【Tech Arch】Spark为何成为大数据引擎之王
Apache Spark作为当前大数据领域最流行的计算引擎之一,凭借其革命性的内存计算和弹性分布式数据集(RDD)架构,成功解决了Hadoop MapReduce在迭代计算、交互式查询和流式处理等场景下的性能瓶颈。Spark通过将数据缓存在内存中而非频繁落盘,实现了比MapReduce高100倍的处理速度,同时其丰富的生态系统和多语言支持使其成为数据科学、机器学习和实时分析的首选工具。本文将从Spark的基本概念、架构设计、解决的问题、关键特性、与同类产品的对比、使用方法等方面进行全面解析,帮助技术开发人员深入了解这一强大的数据处理框架。

一、什么是Spark:诞生背景
Apache Spark诞生于2009年,由加州大学伯克利分校的AMP实验室(Algorithms, Machines, and People Lab)开发,最初是作为研究项目存在的。Spark的出现源于对Hadoop MapReduce框架的深刻反思——MapReduce虽然在处理大规模批处理作业方面表现出色,但在需要多次迭代处理同一数据集的场景中存在严重性能问题。机器学习算法中的迭代计算、图计算中的多次遍历等任务,MapReduce每次都需要从磁盘重新加载数据,导致大量的I/O开销和处理时间。
Spark最初被称为"Spark"是因为它旨在"点燃"大数据处理的效率革命。2013年,Spark被捐赠给Apache基金会,2014年成为Apache顶级项目,标志着其从研究项目到工业级应用的转变。Spark的开发语言是Scala,但很快扩展支持了Java、Python和R等语言,使其更具普适性和易用性。
Spark的诞生背景与当时大数据处理面临的三大挑战密切相关:
迭代计算效率低下:MapReduce的批处理模型无法有效支持机器学习等需要多次迭代的算法,每次迭代都需要重新读取数据,导致性能严重下降。
交互式查询延迟高:Hive和Pig等工具虽然提供了SQL接口,但每次查询都需要启动完整的MapReduce作业,无法满足实时或近实时的交互需求。
流式处理支持不足:Hadoop生态系统主要面向批处理,缺乏对实时数据流的高效处理支持,而市场对实时分析的需求日益增长。
Spark正是针对这些挑战而设计的,通过引入内存计算和弹性分布式数据集(RDD)的概念,使大数据处理从"磁盘为中心"转变为"内存为中心",从而大幅提升处理速度和灵活性。

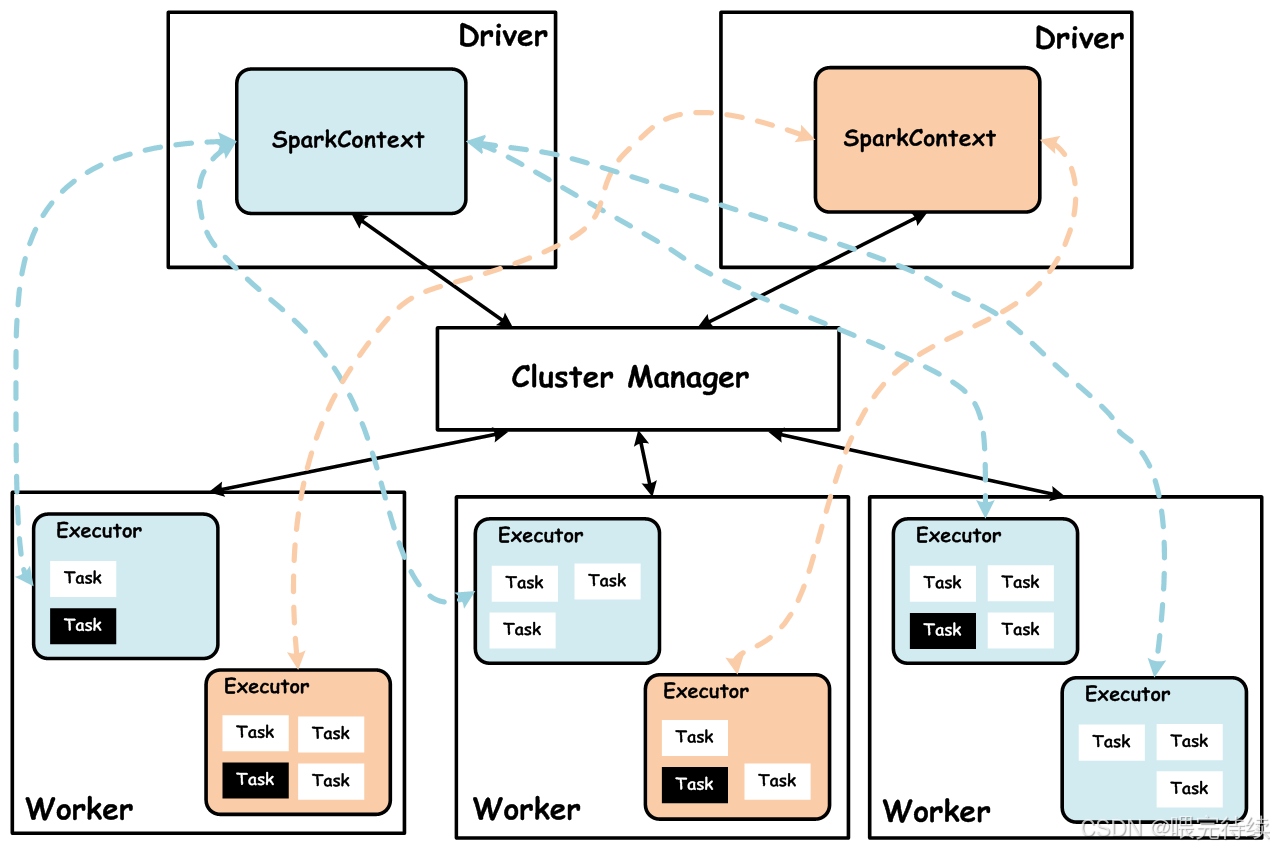
二、Spark架构设计
Spark的架构设计是其性能优势的核心,它采用了一种层次化的分布式计算模型,主要包括以下几个关键组件:
2.1 集群管理器
Spark支持多种集群管理器,使其能够无缝集成到不同的分布式环境:
| 集群管理器 | 适用场景 | 资源调度特点 |
|---|---|---|
| Standalone | 简单测试环境或自建集群 | FIFO调度,资源预分配 |
| YARN | Hadoop生态系统 | 动态资源分配,与Hadoop共享资源 |
| Mesos | 多租户共享集群 | 静态和动态共享CPU内核 |
| Kubernetes | 容器化云环境 | 细粒度资源管理,Executor以Pod形式运行 |
在Spark 3.5版本中,Kubernetes已成为主要部署方式,支持Spark应用直接在Kubernetes集群上运行。通过YAML配置文件定义资源请求和限制:
apiVersion: batch/v1
kind: Job
metadata:name: sparkJob
spec:template:spec:containers:- name: sparkimage: apache/spark-py:3.5.4command: ["spark-submit", "--class", "com.example.SparkApp", ...]resources:limits:cpu: "2"memory: "4Gi"requests:cpu: "1"memory: "2Gi"restartPolicy: Never2.2 驱动程序(Driver)
驱动程序是Spark应用程序的协调中心,负责整个计算流程的控制:
- 运行
main()函数和SparkContext,创建Spark应用的入口点 - 解析用户程序,构建DAG(有向无环图)表示计算流程
- 将DAG分解为多个阶段(Stage),每个阶段包含一组可以并行执行的任务(Task)
- 与集群管理器通信,申请和管理Executor资源
- 跟踪应用程序执行状态,处理异常和容错
在Kubernetes部署模式下,Driver通常以独立的Pod运行,而Executor则作为另一组Pod。这种分离使Spark能够更好地利用容器化环境的优势。
2.3 执行器(Executor)
执行器是Spark集群中实际执行计算任务的进程,每个Worker节点通常运行一个Executor:
- 长期驻留的进程,整个应用程序生命周期内保持活跃
- 内部包含线程池,以多线程方式执行Task,减少进程切换开销
- 包含BlockManager组件,负责管理内存和磁盘上的数据块
- 为应用程序缓存中间结果(RDD),支持迭代计算
- 通过心跳机制与Driver保持通信,报告状态和资源使用情况
Executor的资源分配是Spark性能的关键因素。在YARN和Kubernetes模式下,可以动态调整Executor的数量和资源配额,以适应不同的负载需求。
2.4 任务调度机制
Spark的任务调度采用两阶段调度模型,由DAGScheduler和TaskScheduler协作完成:
DAGScheduler:负责将DAG分解为多个Stage。其核心逻辑是根据RDD之间的依赖关系划分阶段:
- 窄依赖(Narrow Dependency):子RDD的每个分区只依赖于父RDD的一个或多个固定分区,允许流水线执行
- 宽依赖(Wide Dependency):子RDD的每个分区依赖于父RDD的所有分区,需要Shuffle操作,形成阶段边界
TaskScheduler:负责将Task分配到Executor的槽(Slot)中执行。每个Executor的槽数量由其分配的CPU核心数决定,任务通过多线程并行执行。
Spark的调度机制还支持数据本地性优化,优先将Task调度到存储所需数据的节点上,减少网络传输开销。这一特性与BlockManager的存储管理紧密配合,进一步提升了处理效率。
三、Spark解决的问题
3.1 迭代计算性能瓶颈
MapReduce在处理迭代计算时存在严重性能问题,主要原因是每次迭代都需要将中间结果写入磁盘,然后从磁盘重新读取。在PageRank算法中,每个迭代步骤都需要计算节点的PageRank值,然后保存到磁盘,下一次迭代再从磁盘读取。这种模式导致大量的I/O开销,随着迭代次数增加,性能下降明显。
Spark通过以下机制解决了这一问题:
- 弹性分布式数据集(RDD):中间结果可以缓存在内存中,避免重复I/O
- 血缘关系(Lineage):记录RDD之间的转换关系,当部分数据丢失时,可以重新计算而不是从磁盘读取
- 内存管理优化:采用混合内存管理策略,根据数据访问模式动态调整内存和磁盘的使用
HiBench基准测试显示,在PageRank工作负载中,Spark比Hadoop MapReduce快18倍 。随着迭代次数增加,性能差距更加明显,如资料[27]所示,优化后的Spark在6GB数据、237次迭代中执行时间比串行程序缩短93.7%,比原生Spark缩短68.2%。
3.2 交互式查询延迟高
传统的Hive和Pig等交互式查询工具基于MapReduce实现,每次查询都需要启动完整的MapReduce作业,导致响应时间通常在分钟级。这种延迟对于数据分析师和科学家来说难以接受,阻碍了快速迭代的数据探索过程。
Spark SQL通过以下技术创新解决了这一问题:
- DataFrame API:提供类似SQL的查询接口,但可以在内存中执行 -催化剂优化器(Catalyst Optimizer):基于规则和代价的查询优化,生成高效的执行计划
- 列式内存存储:仅扫描需要的列,减少内存使用和垃圾回收开销
- 内存缓存:支持将常用数据集缓存在内存中,加速后续查询
这些优化使得Spark SQL能够实现毫秒级到秒级的查询响应时间,比Hive快4-6倍。例如,在聚合和连接操作中,Spark SQL的性能分别比Hadoop提高了4.4倍和6.7倍 。
3.3 流式处理支持不足
Hadoop生态系统主要面向批处理,缺乏对实时数据流的高效处理支持。虽然有Flume和Kafka等工具处理数据收集,但缺乏流式计算引擎。
Spark通过以下组件解决了这一问题:
- Spark Streaming:采用微批处理(micro-batch)模式,将流数据分割为小批量处理,延迟在100ms级
- 结构化流处理(Structured Streaming):基于Spark SQL引擎,实现真正的流式处理,延迟可低至1ms级
- 动态资源分配:根据数据流的流量波动,动态增减Executor数量,避免资源浪费
在流处理场景中,Spark Streaming的延迟比MapReduce的批处理模式低2-3个数量级,同时保持了与批处理相同的API和优化机制,使得开发人员能够轻松地在批处理和流处理之间切换。
四、Spark关键特性
4.1 内存计算引擎
Spark的核心优势在于其内存计算引擎,通过将数据缓存在内存中而非频繁落盘,大幅提升处理速度。Spark的内存管理采用混合策略,根据数据访问模式动态调整内存和磁盘的使用 :
- 内存优先:尽可能将数据缓存在内存中,减少磁盘I/O
- 混合存储:当内存不足时,使用磁盘作为补充存储
- LRU缓存策略:自动驱逐最近最少使用的数据块,释放内存空间
- 细粒度数据放置:根据数据块的访问模式,智能地将数据放置在DRAM或NVM等不同存储层级
这种内存管理策略使得Spark在处理迭代计算时性能显著优于MapReduce。例如,在分波分析程序中,优化后的Spark执行时间比原生Spark缩短了约68.2%,单次迭代的计算代价减小了约80.5%。
4.2 弹性分布式数据集(RDD)
弹性分布式数据集(RDD)是Spark的核心抽象,它表示一个分布式的数据集合,可以并行操作:
- 分区机制:数据被划分为多个分区,分布在集群的不同节点上
- 转换操作:惰性执行的转换操作,如map、filter、union等
- 执行操作:触发计算的执行操作,如count、collect、save等
- 血缘关系:记录RDD之间的转换关系,支持容错和重新计算
- 缓存机制:支持将常用RDD缓存在内存中,加速后续操作
RDD的弹性体现在其能够根据数据访问模式和集群资源情况,动态调整数据的存储位置和方式。这种弹性使得Spark能够高效地处理各种数据规模和访问模式的场景。
4.3 DAG调度器
Spark的DAG调度器是其任务调度的核心,它将用户程序转换为有向无环图,并根据数据依赖关系分解为多个阶段 :
- 依赖分析:识别RDD之间的窄依赖和宽依赖
- 阶段划分:根据Shuffle边界划分阶段,每个阶段包含一组可以并行执行的任务
- 任务分配:将任务分配到Executor的槽中执行,优先考虑数据本地性
- 动态资源分配:根据任务等待情况,动态增减Executor数量
DAG调度器的智能划分使得Spark能够在保证正确性的同时,最大化并行度,减少任务等待时间。例如,当检测到某个应用存在任务处于等待调度状态时,Spark会根据检测次数呈指数增长地追增Executor数量(如第一次追增1个,第二次追增2个,第三次追增4个) 。
4.4 多语言支持
Spark提供了丰富的多语言API,使得开发人员可以根据熟悉程度和项目需求选择合适的编程语言:
- Scala:Spark的核心实现语言,提供最丰富的API和最佳性能
- Java:与Scala同等性能,适合Java生态系统的开发人员
- Python:通过PySpark库提供支持,语法简洁,适合数据科学场景
- R:通过SparkR库提供支持,适合统计分析和机器学习
- SQL:通过Spark SQL提供标准SQL接口,适合数据分析师
这种多语言支持使得Spark能够覆盖更广泛的技术社区和应用场景,从传统的数据工程师到现代的数据科学家都能找到适合自己的编程接口。
4.5 生态系统
Spark的生态系统是其另一个核心优势,它提供了一系列针对特定场景的库和工具:
- Spark Core:核心计算引擎,提供分布式任务调度和内存管理
- Spark SQL:结构化数据处理,支持DataFrame API和标准SQL查询
- Spark Streaming:实时流数据处理,支持微批处理和结构化流处理
- MLlib:机器学习库,提供分类、回归、聚类等算法
- GraphX:图计算库,提供图数据处理和分析功能
- Delta Lake:数据湖仓解决方案,支持ACID事务和流批一体处理

这些组件可以无缝集成,允许开发人员在同一个应用程序中混合使用不同的功能。例如,可以在处理实时数据流的同时,进行复杂的图计算和机器学习模型训练。
五、Spark与同类产品对比
5.1 Spark vs Hadoop MapReduce
| 特性 | Spark | Hadoop MapReduce |
|---|---|---|
| 计算模型 | 内存计算,中间结果缓存 | 磁盘计算,每次操作结果落盘 |
| 资源管理 | 动态资源分配,Executor可增减 | 静态资源分配,资源固定 |
| 任务调度 | 多线程模型,低启动开销 | 多进程模型,高启动开销 |
| 迭代计算 | 高效支持,性能提升100倍 | 低效支持,每次迭代重新读取数据 |
| 交互式查询 | 支持毫秒级响应 | 支持分钟级响应 |
| 流式处理 | 支持微批处理和结构化流处理 | 不支持实时流处理 |
Spark在性能方面显著优于MapReduce,特别是在迭代计算和交互式查询场景 。例如,在HiBench基准测试中,Spark在PageRank工作负载的性能比Hadoop提高18倍,SQL类工作负载如聚合和连接,Spark的性能分别比Hadoop提高4.4倍和6.7倍 。然而,Spark的内存消耗也比Hadoop更高,在大多数工作负载中,Spark会比Hadoop消耗更多的内存资源 。
5.2 Spark vs Flink
| 特性 | Spark | Flink |
|---|---|---|
| 计算模型 | 微批处理为主,支持结构化流处理 | 纯流处理模型,支持低延迟处理 |
| 资源管理 | 支持多种集群管理器,包括Kubernetes | 原生支持Kubernetes,资源管理更灵活 |
| 状态管理 | 通过缓存和检查点实现 | 原生支持状态管理,更高效 |
| 容错机制 | 基于血缘关系的重新计算 | 基于检查点的增量恢复 |
| 生态系统 | 成熟的生态系统,包括SQL、MLlib等 | 专注于流处理,生态系统正在扩展 |
Spark和Flink在流处理领域各有优势。Spark Streaming的微批处理模式适合对延迟要求不特别高的场景,而Flink的纯流处理模型更适合对延迟要求极高的场景。Spark的优势在于其成熟的生态系统和多语言支持,而Flink的优势在于其更低的延迟和更高效的资源管理。
5.3 Spark vs Storm
| 特性 | Spark | Storm |
|---|---|---|
| 计算模型 | 微批处理,支持结构化流处理 | 纯流处理模型 |
| 资源管理 | 需要外部集群管理器 | 原生集成ZooKeeper |
| 状态管理 | 通过缓存实现 | 最初不支持,后来通过Trident支持 |
| 数据处理语义 | 支持精确一次处理 | 支持至少一次处理 |
| 生态系统 | 成熟的生态系统,包括SQL、MLlib等 | 生态系统相对简单 |
Spark Streaming在流处理领域提供了更全面的解决方案 ,既支持批处理,又支持流处理,还支持分布式图计算、机器学习库等高级功能。而Storm虽然在实时性方面表现良好,但缺乏这些高级功能的支持 。
六、Spark使用方法
6.1 部署Spark
部署Spark是使用Spark的第一步,主要部署方式包括:
Standalone模式:适合简单的测试环境,部署步骤相对简单:
# 下载并解压Spark
wget https://archive.apache.org/dist/spark/spark-3.5.4/spark-3.5.4-bin-hadoop3.tgz
tar -zxvf spark-3.5.4-bin-hadoop3.tgz
mv spark-3.5.4-bin-hadoop3 spark-3.5.4# 配置环境变量
echo 'export SPARK_HOME=/path/to/spark-3.5.4' >> ~/.bashrc
echo 'export PATH=$PATH:$SPARK_HOME/bin' >> ~/.bashrc
source ~/.bashrc# 启动集群
cd $SPARK_HOME
sbin/start-master.sh
sbin/start-worker.sh -h <master-host>Kubernetes模式:适合容器化云环境,部署步骤如下:
# 创建Spark Master
kubectl create -f spark-master-controller.yaml# 创建Spark Master服务
kubectl create -f spark-master-service.yaml# 创建Spark Worker
kubectl create -f spark-worker-controller.yaml# 验证部署
kubectl get all6.2 Python API使用示例
Spark提供了丰富的Python API,以下是几个常见场景的代码示例:
批处理示例:
from pyspark.sql import SparkSession# 创建SparkSession
spark = SparkSession.builder \.appName("WordCount") \.master("local[*]") \.getOrCreate()# 加载数据
df = spark.read.text("input.txt")# 处理数据
word_counts = df.rdd \.flatMap(lambda line: line.split()) \.map(lambda word: (word, 1)) \.reduceByKey(lambda a, b: a + b)# 保存结果
word_counts.toDF().write.csv("output.csv")# 停止SparkSession
spark.stop()结构化流处理示例:
from pyspark.sql import SparkSession
from pyspark.sql functions import col, window
from pyspark.sql types import StructType, StructField, IntegerType, StringType, TimestampType# 创建SparkSession
spark = SparkSession.builder \.appName("RealTimeWordCount") \.config("spark动态资源分配 enabled", "true") \.getOrCreate()# 定义输入输出结构
schema = StructType([StructField("word",弦型),StructField("count",整型),StructField("timestamp",时间戳类型)
])# 读取实时数据
stream_df = spark.readStream \.schema(schema) \.format("kafka") \.option("kafka.bootstrap.servers", "localhost:9092") \.option("subscribe", "word_count_stream") \.load()# 处理实时数据
windowed_counts = stream_df \.withWatermark("timestamp", "5 minutes") \.groupby(window(col("timestamp"), "1 hour", "5 minutes"), col("word")) \.sum("count")# 输出结果
query = windowed_counts.writeStream \.outputMode("更新") \.format("console") \.start()# 等待流处理完成
query.awaitTermination()机器学习示例:
from pyspark.sql import SparkSession
from pyspark.ml.classification import NaiveBayes
from pyspark.ml.evaluation import MultinomialClassificationEvaluator
from pyspark.ml.feature import Vectorizer, StringIndexer
from pyspark.sql functions import col# 创建SparkSession
spark = SparkSession.builder \.appName("NaiveBayesExample") \.getOrCreate()# 加载数据
data = spark.read.format("libsvm").load("data/mllib sampleNB.txt")# 特征工程
labelIndexer = StringIndexer(inputCol="label", outputCol="indexedLabel").fit(data)
featureVectorizers = Vectorizer(inputCol="features", outputCol="vectorizedFeatures").fit(data)# 组装管道
pipeline = Pipeline(stages=[labelIndexer, featureVectorizers, nb])# 训练模型
model = pipeline.fit trainingData# 评估模型
evaluator = MultinomialClassificationEvaluator(labelCol="indexedLabel", predictionCol="prediction", metricName="accuracy")
accuracy = evaluator.evaluate predictions
print(f"模型准确率: {accuracy}")6.3 优化配置
Spark的性能可以通过多种配置参数进行优化:
# 提交任务时的优化配置
spark-submit \--master k8s://http://172.17.67.89:8001 \--deploy-mode client \--name spark-video-compress \--conf spark.kubernetes.namespace=default \--conf spark.executor.instances=5 \--conf spark.executor.cores=2 \--conf spark.executor.memory=1000m \--conf spark动态资源分配.enabled=true \--conf spark.kubernetes.container.image=apache/spark-py \--conf spark.kubernetes.authenticate driver.serviceAccountName=spark \--conf spark.kubernetes.executor.volumes persistentVolumeClaim nfs-pvc-volume.options氯胺my-nfs-pvc \--pyFiles /path/to/your python files \/path/to/your application.py这些配置参数可以根据具体应用场景进行调整,例如:
spark.executor memory:设置Executor内存大小,影响处理能力spark动态资源分配.enabled:启用动态资源分配,适应负载变化spark.sql shuffle.partitions:设置Shuffle分区数,影响并行度和资源使用spark.sql adaptive.enabled:启用自适应查询执行,优化执行计划
七、Spark生态系统与未来趋势
7.1 生态系统演进
Spark的生态系统经历了从简单到复杂的演进过程:
- 初期:以Spark Core为核心,提供基本的分布式计算功能
- 扩展期:引入Spark SQL、Spark Streaming、MLlib和GraphX等组件
- 成熟期:与数据湖技术结合,形成完整的数据湖仓解决方案
Delta Lake是Spark生态系统的重要扩展 ,它解决了数据湖中的不一致性问题,提供了ACID事务、时间旅行和流批一体处理等特性。Delta Lake与Spark SQL深度集成,允许开发人员在数据湖上执行类似数据仓库的操作。
7.2 云原生趋势
随着云计算的发展,Spark正朝着云原生方向演进,更好地适应容器化和弹性伸缩的云环境:
- Kubernetes原生支持:Spark可以直接在Kubernetes上运行,无需依赖YARN或Mesos
- 云服务集成:与AWS、Azure、GCP等云平台深度集成,提供一键部署和管理功能
- 自动扩缩容:根据负载自动调整集群规模,优化资源使用和成本
- 云存储优化:针对云存储(如S3)的特性进行优化,提高读写效率
这些云原生特性使得Spark能够在云环境中实现更高的弹性和效率,适应不断变化的业务需求。
7.3 未来发展方向
Spark未来的发展方向包括:
- 流批一体:进一步融合批处理和流处理,提供统一的API和优化策略
- 机器学习集成:加强与深度学习框架的集成,提供端到端的AI解决方案
- 图计算扩展:增强GraphX的功能,支持更复杂的图算法和分析
- 数据湖优化:与Delta Lake等数据湖技术更紧密集成,提供完整的数据湖解决方案
- 云原生深化:更好地适应容器化和弹性伸缩的云环境,提供更高效的资源管理
随着这些方向的发展,Spark将继续引领大数据处理的创新,为数据驱动的业务提供更强大的支持。
八、文末
Apache Spark通过内存计算和弹性分布式数据集(RDD)的概念,成功解决了Hadoop MapReduce在迭代计算、交互式查询和流式处理等场景下的性能瓶颈 。其丰富的生态系统和多语言支持使其成为数据处理领域的首选工具,适用于从批处理到实时分析的各种场景。
对于技术开发人员,建议从以下几个方面入手学习和使用Spark:
- 先掌握Spark Core的基本概念和API,理解RDD和DAG的机制
- 然后学习Spark SQL和DataFrame API,掌握结构化数据处理的方法
- 根据具体需求,选择学习Spark Streaming、MLlib或GraphX等组件
- 了解Spark在不同集群管理器上的部署和配置方法
- 掌握Spark性能优化的技巧,包括内存配置、资源分配和查询优化
随着大数据技术的不断发展,Spark将继续演进,与云原生和AI技术深度融合。技术开发人员应该持续关注Spark的最新发展,掌握其在不同场景下的最佳实践,以充分发挥Spark的强大能力,为数据驱动的业务提供更高效、更灵活的支持。