Spark03-RDD02-常用的Action算子
一、常用的Action算子
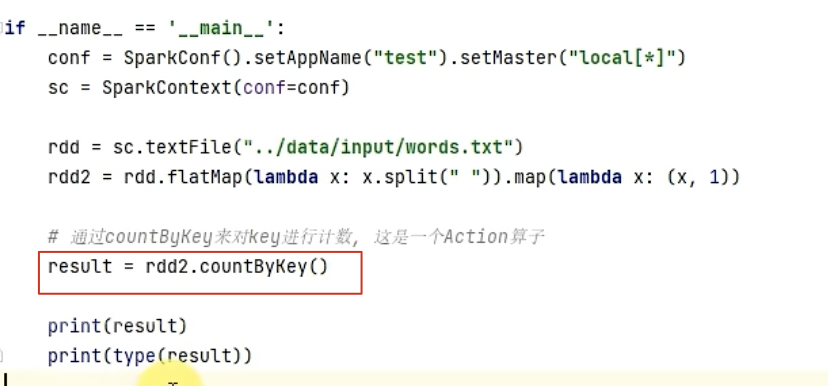
1-1、countByKey算子
作用:统计key出现的次数,一般适用于K-V型的RDD。
【注意】:
1、collect()是RDD的算子,此时的Action算子,没有生成新的RDD,所以,没有collect()!!!
2、Action算子,返回值不再是RDD,而是字典!
示例:

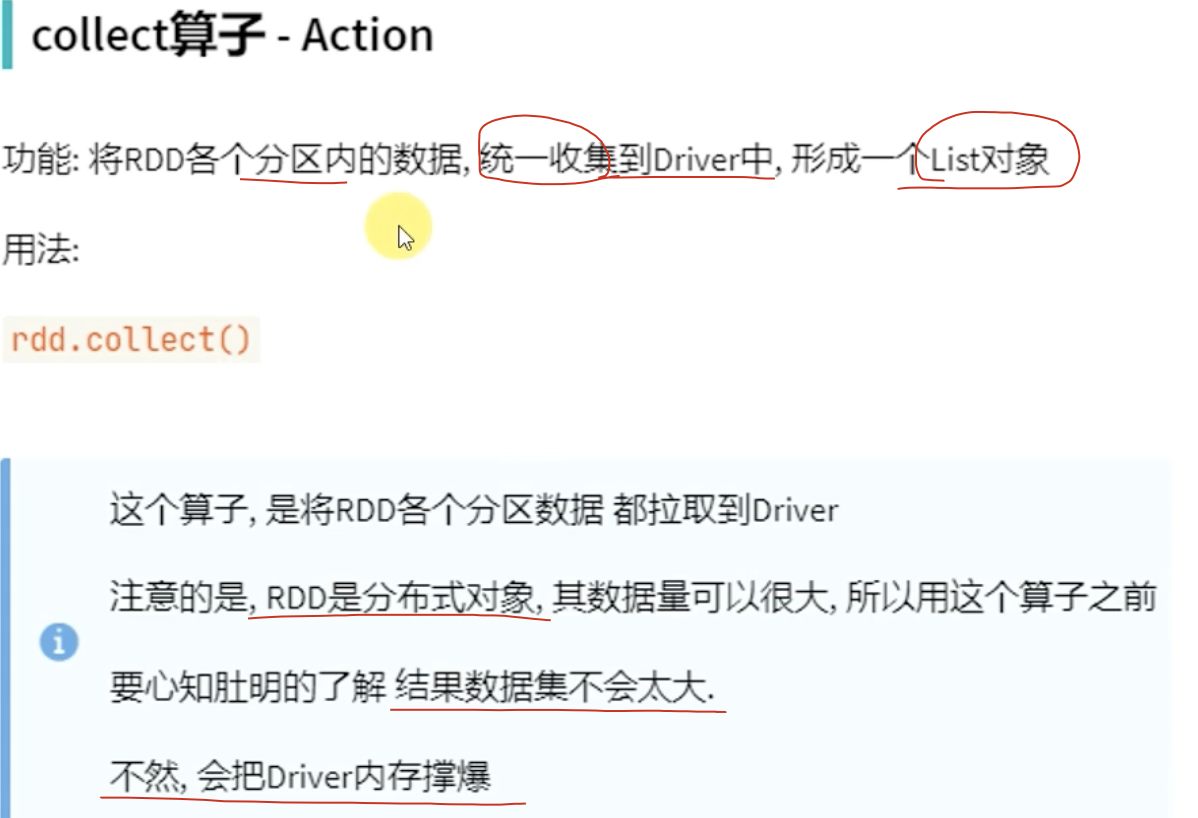
1-2、collect算子
1-3、reduce算子

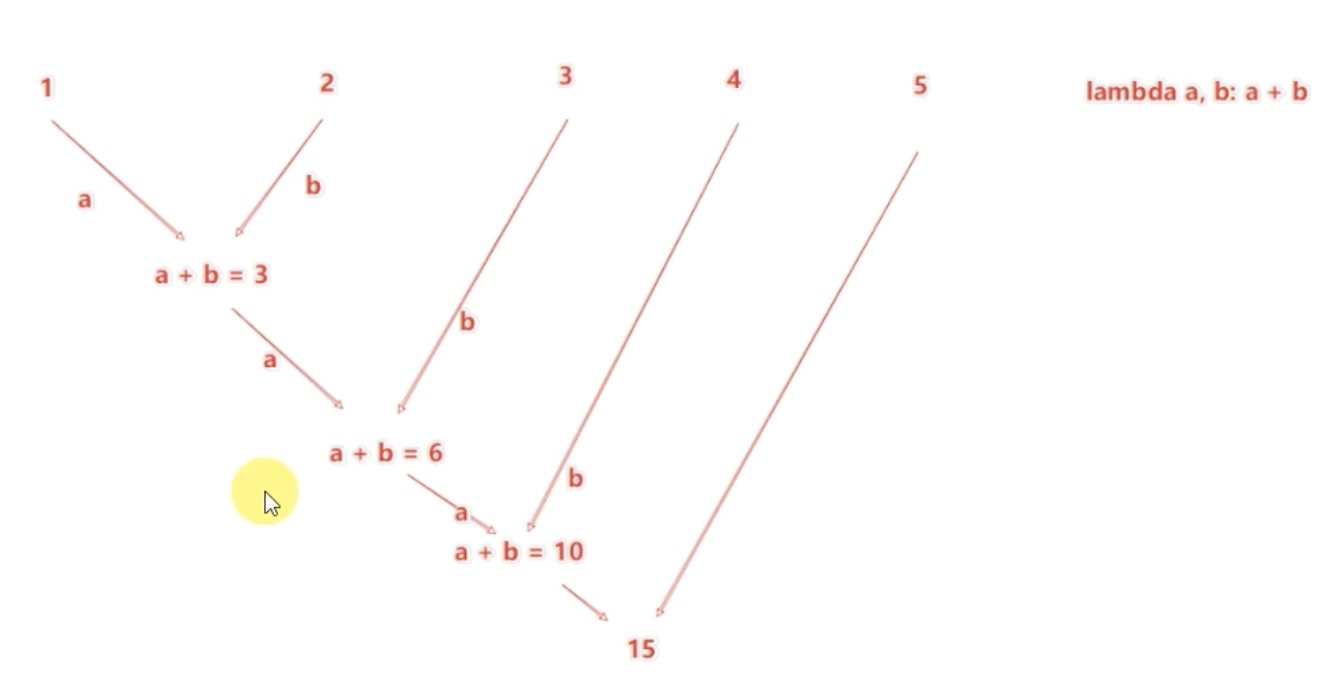
示例:
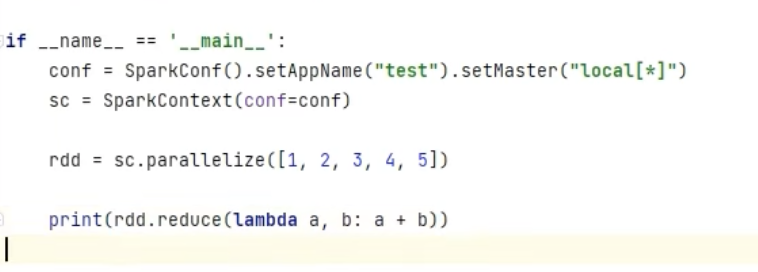
返回结果:15
回顾:reduceByKey的逻辑:Spark03-RDD01-简介+常用的Transformation算子-CSDN博客
1-4、fold算子

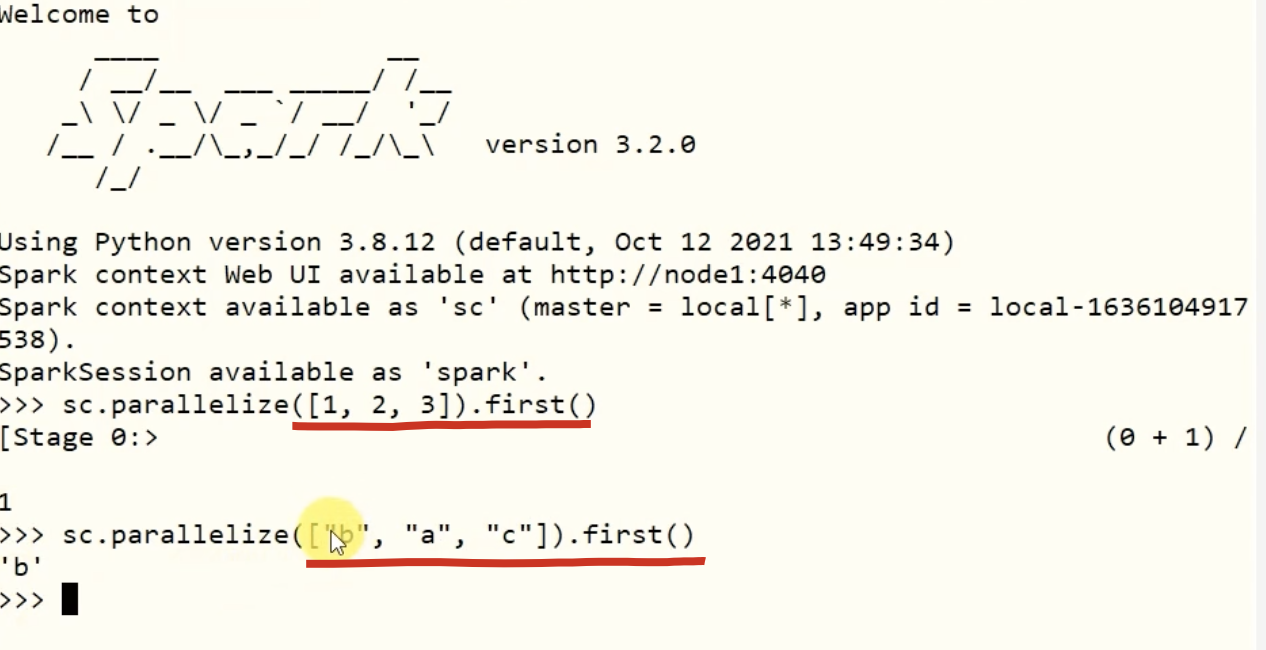
1-5、first算子

示例:
1-6、take算子
功能:获取RDD的前N个元素,组合成list返回给你。
示例:

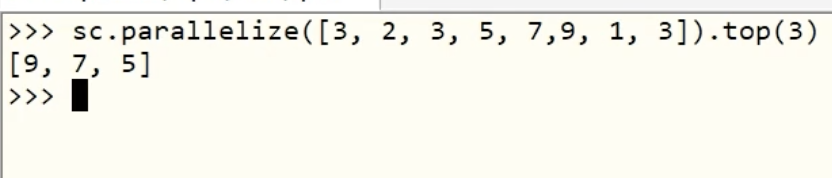
1-7、top算子
功能:对RDD数据集,先降序,再取前N个。相当于:取最大的前N个数字,返回类型:list。
【注意】:item之间的比较,可以自定义比较函数。
1-8、count算子
计算RDD有多少条数据,返回的是一个数字!

1-9、takeSample算子
1. 作用
takeSample 用于从 RDD 中随机抽取一定数量的元素,返回的是一个 Python list(而不是 RDD)。
它常用于数据探索,比如从一个很大的分布式数据集中 随机取样 看看大概长什么样。
2. 函数签名
RDD.takeSample(withReplacement, num, seed=None)
-
withReplacement:
True/False-
True:有放回抽样(同一个元素可能被多次抽到) -
False:无放回抽样(每个元素最多出现一次)
-
-
num:
int-
需要抽取的样本数量
-
-
seed:
int(可选)-
随机数种子。指定后每次结果一致;不指定时每次运行结果可能不同
-
3. 返回值
返回的是一个 list,包含抽到的样本。
⚠️ 注意:不会返回一个 RDD,而是直接把样本收集到 driver 程序。
在 PySpark 的
takeSample里,如果是无放回抽样 (withReplacement=False),且你请求的样本数量 大于 RDD 总数,即:num > RDD.count(),结果会直接返回 整个 RDD,不会报错。
4. 示例代码
from pyspark import SparkContextsc = SparkContext("local", "TakeSampleExample")data = sc.parallelize(range(1, 101)) # RDD: 1 ~ 100# 无放回抽样,取 10 个
sample1 = data.takeSample(False, 10)
print("无放回抽样:", sample1)# 有放回抽样,取 10 个
sample2 = data.takeSample(True, 10)
print("有放回抽样:", sample2)# 固定随机种子
sample3 = data.takeSample(False, 10, seed=42)
print("固定种子:", sample3)
运行可能结果:
无放回抽样: [57, 3, 85, 21, 92, 38, 44, 71, 5, 66]
有放回抽样: [21, 21, 45, 72, 3, 98, 45, 12, 7, 7]
固定种子: [63, 2, 73, 82, 23, 18, 47, 74, 96, 94]
5. 特点 & 注意点
-
返回 Python list,所以抽样结果会被拉回 driver 内存。
-
不适合
num特别大(比如几百万),会导致 driver 内存爆炸。
-
-
比
sample不同-
sample(withReplacement, fraction, seed)→ 返回 RDD(按比例抽样) -
takeSample(withReplacement, num, seed)→ 返回 list(按数量抽样)
总结:
-
想要 指定比例抽样 → 用
sample -
想要 指定数量抽样 → 用
takeSample
-
6. 使用场景
-
调试 / 探索:比如 RDD 太大,不可能直接
collect(),就可以takeSample(False, 20)随机取 20 个元素看一眼。 -
机器学习抽样:从数据集中随机取一部分作为训练集 / 测试集。
-
模拟实验:需要随机数据时快速取一批样本。
1-10、takeOrder算子
1. 作用
takeOrdered 用于 从 RDD 中取出前 n 个元素,返回的是一个 Python list。
-
默认情况下,按 升序 排序后取前 n 个;(最小的前n个)
-
也可以通过
key参数指定排序规则。
2. 函数签名
RDD.takeOrdered(num, key=None)
-
num:
int
要取的元素个数。 -
key:
function(可选)
用来指定排序方式。-
不指定 → 默认升序
-
指定
lambda x: -x→ 可以变成降序
-
3. 返回值
返回一个 list,长度最多是 num,包含排序后的前 n 个元素。
(⚠️ 和 takeSample 一样,也会把结果拉回到 driver)
4. 示例代码
from pyspark import SparkContext
sc = SparkContext("local", "TakeOrderedExample")data = sc.parallelize([5, 1, 8, 3, 2, 10, 6])# 取前 3 个最小的元素(默认升序)
result1 = data.takeOrdered(3)
print("最小的3个:", result1)# 取前 3 个最大的元素(用 key 参数)
result2 = data.takeOrdered(3, key=lambda x: -x)
print("最大的3个:", result2)# 按元素的平方排序,取前 3 个
result3 = data.takeOrdered(3, key=lambda x: x*x)
print("平方最小的3个:", result3)
可能输出:
最小的3个: [1, 2, 3]
最大的3个: [10, 8, 6]
平方最小的3个: [1, 2, 3]
5. 特点 & 注意点
-
返回 Python list,结果会直接拉到 driver。
-
如果
num很大,可能导致内存压力。
-
-
和其他算子的区别
-
top(n):返回最大的 n 个元素,默认降序。(只能是降序) -
takeOrdered(n):返回最小的 n 个元素,默认升序。 -
sortBy(key, ascending, numPartitions):返回排序后的 RDD,比takeOrdered重得多,因为它要分布式全排序。
总结:
-
只想取 前 n 个 → 用
takeOrdered或top(高效) -
想要 全局排序 → 用
sortBy(代价更大)
-
6. 使用场景
-
取 Top-N 或 Bottom-N 样本,比如成绩前 10 名、销售额最高的 5 个商品。
-
数据探索时快速查看极值(最小/最大值)。
-
机器学习前的数据预处理,比如截取一部分样本。
1-11、foreach算子
1. 作用
foreach 用于对 RDD 的每个元素执行一个指定的函数(function),但 不会返回任何结果。
它的典型用途是:
-
在每个分区的 worker 节点上,对数据做副作用操作,比如写数据库、写文件、更新计数器。
2. 函数签名
RDD.foreach(f)
-
f: 一个函数,接收 RDD 的元素作为输入,对它进行处理。
3. 特点
-
没有返回值
-
foreach的返回值是None,所以你不能像map那样拿到新 RDD。 -
它是一个 Action 算子,会触发真正的执行。
-
-
副作用在 Executor 端发生
-
函数
f会在集群各个节点(Executor)上执行,而不是在 driver 上。 -
所以你在
f里print,日志会打印到 Executor 的日志里,而不是 driver 的控制台。 -
如果你要在 driver 上调试看数据,可以用
collect()。
-
-
常用场景
-
写数据库:
foreach(lambda x: save_to_mysql(x)) -
写文件系统:
foreach(lambda x: write_to_hdfs(x)) -
更新外部存储:
foreach(lambda x: redis_client.set(x[0], x[1]))
-
4. 示例
from pyspark import SparkContextsc = SparkContext("local", "ForeachExample")data = sc.parallelize([1, 2, 3, 4, 5])def process(x):print(f"处理元素: {x}")# foreach 对每个元素执行 process
data.foreach(process)
⚠️ 注意:
-
在本地模式(local)下,你可能能在控制台看到输出。
-
在集群模式(YARN、Standalone、Mesos),打印信息会在 Executor 日志,driver 控制台一般看不到。
5. foreach 和 foreachPartition 的区别
-
foreach(f)
→ 每个元素都执行一次f。 -
foreachPartition(f)
→ 每个 分区 执行一次f,f的输入是该分区的迭代器。
一般写数据库、写外部存储时推荐 foreachPartition,这样可以:
-
避免频繁建立连接(每个分区建立一次连接,而不是每条记录都建立)。
-
提高性能。
6. 对比 map
| 算子 | 是否返回新 RDD | 是否触发 Action | 典型用途 |
|---|---|---|---|
map | ✅ 是 | ❌ 否 | 数据转换 |
foreach | ❌ 否 | ✅ 是 | 副作用操作(写库/打印/发送消息) |
1-12、saveAsTextFile算子
1. 基本功能
saveAsTextFile(path) 是 Action算子(触发计算的算子),用于将 RDD 的内容 保存到 HDFS、本地文件系统或其他兼容 Hadoop 的文件系统中,存储格式是 文本文件。
-
每个元素会被转换为一行字符串(调用
str()方法) -
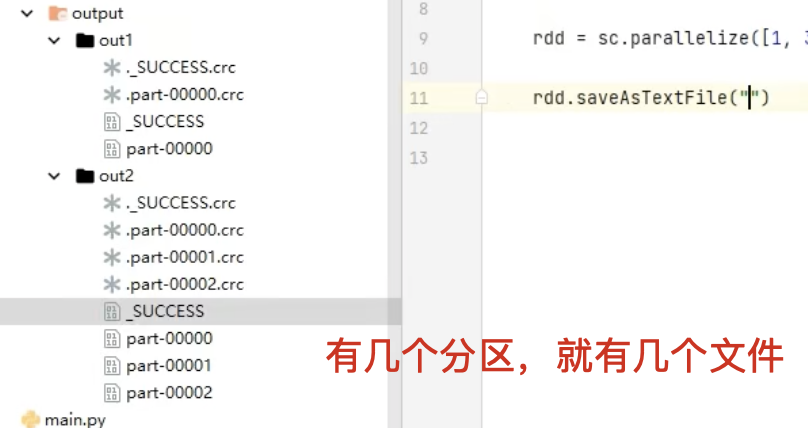
最终生成的结果是 一个目录,而不是单个文件
-
目录中包含多个分区文件(如
part-00000、part-00001…),每个文件对应 RDD 的一个分区
2. 使用方法
# 假设已有一个RDD
rdd = sc.parallelize([1, 2, 3, 4, 5], numSlices=2)# 保存为文本文件
rdd.saveAsTextFile("output_rdd")
结果目录结构
output_rdd/├── part-00000├── part-00001└── _SUCCESS
-
part-00000、part-00001:存储 RDD 每个分区的数据 -
_SUCCESS:一个空文件,表示任务成功结束
3. 关键注意事项
-
路径必须不存在
Spark 默认不允许写入已存在的目录,否则会报错:org.apache.hadoop.mapred.FileAlreadyExistsException解决办法:先删除旧目录,再保存。
import shutil shutil.rmtree("output_rdd", ignore_errors=True) rdd.saveAsTextFile("output_rdd") -
输出是多个文件
如果需要单个文件,可以在保存前 合并分区:rdd.coalesce(1).saveAsTextFile("output_single_file")输出目录下只会有一个
part-00000。
coalesce(1)会把 RDD 的所有数据压缩到 一个分区。“创建一个新的目标分区,然后把数据往里压”。- 保存时 Spark 会根据分区数写出文件,因此只会生成 一个
part-00000文件。
如果是要交付给外部系统(比如 CSV 文件要交给别人用),那通常会
coalesce(1)
3. 数据类型要求
示例:
kv_rdd = sc.parallelize([("a", 1), ("b", 2)], 2)
kv_rdd.saveAsTextFile("output_kv")
# 文件内容大概是:
# ('a', 1) part-00000
# ('b', 2) part-00001
-
saveAsTextFile默认调用str()转换元素 -
如果是
(key, value)形式的 RDD,输出会是(key, value)的字符串
4. 典型应用场景
-
保存日志处理结果到 HDFS
-
将 RDD 转换为文本存储,供下游任务(Hive、Spark SQL)使用
-
与
saveAsSequenceFile、saveAsObjectFile对比,用于不同场景的持久化存储
【小结】:
- foreach
- saveAsTestFile
这两个算子是分区(Excutor)直接执行的,跳过Driver,由所在的分区(Excutor)直接执行,性能比较好!
其余的Action算子都会将结果发送至Driver