机器学习 - Kaggle项目实践(5)Quora Question Pairs 文本相似
Quora Question Pairs | Kaggle
Quora Question Pairs 文本相似 | Kaggle
问题背景 Quora 这个平台有上万条问题,人们有时提的问题意思是相近重复的。
目标:给两个问题,返回他们俩重复/意思相近的概率。(进而可以提高用户看帖子的效率 筛选出好问题)
NLP自然语言处理问题:
1. 做EDA分析时 围绕特殊字符,问题text长度,云图等。
2. 句子特征转换 帮助分析两个问句相似性 这里用到公共单词比例+TF-IDF向量化余弦相似度。
3. 平衡划分数据集后,调用XGBoost模型。
1. 数据导入和缺失值填充
import numpy as np
import pandas as pddf_train = pd.read_csv('/kaggle/input/quora-question-pairs/train.csv.zip')
display(df_train.head())
df_test = pd.read_csv('/kaggle/input/quora-question-pairs/test.csv')
display(df_test.head())for col in ['question1','question2']:df_train[col] = df_train[col].fillna('').astype(str)df_test[col] = df_test[col].fillna('').astype(str)2. EDA 探索性数据分析
(1)问题的字符长度和以及单词数目和:
import matplotlib.pyplot as plt
import seaborn as sns
%matplotlib inline
pal = sns.color_palette() # 颜色train_qs = pd.Series(df_train['question1'].tolist() + df_train['question2'].tolist()).astype(str)
test_qs = pd.Series(df_test['question1'].tolist() + df_test['question2'].tolist()).astype(str)dist_train = train_qs.apply(len) # apply长度
dist_test = test_qs.apply(len)
plt.figure(figsize=(15, 10)) # 直方图
plt.hist(dist_train, bins=200, range=[0, 200], color=pal[2], density=True, label='train')
plt.hist(dist_test, bins=200, range=[0, 200], color=pal[1], density=True, alpha=0.5, label='test')
plt.legend()print('mean-train {:.2f} mean-test {:.2f} max-train {:.2f} max-test {:.2f}'.format(dist_train.mean(), dist_test.mean(),dist_train.max(), dist_test.max())) # 均值 最大值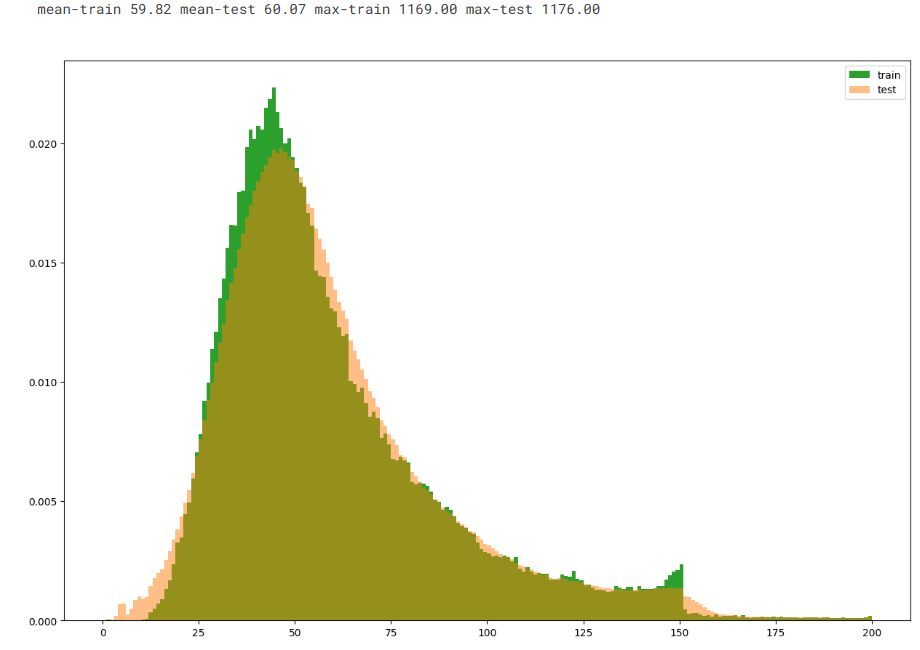
dist_train = train_qs.apply(lambda x: len(x.split(' ')))
dist_test = test_qs.apply(lambda x: len(x.split(' ')))plt.figure(figsize=(15, 10))
plt.hist(dist_train, bins=50, range=[0, 50], color=pal[2], density=True, label='train')
plt.hist(dist_test, bins=50, range=[0, 50], color=pal[1], density=True, alpha=0.5, label='test')
plt.legend()print('mean-train {:.2f} std-train {:.2f} mean-test {:.2f} std-test {:.2f} max-train {:.2f} max-test {:.2f}'.format(dist_train.mean(), dist_train.std(), dist_test.mean(), dist_test.std(), dist_train.max(), dist_test.max()))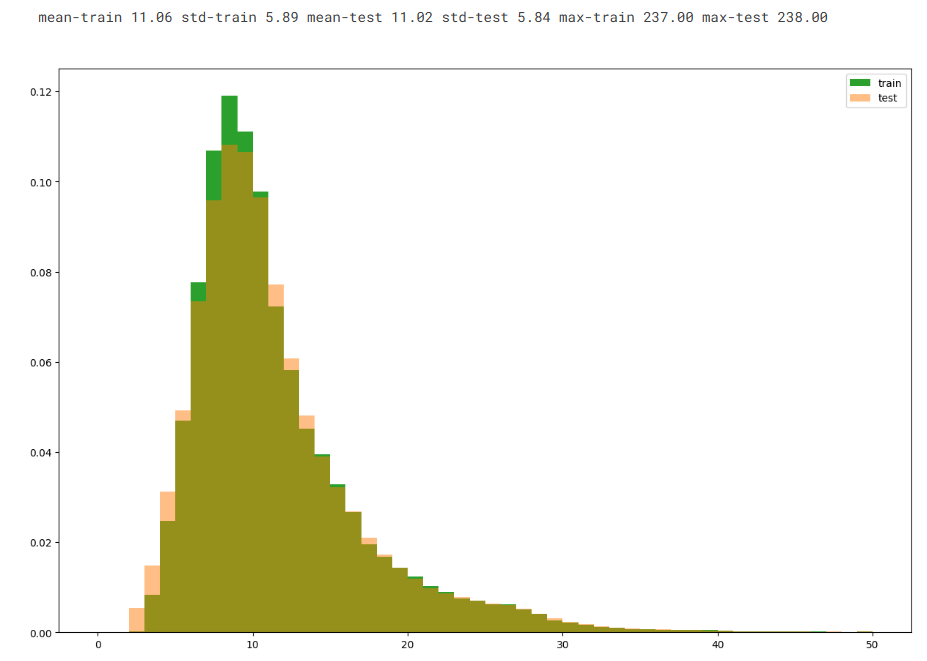
可见字符数在25-100居多 单词数在5-20居多
(2)词汇云图 看哪些词经常出现
from wordcloud import WordCloud
cloud = WordCloud(width=1440, height=1080).generate(' '.join(train_qs.astype(str)))
plt.figure(figsize=(20, 15))
plt.imshow(cloud)
plt.axis('off')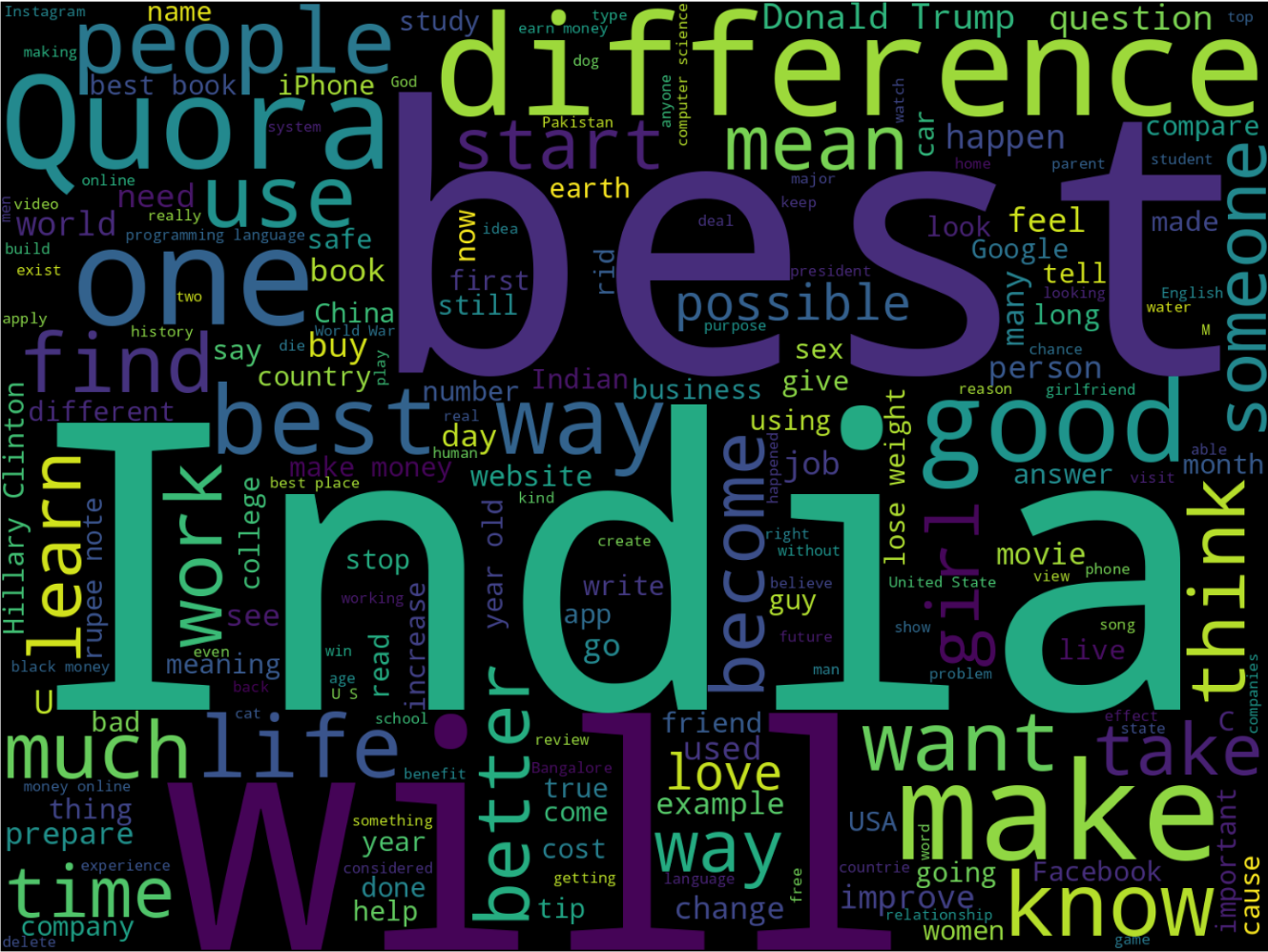
(3)特殊符号 语义分析
问号 句号 数学符号 数字;这些符号反映类别
qmarks = np.mean(train_qs.apply(lambda x: '?' in x)) # 包含问号的问题比例
math = np.mean(train_qs.apply(lambda x: '[math]' in x)) # 包含数学标签的问题比例
fullstop = np.mean(train_qs.apply(lambda x: '.' in x)) # 包含句号的问题比例
numbers = np.mean(train_qs.apply(lambda x: max([y.isdigit() for y in x],default=False))) # 包含数字的比例print('Questions with question marks: {:.2f}%'.format(qmarks * 100))
print('Questions with [math] tags: {:.2f}%'.format(math * 100))
print('Questions with full stops: {:.2f}%'.format(fullstop * 100))
print('Questions with numbers: {:.2f}%'.format(numbers * 100))发现基本都带问号 少量带数字。

3. 句子转化 特征选取
特征一:两句话公共单词的比例
先去除停用词;再分别计算两句话中 也属于对方的单词数,进而计算出公共比例。
def word_match_share(row): # 公共单词比例q1words = {}q2words = {}for word in str(row['question1']).lower().split():if word not in stops: # 移除停用词q1words[word] = 1for word in str(row['question2']).lower().split():if word not in stops: # 移除停用词q2words[word] = 1if len(q1words) == 0 or len(q2words) == 0:return 0# 计算共享单词比例shared_words_in_q1 = [w for w in q1words.keys() if w in q2words]shared_words_in_q2 = [w for w in q2words.keys() if w in q1words]R = (len(shared_words_in_q1) + len(shared_words_in_q2))/(len(q1words) + len(q2words))return Rfrom nltk.corpus import stopwords
stops = set(stopwords.words("english")) # 停用词
df_train['word_match'] = df_train.apply(word_match_share, axis=1)
df_test['word_match'] = df_test.apply(word_match_share, axis=1)# 绘图
plt.figure(figsize=(15, 5))
plt.hist(df_train['word_match'][df_train['is_duplicate'] == 0], bins=20, density=True, label='Not Duplicate')
plt.hist(df_train['word_match'][df_train['is_duplicate'] == 1], bins=20, density=True, alpha=0.7, label='Duplicate')
plt.legend()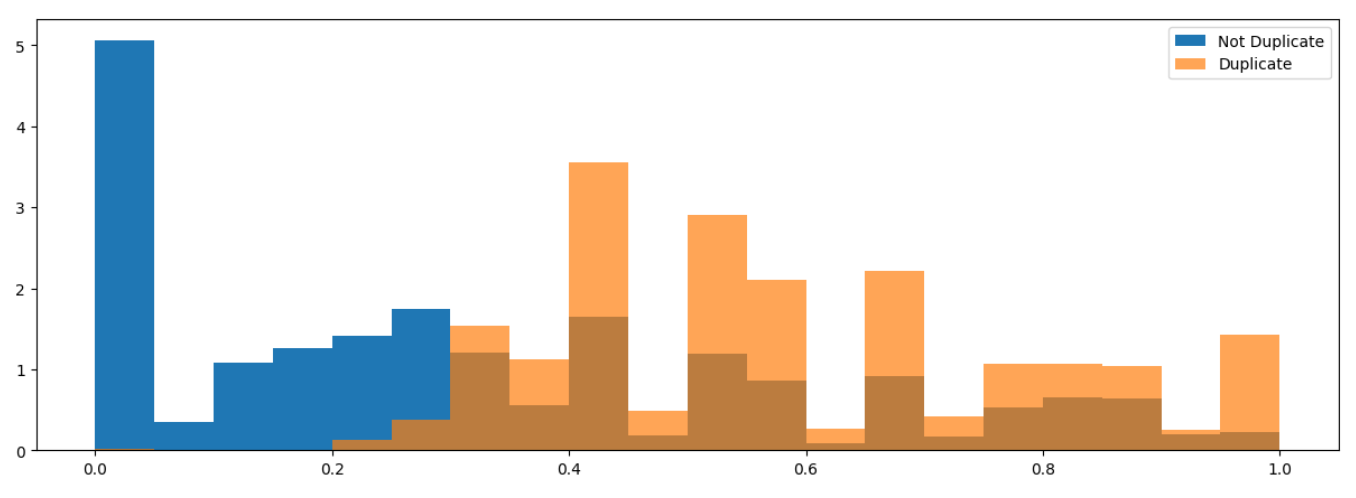
特征二:对两个问题做 TF-IDF 转换后计算余弦相似度
from sklearn.feature_extraction.text import TfidfVectorizerall_questions = pd.Series(df_train['question1'].tolist() + df_train['question2'].tolist() +df_test['question1'].tolist() + df_test['question2'].tolist()).astype(str)tfidf = TfidfVectorizer(ngram_range=(1,1), min_df=3, stop_words='english') # 每个单词为一组 至少出现3次
tfidf.fit(all_questions)# transform
q1_train_tfidf = tfidf.transform(df_train['question1'])
q2_train_tfidf = tfidf.transform(df_train['question2'])
q1_test_tfidf = tfidf.transform(df_test['question1'])
q2_test_tfidf = tfidf.transform(df_test['question2'])每行每两个问题计算向量余弦值 a.multiply(b) 逐元素乘法;
.sum(axis=1)逐元素乘积矩阵按行求和; .A1 将其扁平化为 1维数组
分母为 二范数 自己内积得到平方 再求和开根
# 逐行计算稀疏矩阵的余弦相似度
def cosine_sim_sparse(a, b):num = a.multiply(b).sum(axis=1).A1 # 点积denom = np.sqrt(a.multiply(a).sum(axis=1).A1) * np.sqrt(b.multiply(b).sum(axis=1).A1) # 分母范数denom = np.where(denom == 0, 1e-9, denom) # 防止分母为0;分母为0 就换成1e-9return num / denomdf_train['tfidf_cosine'] = cosine_sim_sparse(q1_train_tfidf, q2_train_tfidf)
df_test['tfidf_cosine'] = cosine_sim_sparse(q1_test_tfidf, q2_test_tfidf)4. 平衡&划分训练集
组合两个特征 + 准备数据集
feature_cols = ['word_match', 'tfidf_cosine']
X = df_train[feature_cols].fillna(0)
X_test = df_test[feature_cols].fillna(0)
y = df_train['is_duplicate'].valuestrick:重新平衡数据集(竞赛技巧)
通过之前的提交发现 测试集正样本比例大概为 p=0.165;而我们的训练集比例约为0.37
希望模型预测概率更匹配某个目标分布,复制负样本 使得训练集正样本比例接近 p
拆成 pos 和 neg;复制neg;再把新的pos和neg拼接;再进行训练集划分
pos = X[y == 1]
neg = X[y == 0]p = 0.165 # 目标正样本比例
scale = ((len(pos) / (len(pos) + len(neg))) / p) - 1
# 扩倍复制 neg
while scale > 1:neg = pd.concat([neg, neg])scale -= 1
if scale > 0:neg = pd.concat([neg, neg[:int(scale * len(neg))]])X_bal = pd.concat([pos, neg])
y_bal = np.concatenate([np.ones(len(pos)), np.zeros(len(neg))])from sklearn.model_selection import train_test_split
X_train, X_valid, y_train, y_valid = train_test_split(X_bal, y_bal, test_size=0.2, random_state=4242, shuffle=True)5. 调用XGBoost训练
xgb.DMatrix 是 XGBoost 优化的数据格式
设置参数 二分类问题,损失指标,树深度,学习率。
watchlist:指定需要监控的数据集,这里同时监控训练集和验证集
num_boost_round=400:最大 boosting 轮数(树的数量)
early_stopping_rounds=50:早停机制 - 如果验证集性能在连续50轮内没有提升,就停止训练
verbose_eval=10:每10轮输出一次评估结果
from sklearn.metrics import log_loss, roc_auc_score
import xgboost as xgbparams = {'objective': 'binary:logistic', # 二分类问题,输出概率'eval_metric': 'logloss', # 评估指标:对数损失'eta': 0.02, # 学习率(步长收缩)'max_depth': 4, # 树的最大深度'seed': 4242, # 随机种子(确保结果可重现)'silent': 1 # 静默模式(不输出训练信息)
}d_train = xgb.DMatrix(X_train, label=y_train) # 训练集
d_valid = xgb.DMatrix(X_valid, label=y_valid) # 验证集watchlist = [(d_train, 'train'), (d_valid, 'valid')]
bst = xgb.train(params, d_train, num_boost_round=400, evals=watchlist,early_stopping_rounds=50, verbose_eval=10)# 最终验证集损失评估
p_valid = bst.predict(d_valid)
print("Validation logloss:", log_loss(y_valid, p_valid))
print("Validation AUC:", roc_auc_score(y_valid, p_valid))6. 预测并保存结果
d_test = xgb.DMatrix(X_test)
p_test = bst.predict(d_test)sub = pd.DataFrame()
sub['test_id'] = df_test['test_id']
sub['is_duplicate'] = p_test
sub.to_csv('submission.csv', index=False)