第七章.干货干货!!!Langchain4j开发智能体-文生图文生视频
前言
可能我们都用过三方的大模型如:文心一言,通义千问等的文生图/语音/视频的功能,当我们输入需求大模型就可以根据我们的需求生成对应的图片或者视频。那么在你的项目中可能也会有这样的需求,我们一起来看看如何实现它。
百炼大模型平台
这里我使用百炼大模型平台现成的模型来实现文生图等功能,如果你还没有百炼平台的apikey,请先去这个地址创建 https://bailian.console.aliyun.com/?apiKey=1#/api-key 。
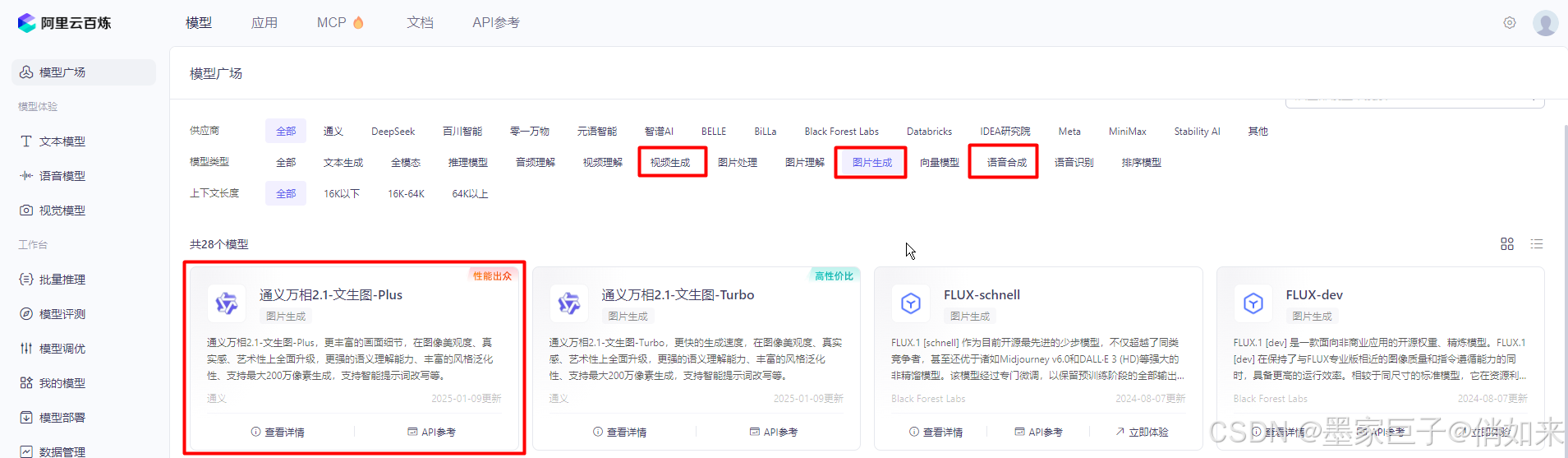
在百炼平台上有对应的文生图/视频/语音对应的模型通义万向:选择一个模型-api参考-点击进去我们可以看到他的使用方式
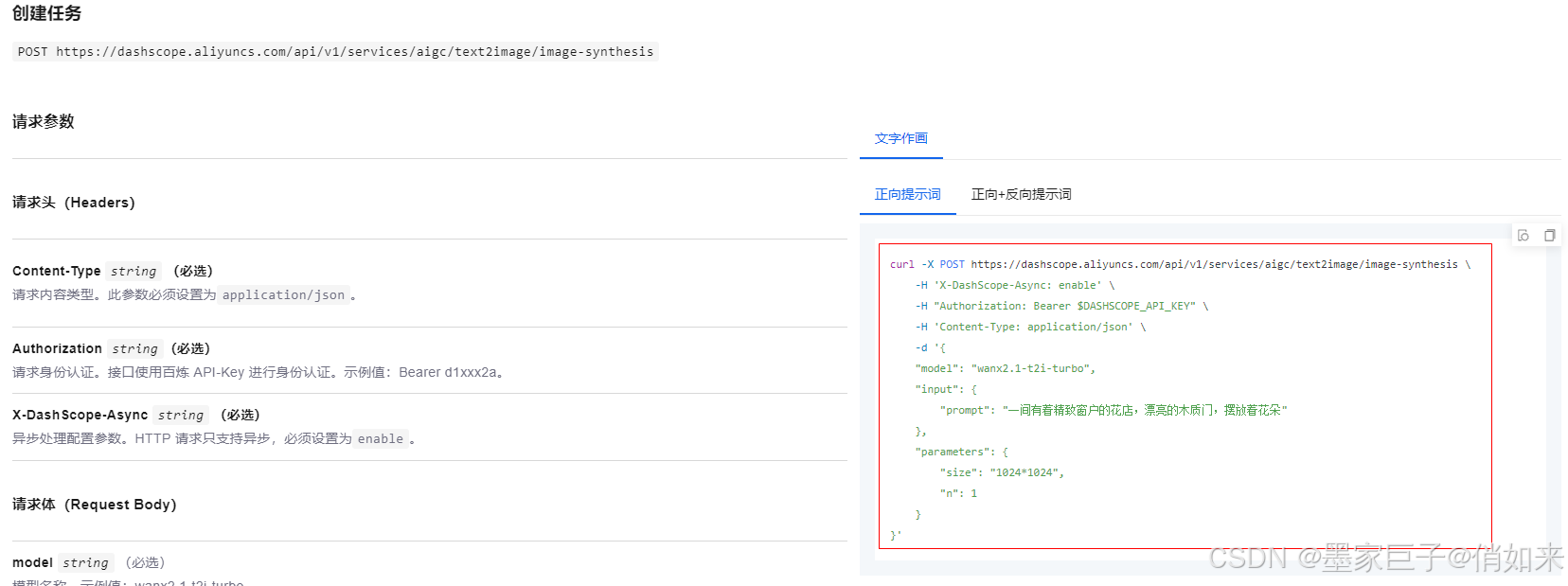
在往底部滑动我们可以看到各种语言的使用方式,找到java实例

有了代码示例后我们就根据该实例来接入自己的智能体了。
接入百炼文生图
这里我使用的是 WanxImageModel 万象模型去构建,需要指定模型名字和李的apkey。如下
/*** 文生图*/@RequestMapping(value="/chat/image", produces = TEXT_EVENT_STREAM_VALUE)public String chatImage(@RequestParam("message") String message) {setEncoder();WanxImageModel wanxImageModel = WanxImageModel.builder().modelName("wanx2.1-t2i-plus").apiKey("sk-你的key").build();Response<Image> response = wanxImageModel.generate(message);return response.content().url().toString();}
其实 WanxImageModel 还可以设置很多的参数,比如:图片风格,图片像素等等,你可以根据官网文档自己去设置。测试效果如下
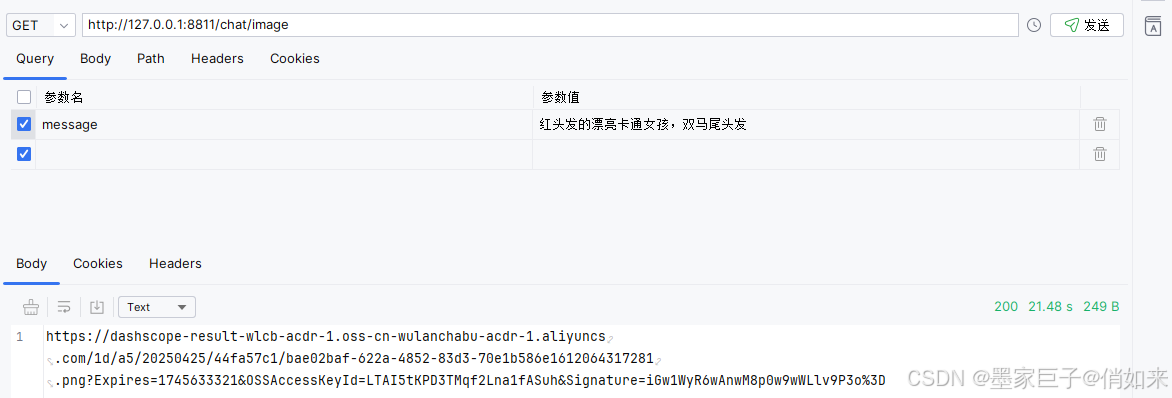
大模型会把生成好的图片地址返回给我们,下载下来

文生视频/音频的代码我也贴一下,实现方式都一样,具体细节请参考官网
/*** 文生语音*/@RequestMapping(value="/chat/audio", produces = TEXT_EVENT_STREAM_VALUE)public String chatAudio(@RequestParam("message") String message) {String model = "cosyvoice-v1";String voice = "longxiaochun";SpeechSynthesisParam param = SpeechSynthesisParam.builder()// 若没有将API Key配置到环境变量中,需将下面这行代码注释放开,并将your-api-key替换为自己的API Key.apiKey("sk-你的key").model(model).voice(voice).build();// 同步模式:禁用回调(第二个参数为null)SpeechSynthesizer synthesizer = new SpeechSynthesizer(param, null);// 阻塞直至音频返回ByteBuffer audio = synthesizer.call(message);// 将音频数据保存到本地文件“output.mp3”中File file = new File("output.mp3");System.out.println("[Metric] requestId: "+ synthesizer.getLastRequestId()+ ", first package delay ms: "+ synthesizer.getFirstPackageDelay());try (FileOutputStream fos = new FileOutputStream(file)) {fos.write(audio.array());} catch (IOException e) {throw new RuntimeException(e);}return "ok";}/*** 文生视频*/@RequestMapping(value="/chat/video", produces = TEXT_EVENT_STREAM_VALUE)public String chatVideo(@RequestParam("message") String message) {VideoSynthesis vs = new VideoSynthesis();VideoSynthesisParam param = VideoSynthesisParam.builder().apiKey("sk-你的key").model("wanx2.1-t2v-turbo").prompt(message).size("1280*720").build();VideoSynthesisResult result = null;try {result = vs.call(param);} catch (NoApiKeyException e) {throw new RuntimeException(e);} catch (InputRequiredException e) {throw new RuntimeException(e);}return JsonUtils.toJson(result);}
总结
好吧文章到这结束,本文介绍了如何通过百炼大模型实现文生图/文生视频等,其实学到这里你时候已经有想法搭建自己的大模型平台了呢?实现一套用户系统,开发一套UI界面,对接自己的大模型或者三方大模型实现对话,搜索,文生图等各种功能。 喜欢的话请三链哦,你的鼓励是我最大的动力,下一章我们学习如何使用SpringAI开发MCPServer 和 MCPClient。