大模型常用的数据类型FP32,BF16,FP16
1 一切的起点,FP32 (单精度浮点数)
在深入了解低精度格式之前,我们必须先理解它们的基准——FP32。
1.1. IEEE 754 标准回顾
计算机的世界由0和1组成,为了表示像3.14159这样的“小数”,工程师们制定了IEEE 754标准。它定义了浮点数在二进制中如何存储,使其可以表示极大或极小的数值。
1.2. FP32 的内部结构
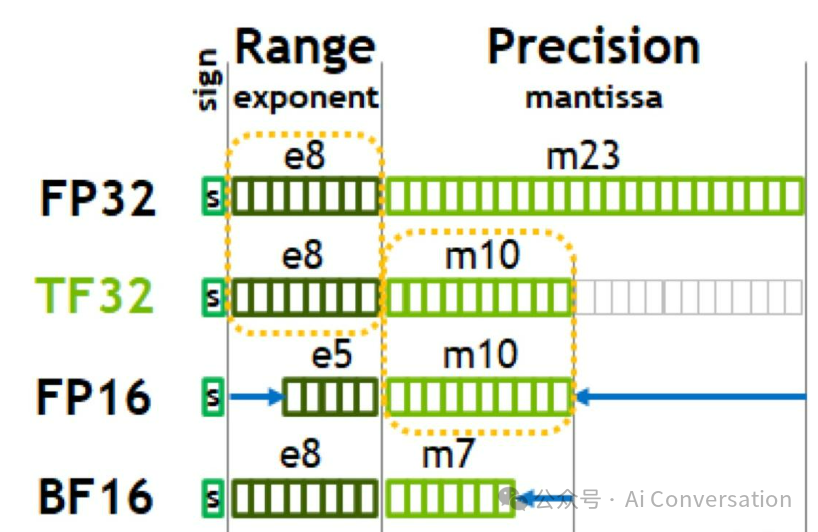
一个32位的FP32数值由三部分构成:
- 符号位 (Sign, S): 1位。0代表正数,1代表负数。
- 指数位 (Exponent, E): 8位。用于表示数值的“大小范围”或“量级”,类似于科学记数法中的10的N次方。
- 尾数位 (Mantissa, M): 23位。用于表示数值的“有效数字”,决定了数值的精度。
其值的计算公式为:V=(−1)S×2E−127×(1.M),这里的127是FP32的偏置值 (bias)。
S - 符号位 (Sign)
- 是什么:这是最简单的一部分。它是一个单独的比特位(0或1)。
- 如何工作:
- 如果 S = 0,则 (−1)0=1,表示这个数是正数。
- 如果 S = 1,则 (−1)1=−1,表示这个数是负数。
- 目的:用1个比特位决定数字的正负。
E - 指数位 (Exponent)
- 是什么:在FP32中,这是8个比特位,用来存储指数。
- 关键问题:指数可以是正数(比如 25,一个较大的数),也可以是负数(比如 2−3,一个很小的数)。我们如何用8个比特表示正负指数呢?
- 解决方案:指数偏移 (Exponent Bias)
- 我们不直接存储负数。而是给实际的指数加上一个固定的偏移值(Bias),确保存储到E里的值永远是正数。
- 对于FP32,这个偏移值规定为127。
- 所以,我们有了这个关系:存储值 E = 真实指数 + 127
- 反过来,在计算真实数值时,就要减去这个偏移值:真实指数 = 存储值 E - 127。
- 这就是公式中 E-127 的由来! 它是为了从存储的8位无符号整数E(范围0-255)中,还原出可正可负的真实指数。
M - 尾数位 (Mantissa) 和 (1.M)
- 是什么:在FP32中,这是剩下的23个比特位,用来存储有效数字的小数部分。
1.3. 动态范围与精度
- 动态范围 (Dynamic Range): 由指数位决定。指一个数据类型能表示的最大值和最小值之间的范围。FP32的8位指数使其可以表示从约 1.18times10−38 到 3.4times1038 的广大范围。
- 精度 (Precision): 由尾数位决定。指一个数据类型能表示的有效数字的多少。FP32的23位尾数提供了大约7位十进制数的精度。
1.4. 小结
FP32拥有广阔的动态范围和足够的精度,使其成为科学计算和传统深度学习训练的默认选择。然而,每个数字32位的“体重”在处理动辄数十亿参数的模型时,显得过于臃肿和低效。
2 半精度双雄 - FP16 与 BF16 的对决
为了解决FP32的效率问题,研究人员提出了多种16位半精度格式,其中FP16和BF16脱颖而出。它们都只占用FP32一半的内存,但通过不同的“牺牲”策略,实现了不同的特性。
2.1. FP16 (半精度浮点数)
FP16是更早被广泛应用的半精度格式。
- 2.1.1. 比特结构:
- 符号位: 1位
- 指数位: 5位
- 尾数位: 10位
- 2.1.2. 特点: FP16选择保留更多的尾数位(10位),牺牲了指数位(5位)。这意味着它具有相对不错的精度,但动态范围非常有限(约 6times10−5 到 65504)。
- 2.1.3. 动态范围问题: 5位的指数位是FP16最大的弱点。在深度学习训练中,梯度(尤其是在训练后期)可能会变得非常小,超出FP16能表示的最小范围,导致下溢 (Underflow),梯度变为0,模型停止学习。同样,一些中间计算结果也可能超出其最大范围,导致上溢 (Overflow),变成无穷大 (Inf)。
- 2.1.4. 应用场景:
- 模型推理: 推理时,权重和激活值的范围通常是已知的、可控的,FP16的精度优势能带来更好的结果。
- 游戏图形: 游戏渲染中广泛使用。
- 混合精度训练: 配合“损失缩放”技术克服动态范围问题。
2.2. BF16 (BFloat16 )
BF16由Google Brain团队提出,专为深度学习设计。
- 2.2.1. 比特结构:
- 符号位: 1位
- 指数位: 8位
- 尾数位: 7位
- 2.2.2. 特点: BF16做出了与FP16相反的权衡。它保留了与FP32完全相同的8位指数位,但只留下了7位尾数位。这意味着它的动态范围与FP32完全一致,从根本上避免了训练中的上溢和下溢问题,但代价是精度较低。
- 2.2.3. 为何BF16更适合训练?: 深度学习模型对动态范围的稳定性远比对极高的数值精度更敏感。BF16的宽广范围确保了梯度和激活值总能被有效表示,使得训练过程更加稳定,无需像FP16那样依赖复杂的损失缩放技术。可以简单地将FP32数截断为BF16数,转换非常方便。
- 2.2.4. 应用场景:
- 大规模模型训练: 几乎成为现代大语言模型(LLM)和大型视觉模型训练的标配。
- AI加速器: Google TPU 从设计之初就原生支持,现在也成为NVIDIA新一代GPU的标配。
2.3. 核心对比:FP16 vs. BF16
特性 | FP16 (半精度) | BF16 | FP32 (单精度) |
总位数 | 16 | 16 | 32 |
符号位 | 1 | 1 | 1 |
指数位 | 5 | 8 | 8 |
尾数位 | 10 | 7 | 23 |
动态范围 | 小 (易溢出) | 大 (同FP32) | 大 |
精度 | 较高 | 较低 | 高 |
主要优点 | 精度相对较高,节省内存 | 训练稳定,范围广,节省内存 | 标准,精确 |
主要缺点 | 动态范围小,训练不稳定 | 精度较低 | 内存和计算开销大 |
核心权衡 | 牺牲范围,保留精度 | 牺牲精度,保留范围 | - |
硬件支持 | NVIDIA (V100+), 主流GPU | Google TPU, NVIDIA (A100+), Intel Gaudi | 所有现代处理器 |
一句话总结:需要稳定训练选BF16,需要推理精度选FP16。
3 极致效率 - INT8 (8位整型) 与量化
当我们追求极致的性能和能效时,浮点数就不再是最佳选择了。INT8,即8位整型,能提供数倍于半精度浮点数的计算吞吐量,尤其是在支持它的硬件上。但天下没有免费的午餐,使用INT8需要一个关键步骤——量化。
3.1. 什么是量化 (Quantization)?
量化是将连续的浮点数值(如FP32)映射到有限的、离散的整数值(如INT8)集合的过程。
想象一下,我们有一把包含无数刻度的浮点数“尺子”,现在我们要用一把只有256个刻度(28=256)的整数“尺子”来测量同样的物体。我们必须找到一种映射关系,将浮点世界中的一个范围对应到整数世界里的一个特定值。
3.2. INT8 的原理
- 3.2.1. 比特结构: 8个比特可以表示256个不同的整数。可以是有符号的 [-128, 127] 或无符号的 [0, 255]。
- 3.2.2. 核心公式: 量化和反量化的过程可以用一个简单的线性公式来描述:
RealValue=(IntegerValue−ZeroPoint)×Scale
- RealValue: 原始的FP32值。
- IntegerValue: 量化后的INT8值。
- Scale (缩放因子): 一个浮点数,表示整数世界里的一个单位对应浮点世界里的多大距离。
- ZeroPoint (零点): 一个整数,表示浮点世界的0对应整数世界的哪个值。这对于非对称分布的数据至关重要。
- 3.2.3. 对称 vs. 非对称量化:
- 对称量化: 将浮点范围 [-R, R] 映射到 [-127, 127]。零点固定为0,计算更简单。
- 非对称量化: 将浮点范围 [min, max] 映射到 [0, 255](或 [-128, 127])。需要计算零点,能更好地拟合非对称的数据分布(如ReLU激活函数后的值)。
3.3. 量化的两种主流方法
- PTQ (训练后量化):
- 流程: 拿一个已经训练好的FP32模型,用一小部分校准数据集(calibration data)来计算权重和激活值的Scale和ZeroPoint,然后将模型转换成INT8格式。
- 优点: 非常简单、快速,无需重新训练。
- 缺点: 由于量化是在训练后“硬”施加的,可能会导致明显的精度下降,尤其对某些模型敏感层。
- QAT (量化感知训练):
- 流程: 在FP32模型训练的后期,或在整个微调(fine-tuning)过程中,在模型的前向传播中模拟量化操作(即插入“伪量化”节点)。这使得模型在训练时就能“感知”到量化带来的误差,并学习如何适应它,从而调整权重以最小化这种误差。
- 优点: 通常能获得远高于PTQ的精度,有时甚至能接近FP32模型的水平。
- 缺点: 过程更复杂,需要额外的训练或微调。
3.4. INT8 的优势与挑战
- 优势:
- 极致性能: 现代GPU的Tensor Core执行INT8矩阵乘法的理论速度是FP16的2倍,是FP32的4倍。
- 极低内存: 内存占用是FP32的1/4。
- 能耗更低: 整型运算比浮点运算更节省能源,非常适合边缘设备。
- 挑战:
- 精度损失: 这是最主要的挑战,需要通过QAT等技术来弥补。
- 对离群值敏感: 一个异常大的激活值(outlier)可能会严重影响Scale的计算,从而拉低整个张量的量化精度。
3.5. 应用场景
INT8是模型推理阶段的王者,尤其是在对延迟、吞吐量和成本有严格要求的场景,如:
- 云端AI服务: 搜索引擎、推荐系统、语音识别。
- 边缘计算: 自动驾驶、智能手机、安防摄像头。
4 前沿技术 - FP8 (8位浮点数) 的崛起
INT8在推理上表现卓越,但在训练上却难以应用,因为它狭窄的动态范围无法承载梯度这样剧烈变化的数值。有没有一种格式,既能拥有INT8般的极致效率,又能像浮点数一样处理宽广的动态范围,从而胜任训练任务呢?答案就是 FP8。
4.1. 为什么在INT8之后还需要FP8?
FP8旨在结合INT8的速度和BF16的动态范围。它是一种8位的浮点格式,这意味着它和FP32/FP16一样,拥有符号、指数和尾数位。这使得它天然具有宽广的动态范围,避免了INT8量化中对离群值敏感和精度校准复杂的问题。
4.2. FP8 的两种变体
为了在有限的8位内最大化效益,NVIDIA在其Hopper架构中引入了两种可切换的FP8格式:
- E4M3 (4位指数,3位尾数):
- 结构: 1个符号位,4个指数位,3个尾数位。
- 特点: 指数位较少,动态范围相对窄;但尾数位较多,精度更高。
- 用途: 主要用于神经网络中前向和反向传播的计算。在这些步骤中,数值的精度至关重要。
- E5M2 (5位指数,2位尾数):
- 结构: 1个符号位,5个指数位,2个尾数位。
- 特点: 指数位更多(与FP16相同),动态范围更广;但尾数位极少,精度较低。
- 用途: 主要用于存储和计算梯度。梯度在训练过程中变化范围极大,需要宽广的动态范围来防止下溢或上溢。
4.3. FP8 的工作机制
FP8的威力在于动态切换。NVIDIA的Transformer Engine这样的软件库会自动处理这一切:
- 在前向传播计算激活值时,使用E4M3格式,以保证计算精度。
- 在反向传播计算梯度时,切换到E5M2格式,以容纳梯度的巨大动态范围。
- 权重更新仍然在更高精度(如FP32)下进行。
这种智能切换机制,使得FP8可以在不牺牲训练稳定性的前提下,实现接近INT8的计算速度。
4.4. 优势与应用
- 优势: FP8是目前在性能、动态范围和精度之间取得了最佳平衡的低精度格式,尤其适合训练和推理超大规模的Transformer模型(LLM)。它比BF16快,同时比INT8更易用、更稳定。
- 应用与硬件: FP8是NVIDIA H100/H200系列GPU的标志性特性,配合Transformer Engine库,已成为训练和推理顶尖LLM的首选方案。
5 综合应用与最佳实践
5.1. 横向对比总表
特性 | FP32 | FP16 | BF16 | INT8 (量化) | FP8 (E4M3/E5M2) | 特性 | FP32 | FP16 |
总位数 | 32 | 16 | 16 | 8 | 8 | 总位数 | 32 | 16 |
类型 | 浮点 | 浮点 | 浮点 | 整型 | 浮点 | 类型 | 浮点 | 浮点 |
动态范围 | 非常大 | 小 | 非常大 | 极小 (依赖量化) | 中/大 | 动态范围 | 非常大 | 小 |
精度 | 非常高 | 较高 | 较低 | 依赖量化 | 中/低 | 精度 | 非常高 | 较高 |
内存占用 (相对FP32) | 1x | 0.5x | 0.5x | 0.25x | 0.25x | 内存占用 (相对FP32) | 1x | 0.5x |
性能 (理论) | 1x | 2-4x | 2-4x | 4-8x | 4-8x | 性能 (理论) | 1x | 2-4x |
主要优点 | 精度高,标准 | 节省资源,推理精度好 | 训练稳定,范围广 | 极致速度和效率 | 速度、范围和易用性的平衡 | 主要优点 | 精度高,标准 | 节省资源,推理精度好 |
主要挑战 | 开销大 | 训练易溢出 | 精度损失 | 精度损失大,过程复杂 | 需要最新硬件和软件支持 | 主要挑战 | 开销大 | 训练易溢出 |
核心应用 | 基准,敏感计算 | 推理,图形 | 训练 (尤其LLM) | 推理 (尤其边缘端) | LLM训练与推理 | 核心应用 | 基准,敏感计算 | 推理,图形 |
5.2. 混合精度训练 (Mixed Precision Training) 详解
这是在FP16和BF16时代最核心的加速技术。以FP16为例,其工作流程如下:
- FP32主权重: 在内存中保留一份FP32格式的“主权重 (master weights)”,用于稳定地累积梯度更新。
- FP16计算: 在每次迭代的前向传播和反向传播中,将FP32权重转换为FP16格式进行计算。这利用了Tensor Core的FP16加速能力。
- 损失缩放 (Loss Scaling): 这是针对FP16的关键步骤。在反向传播前,将计算出的损失值 (Loss) 乘以一个大的系数(如1024)。根据链式法则,这个系数会传递到所有梯度上,将那些原本可能因太小而下溢的梯度“放大”到FP16的可表示范围内。
- 梯度更新: 将计算出的FP16梯度转换回FP32格式,并除以之前的缩放系数以还原真实值。然后用这个FP32梯度去更新FP32主权重。
对于BF16,由于其动态范围与FP32相同,通常不需要损失缩放,使得混合精度训练流程更简单。
5.3. 如何为你的应用选择合适的数据类型?
- 如果你在做模型训练:
- 拥有最新GPU (NVIDIA H100+): FP8 是最佳选择,能带来最快的速度和稳定性。
- 拥有上一代GPU/TPU (NVIDIA A100+, Google TPU): BF16 是标准选择,稳定且高效。
- 拥有更早的GPU (NVIDIA V100): 使用带损失缩放的FP16混合精度训练。
- 如果你在做模型推理:
- 追求极致性能和低成本: INT8 是不二之选。投入时间进行精细的量化(PTQ或QAT)会带来巨大回报。
- 模型对精度非常敏感,或不愿投入量化工程: FP16 是一个很好的选择,它比FP32快得多,且精度损失可控。
- 应用部署在支持BF16的硬件上: BF16 也是一个简单的选项,转换方便。
- 拥有最新硬件: FP8 将成为推理的新标准,兼顾速度和易用性。
- 精度永远是第一位?: 始终保留FP32作为基准线 (baseline),并在模型的某些敏感部分(如最终的分类层)强制使用FP32计算,以保证数值稳定性。
6 未来展望
低精度计算的探索永无止境。
- 更低比特: 学术界正在研究FP4、2位(三元网络)甚至1位(二元网络)等极限压缩技术,试图在可接受的精度下,将模型压缩到极致。
- 软硬协同: 未来的AI框架和编译器(如PyTorch, TensorFlow, Jax)将更加智能,能够根据模型结构、硬件特性和用户目标,自动选择和转换最佳的数据类型组合,让开发者无需关心底层细节。
- 算法创新: 新的模型架构和训练算法也在不断涌现,它们天生就对低精度计算更加鲁棒。
总结: 从FP32到FP8,我们看到了一场AI计算领域关于精度、范围和效率的持续演进和权衡。没有一种数据类型是万能的“银弹”。理解它们的内在原理和适用场景,是在AI工程实践中打造高效、强大、可落地的模型的必备技能