开源日志log4cplus—调用MultiByteToWideChar提示未定义,CP_UTF8未定义定原因有哪些,如何改进?
文章目录
- ⚠️ 根本原因分析
- 1. 缺失 Windows API 头文件
- 2. 未链接 Kernel32.lib 库
- 3. 字符集配置冲突
- 4. Windows SDK 版本过低
- 5. 作用域或拼写错误
- 6. CP_UTF8报错未定义被被log4cplus截断了
- 🛠️ 改进方案与代码示例
- ✅ 1. 包含正确的头文件并链接库
- ✅ 2. 统一字符集配置
- ✅ 3. 使用 log4cplus 内置转换宏(推荐替代方案)
- ✅ 4. 手动转换的安全实现示例
- ⚠️ 注意事项
- 💎 总结建议
在 log4cplus 中使用
MultiByteToWideChar 和
CP_UTF8 时出现“未定义标识符”错误,通常由以下原因导致。以下是详细分析和改进方案:
⚠️ 根本原因分析
1. 缺失 Windows API 头文件
MultiByteToWideChar和CP_UTF8是 Windows API 的组成部分,声明在<windows.h>或更细分的头文件中(如<winnls.h>或<stringapiset.h>)。- 未包含头文件:若代码中未包含这些头文件,编译器无法识别符号。
- 兼容性差异:
- Windows 7 及更早版本:需包含
<winnls.h>。 - Windows 8+ 版本:推荐包含
<stringapiset.h>。
- Windows 7 及更早版本:需包含
2. 未链接 Kernel32.lib 库
- Windows API 函数需链接
kernel32.lib,否则会提示未定义符号。
3. 字符集配置冲突
- 若项目设置为 “使用多字节字符集”(而非 Unicode),
CP_UTF8可能未被正确定义。 - log4cplus 的
tstring类型依赖UNICODE宏:若未启用 Unicode,tstring实际为std::string,此时无需宽字符转换。
4. Windows SDK 版本过低
- 旧版 Windows SDK(如针对 XP 开发)可能未完整定义
CP_UTF8(值为65001)。
5. 作用域或拼写错误
- 误写为
MultiByteToWideChar(正确) vsMultibyteToWideChar(错误)。 - 在未包含头文件的
.cpp文件中直接使用。
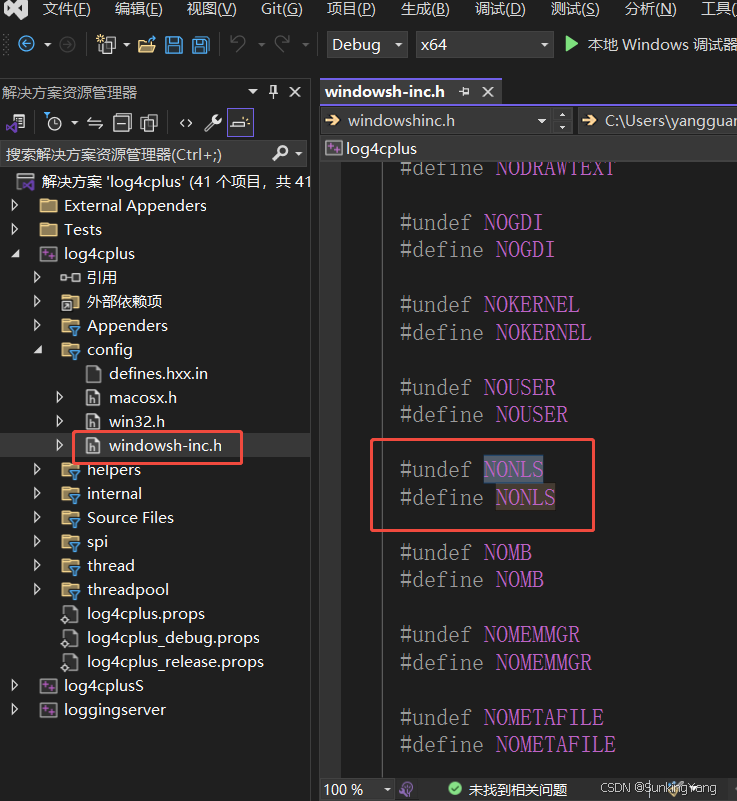
6. CP_UTF8报错未定义被被log4cplus截断了
如图,CP_UTF8被宏定义在WinNis.h文件里,但前提是未定义NONLS。
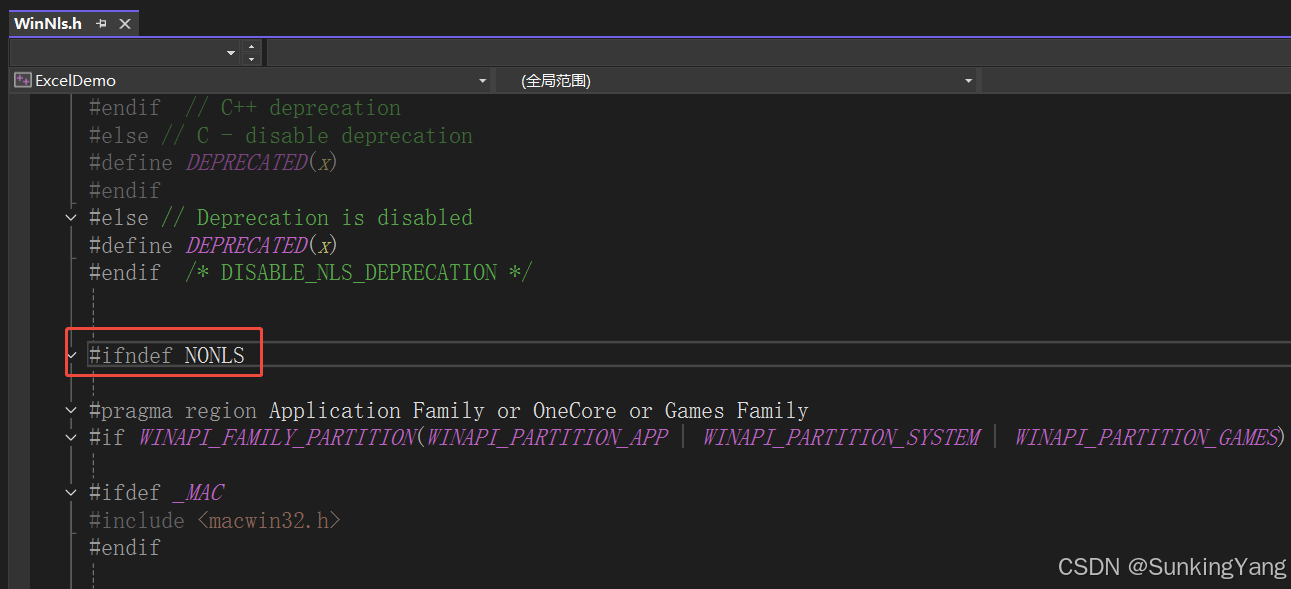
但在log4cplus里,重新在wundowsh-inc.h里将这个宏定义了,所以后续无法再使用。
🛠️ 改进方案与代码示例
✅ 1. 包含正确的头文件并链接库
// 在调用转换的源文件中添加
#include <Windows.h> // 或根据版本选择:
#if WINVER >= 0x0602 // Windows 8+#include <stringapiset.h>
#else#include <winnls.h>
#endif// 链接 kernel32.lib(在项目属性中添加)
#pragma comment(lib, "kernel32.lib")
✅ 2. 统一字符集配置
- Visual Studio 设置:
项目属性 → 高级 → 字符集 → 选择 “使用 Unicode 字符集”(自动定义UNICODE和_UNICODE)。 - 手动定义宏(若需兼容旧项目):
#define UNICODE #define _UNICODE
✅ 3. 使用 log4cplus 内置转换宏(推荐替代方案)
log4cplus 提供 LOG4CPLUS_STRING_TO_TSTRING 宏,自动处理编码转换,避免直接调用 Windows API:
#include <log4cplus/helpers/stringhelper.h> // 必需头文件std::string utf8Str = "日志内容";
log4cplus::tstring tStr = LOG4CPLUS_STRING_TO_TSTRING(utf8Str);
✅ 4. 手动转换的安全实现示例
若需自定义转换逻辑,需严格处理缓冲区与编码:
#include <Windows.h>log4cplus::tstring ConvertToTString(const std::string& str) {
#ifdef UNICODE// 计算所需缓冲区大小int wlen = MultiByteToWideChar(CP_UTF8, 0, str.c_str(), -1, nullptr, 0);if (wlen == 0) return L""; // 错误处理// 分配缓冲区并转换std::wstring wstr(wlen, 0);MultiByteToWideChar(CP_UTF8, 0, str.c_str(), -1, &wstr[0], wlen);return wstr;
#elsereturn str; // 多字节模式无需转换
#endif
}
⚠️ 注意事项
-
编码一致性
- 输入
std::string必须为 UTF-8 编码,否则转换后乱码。 - 多字节模式下,确保字符串与系统本地编码(如 GBK)匹配。
- 输入
-
跨平台兼容性
- Windows 专属 API 不可跨平台。Linux/macOS 项目需改用
iconv或 C++11<codecvt>(C++17 后弃用)。
- Windows 专属 API 不可跨平台。Linux/macOS 项目需改用
-
预防性检查
- 调用
MultiByteToWideChar后检查返回值:if (result == 0) {DWORD err = GetLastError();// 处理错误(如非法字符、缓冲区不足) }
- 调用
💎 总结建议
| 场景 | 推荐方案 | 优势 |
|---|---|---|
| 简化 log4cplus 日志记录 | 使用 LOG4CPLUS_STRING_TO_TSTRING 宏 | 自动适配编码,无需手动处理 API |
| 需精细控制转换逻辑 | 手动调用 MultiByteToWideChar + 条件编译 | 精确控制缓冲区与错误处理 |
| 修复未定义错误 | 包含 <Windows.h> + 链接 kernel32.lib | 解决 API 符号缺失问题 |
| 多字节项目(无 Unicode) | 直接传递 std::string 给 log4cplus | 零开销 |
优先使用 log4cplus 内置宏,避免直接调用平台相关 API。若仍需调用 Windows 函数,务必包含头文件、链接库,并验证字符集配置。
上一篇:开源日志源码——log4cplus 日志文件未生成得原因一般有哪些?
后面的属于水文,没有任何参考意义。
不要看
不要看
不要看
重要的事情说三遍!!!
让大家先笑一会!!!!

关于log4cplus中调用MultiByteToWideChar和CP_UTF8时出现未定义错误的原因和解决方案。这是一个技术性很强的问题,涉及到C++编程、Windows API和日志库log4cplus的使用。
从用户的问题历史来看,用户最近在开发一个使用log4cplus的项目,并且遇到了字符编码转换的问题。用户已经尝试过使用MultiByteToWideChar和CP_UTF8,但遇到了未定义的错误。这表明用户的开发环境可能存在配置问题或者头文件缺失。
用户可能是在Windows平台上开发,因为MultiByteToWideChar是Windows特有的API。用户可能正在尝试在log4cplus中记录包含非ASCII字符(如中文)的日志信息,这需要使用宽字符(wchar_t)或Unicode编码来处理。
我看到了很多搜索结果,其中
详细介绍了MultiByteToWideChar函数的用法和参数说明。
则讨论了字符编码转换的常见问题和解决方案。
提到了Windows从2000开始使用Unicode开发,如果传递ANSI字符串,系统会先将其转换为Unicode。
对于用户的问题,未定义错误可能由几个原因造成:缺少必要的头文件(如windows.h或winnls.h),项目未正确链接kernel32.lib库,字符集设置不匹配,或者log4cplus的编译选项问题。
为了帮助用户解决这个问题,我需要提供详细的解决方案:包含正确的头文件,链接必要的库,设置字符集选项,使用条件编译处理不同Windows版本,以及使用log4cplus内置的字符串转换宏作为替代方案。
我还考虑设计一个清晰的回答结构,使用标题和分段来组织内容。准备在原因分析部分使用图标增加可读性,在解决方案部分提供具体的代码示例,包括头文件包含、链接库设置、字符集配置等。最后会给出一个完整的代码示例,展示如何正确地在log4cplus中使用MultiByteToWideChar和CP_UTF8。
在回答时,会在关键点加粗,使用代码块展示具体实现,并提供预防性建议以避免未来出现类似问题。这样可以帮助用户彻底解决当前的编译错误,并理解背后的原理。