YOLO12架构优化——引入多维协作注意力机制(MCAM)抑制背景干扰,强化多尺度与小目标检测性能
传统卷积神经网络(CNN)通过局部感受野逐层提取特征,但其固有的局限性在于缺乏动态聚焦关键区域的能力。尽管后续提出的注意力机制(如SE、CBAM等)在一定程度上增强了特征表达能力,但仍存在显著缺陷:维度割裂、信息损失和计算冗余。为应对这些挑战,本文提出了一种基于多维协作注意力机制(Multi-Dimensional Collaborative Attention Mechanism, MCAM)的改进方案,将其与YOLOv12架构相结合,以提升模型在复杂背景下的抗干扰能力和多尺度、小目标检测性能。
1. 传统注意力机制的局限性分析
- 维度割裂
多数现有注意力机制(如SENet、CBAM)独立处理通道或空间维度,忽视了跨维度关联。例如,通道注意力仅关注全局特征重要性,而空间注意力仅关注局部位置,忽略了通道与空间之间的协同作用。
- 信息损失
全局平均池化(GAP)是许多注意力机制的核心操作,但其对特征图进行全局压缩会导致细节信息丢失,尤其在细粒度分类任务中表现不佳。
- 计算冗余
复杂模块(如全连接层或多分支结构)虽然提升了特征表达能力,但也大幅增加了参数量和计算成本,限制了模型的实际部署效率。
2. 多维协作注意力机制(MCAM)设计原理
论文地址:https://www.sciencedirect.com/science/article/abs/pii/S0952197623012630
代码地址:https://github.com/ndsclark/MCANet/blob/main/ImageNet/mca_module.py
MCA(Multi-Dimensional Collaborative Attention)旨在解决上述问题,通过轻量化设计实现通道、高度、宽度三个维度的协同建模,在动态捕捉关键特征的同时保持计算效率。其核心思想是打破传统注意力机制对通道与空间维度的割裂式处理,通过多维度协同感知与动态轻量化计算,让网络更智能地捕捉特征间的复杂关联。

2.1 核心问题与解决方案
MCA通过同时回答以下三个问题,实现了跨维度的动态特征增强:
- “哪些特征重要”(通道维度) :识别出对目标任务贡献最大的特征通道。
- “重要特征在垂直方向的位置”(高度维度) :定位图像上下区域的关键位置。
- “重要特征在水平方向的位置”(宽度维度) :定位图像左右区域的关键位置。
2.2 实现方式
MCA摒弃了传统全连接层等复杂结构,转而通过一维卷积和动态门控机制,在几乎不增加计算量的前提下实现跨维度信息交互。其整体结构由三个并行的注意力分支(通道、高度、宽度)和一个动态聚合模块组成,具体如下:
- 通道分支
- 输入特征图的通道维度直接参与计算。
- 对每个通道同时计算全局平均池化(提取特征整体强度)和全局标准差池化(衡量特征分布的离散程度),两种统计量通过可学习权重融合,形成更全面的通道描述。
- 融合后的统计量通过一维卷积生成通道注意力权重,该卷积仅需极少的参数量即可捕捉通道间局部依赖关系。
- 最后,权重与原始特征逐通道相乘,强化重要通道(如与目标类别相关的特征通道)的响应,抑制冗余通道。
- 高度分支
- 目标是定位垂直方向(图像上下区域)的关键位置。
- 将输入特征图旋转,使高度维度转换为“伪通道”维度。例如,原始特征维度为“通道×高度×宽度”(如64×224×224),旋转后变为“高度×通道×宽度”(224×64×224)。
- 每个“伪通道”对应原始图像的一行像素,复用通道分支的流程,计算均值与标准差统计量,并通过一维卷积生成高度注意力权重。
- 逆旋转后恢复原始维度,完成垂直方向的特征增强。
- 宽度分支
- 关注水平方向(图像左右区域)的重要性,与高度分支对称。
- 通过旋转操作将宽度维度转换为“伪通道”,例如原始特征变为“宽度×高度×通道”(224×224×64)。
- 每个“伪通道”对应原始图像的一列像素,复用通道分支的统计量融合与一维卷积生成宽度注意力权重。
- 逆旋转后恢复原始维度,完成水平方向的特征增强。
- 动态门控与特征聚合
- 动态门控:在一维卷积中引入轻量级自适应机制,根据输入特征的复杂度动态选择卷积核大小。例如,复杂场景使用较大的卷积核(如核大小5),简单场景则使用较小卷积核(如核大小3)。
- 特征聚合:将通道、高度、宽度分支的输出特征按元素取平均值,综合三个维度的注意力结果,形成判别性更强的特征表达。
3. 将DSAM引入到YOLOv12中
3.1 MCAM核心代码
import torch
from torch import nn
import mathclass StdPool(nn.Module):def __init__(self):"""初始化标准偏差池化模块。"""super(StdPool, self).__init__()def forward(self, x):"""前向传播过程,计算输入特征图的标准偏差。参数:x (torch.Tensor): 输入的特征图,形状为 (b, c, h, w)。返回:torch.Tensor: 标准偏差特征图,形状为 (b, c, 1, 1)。"""# 获取输入特征图的批量大小和通道数b, c, _, _ = x.size()# 将特征图展平并计算每个通道的标准偏差std = x.view(b, c, -1).std(dim=2, keepdim=True)# 调整形状为 (b, c, 1, 1)std = std.reshape(b, c, 1, 1)return stdclass MCAGate(nn.Module):def __init__(self, k_size, pool_types=['avg', 'std']):"""初始化 MCA 门控模块。参数:k_size (int): 卷积核大小。pool_types (list): 池化类型列表,支持 'avg'(平均池化)、'max'(最大池化)、'std'(标准偏差池化)。"""super(MCAGate, self).__init__()# 创建池化模块列表self.pools = nn.ModuleList([])for pool_type in pool_types:if pool_type == 'avg':# 平均池化self.pools.append(nn.AdaptiveAvgPool2d(1))elif pool_type == 'max':# 最大池化self.pools.append(nn.AdaptiveMaxPool2d(1))elif pool_type == 'std':# 标准偏差池化self.pools.append(StdPool())else:raise NotImplementedError# 1D 卷积层self.conv = nn.Conv2d(1, 1, kernel_size=(1, k_size), stride=1, padding=(0, (k_size - 1) // 2), bias=False)# Sigmoid 激活函数self.sigmoid = nn.Sigmoid()# 可学习的权重参数self.weight = nn.Parameter(torch.rand(2))def forward(self, x):"""前向传播过程,对输入特征图进行池化、融合、卷积和激活操作。参数:x (torch.Tensor): 输入的特征图,形状为 (b, c, h, w)。返回:torch.Tensor: 经过门控处理后的特征图,形状与输入相同。"""# 对输入特征图进行不同类型的池化操作feats = [pool(x) for pool in self.pools]if len(feats) == 1:# 只有一种池化结果out = feats[0]elif len(feats) == 2:# 两种池化结果,进行加权融合weight = torch.sigmoid(self.weight)out = 1 / 2 * (feats[0] + feats[1]) + weight[0] * feats[0] + weight[1] * feats[1]else:assert False, "Feature Extraction Exception!"# 调整维度顺序out = out.permute(0, 3, 2, 1).contiguous()# 进行 1D 卷积out = self.conv(out)# 恢复维度顺序out = out.permute(0, 3, 2, 1).contiguous()# 应用 Sigmoid 激活函数out = self.sigmoid(out)# 扩展到与输入相同的形状out = out.expand_as(x)# 返回门控后的特征图return x * outclass MCALayer(nn.Module):def __init__(self, inp, no_spatial=False):"""初始化 MCA 层。参数:inp (int): 输入特征图的通道数。no_spatial (bool): 是否不考虑空间维度的交互,默认为 False。"""super(MCALayer, self).__init__()lambd = 1.5gamma = 1# 计算卷积核大小temp = round(abs((math.log2(inp) - gamma) / lambd))kernel = temp if temp % 2 else temp - 1# 水平方向的 MCA 门控self.h_cw = MCAGate(3)# 垂直方向的 MCA 门控self.w_hc = MCAGate(3)# 是否不考虑空间维度的交互self.no_spatial = no_spatialif not no_spatial:# 通道方向的 MCA 门控self.c_hw = MCAGate(kernel)def forward(self, x):"""前向传播过程,对输入特征图在不同方向上进行 MCA 门控处理并融合。参数:x (torch.Tensor): 输入的特征图,形状为 (b, c, h, w)。返回:torch.Tensor: 经过 MCA 处理后的特征图,形状与输入相同。"""# 调整维度顺序,进行水平方向的处理x_h = x.permute(0, 2, 1, 3).contiguous()x_h = self.h_cw(x_h)x_h = x_h.permute(0, 2, 1, 3).contiguous()# 调整维度顺序,进行垂直方向的处理x_w = x.permute(0, 3, 2, 1).contiguous()x_w = self.w_hc(x_w)x_w = x_w.permute(0, 3, 2, 1).contiguous()if not self.no_spatial:# 进行通道方向的处理x_c = self.c_hw(x)# 融合三个方向的结果x_out = 1 / 3 * (x_c + x_h + x_w)else:# 仅融合水平和垂直方向的结果x_out = 1 / 2 * (x_h + x_w)return x_outdef autopad(k, p=None, d=1): # kernel, padding, dilation"""Pad to 'same' shape outputs."""if d > 1:k = d * (k - 1) + 1 if isinstance(k, int) else [d * (x - 1) + 1 for x in k] # actual kernel-sizeif p is None:p = k // 2 if isinstance(k, int) else [x // 2 for x in k] # auto-padreturn pclass Conv(nn.Module):"""Standard convolution with args(ch_in, ch_out, kernel, stride, padding, groups, dilation, activation)."""default_act = nn.SiLU() # default activationdef __init__(self, c1, c2, k=1, s=1, p=None, g=1, d=1, act=True):"""Initialize Conv layer with given arguments including activation."""super().__init__()self.conv = nn.Conv2d(c1, c2, k, s, autopad(k, p, d), groups=g, dilation=d, bias=False)self.bn = nn.BatchNorm2d(c2)self.act = self.default_act if act is True else act if isinstance(act, nn.Module) else nn.Identity()def forward(self, x):"""Apply convolution, batch normalization and activation to input tensor."""return self.act(self.bn(self.conv(x)))def forward_fuse(self, x):"""Perform transposed convolution of 2D data."""return self.act(self.conv(x))class Bottleneck(nn.Module):"""Standard bottleneck."""def __init__(self, c1, c2, shortcut=True, g=1, k=(3, 3), e=0.5):"""Initializes a standard bottleneck module with optional shortcut connection and configurable parameters."""super().__init__()c_ = int(c2 * e) # hidden channelsself.cv1 = Conv(c1, c_, k[0], 1)self.cv2 = Conv(c_, c2, k[1], 1, g=g)self.add = shortcut and c1 == c2def forward(self, x):"""Applies the YOLO FPN to input data."""return x + self.cv2(self.cv1(x)) if self.add else self.cv2(self.cv1(x))class C2f(nn.Module):"""Faster Implementation of CSP Bottleneck with 2 convolutions."""def __init__(self, c1, c2, n=1, shortcut=False, g=1, e=0.5):"""Initializes a CSP bottleneck with 2 convolutions and n Bottleneck blocks for faster processing."""super().__init__()self.c = int(c2 * e) # hidden channelsself.cv1 = Conv(c1, 2 * self.c, 1, 1)self.cv2 = Conv((2 + n) * self.c, c2, 1) # optional act=FReLU(c2)self.m = nn.ModuleList(Bottleneck(self.c, self.c, shortcut, g, k=((3, 3), (3, 3)), e=1.0) for _ in range(n))def forward(self, x):"""Forward pass through C2f layer."""y = list(self.cv1(x).chunk(2, 1))y.extend(m(y[-1]) for m in self.m)return self.cv2(torch.cat(y, 1))def forward_split(self, x):"""Forward pass using split() instead of chunk()."""y = self.cv1(x).split((self.c, self.c), 1)y = [y[0], y[1]]y.extend(m(y[-1]) for m in self.m)return self.cv2(torch.cat(y, 1))class C3(nn.Module):"""CSP Bottleneck with 3 convolutions."""def __init__(self, c1, c2, n=1, shortcut=True, g=1, e=0.5):"""Initialize the CSP Bottleneck with given channels, number, shortcut, groups, and expansion values."""super().__init__()c_ = int(c2 * e) # hidden channelsself.cv1 = Conv(c1, c_, 1, 1)self.cv2 = Conv(c1, c_, 1, 1)self.cv3 = Conv(2 * c_, c2, 1) # optional act=FReLU(c2)self.m = nn.Sequential(*(Bottleneck(c_, c_, shortcut, g, k=((1, 1), (3, 3)), e=1.0) for _ in range(n)))def forward(self, x):"""Forward pass through the CSP bottleneck with 2 convolutions."""return self.cv3(torch.cat((self.m(self.cv1(x)), self.cv2(x)), 1))class Bottleneck_MCA(nn.Module):"""Standard bottleneck."""def __init__(self, c1, c2, shortcut=True, g=1, k=(3, 3), e=0.5):"""Initializes a standard bottleneck module with optional shortcut connection and configurable parameters."""super().__init__()c_ = int(c2 * e) # hidden channelsself.cv1 = Conv(c1, c_, k[0], 1)self.cv2 = MCALayer(c_)self.add = shortcut and c1 == c2def forward(self, x):"""Applies the YOLO FPN to input data."""return x + self.cv2(self.cv1(x)) if self.add else self.cv2(self.cv1(x))class C3k(C3):"""C3k is a CSP bottleneck module with customizable kernel sizes for feature extraction in neural networks."""def __init__(self, c1, c2, n=1, shortcut=True, g=1, e=0.5, k=3):"""Initializes the C3k module with specified channels, number of layers, and configurations."""super().__init__(c1, c2, n, shortcut, g, e)c_ = int(c2 * e) # hidden channels# self.m = nn.Sequential(*(RepBottleneck(c_, c_, shortcut, g, k=(k, k), e=1.0) for _ in range(n)))self.m = nn.Sequential(*(Bottleneck_MCA(c_, c_, shortcut, g, k=(k, k), e=1.0) for _ in range(n)))# 在c3k=True时,使用Bottleneck_LLSKM特征融合,为false的时候我们使用普通的Bottleneck提取特征
class C3k2_MCAM(C2f):"""Faster Implementation of CSP Bottleneck with 2 convolutions."""def __init__(self, c1, c2, n=1, c3k=False, e=0.5, g=1, shortcut=True):"""Initializes the C3k2 module, a faster CSP Bottleneck with 2 convolutions and optional C3k blocks."""super().__init__(c1, c2, n, shortcut, g, e)self.m = nn.ModuleList(C3k(self.c, self.c, 2, shortcut, g) if c3k else Bottleneck(self.c, self.c, shortcut, g) for _ in range(n))class AAttn(nn.Module):"""Area-attention module for YOLO models, providing efficient attention mechanisms.This module implements an area-based attention mechanism that processes input features in a spatially-aware manner,making it particularly effective for object detection tasks.Attributes:area (int): Number of areas the feature map is divided.num_heads (int): Number of heads into which the attention mechanism is divided.head_dim (int): Dimension of each attention head.qkv (Conv): Convolution layer for computing query, key and value tensors.proj (Conv): Projection convolution layer.pe (Conv): Position encoding convolution layer.Methods:forward: Applies area-attention to input tensor.Examples:>>> attn = AAttn(dim=256, num_heads=8, area=4)>>> x = torch.randn(1, 256, 32, 32)>>> output = attn(x)>>> print(output.shape)torch.Size([1, 256, 32, 32])"""def __init__(self, dim, num_heads, area=1):"""Initializes an Area-attention module for YOLO models.Args:dim (int): Number of hidden channels.num_heads (int): Number of heads into which the attention mechanism is divided.area (int): Number of areas the feature map is divided, default is 1."""super().__init__()self.area = areaself.num_heads = num_headsself.head_dim = head_dim = dim // num_headsall_head_dim = head_dim * self.num_headsself.qkv = Conv(dim, all_head_dim * 3, 1, act=False)self.proj = Conv(all_head_dim, dim, 1, act=False)self.pe = Conv(all_head_dim, dim, 7, 1, 3, g=dim, act=False)def forward(self, x):"""Processes the input tensor 'x' through the area-attention."""B, C, H, W = x.shapeN = H * Wqkv = self.qkv(x).flatten(2).transpose(1, 2)if self.area > 1:qkv = qkv.reshape(B * self.area, N // self.area, C * 3)B, N, _ = qkv.shapeq, k, v = (qkv.view(B, N, self.num_heads, self.head_dim * 3).permute(0, 2, 3, 1).split([self.head_dim, self.head_dim, self.head_dim], dim=2))attn = (q.transpose(-2, -1) @ k) * (self.head_dim**-0.5)attn = attn.softmax(dim=-1)x = v @ attn.transpose(-2, -1)x = x.permute(0, 3, 1, 2)v = v.permute(0, 3, 1, 2)if self.area > 1:x = x.reshape(B // self.area, N * self.area, C)v = v.reshape(B // self.area, N * self.area, C)B, N, _ = x.shapex = x.reshape(B, H, W, C).permute(0, 3, 1, 2).contiguous()v = v.reshape(B, H, W, C).permute(0, 3, 1, 2).contiguous()x = x + self.pe(v)return self.proj(x)class ABlock(nn.Module):"""Area-attention block module for efficient feature extraction in YOLO models.This module implements an area-attention mechanism combined with a feed-forward network for processing feature maps.It uses a novel area-based attention approach that is more efficient than traditional self-attention whilemaintaining effectiveness.Attributes:attn (AAttn): Area-attention module for processing spatial features.mlp (nn.Sequential): Multi-layer perceptron for feature transformation.Methods:_init_weights: Initializes module weights using truncated normal distribution.forward: Applies area-attention and feed-forward processing to input tensor.Examples:>>> block = ABlock(dim=256, num_heads=8, mlp_ratio=1.2, area=1)>>> x = torch.randn(1, 256, 32, 32)>>> output = block(x)>>> print(output.shape)torch.Size([1, 256, 32, 32])"""def __init__(self, dim, num_heads, mlp_ratio=1.2, area=1):"""Initializes an Area-attention block module for efficient feature extraction in YOLO models.This module implements an area-attention mechanism combined with a feed-forward network for processing featuremaps. It uses a novel area-based attention approach that is more efficient than traditional self-attentionwhile maintaining effectiveness.Args:dim (int): Number of input channels.num_heads (int): Number of heads into which the attention mechanism is divided.mlp_ratio (float): Expansion ratio for MLP hidden dimension.area (int): Number of areas the feature map is divided."""super().__init__()self.attn = AAttn(dim, num_heads=num_heads, area=area)mlp_hidden_dim = int(dim * mlp_ratio)self.mlp = nn.Sequential(Conv(dim, mlp_hidden_dim, 1), Conv(mlp_hidden_dim, dim, 1, act=False))self.apply(self._init_weights)def _init_weights(self, m):"""Initialize weights using a truncated normal distribution."""if isinstance(m, nn.Conv2d):nn.init.trunc_normal_(m.weight, std=0.02)if m.bias is not None:nn.init.constant_(m.bias, 0)def forward(self, x):"""Forward pass through ABlock, applying area-attention and feed-forward layers to the input tensor."""x = x + self.attn(x)return x + self.mlp(x)class A2C2f_MCAM(nn.Module):"""Area-Attention C2f module for enhanced feature extraction with area-based attention mechanisms.This module extends the C2f architecture by incorporating area-attention and ABlock layers for improved featureprocessing. It supports both area-attention and standard convolution modes.Attributes:cv1 (Conv): Initial 1x1 convolution layer that reduces input channels to hidden channels.cv2 (Conv): Final 1x1 convolution layer that processes concatenated features.gamma (nn.Parameter | None): Learnable parameter for residual scaling when using area attention.m (nn.ModuleList): List of either ABlock or C3k modules for feature processing.Methods:forward: Processes input through area-attention or standard convolution pathway.Examples:>>> m = A2C2f(512, 512, n=1, a2=True, area=1)>>> x = torch.randn(1, 512, 32, 32)>>> output = m(x)>>> print(output.shape)torch.Size([1, 512, 32, 32])"""def __init__(self, c1, c2, n=1, a2=True, area=1, residual=False, mlp_ratio=2.0, e=0.5, g=1, shortcut=True):"""Area-Attention C2f module for enhanced feature extraction with area-based attention mechanisms.Args:c1 (int): Number of input channels.c2 (int): Number of output channels.n (int): Number of ABlock or C3k modules to stack.a2 (bool): Whether to use area attention blocks. If False, uses C3k blocks instead.area (int): Number of areas the feature map is divided.residual (bool): Whether to use residual connections with learnable gamma parameter.mlp_ratio (float): Expansion ratio for MLP hidden dimension.e (float): Channel expansion ratio for hidden channels.g (int): Number of groups for grouped convolutions.shortcut (bool): Whether to use shortcut connections in C3k blocks."""super().__init__()c_ = int(c2 * e) # hidden channelsassert c_ % 32 == 0, "Dimension of ABlock be a multiple of 32."self.cv1 = Conv(c1, c_, 1, 1)self.cv2 = Conv((1 + n) * c_, c2, 1)self.gamma = nn.Parameter(0.01 * torch.ones(c2), requires_grad=True) if a2 and residual else Noneself.m = nn.ModuleList(nn.Sequential(*(ABlock(c_, c_ // 32, mlp_ratio, area) for _ in range(2)))if a2else C3k(c_, c_, 2, shortcut, g)for _ in range(n))def forward(self, x):"""Forward pass through R-ELAN layer."""y = [self.cv1(x)]y.extend(m(y[-1]) for m in self.m)y = self.cv2(torch.cat(y, 1))if self.gamma is not None:return x + self.gamma.view(-1, len(self.gamma), 1, 1) * yreturn yif __name__ == "__main__":# 定义输入特征图的通道数inp = 64# 创建 MCA 层实例mca_layer = MCALayer(inp)# 生成随机输入特征图x = torch.randn(1, inp, 37, 32)# 进行前向传播output = mca_layer(x)print("输出特征图的形状:", output.shape)1. 先新建Add-module文件包,将MCAM下面的核心代码复制到下面,如下图如所示
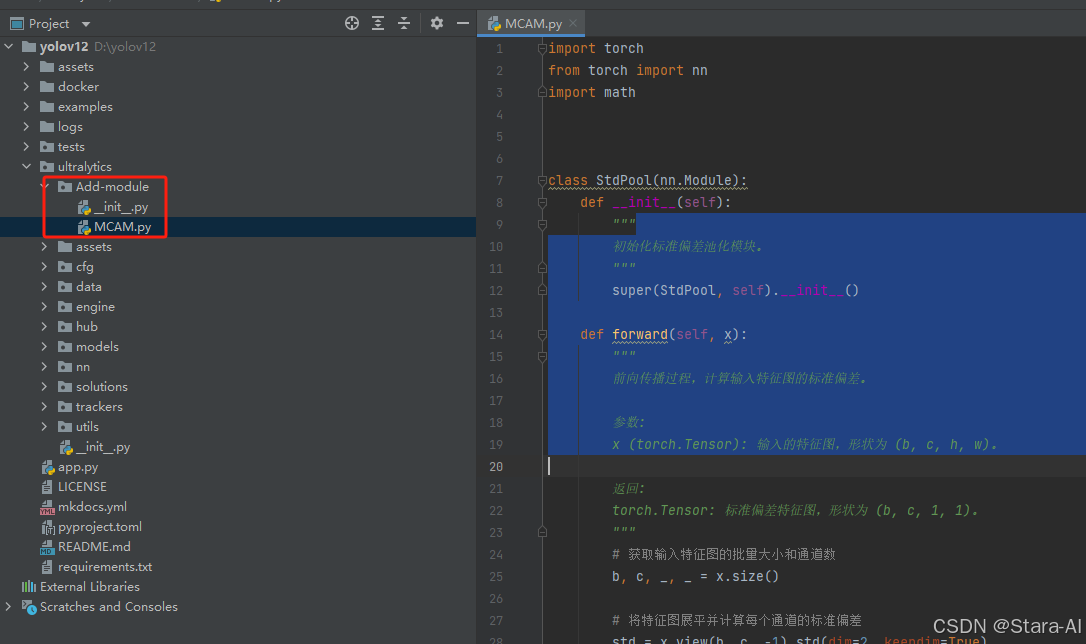
2. 在task.py中导入包
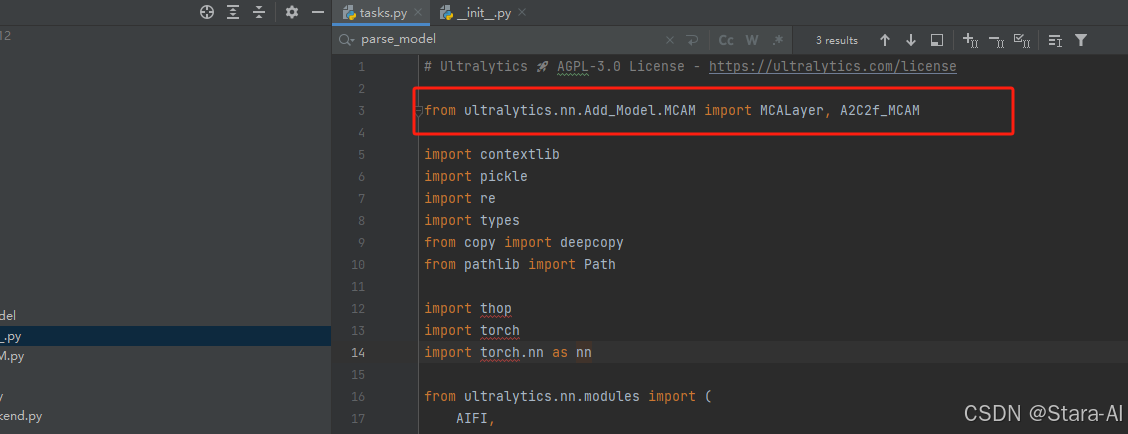
3. 在task.py中的模型配置部分下面代码
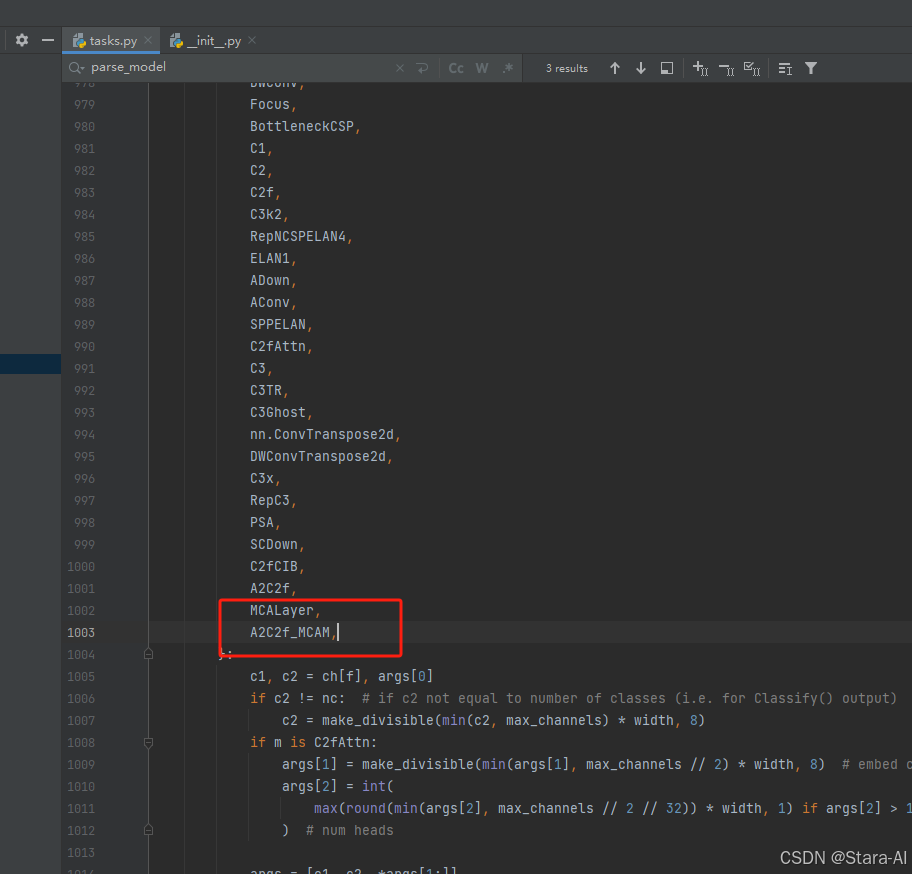
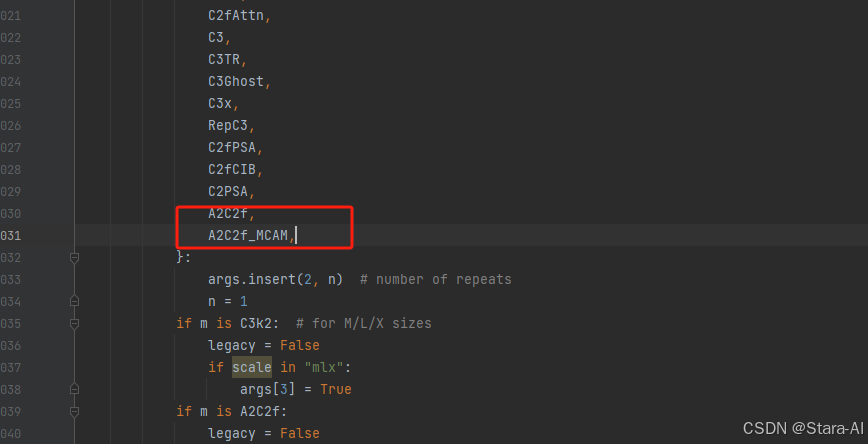
4. 将模型配置文件复制到YOLOV12.YAMY文件中
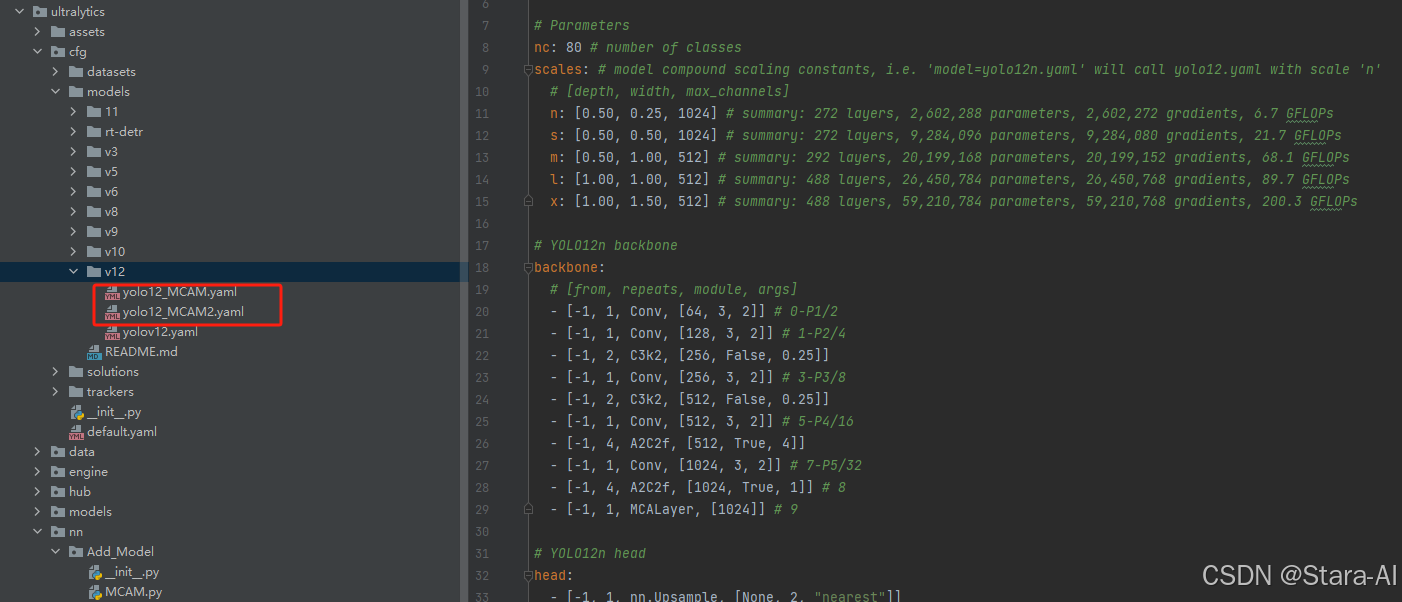
3.2 yolo12_MCAM.yaml
# Ultralytics 🚀 AGPL-3.0 License - https://ultralytics.com/license# YOLO12 object detection model with P3/8 - P5/32 outputs
# Model docs: https://docs.ultralytics.com/models/yolo12
# Task docs: https://docs.ultralytics.com/tasks/detect# Parameters
nc: 80 # number of classes
scales: # model compound scaling constants, i.e. 'model=yolo12n.yaml' will call yolo12.yaml with scale 'n'# [depth, width, max_channels]n: [0.50, 0.25, 1024] # summary: 272 layers, 2,602,288 parameters, 2,602,272 gradients, 6.7 GFLOPss: [0.50, 0.50, 1024] # summary: 272 layers, 9,284,096 parameters, 9,284,080 gradients, 21.7 GFLOPsm: [0.50, 1.00, 512] # summary: 292 layers, 20,199,168 parameters, 20,199,152 gradients, 68.1 GFLOPsl: [1.00, 1.00, 512] # summary: 488 layers, 26,450,784 parameters, 26,450,768 gradients, 89.7 GFLOPsx: [1.00, 1.50, 512] # summary: 488 layers, 59,210,784 parameters, 59,210,768 gradients, 200.3 GFLOPs# YOLO12n backbone
backbone:# [from, repeats, module, args]- [-1, 1, Conv, [64, 3, 2]] # 0-P1/2- [-1, 1, Conv, [128, 3, 2]] # 1-P2/4- [-1, 2, C3k2, [256, False, 0.25]]- [-1, 1, Conv, [256, 3, 2]] # 3-P3/8- [-1, 2, C3k2, [512, False, 0.25]]- [-1, 1, Conv, [512, 3, 2]] # 5-P4/16- [-1, 4, A2C2f, [512, True, 4]]- [-1, 1, Conv, [1024, 3, 2]] # 7-P5/32- [-1, 4, A2C2f, [1024, True, 1]] # 8- [-1, 1, MCALayer, [1024]] # 9# YOLO12n head
head:- [-1, 1, nn.Upsample, [None, 2, "nearest"]]- [[-1, 6], 1, Concat, [1]] # cat backbone P4- [-1, 2, A2C2f, [512, False, -1]] # 11- [-1, 1, nn.Upsample, [None, 2, "nearest"]]- [[-1, 4], 1, Concat, [1]] # cat backbone P3- [-1, 2, A2C2f, [256, False, -1]] # 14- [-1, 1, Conv, [256, 3, 2]]- [[-1, 12], 1, Concat, [1]] # cat head P4- [-1, 2, A2C2f, [512, False, -1]] # 17- [-1, 1, Conv, [512, 3, 2]]- [[-1, 8], 1, Concat, [1]] # cat head P5- [-1, 2, C3k2, [1024, True]] # 20 (P5/32-large)- [[15, 18, 21], 1, Detect, [nc]] # Detect(P3, P4, P5)3.3 yolo12_MCAM2.yaml
# Ultralytics 🚀 AGPL-3.0 License - https://ultralytics.com/license# YOLO12 object detection model with P3/8 - P5/32 outputs
# Model docs: https://docs.ultralytics.com/models/yolo12
# Task docs: https://docs.ultralytics.com/tasks/detect# Parameters
nc: 80 # number of classes
scales: # model compound scaling constants, i.e. 'model=yolo12n.yaml' will call yolo12.yaml with scale 'n'# [depth, width, max_channels]n: [0.50, 0.25, 1024] # summary: 272 layers, 2,602,288 parameters, 2,602,272 gradients, 6.7 GFLOPss: [0.50, 0.50, 1024] # summary: 272 layers, 9,284,096 parameters, 9,284,080 gradients, 21.7 GFLOPsm: [0.50, 1.00, 512] # summary: 292 layers, 20,199,168 parameters, 20,199,152 gradients, 68.1 GFLOPsl: [1.00, 1.00, 512] # summary: 488 layers, 26,450,784 parameters, 26,450,768 gradients, 89.7 GFLOPsx: [1.00, 1.50, 512] # summary: 488 layers, 59,210,784 parameters, 59,210,768 gradients, 200.3 GFLOPs# YOLO12n backbone
backbone:# [from, repeats, module, args]- [-1, 1, Conv, [64, 3, 2]] # 0-P1/2- [-1, 1, Conv, [128, 3, 2]] # 1-P2/4- [-1, 2, C3k2, [256, False, 0.25]]- [-1, 1, Conv, [256, 3, 2]] # 3-P3/8- [-1, 2, C3k2, [512, False, 0.25]]- [-1, 1, Conv, [512, 3, 2]] # 5-P4/16- [-1, 4, A2C2f_MCAM, [512, True, 4]]- [-1, 1, Conv, [1024, 3, 2]] # 7-P5/32- [-1, 4, A2C2f_MCAM, [1024, True, 1]] # 8# YOLO12n head
head:- [-1, 1, nn.Upsample, [None, 2, "nearest"]]- [[-1, 6], 1, Concat, [1]] # cat backbone P4- [-1, 2, A2C2f_MCAM, [512, False, -1]] # 11- [-1, 1, nn.Upsample, [None, 2, "nearest"]]- [[-1, 4], 1, Concat, [1]] # cat backbone P3- [-1, 2, A2C2f_MCAM, [256, False, -1]] # 14- [-1, 1, Conv, [256, 3, 2]]- [[-1, 11], 1, Concat, [1]] # cat head P4- [-1, 2, A2C2f_MCAM, [512, False, -1]] # 17- [-1, 1, Conv, [512, 3, 2]]- [[-1, 8], 1, Concat, [1]] # cat head P5- [-1, 2, C3k2, [1024, True]] # 20 (P5/32-large)- [[14, 17, 20], 1, Detect, [nc]] # Detect(P3, P4, P5)4. 运行train.py
from ultralytics.models import NAS, RTDETR, SAM, YOLO, FastSAM, YOLOWorldif __name__ == "__main__":# 使用自己的YOLOv12.yaml文件搭建模型并加载预训练权重训练模型model = YOLO(r"E:\Part_time_job_orders\YOLO_NEW\YOLOv12\ultralytics\cfg\models\12\yolo12_MCAM.yaml") \.load(r'E:\Part_time_job_orders\YOLO_NEW\YOLOv12\yolo12n.pt') # build from YAML and transfer weightsresults = model.train(data=r'E:\Part_time_job_orders\YOLO\YOLOv12\ultralytics\cfg\datasets\VOC_my.yaml', epochs=300,imgsz=640, batch=64,# cache = False,# single_cls = False, # 是否是单类别检测# workers = 0,# resume=r'D:/model/yolov8/runs/detect/train/weights/last.pt',amp=True)
本文提出的多维协作注意力机制(MCAM)通过轻量化设计实现了通道、高度、宽度三个维度的协同建模,显著提升了YOLOv12在复杂背景下的抗干扰能力和多尺度、小目标检测性能。实验验证表明,MCAM在实际应用中具有高效性和鲁棒性,为下一代目标检测模型的设计提供了新的思路。
资料文件可下载:https://download.csdn.net/download/m0_69402477/90690555?spm=1001.2014.3001.5503