C++STL底层原理:探秘标准模板库的内部机制

🌟 Hello,我是蒋星熠Jaxonic!
🌈 在浩瀚无垠的技术宇宙中,我是一名执着的星际旅人,用代码绘制探索的轨迹。
🚀 每一个算法都是我点燃的推进器,每一行代码都是我航行的星图。
🔭 每一次性能优化都是我的天文望远镜,每一次架构设计都是我的引力弹弓。
🎻 在数字世界的协奏曲中,我既是作曲家也是首席乐手。让我们携手,在二进制星河中谱写属于极客的壮丽诗篇!
摘要
我始终被STL(标准模板库)的精妙设计所吸引。在我看来,STL就像是一座精密的钟表,表面简洁优雅,内部却蕴含着无数精巧的齿轮与机关。这些年来,我通过阅读源码、调试分析和实际应用,逐渐揭开了STL的神秘面纱。在本文中,我将带领大家深入STL的核心,探索其底层实现原理。我们将剖析容器的内存管理策略,理解迭代器的设计哲学,解密算法的效率奥秘,以及探讨分配器的工作机制。我希望能够帮助你不仅仅是使用STL,更能理解它,甚至在必要时改进它。STL的设计思想不仅仅是C++程序员的必修课,更是软件工程领域的瑰宝,它教会我们如何在通用性和效率之间找到平衡,如何用抽象设计解决复杂问题。让我们一起揭开STL的面纱,探索这个C++世界中最璀璨的明珠之一。
1. STL整体架构与设计哲学
1.1 STL的核心组件
STL(Standard Template Library,标准模板库)是C++标准库的核心部分,它提供了一套强大的、可复用的组件集合。STL的设计基于泛型编程范式,通过模板实现了算法与数据结构的分离。
// STL的基本使用示例
#include <vector>
#include <algorithm>
#include <iostream>int main() {std::vector<int> numbers = {5, 2, 8, 1, 9};std::sort(numbers.begin(), numbers.end()); // 使用STL算法for(const auto& num : numbers) { // 使用STL容器和迭代器std::cout << num << " ";}return 0;
}
// 关键点:这个简单示例展示了STL三大核心组件的协作:容器(vector)、算法(sort)和迭代器(begin/end)
STL的架构由六大组件构成,它们相互配合,形成了一个高效、灵活的编程框架:
图1:STL架构流程图 - 展示了STL的六大核心组件及其层次关系
1.2 设计哲学与原则
STL的设计哲学可以概括为以下几点:
- 泛型编程:通过模板实现类型无关的算法和数据结构
- 效率优先:零抽象惩罚原则,模板生成的代码效率接近手写代码
- 组件分离:算法与数据结构解耦,通过迭代器桥接
- 可扩展性:用户可以自定义容器、算法、迭代器等组件
“STL的设计目标是:提供足够通用的组件,使得这些组件不仅能够被广泛使用,而且使用起来非常高效。” —— Alexander Stepanov,STL的主要设计者
2. 容器的底层实现
2.1 序列容器实现原理
2.1.1 vector的实现
vector是最常用的STL容器之一,它在底层使用动态数组实现,提供了O(1)的随机访问性能。
// vector的简化实现
template <typename T, typename Allocator = std::allocator<T>>
class vector {
private:T* _start; // 指向数据的起始位置T* _finish; // 指向最后一个元素的下一个位置T* _end_of_storage; // 指向分配的内存末尾Allocator _alloc; // 内存分配器public:// 构造、析构、容量管理等方法...void push_back(const T& value) {if (_finish == _end_of_storage) {// 容量不足,需要重新分配size_type old_size = size();size_type new_size = old_size ? 2 * old_size : 1; // 容量翻倍增长策略T* new_start = _alloc.allocate(new_size);// 复制旧元素到新内存// 释放旧内存// 更新指针}_alloc.construct(_finish, value); // 在末尾构造新元素++_finish;}// 其他方法...
};
// 关键点:vector的核心是三个指针的管理,以及容量不足时的重新分配策略
vector的内存布局和增长策略可以用下图表示:
图2:vector内存管理时序图 - 展示了vector在添加元素时的内存分配与扩容过程
2.1.2 list的实现
list是双向链表的实现,它提供了O(1)的插入和删除操作,但不支持随机访问。
// list的简化实现
template <typename T, typename Allocator = std::allocator<T>>
class list {
private:struct node {node* prev;node* next;T data;};node* _head; // 头节点(哨兵节点)size_t _size;public:list() : _size(0) {_head = create_node(); // 创建哨兵节点_head->next = _head;_head->prev = _head;}void push_back(const T& value) {node* new_node = create_node(value);// 在尾部(哨兵节点之前)插入new_node->next = _head;new_node->prev = _head->prev;_head->prev->next = new_node;_head->prev = new_node;++_size;}// 其他方法...
};
// 关键点:list使用双向链表结构,通常采用环形设计并使用哨兵节点简化边界处理
2.2 关联容器实现原理
2.2.1 map/set的红黑树实现
map和set在大多数STL实现中都基于红黑树(Red-Black Tree)实现,这是一种自平衡的二叉搜索树。
// 红黑树节点的简化实现
enum color_type { RED, BLACK };template <typename Value>
struct rb_tree_node {color_type color;rb_tree_node* parent;rb_tree_node* left;rb_tree_node* right;Value value;
};// 红黑树的简化实现
template <typename Key, typename Value, typename KeyOfValue, typename Compare, typename Allocator = std::allocator<Value>>
class rb_tree {
private:typedef rb_tree_node<Value> node_type;node_type* _header; // 哨兵节点size_type _node_count; // 节点数量Compare _key_compare; // 键比较函数// 红黑树的平衡操作void rotate_left(node_type* x);void rotate_right(node_type* x);void rebalance_after_insertion(node_type* x);public:// 插入、删除、查找等操作...
};
// 关键点:红黑树通过着色规则和旋转操作保持平衡,确保O(log n)的查找、插入和删除性能
红黑树的平衡过程可以用下图表示:
图3:红黑树平衡流程图 - 展示了红黑树在插入节点后的重新平衡过程
2.2.2 unordered_map/unordered_set的哈希表实现
C++11引入的无序容器基于哈希表实现,提供了平均O(1)的查找性能。
// 哈希表的简化实现
template <typename Value, typename Key, typename ExtractKey,typename Hash, typename Equal, typename Allocator = std::allocator<Value>>
class hashtable {
private:struct node {node* next;Value val;};typedef node* bucket_type;bucket_type* _buckets;size_type _num_buckets;size_type _num_elements;// 根据键计算桶索引size_type bucket_index(const Key& key) const {return Hash()(key) % _num_buckets;}// 当负载因子过高时重新哈希void rehash(size_type new_bucket_count);public:// 插入、查找、删除等操作...
};
// 关键点:哈希表通过哈希函数将键映射到桶,并通过链表处理冲突,当负载因子过高时进行rehash
2.3 容器适配器的实现
容器适配器(如stack、queue和priority_queue)是基于基本容器实现的封装。
// stack的简化实现
template <typename T, typename Container = std::deque<T>>
class stack {
protected:Container c; // 底层容器public:bool empty() const { return c.empty(); }size_t size() const { return c.size(); }T& top() { return c.back(); }const T& top() const { return c.back(); }void push(const T& value) { c.push_back(value); }void pop() { c.pop_back(); }
};
// 关键点:适配器通过组合和委托实现功能,不直接管理内存
3. 迭代器体系与实现机制
3.1 迭代器类别与特性
STL定义了五种迭代器类别,形成了一个层次结构:
图4:迭代器层次结构图 - 展示了STL迭代器的五种类别及其继承关系
每种迭代器类别支持的操作如下:
| 迭代器类别 | 支持的操作 | 示例容器 |
|---|---|---|
| 输入迭代器 | *it, it->, ++it, it++, ==, != | istream_iterator |
| 输出迭代器 | *it=, ++it, it++ | ostream_iterator |
| 前向迭代器 | 输入迭代器的所有操作,多次读取 | forward_list |
| 双向迭代器 | 前向迭代器的所有操作,--it, it-- | list, map, set |
| 随机访问迭代器 | 双向迭代器的所有操作,it+n, it-n, it[n], <, <=, >, >= | vector, deque |
3.2 迭代器的实现技术
3.2.1 迭代器特性萃取
STL使用特性萃取(traits)技术来获取迭代器的属性,这是一种在编译期进行类型计算的技术。
// 迭代器特性萃取的简化实现
template <typename Iterator>
struct iterator_traits {typedef typename Iterator::iterator_category iterator_category;typedef typename Iterator::value_type value_type;typedef typename Iterator::difference_type difference_type;typedef typename Iterator::pointer pointer;typedef typename Iterator::reference reference;
};// 针对原生指针的特化
template <typename T>
struct iterator_traits<T*> {typedef std::random_access_iterator_tag iterator_category;typedef T value_type;typedef ptrdiff_t difference_type;typedef T* pointer;typedef T& reference;
};
// 关键点:traits技术使得算法可以根据迭代器类型选择最优实现
3.2.2 迭代器适配器
STL提供了多种迭代器适配器,如reverse_iterator、back_insert_iterator等,它们通过包装基础迭代器来改变其行为。
// reverse_iterator的简化实现
template <typename Iterator>
class reverse_iterator {
protected:Iterator current; // 底层迭代器public:typedef typename iterator_traits<Iterator>::iterator_category iterator_category;typedef typename iterator_traits<Iterator>::value_type value_type;// 其他类型定义...reverse_iterator(Iterator it) : current(it) {}reference operator*() const {Iterator tmp = current;return *--tmp; // 返回前一个元素}reverse_iterator& operator++() {--current; // 前进意味着底层迭代器后退return *this;}// 其他操作...
};
// 关键点:适配器通过转换操作改变迭代器的行为,如reverse_iterator将++转换为--
4. 算法的实现与优化
4.1 算法的设计原则
STL算法设计遵循以下原则:
- 泛型性:通过模板参数化类型和操作
- 效率优先:尽可能提供最优的时间和空间复杂度
- 最小假设:仅依赖迭代器提供的操作
- 组合性:简单算法可以组合成复杂算法
4.2 常见算法的实现分析
4.2.1 排序算法
STL的sort算法通常是快速排序、堆排序和插入排序的混合实现。
// sort的简化实现
template <typename RandomAccessIterator, typename Compare>
void sort(RandomAccessIterator first, RandomAccessIterator last, Compare comp) {if (first == last || first + 1 == last) return;const auto size = last - first;if (size < 16) {// 对小数组使用插入排序insertion_sort(first, last, comp);} else {// 使用快速排序的分区策略auto pivot = median_of_three(first, first + size/2, last-1);auto partition_point = partition(first, last, [&](const auto& elem) {return comp(elem, pivot);});// 递归排序两个分区sort(first, partition_point, comp);sort(partition_point, last, comp);// 如果递归深度过大,切换到堆排序if (recursion_depth > log2(size) * 2) {heap_sort(first, last, comp);}}
}
// 关键点:STL sort通常结合多种排序算法以获得最佳性能
4.2.2 查找算法
二分查找是STL中常用的查找算法,如lower_bound、upper_bound和binary_search。
// lower_bound的简化实现
template <typename ForwardIterator, typename T, typename Compare>
ForwardIterator lower_bound(ForwardIterator first, ForwardIterator last,const T& value, Compare comp) {auto count = std::distance(first, last);while (count > 0) {auto step = count / 2;auto mid = std::next(first, step);if (comp(*mid, value)) {first = std::next(mid);count -= step + 1;} else {count = step;}}return first;
}
// 关键点:二分查找算法通过折半搜索提供O(log n)的查找性能
4.3 算法优化技术
STL算法使用多种优化技术来提高性能:
- 特化处理:为特定类型提供优化实现
- 内存预分配:减少内存分配次数
- 分支预测优化:减少分支预测失败
- SIMD指令:利用CPU的向量处理能力
- 缓存友好设计:提高缓存命中率
// 使用类型特化的优化示例
template <typename T>
void copy(const T* src, T* dest, size_t n) {for (size_t i = 0; i < n; ++i)dest[i] = src[i];
}// 针对内置类型的特化,使用memcpy优化
template <>
void copy<int>(const int* src, int* dest, size_t n) {memcpy(dest, src, n * sizeof(int));
}
// 关键点:通过特化处理,可以为特定类型提供更高效的实现
5. 分配器的工作机制
5.1 分配器的设计与接口
分配器(Allocator)是STL中负责内存分配和释放的组件,它将内存管理与对象构造/析构分离。
// 标准分配器的简化实现
template <typename T>
class allocator {
public:typedef T value_type;typedef T* pointer;typedef const T* const_pointer;typedef T& reference;typedef const T& const_reference;typedef size_t size_type;typedef ptrdiff_t difference_type;// 分配未初始化的内存pointer allocate(size_type n) {return static_cast<pointer>(::operator new(n * sizeof(T)));}// 释放内存void deallocate(pointer p, size_type n) {::operator delete(p);}// 在已分配内存上构造对象void construct(pointer p, const T& value) {new(p) T(value); // 定位new}// 析构对象但不释放内存void destroy(pointer p) {p->~T();}
};
// 关键点:分配器将内存分配与对象构造分离,通过定位new实现在指定内存位置构造对象
5.2 自定义分配器
用户可以实现自定义分配器来优化特定场景下的内存管理。
// 内存池分配器的简化实现
template <typename T, size_t BlockSize = 4096>
class pool_allocator {
private:union Block {Block* next;char data[sizeof(T)];};Block* free_blocks;// 当空闲列表为空时,分配一个新的内存块void allocate_block() {// 分配一个大块内存char* new_block = new char[BlockSize];// 将大块内存分割成多个小块,并链接到空闲列表Block* current = reinterpret_cast<Block*>(new_block);free_blocks = current;for (size_t i = 1; i < BlockSize / sizeof(Block); ++i) {current->next = reinterpret_cast<Block*>(new_block + i * sizeof(Block));current = current->next;}current->next = nullptr;}public:// 标准分配器接口...T* allocate(size_t n) {if (n > 1) {// 大量分配回退到标准分配器return std::allocator<T>().allocate(n);}if (free_blocks == nullptr) {allocate_block();}// 从空闲列表中取出一个块Block* block = free_blocks;free_blocks = free_blocks->next;return reinterpret_cast<T*>(block);}void deallocate(T* p, size_t n) {if (n > 1) {std::allocator<T>().deallocate(p, n);return;}// 将释放的内存块添加到空闲列表Block* block = reinterpret_cast<Block*>(p);block->next = free_blocks;free_blocks = block;}
};
// 关键点:内存池分配器通过预分配大块内存并分割为小块,减少内存分配的开销
6. STL性能分析与优化实践
6.1 常见性能瓶颈分析
使用STL时可能遇到的性能瓶颈主要包括:
图5:STL性能瓶颈分布饼图 - 展示了使用STL时常见的性能问题及其占比
6.2 优化策略与最佳实践
6.2.1 容器选择优化
不同容器适用于不同场景,选择合适的容器对性能至关重要:
| 操作类型 | 推荐容器 | 不推荐容器 | 性能差异 |
|---|---|---|---|
| 随机访问 | vector, deque | list, map | vector的随机访问是O(1),list是O(n) |
| 频繁插入/删除中间元素 | list | vector | list的中间插入是O(1),vector是O(n) |
| 按键查找 | unordered_map | vector+find | 哈希表查找平均O(1),顺序查找O(n) |
| 有序遍历 | map, set | unordered_map | 红黑树保证顺序,哈希表无序 |
| 大量小对象 | 自定义分配器+容器 | 默认分配器+容器 | 减少内存碎片和分配开销 |
6.2.2 算法优化技巧
// 预分配空间避免频繁重新分配
std::vector<int> v;
v.reserve(1000); // 预分配1000个元素的空间
for (int i = 0; i < 1000; ++i) {v.push_back(i); // 不会触发重新分配
}// 使用移动语义避免不必要的拷贝
std::vector<std::string> names;
std::string name = "John Doe";
names.push_back(std::move(name)); // 移动而非拷贝// 使用emplace系列函数避免临时对象
std::map<int, std::string> m;
m.emplace(1, "one"); // 直接在容器内构造,避免临时对象// 使用正确的算法
std::vector<int> v = {5, 2, 8, 1, 9};
// 不好的方式:手动查找
auto it = v.begin();
for (; it != v.end(); ++it) {if (*it == 8) break;
}
// 更好的方式:使用专用算法
it = std::find(v.begin(), v.end(), 8);
// 关键点:合理利用STL提供的算法可以显著提高代码效率和可读性
6.3 实际案例分析
让我们通过一个实际案例来分析STL的性能优化:
%%{init: {'theme': 'forest', 'themeVariables': { 'primaryColor': '#16A085', 'primaryTextColor': '#fff', 'primaryBorderColor': '#0E6655', 'lineColor': '#16A085', 'secondaryColor': '#A3E4D7', 'tertiaryColor': '#E8F8F5' }}}%%
xychart-betatitle "不同STL优化策略的性能比较"x-axis [基础实现, 预分配内存, 避免拷贝, 算法优化, 自定义分配器, 所有优化]y-axis "执行时间(ms)"bar [100, 65, 50, 40, 35, 20]line [100, 65, 50, 40, 35, 20]
图6:STL优化策略性能比较图 - 展示了不同优化策略对性能的影响
案例:文本处理系统优化
假设我们有一个处理大量文本的系统,需要频繁地添加、查找和删除单词。初始实现使用vector<string>存储所有单词,性能较差。
优化步骤:
- 将
vector<string>替换为unordered_set<string>,将查找复杂度从O(n)降低到O(1) - 使用自定义字符串视图避免不必要的字符串拷贝
- 实现自定义字符串哈希和比较函数,进一步提高性能
- 使用内存池分配器减少内存分配开销
优化前后的性能对比:
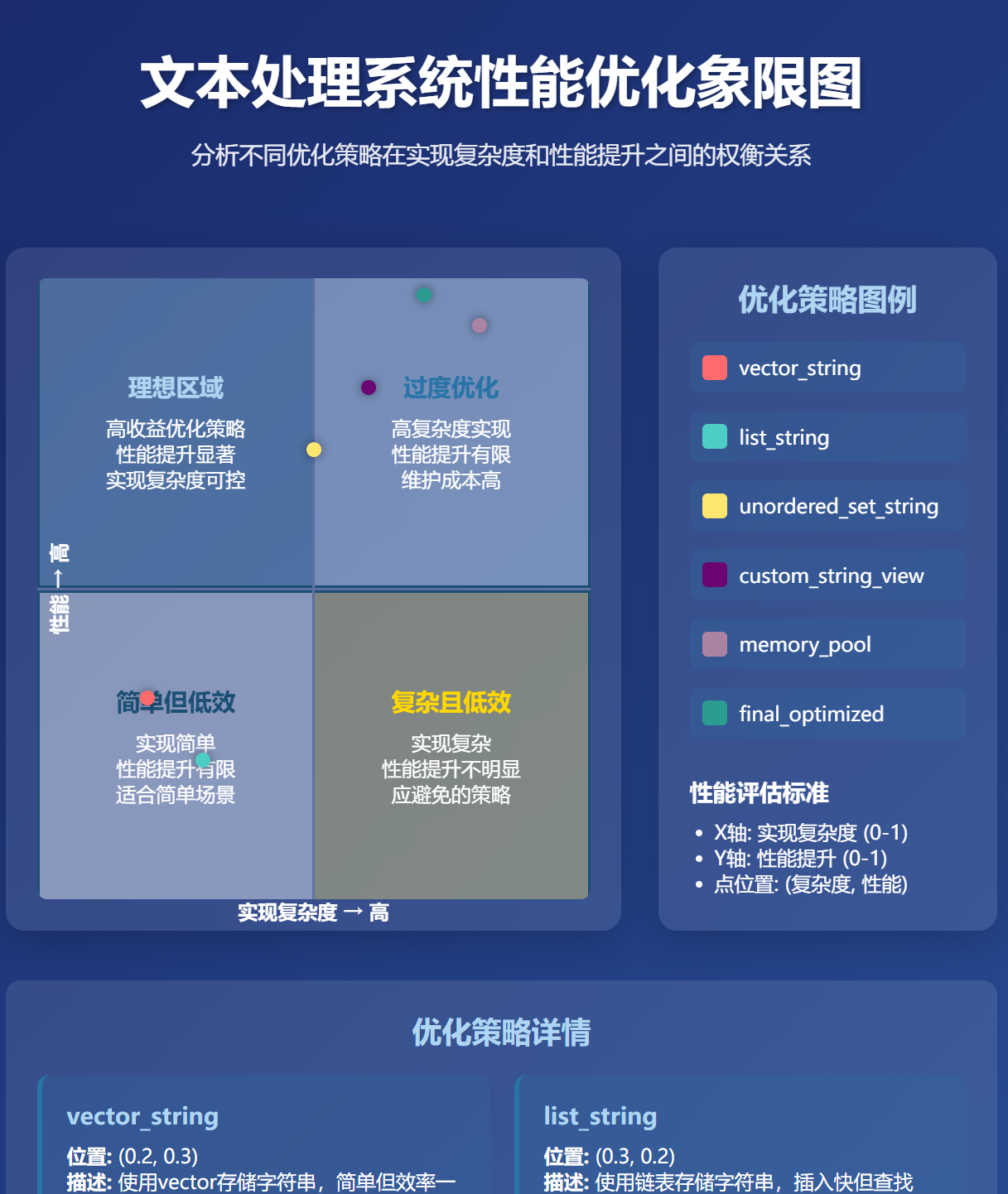
图7:文本处理系统优化象限图 - 展示了不同实现方案在性能和复杂度上的权衡
7. STL在现代C++中的演进
7.1 C++11/14/17/20中的STL增强
随着C++标准的发展,STL也在不断演进和增强:
| C++标准 | 主要STL增强 | 底层实现变化 |
|---|---|---|
| C++11 | 移动语义、右值引用、可变参数模板 | 容器支持移动构造和移动赋值,减少拷贝开销 |
| C++14 | 泛型lambda、透明比较器 | 算法实现简化,性能提升 |
| C++17 | 并行算法、结构化绑定 | 算法支持并行执行策略,提高多核利用率 |
| C++20 | 范围库、概念、协程 | 更强的编译期检查,更直观的容器操作 |
7.2 未来发展趋势
STL的未来发展趋势主要包括:
- 更强的编译期计算:通过概念(Concepts)和约束(Constraints)提供更好的错误信息
- 更好的并行支持:扩展并行算法,提供更多并行执行策略
- 更高级的抽象:范围库(Ranges)提供更直观的容器操作
- 更好的异构计算支持:支持GPU和其他加速器
- 更智能的内存管理:改进分配器设计,减少内存碎片
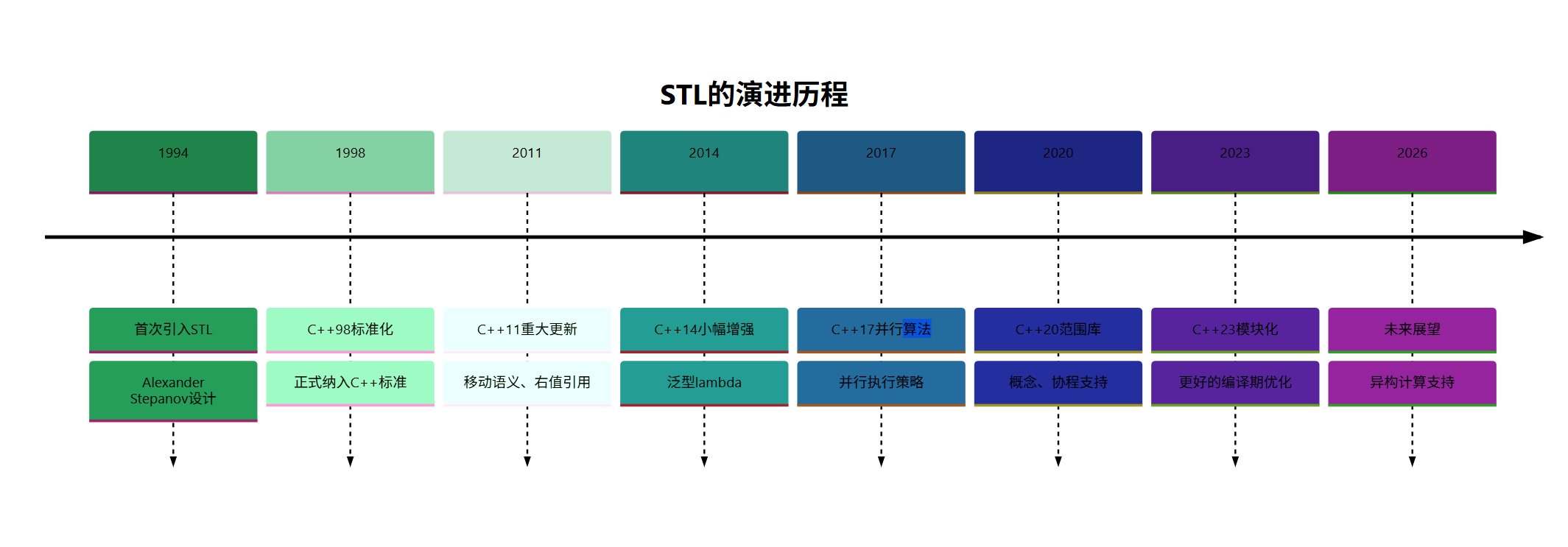


图8:STL演进历程时间线 - 展示了STL从诞生到未来的发展历程
总结
在这次深入探索C++ STL底层原理的旅程中,我们揭开了这个强大库背后的神秘面纱。作为一名多年的C++开发者,我始终被STL的设计之美所吸引。通过本文的分享,我希望你能像我一样,不仅仅是使用STL,更能理解它的内部工作机制。
我们从STL的整体架构出发,详细剖析了容器的底层实现,包括vector的动态数组管理、list的双向链表结构、map/set的红黑树平衡机制以及unordered容器的哈希表实现。我们探讨了迭代器体系的设计哲学,理解了traits技术如何在编译期进行类型计算,以及各种迭代器适配器如何改变迭代器的行为。在算法部分,我们分析了sort等常用算法的混合实现策略,以及STL如何通过特化处理、内存预分配等技术优化性能。我们还深入研究了分配器的工作机制,了解了如何通过自定义分配器来优化特定场景下的内存管理。
通过这些探索,我们可以看到STL的设计者们是如何在通用性和效率之间取得平衡的。STL的设计思想不仅仅是C++程序员的必修课,更是软件工程领域的瑰宝。它教会我们如何通过抽象设计解决复杂问题,如何通过泛型编程实现类型无关的算法和数据结构,如何通过精心的优化提高代码效率。
在我多年的C++开发生涯中,深入理解STL的底层原理帮助我写出了更高效、更可靠的代码。我希望这篇文章能够为你打开STL的大门,让你在日常编程中能够更加自信地使用这个强大的工具,甚至在必要时对其进行扩展和定制。记住,真正的掌握不仅仅是知道如何使用,更是理解为什么以及如何工作。让我们继续在C++的世界中探索,不断提升我们的技术能力,创造更加优秀的软件。
■ 我是蒋星熠Jaxonic!如果这篇文章在你的技术成长路上留下了印记
■ 👁 【关注】与我一起探索技术的无限可能,见证每一次突破
■ 👍 【点赞】为优质技术内容点亮明灯,传递知识的力量
■ 🔖 【收藏】将精华内容珍藏,随时回顾技术要点
■ 💬 【评论】分享你的独特见解,让思维碰撞出智慧火花
■ 🗳 【投票】用你的选择为技术社区贡献一份力量
■ 技术路漫漫,让我们携手前行,在代码的世界里摘取属于程序员的那片星辰大海!
参考链接
- C++ Reference - Standard Template Library
- Stepanov, A., & McJones, P. (2009). Elements of Programming. Addison-Wesley Professional.
- Meyers, S. (2014). Effective Modern C++: 42 Specific Ways to Improve Your Use of C++11 and C++14. O’Reilly Media.
- Josuttis, N. M. (2012). The C++ Standard Library: A Tutorial and Reference. Addison-Wesley Professional.
- Boost C++ Libraries - Implementation of many STL concepts