k8s下的网络通信与认证
k8s网络通信
k8s通信整体架构
k8s通过CNI接口接入其他插件来实现网络通讯。目前比较流行的插件有flannel,calico等
CNI插件存放位置:# cat /etc/cni/net.d/10-flannel.conflist
插件使用的解决方案如下
虚拟网桥,虚拟网卡,多个容器共用一个虚拟网卡进行通信。
多路复用:MacVLAN,多个容器共用一个物理网卡进行通信。
硬件交换:SR-LOV,一个物理网卡可以虚拟出多个接口,这个性能最好。
容器间通信:
同一个pod内的多个容器间的通信,通过lo即可实现pod之间的通信
同一节点的pod之间通过cni网桥转发数据包。
不同节点的pod之间的通信需要网络插件支持
pod和service通信: 通过iptables或ipvs实现通信,ipvs取代不了iptables,因为ipvs只能做负载均衡,而做不了nat转换
pod和外网通信:iptables的MASQUERADE
Service与集群外部客户端的通信;(ingress、nodeport、loadbalancer)
calico网络插件
删除之前的网络fannel
部署calico
删除资源

删除配置文件
![]()
其他主机也要删除

下载calico并部署

有四个镜像

发布资源到私人仓库中

修改配置文件,
![]()


指定配置

运行配置文件,生成资源

等待是否都running

现在网络运行成功
k8s调度(Scheduling)
在那个资源中,用那个的资源,这就叫调度
调度在Kubernetes中的作用
调度是指将未调度的Pod自动分配到集群中的节点的过程
调度器通过 kubernetes 的 watch 机制来发现集群中新创建且尚未被调度到 Node 上的 Pod
调度器会将发现的每一个未调度的 Pod 调度到一个合适的 Node 上来运行
常用调度方法
nodename
nodeName 是节点选择约束的最简单方法,但一般不推荐
如果 nodeName 在 PodSpec 中指定了,则它优先于其他的节点选择方法
使用 nodeName 来选择节点的一些限制
如果指定的节点不存在。
如果指定的节点没有资源来容纳 pod,则pod 调度失败。
云环境中的节点名称并非总是可预测或稳定的
实例:




默认情况下是在node2节点上,现在我不想要在node2上,可以在配置文件上设置

再次运行查看

但是一般我们不使用这个指定,它对于这个你能掌控的node限制很大,没有符合要求的,就不会运行成功了,一直pengding


Nodeselector(通过标签控制节点)
名字不容易被确认,标签好被确认

如果任何节点上都没有标签,那他始终不会成功运行

查看标签

添加标签


修改标签

删除标签

在其他node上也一样

affinity(亲和性)
亲和与反亲和
nodeSelector 提供了一种非常简单的方法来将 pod 约束到具有特定标签的节点上。亲和/反亲和功能极大地扩展了你可以表达约束的类型。
使用节点上的 pod 的标签来约束,而不是使用节点本身的标签,来允许哪些 pod 可以或者不可以被放置在一起。
nodeAffinity节点亲和
那个节点服务指定条件就在那个节点运行
requiredDuringSchedulingIgnoredDuringExecution 必须满足,但不会影响已经调度
preferredDuringSchedulingIgnoredDuringExecution 倾向满足,在无法满足情况下也会调度pod
IgnoreDuringExecution 表示如果在Pod运行期间Node的标签发生变化,导致亲和性策略不能满足,则继续运行当前的Pod。
nodeaffinity还支持多种规则匹配条件的配置如
| 匹配规则 | 功能 |
|---|---|
| ln | label 的值在列表内 |
| Notln | label 的值不在列表内 |
| Gt | label 的值大于设置的值,不支持Pod亲和性 |
| Lt | label 的值小于设置的值,不支持pod亲和性 |
| Exists | 设置的label 存在 |
| DoesNotExist | 设置的 label 不存在 |
示例:
![]()

检查

存在Exists参数


反选,不能有这个标签,有这个标签就不选


Podaffinity(pod的亲和)
那个节点有符合条件的POD就在那个节点运行
podAffinity 主要解决POD可以和哪些POD部署在同一个节点中的问题
podAntiAffinity主要解决POD不能和哪些POD部署在同一个节点中的问题。它们处理的是Kubernetes集群内部POD和POD之间的关系。
Pod 间亲和与反亲和在与更高级别的集合(例如 ReplicaSets,StatefulSets,Deployments 等)一起使用时,
Pod 间亲和与反亲和需要大量的处理,这可能会显著减慢大规模集群中的调度。
示例:





testpod在哪里运行,他就在哪里运行

反选


Podantiaffinity(pod反亲和)

设定我的运行pod不亲和
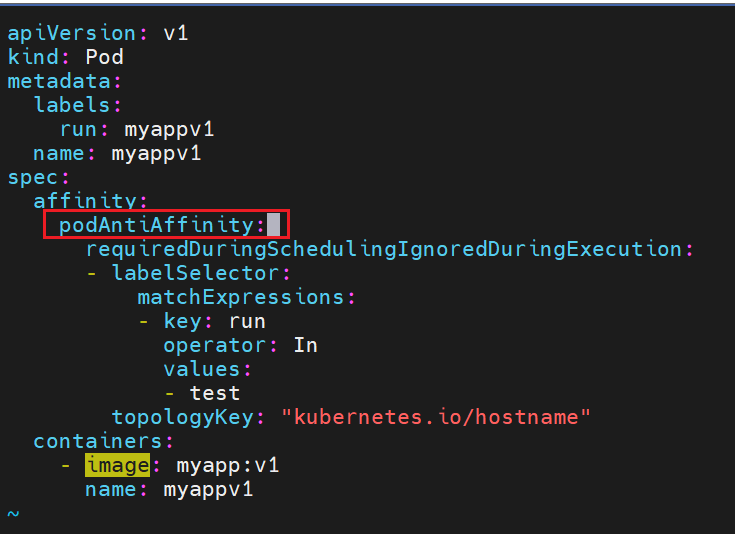
和反选的亲和不一样,但是效果一样

Taints(污点模式,禁止调度)
Taints(污点)是Node的一个属性,设置了Taints后,默认Kubernetes是不会将Pod调度到这个Node上
Kubernetes如果为Pod设置Tolerations(容忍),只要Pod能够容忍Node上的污点,那么Kubernetes就会忽略Node上的污点,就能够(不是必须)把Pod调度过去
可以使用命令 kubectl taint 给节点增加一个 taint:
$ kubectl taint nodes <nodename> key=string:effect #命令执行方法 $ kubectl taint nodes node1 key=value:NoSchedule #创建 $ kubectl describe nodes server1 | grep Taints #查询 $ kubectl taint nodes node1 key- #删除
其中[effect] 可取值:
| effect值 | 解释 |
|---|---|
| NoSchedule | POD 不会被调度到标记为 taints 节点 |
| PreferNoSchedule | NoSchedule 的软策略版本,尽量不调度到此节点 |
| NoExecute | 如该节点内正在运行的 POD 没有对应 Tolerate 设置,会直接被逐出 |
过滤污点的命令

创建模板

此时还没有设置污点,新建控制器生成两个pod,两个都被平等分配到两个pod上


可以看到它们被平等的分配到每一个节点上


这里先创建了一个pod检查效果,可以看到是被分配到了节点上的

设置了污点在node2上,原先建立的没有影响


但是新建的就全部在node1上了

同时生成6个,都是在node1上

删除污点

PreferNoSchedule
这个污点的效果是尽量不往上面放,但是没有了合适的节点还是得上

在node1上设置驱逐,也是一个污点,现在有的被驱逐出节点,以后也不能上这个节点上,那此时pod现在就到node2节点上了,因为相对来说在节点2上,还是可以放在上面的

修改污点可以直接改
现在设置一个不能往上放的污点在2上

但是我有一些必须要放的插件,该怎么容忍他呢
设定容忍污点




精确的匹配了键和值




删除所有节点,不影响后面的实验


使用身份再使用授权
认证(在k8s中建立认证用户)
创建UserAccount


建立自己的key
然后给它签名




#建立k8s中的用户


#为用户创建集群的安全上下文

#切换用户,用户在集群中只有用户身份没有授权

#切换会集群管理

RBAC(Role Based Access Control)
允许管理员通过Kubernetes API动态配置授权策略。RBAC就是用户通过角色与权限进行关联。
RBAC只有授权,没有拒绝授权,所以只需要定义允许该用户做什么即可
RBAC的三个基本概念
Subject:被作用者,它表示k8s中的三类主体, user, group, serviceAccount
Role:角色,它其实是一组规则,定义了一组对 Kubernetes API 对象的操作权限。
RoleBinding:定义了“被作用者”和“角色”的绑定关系
RBAC包括四种类型:Role、ClusterRole、RoleBinding、ClusterRoleBinding
Role 和 ClusterRole
Role是一系列的权限的集合,Role只能授予单个namespace 中资源的访问权限。
ClusterRole 跟 Role 类似,但是可以在集群中全局使用。
Kubernetes 还提供了四个预先定义好的 ClusterRole 来供用户直接使用
cluster-amdin、admin、edit、view
role授权实施
#生成role的yaml文件

#更改文件内容
上下两组授权

#创建role


#建立角色绑定



#切换用户测试授权

切换回管理员

clusterrole授权实施


#建立集群角色绑定

