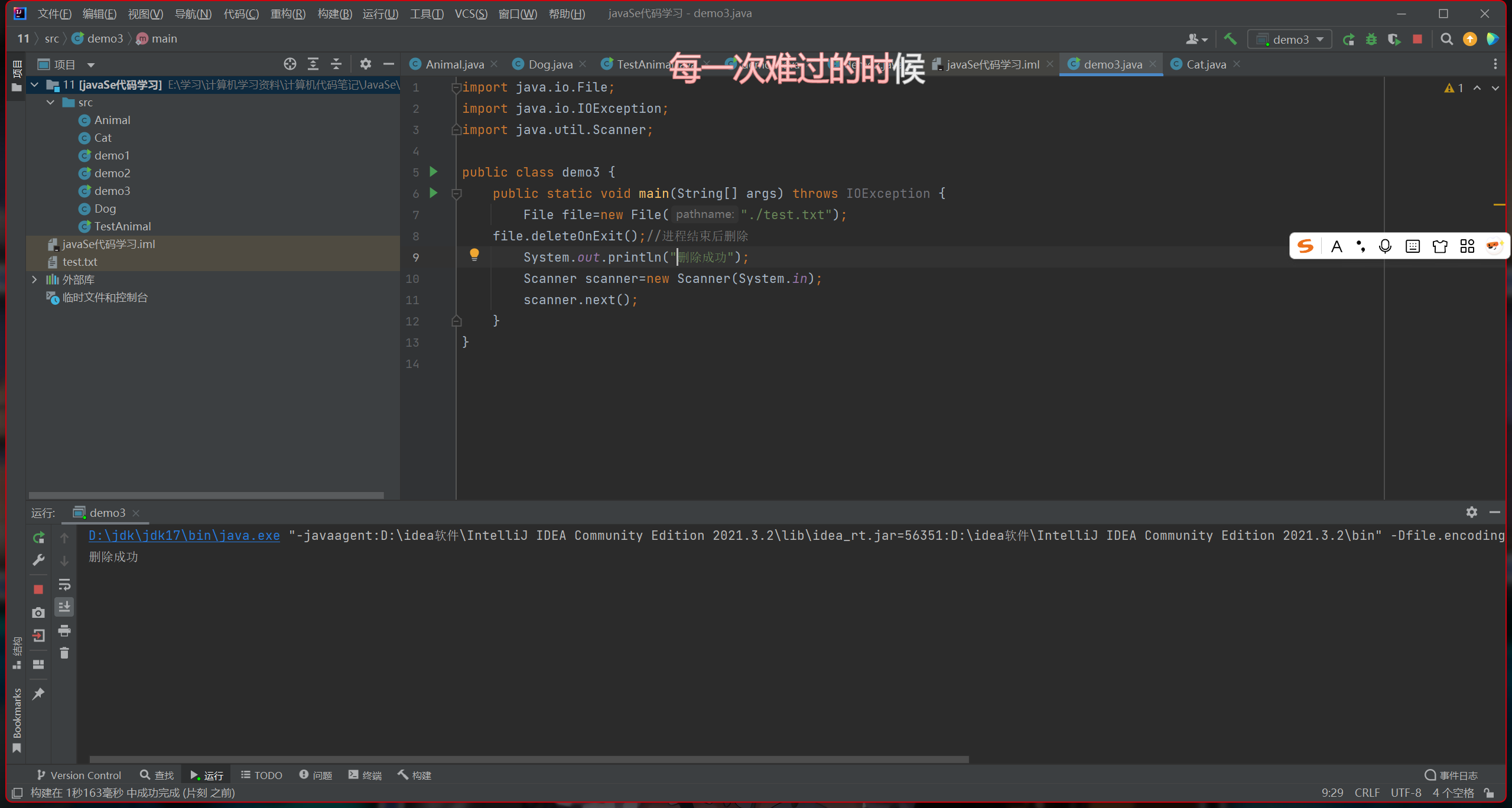
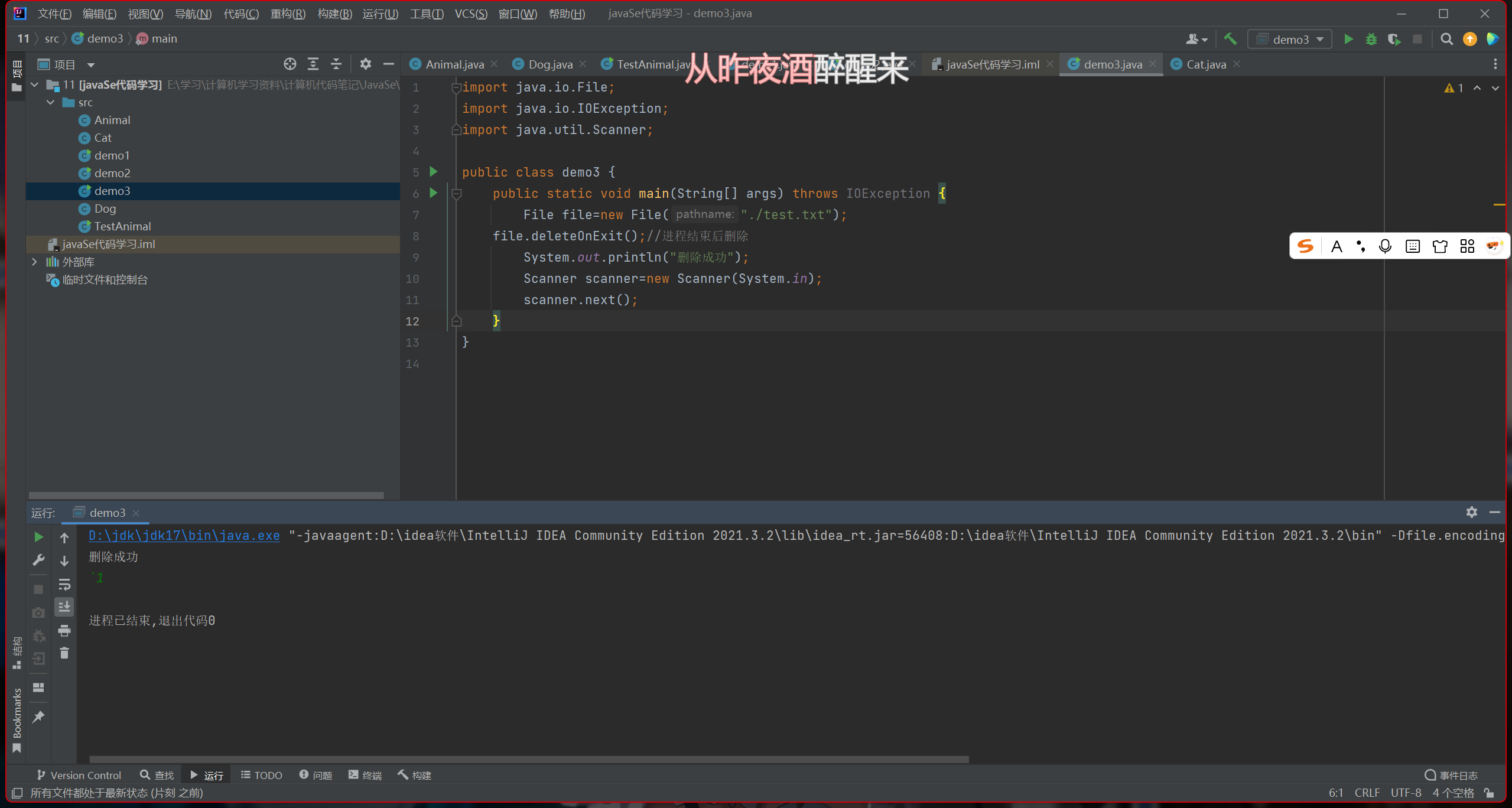
可以看出,程序结束后才删除该文件
它的意义是构造临时文件,程序结束就删除
实例四
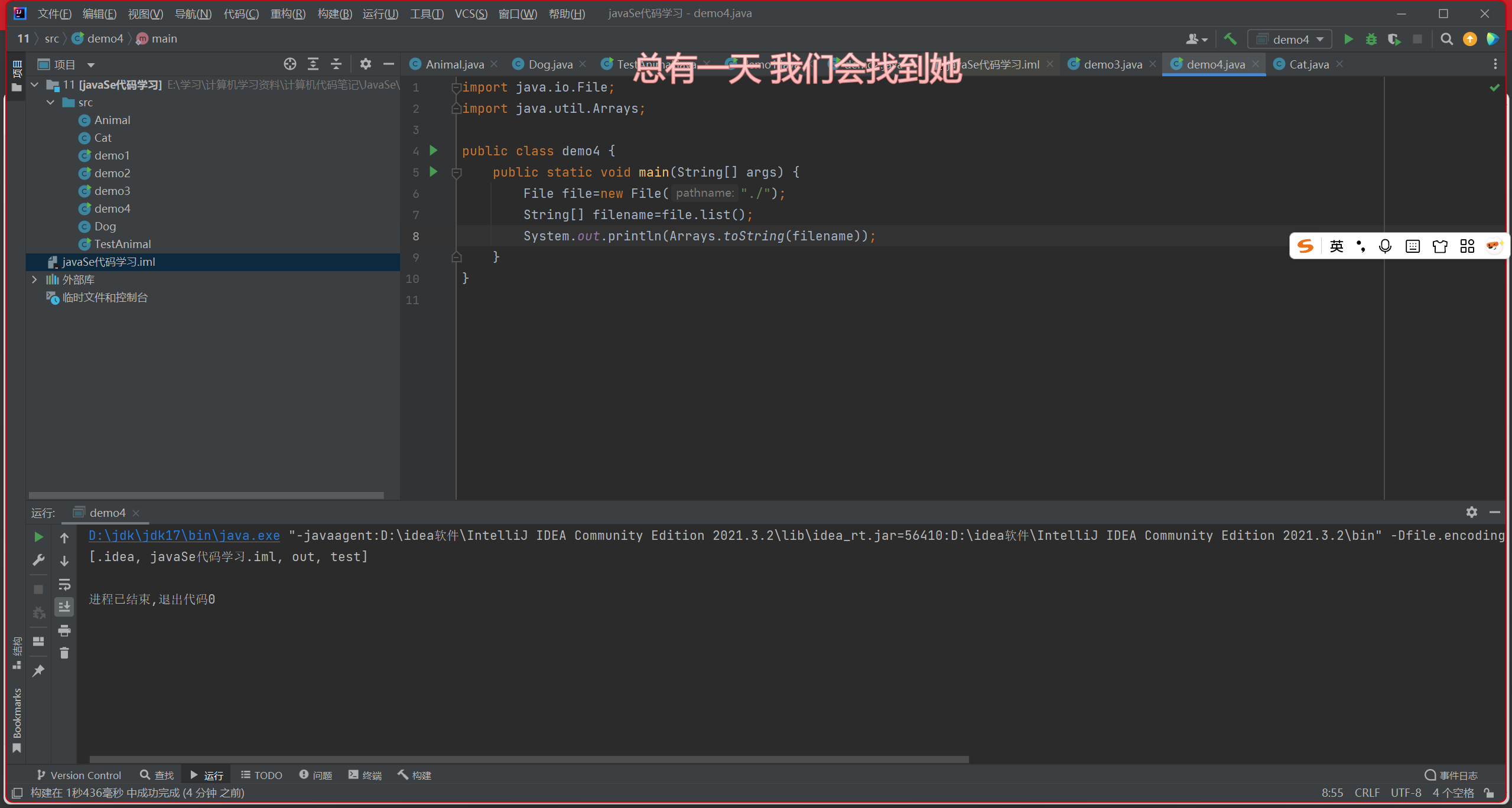
打印当前目录下所有的文件
实例五
递归打印目录里所有的文件
import java.io.File;
import java.io.IOException;public class demo5 {public static void scan(File file) throws IOException {if(!file.isDirectory()){//判断当前是否是目录return;}File[] filename=file.listFiles();if(filename==null ||filename.length==0) {//不存在的路径或者是空目录return;}System.out.println(file.getAbsolutePath());for(File f:filename){if(f.isFile()){System.out.println(f.getAbsolutePath());}else{scan(f);}}}public static void main(String[] args) throws IOException {File file=new File("./");scan(file);}
}
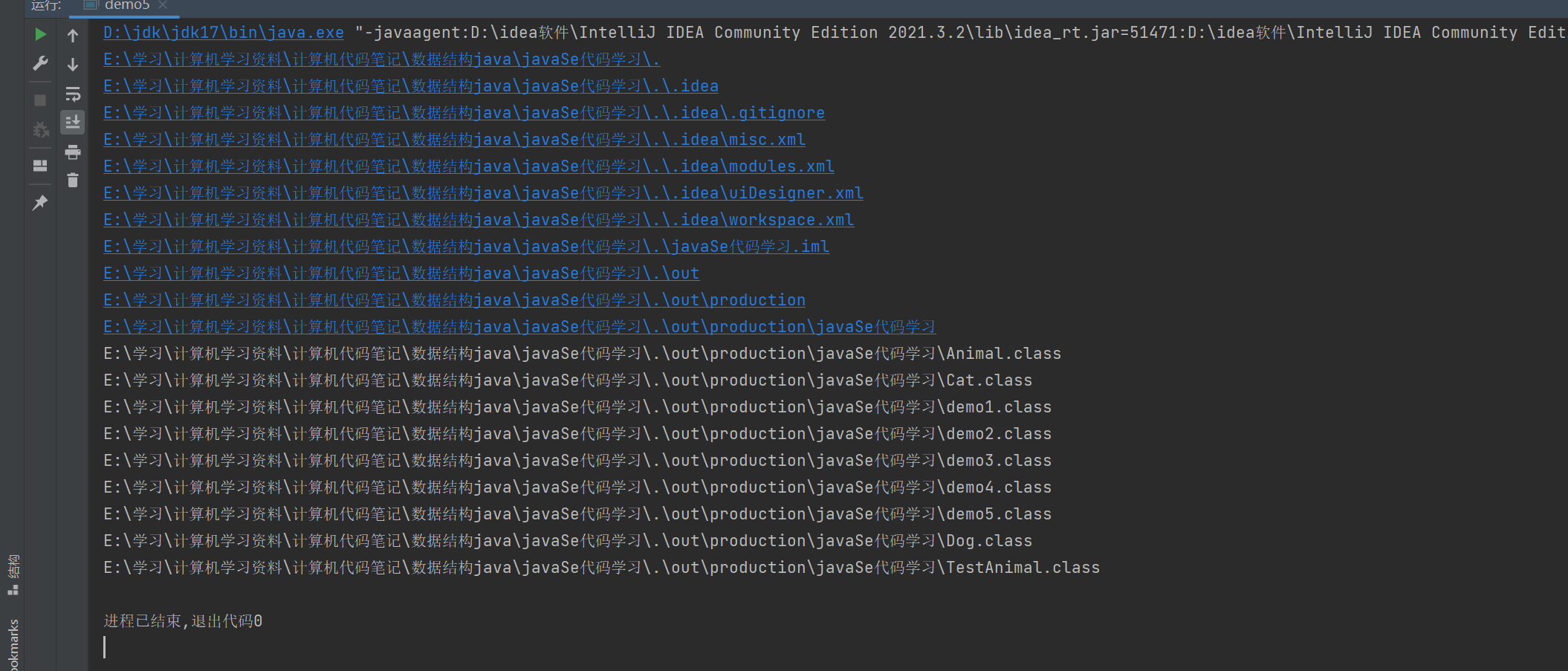
实例六
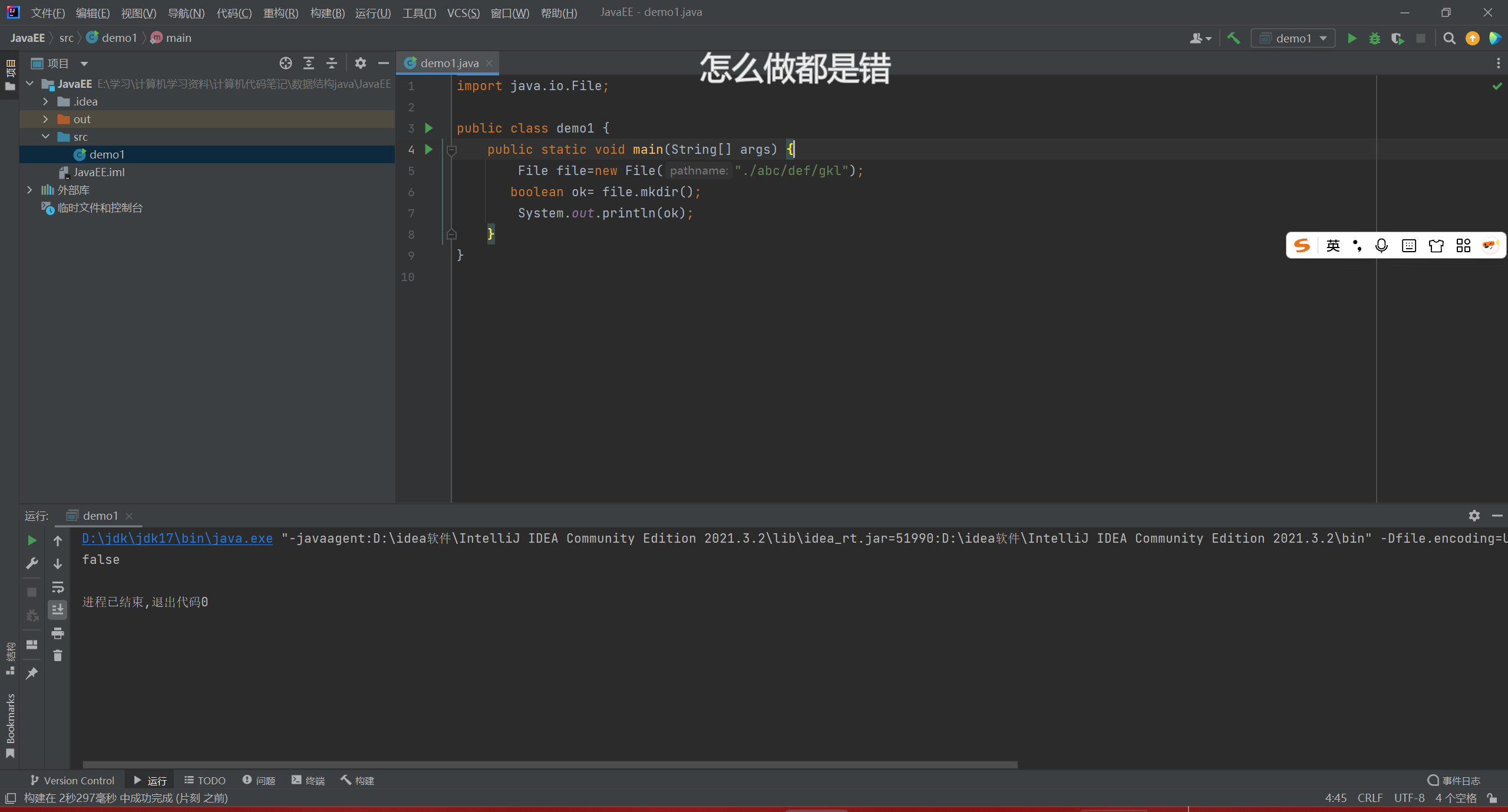
mkdir只能创建一个目录
mkdirs才可以创建多个目录
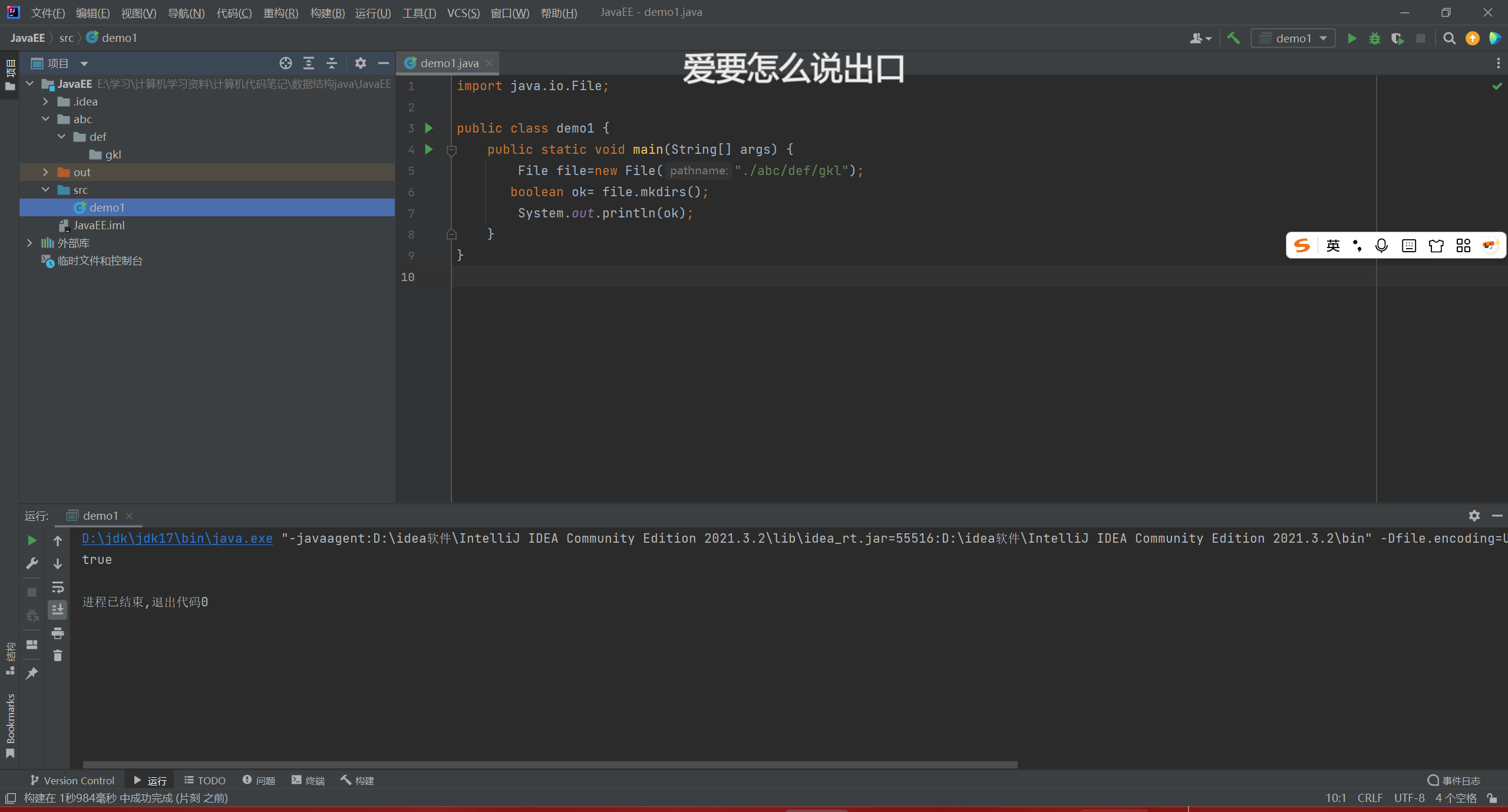
实例七
renameTo()文件的移动

renameTo()文件的重命名
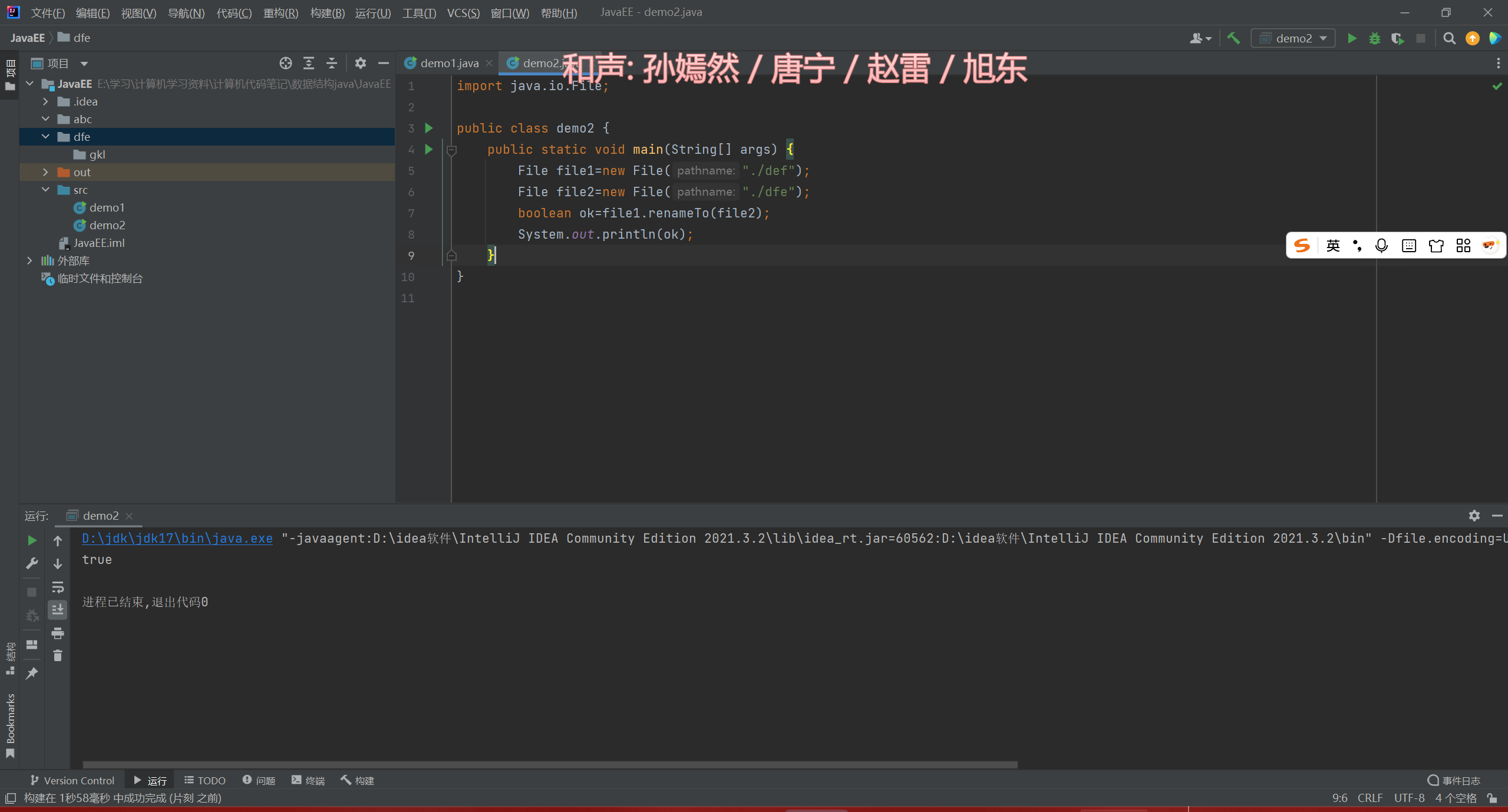
二、文件内容的读写——数据流
文件内容操作,读文件和写文件都是操作系统提供了 API.Java进行了封装
操作系统本身提供的文件读写的api就是流式
C/C++其他语言中文件操作也是成为“流”
Java实现IO流类有很多
分成两个大类
1.字节流
(二进制)
读写数据的基本单位就是字节
InputStream
OutputStream
2.字符流
(文本)
读写数据的基本单位就是字符
(字符流内部做的工作更多一些,会自动的查询码表,把二进制数据转换成对应的字符)
Reader
Writer
一个字符是几个字节?
答:不确定,取决于实际的编码方式
例如:gbk编码汉字就是2个字节,utf-8编码汉字就是3个字节,如果编码英语单词都是一个字节
输入输出的视角站在CPU的角度上去考虑,远离CPU是输出,靠近CPU是输入
以上四个类都是“抽象类”
实际上真正干活的并非是上面这四个
另外Java提供了很多很多的类,实现上面这四个抽象类
类的种类非常多,大家的用法都差不多,常用的类也没几个,所以使用FileInputStream类

此处抛出了FileNotFoundException,这个异常属于IOException,所以可以抛出它的父类
此处隐含了一个操作“打开文件”
针对文件进行读写,务必需要先打开(操作系统基本要求)
有打开就有关闭
如果不关闭会怎么样?
打开文件其实就是在该进程的文件描述符表中创建了一个新的表项
描述了该进程都要操作哪些文件,文件描述符表可以视为一个数组,数组的每个元素都是一个struct file对象(Linux内核)
每个结构体就描述了对应操作的文件的信息,数组的下标就称为“文件描述符”
除非主动调用close关闭文件,才是才释放出空间
如果代码里一直在打开,不去关闭就会使得这里的资源越来越少,把数组搞满了后续再打开就会失败——————这个问题就叫做“文件资源泄露”
由于有时候inputStream.close()因为抛出异常所以无法执行到
所以可以放在try-catch中的finally中

因为close也需要抛出异常,这样写并不好看
所以可以换个简单的写法
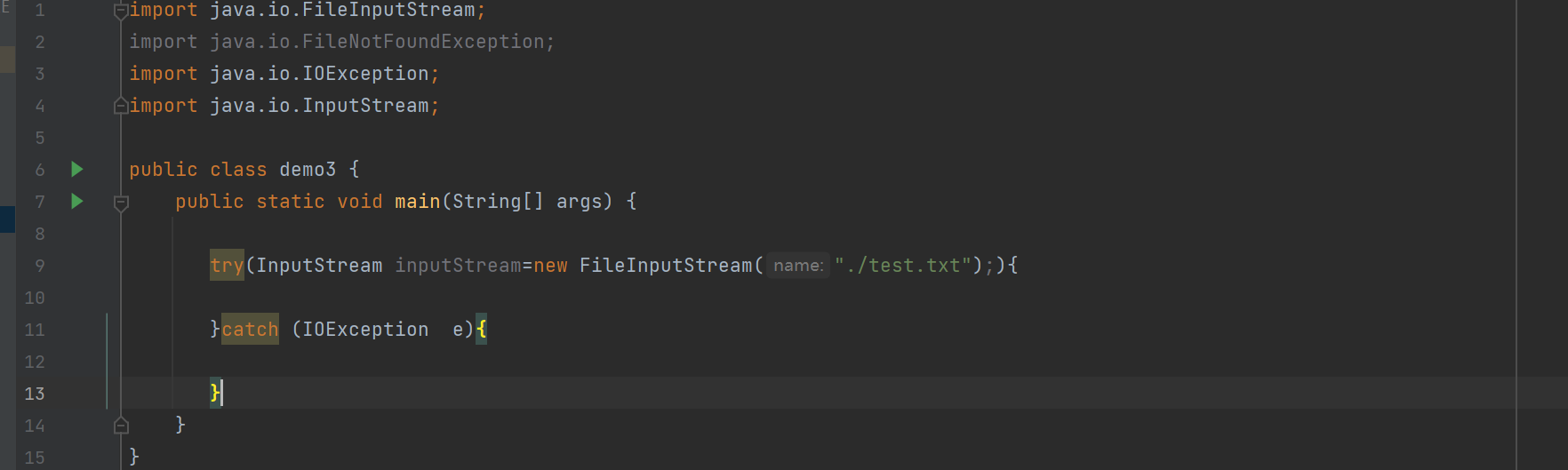
这里就不需要写finally了,也不必写close了
这里的用法是try with resource
这里的()中创建的资源(可以是多个)
try的{}执行完毕,最终都会自动的执行这里的close~~
这里自动close 的使用条件是类中实现了Closable接口
InputStream
1.InputStream.read()
public static void main(String[] args) {try (InputStream inputStream = new FileInputStream("./test.txt")) {while (true) {int n=inputStream.read();//返回读取到的内容,返回是0-255,如果文件读取完毕返回’-1‘,所以需要大于byte的数据类型if(n==-1){break;}System.out.printf("0x%x\n",n);}} catch (IOException e) {}}用硬盘读取到内存中,调用一次读一个字节,这个返回值就是这个字节的内容(byte)
2.InputStream.read(buffer)
public static void main(String[] args) {try(InputStream inputStream=new FileInputStream("./test.txt")){while(true){byte[] buffer=new byte[1024];//上一个方法是读取一个字节,输出一个字节,这个是一口气读取最多1024个,返回结果为读取的个数,将内容存储在字节数组中,如果文件结束返回-1int n= inputStream.read(buffer);if(n==-1){break;}for(int i=0;i<n;i++){System.out.printf("0x%x\n",buffer[i]);}}} catch (IOException e) {e.printStackTrace();}}频繁多次读取硬盘,当时硬盘的IO耗时比较多,希望能减少IO次数
此处的buffer是输出型参数,比较少见,这个操作就会把硬盘中读取的数据填充到内存的字节数组中,一次OI尽可能去填满
buffer/buf的单词是缓冲区,就是个内存空间,通过这个空间“暂时的存储某个数据”
3.InputStream.read(byte[] buffer,int off,int len)
这个版本类似于刚才,把数据往字节数组中填充,不是使用整个数组,是使用数组中【off,off+len】范围的区间,offset是偏移量,不是关闭
以OutputSteam
1.OutputSteam.write()
public static void main(String[] args) {try (OutputStream outputStream=new FileOutputStream("./test.txt",false)){//按字节来写操作outputStream.write(0x68);//写操作会把之前的内容清空outputStream.write(0x65);//如果不希望被清空,可以把后面的false改为true,实现追加写操作outputStream.write(0x6c);outputStream.write(0x6c);outputStream.write(0x6f);outputStream.write(0x68);outputStream.write(0x65);outputStream.write(0x6c);outputStream.write(0x6c);outputStream.write(0x6f);}catch (IOException e){}}每一次写入一个字节,这里的操作会把之前的内容清空,再进行写操作。只要使用OutputStream去打开文件,内容就全部清空了,这是默认的
可以在new FileOutputStream("./test.txt",true)
将后面的参数改为true,就可以实现追加写,包吃原内容不变,在末尾写入新的内容
2.OutputStream.read(buffer)
和之前的一样,这里的buffer是一个字节数组
把整个字节数组写入
public static void main(String[] args) {//按照数据来写操作try(OutputStream outputStream=new FileOutputStream("./test.txt")){byte[] buffer=new byte[]{0x68,0x65,0x6c,0x6c,0x6f};//buffer 在这里的作用是缓冲区,outputStream.write(buffer);//在这里,buff是输出型参数,java中输出型参数很少见}catch (IOException e){}}3.OutputSream.read(byte[] buffer,int off,int len)
public static void main(String[] args) {try(OutputStream outputStream=new FileOutputStream("./test.txt")){byte[] buffer=new byte[]{0x68,0x65,0x6c,0x6c,0x6f};//buffer 在这里的作用是缓冲区,outputStream.write(buffer,1,4);//在这里,buff是输出型参数,java中输出型参数很少见}catch (IOException e){//off是偏移量,从off开始,往后几个字节,len就是长度,往后的几个字节}}结果为:0x65 0x6c 0x6c 0x6f
Reader
1.reader.read()
public static void main(String[] args) {try(Reader reader=new FileReader("./test.txt")){while(true){int n=reader.read();if(n==-1){break;}char ch=(char)n;System.out.print(ch);}}catch (IOException e){}}与之前类似,一个字符一个字符的读取,返回值是读取到的内容,如果返回-1表示文件结束
最初的字节来读取是以utf8编码的,每个汉字占据3给字节,但是java 的char是2个字节
此处char表示的汉字就不再使用utf8,而是使用unicode,在unicode一个汉字结束两个字节
所以使用字符流读取数据的过程中,Java标准库内部就自动针对数据的编码进行转码了
2.reader.read(buffer)
try(Reader reader=new FileReader("./test.txt")){//java的char是两个字节,用的是Unicode来编码while(true){//在字符流读取数据的过程中,java标准库内部就自动针对数据的编码进行转码char[] buffer=new char[1024];int n=reader.read(buffer);if(n==-1){break;}for(int i=0;i<n;i++){System.out.print((buffer[i]));}}}catch (IOException e){}}以数组方式读取
Writer
1.writer.write()
public static void main(String[] args) {try(Writer writer=new FileWriter("./test.txt",false)){//此处可以追加true,进行字符拼接writer.write("你好,我是狐小粟");}catch (IOException e){}}可以直接写入一个String到文件中
2.writer.write(buffer)
同上
作为scanner的参数
public static void main(String[] args) {try(InputStream inputStream=new FileInputStream("./test.txt")){//使用scanner,用inputStream来作为参数读取文件的内容Scanner scanner=new Scanner(inputStream);while(scanner.hasNext()){System.out.println(scanner.nextInt());}}catch (IOException e){}}Scanner中也可以写其他文件的inputStream
三、练习
1.通过关键字再指定路径中删除(查找(递归遍历)+删除)
import java.io.File;
import java.util.Scanner;public class demo13 {private static void scan(File currentFile,String key){if(!currentFile.isDirectory()){return;}File[] files=currentFile.listFiles();if(files==null||files.length==0){return;}for(File file:files){if(file.isFile()){//是否是普通文件//delete(file,key); //删除}else {//是否是目录scan(file,key);}}}private static void delete(File file,String key){if(file.getName().contains(key)){System.out.println(file.getAbsoluteFile());System.out.println("是否确定该文件 Y/N");Scanner scanner=new Scanner(System.in);String choice =scanner.next();if(choice.equals("y")||choice.equals("Y")){file.delete();System.out.println("删除成功");}}else{return;}}public static void main(String[] args) {System.out.println("请输入要搜索的路径");Scanner scanner=new Scanner(System.in);String rootpath=scanner.next();File rootFile=new File(rootpath);if(!rootFile.isDirectory()){return;}System.out.println("请输入要删除的文件的关键字");String key=scanner.next();scan(rootFile,key);}
}
2.文件的复制
public static void main(String[] args) {//文件的复制Scanner scanner=new Scanner(System.in);System.out.println("请输入要复制的路径");String sourcepath=scanner.next();File sourceFile=new File(sourcepath);if(!sourceFile.isFile()){System.out.println("输入的原路径地址有误");return;}System.out.println("请输入目标地址");String destPath=scanner.next();File destFile=new File(destPath);if(!destFile.getParentFile().isDirectory()){System.out.println("目标文件地址有误");return;}try(InputStream inputStream=new FileInputStream(sourceFile); OutputStream outputStream=new FileOutputStream(destFile)){while(true){byte[] buffer=new byte[1024];int n=inputStream.read(buffer);if(n==-1){return;}outputStream.write(buffer,0,n);}}catch (IOException e){}}try()这里可以写多个对象,多个对象的构造过程使用 ; 分割
3.查询指定路径下的文件内部是否存在关键词(遍历打开非目录文件+将非目录文件下的所有字符全部字符串拼接,并且最后查看是否含有该关键字)
public static void main(String[] args) {Scanner scanner=new Scanner(System.in);System.out.println("请输入要查询的路径");String path=scanner.next();File destFile=new File(path);if(!destFile.isDirectory()){return;}System.out.println("请输入要查询的关键词");String key =scanner.next();scan(destFile,key);//查询}private static void scan(File destFile, String key) {if(!destFile.isDirectory()){return;}File[] files=destFile.listFiles();if(files==null||files.length==0){return;}for(File file:files){if(file.isFile()){doSearch(file,key);}else{scan(file,key);}}}private static void doSearch(File destFile, String key) {StringBuffer stringBuffer=new StringBuffer();try(Reader reader=new FileReader(destFile)) {while(true){char[] buffer=new char[1024];int n=reader.read(buffer);if(n==-1){break;}String s=new String(buffer,0,n);stringBuffer.append(s);}}catch (IOException e){}if(stringBuffer.indexOf(key)==-1){return;}else{System.out.println("找到了匹配的文件"+destFile.getAbsoluteFile());}}此处的代码逻辑的效率是非常低的,每一次查询都会涉及大量的IO操作,尤其硬盘上可能有一些大的文件
这种思路不能适应频繁查询场景,也不能适应目录中文件数目特别多特别大的场景
基于内容的查询案例------搜索引擎
搜索引擎中搜索的过程也就是文件中查找内容是否被包含的过程
搜索出来的结果都是一些html文件
这些html文件里面一定包含你的查询词(或者和查询词有关联
搜索引擎这种场景,不能使用上述的“遍历文件”方式实现
其中最核心的优化,引入了神奇的数据结构‘倒排索引’
提前把所有的文件里面的内容都分析好,分析出一个文件中包含哪些词
基于这个结果,得到另一份数据(每个词都在哪些文件中包含着)