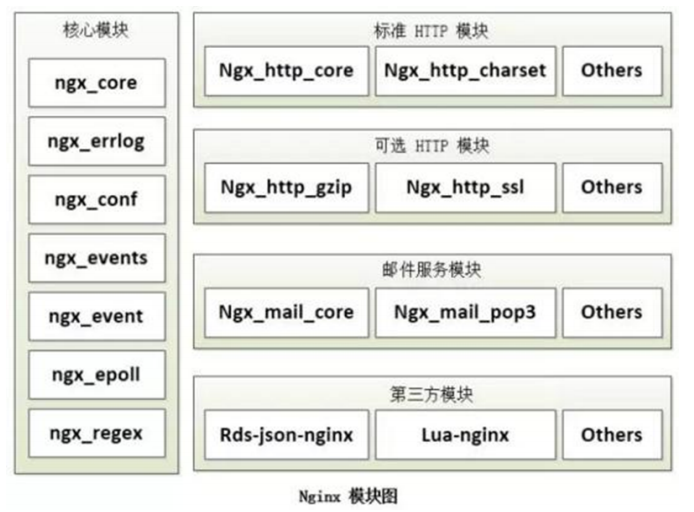
nginx高性能web服务器
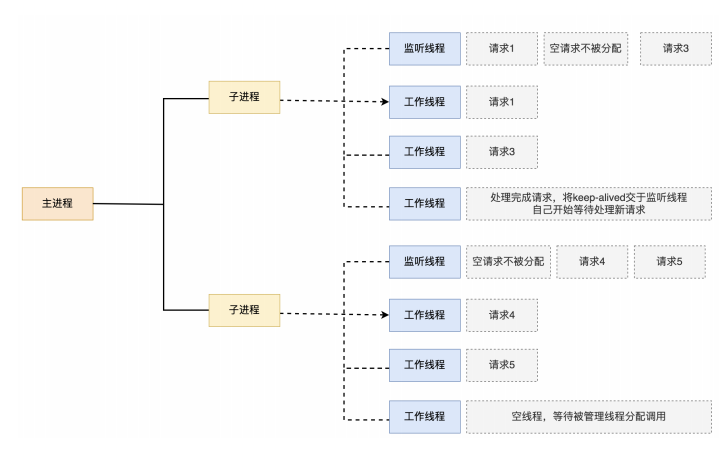

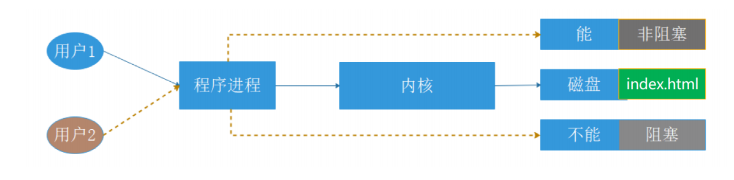
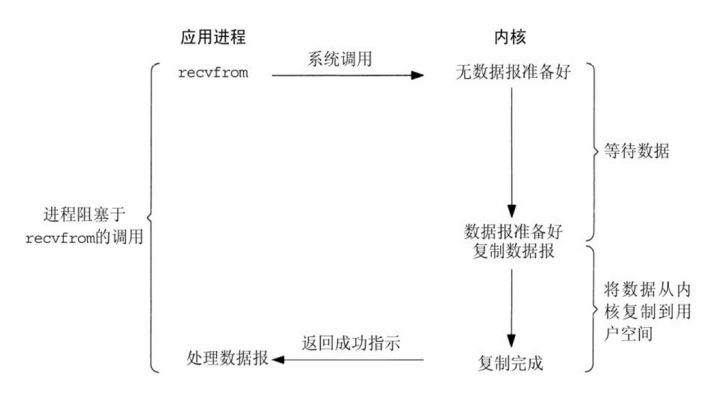
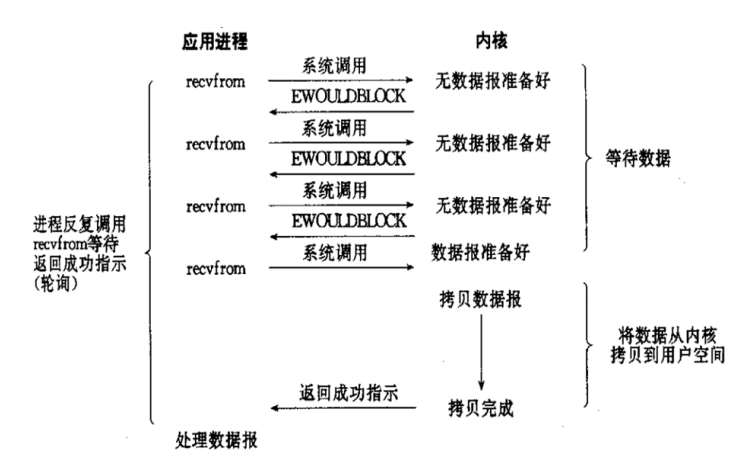
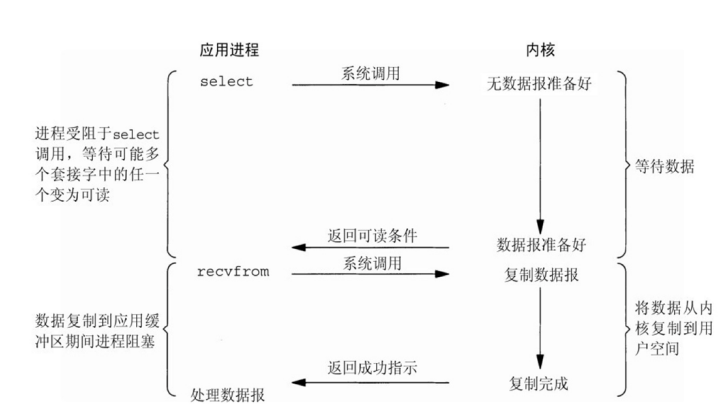
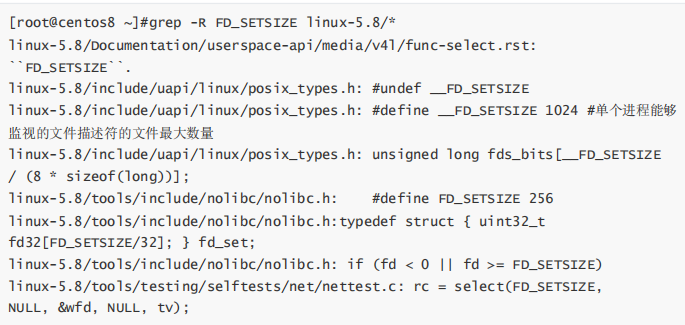
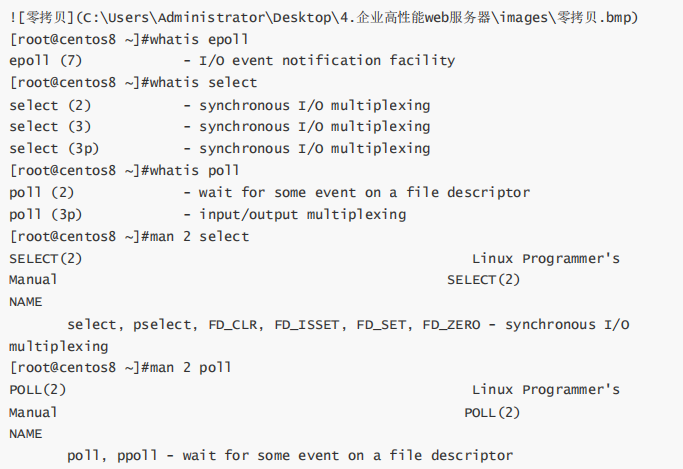
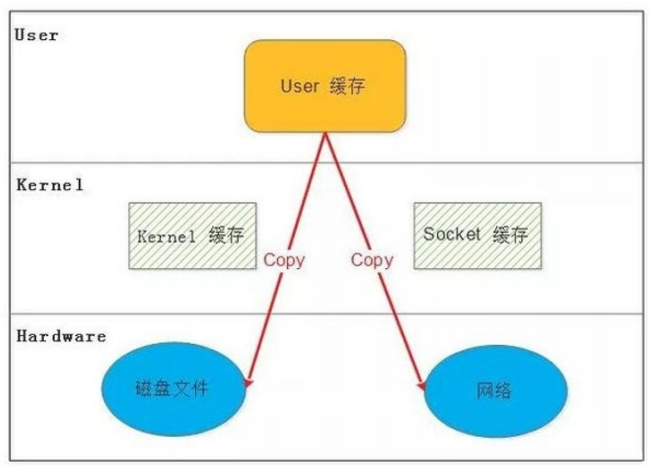
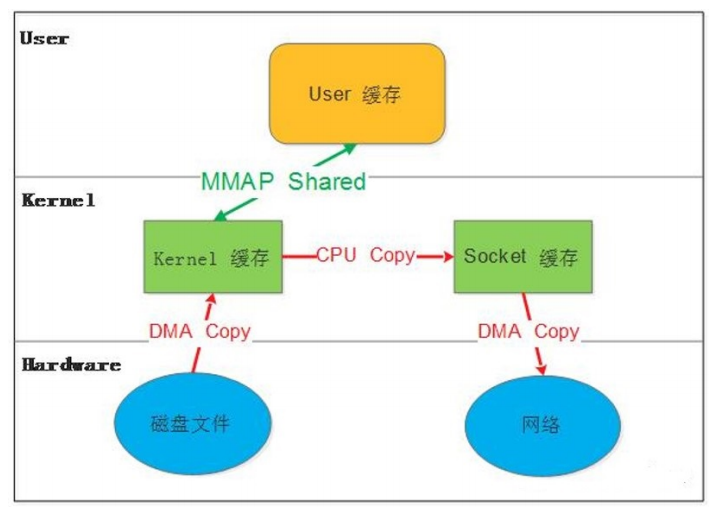
编译安装示例:
#!/bin/bash# 安装依赖
dnf install gcc pcre-devel zlib-devel openssl-devel -y# 创建 Nginx 用户
useradd -s /sbin/nologin -M nginx# 解压 Nginx 源码包
tar zxf nginx-1.24.0.tar.gz
cd nginx-1.24.0/# 配置编译选项
./configure --prefix=/usr/local/nginx \
--user=nginx \
--group=nginx \
--with-http_ssl_module \
--with-http_v2_module \
--with-http_realip_module \
--with-http_stub_status_module \
--with-http_gzip_static_module \
--with-pcre \
--with-stream \
--with-stream_ssl_module \
--with-stream_realip_module# 编译并安装
make && make install# 创建软链接使命令全局可用
ln -s /usr/local/nginx/sbin/nginx /usr/sbin/nginx# 验证安装
nginx -v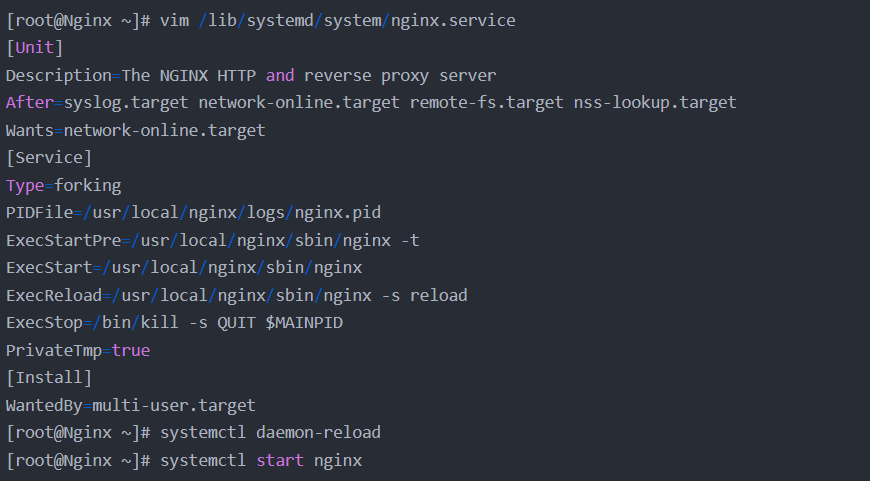
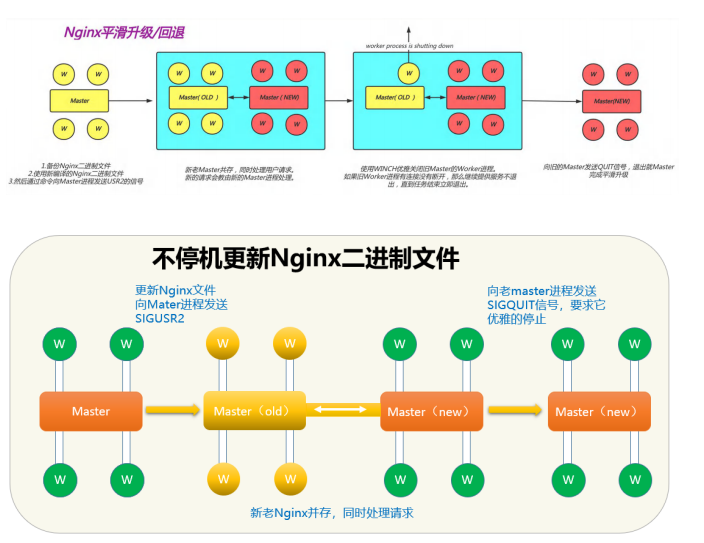
[root@Nginx nginx]# tar zxf nginx-1.26.1.tar.gz
[root@Nginx nginx]# cd nginx-1.26.1/# 编译新版本
[root@Nginx nginx-1.26.1]# ./configure --with-http_ssl_module --with-http_v2_module \
--with-http_realip_module --with-http_stub_status_module --with-http_gzip_static_module \
--with-pcre --with-stream --with-stream_ssl_module --with-stream_realip_module# 仅执行make,无需make install
[root@Nginx nginx-1.26.1]# make# 对比新旧版本
[root@Nginx nginx-1.26.1]# ll objs/nginx /usr/local/nginx/sbin/nginx
-rwxr-xr-x 1 root root 1239416 Jul 18 15:08 objs/nginx
-rwxr-xr-x 1 root root 5671488 Jul 18 11:41 /usr/local/nginx/sbin/nginx# 备份旧版nginx
[root@Nginx ~]# cd /usr/local/nginx/sbin/
[root@Nginx sbin]# cp nginx nginx.24# 替换为新版本
[root@Nginx sbin]# \cp -f /root/nginx/nginx-1.26.1/objs/nginx /usr/local/nginx/sbin# 配置检测
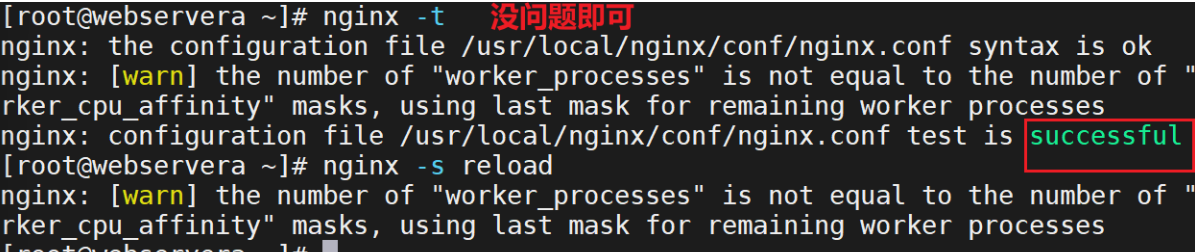
[root@Nginx sbin]# nginx -t
nginx: the configuration file /usr/local/nginx/conf/nginx.conf syntax is ok
nginx: configuration file /usr/local/nginx/conf/nginx.conf test is successful# 平滑升级
[root@Nginx sbin]# kill -USR2 48732 # nginx worker ID# 查看进程状态
[root@Nginx sbin]# ps aux | grep nginx
root 48732 0.0 0.1 9868 2436 ? Ss 14:17 0:00 nginx: master process /usr/local/nginx/sbin/nginx
nobody 48733 0.0 0.2 14200 4868 ? S 14:17 0:00 nginx: worker process
root 52075 0.0 0.3 9876 6528 ? S 15:41 0:00 nginx: master process /usr/local/nginx/sbin/nginx
nobody 52076 0.0 0.2 14208 4868 ? S 15:41 0:00 nginx: worker process# 验证版本
[root@Nginx sbin]# curl -I localhost
HTTP/1.1 200 OK
Server: nginx/1.24.0 # 旧版本仍在运行
...# 回收旧版本
[root@Nginx sbin]# kill -WINCH 48732# 再次验证
[root@Nginx sbin]# curl -I localhost
HTTP/1.1 200 OK
Server: nginx/1.26.1 # 新版本已生效
...# 版本回滚操作
[root@Nginx sbin]# cp nginx nginx.26
[root@Nginx sbin]# mv nginx.24 nginx
[root@Nginx sbin]# kill -HUP 48732
[root@Nginx sbin]# kill -WINCH 52075# 最终验证
[root@Nginx sbin]# curl -I localhost
HTTP/1.1 200 OK
Server: nginx/1.24.0 # 回滚完成
...





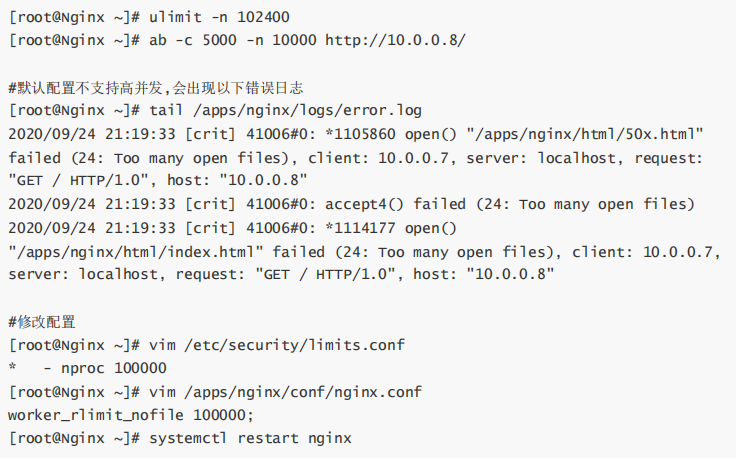
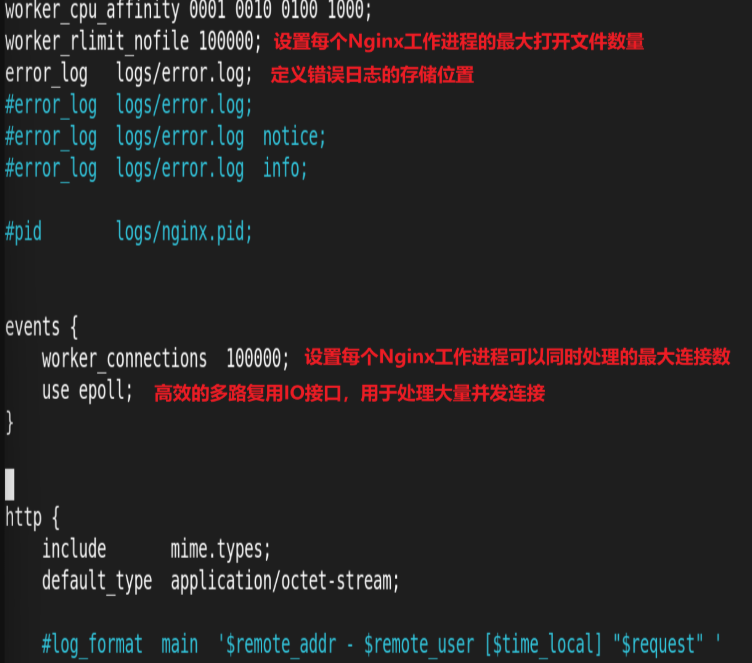

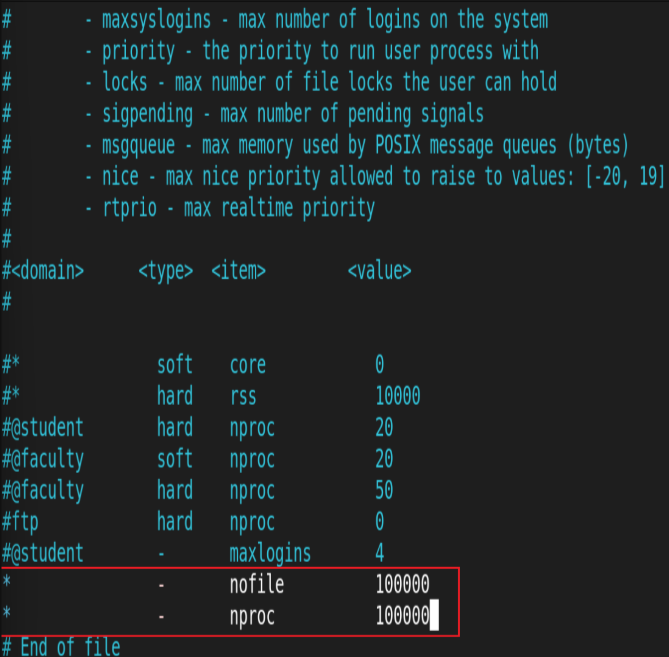


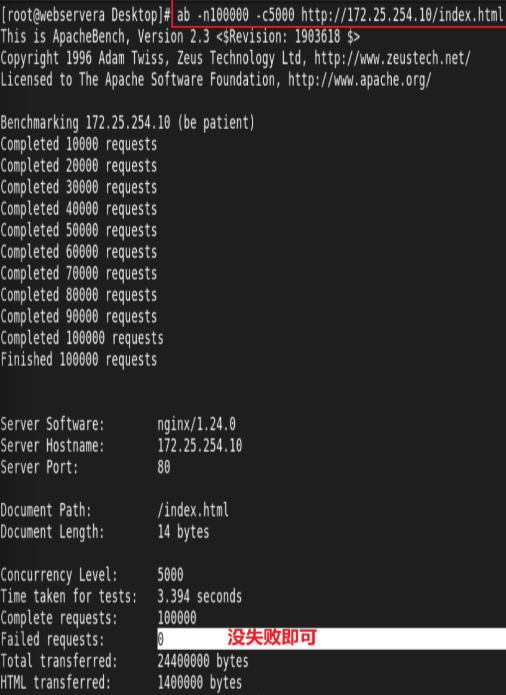
测试:
-n:请求总量
-c:并发量
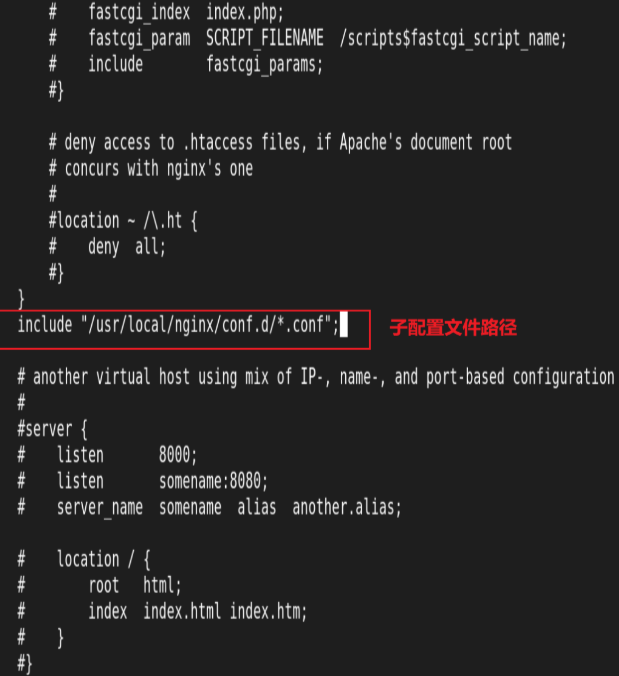
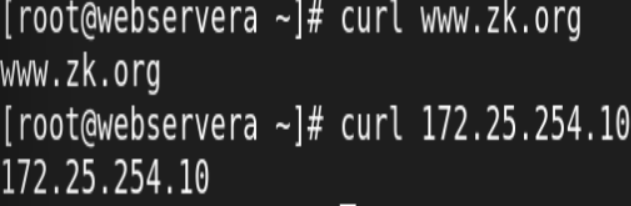
4.建立nginx站点:
![]()

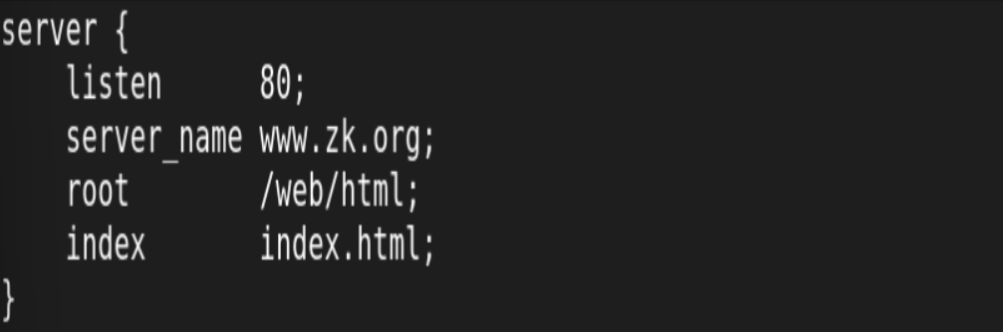


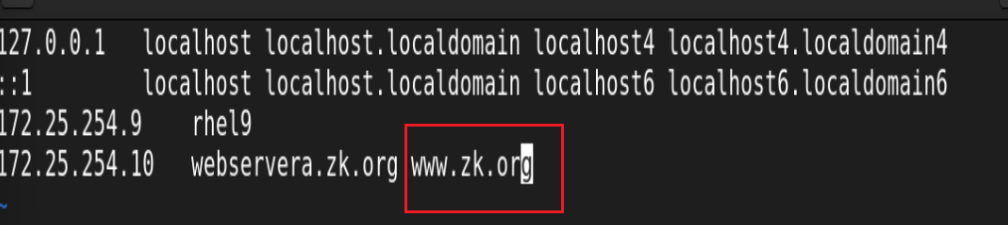
![]()
5.root 与 alias
root:指定web的家目录,在定义location的时候,文件的绝对路径等于 root+location
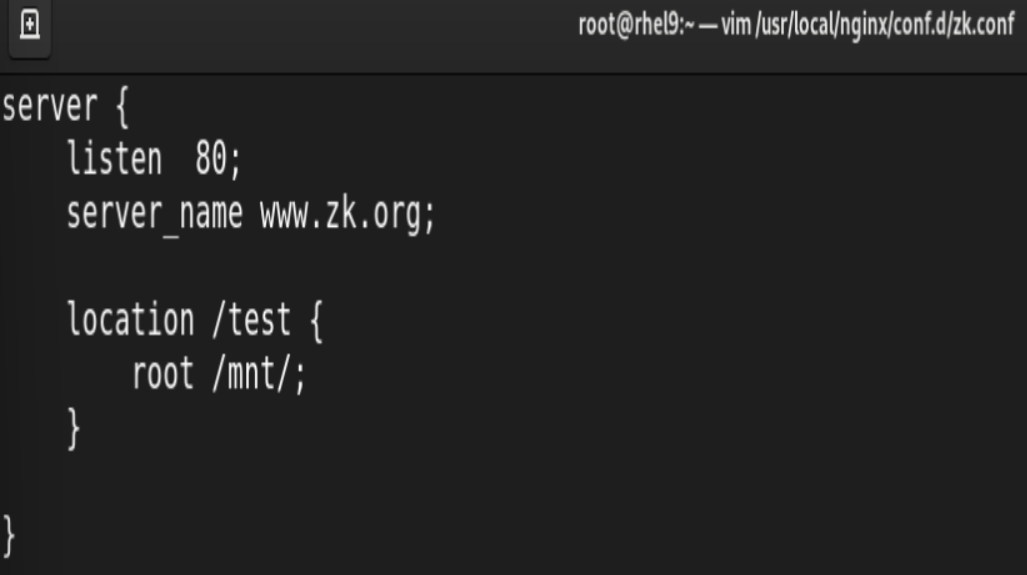

![]()
alias:定义路径别名,会把访问的路径重新定义到其指定的路径,文档映射的另一种机制;仅能用于 location上下文,此指令使用较少
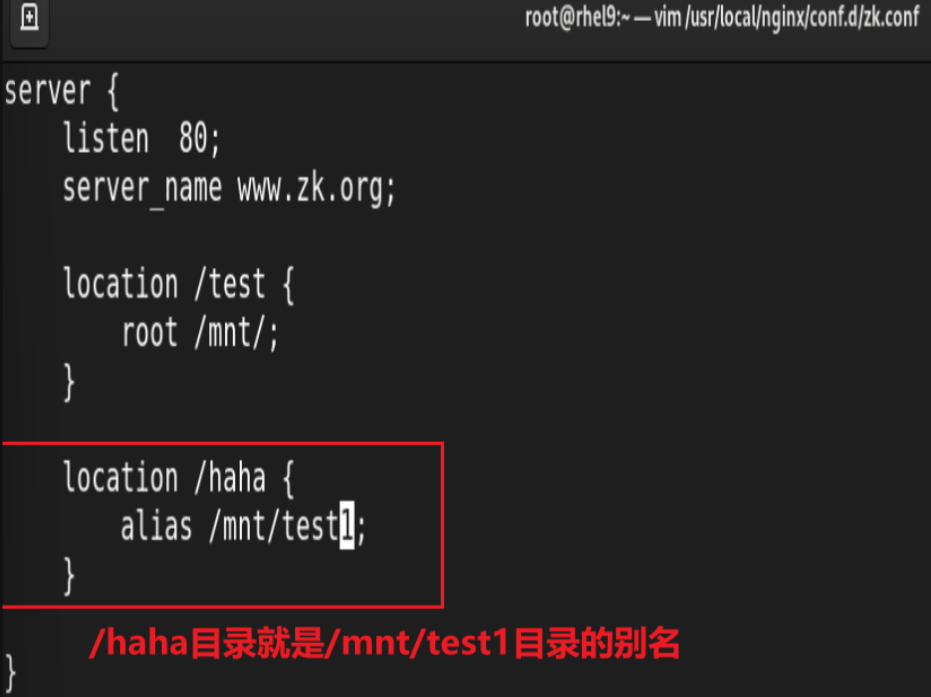
![]()


6.location 的详细使用
在一个server中location配置段可存在多个,用于实现从uri到文件系统的路径映射
ngnix会根据用户请求的URI来检查定义的所有location,按一定的优先级找出一个最佳匹配
而后应用其配置在没有使用正则表达式的时候,nginx会先在server中的多个location选取匹配度最高的一个uri
uri是用户请求的字符串,即域名后面的web文件路径
然后使用该location模块中的正则url和字符串,如果匹配成功就结束搜索,并使用此location处理此请求
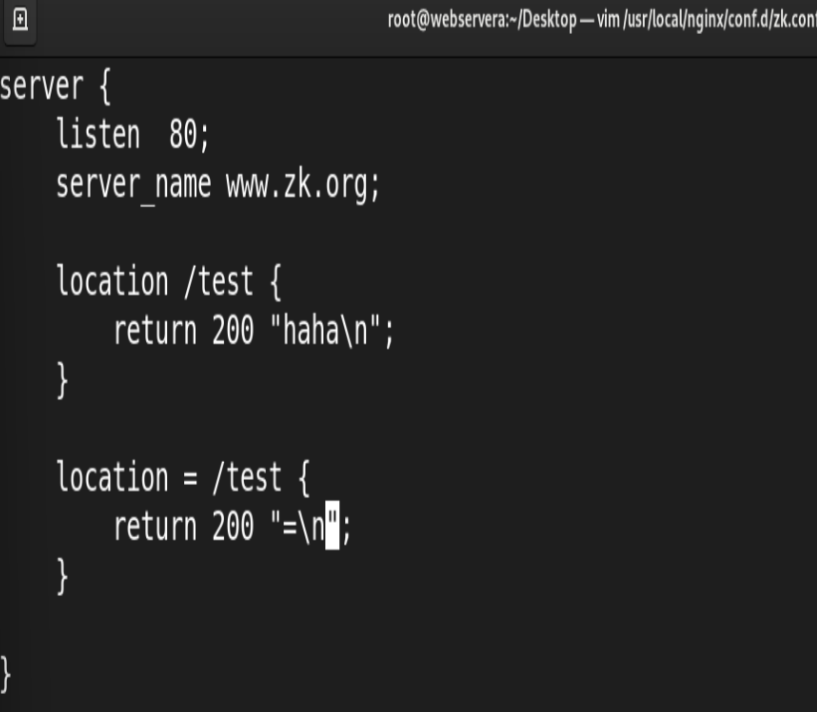
#语法规则:
location [ = | ~ | ~* | ^~ ] uri { ... }
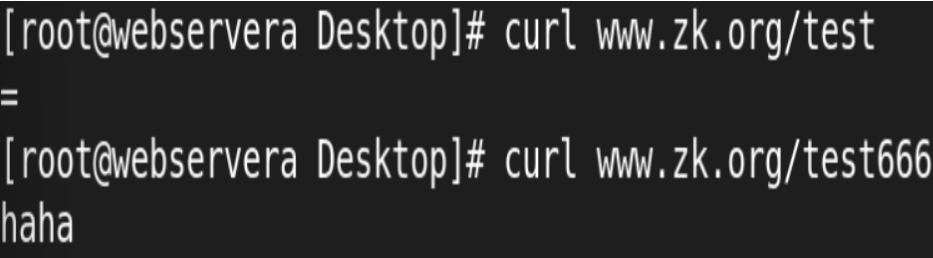
= #用于标准uri前,需要请求字串与uri精确匹配,大小敏感,如果匹配成功就停止向下匹配并立
即处理请求
^~ #用于标准uri前,表示包含正则表达式,并且匹配以指定的正则表达式开头
#对uri的最左边部分做匹配检查,不区分字符大小写
~ #用于标准uri前,表示包含正则表达式,并且区分大小写
~* #用于标准uri前,表示包含正则表达式,并且不区分大写
不带符号 #匹配起始于此uri的所有的uri
\ #用于标准uri前,表示包含正则表达式并且转义字符。可以将 . * ?等转义为普通符号
#匹配优先级从高到低:
=, ^~, ~/~*, 不带符号
nginx -s reload
测试:
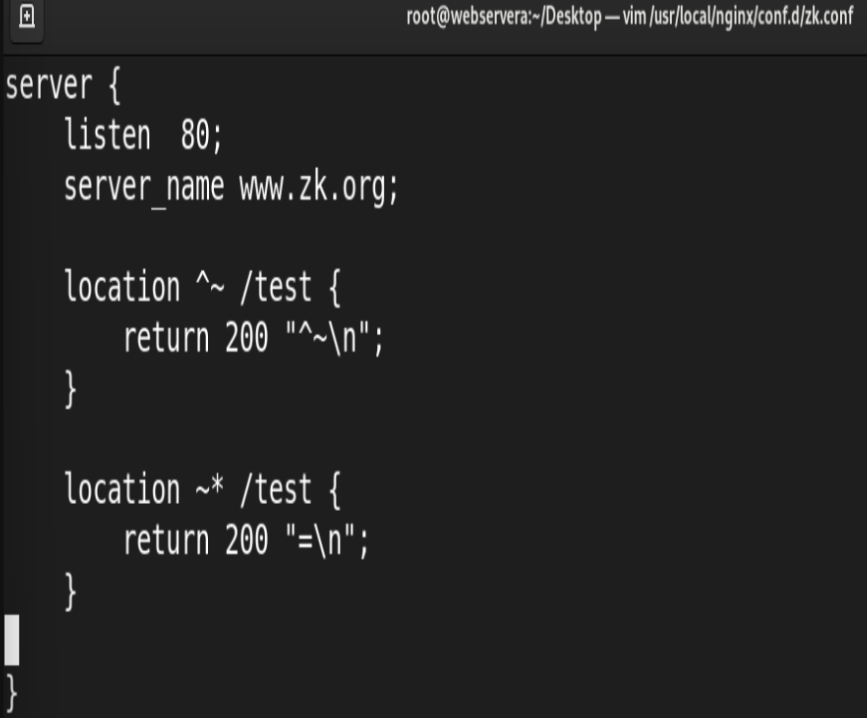

测试:
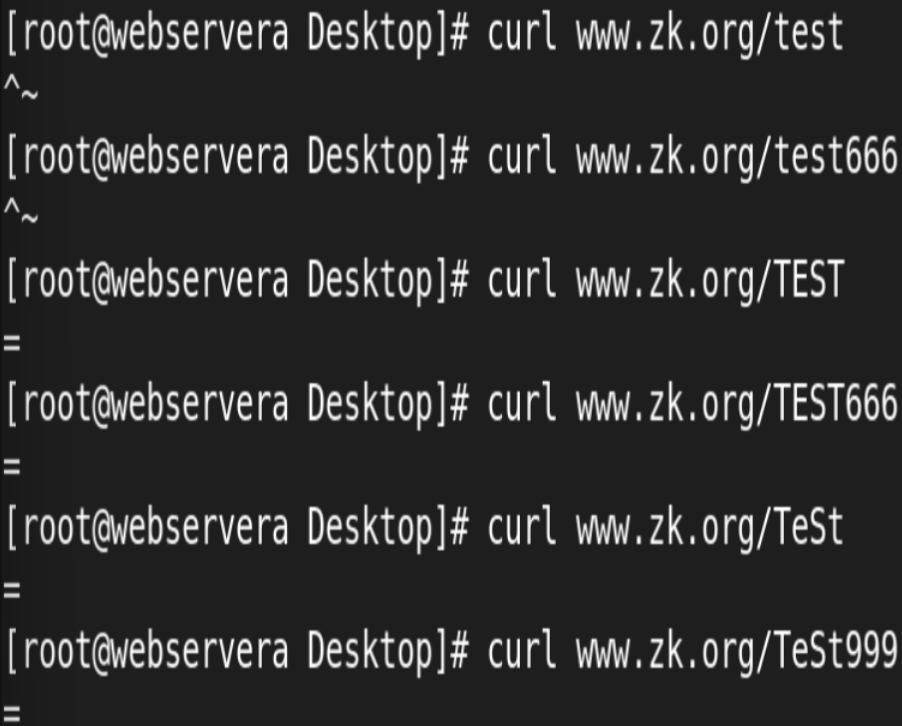
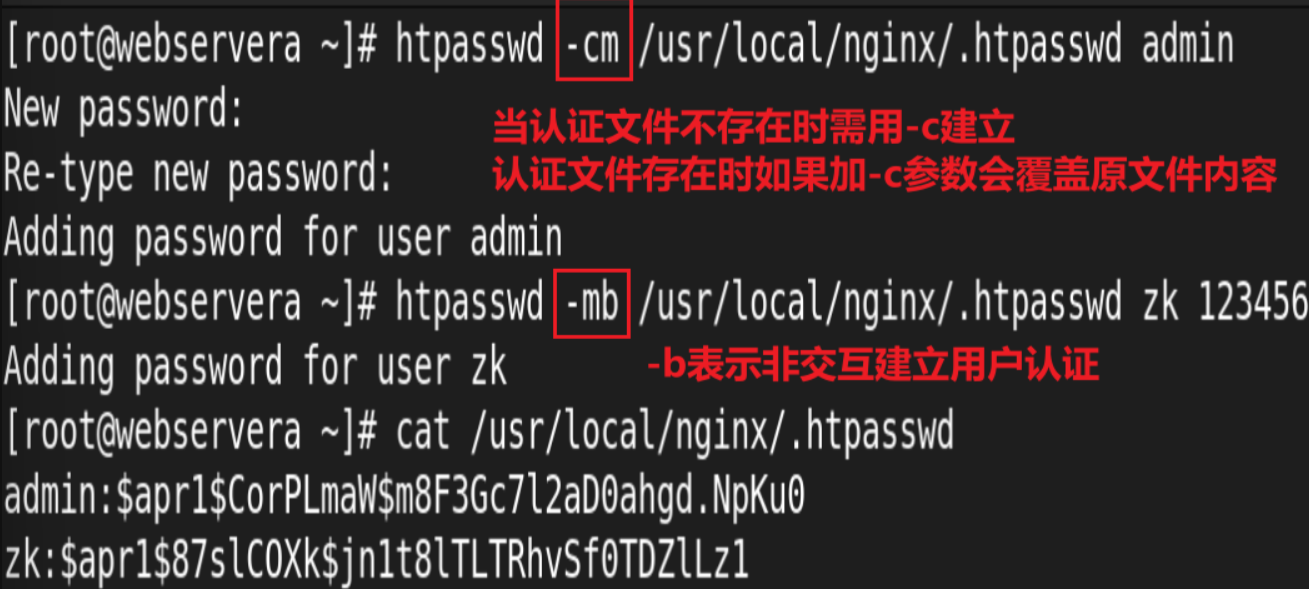
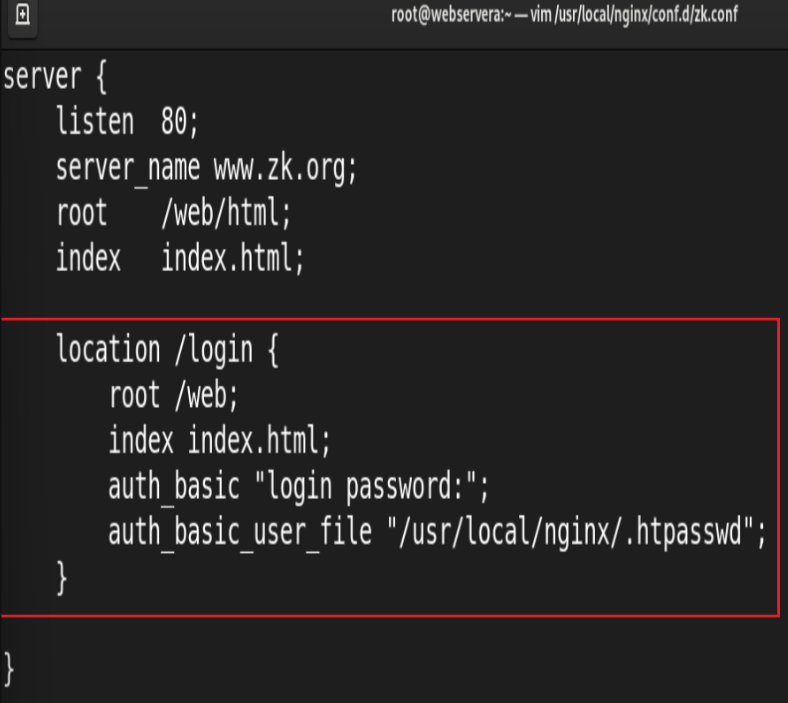
7.Nginx 账户认证功能
由 ngx_http_auth_basic_module 模块提供此功能

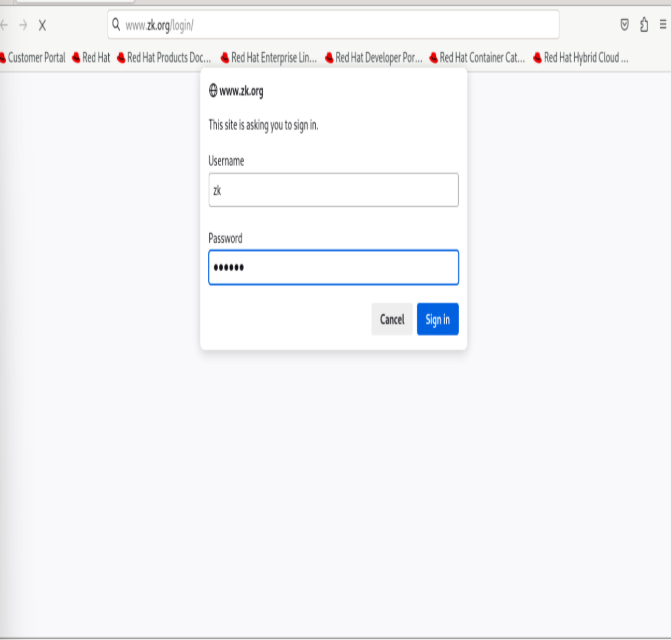
测试:

8.自定义错误页面
自定义错误页,同时也可以用指定的响应状态码进行响应, 可用位置:http, server, location, if in location
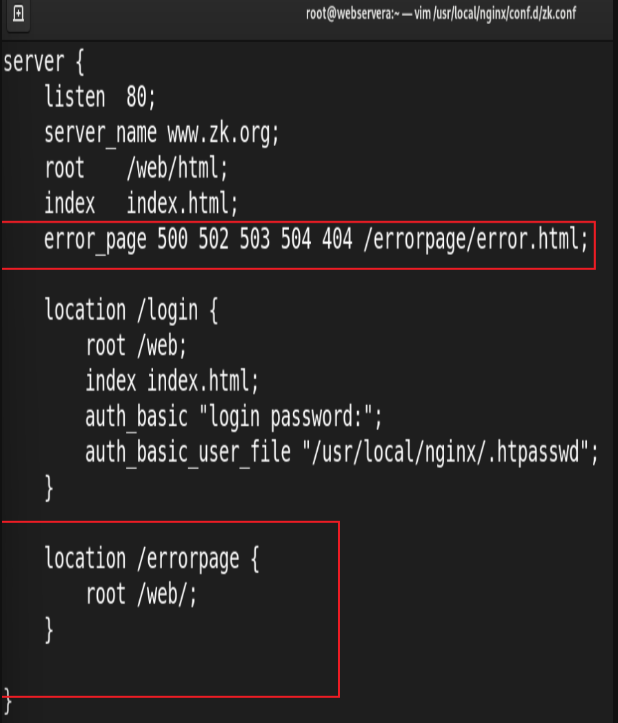

测试:

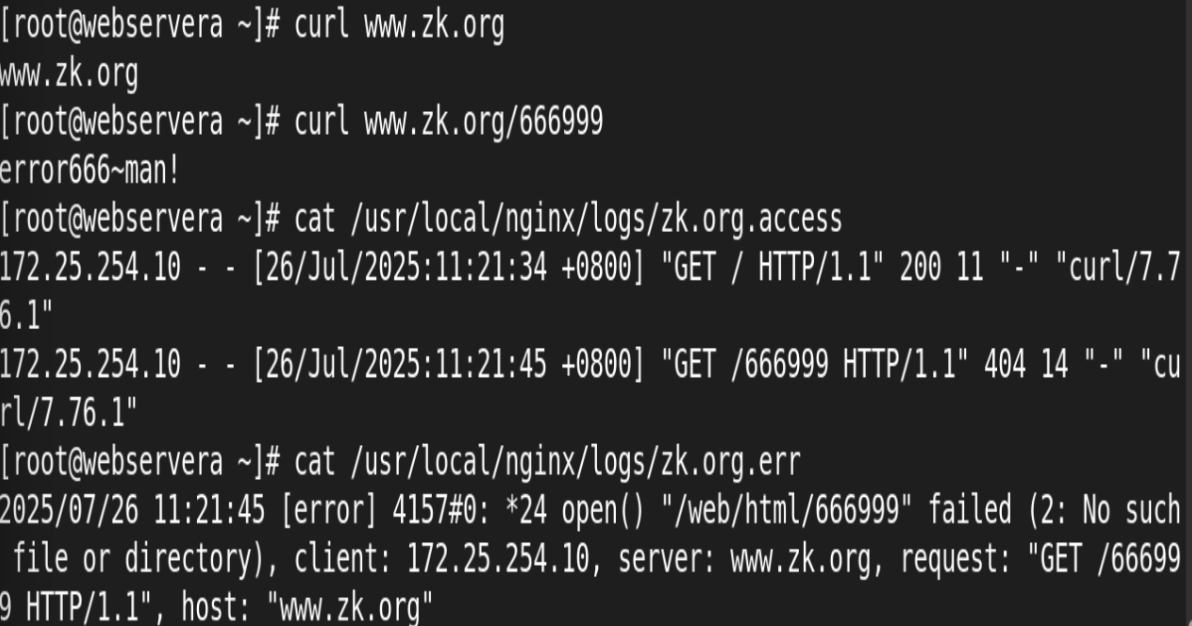
9.自定义错误日志
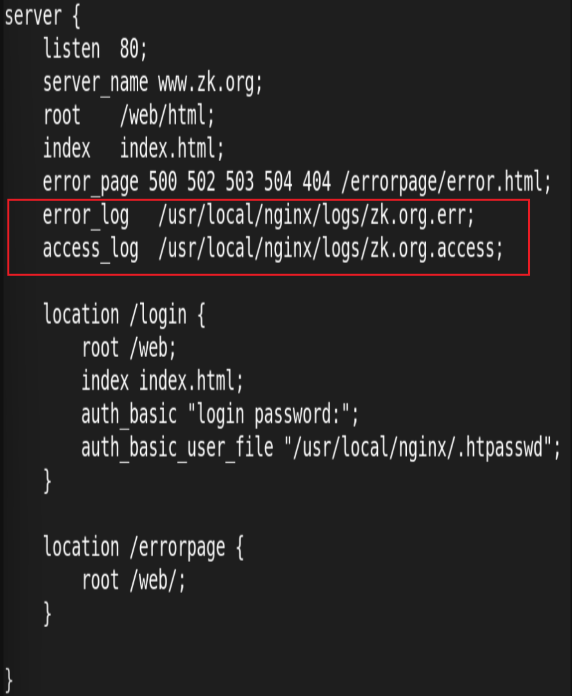
测试:
10.检测文件是否存在
try_files会按顺序检查文件是否存在,返回第一个找到的文件或文件夹(结尾加斜线表示为文件夹),如 果所有文件或文件夹都找不到,会进行一个内部重定向到最后一个参数。只有最后一个参数可以引起一个内部重定向,之前的参数只设置内部URI的指向。最后一个参数是回退URI且必须存在,否则会出现内部500错误。
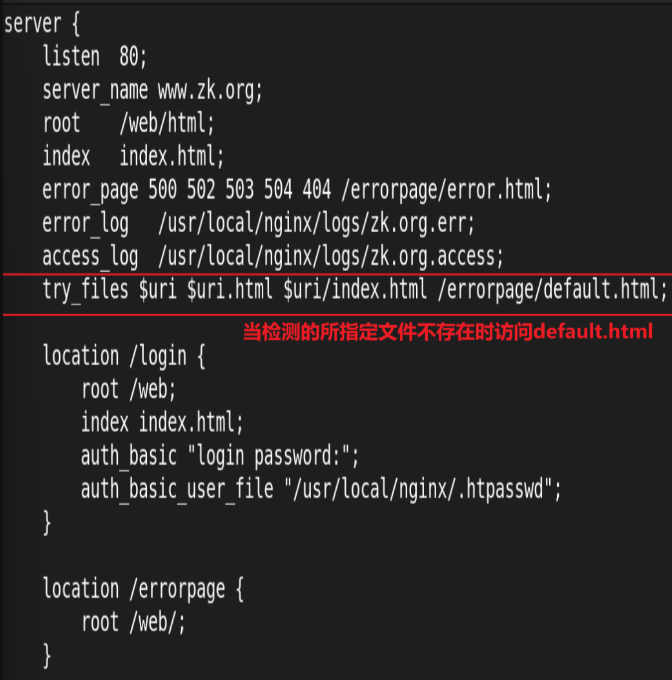

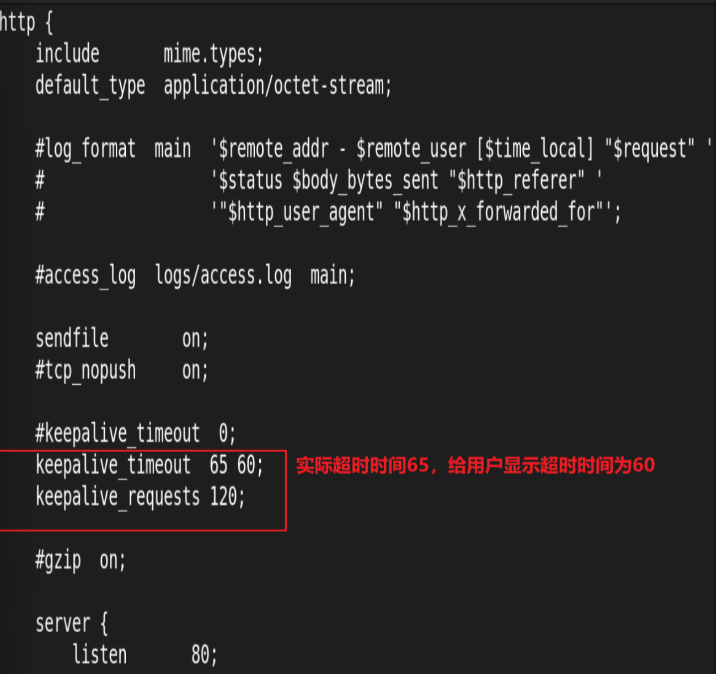
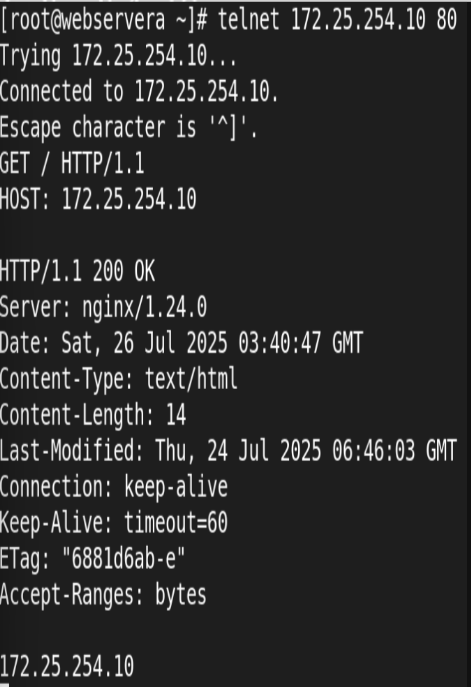
11.长连接配置

![]()
安装测试软件:

测试:
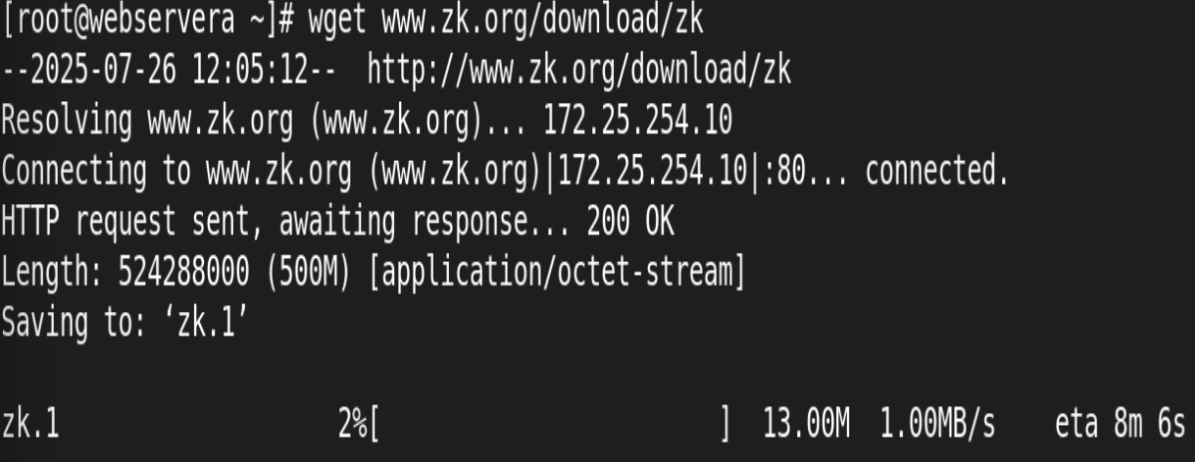
12.作为下载服务器配置

建立共享资源存放目录:
![]()

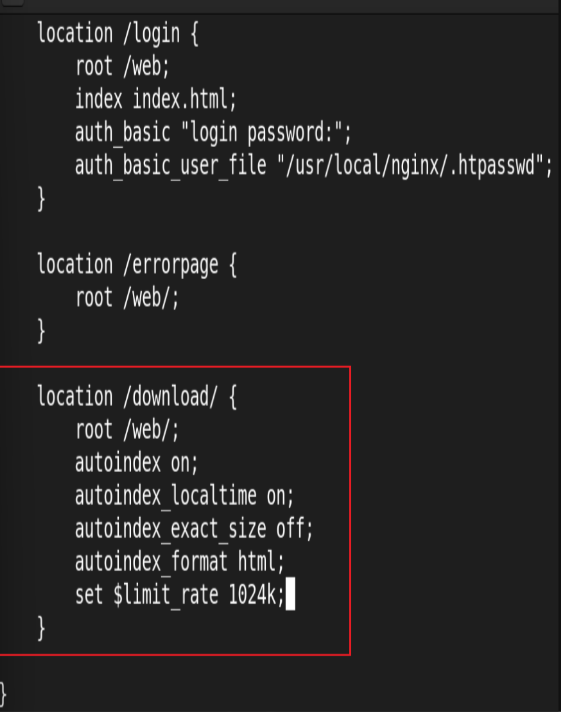
测试:
四、Nginx 高级配置
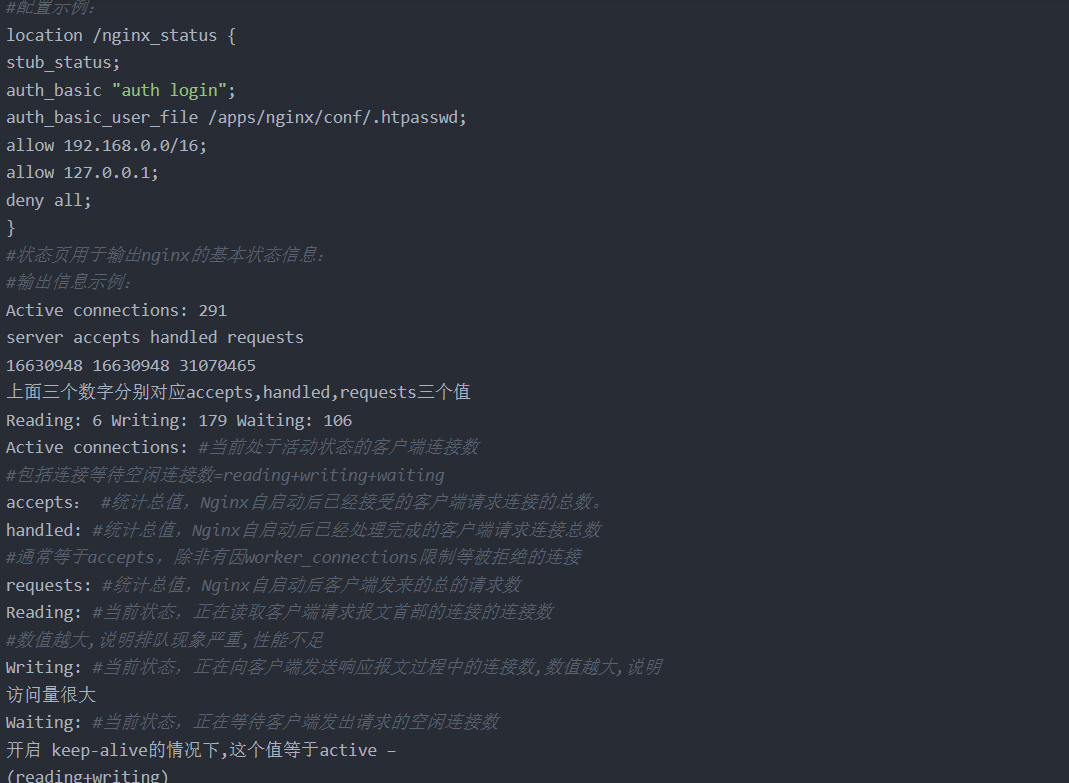
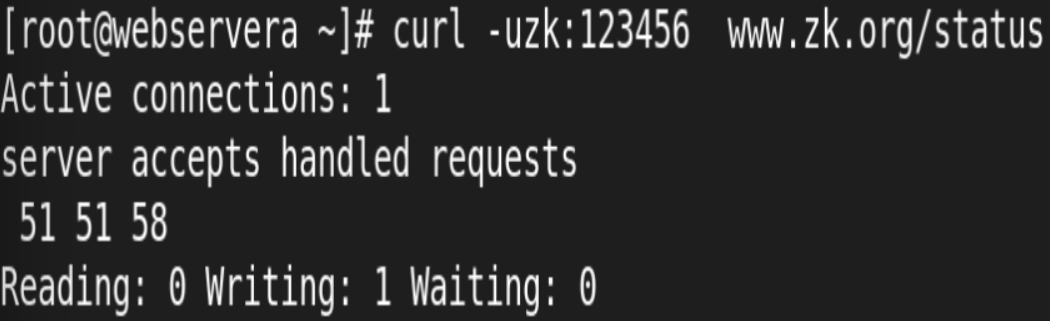
1.Nginx 状态页
基于nginx 模块 ngx_http_stub_status_module 实现, 在编译安装nginx的时候需要添加编译参数 --with-http_stub_status_module 否则配置完成之后监测会是提示法错误
状态页显示的是整个服务器的状态,而非虚拟主机的状态
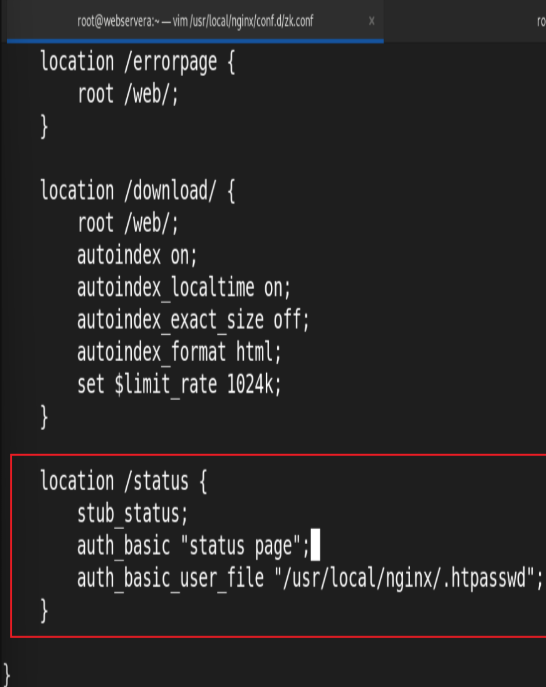

测试:
2.Nginx 压缩功能
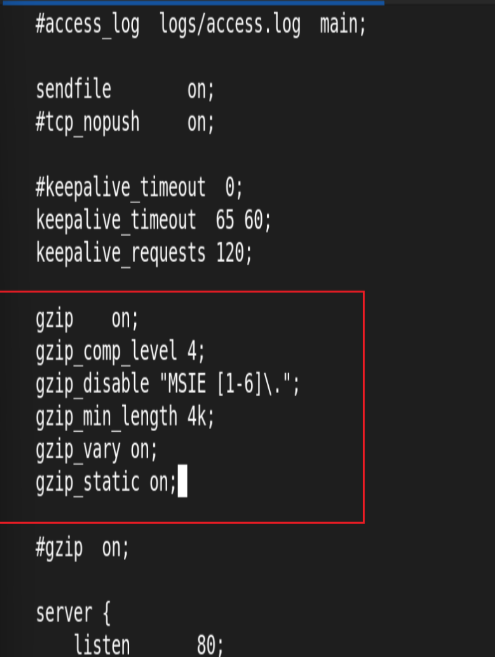
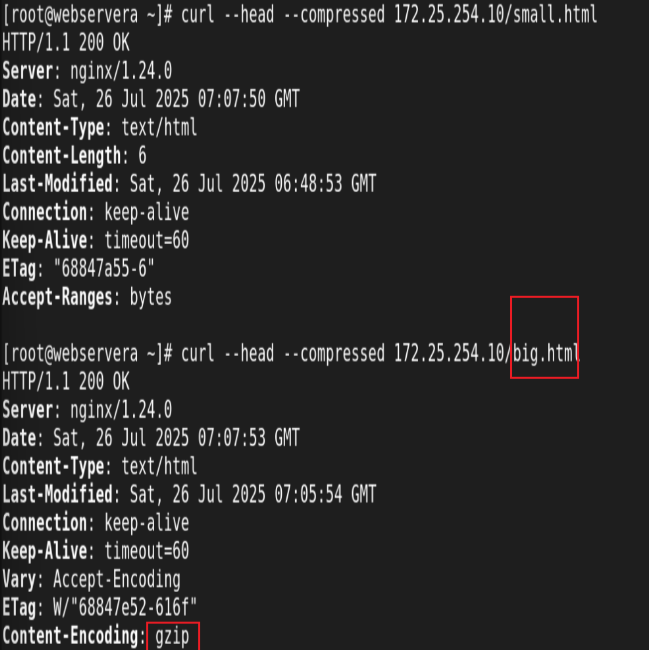
Nginx支持对指定类型的文件进行压缩然后再传输给客户端,而且压缩还可以设置压缩比例,压缩后的文件大小将比源文件显著变小,样有助于降低出口带宽的利用率,降低企业的IT支出,不过会占用相 应的CPU资源。 Nginx对文件的压缩功能是依赖于模块 ngx_http_gzip_module,默认是内置模块

建立实验素材:

编辑主配置文件:
测试:
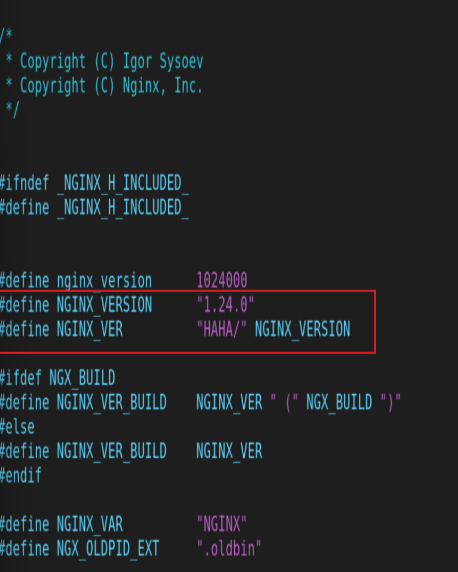
3.Nginx的版本隐藏
用户在访问nginx的时候,我们可以从报文中获得nginx的版本,相对于裸漏版本号的nginx,我们把其隐藏起来更安全(编译之前设置)
![]()
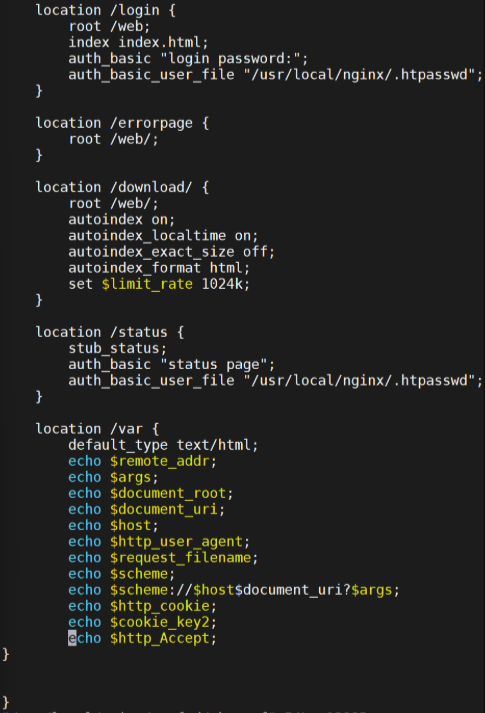
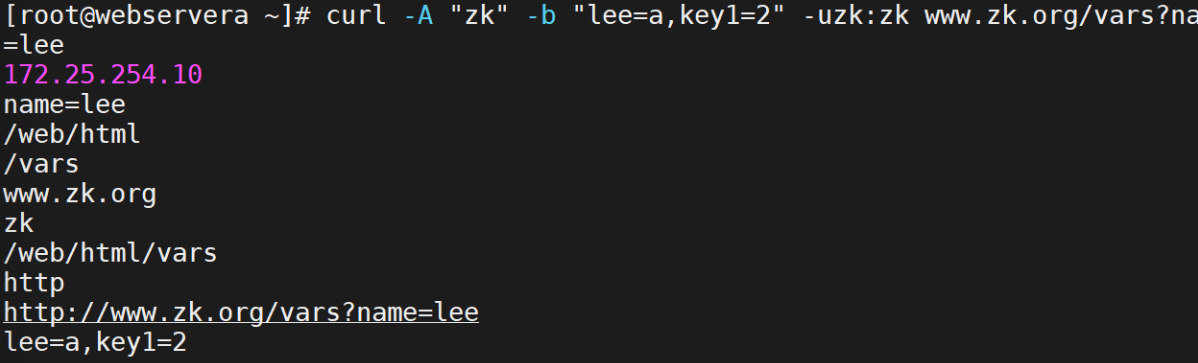
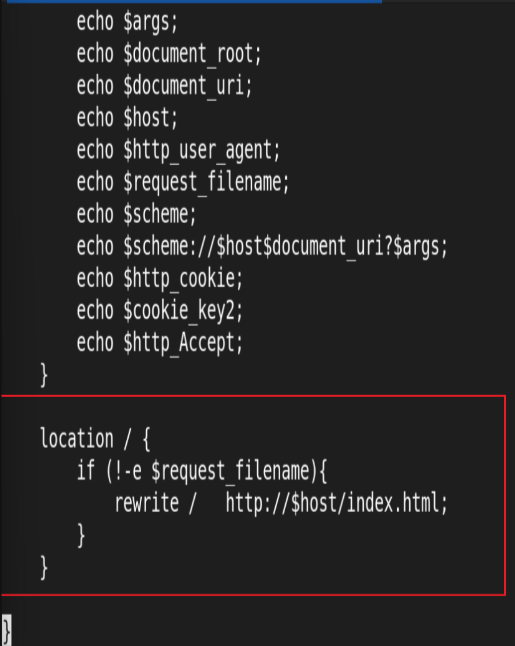
4.Nginx 变量使用
常用内置变量
$remote_addr;
# 存储客户端公网IP地址$args;
# 存储URL中的所有请求参数
# 示例:https://search.jd.com/Search?keyword=手机&enc=utf-8
# 返回结果:keyword=手机&enc=utf-8$is_args;
# 若请求带参数则返回"?",否则返回空值$document_root;
# 当前请求资源的系统根目录路径
# 示例:/webdata/nginx/timinglee.org/lee$document_uri;
# 当前请求中不带参数的URI部分
# 示例:http://lee.timinglee.org/var?\id=11111
# 返回结果:/var$host;
# 请求的主机名limit_rate 10240;
echo $limit_rate;
# 显示网络速率限制值(未设置则显示0)$remote_port;
# 客户端连接Nginx时使用的随机端口号$remote_user;
# 通过Auth Basic Module认证的用户名$request_body_file;
# 反向代理时发送给后端服务器的本地资源文件名$request_method;
# 请求方法(GET/PUT/DELETE等)$request_filename;
# 当前请求资源文件的完整磁盘路径
# 示例:webdata/nginx/timinglee.org/lee/var/index.html$request_uri;
# 包含参数的原始URI(不包含主机名)
# 格式:$document_uri?$args
# 示例:/main/index.do?id=20190221&partner=search$scheme;
# 请求协议(http/https/ftp等)$server_protocol;
# 客户端使用的协议版本
# 示例:HTTP/1.0, HTTP/1.1, HTTP/2.0$server_addr;
# 服务器IP地址$server_name;
# 虚拟主机名$server_port;
# 虚拟主机端口号$http_user_agent;
# 客户端浏览器信息$http_cookie;
# 客户端所有cookie信息$cookie_<name>;
# 获取指定cookie键值(将name替换为实际cookie名)$http_<name>;
# 获取请求头字段值(name需小写,横线转下划线)先备份原本的主和子配置文件
systemctl stop nginx
编译中添加插件:
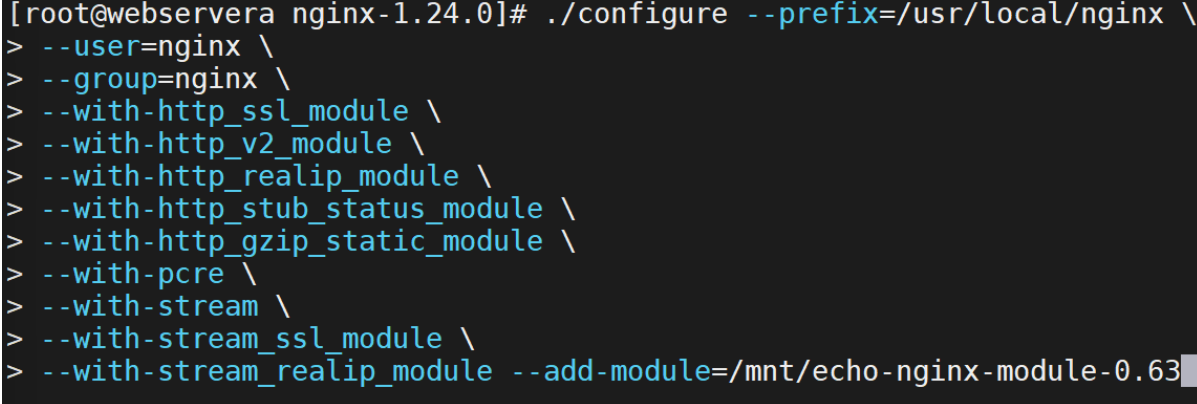
make & make install 重新编译安装
将原来的主和子配置文件覆盖新的主和子配置文件
systemctl restart nginx
编辑配置文件:
测试:
五、Nginx Rewrite 相关功能
Nginx服务器利用 ngx_http_rewrite_module 模块解析和处理rewrite请求
此功能依靠 PCRE(perl compatible regular expression),因此编译之前要安装PCRE库
rewrite是nginx服务器的重要功能之一,用于实现URL的重写,URL的重写是非常有用的功能
比如它可以在我们改变网站结构之后,不需要客户端修改原来的书签,也无需其他网站修改我们的 链接,就可以设置为访问
另外还可以在一定程度上提高网站的安全性。
1.ngx_http_rewrite_module 模块指令
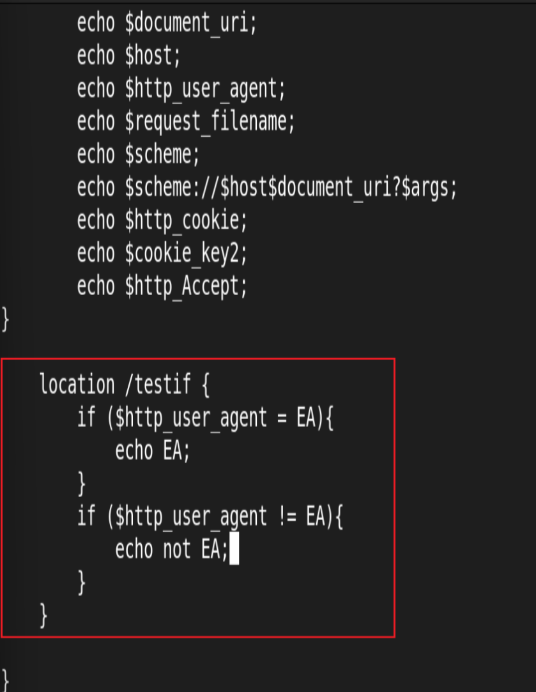
if 指令
用于条件匹配判断,并根据条件判断结果选择不同的Nginx配置,可以配置在server或location块中进行配置,Nginx的if语法仅能使用if做单次判断,不支持使用if else或者if elif这样的多重判断
使用正则表达式对变量进行匹配,匹配成功时if指令认为条件为true,否则认为false,变量与表达式之间使用以下符号链接:
= #比较变量和字符串是否相等,相等时if指令认为该条件为true,反之为false
!= #比较变量和字符串是否不相等,不相等时if指令认为条件为true,反之为false
~ #区分大小写字符,可以通过正则表达式匹配,满足匹配条件为真,不满足匹配条件为假
!~ #区分大小写字符,判断是否匹配,不满足匹配条件为真,满足匹配条件为假
~* #不区分大小写字符,可以通过正则表达式匹配,满足匹配条件为真,不满足匹配条件为假
!~* #不区分大小字符,判断是否匹配,满足匹配条件为假,不满足匹配条件为真
-f 和 !-f #判断请求的文件是否存在和是否不存在
-d 和 !-d #判断请求的目录是否存在和是否不存在
-x 和 !-x #判断文件是否可执行和是否不可执行
-e 和 !-e #判断请求的文件或目录是否存在和是否不存在(包括文件,目录,软链接)
#注意:
#如果$变量的值为空字符串或0,则if指令认为该条件为false,其他条件为true。
#nginx 1.0.1之前$变量的值如果以0开头的任意字符串会返回false

测试:

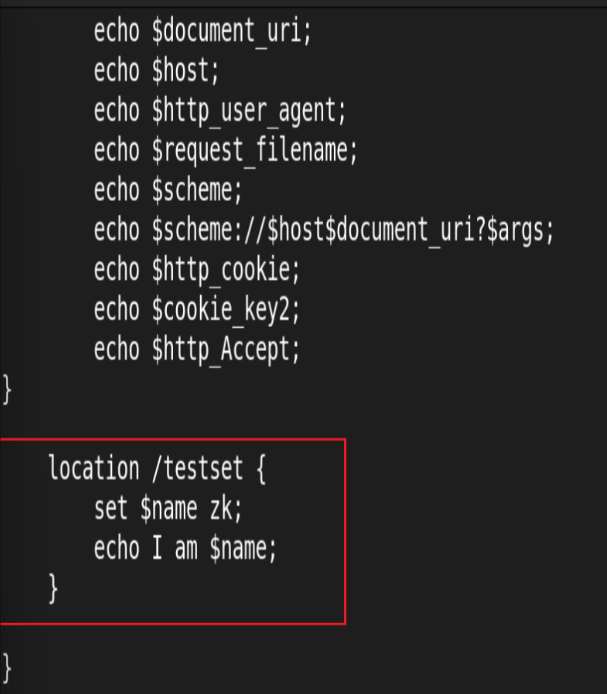
set 指令
指定key并给其定义一个变量,变量可以调用Nginx内置变量赋值给key另外set定义格式为set $key value,value可以是text, variables和两者的组合。
测试:

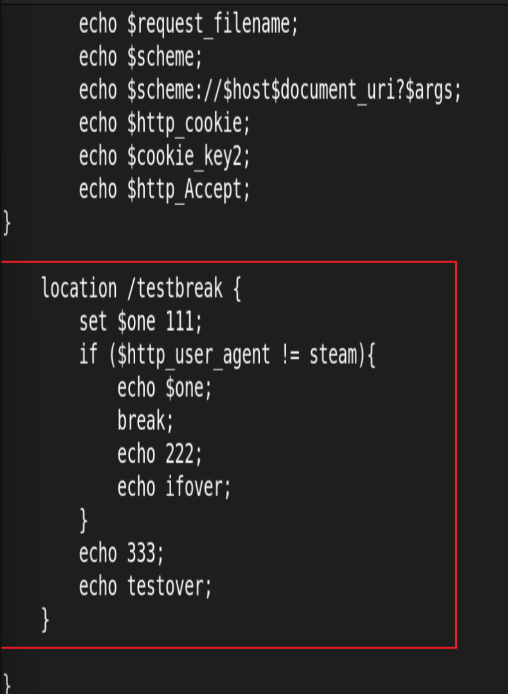
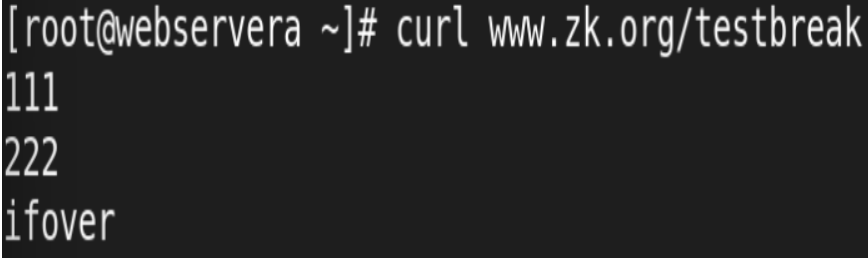
break 指令
用于中断当前相同作用域(location)中的其他Nginx配置 与该指令处于同一作用域的Nginx配置中,位于它前面的配置生效位于后面的 ngx_http_rewrite_module 模块中指令就不再执行Nginx服务器在根据配置处理请求的过程中遇到该指令的时候,回到上一层作用域继续向下读取配置, 该指令可以在server块和locationif块中使用
测试:
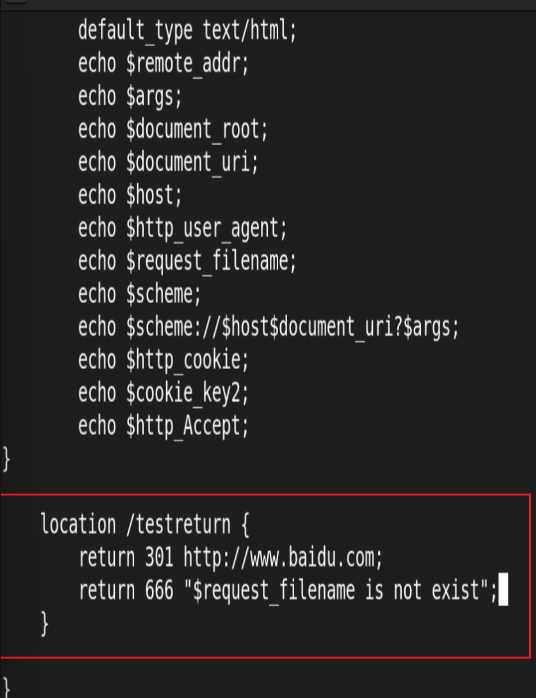
return 指令
return用于完成对请求的处理,并直接向客户端返回响应状态码,比如:可以指定重定向URL(对于特殊重 定向状态码,301/302等) 或者是指定提示文本内容(对于特殊状态码403/500等),处于此指令后的所有配置都将不被执行,return可以在server、if 和 location块进行配置
测试:
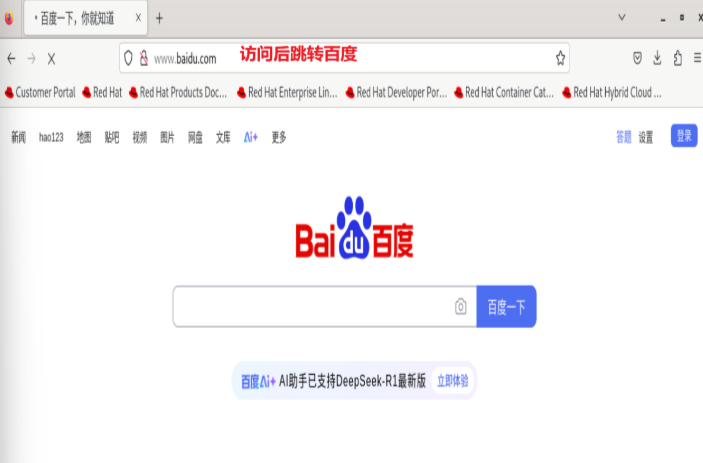
2.rewrite 指令
通过正则表达式的匹配来改变URI,可以同时存在一个或多个指令,按照顺序依次对URI进行匹配, rewrite主要是针对用户请求的URL或者是URI做具体处理
rewrite将用户请求的URI基于regex所描述的模式进行检查,匹配到时将其替换为表达式指定的新的URI
注意:如果在同一级配置块中存在多个rewrite规则,那么会自下而下逐个检查;被某条件规则替换完成后,会重新一轮的替换检查,隐含有循环机制,但不超过10次;如果超过,提示500响应码,[flag]所表示的标志位用于控制此循环机制
如果替换后的URL是以http://或https://开头,则替换结果会直接以重定向返回给客户端, 即永久重定向 301
正则表达式格式
. #匹配除换行符以外的任意字符
\w #匹配字母或数字或下划线或汉字
\s #匹配任意的空白符
\d #匹配数字
\b #匹配单词的开始或结束
^ #匹配字付串的开始
$ #匹配字符串的结束
* #匹配重复零次或更多次
+ #匹配重复一次或更多次
? #匹配重复零次或一次
(n) #匹配重复n次
{n,} #匹配重复n次或更多次
{n,m} #匹配重复n到m次
*? #匹配重复任意次,但尽可能少重复
+? #匹配重复1次或更多次,但尽可能少重复
?? #匹配重复0次或1次,但尽可能少重复
{n,m}? #匹配重复n到m次,但尽可能少重复
{n,}? #匹配重复n次以上,但尽可能少重复
\W #匹配任意不是字母,数字,下划线,汉字的字符
\S #匹配任意不是空白符的字符
\D #匹配任意非数字的字符
\B #匹配不是单词开头或结束的位置
[^x] #匹配除了x以外的任意字符
[^lee] #匹配除了lee 这几个字母以外的任意字符
rewrite flag 使用介绍
利用nginx的rewrite的指令,可以实现url的重新跳转,rewrite有四种不同的flag,分别是redirect(临时 重定向302)、permanent(永久重定向301)、break和last。其中前两种是跳转型的flag,后两种是代理型
跳转型指由客户端浏览器重新对新地址进行请求
代理型是在WEB服务器内部实现跳转
flag 说明:
redirect;
#临时重定向,重写完成后以临时重定向方式直接返回重写后生成的新URL给客户端
#由客户端重新发起请求;使用相对路径,或者http://或https://开头,状态码:302
permanent;
#重写完成后以永久重定向方式直接返回重写后生成的新URL给客户端
#由客户端重新发起请求,状态码:301
break;
#重写完成后,停止对当前URL在当前location中后续的其它重写操作
#而后直接跳转至重写规则配置块之后的其它配置,结束循环,建议在location中使用
#适用于一个URL一次重写
last;
#重写完成后,停止对当前URI在当前location中后续的其它重写操作,
#而后对新的URL启动新一轮重写检查,不建议在location中使用
#适用于一个URL多次重写,要注意避免出现超过十次以及URL重写后返回错误的给用户
rewrite案例: 域名永久与临时重定向
域名的临时的调整,后期可能会变,之前的域名或者URL可能还用、或者跳转的目的域名和URL还会跳 转,这种情况浏览器不会缓存跳转,临时重定向不会缓存域名解析记录(A记录),但是永久重定向会缓存
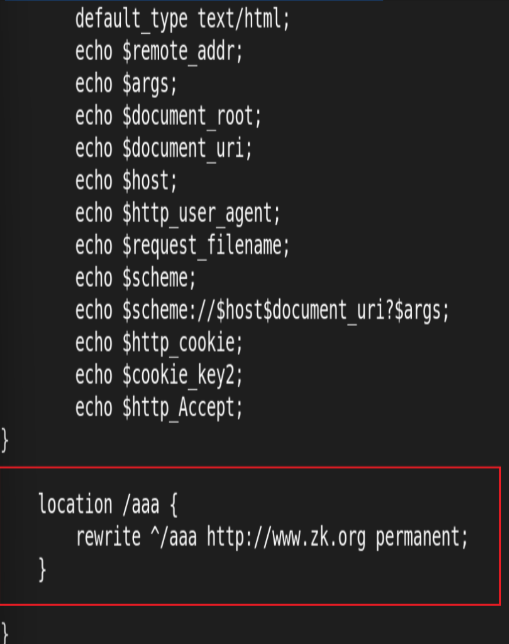
永久重定向301:
域名永久型调整,即域名永远跳转至另外一个新的域名,之前的域名再也不使用,跳转记录可以缓存到 客户端浏览器 永久重定向会缓存DNS解析记录, 浏览器中有 from disk cache 信息,即使nginx服务器无法访问,浏览器也 会利用缓存进行重定向
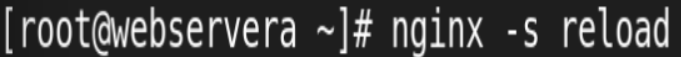

临时重定向302:
域名临时重定向,告诉浏览器域名不是固定重定向到当前目标域名,后期可能随时会更改,因此浏览器 不会缓存当前域名的解析记录,而浏览器会缓存永久重定向的DNS解析记录,这也是临时重定向与永久 重定向最大的本质区别。
即当nginx服务器无法访问时,浏览器不能利用缓存,而导致重定向失败
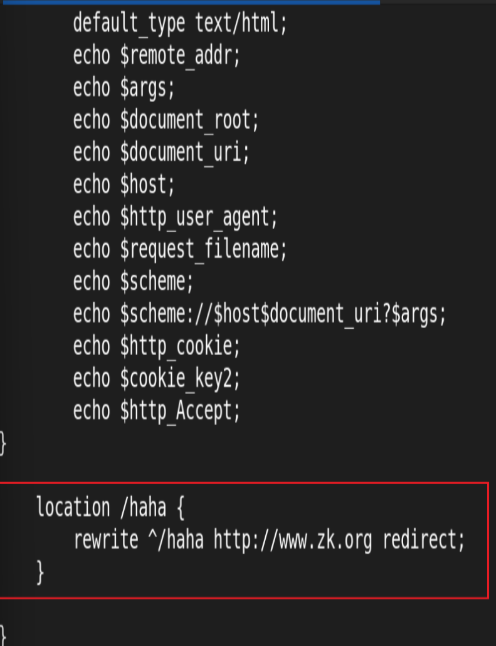
 rewrite 案例: break 与 last
rewrite 案例: break 与 last
测试:

break:终止当前rewrite规则,不再匹配后续规则或location。
last:完成当前rewrite规则后,重新匹配location。
默认行为为last,可根据需求选择合适的指令。
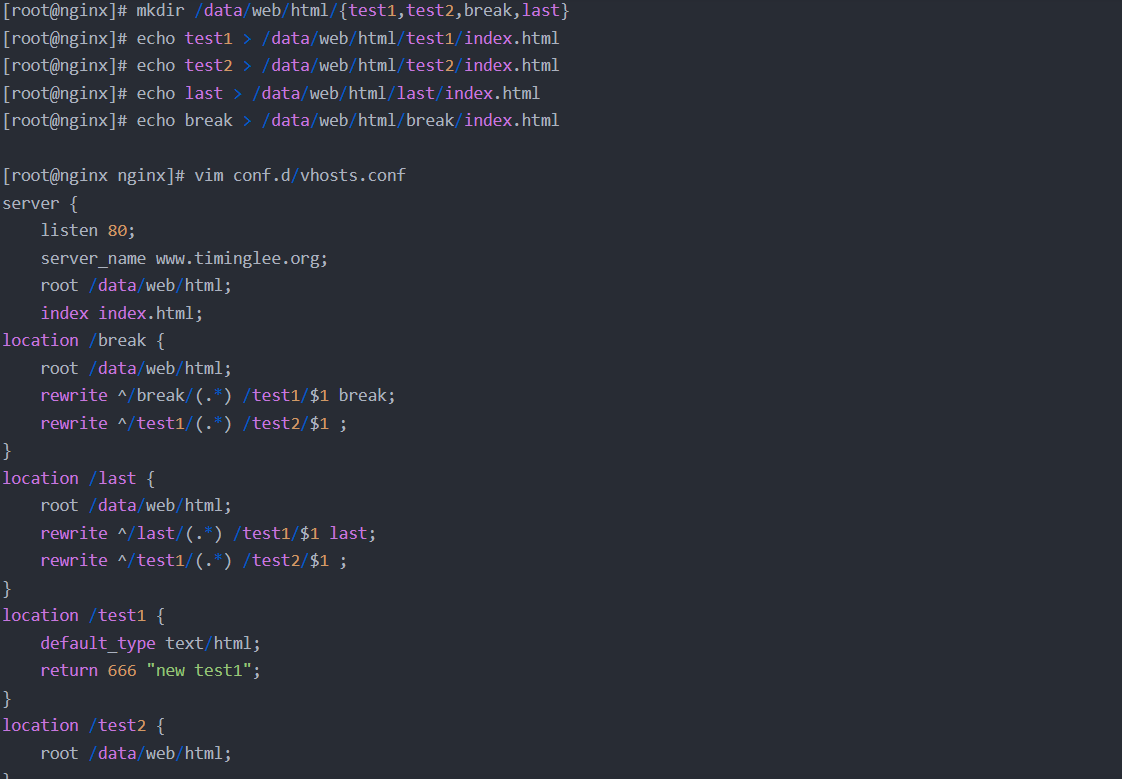
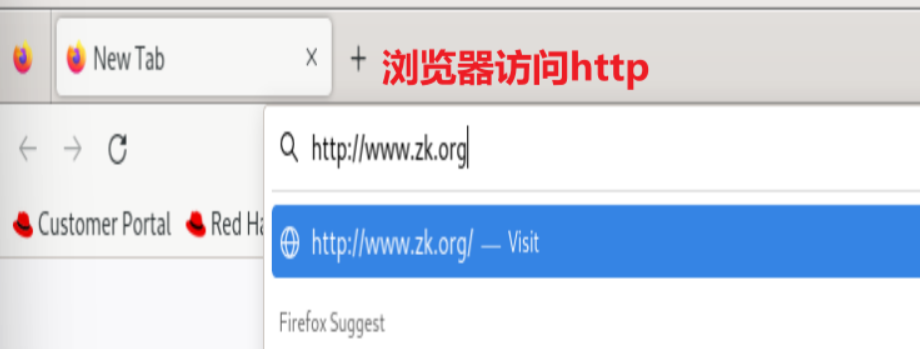
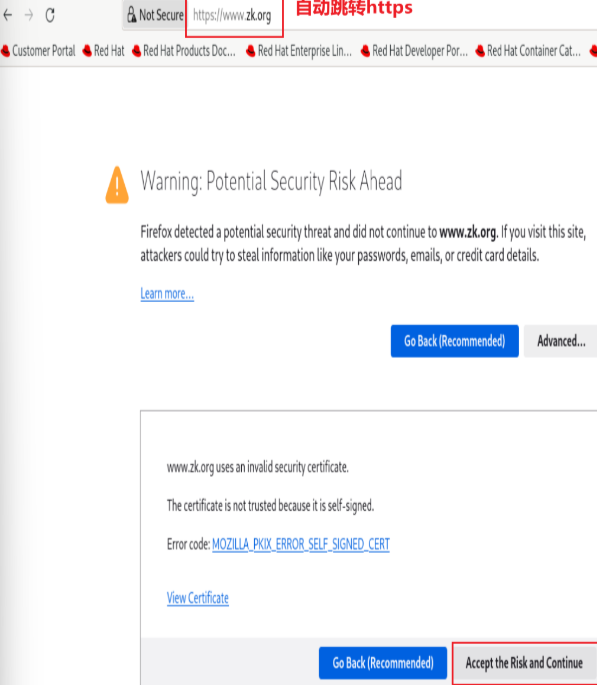
rewrite案例: 自动跳转 https
案例:基于通信安全考虑公司网站要求全站 https,因此要求将在不影响用户请求的情况下将http请求全部自动跳转至 https,另外也可以实现部分 location 跳转
制作证书:
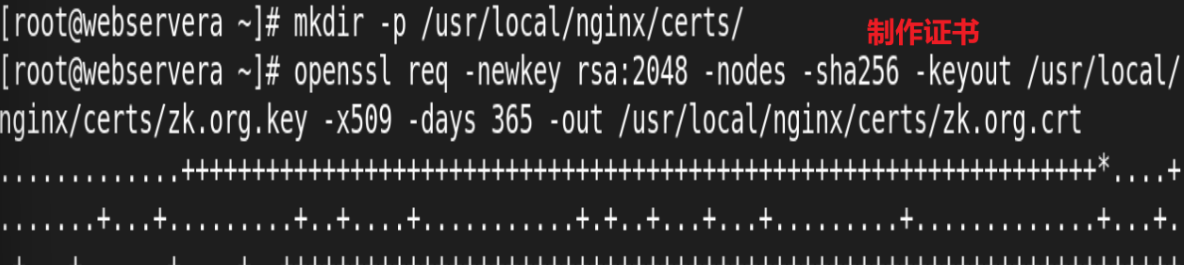
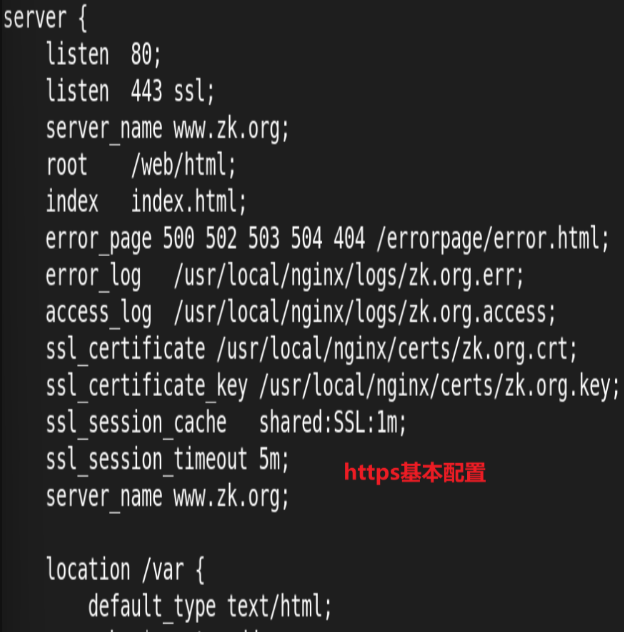
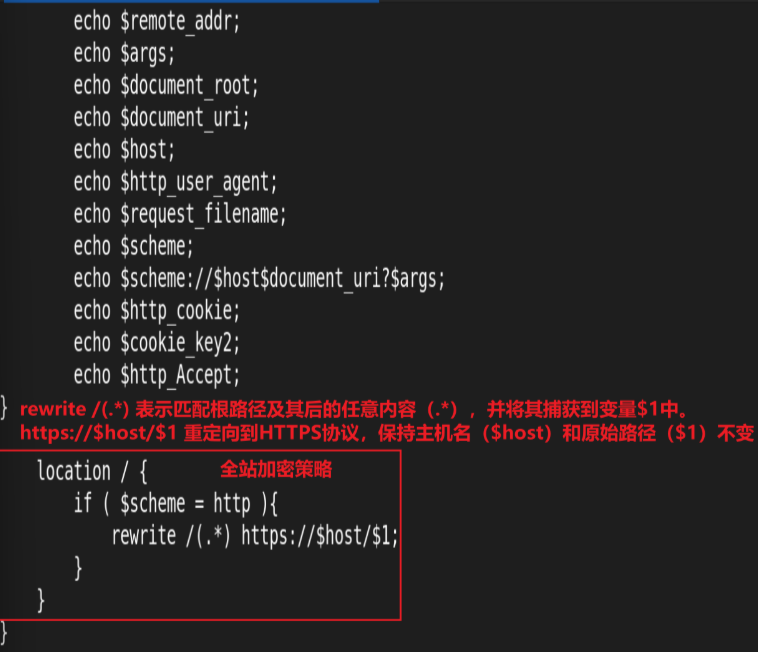
测试:
rewrite 案例: 判断网页存在与否
案例:当用户访问到公司网站的时输入了一个错误的URL,可以将用户重定向至官网首页
测试:

3.Nginx 防盗链
防盗链基于客户端携带的referer实现,referer是记录打开一个页面之前记录是从哪个页面跳转过来的标 记信息,如果别人只链接了自己网站图片或某个单独的资源,而不是打开了网站的整个页面,这就是盗 链,referer就是之前的那个网站域名,正常的referer信息有以下几种:

正常通过搜索引擎搜索web 网站并访问该网站的referer信息如下:
日志
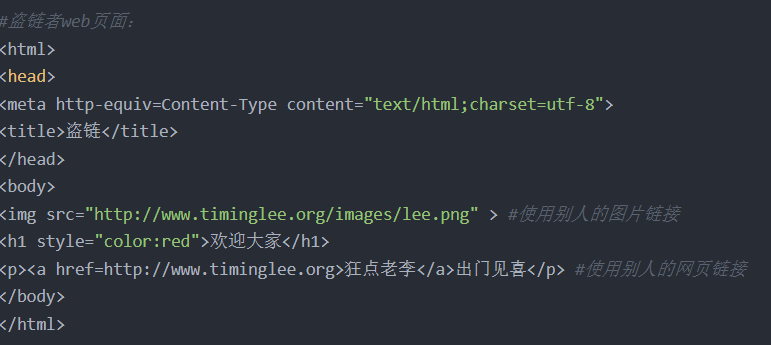
实现盗链
在一个web 站点盗链另一个站点的资源信息,比如:图片、视频等
实现防盗链
基于访问安全考虑,nginx支持通过ngx_http_referer_module模块,检查访问请求的referer信息是否有效 实现防盗链功能
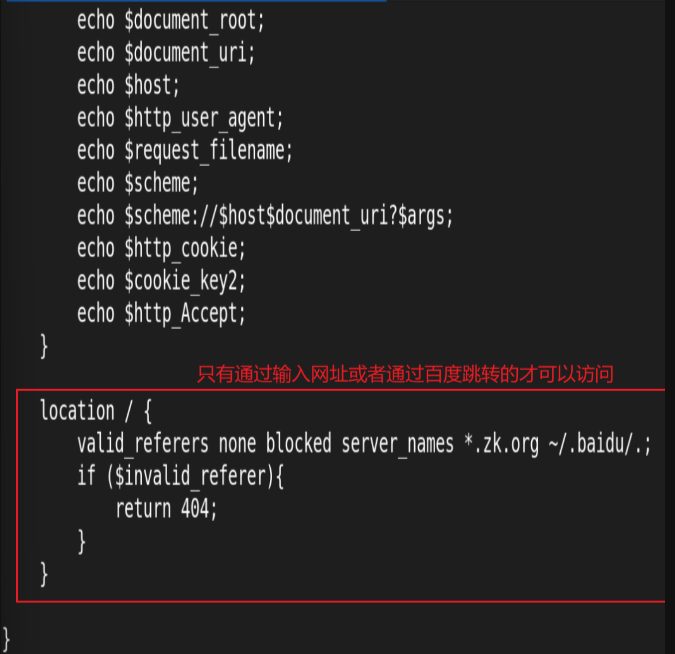
六、Nginx 反向代理功能
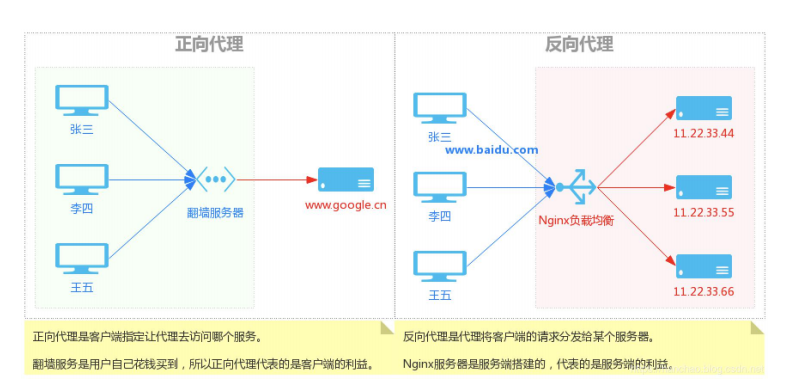
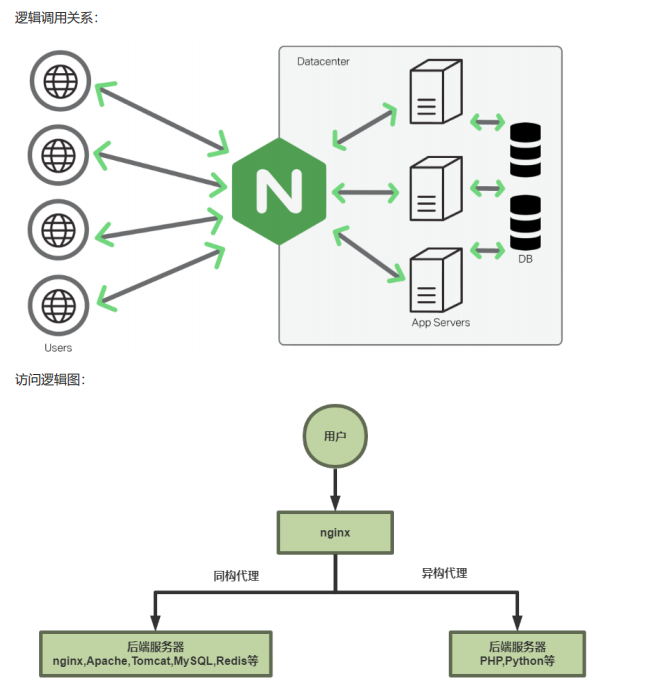
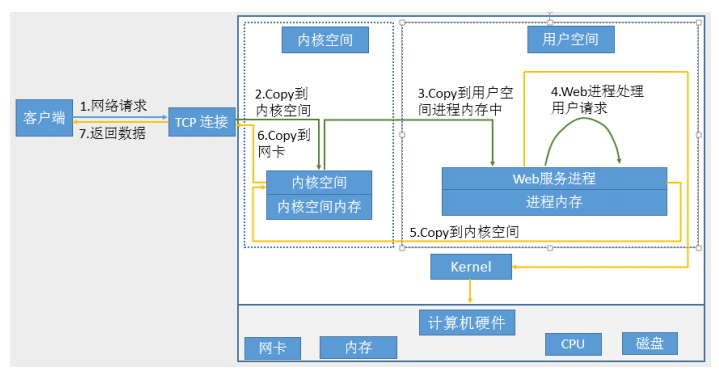
同构代理:用户不需要其他程序的参与,直接通过http协议或者tcp协议访问后端服务器
异构代理:用户访问的资源时需要经过处理后才能返回的,比如php,python,等等,这种访问资源需要经过处理才能被访问
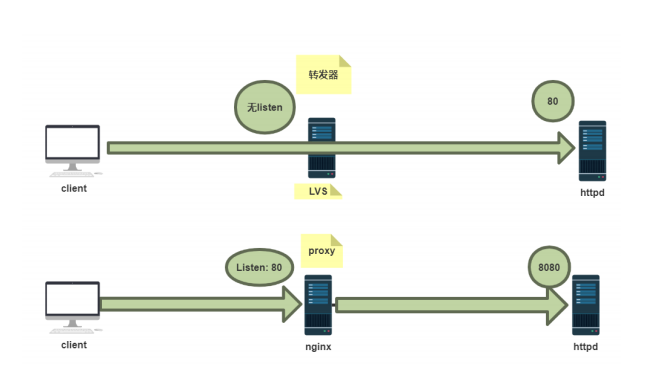
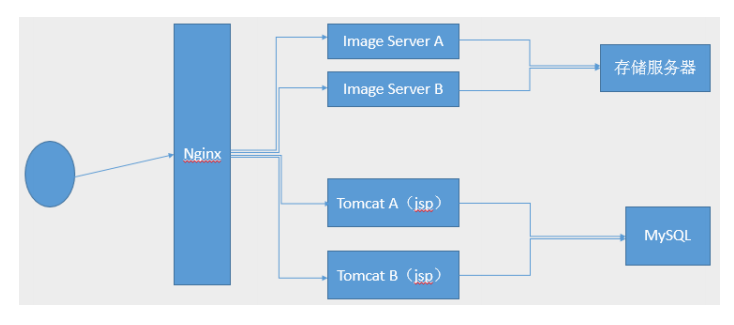
1.实战案例: 反向代理针对特定的资源实现代理(动静分离)
要求:将用户对域 www.zk.org 的请求转发给后端服务器处理
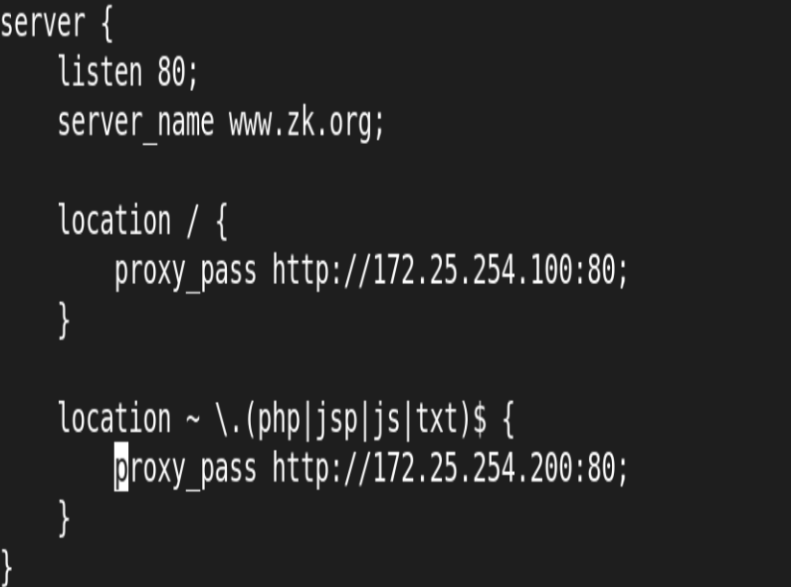
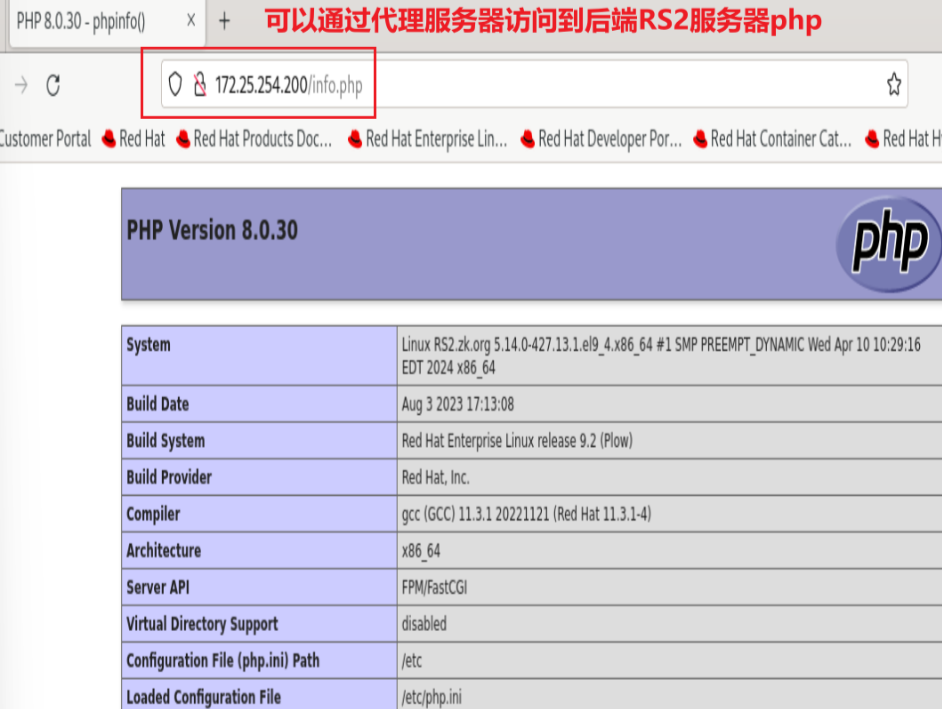
RS1和RS2安装httpd并启动,关闭火墙和selinux
RS2安装php,并在默认发布目录写info.php


2.反向代理示例: 缓存功能
编辑主配置文件:
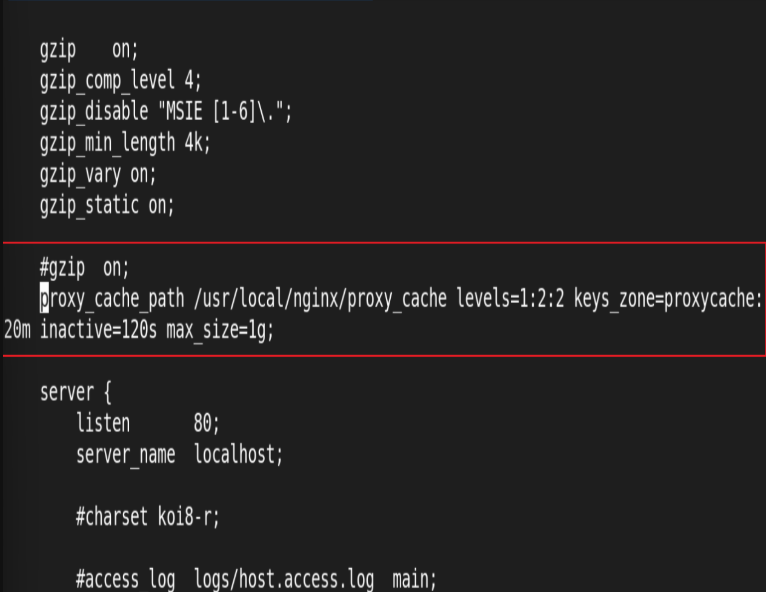
编辑子配置文件:

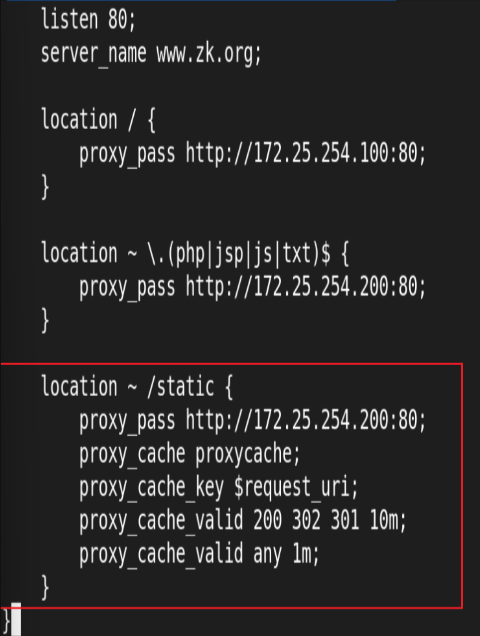
访问并验证缓存文件:
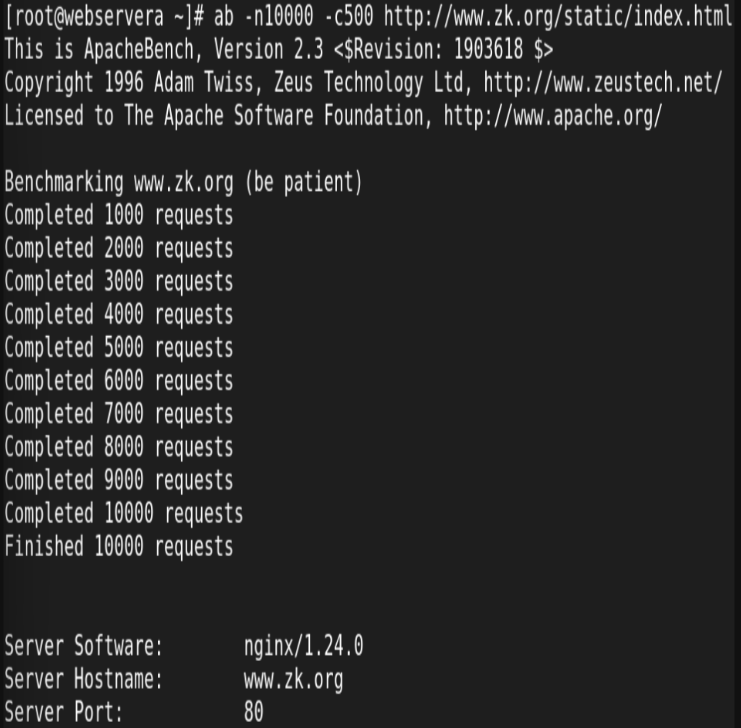
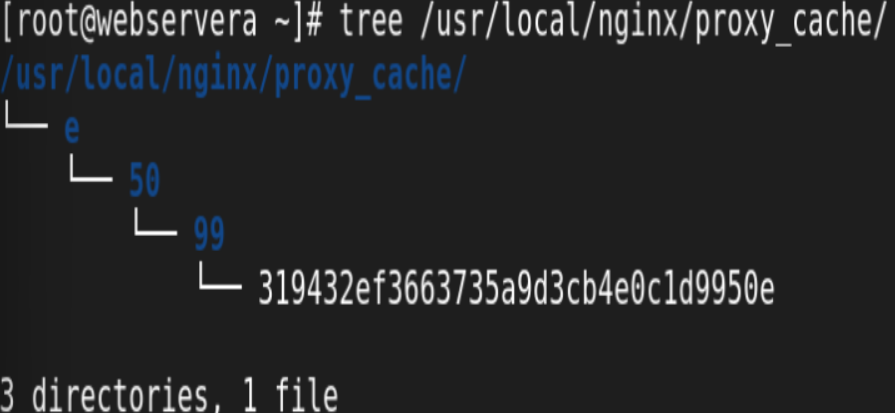
验证缓存目录结构及文件大小:
3.http 反向代理负载均衡
注意: 本节实验过程中先关闭缓存
配置:
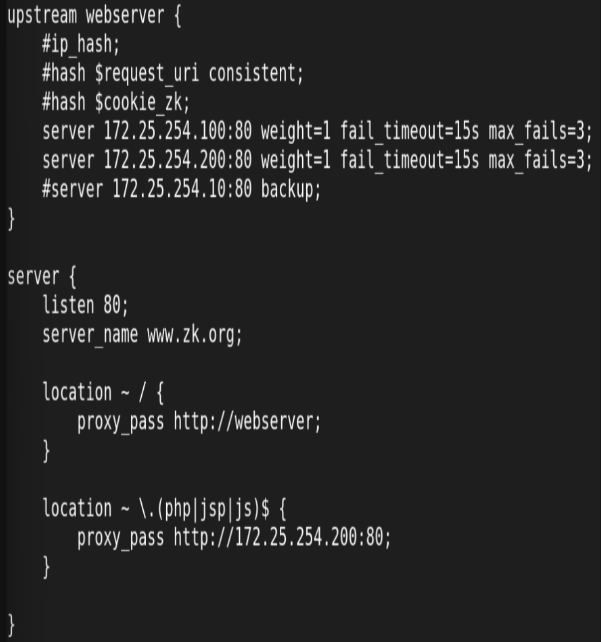
测试:
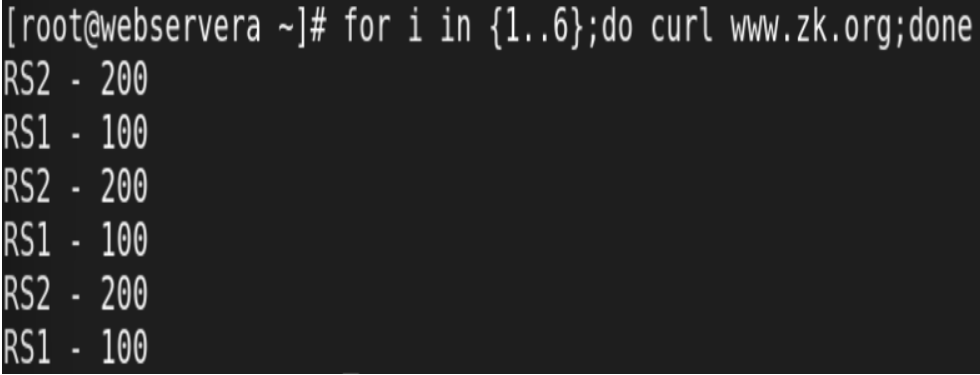
4.基于Cookie 实现会话绑定
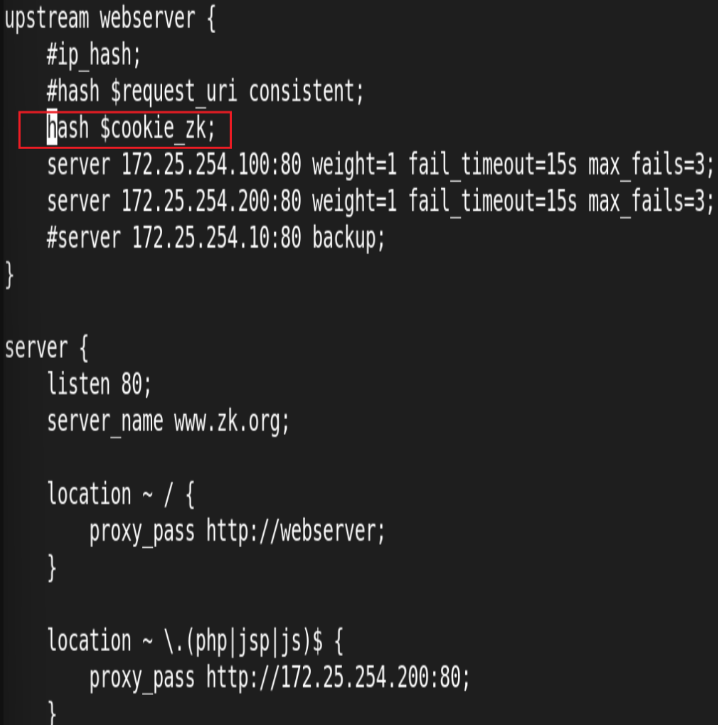
测试:
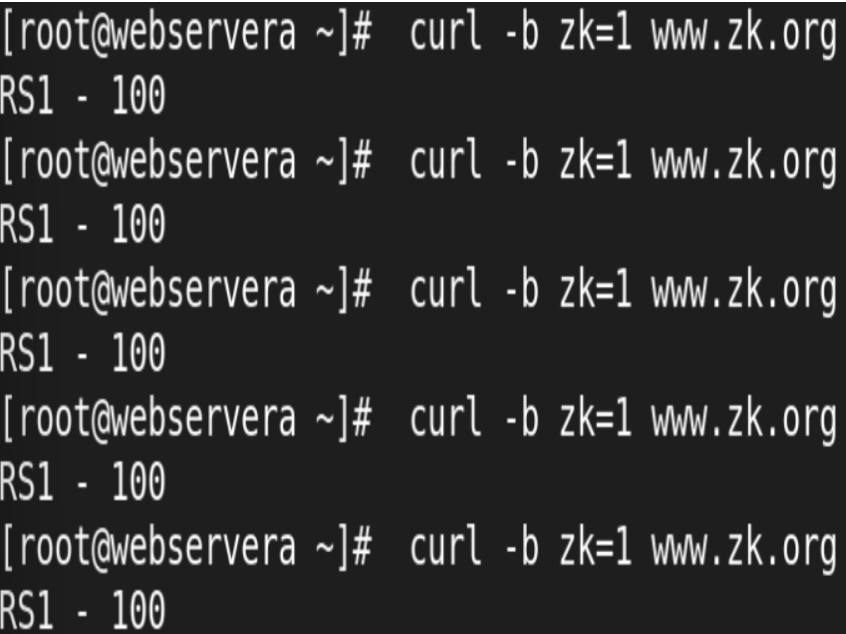
5.实现 Nginx 四层负载均衡
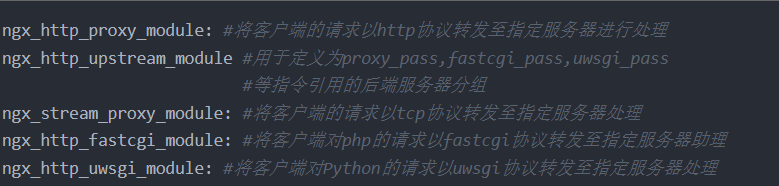
Nginx在1.9.0版本开始支持tcp模式的负载均衡,在1.9.13版本开始支持udp协议的负载,udp主要用于 DNS的域名解析,其配置方式和指令和http 代理类似,其基于ngx_stream_proxy_module模块实现tcp 负载,另外基于模块ngx_stream_upstream_module实现后端服务器分组转发、权重分配、状态监测、 调度算法等高级功能。 如果编译安装,需要指定 --with-stream 选项才能支持ngx_stream_proxy_module模块
tcp负载均衡配置参数
注意:tcp的负载均衡要位于http语句块之外

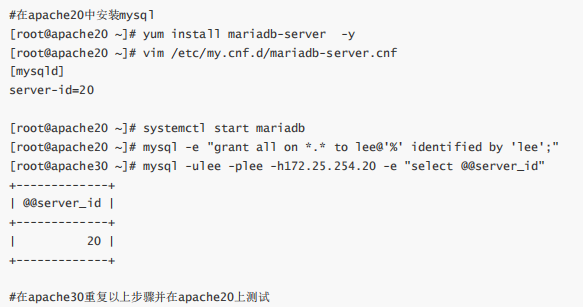
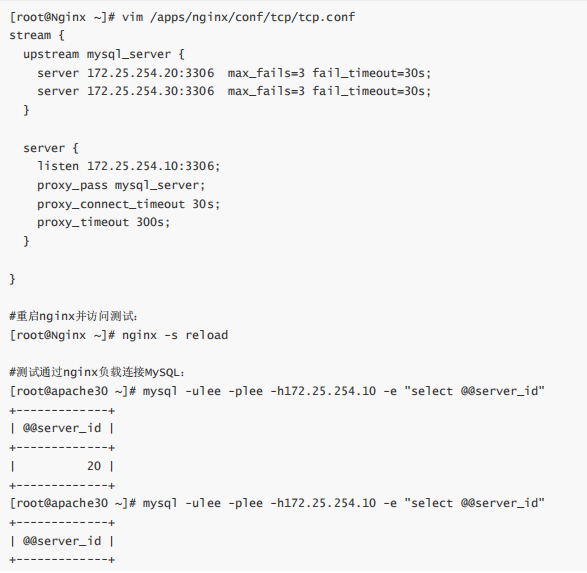
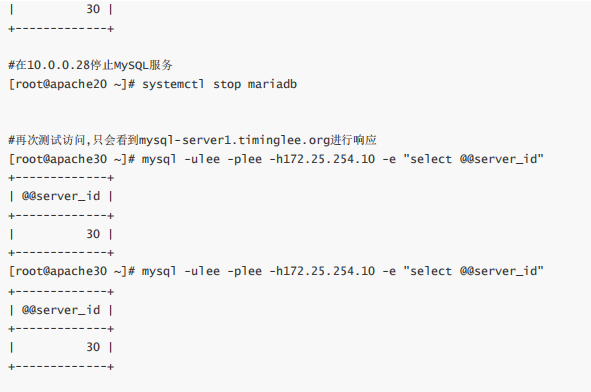
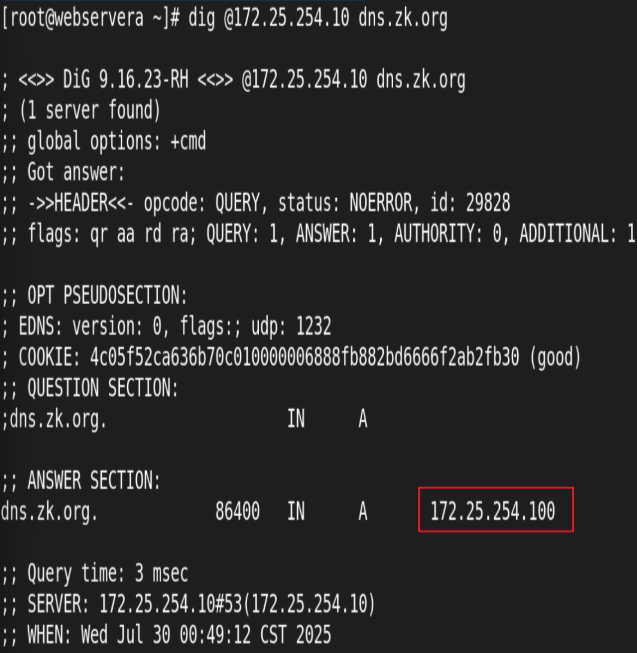
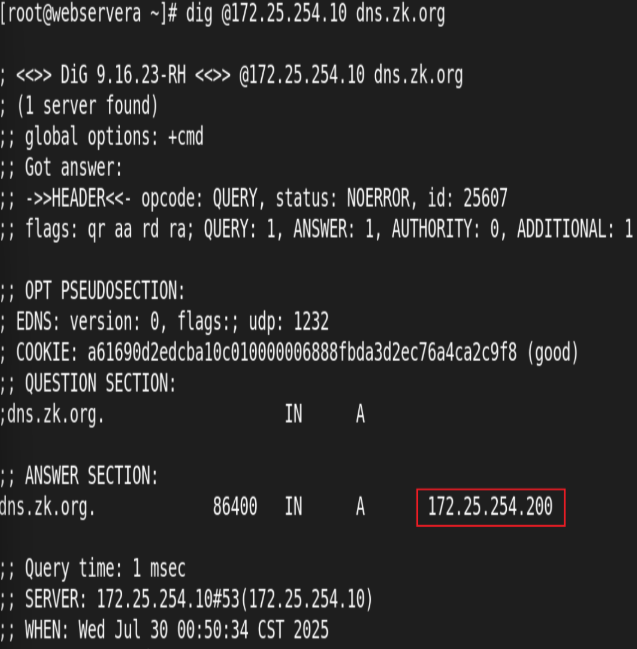
udp 负载均衡实例: DNS
两RS配置DNS:


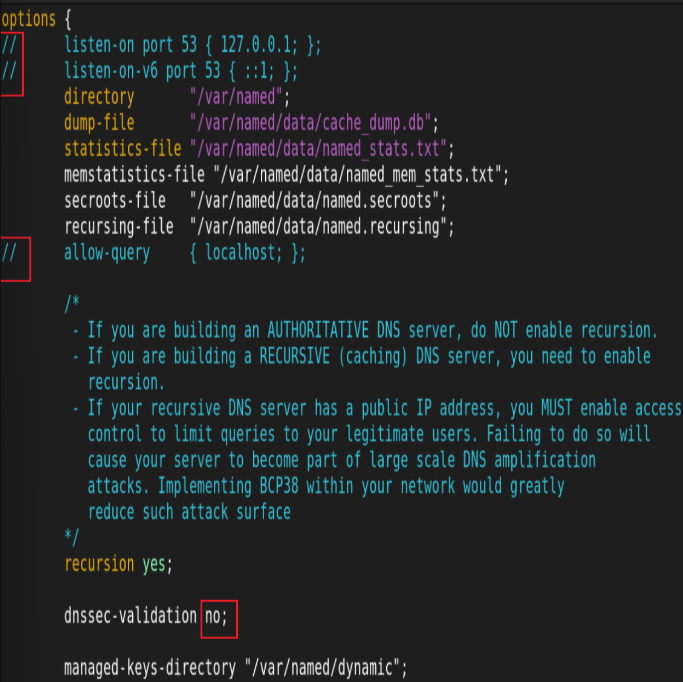

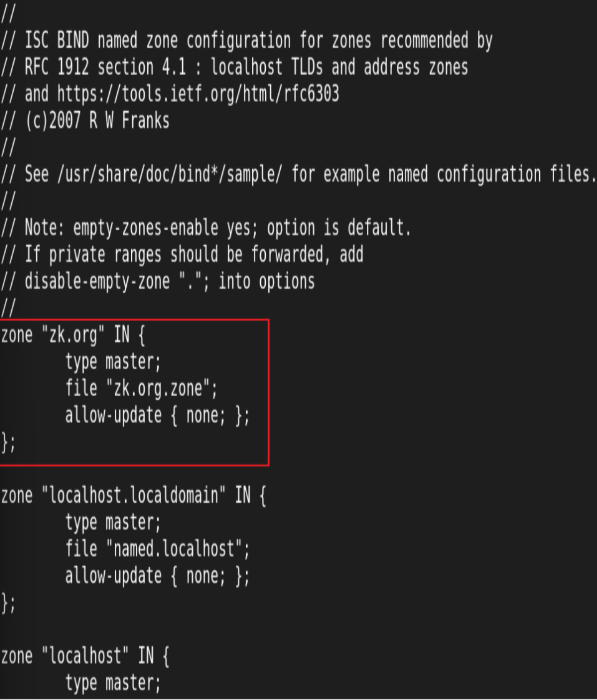

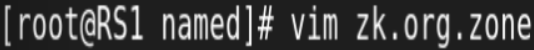
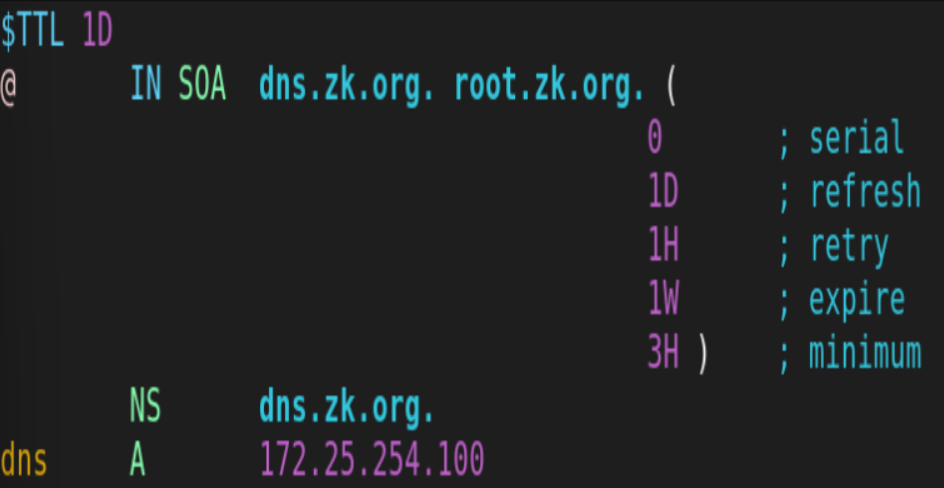
![]()
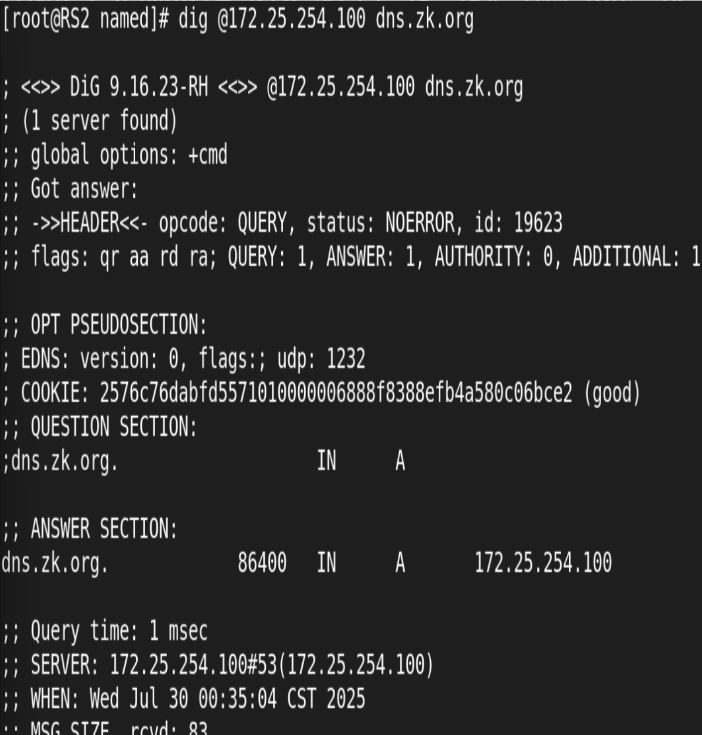
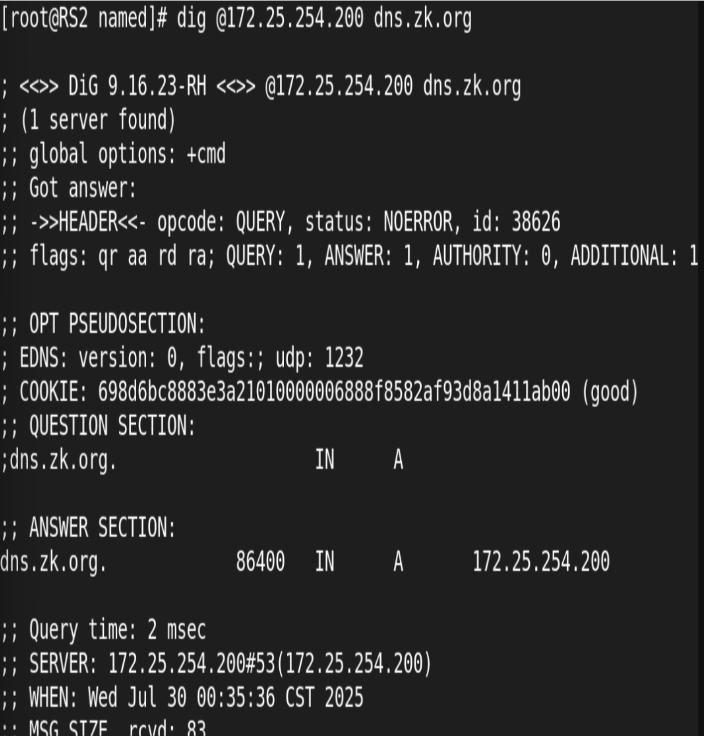
在http外指定新的子配置文件目录:

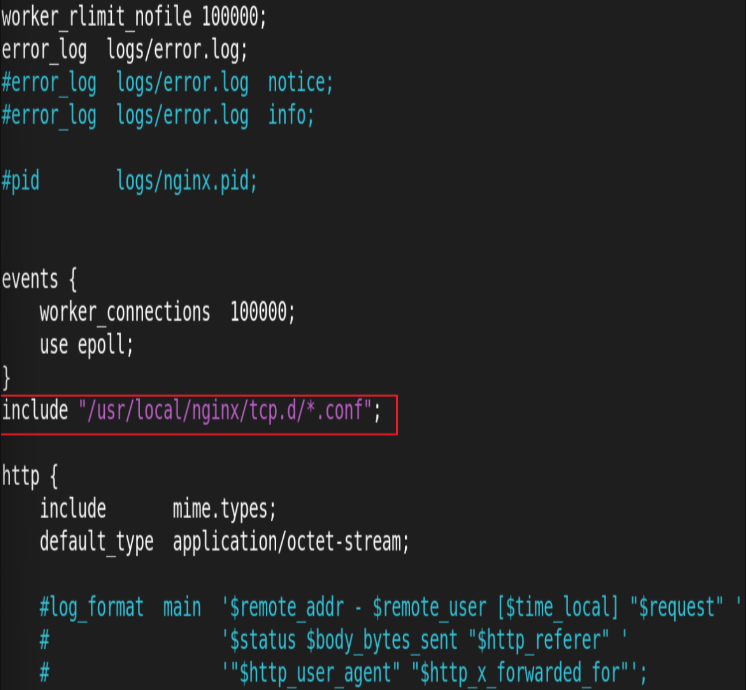
建立目录和子配置文件:

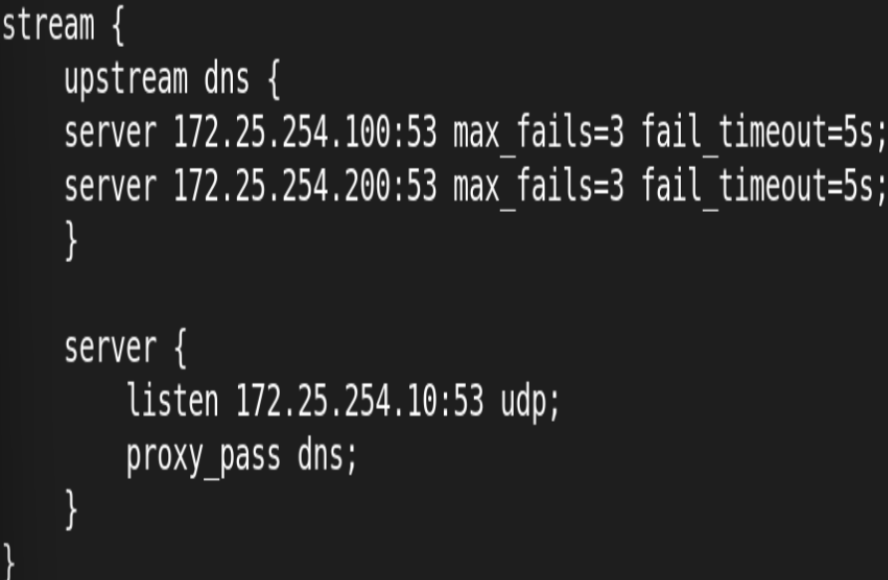
如果要53端口同时开udp和tcp的话就要多复制出条server块然后把第二个server块的udp去掉
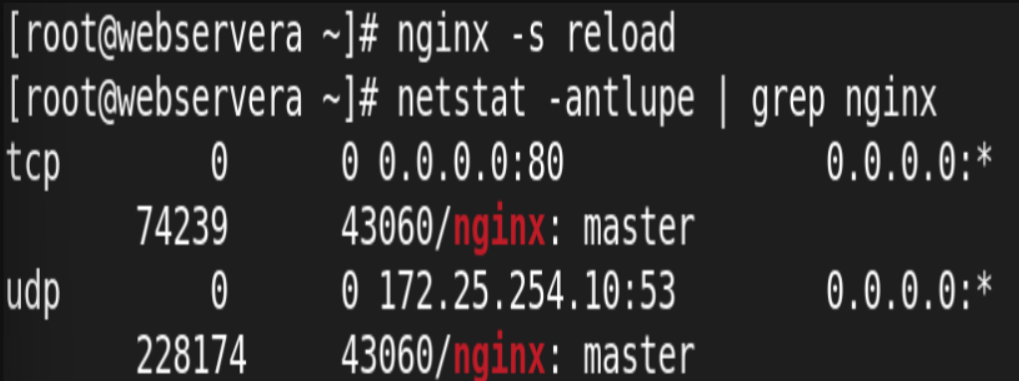
访问测试:
从前端主机成功轮询访问到100和200server
6.实现 FastCGI
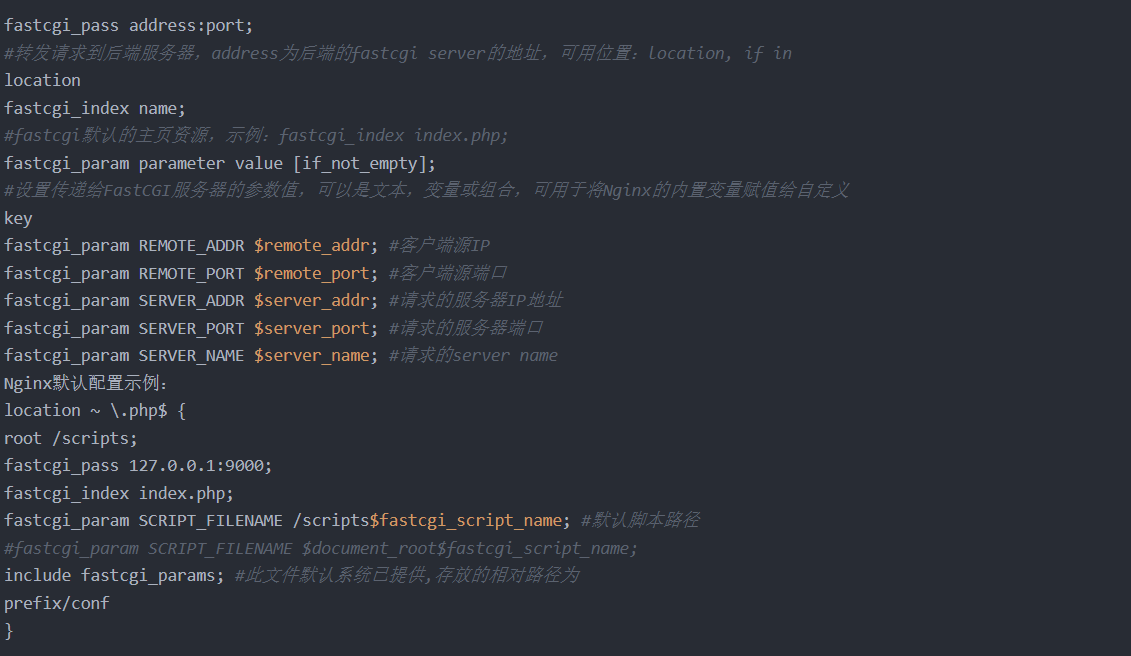
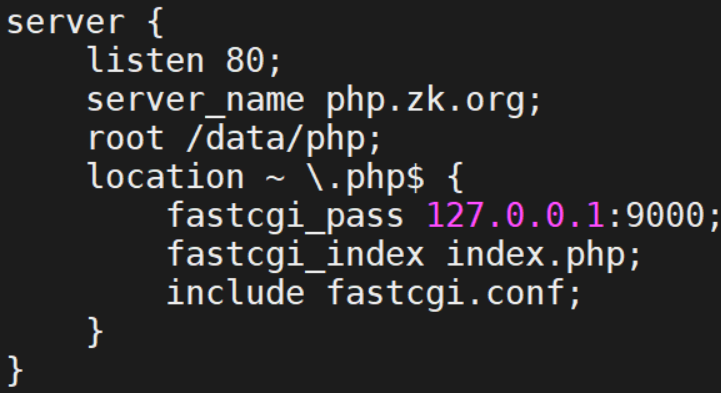
1.FastCGI配置指令
Nginx基于模块ngx_http_fastcgi_module实现通过fastcgi协议将指定的客户端请求转发至php-fpm处 理,其配置指令如下:
2.FastCGI实战案例 : Nginx与php-fpm在同一服务器
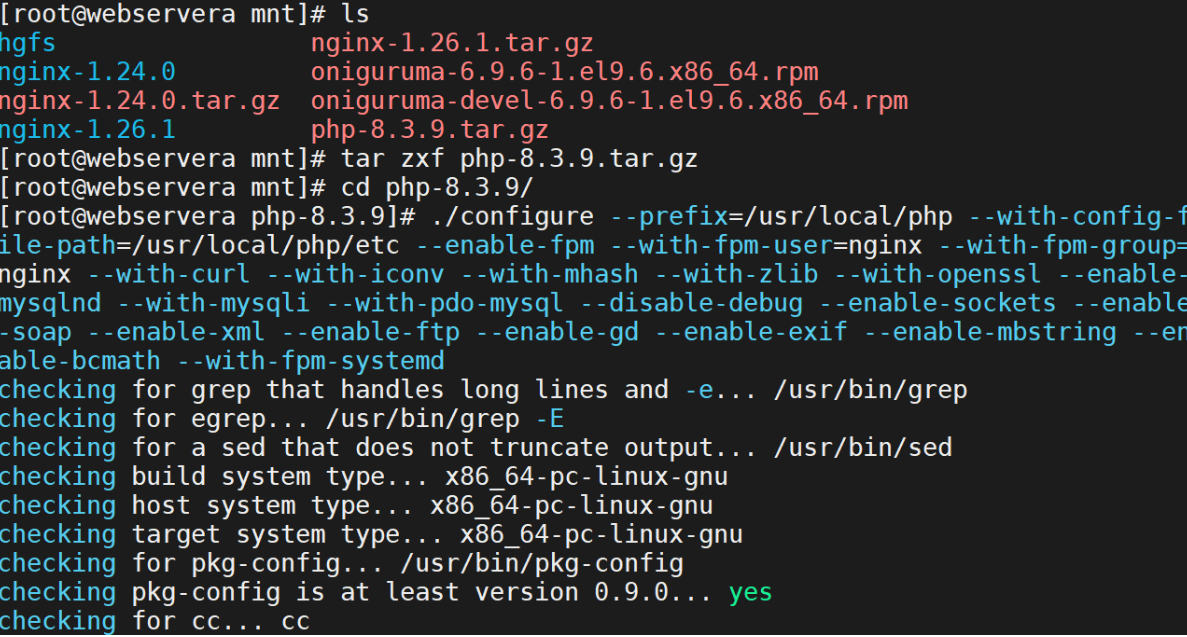
编译安装
编译安装更方便自定义参数或选项,所以推荐大家使用源码编译
解决php依赖:

如果oniguruma-devel没有则:

![]()
解压源码并安装
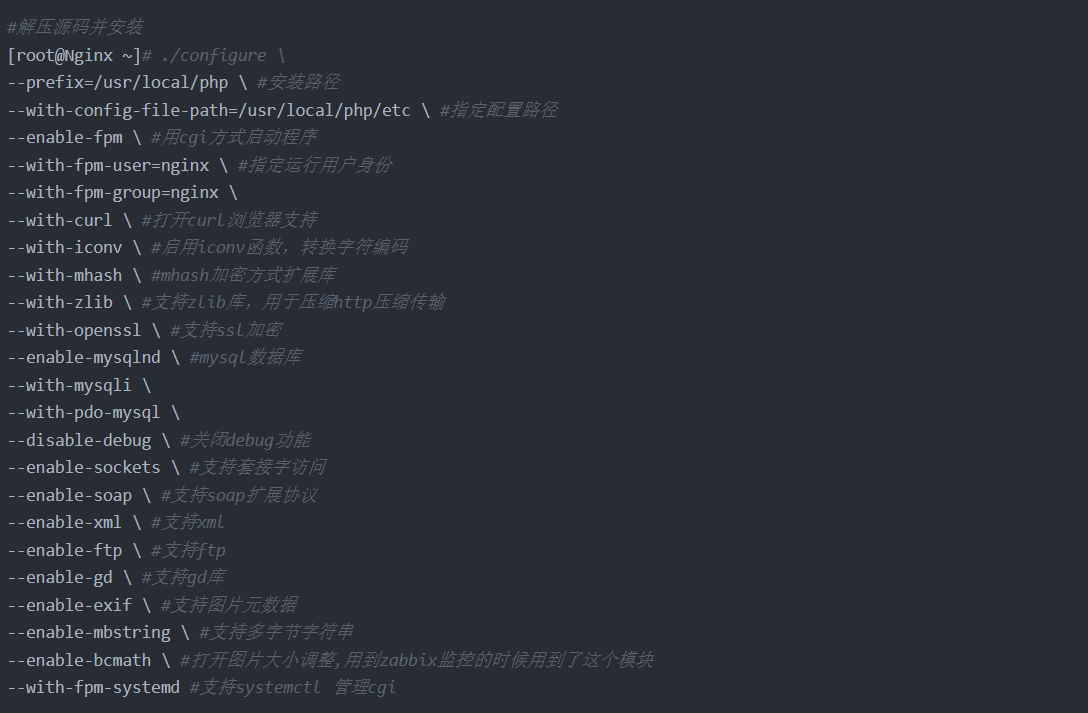

等待编译安装
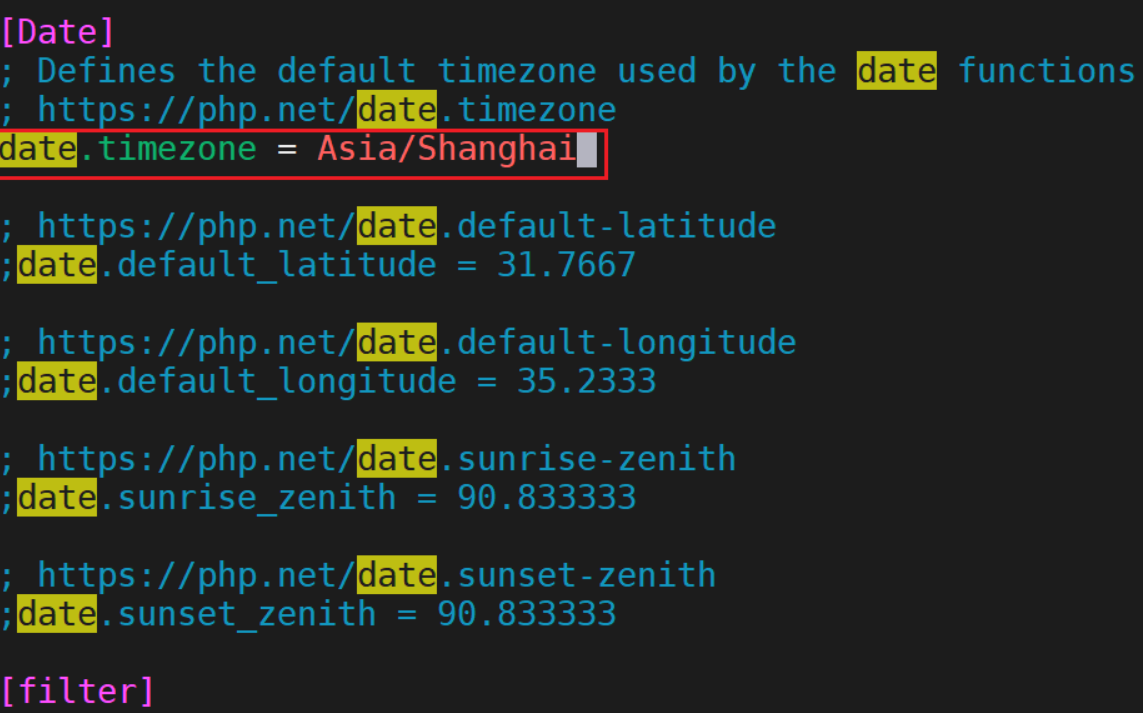
php相关配置优化

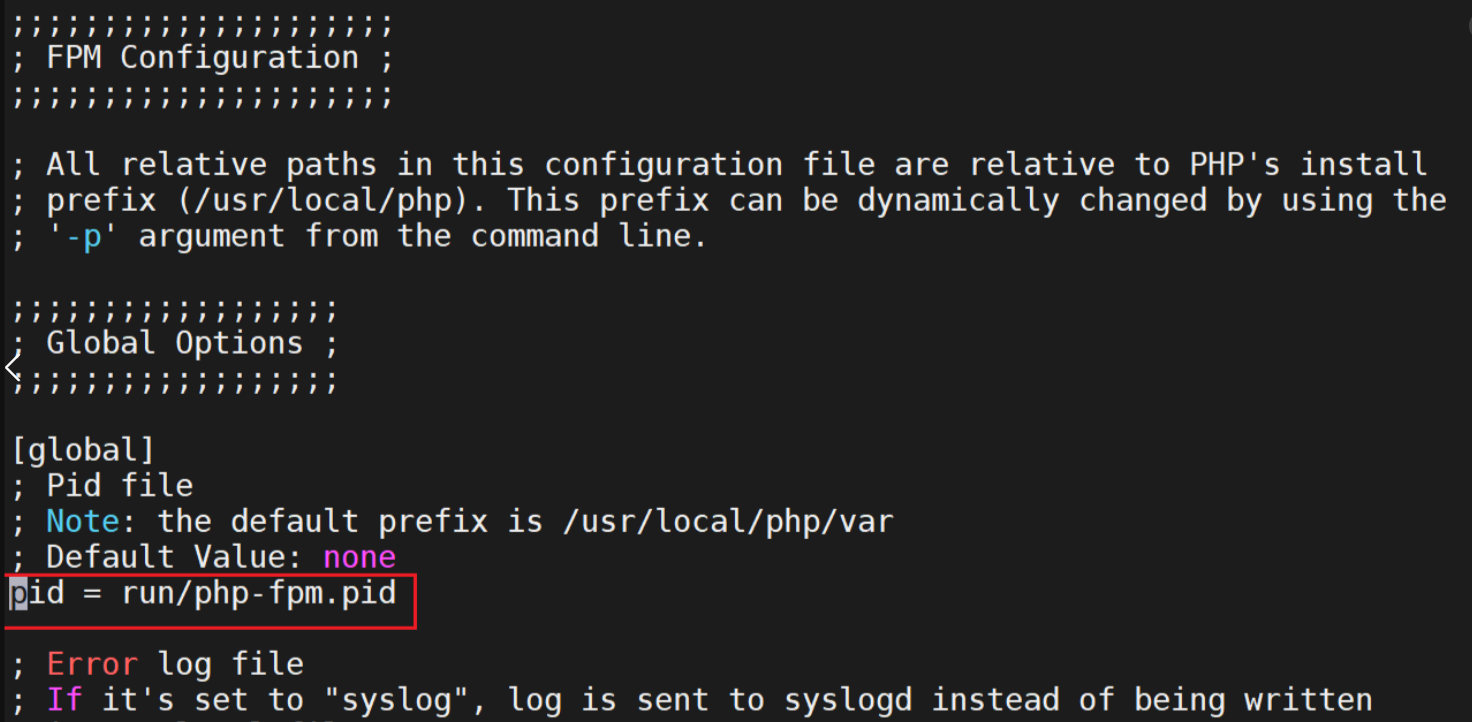

生成主配置文件:

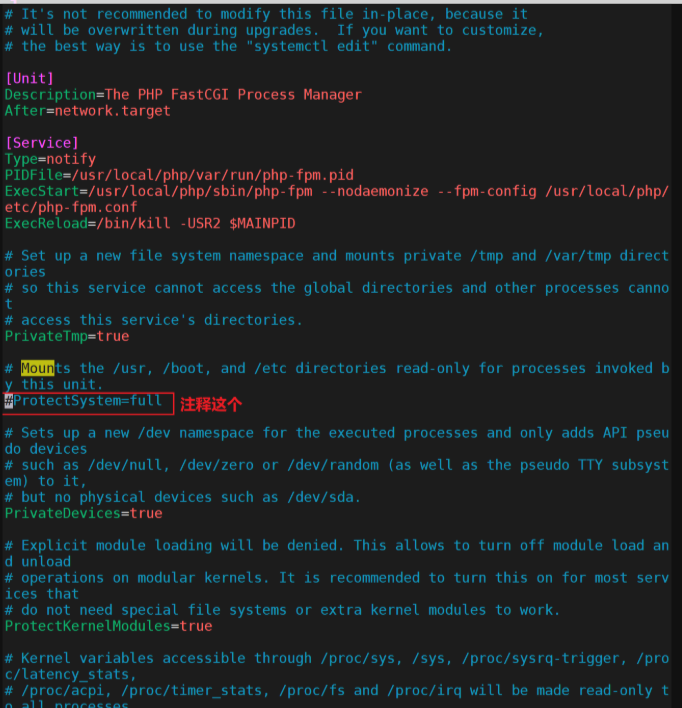
生成启动文件:

![]()

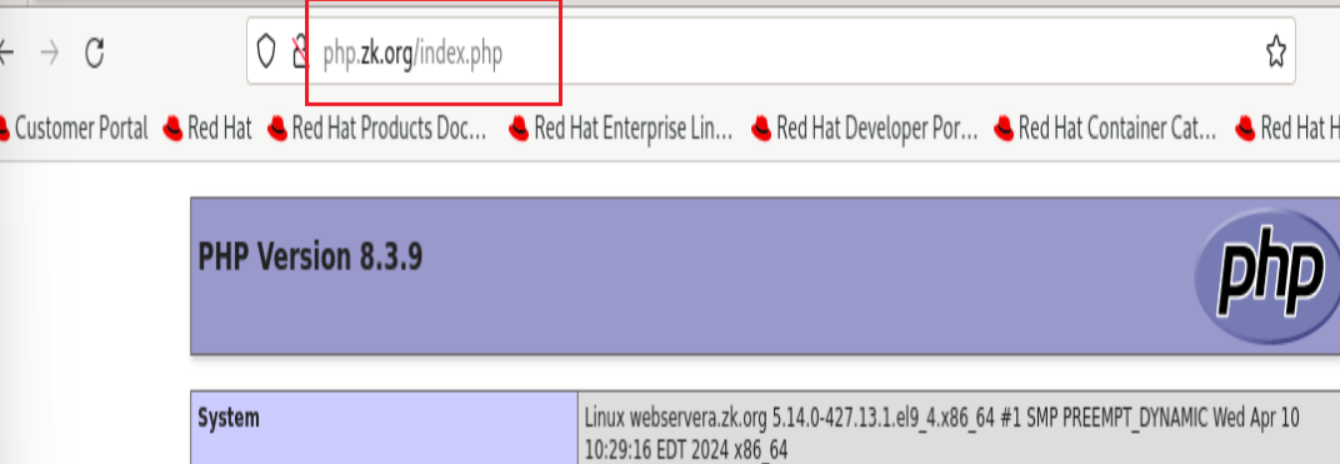
准备php测试页面

Nginx配置转发
Nginx安装完成之后默认生成了与fastcgi的相关配置文件,一般保存在nginx的安装路径的conf目录当 中,比如/apps/nginx/conf/fastcgi.conf、/apps/nginx/conf/fastcgi_params


DNS解析:

添加php环境变量:
![]()
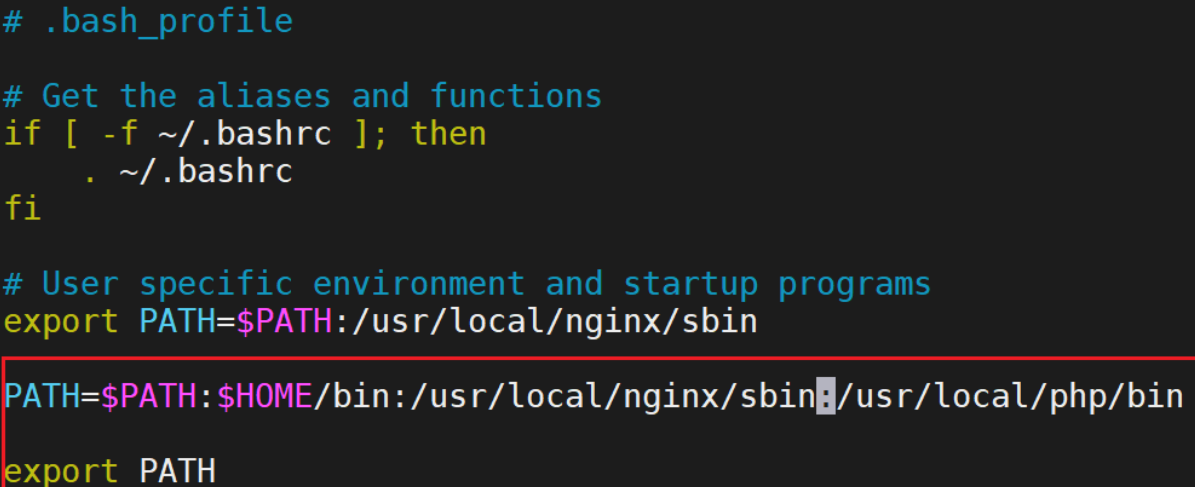
![]()
3.php的动态扩展模块(php的缓存模块)
软件下载:http://pecl.php.net/package/memcache
安装memcache模块

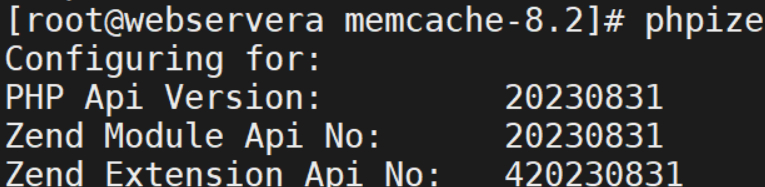
![]()

复制测试文件到nginx发布目录中
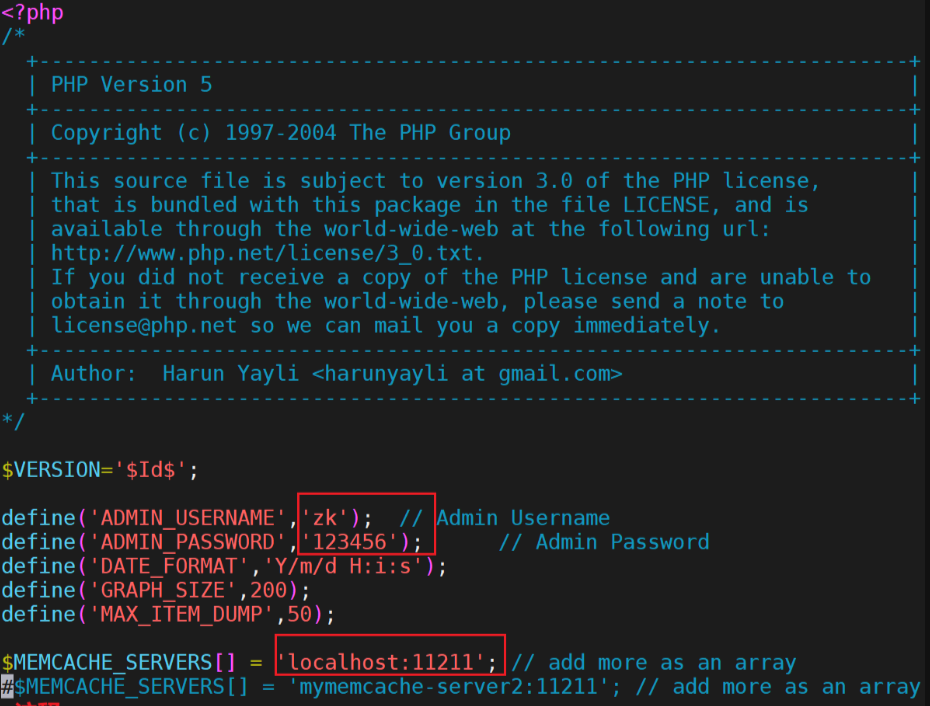
修改状态页面的登陆密码和memcache的访问接口
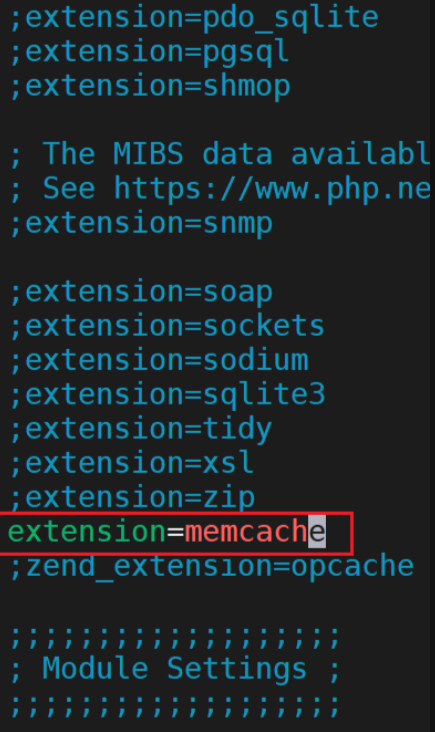
配置php加载memcache模块
![]()

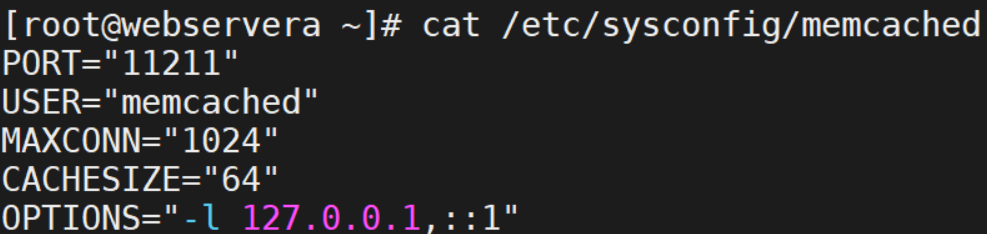
部署memcached
![]()


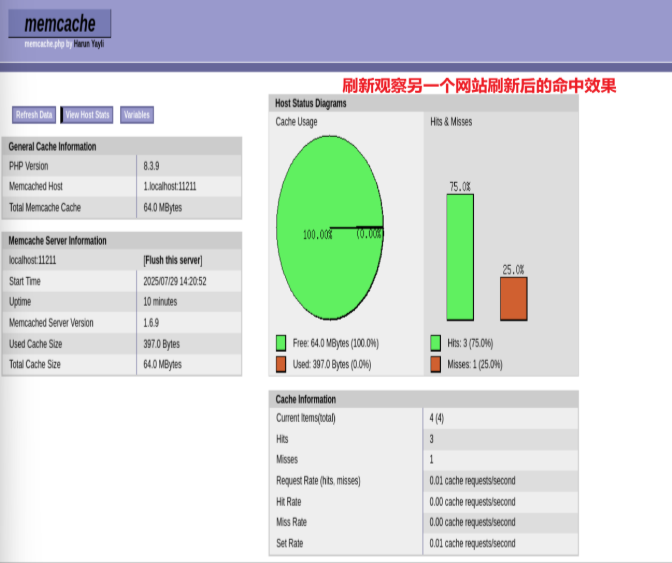
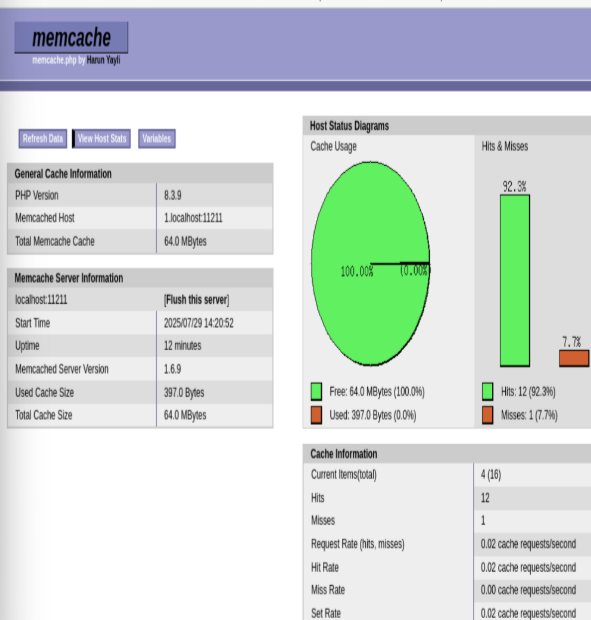
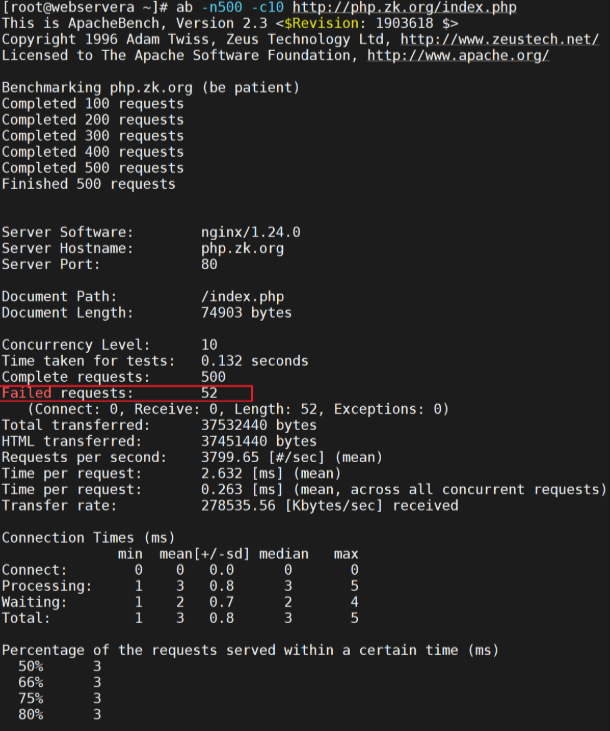
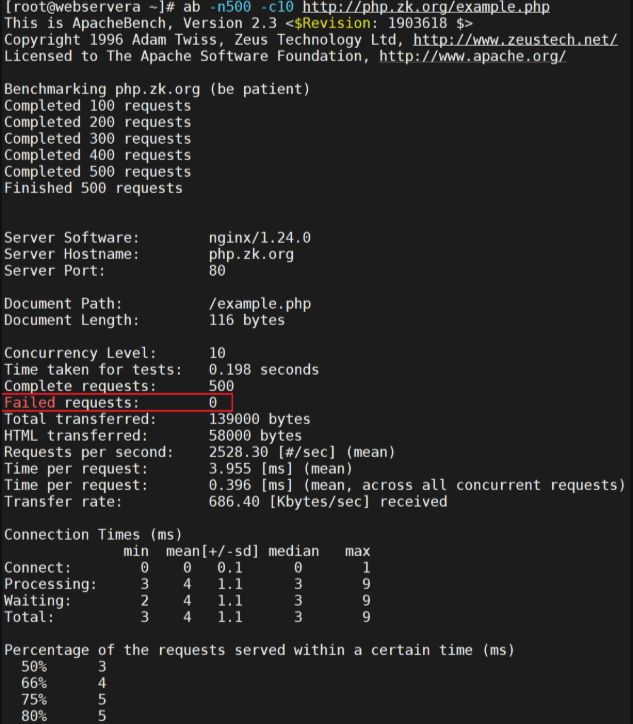
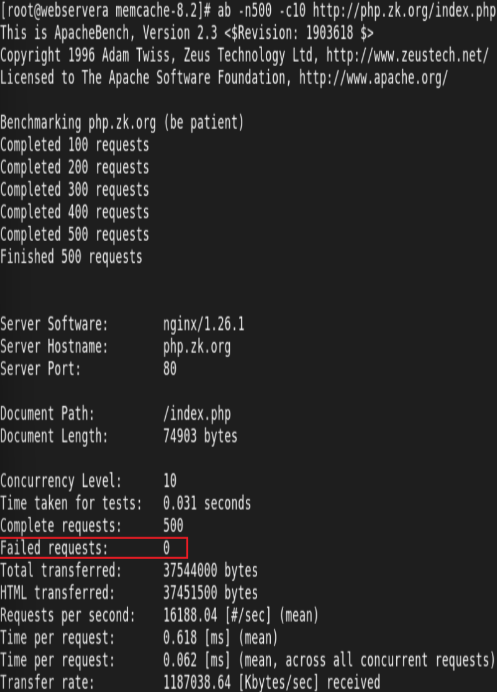
性能对比:
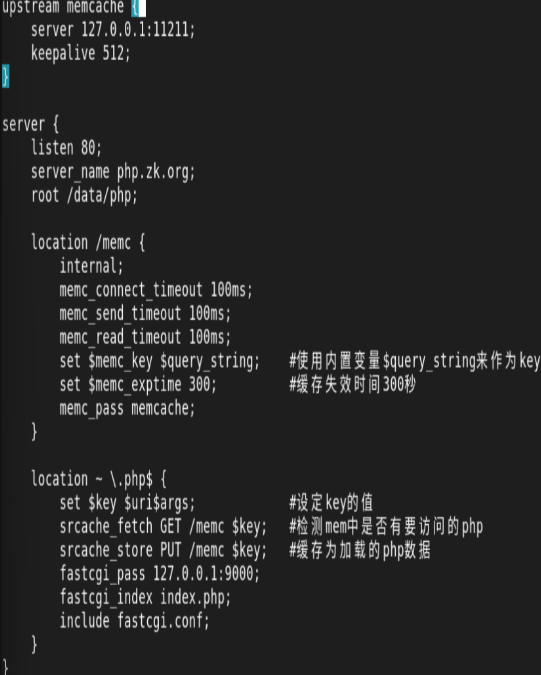
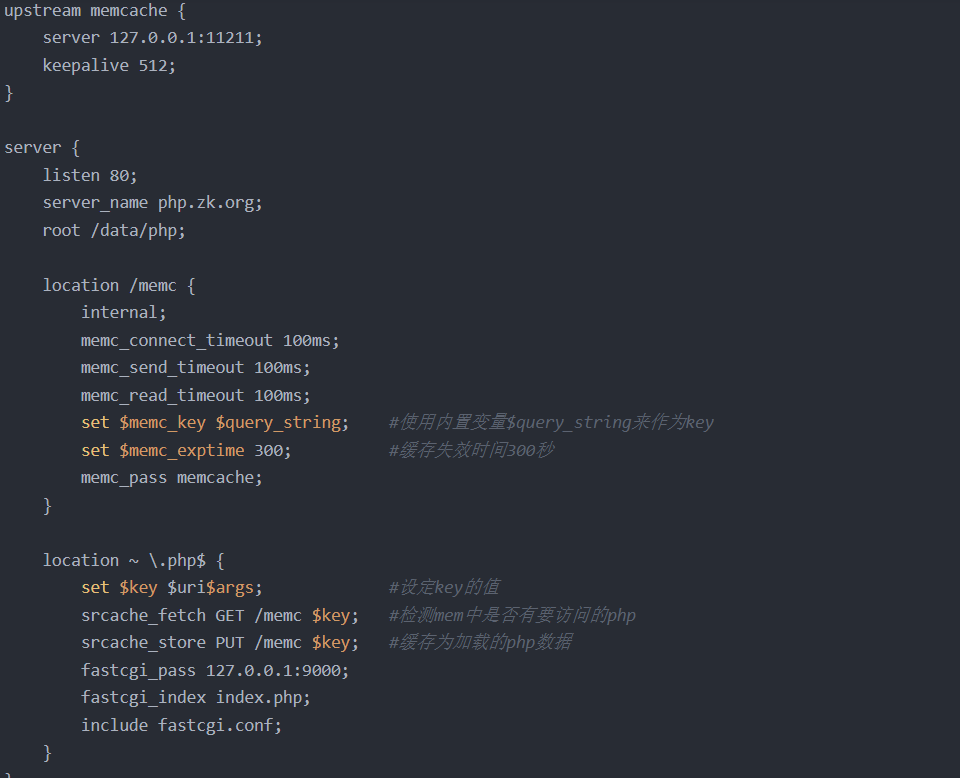
4.php高速缓存
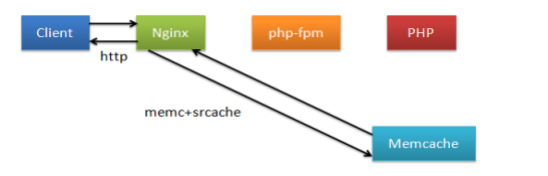
部署方法
在我们安装的nginx中默认不支持memc和srcache功能,需要借助第三方模块来让nginx支持此功能,所以nginx需要重新编译
备份配置文件:



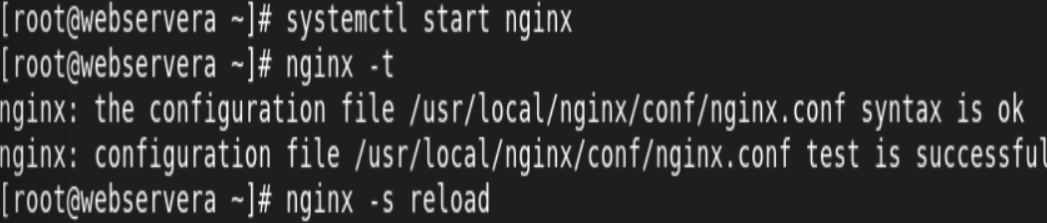
编译:

./configure --prefix=/usr/local/nginx --user=nginx --group=nginx --with-http_ssl_module --with-http_v2_module --with-http_realip_module --with-http_stub_status_module --with-http_gzip_static_module --with-pcre --with-stream --with-stream_ssl_module --with-stream_realip_module --add-module=/mnt/memc-nginx-module-0.20 --add-module=/mnt/srcache-nginx-module-0.33
编译安装:

恢复备份配置文件:
![]()
![]()

编辑配置文件:
![]()
测试压测:
七、nginx 二次开发版本
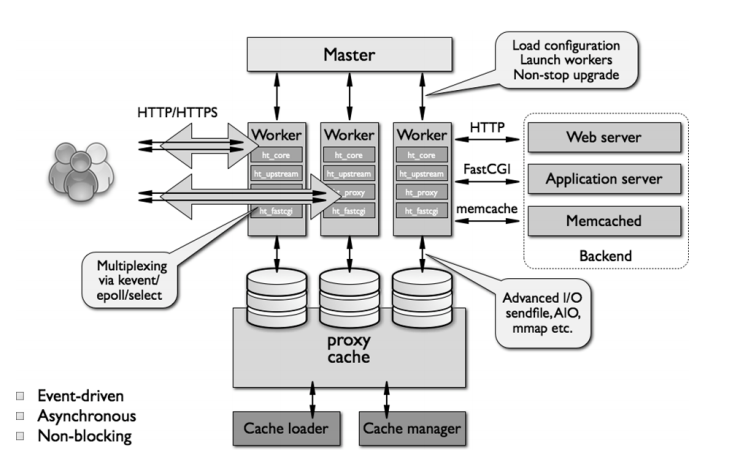
openresty
Nginx 是俄罗斯人发明的, Lua 是巴西几个教授发明的,中国人章亦春把 LuaJIT VM 嵌入到 Nginx中, 实现了OpenResty 这个高性能服务端解决方案
OpenResty® 是一个基于 Nginx 与 Lua 的高性能 Web 平台,其内部集成了大量精良的 Lua 库、第三方模块以及大多数的依赖项。用于方便地搭建能够处理超高并发、扩展性极高的动态Web 应用、Web 服 务和动态网关。
OpenResty® 通过汇聚各种设计精良的 Nginx 模块(主要由 OpenResty 团队自主开发),从而将Nginx 有效地变成一个强大的通用 Web 应用平台。这样,Web 开发人员和系统工程师可以使用 Lua 脚本语言调动 Nginx 支持的各种 C 以及 Lua 模块,快速构造出足以胜任 10K 乃至 1000K 以上单机并发连接的高性能 Web 应用系统。
OpenResty 由于有功能强大且方便的的API,可扩展性更强,如果需要实现定制功能,OpenResty是个不错的选择
官网: http://openresty.org/cn/
编译安装 openresty:
因为openresty与nginx冲突,所以编译安装 openresty前要把nginx卸载:


![]()



./configure --prefix=/usr/local/openresty --user=nginx --group=nginx --with-http_ssl_module --with-http_v2_module --with-http_realip_module --with-http_stub_status_module --with-http_gzip_static_module --with-pcre --with-stream --with-stream_ssl_module --with-stream_realip_module
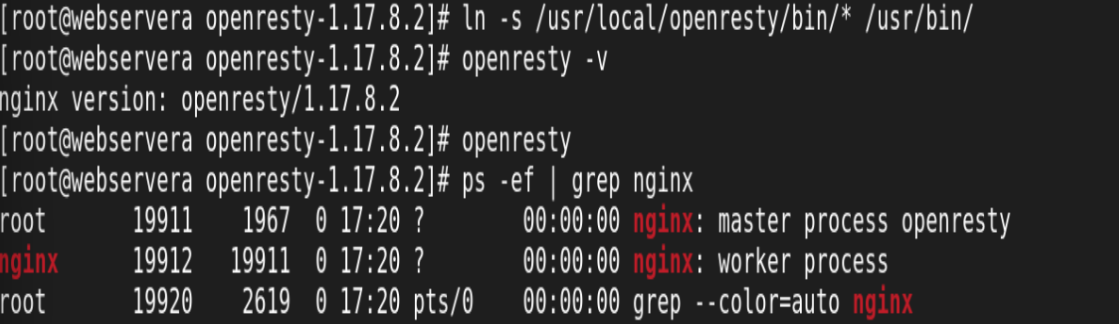
![]()
启动: