机器学习05-朴素贝叶斯算法
前言:
至此我们学习了sklearn库里的特征工程(对数据集进行处理),学习了对模型评估、选择和调优。本节学习的是机器学习中的算法之一朴素贝叶斯算法。它是一个可以对数据集进行分类任务的算法,它运用的就是概率论中的贝叶斯定理,而朴素贝叶斯就是建立在特征之间独立的情况下。本节会运用概率论中的一些知识点和公式,复习或者了解一下会更助于我们学习该算法。
一、朴素贝叶斯分类算法
1、贝叶斯算法
贝叶斯算法就是使用概率来估计数据的类别信息
条件概率:在B发生了的时候,A发生的概率,数学符号P(A|B)
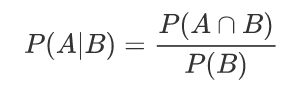
(P(A∩B):就是AB同时发生的概率,P(B):B发生的概率)
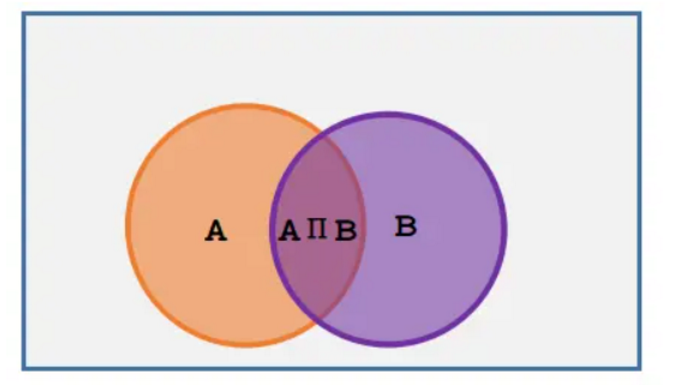
独立事件:事件A和事件B两个发生的时候,互不影响 ,即

联合概率:指两个或多个事件同时发生的概率,记作 P(A∩B) 或 P(A,B)。

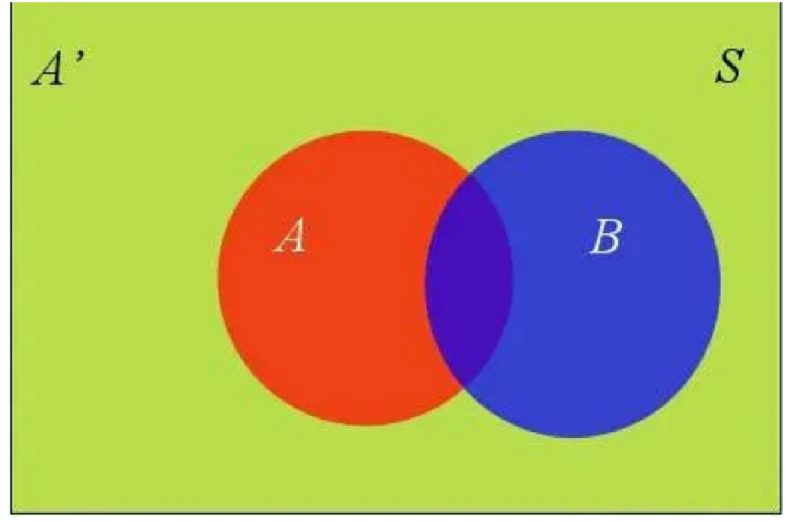
联合概率和条件概率的关系:如果 A 和 A' 构成样本空间的一个划分,那么事件 B 的概率,就等于 A 和 A' 的概率分别乘以 B 对这两个事件的条件概率之和。
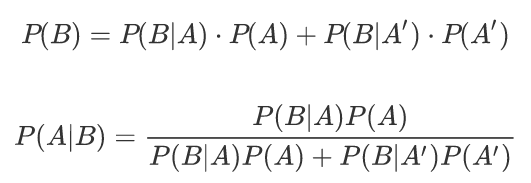
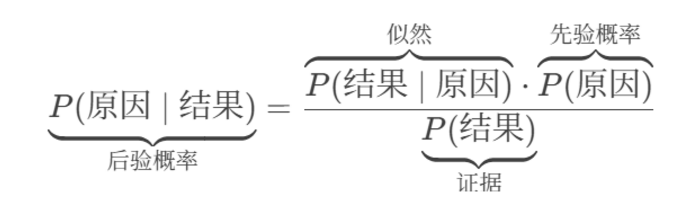
贝叶斯定理:是基于假设的先验概率、给定假设下观察到不同数据的概率,提供了一种计算后验概率的方法。
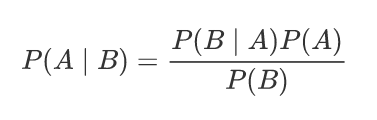
P(A|B):在事件 B 发生的条件下,事件 A 发生的概率(后验概率,即更新后的信念)
P(B|A):在事件 A 发生的条件下,事件 B 发生的概率(似然,即观测数据的可能性)
P(A):事件 A 的先验概率(未考虑 B 时的初始概率)
P(B):所有情况下 B 发生的总概率
假设我们收到了一封邮件,有可能是垃圾邮件、有可能不是垃圾邮件
假设垃圾邮件中存在词语国外高薪业务。
先验概率:根据以往的经验,收到邮件之后,我认为它是垃圾邮件的一个概率值。
似然:认为邮件就是垃圾邮件,邮件中有国外高新业务的一个概率情况。
证据:一般可以忽略,这个值就是拿来做归一化的。
后验概率:最后得到这个包含了国外高薪业务的词语的邮件是垃圾邮件的概率情况。
公式如下所示:

如果这个垃圾邮件的判断条件除了出现国外高薪业务的词语还有免费的词语,即结果有两个。则公式如下所示:

2、朴素贝叶斯
贝叶斯定理的贝叶斯模型是一类简单常用的分类算法,也是一种基于概率论的监督学习算法,它广泛应用于分类任务中。
设X 是特征,a 是类别,则贝叶斯公式有:
朴素贝叶斯中朴素二字就是建立在假设各个特征之间独立的情况下,那么概率公式就可以转化为
3、拉普拉斯平滑系数
在有的情况下,由于样本数量少,有的数据特征并没有出现在样本中,那么计算出来的概率可能出现0值的情况。但在实际中,即使某个特征没有出现在样本中,那么也不能够排除它在测试样本中出现的情况。所以就可以使用拉普拉斯平滑系数来避免这种情况(零概率陷阱)
计算公式:
计算公式如下:
| 符号 | 含义 |
|---|---|
| Ni | 在类别 C 中,特征 F1 取当前特定值的样本数量 |
| N | 类别 C 的总样本数 |
| α | 平滑系数(通常取 1,称为拉普拉斯平滑;若取其他值,称为 Lidstone 平滑) |
| m | 特征 F1 的可能取值数(例如,若 F1 是“颜色”,则 m 为颜色种类数) |
4、案例
用朴素贝叶斯算法对鸢尾花的分类案例代码:
import numpy as np
#导入朴素贝叶斯
from sklearn.native_bayes import GaussianNB
#导入数据集
from sklearn.datasets import load_iris
#导入划分数据集包
from sklearn.model_selection import train_test_split
#导入模型评估指标
from sklearn.metrics import accuracy_score, classification_report, confusion_matrix
#加载数据集
iris=load_iris()
data,target=iris.data,iris.target
X_train,X_test,y_train,y_test=train_test_split(data,target,test_size=0.2,random_state=42)
#创建估计器(创建对象)
gnb=GaussianNB()
#训练模型
gnb.fit(X_train,y_train)
#预测
"""predict:对应标签predict_proba:每个标签的概率
"""
np.set_printoptions(suppress= True)#忽略科学计数法
#新数据
predict_data=np.array([[5.1,3.5,1.4,0.2]])
print("新数据中的预测数据",gnb.predict(predict_data))
print("新数据中的预测概率",gnb.predict_proba(predict_data))
# 模型评估
result=gnb.predict(X_test)
#输出模型得分
print("模型得分:\n", gnb.score(X_test,y_test))
print("预测准确率:\n", accuracy_score(y_test, result))
print("分类报告:\n", classification_report(y_test, result))
print("混淆矩阵:\n", confusion_matrix(y_test, result))结果输出:
新数据中的预测数据 [0] 新数据中的预测概率 [[1. 0. 0.]] 模型得分:1.0 预测准确率:1.0 分类报告:precision recall f1-score support 0 1.00 1.00 1.00 101 1.00 1.00 1.00 92 1.00 1.00 1.00 11 accuracy 1.00 30macro avg 1.00 1.00 1.00 30 weighted avg 1.00 1.00 1.00 30 混淆矩阵:[[10 0 0][ 0 9 0][ 0 0 11]]