如何通过API接口实现批量获取淘宝商品数据?(官方与非官方渠道分享)
获取淘宝商品数据需要通过API接口实现,主要是淘宝开放平台(Taobao Open Platform)和非官方的爬虫方式或者第三方数据公司。以下是通过官方 API 批量获取淘宝商品数据的步骤和说明:
官方API流程
一、前期准备
注册淘宝开放平台账号
访问 淘宝开放平台,注册开发者账号并完成实名认证。创建应用
在开放平台控制台创建应用,获取App Key和App Secret(用于 API 调用的身份验证)。注意应用需要通过审核才能使用部分高级接口。了解权限与接口
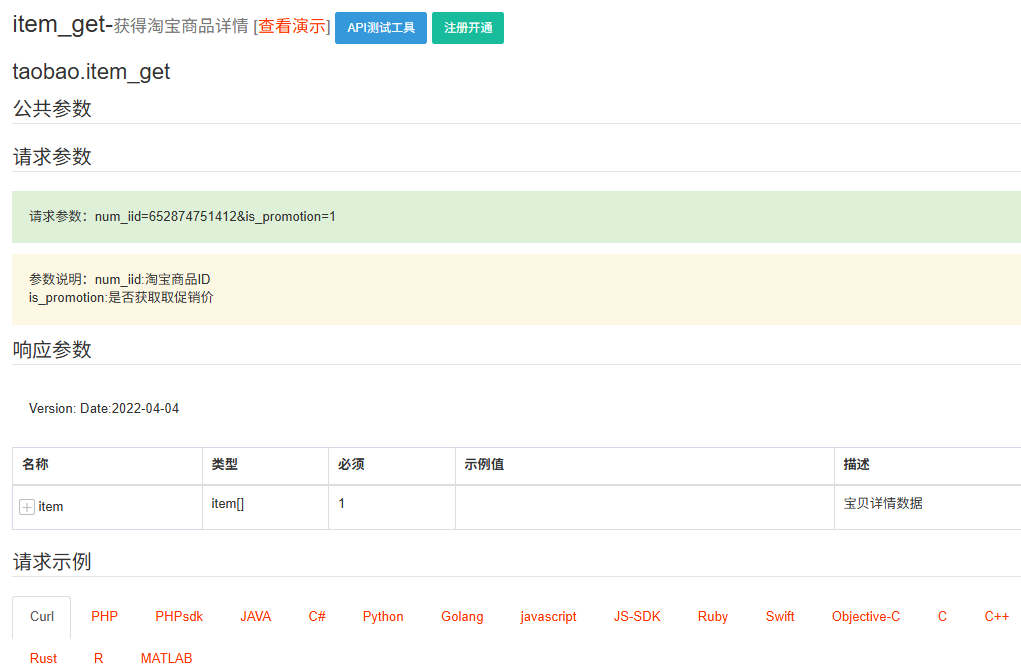
淘宝开放平台提供了多种商品相关 API,常用的批量获取商品数据的接口包括:taobao.items.search:搜索商品(需申请对应权限)taobao.product.get:获取商品详情taobao.item.seller.get:获取卖家商品列表
具体接口文档可查阅淘宝开放平台 API 文档中心。
二、API 调用流程
获取访问令牌(Access Token)
大部分 API 需要通过App Key和App Secret获取临时访问令牌(Token),用于后续接口调用。构造 API 请求
调用 API 时需按照规范拼接请求参数,包括:- 公共参数(如
app_key、method、timestamp、sign等,用于身份验证和请求合法性校验) - 业务参数(如搜索关键词、页码、每页数量等,根据具体接口定义)
- 公共参数(如
处理响应数据
API 返回的数据格式通常为 JSON 或 XML,需解析后提取所需的商品信息(如标题、价格、销量、图片等)。
三、示例代码(Python)
以下是使用 taobao.items.search 接口批量获取商品数据的简单示例(需替换为自己的 App Key、App Secret 和 Token):
import requests
import time
import hashlib
import json# 配置信息(替换为自己的)
APP_KEY = "你的App Key"
APP_SECRET = "你的App Secret"
ACCESS_TOKEN = "你的Access Token"
API_URL = "http://gw.api.taobao.com/router/rest"def get_taobao_products(keyword, page=1, page_size=20):"""调用淘宝API搜索商品:param keyword: 搜索关键词:param page: 页码:param page_size: 每页数量(最大通常为100):return: 商品数据列表"""# 公共参数params = {"app_key": APP_KEY,"method": "taobao.items.search","format": "json","v": "2.0","sign_method": "md5","timestamp": time.strftime("%Y-%m-%d %H:%M:%S"),"access_token": ACCESS_TOKEN,# 业务参数"q": keyword, # 搜索关键词"page_no": page,"page_size": page_size,# 可添加其他筛选条件,如价格区间、销量等# "start_price": 10,# "end_price": 100,}# 生成签名(淘宝API要求的签名算法)sorted_params = sorted(params.items(), key=lambda x: x[0])sign_str = APP_SECRET + "".join([f"{k}{v}" for k, v in sorted_params]) + APP_SECRETparams["sign"] = hashlib.md5(sign_str.encode()).hexdigest().upper()# 发送请求response = requests.get(API_URL, params=params)result = json.loads(response.text)# 解析结果if "error_response" in result:print(f"错误:{result['error_response']['msg']}")return []return result.get("items_search_response", {}).get("items", {}).get("item", [])# 批量获取数据(分页示例)
if __name__ == "__main__":keyword = "手机"total_pages = 5 # 需获取的总页数all_products = []for page in range(1, total_pages + 1):print(f"获取第{page}页数据...")products = get_taobao_products(keyword, page=page)if not products:break # 无数据时停止all_products.extend(products)time.sleep(1) # 控制调用频率,避免触发限流print(f"共获取{len(all_products)}条商品数据")# 处理数据(如保存到数据库或文件)for item in all_products[:5]: # 打印前5条示例print(f"标题:{item.get('title')},价格:{item.get('price')},销量:{item.get('sale')}")
爬虫实现
- 目标分析:确定需爬取的商品字段(标题、价格等)及目标页面(搜索页 / 列表页)。
- 环境准备:用 Python+Requests/Scrapy 发送请求,Selenium 处理动态渲染,Fiddler 抓包分析接口。
- 反爬应对:添加随机 User-Agent、IP 代理,模拟真实浏览间隔,破解 cookie 或登录态验证。
- 数据提取:用 XPath/CSS 选择器解析静态页面,或直接解析 API 返回的 JSON 数据。
- 批量爬取:分页循环请求,用队列管理 URL,异常重试确保稳定性。
- 数据存储:将提取的信息保存到 CSV / 数据库,去重清洗后使用
第三方数据公司API对接
第三方数据公司接入 API 批量获取淘宝商品数据的流程如下:
资质对接
与淘宝开放平台或其授权的服务商签订合作协议,获取企业级 API 接入资质,明确数据使用范围和权限。技术对接准备
申请专属的 App Key、App Secret,完成接口权限开通(如商品搜索、详情查询等高级接口),获取接口调用规范文档。
开发集成
- 按文档实现签名算法、Token 管理(自动续期)等认证逻辑
- 封装 API 调用模块,支持批量请求(如分页查询、多关键词并发)
- 处理接口限流(按配额控制 QPS)、错误重试和数据解析
数据处理与服务
- 建立数据缓存 / 存储系统(如数据库 + 缓存层)
- 对原始数据清洗、去重、结构化处理
- 封装成标准化数据接口或 SDK,提供给下游客户使用
运维与合规
监控接口调用状态、配额使用情况,定期同步淘宝 API 更新,确保数据获取合规性(符合平台协议及隐私法规)。
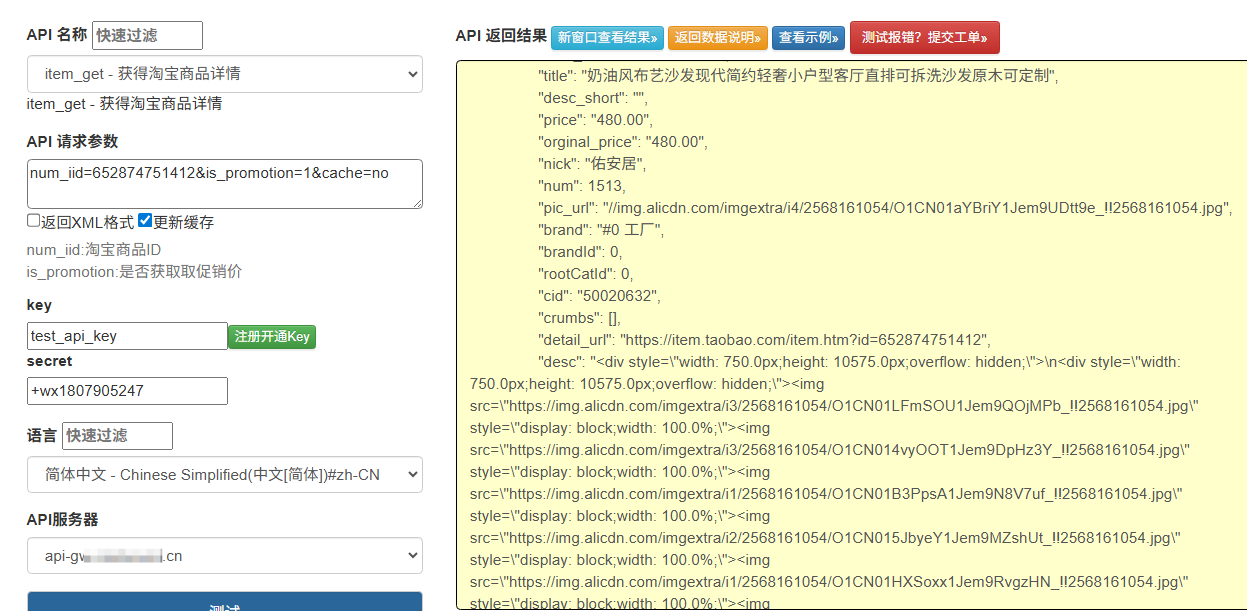
api免费测试页
该模式依托官方合规渠道,稳定性和合法性远高于爬虫,适合规模化数据服务。