人工智能-python-深度学习-反向传播优化算法
文章目录
- 1. 前向传播(Forward Propagation)
- 数学表达式:
- 作用:
- 2. 反向传播(Backpropagation)
- 过程描述:
- 数学描述:
- 3. 梯度下降算法
- 传统梯度下降方式:
- 存在的问题:
- 4. 优化下降方式
- 1. **Momentum(动量法)**:
- 2. **AdaGrad**:
- 3. **RMSProp**:
- 4. **Adam(自适应矩估计)**:
- 5. 总结
1. 前向传播(Forward Propagation)
前向传播是神经网络中的第一步,主要目的是通过输入数据计算模型的输出。通过每层的加权和以及激活函数,数据逐层传递,最终产生预测结果。
数学表达式:
-
输入层到隐藏层:
假设输入层为 x\mathbf{x}x,权重为 W\mathbf{W}W,偏置为 b\mathbf{b}b,隐藏层的激活函数为 f(⋅)f(\cdot)f(⋅),则第 hhh 个隐藏层的输出 h\mathbf{h}h 可以表示为:
h=f(Wx+b)\mathbf{h} = f(\mathbf{W} \mathbf{x} + \mathbf{b}) h=f(Wx+b)
这里的加权和 Wx+b\mathbf{W} \mathbf{x} + \mathbf{b}Wx+b 就是输入数据与网络权重的线性组合,激活函数则将其映射到新的空间。
-
隐藏层到输出层:
输出层的计算则是从隐藏层输出 h\mathbf{h}h 决定的:
ypred=g(W′h+b′)\mathbf{y_{pred}} = g(\mathbf{W'} \mathbf{h} + \mathbf{b'}) ypred=g(W′h+b′)
输出层的激活函数 g(⋅)g(\cdot)g(⋅) 取决于任务类型。例如,对于分类任务,可能使用 softmax,对于回归任务,可能使用 线性激活函数。
作用:
前向传播的目的是从输入数据得到预测结果。这些预测结果将用于计算损失函数,并在反向传播中进行梯度计算。它是神经网络的基础部分,为后续的误差传递和优化奠定了基础。
2. 反向传播(Backpropagation)

反向传播是神经网络中非常重要的步骤,它的目的是计算每一层的梯度(即损失函数相对于每层权重的偏导数),并通过梯度下降优化网络参数。
反向传播的关键是通过 链式法则,逐层计算从输出到输入的梯度。这样,神经网络就能够调整每一层的权重,最小化损失函数。
过程描述:
-
计算损失函数:首先,计算网络的输出和真实标签之间的误差。常用的损失函数包括 均方误差(MSE) 和 交叉熵损失(Cross-Entropy Loss)。
-
计算输出层梯度:通过计算损失函数对输出层的梯度,得到每个输出节点的误差。
-
反向传播计算梯度:使用链式法则,从输出层开始,逐层计算每个隐藏层的梯度。这些梯度反映了每一层的权重如何影响最终的输出。
-
更新权重和偏置:通过计算得到的梯度更新权重和偏置,优化网络。
数学描述:
梯度更新的基本公式是:
W=W−η∂L∂W\mathbf{W} = \mathbf{W} - \eta \frac{\partial L}{\partial \mathbf{W}} W=W−η∂W∂L
b=b−η∂L∂b\mathbf{b} = \mathbf{b} - \eta \frac{\partial L}{\partial \mathbf{b}} b=b−η∂b∂L
其中,η\etaη 是学习率,控制每次更新的步长,∂L∂W\frac{\partial L}{\partial \mathbf{W}}∂W∂L 和 ∂L∂b\frac{\partial L}{\partial \mathbf{b}}∂b∂L 分别是损失函数相对于权重和偏置的梯度。
3. 梯度下降算法
梯度下降算法是最常用的优化方法,其目的是最小化损失函数,更新网络参数。梯度下降的核心思想是沿着损失函数的负梯度方向调整参数,以减少模型的误差。
数学公式:
wijnew=wijold−α∂E∂wijw_{ij}^{new}= w_{ij}^{old} - \alpha \frac{\partial E}{\partial w_{ij}} wijnew=wijold−α∂wij∂E
其中,α\alphaα是学习率:
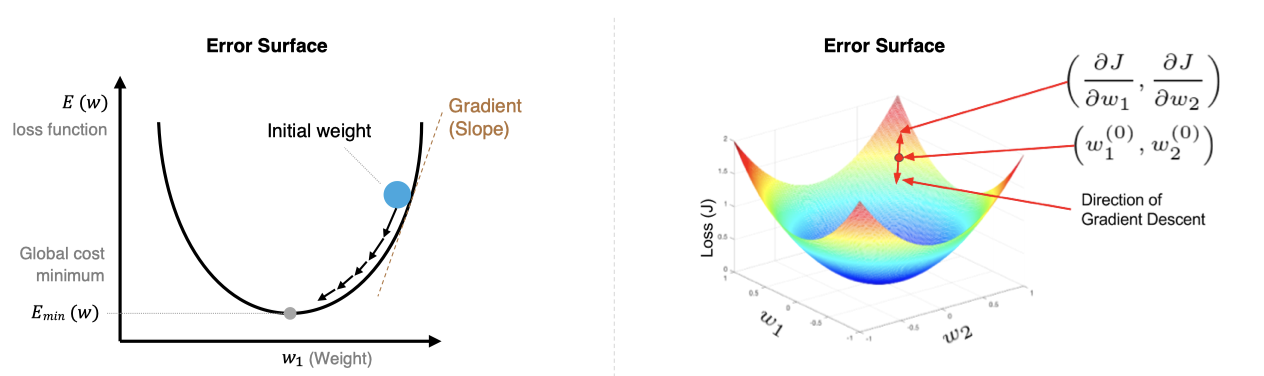
- 学习率太小,每次训练之后的效果太小,增加时间和算力成本。
- 学习率太大,大概率会跳过最优解,进入无限的训练和震荡中。
- 解决的方法就是,学习率也需要随着训练的进行而变化。
- 过程阐述:
-
初始化参数:随机初始化模型的参数 θ\theta θ,如权重 WWW和偏置 bbb。
-
计算梯度:损失函数 L(θ)L(\theta)L(θ)对参数 θ\thetaθ 的梯度 ∇θL(θ)\nabla_\theta L(\theta)∇θL(θ),表示损失函数在参数空间的变化率。
-
更新参数:按照梯度下降公式更新参数:θ:=θ−α∇θL(θ)\theta := \theta - \alpha \nabla_\theta L(\theta)θ:=θ−α∇θL(θ),其中,α\alphaα 是学习率,用于控制更新步长。
-
迭代更新:重复【计算梯度和更新参数】步骤,直到某个终止条件(如梯度接近0、不再收敛、完成迭代次数等)。
传统梯度下降方式:
- 批量梯度下降(Batch Gradient Descent):在每次更新时,使用整个训练集计算梯度。优点是梯度的估计较为精确,但缺点是计算量非常大,尤其是数据量非常大时,效率较低。
-
特点:
- 每次更新参数时,使用整个训练集来计算梯度。
-
优点:
- 收敛稳定,能准确地沿着损失函数的真实梯度方向下降。
- 适用于小型数据集。
-
缺点:
- 对于大型数据集,计算量巨大,更新速度慢。
- 需要大量内存来存储整个数据集。
-
公式:
θ=θ−α1m∑i=1m∇θL(y^(i),y(i))\theta = \theta - \alpha \frac{1}{m} \sum_{i=1}^{m} \nabla_\theta L(\hat{y}^{(i)}, y^{(i)}) θ=θ−αm1i=1∑m∇θL(y^(i),y(i))
其中,mmm 是训练集样本总数,x(i),y(i)x^{(i)}, y^{(i)} x(i),y(i)是第 iii 个样本及其标签,y^(i)\hat{y}^{(i)}y^(i)是第 iii 个样本预测值。
例如,在训练集中有100个样本,迭代50轮。
那么在每一轮迭代中,都会一起使用这100个样本,计算整个训练集的梯度,并对模型更新。
所以总共会更新50次梯度。
因为每次迭代都会使用整个训练集计算梯度,所以这种方法可以得到准确的梯度方向。
但如果数据集非常大,那么就导致每次迭代都很慢,计算成本就会很高。
示例:
x = torch.randn(1000, 10)y = torch.randn(1000, 1)dataset = TensorDataset(x, y)dataloader = DataLoader(dataset, batch_size=len(dataset))model = nn.Linear(10, 1)criterion = nn.MSELoss()optimizer = optim.SGD(model.parameters(), lr=0.01)epochs = 100for epoch in range(epochs):for b_x, b_y in dataloader:optimizer.zero_grad()output = model(b_x)loss = criterion(output, b_y)loss.backward()optimizer.step()print('Epoch %d, Loss: %f' % (epoch, loss.item()))
- 随机梯度下降(Stochastic Gradient Descent, SGD):每次更新时,使用一个样本计算梯度。这使得每次更新的速度非常快,适合大规模数据集,但每次梯度的估计波动较大,可能导致训练不稳定。
-
特点:
- 每次更新参数时,仅使用一个样本来计算梯度。
-
优点:
- 更新频率高,计算快,适合大规模数据集。
- 能够跳出局部最小值,有助于找到全局最优解。
-
缺点:
- 收敛不稳定,容易震荡,因为每个样本的梯度可能都不完全代表整体方向。
- 需要较小的学习率来缓解震荡。
-
公式:
θ=θ−α∇θL(y^(i),y(i))\theta = \theta - \alpha \nabla_\theta L(\hat{y}^{(i)}, y^{(i)}) θ=θ−α∇θL(y^(i),y(i))其中,x(i),y(i)x^{(i)}, y^{(i)}x(i),y(i) 是当前随机抽取的样本及其标签。
例如,如果训练集有100个样本,迭代50轮,那么每一轮迭代,会遍历这100个样本,每次会计算某一个样本的梯度,然后更新模型参数。
换句话说,100个样本,迭代50轮,那么就会更新100*50=5000次梯度。
因为每次只用一个样本训练,所以迭代速度会非常快。
但更新的方向会不稳定,这也导致随机梯度下降,可能永远都不会收敛。
不过也因为这种震荡属性,使得随机梯度下降,可以跳出局部最优解。
这在某些情况下,是非常有用的。
示例:
x = torch.randn(1000, 10)y = torch.randn(1000, 1)dataset = TensorDataset(x, y)dataloader = DataLoader(dataset, batch_size=1)model = nn.Linear(10, 1)criterion = nn.MSELoss()optimizer = optim.SGD(model.parameters(), lr=0.01)epochs = 100for epoch in range(epochs):for b_x, b_y in dataloader:optimizer.zero_grad()output = model(b_x)loss = criterion(output, b_y)loss.backward()optimizer.step()print('Epoch %d, Loss: %f' % (epoch, loss.item()))
- 小批量梯度下降(Mini-batch Gradient Descent):每次更新时,使用一小批样本计算梯度。它是批量梯度下降和随机梯度下降的折中方法,计算效率高,且能稳定收敛。
-
特点:
- 每次更新参数时,使用一小部分训练集(小批量)来计算梯度。
-
优点:
- 在计算效率和收敛稳定性之间取得平衡。
- 能够利用向量化加速计算,适合现代硬件(如GPU)。
-
缺点:
- 选择适当的批量大小比较困难;批量太小则接近SGD,批量太大则接近批量梯度下降。
- 通常会根据硬件算力设置为32\64\128\256等2的次方。
-
公式:
θ:=θ−α1b∑i=1b∇θL(y^(i),y(i))\theta := \theta - \alpha \frac{1}{b} \sum_{i=1}^{b} \nabla_\theta L(\hat{y}^{(i)}, y^{(i)}) θ:=θ−αb1i=1∑b∇θL(y^(i),y(i))
其中,bbb 是小批量的样本数量,也就是 batch_sizebatch\_sizebatch_size。
例如,如果训练集中有100个样本,迭代50轮。
如果设置小批量的数量是20,那么在每一轮迭代中,会有5次小批量迭代。
换句话说,就是将100个样本分成5个小批量,每个小批量20个数据,每次迭代用一个小批量。
因此,按照这样的方式,会对梯度,进行50轮*5个小批量=250次更新。
示例:
x = torch.randn(1000, 10)y = torch.randn(1000, 1)dataset = TensorDataset(x, y)# 小批量梯度下降,每批次100个样本dataloader = DataLoader(dataset, batch_size=100, shuffle=True)model = nn.Linear(10, 1)criterion = nn.MSELoss()optimizer = optim.SGD(model.parameters(), lr=0.01)epochs = 100for epoch in range(epochs):for b_x, b_y in dataloader:optimizer.zero_grad()output = model(b_x)loss = criterion(output, b_y)loss.backward()optimizer.step()print('Epoch %d, Loss: %f' % (epoch, loss.item()))
存在的问题:
-
局部最小值:在非凸的损失函数中,梯度下降容易陷入局部最小值,而不是全局最小值。
-
梯度消失/爆炸:在深度网络中,反向传播时的梯度可能变得非常小(消失)或非常大(爆炸),导致训练困难。
4. 优化下降方式
随着神经网络的复杂性增加,许多优化算法被提出以克服传统梯度下降法的问题。这些优化方法通过对每个参数的梯度进行调整,从而加速训练并提高收敛性。
1. Momentum(动量法):
动量法通过引入上一轮的梯度来调整当前的梯度,从而加速梯度下降并减少震荡。它的核心思想类似物理中的动量,当前的梯度不仅依赖于当前的误差,还依赖于之前的更新。
vt=βvt−1+(1−β)∇L(θ)v_t = \beta v_{t-1} + (1 - \beta) \nabla L(\theta) vt=βvt−1+(1−β)∇L(θ)
其中,vtv_tvt 是当前的动量,β\betaβ 是动量因子,通常接近 1。
2. AdaGrad:
AdaGrad通过自适应地调整每个参数的学习率,使得稀疏特征的学习率增大,频繁出现的特征学习率减小。这样可以避免在特定方向上学习过快。
θ=θ−ηGt+ϵ\theta = \theta - \frac{\eta}{\sqrt{G_t + \epsilon}} θ=θ−Gt+ϵη
其中,GtG_tGt 是梯度的累积平方和,ϵ\epsilonϵ 是防止除零错误的小常数。
3. RMSProp:
RMSProp改进了AdaGrad,通过引入指数加权平均来计算梯度的平方,从而避免了AdaGrad导致的学习率过快下降问题。它更适合处理非平稳的目标函数。
vt=βvt−1+(1−β)∇L(θ)2v_t = \beta v_{t-1} + (1 - \beta) \nabla L(\theta)^2 vt=βvt−1+(1−β)∇L(θ)2
4. Adam(自适应矩估计):
Adam结合了Momentum和RMSProp的优点,通过同时考虑梯度的一阶矩和二阶矩来调整学习率。它自适应地调整每个参数的学习率,非常适合大规模数据和复杂模型。
mt=β1mt−1+(1−β1)∇L(θ)m_t = \beta_1 m_{t-1} + (1 - \beta_1) \nabla L(\theta) mt=β1mt−1+(1−β1)∇L(θ)
vt=β2vt−1+(1−β2)∇L(θ)2v_t = \beta_2 v_{t-1} + (1 - \beta_2) \nabla L(\theta)^2 vt=β2vt−1+(1−β2)∇L(θ)2
mt^=mt1−β1t,vt^=vt1−β2t\hat{m_t} = \frac{m_t}{1 - \beta_1^t}, \quad \hat{v_t} = \frac{v_t}{1 - \beta_2^t} mt^=1−β1tmt,vt^=1−β2tvt
θ=θ−ηmt^vt^+ϵ\theta = \theta - \frac{\eta \hat{m_t}}{\sqrt{\hat{v_t}} + \epsilon} θ=θ−vt^+ϵηmt^
5. 总结
- 前向传播:神经网络的第一步,通过输入数据计算预测结果,为后续的反向传播提供基础。
- 反向传播:通过计算每层的梯度,逐层调整网络参数,使得模型误差最小化。
- 梯度下降优化:包括批量梯度下降、随机梯度下降和小批量梯度下降,解决了计算效率和收敛性的问题。
- 优化算法:Momentum、AdaGrad、RMSProp、Adam等优化算法,通过自适应调整学习率,进一步提高了神经网络训练的效率和效果。
通过这些方法,我们不仅能提高训练的速度,还能有效避免传统梯度下降的不足,如局部最小值、梯度消失等问题,从而实现更好的模型性能。