畅游Diffusion数字人(28):InstantID原班人马提出个性化人物定制InstantCharacter
畅游Diffusion数字人(0):专栏文章导航
前言:InstantX实验室又推出大作啦,这次是InstantID的原作者联合腾讯混元提出了个性化人物定制的论文《InstantCharacter:Personalize Any Characters with a Scalable Diffusion Transformer Framework》。这个任务比ID保持难度大,更具有挑战性。这篇博客详细解读一下InstantCharacter的原理。
目录
贡献概述
动机
方法详解
1、可拓展的Adapter
2、三阶段微调策略
贡献概述

动机
1、当前基于学习的主体定制方法主要依赖于 U-Net 架构,泛化能力有限,图像质量受到影响。
2、基于优化的方法需要针对特定主题的微调,这不可避免地会降低文本的可控性。
为了应对这些挑战,我们提出了 InstantCharacter,这是一个基于基础扩散转换器构建的角色自定义可扩展框架。InstantCharacter 展示了三个基本优势:首先,它实现了跨不同角色外观、姿势和样式的开放域个性化,同时保持了高保真结果。其次,该框架引入了一个带有堆叠变压器编码器的可扩展适配器,它可以有效地处理开放域字符特征,并与现代扩散变压器的潜在空间无缝交互。第三,为了有效地训练框架,我们构建了一个包含 1000 万个关卡样本的大规模字符数据集。数据集系统地组织为成对(多视图字符)和非成对(文本-图像组合)子集。这种双数据结构可以通过不同的学习路径同时优化身份一致性和文本可编辑性。
方法详解
首先,开发了一个可扩展的适配器模块,以有效解析字符特征并与 DiTs 潜在空间无缝交互。其次,设计了一个渐进的三阶段训练策略来适应我们收集的多功能数据集,从而实现字符一致性和文本可编辑性的单独训练。通过协同结合灵活的适配器设计和分阶段学习策略,我们增强了通用角色定制能力,同时最大限度地保留了基本 DiT 模型的生成先验。
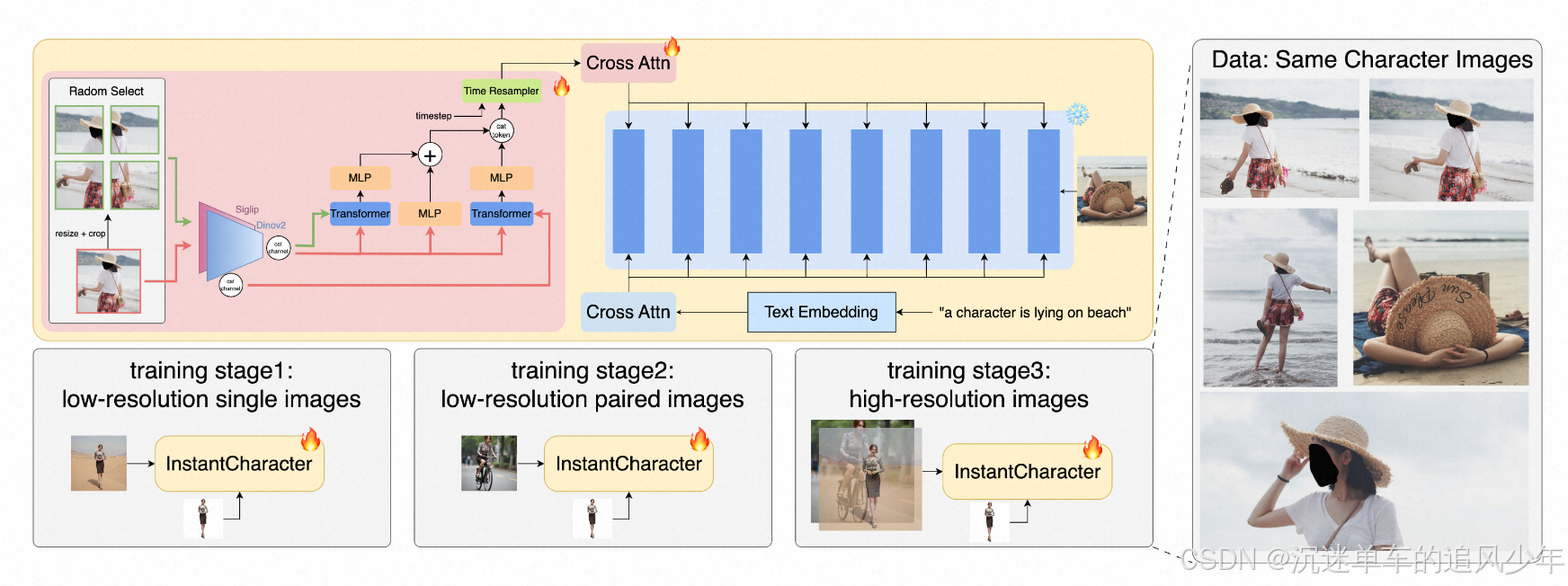
1、可拓展的Adapter
-
替换之前的CLIP编码器。以前的方法通常依赖于 CLIP来实现其对齐的视觉和文本特征。然而,虽然 CLIP 能够捕获抽象语义信息,但它往往会丢失详细的纹理信息,这对于保持字符一致性至关重要。为此,我们用 SigLIP替换了 CLIP,它擅长捕获更细粒度的字符信息。此外,我们引入了 DINOv2作为另一种图像编码器,以增强特征的鲁棒性,减少由背景或其他干扰因素引起的特征损失。最后,我们通过通道级连接集成了 DINOv2 和 SigLIP 特征,从而更全面地表示开放域字符。
-
中间编码器。由于 SigLIP 和 DINOv2 是以相对较低的分辨率 384 进行预训练和推理的,因此在处理高分辨率字符图像时,通用视觉编码器的原始输出可能会丢失细粒度特征。为了缓解这个问题,我们采用双流特征融合策略来分别探索低级和区域级特征。首先,我们直接从通用视觉编码器的浅层中提取低级特征,捕获在较高层中经常丢失的细节。其次,我们将参考图像分成多个不重叠的补丁,并将每个补丁馈送到视觉编码器中,以获得区域级特征。然后,这两个不同的特征流通过专用的中间变压器编码器进行分层集成。具体来说,每个特征路径都由单独的 transformer 编码器独立处理,以与高级语义特征集成。随后,来自两条途径的精细特征嵌入沿标记维度连接,建立捕获多级互补信息的全面融合表示。
-
投影头。最后,通过投影头将精致的角色特征投射到降噪空间中,并与潜在的噪声相互作用。我们通过一个时间步长感知的 Q-former 来实现这一点,该转换器将中间编码器输出作为键值对处理,同时通过注意力机制动态更新一组可学习的查询。然后,转换后的查询特征通过可学习的交叉注意力层注入降噪空间。最后,该适配器能够忠实地保留身份并灵活适应复杂的文本驱动修改。
2、三阶段微调策略
训练过程采用三阶段渐进策略,从未配对的低分辨率预训练开始,到成对的高分辨率微调结束。