大数据计算引擎(四)—— Impala
*重要工具Impala
介绍
Impala是Cloudera提供的⼀一款开源的针对HDFS和HBASE中的PB级别数据进⾏交互式实时查询的一个分布式,大规模并行处理(MPP)数据库引擎,它包括多个进程。最大卖点就是快。
Impala抛弃了了MapReduce 使⽤了类似于传统的MPP数据库技术,大大提⾼了查询的速度。
MPP (Massively Parallel Processing),就是⼤大规模并行处理理,在MPP集群中,每个节点资源都是独⽴享有也就是有独⽴立的磁盘和内存,每个节点通过⽹网络互相连接,彼此协同计算,作为整体提供数据服务。
简单来说,MPP是将任务并⾏的分散到多个服务器和节点上,在每个节点上计算完成后,将各自部分的 结果汇总在⼀一起得到最终的结果
对于MPP架构的软件来说聚合操作⽐比如计算某张表的总条数,则先进⾏局部聚合(每个节点并⾏计算),然后把局部汇总结果进⾏行行全局聚合(与Hadoop相似)。
Impala与Hive对⽐
Impala的技术优势
- Impala没有采取MapReduce作为计算引擎,MR是⾮非常好的分布式并⾏行行计算框架,但MR引擎更更多的是⾯面向批处理理模式,⽽而不是面向交互式的SQL执行。与 Hive相⽐比:Impala把整个查询任务转为一棵执行计划树,而不是一连串的MR任务,在分发执行计划后,Impala使⽤拉取的方式获取上个阶段的执行结果,把结果数据、按执行树流式传递汇集,减少的了把中间结果写⼊入磁盘的步骤,再从磁盘读取数据的开销。Impala使用服务的方式避免每次执行查询都需要启动的开销,即相比Hive没了MR启动时间。
- 使用LLVM(C++编写的编译器器)产生运行代码,针对特定查询生成特定代码。
- 优秀的IO调度,Impala支持直接数据块读取和本地代码计算。
- 选择适合的数据存储格式可以得到最好的性能(Impala支持多种存储格式)。
- 尽可能使用内存,中间结果不写磁盘,及时通过网络以stream的⽅方式传递。
安装配置
Impala⻆角⾊色
- impala-server:这个进程是Impala真正⼯工作的进程,官⽅方建议把impala-server安装在datanode节点,更靠近数据(短路路读取),进程名impalad
- impala-statestored:健康监控⻆角⾊色,主要监控impala-server,impala-server出现异常时告知给其它impala-server;进程名叫做statestored
- impala-catalogd :管理理和维护元数据(Hive),impala更更新操作;把impala-server更更新的元数据通知给其它impala-server,进程名catalogd
官⽅方建议statestore与catalog安装在同⼀一节点上!!
⭐⭐⭐HIVE要集群模式 开启Metastore 建议Matestore与impala-server在一个机子
linux3安装:
yum install impala -y
yum install impala-server -y
yum install impala-state-store -y
yum install impala-catalog -y
yum install impala-shell -y
linux1 linux2 安装
yum install impala-server -y
yum install impala-shell -y
linux3启动
nohup hive --service metastore &
linux1启动
nohup hive --service hiveserver2 &
短路路读取:就是Client与DataNode属于同⼀一节点,⽆无需再经过⽹网络传输数据,直接本地读取。
所有impala节点执行命令:
ln -s /opt/lxq/servers/hadoop-2.9.2/etc/hadoop/core-site.xml
/etc/impala/conf/core-site.xml
ln -s /opt/lxq/servers/hadoop-2.9.2/etc/hadoop/hdfs-site.xml
/etc/impala/conf/hdfs-site.xml
ln -s /opt/lxq/servers/hive-2.3.7/conf/hive-site.xml
/etc/impala/conf/hive-site.xml
所有节点修改:vim /etc/default/impala
<!--更更新如下内容 -->
IMPALA_CATALOG_SERVICE_HOST=linux123
IMPALA_STATE_STORE_HOST=linux123
MYSQL_CONNECTOR_JAR=/usr/share/java/mysql-connector-java.jar
所有节点创建:
# 所有节点创建节点,并建立软连接
mkdir -p /usr/share/java
ln -s /opt/lxq/servers/hive-2.3.7/lib/mysql-connector-java-5.1.46.jar
/usr/share/java/mysql-connector-java.jar
vim /etc/default/bigtop-utils
export JAVA_HOME=/opt/lxq/servers/jdk1.8.0_231
#linux123启动如下⻆角⾊色
service impala-state-store start
service impala-catalog start
service impala-server start
#其余节点启动如下⻆角⾊色
service impala-server start
ps -ef | grep impala
访问impalad的管理理界⾯面
http://linux123:25000/
访问statestored的管理理界⾯面
http://linux123:25010/
启动之后所有关于Impala的⽇日志默认都在/var/log/impala 这个路路径下,Linux123机器器上⾯面应该有三个进程,Linux121与Linux122机器器上⾯面只有⼀一个进程,如果进程个数不不对,去对应⽬目录下查看报错⽇日志.
Impala会附带安装一些其它东西,要删除
[root@linux122 conf]# which hadoop
/usr/bin/hadoop
[root@linux122 conf]# which hive
/usr/bin/hive
which命令 查找hadoop,hive等会发现,命令文件是/usr/bin/hadoop ⽽非我们自己安装的路
径,需要把这些删除掉,所有节点都要执⾏
[root@linux122 conf]# which hadoop
/usr/bin/hadoop
[root@linux122 conf]# which hive
/usr/bin/hive
rm -rf /usr/bin/hadoop
rm -rf /usr/bin/hdfs
rm -rf /usr/bin/hive
rm -rf /usr/bin/beeline
rm -rf /usr/bin/hiveserver2
#重新⽣生效环境变量量
source /etc/profile
进入impala命令: impala-shell
impala的操作流程更HIVE差不多,就不多重复写了
原理
查询原理
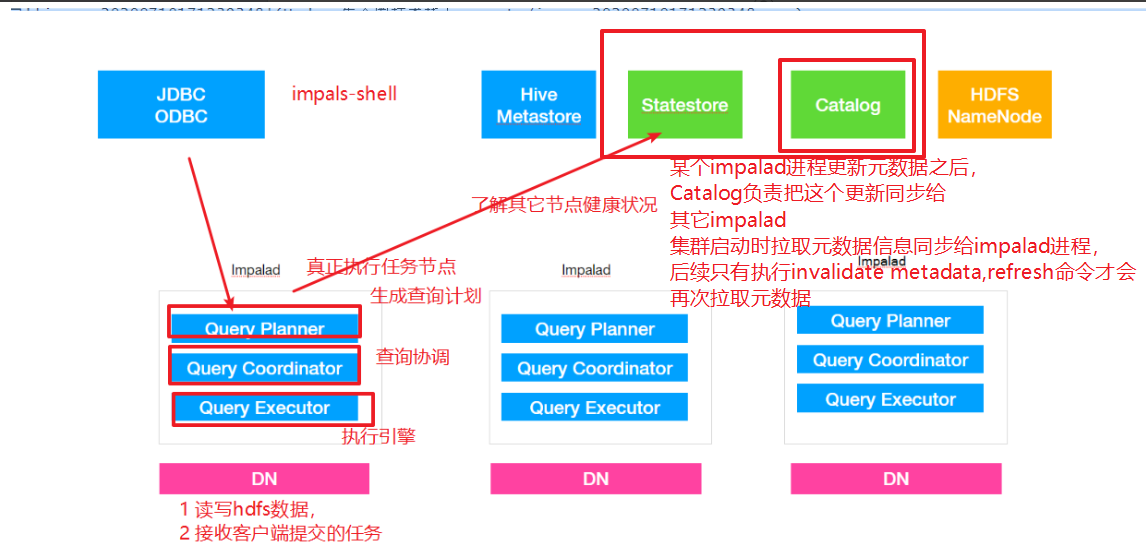
impalad
- 作⽤用,负责读写数据⽂文件,接收来⾃自Impala-shell,JDBC,ODBC等的查询请求,与集群其它Impalad分布式并行完成查询任务,并将查询结果返回给中心协调者。
- 角色名称为Impala Daemon,是在每个节点上运⾏行行的进程,是Impala的核⼼心组件,进程名是 Impalad;
- 为了保证Impalad进程了了解其它Impalad的健康状况,Impalad进程会一直与statestore保持通信。
- Impalad服务由三个模块组成:Query Planner、Query Coordinator和Query Executor,前两个 模块组成前端,负责接收SQL查询请求,解析SQL并转换成执⾏行行计划,交由后端执⾏行行,
statestored
- statestore监控集群中Impalad的健康状况,并将集群健康信息同步给Impalad,
- statestore进程名为statestored
catalogd
- Impala执行的SQL语句句引发元数据发⽣生变化时,catalog服务负责把这些元数据的变化同步给其它Impalad进程(⽇日志验证,监控statestore进程⽇日志)
- catalog服务对应进程名称是catalogd
- 由于⼀一个集群需要⼀一个catalogd以及⼀一个statestored进程,⽽而且catalogd进程所有请求都是经过statestored进程发送,所以官⽅方建议让statestored进程与catalogd进程安排同个节点。
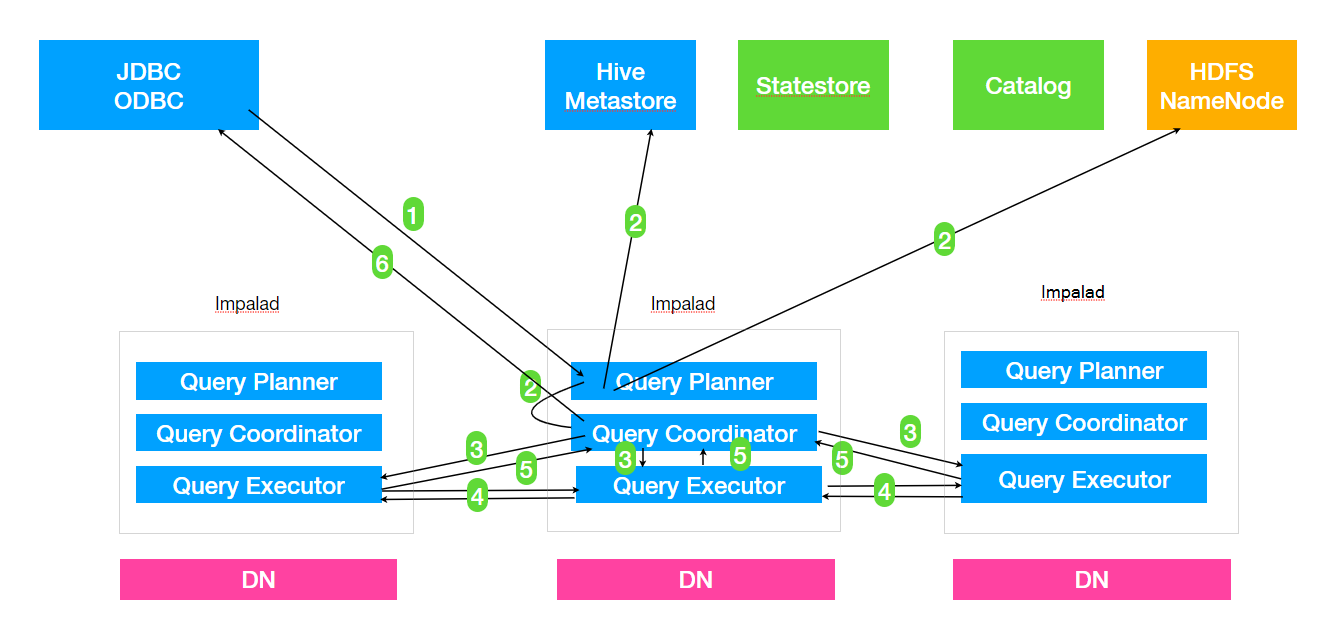
1. Client提交任务
Client发送⼀一个SQL查询请求到任意⼀一个Impalad节点,会返回⼀一个queryId⽤用于之后的客户端操
作。
2. ⽣生成单机和分布式执⾏行行计划
SQL提交到Impalad节点之后,Analyser依次执⾏行行SQL的词法分析、语法分析、语义分析等操作;
从MySQL元数据库中获取元数据,从HDFS的名称节点中获取数据地址,以得到存储这个查询相关
数据的所有数据节点
单机执⾏行行计划: 根据上⼀一步对SQL语句句的分析,由Planner先⽣生成单机的执⾏行行计划,该执⾏行行计
划是有PlanNode组成的⼀一棵树,这个过程中也会执⾏行行⼀一些SQL优化,例例如Join顺序改变、谓
词下推等。
分布式并⾏行行物理理计划:将单机执⾏行行计划转换成分布式并⾏行行物理理执⾏行行计划,物理理执⾏行行计划由⼀一
个个的Fragment组成,Fragment之间有数据依赖关系,处理理过程中需要在原有的执⾏行行计划
之上加⼊入⼀一些ExchangeNode和DataStreamSink信息等。
Fragment : sql⽣生成的分布式执⾏行行计划的⼀一个⼦子任务;
DataStreamSink:传输当前的Fragment输出数据到不不同的节点
3. 任务调度和分发
Coordinator将Fragment(⼦子任务)根据数据分区信息发配到不不同的Impalad节点上执⾏行行。Impalad
节点接收到执⾏行行Fragment请求交由Executor执⾏行行。
4. Fragment之间的数据依赖
每⼀一个Fragment的执⾏行行输出通过DataStreamSink发送到下⼀一个Fragment,Fragment运⾏行行过程中
不不断向coordinator节点汇报当前运⾏行行状态。
5. 结果汇总
查询的SQL通常情况下需要有⼀一个单独的Fragment⽤用于结果的汇总,它只在Coordinator节点运
⾏行行,将多个节点的最终执⾏行行结果汇总,转换成ResultSet信息。
6. 获取结果
客户端调⽤用获取ResultSet的接⼝口,读取查询结果。
优化
⽂文件格式
对于⼤大数据量量来说,Parquet⽂文件格式是最佳的
避免⼩小⽂文件
insert ... values 会产⽣生⼤大量量⼩小⽂文件,避免使⽤用
合理理分区粒度
利利⽤用分区可以在查询的时候忽略略掉⽆无⽤用数据,提⾼高查询效率,通常建议分区数量量在3万以下
(太多的分区也会造成元数据管理理的性能下降)
分区列列数据类型最好是整数类型
分区列列可以使⽤用string类型,因为分区列列的值最后都是作为HDFS⽬目录使⽤用,如果分区列列使⽤用
整数类型可以降低内存消耗
获取表的统计指标:在追求性能或者⼤大数据量量查询的时候,要先获取所需要的表的统计指标
(如:执⾏行行 compute stats )
减少传输客户端数据量量
聚合(如 count、sum、max 等)
过滤(如 WHERE )
limit限制返回条数
返回结果不不要使⽤用美化格式进⾏行行展示(在通过impala-shell展示结果时,添加这些可选参数: -
B、 --output_delimiter )
在执⾏行行之前使⽤用EXPLAIN来查看逻辑规划,分析执⾏行行逻辑
Impala join⾃自动的优化⼿手段就是通过使⽤用COMPUTE STATS来收集参与Join的每张表的统计信
息,然后由Impala根据表的⼤大⼩小、列列的唯⼀一值数⽬目等来⾃自动优化查询。为了了更更加精确地获取
每张表的统计信息,每次表的数据变更更时(如执⾏行行Insert,add partition,drop partition等)最好
都要执⾏行行⼀一遍COMPUTE STATS获取到准确的表统计信息。
感谢阅读!!!