在《unordered_map 和 unordered_set》 中提到过:
哈希是一种思想,通过哈希函数将数据转化为一个或多个整型 —— 映射关系;通过这种映射关系,可以做到以 O(1) 的时间复杂度查找数据。
本文即将介绍的 位图 和 布隆过滤器 就是两个非常典型的哈希思想的应用成果,可以在应对海量数据问题 且 做到极大程度节省空间的同时,快速判断 一个整型 和 一个字符串 是否在 位图 和 布隆过滤器 中。
一、位图
1.1 位图的概念
在直接给出位图的概念之前,我们先温习几个常识:
-
1 int == 4 byte;
-
1 byte == 8 bit ——> 1 int == 32 bit
也就是说,假设我们有 10 个位于 [0, 32) 的整数,仅需 1 个 int 就可以将这些数据标记(在保证数据范围的情况下,即使数据量更大一些也没问题)。

位图的概念:
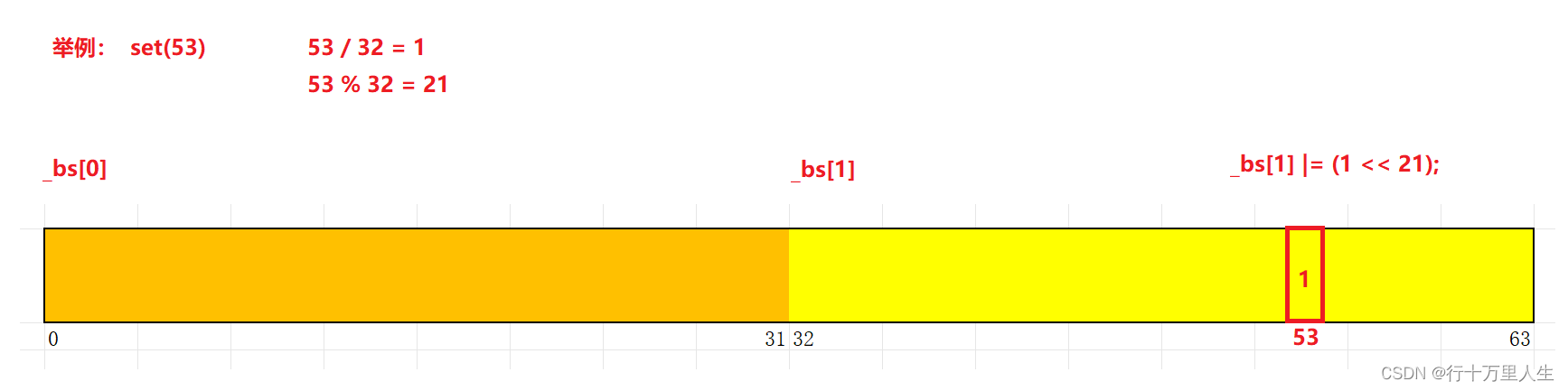
各个比特位上的数据默认为 0 —— 不存在,遍历数据的过程中,将数据对应位置的 0 修改为 1 —— 存在;再判断某个整数是否存在时,仅须根据其对应位置上的状态(0 或 1)即可得出。
图中 “53 在 32 右边” 的情形并不绝对,与机器的大小端有关。无论你的设备是大端机还是小端机,“1 << 21” —— 左移 都能保证把 “1” 往数据高位移动。

进一步延伸,面对这样一个场景:
给40亿个不重复的无符号整数,没排过序。给一个无符号整数,如何快速判断一个数是否在这40亿个数中。
试图通过 排序 + 二分 的办法解决,显然不靠谱 —— 存下 40 亿个整数大约 16 GB 内存。
在 面对海量整型数据,判断某个整数存在与否 的场景下,位图具有无可比拟的优势 —— 占用的空间小且能够快速查找。
一个非常重要的问题:位图应该开多大的空间? 具体要开多大,不是由数据的个数决定,而是由数据的范围决定。
代码:
template<size_t N> // 非类型模板参数class bitset {public:bitset(){_bs.resize(N/32 + 1); // 开 (N/32 + 1) 个 int 类型空间}void set(size_t n) // 将 n 对应的位置状态修改为 1{size_t i = n / 32;size_t j = n % 32;_bs[i] |= (1 << j);}void reset(size_t n) // 将 n 对应的位置状态修改为 0{size_t i = n / 32;size_t j = n % 32;_bs[i] &= ~(1 << j);}bool test(size_t n) // 判断 n 是否存在{size_t i = n / 32;size_t j = n % 32;return _bs[i] & (1 << j);}private:vector<int> _bs;};
位图代码逻辑本身很简单,诸位读者要理解各个函数中位运算的经义。
PS: STL 库中 bitset 是在栈区上开空间,我们实现的位图在堆区上开空间。
1.2 切分思想
还是上面那个的场景(40 亿个不重复整数),我们进一步对可使用内存的大小进行限制 —— 只能使用 256 MB 。
这会带来一个结果:我们无法一次性把这么多整数存入位图 —— 40 亿个不重复整数大约 500 MB。
把这 40 亿个整数分成两个区间:[0, 2 ^ 31) 和 [2 ^ 31, 2 ^ 32) 。(2 ^ 31 与 2 ^ 32 均为数学运算,C++ 中 ^ 为 异或)
先对 [0, 2 ^ 31) 范围内的整数进行 set() 和 test() ,处理完后将位图置空,再处理 [2 ^ 31, 2 ^ 32) 部分。