【李宏毅-2024】第六讲 大语言模型的训练过程1——预训练(Pre-training)
目录
- 概述
- 1. 预训练(Pre-training)
- 2. 微调(Fine-tuning,又称 SFT,Supervised Fine-Tuning)
- 3. 对齐(Alignment,又称 RLHF 或 DPO 等)
- 4 三阶段对比
- 6 第一阶段——自我学习,积累实力
- 6.1 大模型本质上是文字接龙
- 1. 从字符到 token 的拆分过程
- 2. 为什么要用 token 而非字符或单词?
- 3. 关键指标:token 与成本
- 6.2 机器怎么学会做文字接龙
- 1. 语言模型的核心任务
- 2. 数学形式
- 3. 训练目标
- 4. 训练与测试过程
- 5. 三阶段的本质任务
- 6.3 寻找参数面临的挑战
- 1. **参数优化与超参数选择**
- 2. **训练失败与应对**
- 3. **过拟合(Overfitting)**
- 4. 训练过程的核心原则
- 6.4 如何让机器找到比较合理的参数
- 1 增加训练数据的多样性
- 2 设置更合理的初始参数
- 3 引入先验知识
- 6.5 需要多少文字才能学会“文字接龙”?
- 1语言知识(Linguistic Knowledge)的学习
- 2 世界知识(World Knowledge)
- 3 世界知识的多层次性
- 6.6 任何文本皆可用来学“文字接龙”
- 1. **从互联网抓取海量文本**
- 2. **自监督学习(Self-supervised Learning)**
- 3. **大规模数据获取与训练优势**
- 6.7 数据的精炼与完善:数据清理的必要性与操作细节
- 1. 数据清理的必要性
- 2. 六大清理步骤
- 6.8 所有文本资料都能拿来训练“文字接龙”吗?
- 1 是否任何资料都能用于训练?
- 2 版权纠纷与法律风险
- 3 开发团队的常见做法
- 4 授权与合规建议
- 6.9 再训更大的模型也没用:为什么语言模型仍无法好好回答问题?
- 1. 学习方式决定了“只会接龙”
- 2. 缺乏明确的目标引导
- 3. 无效的自问自答模式
- 4. 大模型预训练的困境与解决思路
课程地址 B站 本文参考笔记
概述
大模型的训练通常被概括为 “预训练 → 微调 → 对齐” 三个递进的阶段,每个阶段的目标、数据、算法和产出都有明显差异。下面按时间顺序逐一说明:
1. 预训练(Pre-training)
目标:让模型学会“通用的语言和世界知识”,具备强大的表征与生成能力。
数据:大规模、多领域、多语言的原始文本(如网页、书籍、论文、代码等),数据量通常从几 TB 到数百 TB。
算法:自监督学习(最常见的是下一个 token 预测或 masked token 预测)。
算力:千卡级 GPU/TPU,持续数周到数月。
产出:基座模型(Base model),如 GPT-3、Llama-2、Baichuan-Base。
特点:
- 无人工标注,仅依靠海量文本的自监督信号。
- 模型规模大(数十亿到上万亿参数),训练成本高。
- 具备广泛的知识和语言能力,但没有指令遵循能力,也不保证输出安全、有用。
2. 微调(Fine-tuning,又称 SFT,Supervised Fine-Tuning)
目标:让基座模型学会遵循指令、完成具体任务(问答、摘要、翻译、代码补全等)。
数据:数十万到上百万条 (指令, 输入, 期望输出) 的高质量人工标注数据。
算法:继续用监督学习训练,通常只训练 1–3 个 epoch,学习率较小。
算力:相比预训练下降 2–3 个数量级(几十张卡、几天到一周)。
产出:指令微调模型(Instruct model),如 GPT-3.5-Turbo、Llama-2-Chat、ChatGLM-6B-SFT。
特点:
- 输出风格更贴近人类对话,能执行“请翻译成英文”“写一段 Python 代码”等指令。
- 仍可能输出有害、偏见或事实错误的内容,需要进一步约束。
3. 对齐(Alignment,又称 RLHF 或 DPO 等)
目标:让模型的价值观、安全性、有用性与人类期望“对齐”。
数据:
- 偏好数据(Preference data):人工对同一 prompt 的多个回答进行排序。
- 有时再辅以红队对抗样本、安全准则、宪法原则等。
算法: - 经典路线:RLHF(Reinforcement Learning from Human Feedback,用 PPO 强化学习)。
- 新路线:直接偏好优化(DPO、KTO、RRHF 等),无需显式强化学习。
算力:与微调同一量级,但流程更复杂(需训练奖励模型、做 RL 或偏好优化)。
产出:对话/助手模型(Chat/Assistant model),如 GPT-4、Claude-3、Kimi-Chat。
特点: - 显著降低有害、歧视、幻觉输出,提升帮助性与可操控性。
- 使模型学会说“我不知道”“我无法协助此类请求”等安全表达。
4 三阶段对比
| 阶段 | 训练信号 | 数据规模 | 主要能力获得 | 典型代表 |
|---|---|---|---|---|
| 预训练 | 自监督 | TB 级原始文本 | 通用语言、世界知识 | Llama-2-Base |
| 微调 | 监督学习 | 105–106 条指令 | 遵循指令、任务完成 | Llama-2-Chat-SFT |
| 对齐 | 人类反馈/偏好 | 104–105 条排序 | 安全、有用、符合价值观 | GPT-4, Claude-3 |
这三个阶段并非绝对割裂:
- 一些模型把“微调+对齐”合并为单阶段(如指令微调中直接混入安全数据)。
- 社区出现“继续预训练 → 轻量微调 → 在线对齐”的迭代式开发管线,以持续改进模型。
上面的三个阶段对应到课程中分别是第六节(自我学习,积累实力)、第七节(名师指点,发挥潜力)、第八节(参与实战,打磨技巧)

6 第一阶段——自我学习,积累实力
6.1 大模型本质上是文字接龙
大模型本质上是文字接龙:当生成答案时,模型通过逐步预测和生成单个符号(称为Token),依序构建完整的输出。
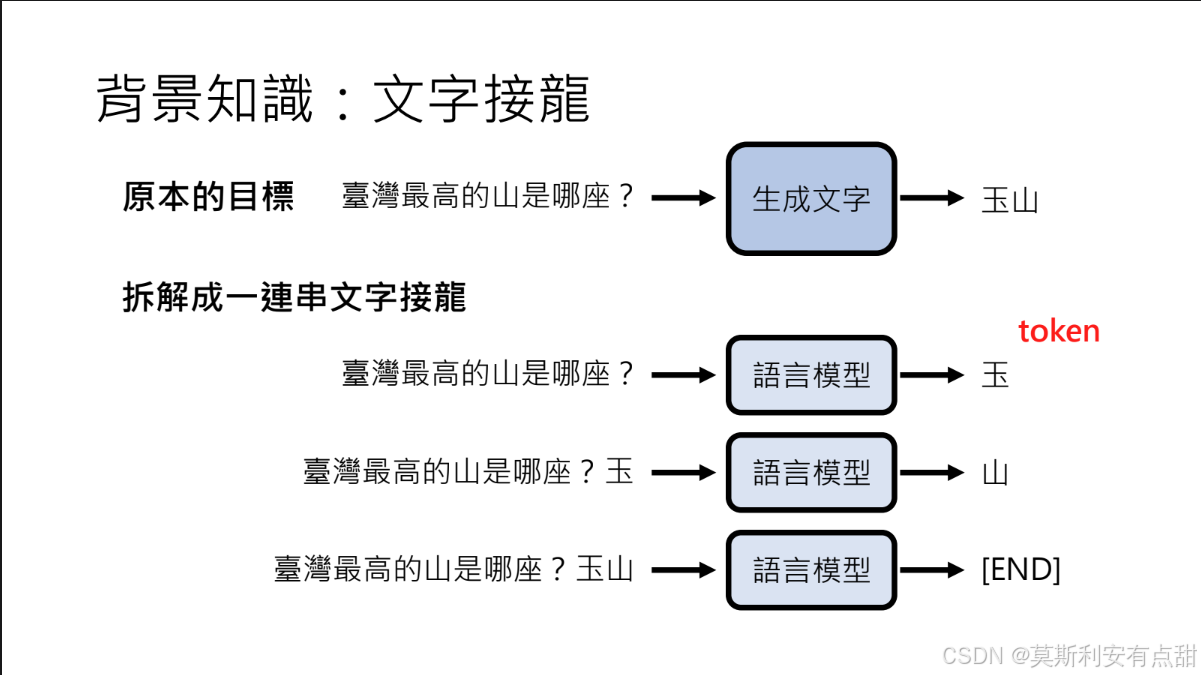
在大模型的语境里,Token 是“文本”被离散化后的最小处理单元;模型既不认识字母,也不直接操作汉字,而是先把所有字符序列拆成一串 token,再进行训练和推理。 可以简单理解为,Token 是模型眼里“语言的字母表”中的单个符号。
可以把文本想象成乐高积木:
- 字符是小颗粒,拼起来太碎;
- 单词是大模块,种类太多;
- token 是官方设计的“标准砖块”,既通用又高效,大模型只认这种砖块。
1. 从字符到 token 的拆分过程
以 OpenAI 的 GPT 系列为例,使用 BPE(Byte Pair Encoding) 子词分词器:
- 英文字母:
"ChatGPT"→["Chat", "G", "PT"](3 个 token) - 中文:
"大模型"→["大", "模型"](2 个 token) - 带标点:
"你好,世界!"→["你好", ",", "世界", "!"](4 个 token) - 极端情况:
一个罕见 emoji🤯可能被拆成多个 byte-level token,也可能独占一个 token,取决于词表是否收录。
2. 为什么要用 token 而非字符或单词?
- 压缩文本长度:高频子词(如 “ing”、“的”、“模型”)用一个 token 表示,减少序列长度。
- 跨语言兼容:同一套词表可同时覆盖 100+ 语言,无需为每种语言单独设计分词器。
- 平衡粒度:比“字符”粗,比“整词”细,避免词表爆炸,又能处理未登录词。
3. 关键指标:token 与成本
- 上下文长度以 token 计数:GPT-4 Turbo 支持 128k tokens ≈ 10 万英文单词。
- 计费单位:OpenAI、Anthropic 等按 “每 1k tokens” 收费,输入与输出分别计价。
- 经验换算:
- 1 个英文单词 ≈ 1.3 tokens
- 1 个汉字 ≈ 1.8–2.2 tokens(取决于文本密度)
6.2 机器怎么学会做文字接龙
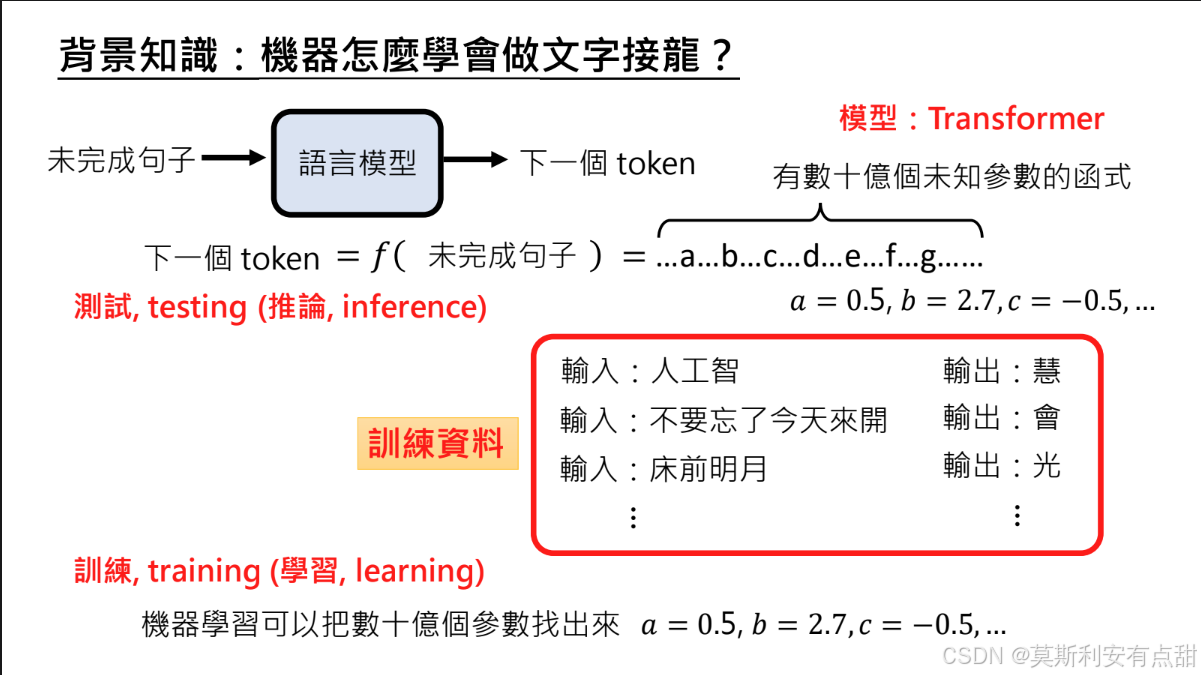
1. 语言模型的核心任务
文字接龙:输入一个未完成的句子 → 输出最可能的下一个 token。
2. 数学形式
模型是一个含 数十亿参数 的 Transformer 函数 f:next_token = f(unfinished_sentence)
3. 训练目标
用海量「句子-下一 token」样本,通过优化算法确定所有参数,使预测误差最小。
4. 训练与测试过程
训练(Training)
• 数据来源:大规模文本,形式为「未完成的句子 → 下一个正确 token」。
• 目标:通过优化算法(如 Adam、SGD)迭代更新数十亿参数,最小化预测误差。
测试 / 推断(Testing / Inference)
• 使用已训练完成的固定参数模型。
• 输入任意文本前缀,模型即时输出最可能的后续 token,参数不再更新。
5. 三阶段的本质任务
无论预训练、微调还是对齐,模型始终在学习「文字接龙」。
阶段差异仅体现在训练数据:
• 阶段 1:通用语料 → 建立广泛语言知识与常识。
• 阶段 2:高质量指令-回答对 → 获得任务理解与指令遵循能力。
• 阶段 3:人类偏好或安全准则数据 → 实现价值观对齐与输出可控。

6.3 寻找参数面临的挑战
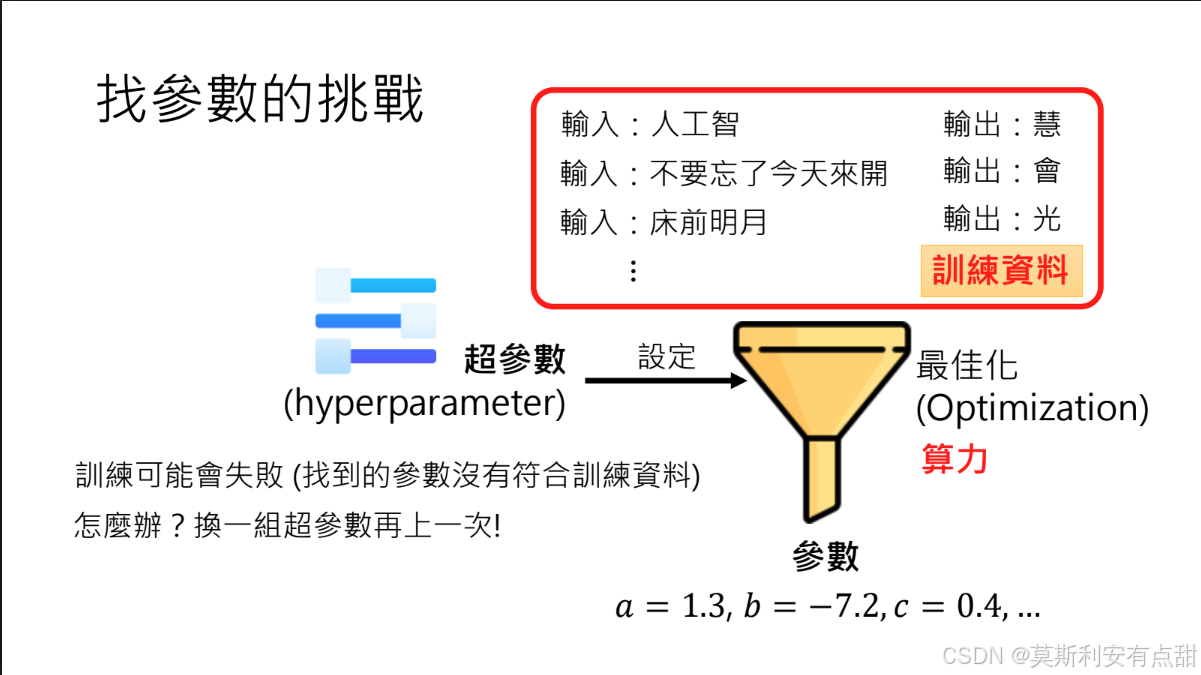
1. 参数优化与超参数选择
- 优化(Optimization):利用机器学习方法自动调整数十亿个模型参数,使模型输出尽可能贴合训练数据。
- 超参数(Hyperparameters):决定“如何优化”的人工设定值,如学习率、优化器类型、批大小等。它们不在训练中被更新,却对结果影响巨大。
- 难点:超参数空间庞大且效果难以预估;训练失败时只能通过反复试错重新设定,耗费大量算力。
2. 训练失败与应对
- 表现:模型在训练集上无法收敛或误差居高不下。
- 根因:超参数设置不当、数据质量差或模型结构设计缺陷。
- 解决:系统性地调整超参数(俗称“调参”),并重启训练。
3. 过拟合(Overfitting)
- 定义:模型在训练集表现优异,但在未见过的新数据(测试集)上表现显著下降。
- 成因:模型过度记忆训练数据中的噪声或局部特征,缺乏泛化能力。
- 示例:猫狗分类器仅依据“黄色=狗,黑色=猫”的颜色特征进行判断,遇到黄色猫时即误判为狗。
过拟合相关课程: 為什麼類神經網路可以正確分辨寶可夢和數碼寶貝呢?
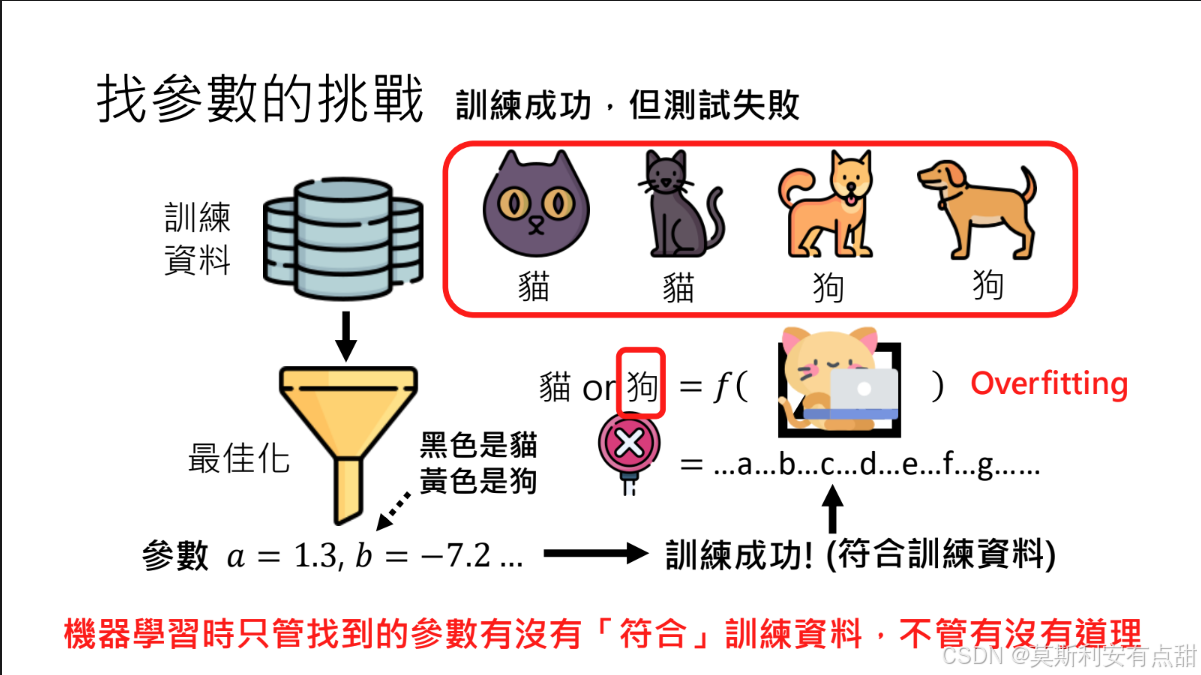
4. 训练过程的核心原则
- 机器只认训练数据:算法唯一目标是最小化训练集上的误差,不会主动评估参数是否合理或能否泛化至其他场景。
- 勿以人智度机心:模型不具备人类的因果推理与常识判断,其“知识”边界完全由给定数据决定。
6.4 如何让机器找到比较合理的参数
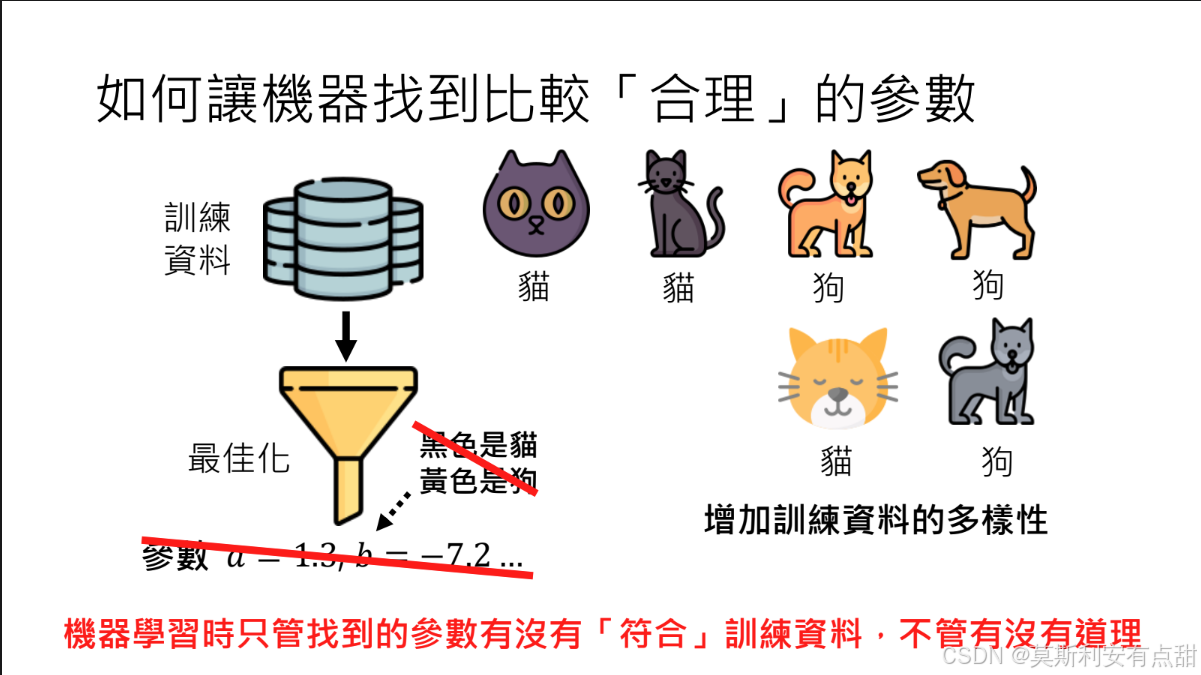
1 增加训练数据的多样性
问题:如果数据分布过于单一,模型易学到虚假或片面特征(如仅凭颜色区分猫狗)。
解决:在猫狗分类任务中补充黄猫、黑狗等反例,迫使模型学习形状、纹理等更本质的特征。
作用:多样化数据削弱虚假关联,提升模型泛化能力,使优化得到的参数更具鲁棒性。
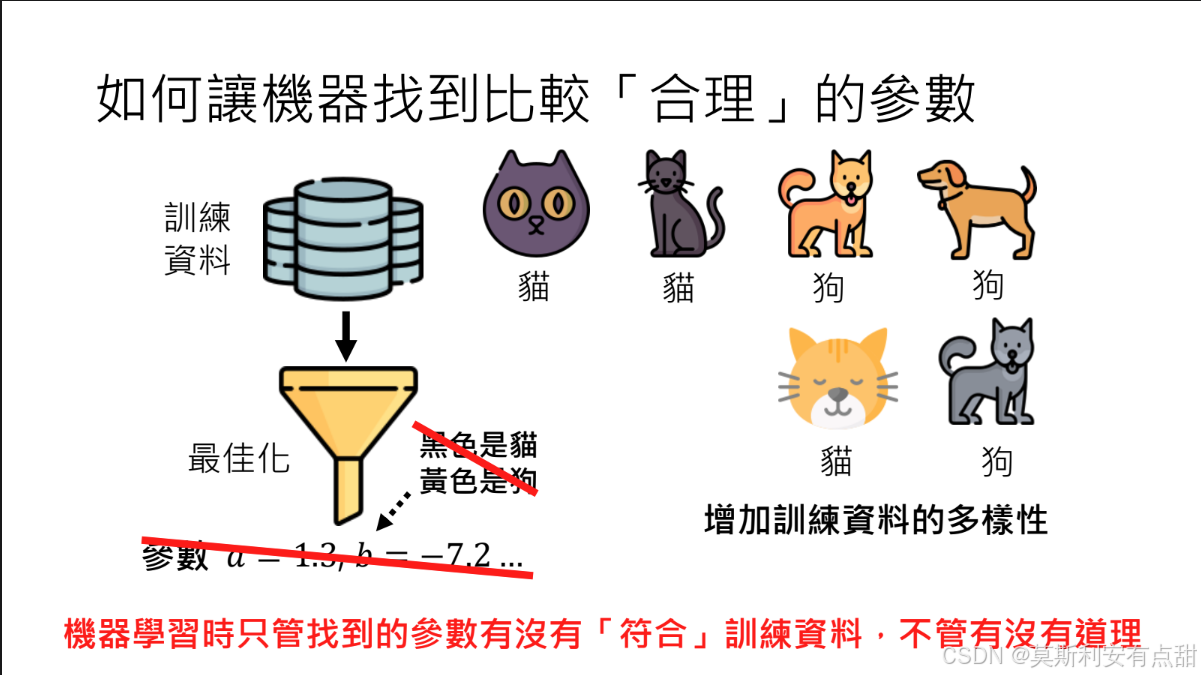
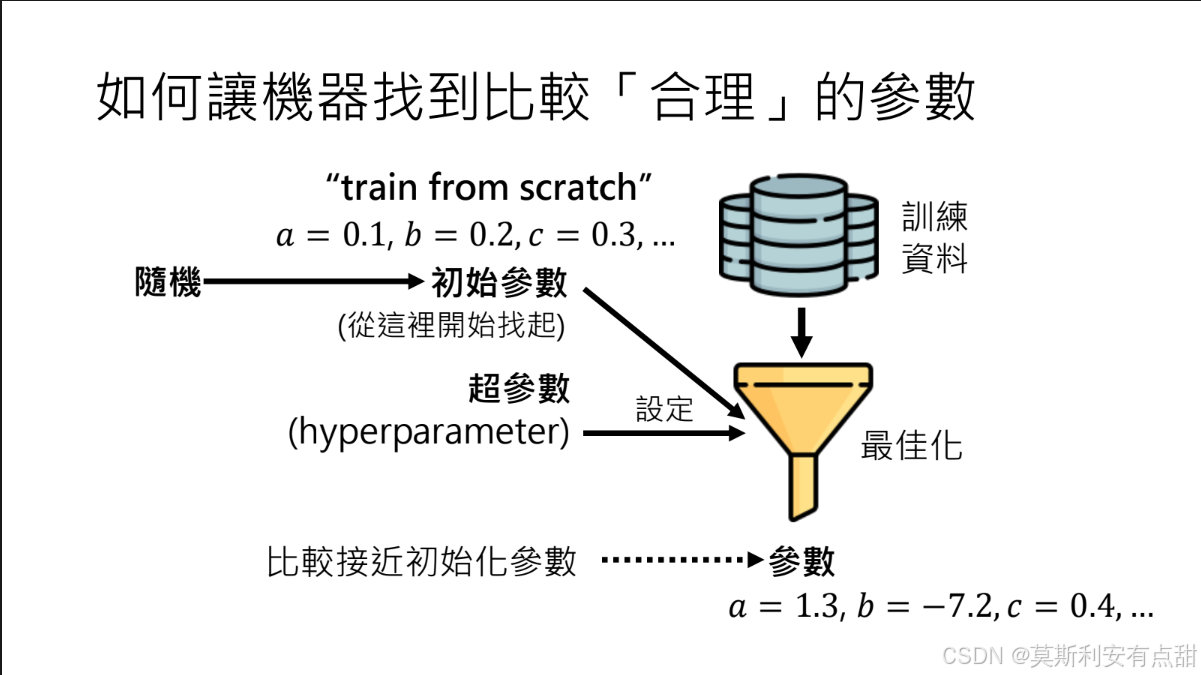
2 设置更合理的初始参数
• 定义:优化算法的起点。最终解通常与初始点在同一“盆地”,因此起点决定搜索效率与结果质量。
• 常见做法
– 随机初始化(Train from Scratch):按特定分布随机生成参数,简单但可能陷入局部最优或训练不稳定。
– 优化初始化:利用预训练、迁移学习或元学习获得接近目标解的初始参数,显著加快收敛并提升性能。
3 引入先验知识
• 概念:通过精心设计的初始参数或约束,将人类知识或经验“植入”模型,指导优化方向。
• 意义:
– 初始参数即“先天知识”,可减少盲目搜索。
– 在数据有限或任务复杂的场景下,先验知识能有效提升最终参数质量。
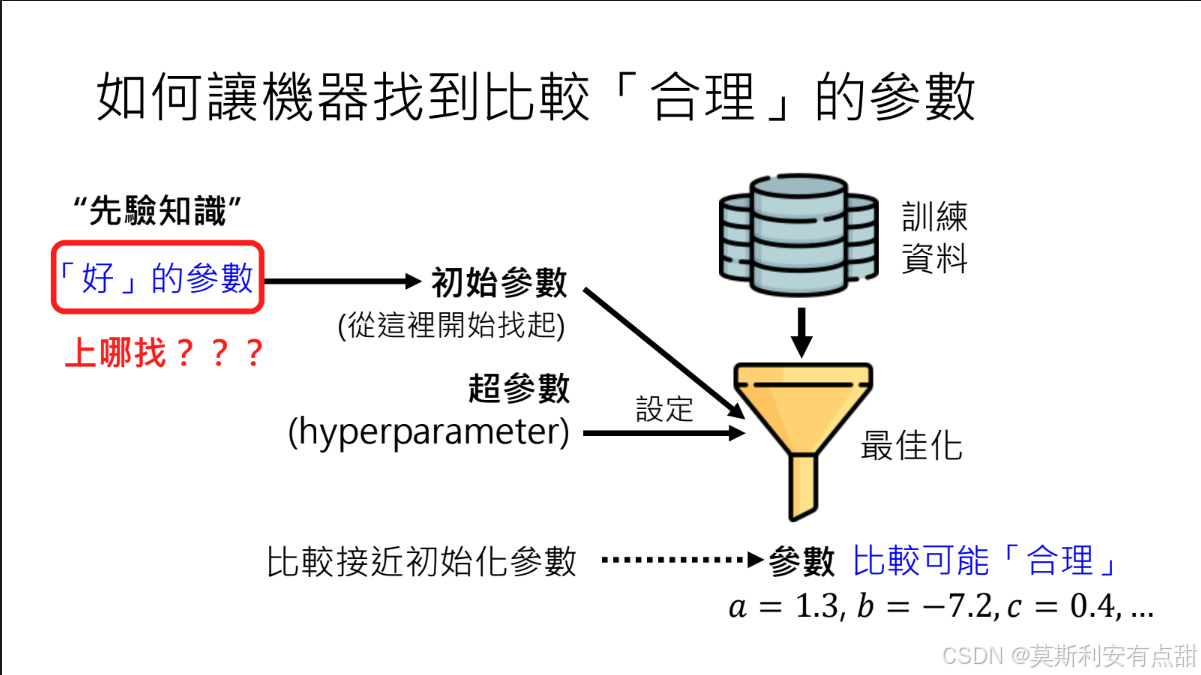
挑战:如何构造高质量的初始参数仍是机器学习研究的核心难题之一,涉及预训练策略、跨任务迁移、元学习等技术。
6.5 需要多少文字才能学会“文字接龙”?
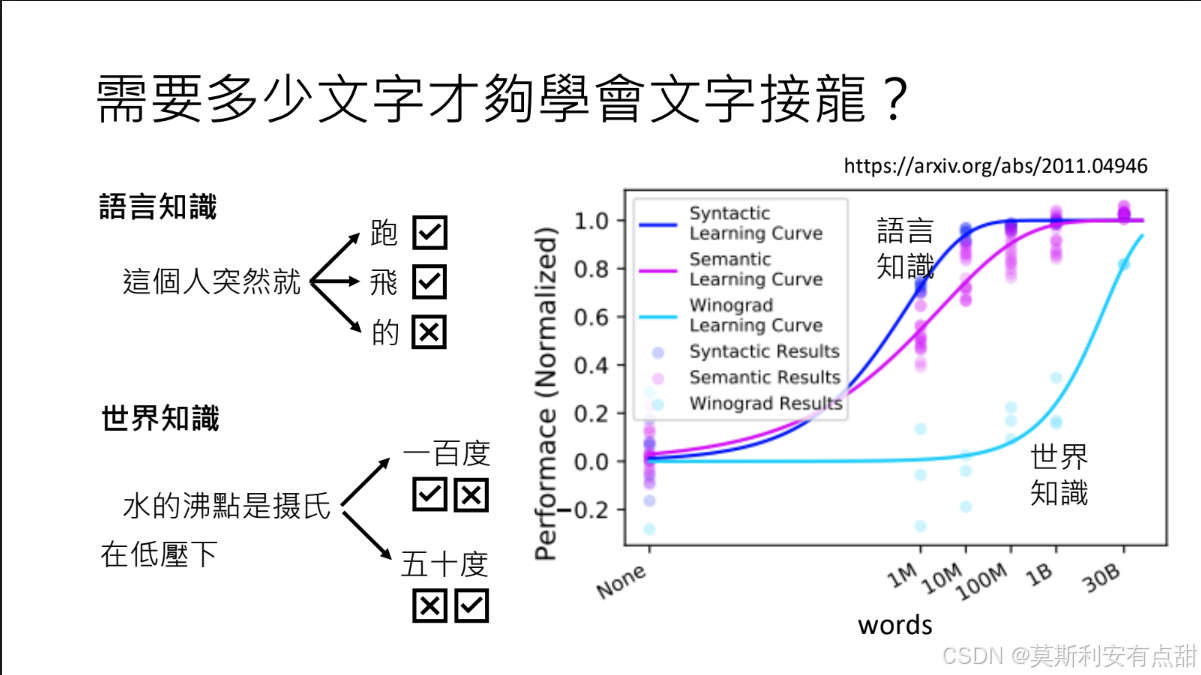
1语言知识(Linguistic Knowledge)的学习
- 任务:要学会“文字接龙”,语言模型需要掌握语言的文法规则,才能理解句子的结构,并作出符合文法的词汇选择。
- 所需数据量:相对有限。研究指出,几千万~几亿词即可让模型掌握基础的语法、词法与句法规则,从而生成符合语言习惯的序列。
2 世界知识(World Knowledge)
- 任务:除了语言知识,语言模型还需要学习世界知识,以理解事实、常识与语境,例如“水的沸点是 100 °C(1 atm)”。
- 数据需求:远超语言知识。
- 量级:即使训练语料达到 300 亿词,仍难以覆盖全部世界知识。
- 原因:
- 事实本身浩如烟海;
- 同一事实在不同上下文(海拔、气压、文化背景)中答案可变;
- 知识呈层次化——从简单事实到深层因果、跨领域关联,均需大量多样化文本才能逐步捕捉。
3 世界知识的多层次性
- 复杂性示例
- 表层:水的沸点为 100 °C(标准大气压)。
- 深层:在高海拔地区气压降低,沸点下降;在高压锅中,沸点升高。
- 数据要求
- 必须包含大规模、多场景、多语言的描述,才能让模型逐渐习得这些条件依赖与因果层次。
- 因此,世界知识的获取是“数据饥饿型”任务:语料越大、越多元,模型掌握得越全面,但仍无法穷尽。
【精炼与完善后的文本】
6.6 任何文本皆可用来学“文字接龙”
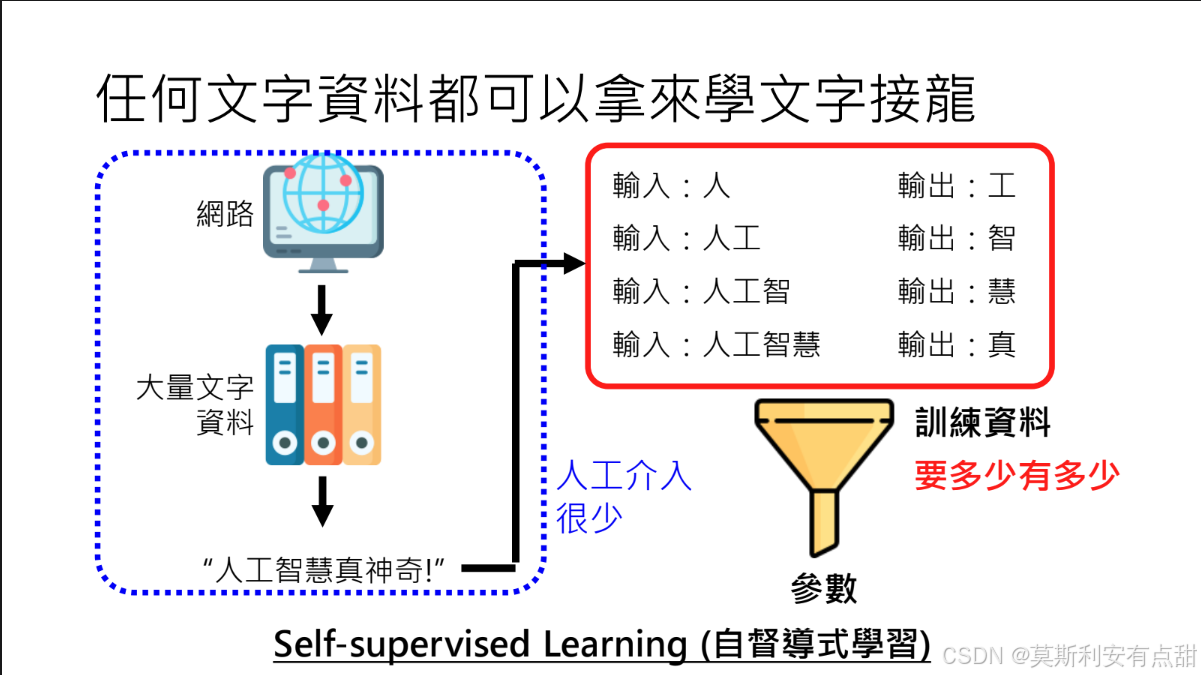
1. 从互联网抓取海量文本
• 网络本身即是一座取之不尽的“语料矿山”。
• 技术路径:网络爬虫 → 清洗去噪 → 按句子或滑动窗口切分 → 构造“上文 → 下一 token”配对。
• 示例:将句子“人工智慧真神奇”拆为
人工 → 智 人工智 → 慧 人工智慧 → 真 ……
即可直接用于自监督训练。
2. 自监督学习(Self-supervised Learning)
• 定义:无需人工标注,模型利用文本自身的顺序结构作为监督信号。
• 流程:
① 自动把连续文本拆成“上文”与“待预测 token”;
② 通过最大化似然,让模型学会在给定前文时输出概率最高的下一词。
• 特点:人力成本低,可扩展至万亿级 token,适合大模型预训练。
3. 大规模数据获取与训练优势
• 数据规模:只要存储与算力允许,爬虫可源源不断提供多语言、多领域文本。
• 训练优势:
– 零人工标注,降低数据准备成本;
– 语料多样性与规模直接决定模型语言能力与泛化上限;
– 同一套流程可复制到任何新语料,持续更新模型知识。
6.7 数据的精炼与完善:数据清理的必要性与操作细节
1. 数据清理的必要性
网络爬取的原始语料虽然规模庞大,但直接用于训练会引入噪声、偏见甚至有害信息。DeepMind 的研究指出:
“未经清洗的数据会显著降低模型质量、安全性和泛化能力。”
因此,自监督学习仍需系统的人工干预与自动化清理流程。
2. 六大清理步骤
① 有害内容过滤
- 使用关键词、分类器或人工审核剔除色情、暴力、仇恨、违法等不当文本。
- 建立动态黑名单,定期更新敏感词库与规则。
② 去除无用符号
- 剥离 HTML 标签、脚本、导航栏、页眉页脚、LaTeX 残留等格式标记。
- 正则 + DOM 解析器组合,保证正文完整性。
③ 保留有效符号
- 保留表情符号(😊、👍)、数学符号(π、∑)、特殊标点(“”、《》),因其可能携带语义或情感信息。
- 建立白名单,避免误删。
④ 数据质量分级
- 高质量来源:维基百科、教科书、政府/学术网站、权威新闻 → 上采样(重复多次)。
- 低质量来源:论坛灌水、自动生成、事实错误 → 下采样或直接剔除。
- 指标:准确性、权威性、有用性、可读性(可由人工+模型联合打分)。
⑤ 去重
- 全局 MinHash / SimHash 检测段落级重复;阈值通常设为 90% 相似度。
- 案例:某婚庆公司广告段落出现 6 万余次,去重后将其权重降至零,防止模型“背广告”。
⑥ 测试集过滤
- 与训练集做反向去重,确保测试样本未在训练阶段曝光。
- 再次执行步骤①–④,保证评估的严谨性与可复现性。
- 效果评估
- 清理后语料规模通常下降 20%–40%,但困惑度(PPL)下降、BLEU/人工评分提升。
- 引入“数据健康报告”:统计每类被过滤内容比例,作为后续迭代依据。
通过上述六步,既保留互联网文本的广度,又最大程度抑制噪声与风险,为大模型提供“干净且富营养”的训练口粮。
【精炼并完善后的文本】
6.8 所有文本资料都能拿来训练“文字接龙”吗?
“海量公开数据≠合法可用”。开发者必须将版权合规纳入数据工程的核心环节,否则模型规模越大,潜在法律风险也越大。
1 是否任何资料都能用于训练?
网络文本虽取之不尽,却并非“拿来即可用”。未经授权的受版权保护内容一旦用于训练,即可能触发侵权诉讼。
2 版权纠纷与法律风险
• 典型案例:2023 年《纽约时报》起诉 OpenAI 与微软,指控其未经授权使用付费新闻训练 GPT 系列。
• 风险点:
– 付费墙后的新闻、学术论文、专利文本、图书、剧本、代码仓库等,均可能受版权或合同条款保护;
– 即使网页公开可见,也不等于放弃版权。
3 开发团队的常见做法
| 做法 | 描述 | 风险等级 |
|---|---|---|
| 大规模爬取公开网页 | 默认“公开即可用”,不筛选版权状态 | 高 |
| 谨慎过滤 | 使用 robots.txt、版权声明、付费墙检测等手段剔除受限内容 | 中 |
| 全授权链路 | 只使用:① 已获直接授权;② 明确 CC-0、CC-BY 等开放许可;③ 自采/自建数据 | 低 |
头部科技公司(Google、Microsoft 等)通常采用第 3 种模式,或与出版机构签署商业许可协议,或自建合法语料库。
4 授权与合规建议
- 建立版权审查流水线
• 元数据识别:抓取时记录域名、版权声明、许可证标签;
• 指纹去重:剔除已知付费内容指纹(如新闻出版商提供的黑名单)。 - 优先使用低风险语料
• 公有领域作品(古腾堡计划、政府公文);
• 开放许可资源(维基百科、CC-BY-SA 新闻、开源代码)。 - 合同与保险
• 与内容方签订“文本挖掘许可”或“AI 训练许可”;
• 购买版权责任保险,降低潜在诉讼成本。
6.9 再训更大的模型也没用:为什么语言模型仍无法好好回答问题?
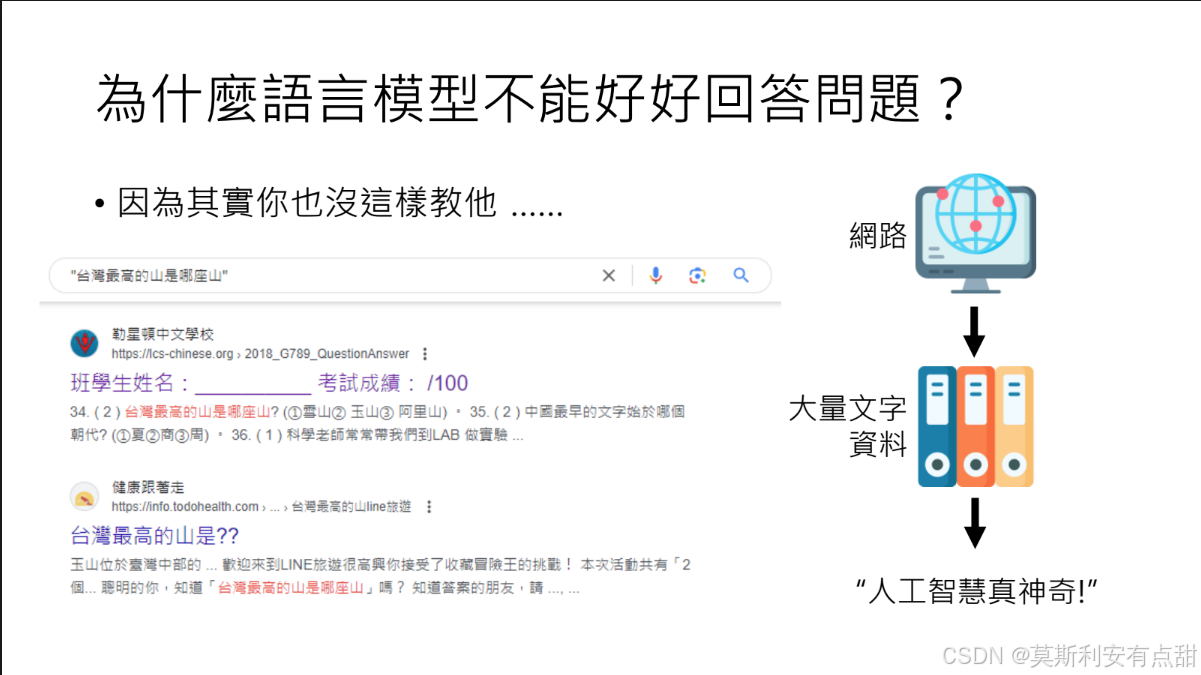
1. 学习方式决定了“只会接龙”
• 训练方法:GPT、PaLM 等模型以无监督“文字接龙”为目标,对互联网、书籍等大规模文本进行下一个 token 的预测。
• 结果:模型学到的是语言形式的统计规律,而非“理解问题—检索知识—组织答案”的显式流程。
2. 缺乏明确的目标引导
• 无答题目标函数:训练语料没有“这是问题—这是标准答案”的成对信号,模型不知道何时该“简洁回答”、何时该“详细解释”。
• 上下文缺失:原始文本不提供“提问者意图、场景约束、答案格式”等关键信息,导致输出往往“答非所问”或冗长发散。
3. 无效的自问自答模式
• 现象示例:问“3×7 等于几?”,模型可能继续生成“那么 7×3 呢?”、“再考虑 3×8…”等衍生问题,而非直接给出“21”。
• 根因:训练时从未被要求“先给出答案”,而是最大化“生成与 prompt 最连贯的后续文本”,于是倾向于扩展话题而非解决问题。
4. 大模型预训练的困境与解决思路
• 虽然语言模型通过大量的无监督学习,积累了大量的文本数据和潜在的语言能力,但纯粹扩大参数量与数据量,只能让模型更熟练地“背台词”,模型并不清楚如何有效地使用这些能力来回答实际问题。
• 解决思路:通过人为设计任务目标、对齐机制与评估标准,使得模型的“内功”转化为可靠的“解题能力”。
