实验4:列表与字典应用
目的 :熟练操作组合数据类型。
试验任务:
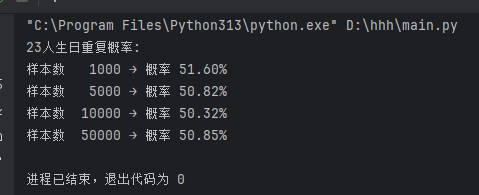
1. 基础:生日悖论分析。如果一个房间有23 人或以上,那么至少有两个人的生日相同的概率大于50%。编写程序,输出在不同随机样本数量下,23 个人中至少两个人生日相同的概率。
测试代码如下:
import randomdef birthday_paradox(sample_size=10000, num_people=23):matches = 0for _ in range(sample_size):birthdays = [random.randint(1, 365) for _ in range(num_people)]if len(birthdays) != len(set(birthdays)):matches += 1return matches / sample_sizesample_sizes = [1000, 5000, 10000, 50000]
print("23人生日重复概率:")
for size in sample_sizes:prob = birthday_paradox(size)print(f"样本数 {size:6} → 概率 {prob:.2%}")
运行截图如下:
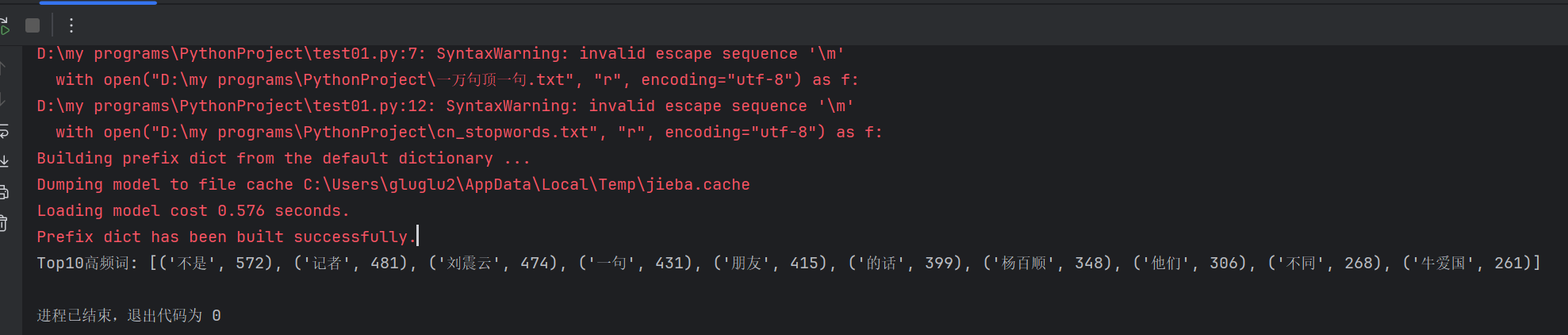
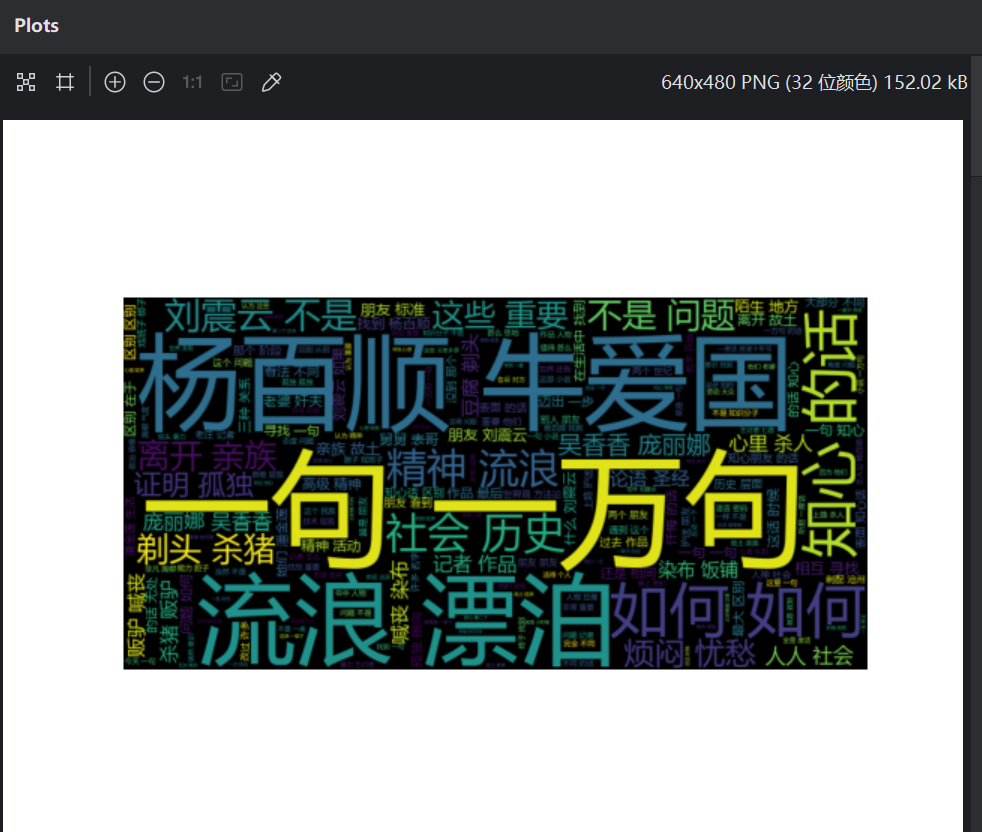
2. 进阶:统计《一句顶一万句》文本中前10 高频词,生成词云。
测试代码如下:
import jieba
from collections import Counter
from wordcloud import WordCloud
import matplotlib.pyplot as plt# 读取文本并分词
with open("一万句顶一句.txt", "r", encoding="utf-8") as f:text = f.read()
words = jieba.lcut(text)# 加载停用词表
with open("cn_stopwords.txt", "r", encoding="utf-8") as f:stopwords = set(f.read().splitlines())# 清洗数据并统计词频
cleaned_words = [w for w in words if len(w) > 1 and w not in stopwords]
word_counts = Counter(cleaned_words).most_common(10)
print("Top10高频词:", word_counts)# 生成词云
wc = WordCloud(font_path="msyh.ttc", width=800, height=400)
wc.generate(" ".join(cleaned_words))
plt.imshow(wc)
plt.axis("off")
plt.show()运行截图如下:
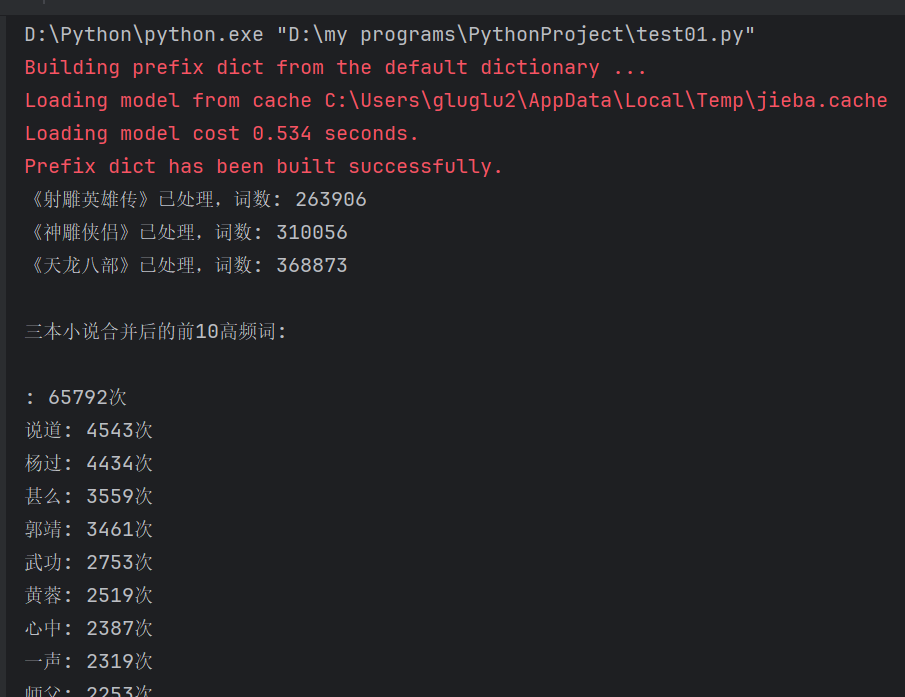
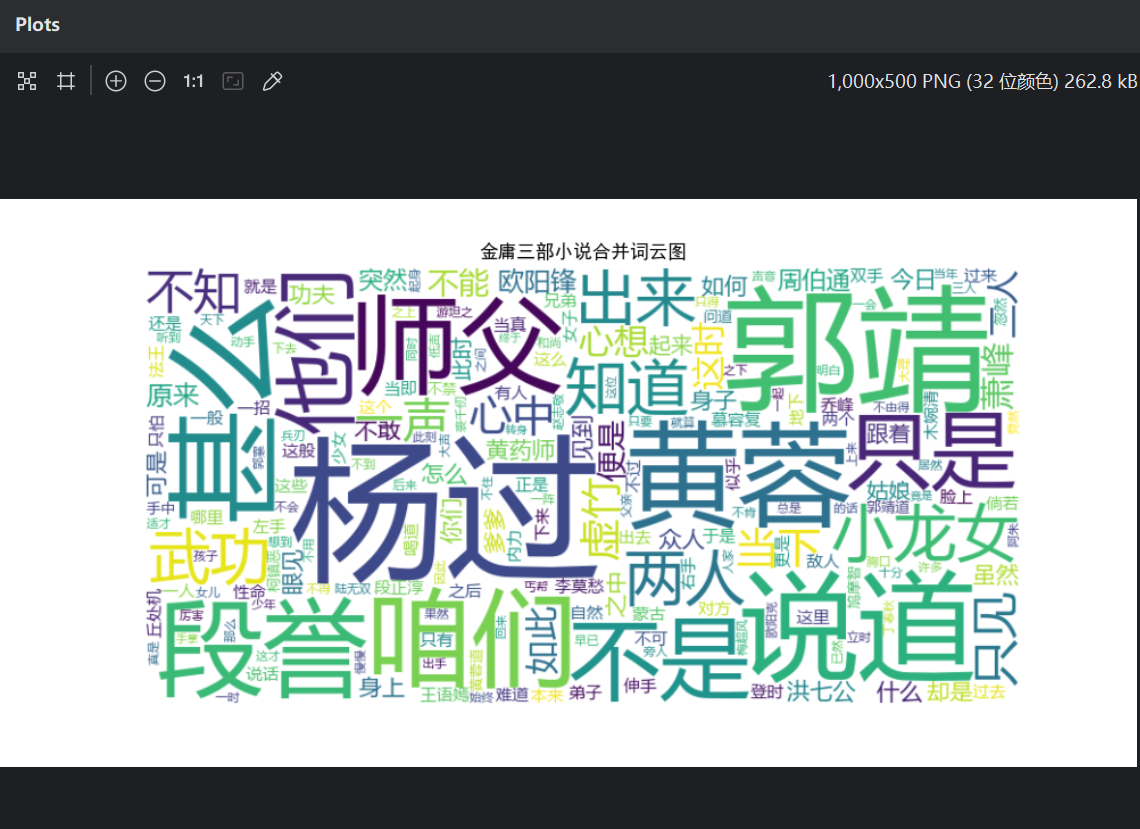
3. 拓展:金庸、古龙等武侠小说写作风格分析。输出不少于3 个金庸(古龙)作品的最常用10 个词语,找到其中的相关性,总结其风格。
测试代码如下:
import jieba
from collections import Counter
from wordcloud import WordCloud
import matplotlib.pyplot as plt
import os# 设置中文字体
plt.rcParams['font.sans-serif'] = ['SimHei']# 加载停用词表
with open("cn_stopwords.txt", "r", encoding="utf-8") as f:stopwords = set(f.read().splitlines())def read_file_safely(filepath):"""安全读取可能编码异常的文件"""with open(filepath, 'rb') as f:raw = f.read()# 尝试常见中文编码encodings = ['gb18030', 'gbk', 'utf-8', 'big5']for enc in encodings:try:return raw.decode(enc)except UnicodeDecodeError:continue# 最后尝试用gb18030并替换错误字符return raw.decode('gb18030', errors='replace')def analyze_novels(novel_files):all_words = []for file in novel_files:title = os.path.splitext(os.path.basename(file))[0]try:content = read_file_safely(file)words = jieba.lcut(content)cleaned_words = [w for w in words if len(w) > 1 and w not in stopwords]all_words.extend(cleaned_words)print(f"《{title}》已处理,词数: {len(cleaned_words)}")except Exception as e:print(f"处理文件 {file} 时出错: {str(e)}")continueif not all_words:print("错误:没有可分析的文本内容")return None# 统计词频total_counts = Counter(all_words).most_common(10)print("\n三本小说合并后的前10高频词:")for word, count in total_counts:print(f"{word}: {count}次")# 生成词云wc = WordCloud(font_path="msyh.ttc",width=800,height=400,background_color='white',max_words=200)wc.generate(" ".join(all_words))plt.figure(figsize=(10, 5))plt.imshow(wc, interpolation='bilinear')plt.axis("off")plt.title("金庸三部小说合并词云图")plt.show()return dict(total_counts)novel_files = [r"射雕英雄传.txt",r"神雕侠侣.txt",r"天龙八部.txt"
]# 检查文件是否存在
for file in novel_files:if not os.path.exists(file):print(f"错误:文件 {file} 不存在")exit()total_results = analyze_novels(novel_files)运行截图如下: