CatBoost(Categorical Boosting,类别提升)总结梳理
它是基于梯度提升决策树(GBDT) 的改进算法,核心优势是原生支持类别特征处理(无需手动编码)和降低过拟合风险,兼顾易用性和性能。
没用过该模型,简单看了下原文:https://arxiv.org/pdf/1706.09516
总结一下:catboost以默认均值或自定义值初始化模型预测结果,通过类别特征自动编码(如目标编码) 处理非数值特征,迭代构建决策树时用梯度提升框架计算样本梯度与二阶导数确定分裂节点,结合防止过拟合策略(如正则化、早停) 优化每棵树,最终将所有树的预测结果加权求和得到最终输出。(用改进的目标编码简化类别特征处理,用排序增强降低过拟合,同时保持梯度提升的高精度)
一、CatBoost 的核心原理
CatBoost 本质是「梯度提升框架」的优化版本,在保留 GBDT“迭代纠错、加法模型” 核心逻辑的基础上,解决了传统 GBDT 的两大痛点:类别特征处理繁琐、梯度估计偏差导致过拟合。其核心原理可拆解为 3 个关键机制:
1. 1 原生处理类别特征:改进的目标编码(Target Encoding)
传统 GBDT(如 XGBoost)处理类别特征时,需手动做「独热编码」(低基数类别)或「标签编码」(高基数类别),但独热编码会导致维度爆炸,标签编码会引入无关顺序关系(如 “颜色 = 红 / 蓝 / 绿” 编码为 1/2/3,模型会误判 “绿 > 蓝 > 红”)。
CatBoost 直接内置了类别特征的目标编码,无需手动预处理,核心逻辑是: 用「类别对应的目标值统计信息」替代类别标签,同时通过「贝叶斯平滑」避免过拟合。具体步骤如下:
-
对某个类别特征 C 的取值 c,计算该取值下所有样本的目标值均值(如分类任务中 “正例占比”,回归任务中 “目标值平均”);
-
为避免 “小样本类别” 的均值波动过大(如某个类别只有 1 个样本,均值 = 该样本目标值,易过拟合),加入贝叶斯平滑项,公式如下:
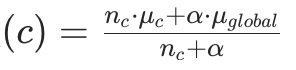 其中:
其中::类别 c 的样本数量;
:类别 c 的目标值均值;
:所有样本的目标值全局均值(先验信息);
:平滑系数(控制先验的权重,
-
训练中,CatBoost 会自动为每个类别特征选择最优的编码方式(无需手动指定平滑系数
1. 2 降低过拟合:排序增强(Ordered Boosting)
传统 GBDT 计算梯度时,会用「当前轮所有样本的预测值」来估计每个样本的梯度,这会导致梯度估计偏差(相当于 “用未来信息拟合当前模型”),进而增加过拟合风险。
CatBoost 提出「排序增强」(Ordered Boosting)来修正这一偏差,核心逻辑是:
- 对每轮训练的样本,随机打乱后分成多个「有序子集」(或按索引顺序);
- 计算某个样本的梯度时,仅用该样本之前的子集的预测值(而非所有样本),模拟 “在线学习” 的场景,避免 “看全数据” 的偏差;
- 通过多轮随机排序,进一步降低随机性带来的波动,最终得到更稳健的梯度估计,从根源减少过拟合。
1. 3 基础框架:梯度提升的延续
CatBoost 仍遵循 GBDT 的核心逻辑 ——迭代生成弱分类器(决策树),每棵树拟合前序模型的残差梯度,最终将所有树的预测值加权求和。与 XGBoost 类似,它也支持:
- 二阶导数优化:用目标函数的二阶导数(Hessian)提升拟合精度(比传统 GBDT 仅用一阶导数更高效);
- 正则化:通过「树深度限制(depth)」「L2 正则(l2_leaf_reg)」「子样本采样(bagging_temperature)」进一步抑制过拟合;
- 缺失值处理:自动学习缺失值的分裂方向(无需手动填充)。
二、CatBoost 流程
2. 1 总结一下
以梯度提升为基础,先对类别特征做贝叶斯平滑的目标编码,再通过 “排序增强” 修正梯度偏差,迭代训练决策树(每棵树拟合前序模型的残差梯度),最终将所有树的预测值加权求和得到结果。
2. 2 分步详细流程
步骤 1:数据准备与初始化
- 识别并指定类别特征(通过
cat_features参数,CatBoost 会自动处理,无需手动编码); - 初始化「初始模型」:通常为所有样本的目标值全局均值(回归任务)或正例占比(二分类任务),记为
(i 为样本索引,0 表示第 0 轮,无树)。
步骤 2:迭代训练决策树(核心环节,共 M 轮)
对每一轮 m(生成第 m 棵树):
-
计算梯度与二阶导数: 基于当前模型的预测值
,用「排序增强」计算每个样本的负梯度(作为 “残差”,即模型需要修正的方向)和二阶导数(用于优化拟合精度):
- 梯度
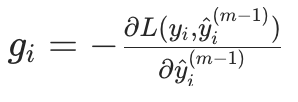 (L 为损失函数,如 MSE、LogLoss);
(L 为损失函数,如 MSE、LogLoss); - 二阶导数
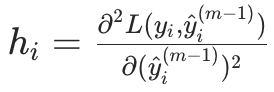
- 梯度
-
构建第 m 棵决策树:
- 对数值特征:按传统方式(如信息增益、基尼系数)寻找最优分裂点;
- 对类别特征:用「目标编码值」替代类别标签后,再寻找分裂点(无需手动处理);
- 分裂时兼顾正则化(如限制树深度、最小叶子样本数),避免树过复杂。
-
计算叶子节点最优权重: 对第 m 棵树的每个叶子节点 j,用梯度和二阶导数计算其最优输出权重
(目标是最小化当前轮的损失),公式与 XGBoost 类似(加入 L2 正则):
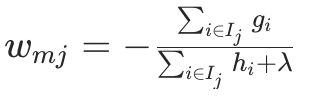 其中
其中是叶子节点 j 包含的样本集合,
是 L2 正则系数(
l2_leaf_reg)。 -
更新模型预测值: 用第 m 棵树的预测值(样本 i 落入叶子的权重
(控制每棵树的贡献,避免过拟合),更新样本 i 的预测值:
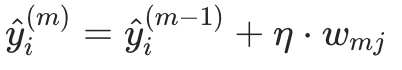
步骤 3:早停(可选,关键正则化手段)
- 训练中划分「验证集」,每轮训练后计算验证集的损失;
- 若连续 k 轮(
early_stopping_rounds)验证集损失不再下降,则停止迭代(避免训练过多树导致过拟合)。
步骤 4:最终预测
所有 M 棵树训练完成后,样本 i 的最终预测值为初始模型加上所有树的预测值之和:
![]()
(分类任务中,需对最终预测值做 sigmoid(二分类)或 softmax(多分类)转换,得到概率)。
三、CatBoost 的核心作用与应用场景
CatBoost 的价值在于降低使用门槛和提升模型稳健性,具体作用和场景如下:
3. 1 核心作用
- 简化类别特征处理:无需手动做独热编码、标签编码或特征交叉,原生支持高基数类别特征(如用户 ID、商品 ID),大幅减少数据预处理工作量;
- 降低过拟合风险:通过排序增强、L2 正则、早停、子样本采样等机制,比传统 GBDT 更难过拟合,模型泛化能力更强;
- 易用性高:API 简洁(与 scikit-learn 兼容),默认参数表现优秀(新手无需大量调参即可得到不错结果);
- 性能均衡:支持 CPU/GPU 加速,处理大数据(千万级样本)时效率不逊于 LightGBM,同时精度与 XGBoost 相当。
3. 2 典型应用场景
- 类别特征丰富的任务: 如电商用户画像(性别、职业、地区、购买渠道)、金融风控(学历、婚姻状态、贷款类型)、推荐系统(用户标签、商品分类)—— 这些场景中类别特征占比高,CatBoost 可直接处理,无需额外编码。
- 对过拟合敏感的场景: 如小样本数据(医疗诊断、稀有事件预测)—— 排序增强能有效修正梯度偏差,减少小样本下的过拟合。
- 快速迭代的业务场景: 如 A/B 测试、临时数据分析 —— 默认参数效果好,无需复杂调参,可快速产出模型结果。
四、一些记录
4. 1 概念方面
-
CatBoost 不是 “只处理类别特征”: 它对数值特征的处理与 XGBoost 一致,只是类别特征是其核心优势;若数据全是数值特征,CatBoost 仍可使用,且过拟合风险更低。
-
排序增强 vs 传统 GBDT 的梯度计算: 传统 GBDT 用 全量样本的预测值 算梯度(有偏差),CatBoost 用 部分样本的预测值 算梯度(无偏差)—— 这是 CatBoost 过拟合少的核心原因,务必理解 “偏差修正” 的逻辑。
-
目标编码 vs 独热编码: 独热编码适合低基数类别(如性别:男 / 女),但高基数类别(如职业:100 + 种)会导致维度爆炸;目标编码用 “目标值均值” 压缩维度,且贝叶斯平滑避免了小样本类别过拟合 —— 这是 CatBoost 处理高基数类别的关键。
4. 2 参数调优
| 参数名 | 作用 | 调优建议 |
|---|---|---|
cat_features | 指定类别特征列(核心!必须手动指定) | 传入类别特征的列名 / 索引(如 ['gender', 'city']) |
learning_rate | 学习率(控制每棵树的贡献) | 默认 0.03,小学习率(0.01-0.1)需配合多树,大学习率(0.1-0.3)训练快但易过拟合 |
depth | 树的最大深度(控制树复杂度) | 默认 6,小数据设 3-5,大数据设 6-10(避免过深) |
l2_leaf_reg | L2 正则系数(抑制叶子权重过大) | 默认 3,过拟合时增大(5-10),欠拟合时减小(1-2) |
early_stopping_rounds | 早停轮数(防止过拟合) | 设为 50-100,验证集损失连续 N 轮不降则停止 |